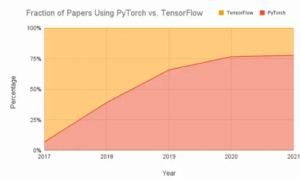
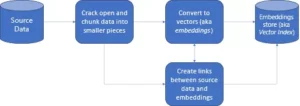
معرفی
در چشم انداز به سرعت در حال تحول هوش مصنوعی مولد، نقش محوری پایگاه های داده برداری به طور فزاینده ای آشکار شده است. این مقاله به هم افزایی پویا بین پایگاههای داده برداری و راهحلهای هوش مصنوعی مولد میپردازد و چگونگی شکلدهی آینده خلاقیت هوش مصنوعی را این بسترهای فناوری بررسی میکند. در سفری به پیچیدگیهای این اتحاد قدرتمند به ما بپیوندید، و بینشهایی را در مورد تأثیر تحولآفرینی که پایگاههای اطلاعاتی برداری در خط مقدم راهحلهای هوش مصنوعی نوآورانه به ارمغان میآورند، باز کنید.
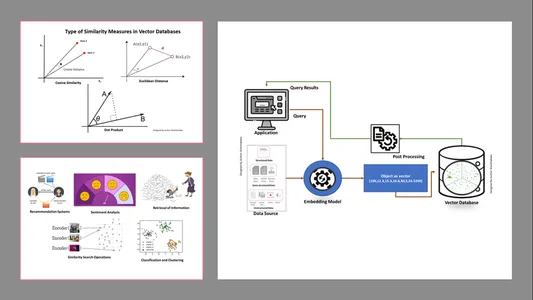
اهداف یادگیری
این مقاله به شما کمک می کند تا جنبه های پایگاه داده برداری زیر را درک کنید.
- اهمیت پایگاه های داده برداری و اجزای کلیدی آن
- مطالعه تفصیلی مقایسه پایگاه داده برداری با پایگاه داده سنتی
- کاوش تعبیههای برداری از دیدگاه کاربردی
- ساخت پایگاه داده برداری با استفاده از Pincone
- پیاده سازی پایگاه داده Pinecone Vector با استفاده از مدل langchain LLM
این مقاله به عنوان بخشی از بلاگاتون علم داده.
جدول محتوا
پایگاه داده برداری چیست؟
پایگاه داده برداری شکلی از جمع آوری داده های ذخیره شده در فضا است. با این حال، در اینجا، در نمایشهای ریاضی ذخیره میشود، زیرا قالب ذخیرهشده در پایگاههای داده، به خاطر سپردن ورودیها برای مدلهای هوش مصنوعی باز آسانتر میشود و به برنامه هوش مصنوعی باز ما اجازه میدهد از جستجوی شناختی، توصیهها و تولید متن برای موارد با کاربردهای مختلف استفاده کند. صنایع تبدیل شده دیجیتالی ذخیره سازی و بازیابی داده ها "جاسازی های برداری" یا "جاسازی ها" نامیده می شود. علاوه بر این، این در قالب آرایه عددی نشان داده شده است. جستجو بسیار ساده تر از پایگاه های داده سنتی است که برای دیدگاه های هوش مصنوعی با قابلیت های گسترده و نمایه شده استفاده می شود.
ویژگی های پایگاه های داده برداری
- از قدرت این تعبیههای برداری استفاده میکند که منجر به نمایهسازی و جستجو در یک مجموعه داده عظیم میشود.
- قابل فشرده سازی با تمام فرمت های داده (تصاویر، متن یا داده).
- از آنجایی که تکنیک های جاسازی و ویژگی های بسیار نمایه شده را تطبیق می دهد، می تواند راه حل کاملی برای مدیریت داده ها و ورودی برای مشکل داده شده ارائه دهد.
- یک پایگاه داده برداری داده ها را از طریق بردارهای با ابعاد بالا شامل صدها بعد سازماندهی می کند. ما می توانیم آنها را خیلی سریع پیکربندی کنیم.
- هر بعد مربوط به ویژگی یا ویژگی خاصی از شی داده ای است که نشان می دهد.
سنتی در مقابل پایگاه داده برداری
- تصویر گردش کار سطح بالا پایگاه داده سنتی و برداری را نشان می دهد
- تعاملات پایگاه داده رسمی از طریق رخ می دهد SQL عبارات و داده های ذخیره شده در قالب ردیف و جدولی.
- در پایگاه داده Vector، تعاملات از طریق متن ساده (به عنوان مثال، انگلیسی) و داده های ذخیره شده در نمایش های ریاضی اتفاق می افتد.
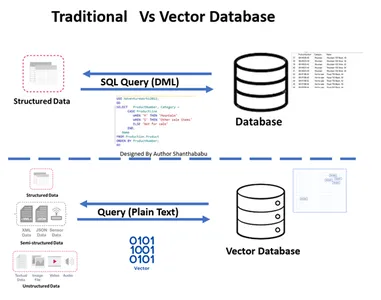
شباهت پایگاههای داده سنتی و برداری
ما باید در نظر بگیریم که پایگاه داده های Vector با پایگاه داده های سنتی چه تفاوتی دارند. بیایید اینجا بحث کنیم. یک تفاوت سریع که می توانم بدهم این است که در پایگاه داده های معمولی. داده ها دقیقاً همانطور که هستند ذخیره می شوند. میتوانیم منطق تجاری را برای تنظیم دادهها و ادغام یا تقسیم دادهها بر اساس الزامات یا خواستههای کسبوکار اضافه کنیم. با این حال، پایگاه داده برداری دارای یک تبدیل عظیم است و داده ها به یک نمایش برداری پیچیده تبدیل می شوند.
در اینجا نقشه ای برای درک و وضوح دیدگاه شما وجود دارد پایگاه داده های ارتباطی در برابر پایگاه های داده برداری تصویر زیر برای درک پایگاههای داده برداری با پایگاههای داده سنتی توضیحی است. به طور خلاصه، ما میتوانیم درجها و حذفها را در پایگاههای داده برداری اجرا کنیم، نه دستورات را بهروزرسانی کنیم.
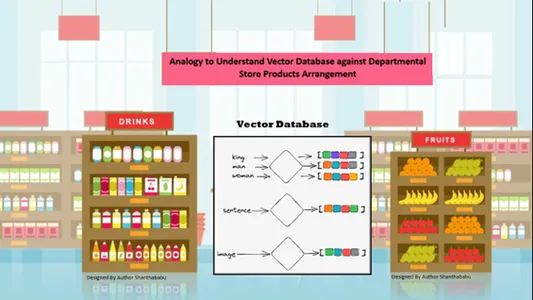
قیاس ساده برای درک پایگاه های داده برداری
داده ها به طور خودکار با شباهت محتوا در اطلاعات ذخیره شده به صورت مکانی مرتب می شوند. بنابراین، بیایید فروشگاه دپارتمان را برای قیاس پایگاه داده برداری در نظر بگیریم. همه محصولات بر اساس ماهیت، هدف، ساخت، استفاده و مقدار پایه در قفسه چیده شده اند. در یک رفتار مشابه، داده ها هستند
به طور خودکار در پایگاه داده برداری با مرتب سازی مشابه، حتی اگر ژانر در هنگام ذخیره یا دسترسی به داده ها به خوبی تعریف نشده باشد.
پایگاه داده های برداری اجازه می دهد تا دانه بندی و ابعاد برجسته در شباهت های خاص وجود داشته باشد، بنابراین مشتری محصول، سازنده و مقدار مورد نظر را جستجو می کند و کالا را در سبد خرید نگه می دارد. پایگاه داده برداری تمام داده ها را در یک ساختار ذخیره سازی کامل ذخیره می کند. در اینجا، مهندسین یادگیری ماشین و هوش مصنوعی نیازی به برچسب گذاری یا برچسب گذاری محتوای ذخیره شده به صورت دستی ندارند.
نظریه های اساسی در پشت پایگاه های داده برداری
- جاسازی های برداری و دامنه آنها
- الزامات نمایه سازی
- درک معنایی و جستجوی تشابه
جاسازی برداری و دامنه آنها
تعبیه برداری یک نمایش برداری بر حسب مقادیر عددی است. در یک فرمت فشرده، جاسازیها ویژگیهای ذاتی و ارتباط دادههای اصلی را به تصویر میکشند و آنها را در موارد استفاده از هوش مصنوعی و یادگیری ماشین تبدیل میکنند. طراحی جاسازیها برای رمزگذاری اطلاعات مربوط به دادههای اصلی در فضایی با ابعاد پایینتر، سرعت بازیابی بالا، کارایی محاسباتی و ذخیرهسازی کارآمد را تضمین میکند.
گرفتن ماهیت داده ها به روشی مشابه ساختار یافته، فرآیند تعبیه برداری است که یک "مدل جاسازی" را تشکیل می دهد. در نهایت، این مدلها همه اشیاء داده را در نظر میگیرند، الگوها و روابط معنیداری را در منبع داده استخراج میکنند و آنها را به جاسازیهای برداری تبدیل میکنند. متعاقباً، الگوریتمها از این تعبیههای برداری برای اجرای وظایف مختلف استفاده میکنند. بسیاری از مدلهای تعبیهشده بسیار توسعهیافته که بهصورت آنلاین بهصورت رایگان یا بهصورت پرداختی در دسترس هستند، انجام تعبیه برداری را تسهیل میکنند.
دامنه جاسازی های برداری از دیدگاه کاربردی
این تعبیهها فشرده هستند، حاوی اطلاعات پیچیده هستند، روابط بین دادههای ذخیره شده در یک پایگاه داده برداری را به ارث میبرند، تجزیه و تحلیل پردازش داده کارآمد را برای تسهیل درک و تصمیمگیری ممکن میسازند، و به صورت پویا محصولات دادههای نوآورانه مختلف را در هر سازمان ایجاد میکنند.
تکنیکهای جاسازی برداری برای اتصال شکاف بین دادههای قابل خواندن و الگوریتمهای پیچیده ضروری هستند. از آنجایی که انواع دادهها بردارهای عددی هستند، ما توانستیم پتانسیل طیف گستردهای از برنامههای هوش مصنوعی مولد را به همراه مدلهای هوش مصنوعی باز موجود باز کنیم.
چندین کار با جاسازی برداری
این تعبیه برداری به ما کمک می کند تا چندین کار را انجام دهیم:
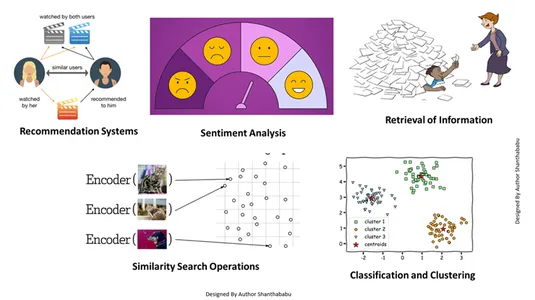
- بازیابی اطلاعات: با کمک این تکنیکهای قدرتمند، میتوانیم موتورهای جستجوی تأثیرگذاری بسازیم که میتوانند به ما در یافتن پاسخها بر اساس درخواستهای کاربر از فایلها، اسناد یا رسانههای ذخیره شده کمک کنند.
- عملیات جستجوی شباهت: این به خوبی سازماندهی شده و نمایه شده است. به ما کمک می کند تا شباهت بین رخدادهای مختلف را در داده های برداری پیدا کنیم.
- طبقه بندی و خوشه بندی: با استفاده از این تکنیکهای جاسازی، میتوانیم این مدلها را برای آموزش الگوریتمهای یادگیری ماشین مرتبط و گروهبندی و طبقهبندی آنها انجام دهیم.
- سیستم های پیشنهادی: از آنجایی که تکنیکهای جاسازی به درستی سازماندهی شدهاند، منجر به سیستمهای توصیهای میشود که محصولات، رسانهها و مقالات را به طور دقیق بر اساس دادههای تاریخی مرتبط میکنند.
- تجزیه و تحلیل احساسات: این مدل تعبیه به ما کمک می کند تا راه حل های احساسی را دسته بندی و استخراج کنیم.
الزامات نمایه سازی
همانطور که می دانیم، ایندکس داده های جستجو را از جدول در پایگاه های داده سنتی، شبیه به پایگاه های داده برداری، بهبود می بخشد و ویژگی های نمایه سازی را فراهم می کند.
پایگاههای داده برداری «شاخصهای مسطح» را ارائه میکنند که نمایش مستقیم تعبیه برداری هستند. قابلیت جستجو جامع است و از خوشه های از پیش آموزش دیده استفاده نمی کند. بردار پرس و جو را در هر جاسازی بردار انجام می دهد و فاصله K برای هر جفت محاسبه می شود.
- به دلیل سهولت این شاخص، حداقل محاسبات برای ایجاد شاخص های جدید مورد نیاز است.
- در واقع، یک نمایه مسطح میتواند به طور مؤثری به پرس و جوها رسیدگی کند و زمان بازیابی سریع را فراهم کند.
درک معنایی و جستجوی تشابه
ما دو جستجوی مختلف را در پایگاههای داده برداری انجام میدهیم: جستجوهای معنایی و مشابه.
- جستجوی معنایی: هنگام جستجوی اطلاعات، به جای جستجو با کلمات کلیدی، می توانید آنها را بر اساس روش گفتگوی معنادار بیابید. مهندسی سریع نقش حیاتی در انتقال ورودی به سیستم دارد. این جستجو بدون شک امکان جستجو و نتایج با کیفیت بالاتری را می دهد که می تواند برای برنامه های کاربردی نوآورانه، سئو، تولید متن و خلاصه سازی تغذیه شود.
- جستجوی شباهت: همیشه در تجزیه و تحلیل داده ها، جستجوی شباهت به مجموعه داده های بدون ساختار و بسیار بهتر داده می شود. در مورد پایگاه داده برداری، باید نزدیکی دو بردار و شباهت آنها به یکدیگر را مشخص کنیم: جداول، متن، اسناد، تصاویر، کلمات و فایل های صوتی. در فرآیند درک، شباهت بین بردارها به عنوان شباهت بین اشیاء داده در مجموعه داده داده شده آشکار می شود. این تمرین به ما کمک می کند تا تعامل را درک کنیم، الگوها را شناسایی کنیم، بینش ها را استخراج کنیم و از دیدگاه های کاربردی تصمیم بگیریم. جستجوی معنایی و شباهت به ما کمک می کند تا برنامه های کاربردی زیر را برای مزایای صنعت بسازیم.
- بازیابی اطلاعات: با استفاده از AI باز و پایگاههای داده برداری، موتورهای جستجو را برای بازیابی اطلاعات با استفاده از پرسشهای کاربران تجاری یا کاربران نهایی و اسناد نمایهشده در داخل DB بردار میسازیم.
- طبقه بندی و خوشه بندی:طبقهبندی یا خوشهبندی نقاط داده یا گروههایی از اشیاء مشابه شامل تخصیص آنها به دستههای متعدد بر اساس ویژگیهای مشترک است.
- تشخیص ناهنجاری: کشف ناهنجاری ها از الگوهای معمول با اندازه گیری شباهت نقاط داده و تشخیص بی نظمی ها.
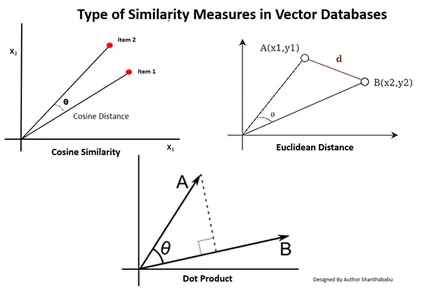
انواع معیارهای تشابه در پایگاه های داده برداری
روش های اندازه گیری به ماهیت داده ها و کاربرد خاص بستگی دارد. معمولاً از سه روش برای سنجش شباهت و آشنایی با یادگیری ماشین استفاده می شود.
فاصله ی اقلیدسی
به عبارت ساده، فاصله بین دو بردار، فاصله خط مستقیم بین دو نقطه برداری است که st را اندازه گیری می کنند.
محصول نقطه ای
این به ما کمک می کند تراز بین دو بردار را درک کنیم، و نشان می دهد که آیا آنها در یک جهت، جهت مخالف، یا عمود بر یکدیگر هستند.
شباهت کسینوس
همانطور که در شکل نشان داده شده است، شباهت دو بردار را با استفاده از زاویه بین آنها ارزیابی می کند. در این مورد، مقادیر و بزرگی بردارها ناچیز است و بر نتایج تأثیر نمی گذارد. در محاسبه فقط زاویه در نظر گرفته می شود.
پایگاه های داده سنتی به دنبال مطابقت دقیق دستور SQL و بازیابی داده ها در قالب جدولی باشید. در عین حال، ما با پایگاههای داده برداری سروکار داریم که با استفاده از تکنیکهای Prompt Engineering، مشابهترین بردار را به جستجوی ورودی به زبان انگلیسی ساده جستجو میکنند. پایگاه داده از الگوریتم جستجوی تقریبی نزدیکترین همسایه (ANN) برای یافتن داده های مشابه استفاده می کند. همیشه نتایج قابل قبولی دقیق در عملکرد، دقت و زمان پاسخگویی بالا ارائه دهید.
مکانیسم کار
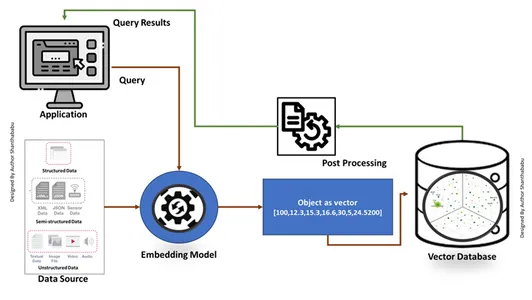
- پایگاه های داده برداری ابتدا داده ها را به بردارهای جاسازی شده تبدیل می کنند، آن ها را در پایگاه های داده برداری ذخیره می کنند و برای جستجوی سریعتر فهرست بندی ایجاد می کنند.
- یک پرس و جو از برنامه با بردار تعبیه شده تعامل می کند، نزدیکترین همسایه یا داده های مشابه را در پایگاه داده برداری با استفاده از یک فهرست جستجو می کند و نتایج ارسال شده به برنامه را بازیابی می کند.
- بر اساس الزامات کسب و کار، داده های بازیابی شده به دقت تنظیم، قالب بندی شده و به سمت کاربر نهایی یا پرس و جو یا فید (عملکردها) نمایش داده می شود.
ایجاد یک پایگاه داده برداری
بیایید با Pinecone ارتباط برقرار کنیم.
میتوانید با استفاده از Google، GitHub یا Microsoft ID به Pinecone متصل شوید.
برای استفاده خود یک لاگین کاربری جدید ایجاد کنید.
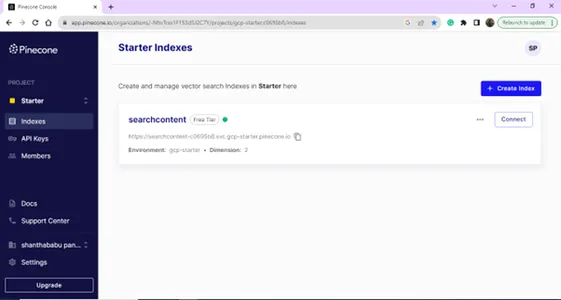
پس از ورود موفقیت آمیز، در صفحه Index قرار می گیرید. شما می توانید یک فهرست برای اهداف پایگاه داده برداری خود ایجاد کنید. بر روی دکمه Create Index کلیک کنید.
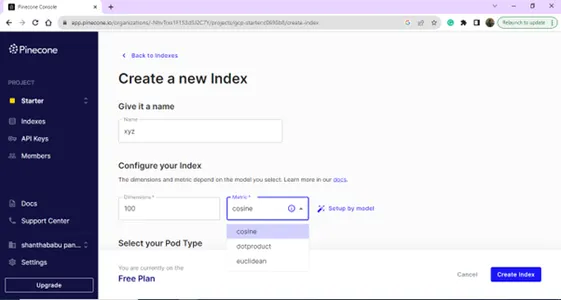
با ارائه نام و ابعاد، فهرست جدید خود را ایجاد کنید.
صفحه فهرست فهرست،
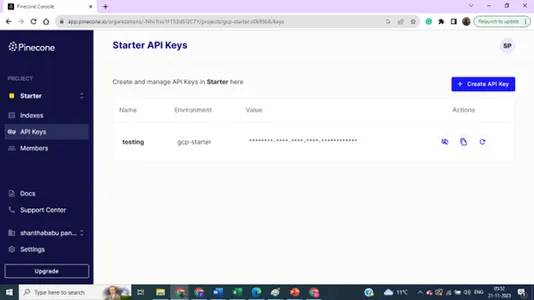
جزئیات فهرست - نام، منطقه و محیط - ما به همه این جزئیات نیاز داریم تا پایگاه داده برداری خود را از کد ساختمان مدل متصل کنیم.
جزئیات تنظیمات پروژه،
شما می توانید تنظیمات برگزیده خود را برای چندین شاخص و کلید برای اهداف پروژه ارتقا دهید.
تا اینجا در مورد ایجاد نمایه و تنظیمات پایگاه داده برداری در Pinecone بحث کردیم.
پیاده سازی پایگاه داده برداری با استفاده از پایتون
حالا بیایید کمی کدنویسی کنیم.
واردات کتابخانه ها
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIارائه کلید API برای OpenAI و پایگاه داده Vector
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)راه اندازی LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)شروع کاج
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" در حال بارگیری فایل csv. برای ساخت پایگاه داده برداری
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()متن را به قطعات تقسیم کنید
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)یافتن متن در text_chunk
text_chunksتولید
[ سند 100nتوصیه: کودکان، فراداده={ 'منبع': '70% سبوس'، 'ردیف': 4})، , …..
تعبیه ساختمان
embeddings = OpenAIEmbeddings()ایجاد یک نمونه Pinecone برای پایگاه داده برداری از «داده»
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")یک بازیابی برای پرس و جو در پایگاه داده برداری ایجاد کنید.
retriever = vectordb.as_retriever(score_threshold = 0.7)بازیابی داده ها از پایگاه داده برداری
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsبا استفاده از Prompt و بازیابی داده ها
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
بیایید داده ها را پرس و جو کنیم.
chain('Can you please provide cereal recommendation for Kids?')خروجی از Query
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]نتیجه
امیدواریم که بتوانید نحوه عملکرد پایگاههای داده برداری، اجزای آن، معماری و ویژگیهای پایگاههای داده برداری در راهکارهای هوش مصنوعی تولیدی را درک کنید. درک تفاوت پایگاه داده برداری با پایگاه داده سنتی و مقایسه با عناصر پایگاه داده معمولی. در واقع، قیاس به شما کمک می کند تا پایگاه داده برداری را بهتر درک کنید. پایگاه داده برداری Pinecone و مراحل نمایه سازی به شما کمک می کند یک پایگاه داده برداری ایجاد کنید و کلید اجرای کد زیر را بیاورید.
گیرنده های کلیدی
- قابل فشرده سازی با داده های ساختاریافته، بدون ساختار و نیمه ساختار یافته.
- این تکنیک های جاسازی و ویژگی های بسیار نمایه شده را تطبیق می دهد.
- فعل و انفعالات از طریق متن ساده با استفاده از یک اعلان (به عنوان مثال، انگلیسی) اتفاق می افتد. و داده های ذخیره شده در نمایش های ریاضی.
- شباهت در پایگاه های داده برداری از طریق - فاصله اقلیدسی، تشابه کسینوس و محصول نقطه کالیبره می شود.
پرسش و پاسخهای متداول
الف. پایگاه داده برداری مجموعه ای از داده ها را در فضا ذخیره می کند. داده ها را در نمایش های ریاضی نگهداری می کند. از آنجایی که فرمت ذخیره شده در پایگاههای اطلاعاتی مدلهای هوش مصنوعی باز را آسانتر میکند تا ورودیهای قبلی را به خاطر بسپارند و به برنامه هوش مصنوعی باز ما اجازه میدهد از جستجوی شناختی، توصیهها و تولید متن دقیق برای موارد استفاده مختلف در صنایع تبدیلشده دیجیتالی استفاده کند.
الف. برخی از ویژگیها عبارتند از: 1. از قدرت این جاسازیهای برداری بهره میبرد که منجر به نمایهسازی و جستجو در یک مجموعه داده عظیم میشود. 2. قابل فشرده سازی با داده های ساختاریافته، بدون ساختار و نیمه ساختار یافته. 3. یک پایگاه داده برداری داده ها را از طریق بردارهای با ابعاد بالا که حاوی صدها بعد هستند سازماندهی می کند.
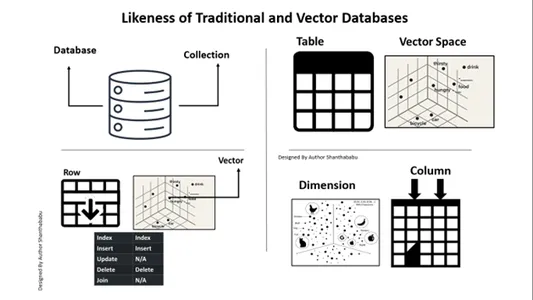
A. پایگاه داده ==> مجموعه ها
جدول==> فضای برداری
ردیف==>سکتور
ستون==>بعد
درج و حذف در پایگاه داده های Vector مانند یک پایگاه داده سنتی امکان پذیر است.
به روز رسانی و عضویت در محدوده نیست.
- بازیابی اطلاعات برای جمع آوری سریع داده ها.
- عملیات جستجوی معنایی و شباهت از اسناد با اندازه بزرگ.
- کاربرد طبقه بندی و خوشه بندی.
– سیستمهای تحلیل احساسات و توصیهها.
A5: در زیر سه روش برای اندازه گیری شباهت آمده است:
- فاصله اقلیدسی
- تشابه کسینوس
– محصول نقطه ای
رسانه نشان داده شده در این مقاله متعلق به Analytics Vidhya نیست و به صلاحدید نویسنده استفاده می شود.
مربوط
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- : دارد
- :است
- :نه
- $UP
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- قادر
- درباره ما
- دسترسی
- دقت
- دقیق
- به درستی
- در میان
- تطبیق می دهد
- اضافه کردن
- اثر
- AI
- مدل های هوش مصنوعی
- الگوریتم
- الگوریتم
- هم ترازی
- معرفی
- اتحاد
- اجازه دادن
- اجازه می دهد تا
- در امتداد
- همیشه
- در میان
- an
- تحلیل
- علم تجزیه و تحلیل
- تجزیه و تحلیل Vidhya
- و
- پاسخ
- هر
- API
- ظاهر
- کاربرد
- برنامه خاص
- برنامه های کاربردی
- تقریبی
- معماری
- هستند
- مرتب شده اند
- صف
- مقاله
- مقالات
- مصنوعی
- هوش مصنوعی
- هوش مصنوعی و یادگیری ماشین
- AS
- جنبه
- ارزیابی می کند
- انجمن
- At
- سمعی
- بطور خودکار
- در دسترس
- مستقر
- BE
- شدن
- شود
- رفتار
- پشت سر
- بودن
- در زیر
- مزایای
- بهتر
- میان
- بلاگاتون
- به ارمغان بیاورد
- ساختن
- بنا
- کسب و کار
- دکمه
- by
- محاسبه
- محاسبه
- نام
- CAN
- قابلیت های
- قابلیت
- گرفتن
- مورد
- موارد
- دسته
- زنجیر
- زنجیر
- مشخصات
- وضوح
- طبقه بندی
- طبقه بندی کنید
- کلیک
- خوشه بندی
- رمز
- برنامه نویسی
- شناختی
- مجموعه
- عموما
- جمع و جور
- مقايسه كردن
- مقایسه
- کامل
- پیچیده
- اجزاء
- جامع
- محاسبه
- محاسباتی
- اتصال
- اتصال
- در نظر بگیرید
- در نظر گرفته
- شامل
- محتوا
- زمینه
- معمولی
- گفتگو
- تبدیل
- مطابقت دارد
- میتوانست
- ایجاد
- ایجاد
- خلاقیت
- مشتری
- داده ها
- تحلیل داده ها
- نقاط داده
- پردازش داده ها
- پایگاه داده
- پایگاه های داده
- مجموعه داده ها
- مقدار
- تصمیم گیری
- تصمیم گیری
- خواسته
- استخراج
- طراحی
- مطلوب
- جزئیات
- کشف
- توسعه
- متفاوت است
- تفاوت
- مختلف
- دیجیتالی
- بعد
- ابعاد
- مستقیم
- جهت
- جهت ها
- کشف
- اختیار
- بحث و تبادل نظر
- بحث کردیم
- نمایش داده
- فاصله
- do
- اسناد و مدارک
- میکند
- دان
- DOT
- پویا
- بطور پویا
- e
- هر
- سهولت
- آسان تر
- به طور موثر
- بهره وری
- موثر
- هر دو
- عناصر
- تعبیه کردن
- قادر ساختن
- پایان
- مهندسی
- مورد تأیید
- موتورهای حرفه ای
- انگلیسی
- تضمین می کند
- محیط
- ماهیت
- ضروری است
- اتر (ETH)
- حتی
- در حال تحول
- اجرا کردن
- ورزش
- بررسی
- عصاره
- تسهیل کردن
- آشنایی
- بسیار
- ویژگی
- امکانات
- تغذیه
- شکل
- پرونده
- فایل ها
- پیدا کردن
- نام خانوادگی
- صاف
- پیروی
- برای
- خط مقدم
- فرم
- قالب
- رایگان
- از جانب
- آینده
- شکاف
- تولید می کنند
- نسل
- مولد
- هوش مصنوعی مولد
- ژانر
- GitHub
- دادن
- داده
- گوگل
- گروه
- گروه ها
- دسته
- رخ دادن
- آیا
- کمک
- کمک می کند
- اینجا کلیک نمایید
- زیاد
- در سطح بالا
- خیلی
- تاریخی
- چگونه
- اما
- HTTPS
- بزرگ
- صدها نفر
- i
- ID
- شناسایی
- if
- تصاویر
- تأثیر
- پیاده سازی
- واردات
- بهبود
- in
- به طور فزاینده
- شاخص
- نمایه شده
- فهرستها
- نشان دادن
- Indices
- لوازم
- صنعت
- موثر
- اطلاعات
- ذاتی
- ابتکاری
- ورودی
- ورودی
- درج می کند
- داخل
- بینش
- نمونه
- در عوض
- اطلاعات
- تعامل
- اثر متقابل
- فعل و انفعالات
- به
- پیچیدگی ها
- شامل
- IT
- ITS
- شغل ها
- پیوستن
- به ما بپیوند
- سفر
- تنها
- کلید
- کلید
- کلید واژه ها
- بچه ها
- دانستن
- برچسب
- زمین
- چشم انداز
- بزرگ
- برجسته
- منجر می شود
- یادگیری
- قدرت نفوذ
- اهرم ها
- پسندیدن
- فهرست
- بارکننده
- منطق
- ورود
- دستگاه
- فراگیری ماشین
- عمده
- ساخت
- باعث می شود
- ساخت
- مدیریت
- روش
- دستی
- سازنده
- نقشه
- عظیم
- کبریت
- ریاضی
- معنی دار
- اندازه
- معیارهای
- اندازه گیری
- مکانیزم
- رسانه ها
- ادغام کردن
- روش شناسی
- روش
- مایکروسافت
- حداقل
- مدل
- مدل
- بیش
- علاوه بر این
- اکثر
- بسیار
- چندگانه
- باید
- نام
- طبیعت
- نیاز
- جدید
- اکنون
- متعدد
- هدف
- اشیاء
- of
- ارائه
- on
- ONE
- آنهایی که
- آنلاین
- فقط
- باز کن
- OpenAI
- عملیات
- مقابل
- or
- سازمان
- سازمان یافته
- سازماندهی می کند
- اصلی
- OS
- دیگر
- ما
- متعلق به
- با ما
- جفت
- بخش
- گذشت
- عبور
- الگوهای
- کامل
- انجام دادن
- کارایی
- انجام
- انجام می دهد
- چشم انداز
- دیدگاه
- تصویر
- محوری
- ساده
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقش
- لطفا
- نقطه
- نقطه
- ممکن
- پتانسیل
- قدرت
- قوی
- عملی
- برنامه های کاربردی عملی
- دقیق
- دقیقا
- تنظیمات
- قبلی
- مشکل
- روند
- محصول
- محصولات
- پروژه
- برجسته
- پرسیدن
- به درستی
- املاک
- ویژگی
- ارائه
- ارائه
- تدارک
- منتشر شده
- خمیر هزارلا
- هدف
- اهداف
- مقدار
- نمایش ها
- سوال
- سریع
- سریعتر
- به سرعت
- سریعا
- توصیه
- توصیه
- با توجه
- منطقه
- روابط
- روابط
- مربوط
- نمایندگی
- نمایندگی
- نشان دهنده
- ضروری
- مورد نیاز
- پاسخ
- پاسخ
- نتیجه
- نتایج
- نشان داد
- نقش
- ROW
- s
- همان
- علم
- حوزه
- جستجو
- موتورهای جستجو
- جستجو
- جستجو
- احساس
- جستجوگرها
- تنظیمات
- شکل
- شکل دادن
- به اشتراک گذاشته شده
- تاقچه
- کوتاه
- نشان داده شده
- نشان می دهد
- طرف
- مشابه
- شباهت ها
- ساده
- پس از
- تنها
- اندازه
- So
- راه حل
- مزایا
- برخی از
- منبع
- فضا
- خاص
- سرعت
- انشعاب
- لکه بینی
- SQL
- دولت
- بیانیه
- اظهارات
- مراحل
- هنوز
- ذخیره سازی
- opbevare
- ذخیره شده
- پرده
- ساختار
- ساخت یافته
- مهاجرت تحصیلی
- متعاقبا
- موفق
- همکاری
- سیستم
- سیستم های
- T
- جدول
- TAG
- وظایف
- تکنیک
- فنی
- قوانین و مقررات
- متن
- تولید متن
- نسبت به
- که
- La
- آینده
- شان
- آنها
- اینها
- آنها
- این
- سه
- از طریق
- زمان
- بار
- به
- سنتی
- قطار
- دگرگون کردن
- دگرگونی
- دگرگونی
- مبدل
- امتحان
- دو
- انواع
- در نهایت
- فهمیدن
- درک
- بی شک
- باز
- باز کردن قفل
- بروزرسانی
- ارتقاء
- us
- استفاده
- استفاده کنید
- استفاده
- کاربر
- استفاده
- با استفاده از
- معمول
- ارزشها
- تنوع
- مختلف
- بسیار
- حیاتی
- vs
- بود
- we
- وب سایت
- به خوبی تعریف شده است
- بود
- چی
- چه شده است
- چه
- که
- در حین
- اراده
- با
- در داخل
- کلمات
- مهاجرت کاری
- کارگر
- خواهد بود
- شما
- شما
- زفیرنت