پروژه های یادگیری ماشینی هر چند وقت یکبار به استقرار موفقیت آمیز می رسند؟ اغلب به اندازه کافی نیست. وجود دارد فراوان of صنعت تحقیق نمایش پروژههای ML معمولاً در ارائه بازدهی شکست میخورند، اما تعداد کمی از آنها نسبت شکست به موفقیت را از دیدگاه دانشمندان داده اندازهگیری کردهاند - افرادی که دقیقاً مدلهایی را توسعه میدهند که این پروژهها قرار است به کار گیرند.
در ادامه نظرسنجی دانشمند داده که سال گذشته با KDnuggets انجام دادم، نظرسنجی علم داده پیشرو در صنعت امسال رکسر آنالیتیکس که توسط مشاور ML اداره می شود به این سوال پاسخ داد - تا حدی به این دلیل که کارل رکسر، موسس و رئیس شرکت، به شما اجازه داد تا واقعاً شرکت کنند، و باعث شد سوالاتی در مورد موفقیت در استقرار گنجانده شود (بخشی از کار من در طول یک سال استادی تجزیه و تحلیل که داشتم). در UVA Darden).
خبر عالی نیست تنها 22 درصد از دانشمندان داده میگویند که ابتکارات «انقلابی» آنها - مدلهایی که برای ایجاد یک فرآیند یا قابلیت جدید ایجاد شدهاند - معمولاً به کار گرفته میشوند. 43٪ می گویند که 80٪ یا بیشتر در استقرار شکست می خورند.
در سراسر تمام انواع پروژههای ML - از جمله مدلهای تازهسازی برای استقرارهای موجود - فقط 32٪ میگویند که مدلهای آنها معمولاً مستقر میشوند.
در اینجا نتایج دقیق آن بخش از نظرسنجی ارائه شده توسط Rexer Analytics ارائه شده است که نرخ استقرار را در سه نوع ابتکار ML نشان می دهد:
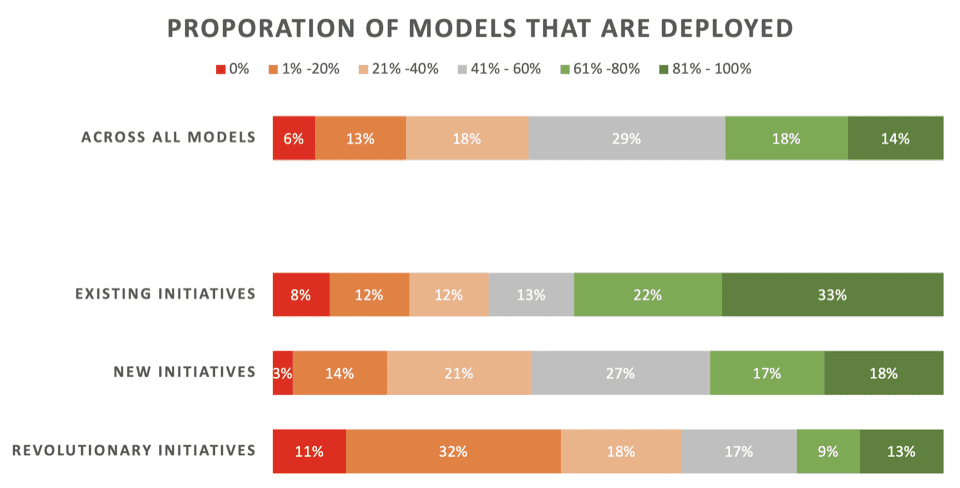
های کلیدی:
- ابتکارات موجود: مدلهایی که برای بهروزرسانی/بهروزرسانی یک مدل موجود که قبلاً با موفقیت اجرا شده است توسعه یافتهاند
- ابتکارات جدید: مدلهایی توسعه یافتهاند تا فرآیند موجود را بهبود ببخشند که هیچ مدلی از قبل برای آن استفاده نشده است
- ابتکارات انقلابی: مدل های توسعه یافته برای فعال کردن یک فرآیند یا قابلیت جدید
به نظر من، این کشمکش برای استقرار از دو عامل اصلی ناشی میشود: برنامهریزی ناقص بومی و ذینفعان کسبوکار که دید مشخصی ندارند. بسیاری از متخصصان داده و رهبران کسب و کار متوجه نشده اند که عملیاتی سازی مورد نظر ML باید با جزئیات زیاد برنامه ریزی شود و از ابتدای هر پروژه ML به شدت دنبال شود.
در واقع، من یک کتاب جدید در مورد آن نوشته ام: کتاب راهنمای هوش مصنوعی: تسلط بر هنر نادر استقرار یادگیری ماشین. در این کتاب، من یک تمرین شش مرحلهای متمرکز بر استقرار را برای راهاندازی پروژههای یادگیری ماشین از مفهوم تا استقرار معرفی میکنم که من آن را مینامم. bizML ( جلد گالینگور یا کتاب الکترونیکی را پیش خرید کنید و نسخه پیشرفته رایگان نسخه کتاب صوتی را دریافت کنید بلافاصله).
ذینفعان کلیدی پروژه ML - فردی که مسئول اثربخشی عملیاتی است که برای بهبود هدف گذاری شده است، مانند یک مدیر خط کسب و کار - نیاز به مشاهده دقیق نحوه بهبود عملکرد ML دارد و انتظار می رود بهبود چقدر ارزش ارائه دهد. آنها به این نیاز دارند تا نهایتاً استقرار یک مدل را روشن کنند و همچنین قبل از آن، اجرای پروژه را در طول مراحل پیش از استقرار تحت فشار قرار دهند.
اما عملکرد ML اغلب اندازه گیری نمی شود! هنگامی که نظرسنجی رکسر پرسید: "شرکت/سازمان شما چند وقت یکبار عملکرد پروژه های تحلیلی را اندازه گیری می کند؟" تنها 48 درصد از دانشمندان داده گفتند "همیشه" یا "بیشتر اوقات". این خیلی وحشی است باید بیشتر از 99٪ یا 100٪ باشد.
و هنگامی که عملکرد اندازه گیری می شود، از نظر معیارهای فنی است که محرمانه هستند و عمدتاً برای ذینفعان تجاری بی ربط هستند. دانشمندان داده بهتر می دانند، اما عموماً رعایت نمی کنند - تا حدی زیرا ابزارهای ML معمولاً فقط معیارهای فنی را ارائه می دهند. بر اساس این نظرسنجی، دانشمندان داده شاخص های کلیدی عملکرد تجاری مانند ROI و درآمد را به عنوان مهم ترین معیارها رتبه بندی می کنند، اما معیارهای فنی مانند لیفت و AUC را به عنوان رایج ترین معیارها فهرست می کنند.
بر اساس این گزارش، معیارهای عملکرد فنی «اساساً برای ذینفعان کسبوکار بیفایده هستند و با آنها ارتباط ندارند». بررسی علوم داده هاروارد. دلیل آن این است: آنها فقط به شما می گویند نسبی عملکرد یک مدل، مانند مقایسه آن با حدس زدن یا خط پایه دیگر. معیارهای کسب و کار به شما می گوید مطلق ارزش تجاری که انتظار می رود مدل ارائه دهد - یا در هنگام ارزیابی پس از استقرار، اثبات شده است که ارائه می دهد. چنین معیارهایی برای پروژه های ML متمرکز بر استقرار ضروری هستند.
فراتر از دسترسی به معیارهای کسب و کار، ذینفعان کسب و کار نیز باید افزایش پیدا کنند. وقتی در نظرسنجی رکسر پرسیده شد: «آیا مدیران و تصمیم گیرندگان در سازمان شما که باید استقرار مدل را تأیید کنند، عموماً به اندازه کافی دانش کافی برای اتخاذ چنین تصمیماتی دارند؟» تنها 49 درصد از پاسخ دهندگان به «بیشتر اوقات» یا «همیشه» پاسخ دادند.
این چیزی است که من معتقدم در حال رخ دادن است. «مشتری» دانشمند داده، ذینفع کسبوکار، اغلب زمانی که نوبت به استقرار مجوز میرسد، دچار سردرگمی میشود، زیرا این به معنای ایجاد یک تغییر عملیاتی قابلتوجه در نان و کره شرکت، فرآیندهای بزرگترین مقیاس آن است. آنها چارچوب زمینه ای را ندارند. به عنوان مثال، آنها تعجب می کنند، "چگونه می توانم بفهمم که این مدل، که عملکرد بسیار کمی از گلوله کریستالی دارد، چقدر کمک می کند؟" بنابراین پروژه می میرد. سپس، قرار دادن خلاقانه نوعی چرخش مثبت بر روی «بینشهای بهدستآمده»، باعث میشود که شکست بهطور منظمی زیر قالیچه جارو شود. تبلیغات هوش مصنوعی حتی زمانی که ارزش بالقوه، هدف پروژه، از بین رفته است، دست نخورده باقی می ماند.
در مورد این موضوع - افزایش ذینفعان - کتاب جدیدم را وصل خواهم کرد، کتاب بازی هوش مصنوعی، فقط یک بار دیگر. این کتاب در حالی که تمرین bizML را پوشش میدهد، با ارائه مقداری حیاتی و در عین حال دوستانه از دانش پیشزمینه نیمهفنی که همه ذینفعان برای رهبری یا مشارکت در پروژههای یادگیری ماشین، از انتها به پایان، به آن نیاز دارند، مهارتهای حرفهای کسبوکار را نیز ارتقا میدهد. این کار حرفه ای های کسب و کار و داده را در یک صفحه قرار می دهد تا بتوانند عمیقاً همکاری کنند و بطور مشترک به طور دقیق ایجاد کنند. یادگیری ماشینی برای پیشبینی چه چیزی فراخوانده میشود، چقدر خوب پیشبینی میکند و چگونه پیشبینیهای آن برای بهبود عملیات انجام میشود.. این موارد ضروری هر ابتکار را میسازند یا شکست میدهند – درست کردن آنها راه را برای استقرار مبتنی بر ارزش یادگیری ماشین هموار میکند.
به جرات می توان گفت که در آنجا دشوار است، به خصوص برای ابتکارات جدید و اولین آزمایش ML. همانطور که نیروی محض هوش مصنوعی توانایی خود را برای جبران مداوم از دست می دهد
ارزش تحقق یافته کمتر از آنچه وعده داده شده بود، فشار بیشتر و بیشتری برای اثبات ارزش عملیاتی ML وجود خواهد داشت. بنابراین من میگویم، اکنون از این کار خارج شوید - فرهنگ مؤثرتری از همکاری بین سازمانی و رهبری پروژه مبتنی بر استقرار را القا کنید!
برای نتایج دقیق تر از 2023 Rexer Analytics Science Data Surveyکلیک کنید اینجا کلیک نمایید. این بزرگترین نظرسنجی از متخصصان علم داده و تجزیه و تحلیل در این صنعت است. این شامل تقریباً 35 سؤال چند گزینه ای و باز است که بسیار بیشتر از نرخ موفقیت استقرار را پوشش می دهد - هفت حوزه کلی علم و عمل داده کاوی: (1) زمینه و اهداف، (2) الگوریتم ها، (3) مدل ها، ( 4) ابزارها (بسته های نرم افزاری مورد استفاده)، (5) فناوری، (6) چالش ها، و (7) آینده. این به عنوان یک سرویس (بدون حمایت شرکتی) به جامعه علم داده انجام می شود و نتایج معمولاً در کنفرانس هفته یادگیری ماشین و از طریق گزارش های خلاصه آزادانه در دسترس به اشتراک گذاشته می شود.
این مقاله محصول کار نویسنده است در حالی که او یک سال به عنوان استاد دویستمین سالگرد بدنی در تجزیه و تحلیل در مدرسه کسب و کار UVA Darden داشت که در نهایت با انتشار کتاب به اوج خود رسید. کتاب راهنمای هوش مصنوعی: تسلط بر هنر نادر استقرار یادگیری ماشین (پیشنهاد رایگان کتاب صوتی).
اریک سیگلدکتر، مشاور برجسته و استاد سابق دانشگاه کلمبیا است که یادگیری ماشینی را قابل درک و فریبنده می کند. او بنیانگذار است دنیای تحلیل پیش بینی کننده و دنیای یادگیری عمیق مجموعه کنفرانس، که از سال 17,000 به بیش از 2009 شرکت کننده خدمات ارائه کرده است، مدرس دوره تحسین شده رهبری و تمرین یادگیری ماشین - تسلط پایان به انتها، یک سخنران محبوب که برای آن سفارش داده شده است بیش از 100 آدرس سخنرانی اصلی، و سردبیر اجرایی زمان یادگیری ماشین. او کتاب پرفروش را نوشته است تجزیه و تحلیل پیش بینی کننده: قدرت پیش بینی اینکه چه کسی کلیک، خرید، دروغ گفتن یا مرگ خواهد کرد، که در دوره های بیش از 35 دانشگاه مورد استفاده قرار گرفته است و او زمانی که استاد دانشگاه کلمبیا بود و در آنجا آواز می خواند جوایز تدریس را به دست آورد. آهنگ های آموزشی به شاگردانش اریک نیز منتشر می کند مقالاتی در مورد تحلیل و عدالت اجتماعی. او را دنبال کنید @predictanalytic.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 000
- 1
- 17
- ٪۱۰۰
- 7
- a
- توانایی
- درباره ما
- دسترسی
- تحسین شده
- مطابق
- در میان
- واقعا
- خطاب
- پیشرفته
- پس از
- تهاجمی
- پیش
- AI
- الگوریتم
- معرفی
- مجاز
- قبلا
- همچنین
- همیشه
- am
- an
- تحلیلی
- علم تجزیه و تحلیل
- و
- اعلام کرد
- دیگر
- تصویب
- تقریبا
- محرمانه
- هستند
- مناطق
- هنر
- مقاله
- AS
- At
- شرکت کنندگان
- حراج
- نویسنده
- در دسترس
- جوایز
- دور
- زمینه
- خط مقدم
- BE
- زیرا
- بوده
- قبل از
- باور
- پرفروش ترین
- بهتر
- کتاب
- نان
- شکستن
- شکستن
- کسب و کار
- رهبران مشاغل
- اما
- خرید
- by
- صدا
- نام
- CAN
- قابلیت
- فریبنده
- چالش ها
- تغییر دادن
- بار
- انتخاب
- کلیک
- مشتری
- سرد
- همکاری
- همکاری
- کلمبیا
- COM
- بیا
- می آید
- عموما
- انجمن
- شرکت
- شرکت
- طرح
- بتون
- انجام
- کنفرانس
- تشکیل شده است
- مشاوره
- مشاور
- متنی
- به طور مستمر
- کمک
- شرکت
- دوره
- دوره
- پوشش
- پوشش
- خلاقانه
- cs
- فرهنگ
- داده ها
- داده کاوی
- علم اطلاعات
- دانشمند داده
- تصمیم گیرندگان
- تصمیم گیری
- عمیقا
- ارائه
- تحویل
- گسترش
- مستقر
- گسترش
- اعزام ها
- جزئیات
- دقیق
- توسعه
- توسعه
- منفصل
- do
- میکند
- دان
- آیا
- مقدار
- پایین
- رانندگی
- در طی
- هر
- سردبیر
- موثر
- اثر
- قادر ساختن
- پایان
- پشت سر هم
- اندمیک
- بالا بردن
- کافی
- اریک
- به خصوص
- ضروری است
- ملزومات
- ایجاد
- اتر (ETH)
- ارزیابی
- حتی
- هر
- مثال
- اعدام
- اجرایی
- موجود
- انتظار می رود
- واقعیت
- عوامل
- FAIL
- شکست
- بسیار
- پا
- کمی از
- رشته
- به دنبال
- برای
- استحکام
- سابق
- موسس
- چارچوب
- رایگان
- آزادانه
- دوستانه
- از جانب
- آینده
- به دست آورد
- سوالات عمومی
- عموما
- دریافت کنید
- گرفتن
- اهداف
- گوگل
- بزرگ
- اتفاق می افتد
- آیا
- he
- برگزار شد
- کمک
- او را
- خود را
- چگونه
- HTML
- HTTP
- HTTPS
- هیپ
- i
- آی بی ام
- مهم
- بهبود
- بهبود
- in
- آغازگر
- از جمله
- گنجاندن
- صنعت
- پیشرو در صنعت
- ابتکار عمل
- ابتکارات
- بینش
- مورد نظر
- به
- معرفی
- نیست
- IT
- ITS
- تنها
- فقط یکی
- کارل
- kdnuggets
- کلید
- مفتاح
- نوع
- دانستن
- دانش
- فاقد
- بزرگترین
- نام
- پارسال
- رهبری
- رهبران
- رهبری
- برجسته
- یادگیری
- دروغ
- پسندیدن
- لینک
- فهرست
- ll
- از دست می دهد
- از دست رفته
- دستگاه
- فراگیری ماشین
- اصلی
- ساخت
- باعث می شود
- ساخت
- مدیر
- مدیران
- روش
- بسیاری
- تسلط
- متوسط
- به معنای
- اندازه
- اندازه گیری
- متریک
- استخراج معدن
- MIT
- ML
- مدل
- مدل
- بیش
- اکثر
- اغلب
- بسیار
- چندگانه
- باید
- my
- نیاز
- نیازهای
- جدید
- اخبار
- نه
- اکنون
- of
- غالبا
- on
- ONE
- آنهایی که
- فقط
- قابل استفاده
- عملیات
- or
- سفارش
- کدام سازمان ها
- خارج
- بسته
- با ما
- بخش
- شرکت کردن
- سنگفرش
- کمال
- کارایی
- انجام می دهد
- شخص
- چشم انداز
- برنامه ریزی
- افلاطون
- هوش داده افلاطون
- PlatoData
- برق وصل کردن
- محبوب
- موقعیت
- مثبت
- پتانسیل
- قدرت
- تمرین
- قبل از سفارش
- گرانبها
- دقیقا
- پیش بینی
- پیش بینی
- پیش بینی می کند
- ارائه شده
- رئيس جمهور
- فشار
- زیبا
- روند
- فرآیندهای
- محصول
- حرفه ای
- معلم
- پروژه
- پروژه ها
- وعده داده شده
- ثابت كردن
- اثبات شده
- انتشار
- منتشر می کند
- هدف
- قرار می دهد
- قرار دادن
- سوال
- سوالات
- رمپ
- رمپینگ
- رتبه بندی
- نادر
- نرخ
- نسبت
- رسیدن به
- متوجه
- شناختن
- بقایای
- گزارش ها
- پاسخ دهندگان
- نتایج
- بازده
- درامد
- انقلابی
- راست
- سنگلاخ
- ROI
- به طور معمول
- دویدن
- s
- امن
- سعید
- همان
- گفتن
- مقیاس
- مدرسه
- علم
- دانشمند
- دانشمندان
- سلسله
- خدمت
- خدمت کرده است
- خدمت
- سرویس
- هفت
- به اشتراک گذاشته شده
- قابل توجه
- پس از
- So
- آگاهی
- نرم افزار
- برخی از
- گوینده
- چرخش
- حمایت
- مراحل
- ذینفع
- سهامداران
- شروع
- ساقه ها
- هنوز
- مبارزه
- دانشجویان
- موفقیت
- موفق
- موفقیت
- چنین
- خلاصه
- بررسی
- رفت و برگشت
- T
- هدف قرار
- تعلیم
- فنی
- پیشرفته
- گفتن
- قوانین و مقررات
- نسبت به
- که
- La
- شان
- آنها
- سپس
- آنجا.
- اینها
- آنها
- این
- سه
- سراسر
- بدین ترتیب
- زمان
- به
- ابزار
- موضوع
- صادقانه
- دو
- در نهایت
- زیر
- فهمیدن
- قابل فهم
- دانشگاه ها
- دانشگاه
- بر
- استفاده
- طلیعه زدن
- معمولا
- ارزش
- Ve
- بسیار
- از طريق
- چشم انداز
- دید
- حیاتی
- بود
- مسیر..
- هفته
- وزن کن
- خوب
- چی
- چه زمانی
- که
- در حین
- WHO
- چرا
- وحشی
- اراده
- با
- بدون
- برنده شد
- تعجب
- مهاجرت کاری
- خواهد بود
- کتبی
- سال
- هنوز
- شما
- شما
- زفیرنت








