
2020 [و نیمه اول 2021] یک قو سیاه بود. خانوادهها، جوامع و شرکتها باید با چیزهایی روبرو میشدند که نمیتوانستند تصور کنند. در این پست، سعی میکنم نحوه تطبیق تیم ParallelDots AI در این دوره و ساختن نسل بعدی راهحلهای هوش مصنوعی خردهفروشی ما را برجسته کنم.
ParallelDots در فوریه 2020 وارد حالت کار از راه دور کامل شد و از آن زمان تا کنون تیم برای یک روز ملاقات فیزیکی نداشته است. ما همیشه قبل از آن یک واحد بسیار فشرده بودیم و بنابراین چند هفته اول کاملاً صرف ایجاد فرهنگ کار از راه دور شد. ما باید به ارتباط بهتر و ساختار مالکیت بسیار متفاوت فکر می کردیم. با توجه به اینکه شرکت با یک شوک تجاری نیز دست و پنجه نرم می کرد، این هفته ها سخت بود. من شخصاً به روشی که تیم ما فشار را مدیریت کرد و نه تنها تنظیم کرد، بلکه تکامل یافت تا به بهترین دستگاه کوبنده فناوری تبدیل شود، افتخار می کنم. فقط چند هفته تغییراتی انجام دادیم و ما عالی بودیم.
چالشهای تیم هوش مصنوعی [حدود مارس 2020]
[شما ممکن است «چرا» الگوریتمها و سیستمهای هوش مصنوعی مختلفی را که در حال ساخت هستیم خستهکننده بدانید، میدانم زیرا این کار را انجام میدهم. به بخش "سیستم ها و الگوریتم های جدید" بروید]
نقش تیم هوش مصنوعی ParallelDots حل مشکلات مختلف است که زیرساخت آموزش و استقرار هوش مصنوعی ما را در ParallelDots تنگ می کند. شما می توانید این چالش ها را به این موارد تقسیم کنید: الف. تنگناهای آموزش هوش مصنوعی و دقت [یا تنگناهای تحقیقاتی] و ب. تنگناهای استقرار/استنتاج [یا تنگناهای MLOPS که ما آنها را می نامیم]. در ابتدای سال 2020، در حالی که فناوری هوش مصنوعی ما در حال پردازش بیش از یک میلیون تصویر در ماه بود، برخی از چالشهایی که انتظار میرفت برای افزایش مقیاس آن حل کنیم عبارت بودند از:
- استقرار یک زیرساخت استنتاج که می تواند به طور خودکار افزایش یابد در صورتی که تصاویر خرده فروشی زیادی برای پردازش وجود داشته باشد تا SLA های ما حفظ شود و در عین حال مطمئن شویم که استقرار برای بارهای کاری کوچک کاهش یافته است. پردازندههای گرافیکی ماشینهای پرهزینهای هستند و داشتن یک زیرساخت ثابت [یا خارج از قفسه یا توسعهدهی دستی] طناب محکمی بین ملاقات با SLA و اجتناب از هزینههای بالا است.
- اجرای الگوریتمهای بینایی رایانه خردهفروشی ما روی تلفن. ما همیشه به محصول جدیدی فکر میکردیم که در آن از هوش مصنوعی لبهای در تلفن در فروشگاههای خردهفروشی کوچک با اتصال اینترنت کند برای مدیریت صورتحساب/GRN/مدیریت موجودی استفاده شود. نه فقط این، برخی از مشتریان بالقوه ساعت شلفساعت ما بهدنبال استقرارهایی بودند که میتوانستند در فروشگاهها برای استنتاج سریع بدون انتظار برای آپلود و پردازش تصویر استفاده شوند. ما میدانستیم که اگر بتوانیم الگوریتمهای هوش مصنوعی خردهفروشیمان را روی تلفنها اجرا کنیم، به ما کمک میکند تا محصول دوم رویایی خود را بسازیم، اما همچنین به محصول فعلیمان کمک میکند مشتریان جدیدی پیدا کند. هر دو چالش فوق به عنوان چالش های MLOPS هستند.
- تشخیص انواع اندازه محصولات در تصاویر. چالش دیگر تشخیص تغییرات سطح اندازه برای یک محصول در تصاویر خرده فروشی بود. به عنوان مثال، فرض کنید که شما تصویر قفسهای از تراشهها دارید و باید تعداد نه تنها ماسالای جادویی Lay را با استفاده از هوش مصنوعی تشخیص دهید، بلکه باید بین بستههای 10 INR / 20 INR / 30 INR از Lay's Magic masala تقسیم کنید. در تحلیل شما برای افرادی که در Computer Vision کار نکرده اند، این ممکن است مشکل بعدی واضح و ساده ای باشد که باید حل شود، زیرا هوش مصنوعی می تواند محصول را در قفسه تشخیص دهد و آنها را به عنوان مارک ها با دقت بسیار بالا طبقه بندی کند. اما شما XKCD #1425 معروف را میشناسید [همیشه یک XKCD مرتبط برای همه چیز وجود دارد. ]. XKCD مربوطه
- بررسی قطعات نقطه فروش مواد. بخش دیگری از تجزیه و تحلیل تصاویر قفسه جدا از شناسایی و شناسایی محصولات موجود در قفسه، تأیید وجود مواد مختلف نقطه فروش در قفسه است. این مواد فروش، چیزهایی هستند که اغلب در فروشگاههای خردهفروشی یا kirana اطراف خود میبینید، مانند نوارهای قفسه، برش، پوستر، گاندولا و قفسههای نمایشی. ما از تطبیق Deep Keypoint برای چنین مسابقاتی برای مدت طولانی استفاده می کردیم و قبلاً خوب کار می کرد. با این حال، با گذشت زمان، مشتریان از ما خواستند که نه تنها POSM را در تصاویر قفسه تأیید کنیم، بلکه به قطعات گمشدهای که ممکن است یک فروشنده در یک POSM از دست داده باشد نیز اشاره کنیم. به عنوان مثال، یک فروشنده ممکن است از قرار دادن یک پوستر روی یک قفسه نمایشی غافل شده باشد یا ممکن است به دلیل تصادف در فروشگاه حذف شده باشد. برای انجام این کار بسیار دقیق در سطحی که طبقهبندی تصاویر در آن کار میکند، به الگوریتمی نیاز داشتیم که در همه جا بدون آموزش کار کند، زیرا POSMها در عرض چند هفته/ماه تغییر میکنند.
- آموزش آشکارسازهای محصولات قفسه ای دقیق تر. Retail Shelf Computer Vision به سمت فناوری داشتن یک آشکارساز شی قفسه عمومی [استخراج هر شی قفسه بدون طبقهبندی آن] در مرحله اول و سپس طبقهبندی محصولات و سپس استخراج در مرحله دوم برای جلوگیری از مشکلات ردیابهای یک مرحلهای + طبقهبندیکننده حرکت کرده است. ایجاد [چولگی عظیم محصول در قفسهها که خروجیهای طبقهبندی بد ایجاد میکند/آموزش دادههای زیادی در هر پروژه و بدون سود افزایشی از هوش مصنوعی بهتر از پروژههای قبلی و غیره]. ما قبلاً چنین سیستمی از یک آشکارساز شی قفسه عمومی و یک طبقهبندی پیشرفته را در مرحله دوم در سال 2019 داشتیم، اما شکل جعبه خروجی آشکارساز شی قفسه میتوانست بهتر باشد.
- استفاده از آموزش های قبلی هوش مصنوعی و تصحیح خطا برای آموزش بهتر و سریع تر طبقه بندی کننده ها. ما طبقهبندیکنندههای زیادی [مدلهایی که اشیای قفسه استخراجشده توسط الگوریتم مرحله ۱ را به یکی از مارکهای محصول مورد نیاز ما طبقهبندی میکنند] آموزش میدهیم. آیا راهی برای استفاده از تمام دادههای آموزشی که جمعآوری میکنیم، از جمله اشتباهات طبقهبندیکنندههای گذشته برای ایجاد الگوریتمی وجود دارد که میتواند به آموزش سریع و دقیقتر طبقهبندیکنندههای جدید کمک کند، سوالی است که همیشه وجود دارد. چهار مشکل تحقیقاتی [1-3] که پیدا کردید، نیازمندی های جدید محصول ساعت قفسه ما [6،3,4] و بهبود پشته موجود [5,6،XNUMX] را منعکس می کند. اکنون مجموعه ای از مشکلات تحقیقاتی از پشته NLP APIهای ما نیز وجود داشت.
- یک API تجزیه و تحلیل احساسات عمومی تر. API تجزیه و تحلیل احساسات که ما به صورت آنلاین داشتیم روی توییتهای حاشیهنویسی داخلی آموزش داده شده بود و بنابراین علیرغم داشتن دقت بالا، ممکن است در موارد خاص دامنهای مانند مقالات سیاسی یا مالی شکست بخورد. برخلاف توییتها، چنین مقالات دامنه متفاوتی توسط افرادی که در حوزه مجموعه داده تجربه ندارند، سخت است. استفاده از بسیاری از دادههای بدون حاشیه برای آموزش طبقهبندیکنندههایی که میتوانند در سراسر دامنه کار کنند، یک چالش همیشه بوده است.
- یک API احساسات هدفمند جدید. تحلیل احساسات مبتنی بر جنبه مدتی است که وجود داشته است. ما در نهایت یک مجموعه داده مشروح داخلی برای چنین تحلیلی داشتیم، اما هدف ما تا حدودی مشخص تر بود. ما میخواستیم یک API بسازیم که در آن یک جمله بگویید: «سیب خوشمزه نبود اما پرتقال واقعاً خوشمزه بود». هنگامی که برای "Apple" تجزیه و تحلیل می شود، خروجی منفی یا زمانی که برای نارنجی آنالیز می شود، مثبت است. بنابراین ما قصد داشتیم یک الگوریتم تحلیل احساسات مبتنی بر جنبه را بسازیم.
اکنون که شما را از جزئیات چالش هایی که می خواستیم حل کنیم خسته کردم، بیایید به قسمت جالب آن برسیم. پلتفرم ها و الگوریتم های جدید MLOPS ما.
سیستم ها و الگوریتم های جدید
اجازه دهید دوستان جدیدم را به شما معرفی کنم، برخی از سیستمهای فنآوری عالی و الگوریتمهای هوش مصنوعی را که در آخرین زمان برای مقابله با تنگناها توسعه دادهایم و به کار گرفتهایم.
هوش مصنوعی تشخیص محصول موبایل یا هوش مصنوعی تشخیص قفسه موبایل
معرفی ParallelDots Oogashop – ارتباط دادن
(فید و ویدیو LinkedIn)
ما نه یک، بلکه دو نوع مختلف الگوریتم هوش مصنوعی را بر روی دستگاه های تلفن همراه ساخته و به کار گرفته ایم. ممکن است چند روز پیش پستهای بسیار ویروسی ما را دیده باشید که در آن صورتحساب تلفن همراه را به نمایش گذاشتیم و در مورد ممیزیهای قفسه آفلاین صحبت کردیم.
در اینجا پیوند به ویژگی تشخیص تصویر روی دستگاه (ODIN) ShelfWatch است - ارتباط دادن
(مقاله)
اساساً، این مدلهای هوش مصنوعی نسخههای کوچکتری از مدلهایی هستند که ما در فضای ابری به کار میبریم. با اندکی کاهش دقت، این مدلها اکنون به اندازهای کوچک هستند که میتوانند روی یک GPU تلفن [که بسیار کوچکتر از یک پردازنده گرافیکی سرویس است] اجرا شوند. چارچوبهای جدید استقرار تلفن همراه Tensorflow همان چیزی است که ما برای استقرار این مدلها به ترتیب در برنامه OOGASHOP و ShelfWatch خود استفاده میکنیم.
(کاغذ) تقسیم بندی قفسه خرده فروشی فشرده برای استقرار موبایل - ارتباط دادن
پراتیوش کومار، موکتاب مایانک سریواستاوا
مقیاس خودکار استنباط هوش مصنوعی ابری
وقتی مغازهها حوالی ساعت 11 صبح باز میشوند [11 صبح برای مناطق زمانی مختلف، یعنی در هر کجای دنیا که مشتریان ما نیروی فروش یا فروشندههای خود را دارند]، سرورهای ما با حجم دیوانهواری از تاجران مواجه میشوند که عکسهایی را در فضای ابری ما آپلود میکنند تا آنها را پردازش کرده و در مورد آنها بگوییم. امتیاز اجرای خرده فروشی و بعد از ساعت 11 شب که فروشگاههای خردهفروشی بسته میشوند، به سختی حجم کار استنتاج هوش مصنوعی کافی نداریم. در حالی که مقیاس خودکار مانند Lambda توسط بسیاری از ارائه دهندگان معرفی شده است، ما یک تکنیک مقیاس خودکار مستقل ابری برای زیرساخت استنتاج هوش مصنوعی خود می خواستیم. هنگامی که تصاویر بیشتری در صف پردازش ما وجود دارد، ما به GPU های بیشتری نیاز داریم که آنها را خرد کنند، در غیر این صورت فقط یکی یا شاید هیچ کدام. برای انجام این کار، کل لایه استنتاج هوش مصنوعی به معماری مبتنی بر Docker، Kubernetes و KEDA منتقل شد که در آن تعداد دلخواه پردازندههای گرافیکی جدید میتوانند بر اساس حجم کار ایجاد شوند. دیگر نیازی به تلاش برای مدیریت SLA شرکت و صرفه جویی در هزینه های پرهزینه برای اجرای ماشین های GPU نیست.
بهبود الگوریتم های تشخیص اشیاء قفسه
(مقاله) آموزش نقشه های گاوسی برای تشخیص اشیاء متراکم - ارتباط دادن
سونال کانت
ما قبلاً از RCNNهای سریعتر ساده استفاده می کردیم که قبلاً برای استخراج شی قفسه آموزش دیده بودند: مقاله ساده تشخیص شیء پایه . برای بسیاری از موارد استفاده به خوبی کار کرد. اما ما به رویکردهای پیشرفته تری نیاز داشتیم. در سال 2020 تیم ما روش جدیدی را برای استفاده از نقشه های گاوسی برای به دست آوردن نتایج جدید کشف کرد. این اثر [بعداً در BMVC، یکی از برترین کنفرانسهای Computer Vision منتشر شد وب سایت BMVC ] به ما کمک کرد تا نه تنها رضایت بخش، بلکه بهترین نتایج ممکن را در تشخیص شی قفسه به دست آوریم.
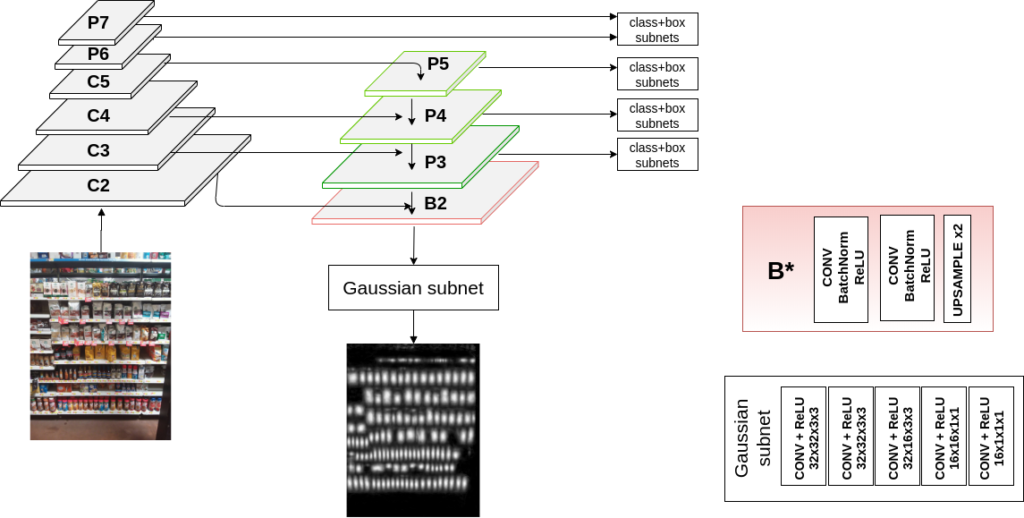
ترفند اساساً استفاده از آموزش نقشههای گاوسی به عنوان یک آسیب کمکی برای تشخیص اشیا است. این کار جعبه های محصولات مختلف را بسیار دقیق تر می کند.
سوال دیگری که ما مدتهاست در تلاش بودیم به آن در زمینه تشخیص اشیاء قفسه بپردازیم این بود که اکنون که نیاز به تشخیص محصولات به یک کار پایین دستی منتقل شده است و وظیفه ترسیم جعبه روی همه محصولات ممکن است، آیا وجود دارد روشی برای استفاده از نویزها و اعوجاج های موجود در یک مجموعه داده عظیم بدون حاشیه برای تشخیص بهتر شی قفسه. در یک کار اخیر، [به آن اشاره شد کارگاه RetailVision در CVPR 2021 کارگاه چشم انداز خرده فروشی ]، ما از مخزن عظیم خود از تصاویر قفسه بدون حاشیه نویسی استفاده می کنیم تا دقت کار تشخیص اشیاء قفسه را بهتر کنیم.
(مقاله) آموزش نیمه نظارتی برای تشخیص اجسام متراکم در صحنه های خرده فروشی – ارتباط دادن
Jaydeep Chauhan، Srikrishna Varadarajan، Muktabh Mayank Srivastava
آموزش دانشآموز مبتنی بر برچسب Psuedola ترفندی است که ما در زمینههای مختلف استفاده کردهایم، نه برای تشخیص اشیاء قفسه. در حالی که سایر تکنیکهای خودآموزی نیاز به بارگذاری دستهای بزرگ در پردازندههای گرافیکی دارند، بنابراین امتحان کردن آنها برای شرکتی مانند سختافزار محدود مانند ParallelDots دشوار میشود. ، برچسبهای کاذب همان چیزی است که ما به عنوان ترفند خود برای انجام خودآموزی تک GPU اقتباس کردهایم.
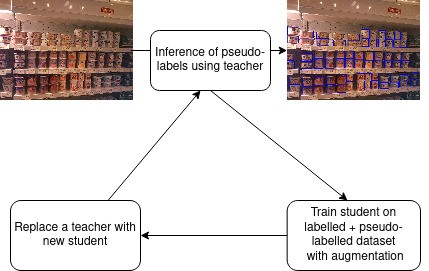
بهبود دقت طبقه بندی
ما در گذشته از ترفندهای متعددی برای آموزش طبقه بندی کننده های دقیق با دقت بالا استفاده کرده ایم.
(کاغذی) کیسه ترفندهایی برای طبقه بندی تصویر محصول خرده فروشی – ارتباط دادن، که نشان می دهد چگونه طبقه بندی کننده ها را با دقت بالا آموزش می دهیم.
Muktabh Mayank Srivastava
تمام جعبههایی که آشکارساز شی قفسه از یک تصویر قفسه استخراج میکند از طریق این طبقهبندیکننده عبور داده میشود تا برند محصول را استنتاج کند.
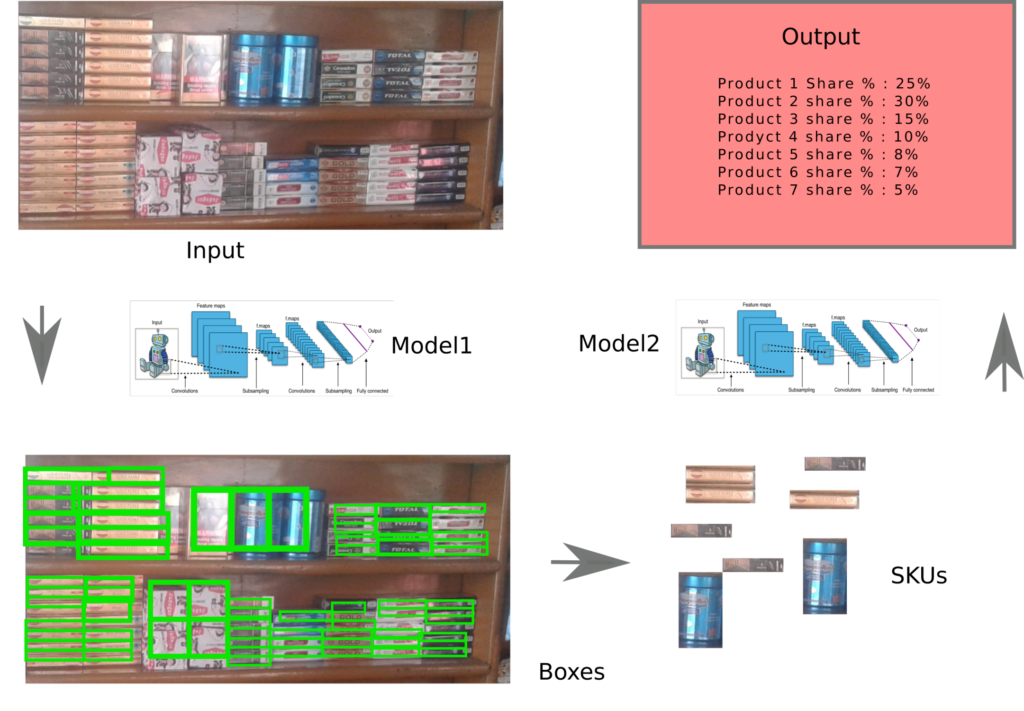
با این حال، با تغییر مکرر کاتالوگهای فروشگاه، طبقهبندیکننده محصولات ما باید تکامل یابد تا کارها را کمی متفاوت انجام دهد. آموزش طبقهبندیکننده منابع فشردهای است، با محصولاتی که به سرعت از کاتالوگهای فروشگاهها اضافه یا حذف میشوند، ما به طبقهبندیکنندهای نیاز داریم که بتوان سریعتر آموزش داد و دقیقتر یا حداقل به اندازه روشهای مربوط به تنظیم دقیق ستون فقرات کامل باشد. این به نظر می رسد که یک کیک داشته باشید و آن را نیز رتبه بندی کنید، و این همان کاری است که تکنیک های خودآموزی در یادگیری عمیق نشان داده شده است. ما سعی کردهایم از مفاهیم Self Learning برای ایجاد طبقهبندیکنندههایی استفاده کنیم که میتوانند بسیار سبک آموزش داده شوند.
(مقاله) استفاده از یادگیری متضاد و برچسب های شبه برای یادگیری بازنمایی برای طبقه بندی تصویر محصول خرده فروشی - ارتباط دادن
Muktabh Mayank Srivastava
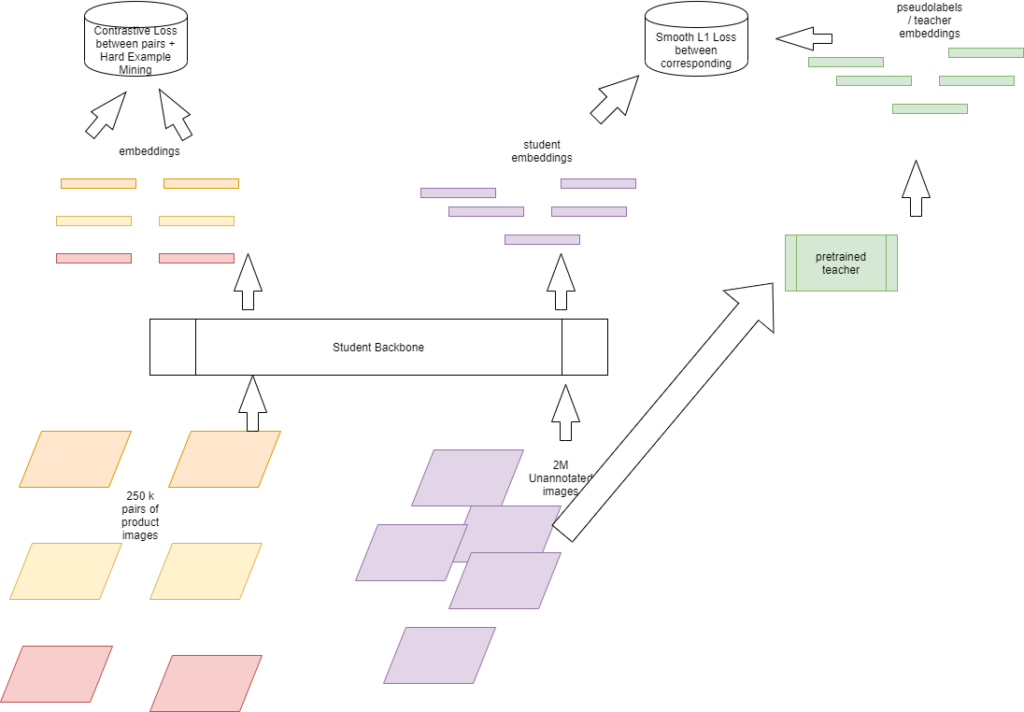
ترفندی که ما در اینجا استفاده میکنیم، استفاده از مخزن عظیم تصاویر محصول خردهفروشی است که [هر دو با حاشیهنویسی و بدون حاشیه] برای آموزش یک یادگیرنده بازنمایی، که خروجی آن میتواند به یک طبقهبندیکننده ساده یادگیری ماشینی برای آموزش داده شود، استفاده میکند. چنین نمایش ویژگی های آموخته شده کاملاً خوب کار می کند. آموزش یک طبقه بندی کننده رگرسیون لجستیک کوچک برای طبقه بندی تصاویر خرده فروشی چقدر جالب است. متأسفانه، ما بیش از 20 برابر تصاویر بیشتری برای چنین کارهایی داریم، بنابراین در حال حاضر دقت ما به زیرساخت سخت افزاری محدود برای انجام چنین خودآموزی محدود شده است و هنوز هم ما در بسیاری از مجموعه داده ها [نه همه] از پیشرفته ترین موارد استفاده می کنیم.
استنتاج بر اساس اندازه در تصاویر قفسه

در حالی که ما مارک های محصولات مختلف را که در تصاویر قفسه دیده می شود شناسایی کرده ایم، مشخصات اخیری که سعی کرده ایم آن را حل کنیم این است که در مورد اینکه محصولی که به آن وابسته هستیم چه نوع اندازه ای از یک محصول است، استدلال کنیم. به عنوان مثال، در حالی که خط لوله Computer Vision یک Lays Magic Masala را در قفسه تشخیص می دهد و آن را به عنوان Lays Magic Masala طبقه بندی می کند، چگونه بفهمیم که نوع 50 گرمی یا نوع 100 گرمی یا نوع 200 گرمی محصول است. بنابراین ما سومین وظیفه پایین دستی را برای حدس زدن نوع اندازه قفسه اضافه می کنیم. این خط لوله جعبه های مختلف استخراج شده از قفسه، مارک های آنها را می گیرد و ویژگی هایی ایجاد می کند که می توان از آنها برای حدس زدن اندازه استفاده کرد. همانطور که واضح است، شما نمی توانید از مختصات جعبه مرزی یا ناحیه برای چنین استدلالی استفاده کنید زیرا می توان تصاویر را از هر فاصله ای گرفت. ما از ویژگی هایی مانند نسبت ابعاد و نسبت مساحت بین جعبه های گروه های مختلف برای استنباط نوع اندازه استفاده می کنیم.
(مقاله) رویکردهای یادگیری ماشین برای انجام استدلال بر اساس اندازه بر روی اشیاء قفسه خرده فروشی برای طبقه بندی انواع محصول - ارتباط دادن
Muktabh Mayank Srivastava، Pratyush Kumar
بسیاری از ترفندهای مهندسی ویژگی برای آموزش دو نوع کار استدلال استفاده میشوند: استفاده از XGBOOST روی ویژگیهای binned و استفاده از شبکه عصبی بر روی ویژگیهای مشتق شده از مدل مخلوط گاوسی.

استدلال در مورد مواد نقطه فروش
وقتی وارد یک فروشگاه خرده فروشی می شوید، متوجه مواد مختلف POSM خواهید شد: نوارهای قفسه، برش، پوستر، گاندولا و قفسه های نمایشی.

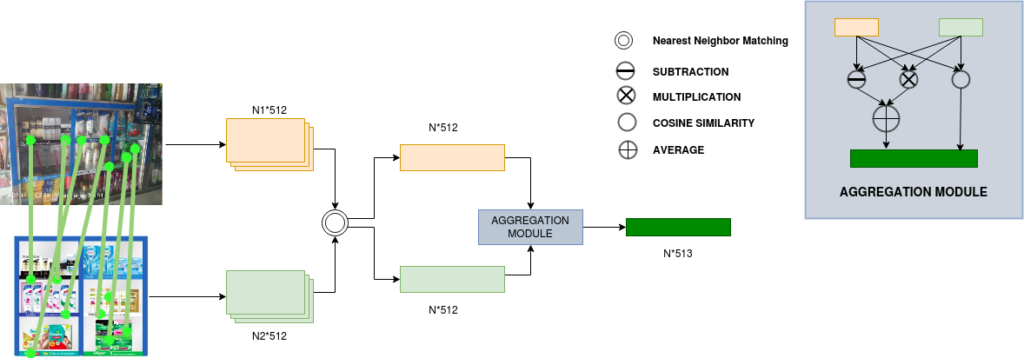
در حالی که ما از تطبیق نمایش نقطه کلیدی مبتنی بر یادگیری عمیق برای تأیید حضور POSM در یک تصویر استفاده میکردیم، وظیفه استدلال در مورد POSM بخش به بخش وجود داشت. به عنوان مثال، در مثال بالا، ممکن است لازم باشد بررسی کنیم که آیا عکس محصول به سمت راست در نوار قفسه ایدهآل در حال حاضر در یک مکان واقعی است یا خیر. ما پس از تأیید POSM به این «تشخیص بخش» می گوییم.
(مقاله) استفاده از تطبیق نقطه کلید و شبکه تعاملی خود توجه برای تأیید POSM های خرده فروشی - ارتباط دادن
هارشیتا ست، سونال کانت، مکتاب مایانک سریواستاوا
اساساً از آنجایی که POSM به صورت هفتگی/ماهانه خیلی سریع تغییر می کند، شما هرگز نمی توانید داده های زیادی برای آموزش الگوریتم های هر POSM به دست آورید. بنابراین ما به الگوریتمهایی نیاز داریم که به گونهای بر روی مجموعه دادههای موجود آموزش داده شوند تا بتوان آنها را بر روی هر مجموعه داده اعمال کرد. این هدف ما از کار اخیر شبکه توجه به خود برای POSM ها است. ما از نقاط کلیدی همسان [در تصویر POSM ایده آل و تصویر کلمه واقعی] و توصیفگرهای آنها [از هر دو تصویر] به عنوان ورودی برای هر بخش به طور جداگانه برای تعیین حضور دقیق استفاده می کنیم.
یک API تجزیه و تحلیل احساسات که روی هر داده دامنه کار می کند
هنگام آموزش یک مدل برای استقرار به عنوان یک API تجزیه و تحلیل احساسات، واقعاً نمی توانید داده هایی را از دامنه های مختلف مشروح دریافت کنید. به عنوان مثال، مدل قبلی تجزیه و تحلیل احساسات ما یک مدل زبان بزرگ بود که با 10 تا 15 هزار توئیت عجیب و غریب که در داخل حاشیهنویسی کردیم، تنظیم شده بود. بنابراین الگوریتم به سختی احساسات بیان شده در حوزه های مختلف را در حین یادگیری مشاهده کرده است. ما سعی کردیم از خودآموزی استفاده کنیم تا الگوریتم طبقهبندی احساسات خود را برای تغییر دامنه مستحکم کنیم. 2 میلیون + جمله بدون حاشیه بردارید، یک نسخه قدیمی از طبقه بندی کننده را اجرا کنید تا برچسب های کاذب ایجاد کنید و یک طبقه بندی کننده جدید آموزش دهید تا این برچسب های کاذب را یاد بگیرد و رونق بگیرد. یکسان. خیلی خوب به نظر می رسد که درست باشد، کار ما را بررسی کنید:
(مقاله) استفاده از برچسبهای کاذب برای آموزش طبقهبندیکننده احساسات باعث میشود که مدل در بین مجموعههای داده تعمیم بهتری داشته باشد - ارتباط دادن
ناتش ردی، موکتاب مایانک سریواستاوا
ایجاد یک روش پیشرفته برای تشخیص احساسات هدفمند
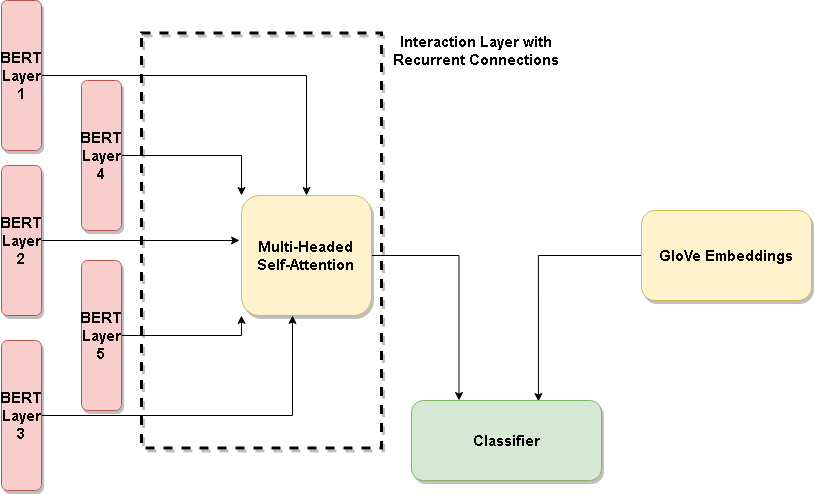
برای ما، در کسب و کار NLP API، احساسات هدفمند زمانی است که شما جمله «سیب آنقدرها هم خوشمزه نبود، اما نارنجی خوب بود» را دارید، یک طبقهبندی کننده وقتی ورودی «سیب» را دریافت کرد، منفی و اگر ورودی نارنجی دریافت کرد، مثبت است. اساساً، احساس معطوف به یک شی در جمله. ما روش جدیدی را توسعه دادهایم که احساسات هدفمند را شناسایی میکند و به زودی به عنوان NLP API در دسترس خواهد بود. زمینه تحقیق با تجزیه و تحلیل احساسات مبتنی بر جنبه مطابقت دارد و کار اخیر ما نتایج پیشرفتهای را در مجموعه دادههای متعدد به دست میآورد، فقط با تنظیم دقیق یک معماری در مقایسه متنی [BERT] و غیر متنی [GloVe]. این احساس در جایی پنهان شده است، درست است؟
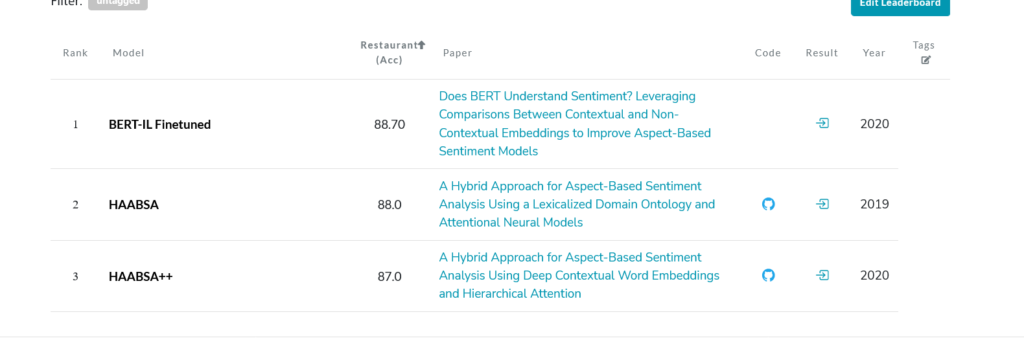
(مقاله) آیا BERT احساسات را درک می کند؟ استفاده از مقایسه بین تعبیههای متنی و غیر متنی برای بهبود مدلهای احساسات مبتنی بر جنبه - ارتباط دادن
به جلو و بالا
امیدوارم از فناوری جدیدی که ما در سال گذشته توسعه داده ایم خوشتان بیاید. بسیار خوشحالم که اگر سوالی دارید پاسخ دهید. ما همچنان به توسعه فناوری جدید و هیجانانگیز ادامه میدهیم و در حال کار روی برخی مشکلات جدید یادگیری ماشینی مانند شبکههای عصبی نمودار برای توصیههای خردهفروشی، طبقهبندی تصاویر خارج از توزیع و مدلهای زبان هستیم. ما نیز در حال استخدام هستیم، برای ما در careers@paralleldots.com بنویسید یا در صفحه AngelList ما درخواست دهید تا به تیم هوش مصنوعی ما بپیوندید. اگر می خواهید مهندس یادگیری ماشین، توسعه دهنده Backend یا مدیر پروژه هوش مصنوعی باشید، می توانید درخواست دهید. ParallelDots AngelList

وبلاگ را دوست داشتید؟ دیگر ما را بررسی کنید وبلاگ ها ببینید چگونه فناوری تشخیص تصویر می تواند به برندها در بهبود استراتژی های اجرایی خود در خرده فروشی کمک کند.
آیا می خواهید ببینید که برند شما در قفسه ها چگونه عمل می کند؟ کلیک اینجا کلیک نمایید برای برنامه ریزی یک نسخه ی نمایشی رایگان برای ShelfWatch.
- &
- 100
- 11
- 2019
- 2020
- 2021
- AI
- آموزش هوش مصنوعی
- الگوریتم
- الگوریتم
- معرفی
- تحلیل
- فرشته شناس
- API
- رابط های برنامه کاربردی
- نرم افزار
- اپل
- معماری
- محدوده
- دور و بر
- هنر
- مقاله
- مقالات
- نماد
- خط مقدم
- بهترین
- صدور صورت حساب
- بیت
- سیاه پوست
- بلاگ
- رونق
- جعبه
- مارک های
- ساختن
- بنا
- کسب و کار
- صدا
- موارد
- به چالش
- تغییر دادن
- رئیس
- چیپس
- طبقه بندی
- مشتریان
- ابر
- ارتباط
- شرکت
- شرکت
- چشم انداز کامپیوتر
- ارتباط
- ادامه دادن
- اصلاحات
- هزینه
- ایجاد
- فرهنگ
- مشتریان
- CVPR
- داده ها
- علم اطلاعات
- دانشمند داده
- روز
- معامله
- یادگیری عمیق
- کشف
- توسعه
- توسعه دهنده
- دستگاه ها
- DevOps
- کشف
- فاصله
- کارگر بارانداز
- حوزه
- مهندس
- مهندسی
- اعدام
- استخراج
- عصاره ها
- چهره
- خانواده
- FAST
- ویژگی
- امکانات
- تغذیه
- زمینه
- سرانجام
- سرمایه گذاری
- نام خانوادگی
- رایگان
- کامل
- GitHub
- خوب
- GPU
- GPU ها
- گرم
- نمودارهای عصبی نمودار
- بزرگ
- سخت افزار
- اینجا کلیک نمایید
- زیاد
- نماد
- استخدام
- چگونه
- HTTPS
- بزرگ
- تصویر
- شناسایی تصویر
- از جمله
- شالوده
- تعاملی
- اینترنت
- IT
- پیوستن
- کوبرنیتس
- زبان
- بزرگ
- یاد گرفتن
- فراگیر
- یادگیری
- سطح
- محدود شده
- ارتباط دادن
- لینک
- بار
- طولانی
- فراگیری ماشین
- ماشین آلات
- ساخت
- مرد
- مدیریت
- نقشه ها
- مارس
- مارس 2020
- مصالح
- میلیون
- MLO ها
- موبایل
- دستگاه های تلفن همراه
- تلفن همراه
- مدل
- حرکت
- شبکه
- شبکه
- عصبی
- شبکه های عصبی
- شبکه های عصبی
- محصول جدید
- nlp
- تشخیص شی
- آنلاین
- باز کن
- دیگر
- مقاله
- مردم
- گوشی های
- سیستم عامل
- نقطه فروش
- پست ها
- در حال حاضر
- فشار
- محصول
- محصولات
- پروژه
- پروژه ها
- دنیای واقعی
- رگرسیون
- کار از راه دور
- کار از راه دور
- گزارش
- مورد نیاز
- تحقیق
- منابع
- نتایج
- خرده فروشی
- اجرای خرده فروشی
- بازده
- دویدن
- فروش
- حراجی
- salesforce
- صرفه جویی کردن
- مقیاس
- علم
- احساس
- تنظیم
- منگوله
- مغازه ها
- ساده
- اندازه
- کوچک
- So
- مزایا
- حل
- انشعاب
- دولت
- opbevare
- پرده
- نوار
- دانشجو
- سیستم
- سیستم های
- فن آوری
- تکنیک
- پیشرفته
- جهان
- زمان
- بالا
- آموزش
- us
- تایید
- تصویری
- دید
- صبر کنيد
- WHO
- در داخل
- مهاجرت کاری
- با این نسخهها کار
- جهان
- سال




