معرفی BERT بسته بندی شده برای افزایش سرعت آموزش 2 برابری در پردازش زبان طبیعی
برای آموزش کارآمدتر، این الگوریتم بسته بندی BERT جدید را بررسی کنید.
By دکتر ماریو مایکل کرل، رهبر اصلی یادگیری ماشین در Graphcore & Matej Kosec، متخصص برنامه های کاربردی هوش مصنوعی در Graphcore

تصویر توسط نویسنده
با استفاده از یک الگوریتم بسته بندی جدید، در حین آموزش BERT-Large، پردازش زبان طبیعی را بیش از 2 برابر افزایش داده ایم. تکنیک بسته بندی جدید ما بالشتک را حذف می کند و محاسبات بسیار کارآمدتری را ممکن می سازد.
ما گمان میکنیم که این میتواند برای مدلهای تاشوی ژنومیک و پروتئین و سایر مدلهای با توزیع طول اریب نیز اعمال شود تا تأثیر بسیار گستردهتری در صنایع و کاربردهای مختلف داشته باشد.
ما الگوریتم بستهبندی هیستوگرام حداقل مربعات غیر منفی بسیار کارآمد Graphcore (یا NNLSHP) و همچنین الگوریتم BERT خود را که برای توالیهای بستهبندی شده اعمال میشود در مقاله جدیدی معرفی کردیم [1].
ضایعات محاسباتی در NLP به دلیل padding توالی
ما شروع به بررسی راه های جدید برای بهینه سازی آموزش BERT در حین کار بر روی اخیر خود کردیم معیارهای ارسالی به MLPerf™. هدف توسعه بهینه سازی های مفیدی بود که به راحتی در برنامه های کاربردی دنیای واقعی به کار گرفته شوند. BERT یک انتخاب طبیعی به عنوان یکی از مدل هایی بود که باید روی این بهینه سازی ها تمرکز کرد، زیرا به طور گسترده در صنعت و توسط بسیاری از مشتریان ما استفاده می شود.
واقعاً ما را شگفتزده کرد که متوجه شدیم در برنامه آموزشی BERT-Large خودمان با استفاده از مجموعه داده ویکیپدیا، 50 درصد از نشانههای مجموعه دادهها به صورت padding هستند - که منجر به هدر رفتن محاسبات میشود.
قرار دادن توالیها برای تراز کردن همه آنها به طول مساوی، رویکرد رایجی است که در پردازندههای گرافیکی استفاده میشود، اما ما فکر میکنیم که ارزش امتحان کردن یک رویکرد متفاوت را دارد.
دنباله ها به دو دلیل دارای تنوع زیادی در طول هستند:
- داده های اساسی ویکی پدیا تنوع زیادی را در طول سند نشان می دهد
- خود پیش پردازش BERT به طور تصادفی اندازه اسناد استخراج شده را کاهش می دهد که برای ایجاد یک دنباله آموزشی ترکیب می شوند.
پر کردن طول به حداکثر طول 512 منجر به این می شود که 50٪ از تمام توکن ها توکن های padding باشند. جایگزینی 50٪ از padding با داده های واقعی می تواند منجر به پردازش 50٪ داده بیشتر با تلاش محاسباتی یکسان و در نتیجه افزایش 2 برابری در شرایط بهینه شود.

شکل 1: توزیع داده های ویکی پدیا. تصویر توسط نویسنده
آیا این مختص ویکی پدیا است؟ خیر
خوب پس مختص زبان است؟ خیر
در واقع، توزیع طول اریب در همه جا یافت می شود: در زبان، ژنومیک و تاشو پروتئین. شکلهای 2 و 3 توزیعهای مجموعه داده SQuAD 1.1 و مجموعه دادههای GLUE را نشان میدهند.

شکل 2: SQuAD 1.1 BERT پیش آموزشی هیستوگرام طول توالی مجموعه داده برای حداکثر طول توالی 384. تصویر توسط نویسنده.

شکل 3: هیستوگرام طول توالی مجموعه داده GLUE برای حداکثر طول دنباله 128. تصویر توسط نویسنده.
چگونه میتوانیم طولهای مختلف را مدیریت کنیم و از اتلاف محاسباتی جلوگیری کنیم؟
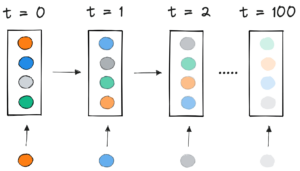
روشهای فعلی به هستههای محاسباتی متفاوتی برای طولهای مختلف نیاز دارند یا اینکه مهندس بهطور برنامهنویسی لایهها را حذف کند و سپس آن را به طور مکرر برای هر بلوک توجه و محاسبه تلفات اضافه کند. صرفه جویی در محاسبه با منفجر کردن کد و پیچیده تر کردن آن جذاب نبود، بنابراین ما به دنبال چیز بهتری بودیم. آیا نمیتوانیم چندین توالی را در یک بسته با حداکثر طول کنار هم قرار دهیم و همه آنها را با هم پردازش کنیم؟ معلوم است، ما می توانیم!
این رویکرد به سه عنصر کلیدی نیاز دارد:
- یک الگوریتم کارآمد برای تصمیم گیری در مورد اینکه کدام نمونه ها را کنار هم قرار دهیم تا کمترین مقدار ممکن را داشته باشیم
- تنظیم مدل BERT برای پردازش بسته ها به جای توالی
- و تنظیم هایپرپارامترها
بسته بندی
در ابتدا، بعید به نظر می رسید که بتوانید مجموعه داده های بزرگی مانند ویکی پدیا را بسیار کارآمد جمع کنید. این مشکل معمولاً به عنوان bin-packing شناخته می شود. حتی زمانی که بسته بندی به سه دنباله یا کمتر محدود می شود، مشکل حاصل همچنان به شدت NP-comple خواهد بود و فاقد یک راه حل الگوریتمی کارآمد است. الگوریتمهای بستهبندی اکتشافی موجود امیدوارکننده نبودند زیرا حداقل پیچیدگی داشتند. O(n ورود(n))، جایی که n تعداد دنباله ها است (~16M برای ویکی پدیا). ما به رویکردهایی علاقه مند بودیم که به خوبی در میلیون ها دنباله مقیاس شوند.
دو ترفند به ما کمک کرد تا پیچیدگی را به شدت کاهش دهیم:
- محدود کردن تعداد دنباله ها در یک بسته به سه (برای اولین رویکرد حل ما)
- فقط بر روی هیستوگرام طول دنباله با یک bin برای هر طول رخ می دهد
حداکثر طول دنباله ما 512 بود. بنابراین، حرکت به سمت هیستوگرام ابعاد و پیچیدگی را از 16 میلیون دنباله به 512 شمارش طول کاهش داد. مجاز کردن حداکثر سه دنباله در یک بسته، تعداد ترکیبات طول مجاز را به 22K کاهش داد. این قبلاً شامل ترفندی میشد که باید دنبالهها براساس طول در بسته مرتب شوند. پس چرا 4 دنباله را امتحان نمی کنید؟ این تعداد ترکیب ها را از 22 هزار به 940 هزار افزایش داد که برای اولین رویکرد مدل سازی ما بسیار زیاد بود. علاوه بر این، عمق 3 در حال حاضر بازده بسته بندی بسیار بالایی را به دست آورده است.
در ابتدا، ما فکر می کردیم که استفاده از بیش از سه دنباله در یک بسته، سربار محاسباتی را افزایش می دهد و بر رفتار همگرایی در طول آموزش تأثیر می گذارد. با این حال، برای پشتیبانی از برنامههایی مانند استنتاج، که نیاز به بستهبندی در زمان واقعی و سریعتر دارند، الگوریتم بستهبندی هیستوگرام حداقل مربعات غیر منفی (NNLSHP) بسیار کارآمد را توسعه دادیم.
بسته بندی هیستوگرام حداقل مربعات غیر منفی (NNLSHP)
بسته بندی Bin اغلب به عنوان یک مسئله بهینه سازی ریاضی فرموله می شود. با این حال، با 16 میلیون دنباله (یا بیشتر) این عملی نیست. متغیرهای مشکل به تنهایی از حافظه اکثر ماشین ها فراتر خواهند رفت. برنامه ریاضی برای رویکرد مبتنی بر هیستوگرام کاملاً منظم است. برای سادگی، ما برای رویکرد حداقل مربعات تصمیم گرفتیم (تبر = ب) با بردار هیستوگرام b. ما آن را با درخواست بردار استراتژی گسترش دادیم x غیرمنفی بودن و اضافه کردن وزنه ها برای ایجاد بالشتک جزئی.
بخش دشوار ماتریس استراتژی بود. هر ستون دارای حداکثر مجموع سه است و کدهایی را رمزگذاری می کند که کدام توالی با هم بسته می شوند تا دقیقاً با طول کل مورد نظر مطابقت داشته باشند. 512 در مورد ما. سطرها هر یک از ترکیبات بالقوه را رمزگذاری می کنند تا به طول کل برسد. بردار استراتژی x چیزی است که ما به دنبال آن بودیم، که توضیح میدهد هر چند وقت یکبار هر کدام از 20 هزار ترکیب را انتخاب میکنیم. جالب اینجاست که در پایان تنها حدود 600 ترکیب انتخاب شدند. برای دستیابی به یک راه حل دقیق، استراتژی مهم است x باید اعداد صحیح مثبت باشند، اما ما متوجه شدیم که یک راه حل گرد تقریبی با فقط غیر منفی x کافی بود برای یک راه حل تقریبی، می توان از یک حل کننده ساده خارج از جعبه برای به دست آوردن نتیجه در عرض 30 ثانیه استفاده کرد.

شکل 4: نمونهای از یک ماتریس استراتژی برای طول دنباله 8 و عمق بستهبندی 3. ردیفها نشاندهنده دنبالههایی به طول 1-8 هستند که در کنار هم قرار میگیرند و ستونها برای تمام ترکیبهای طول ممکن در یک بسته بدون ترتیب خاصی هستند. تصویر توسط نویسنده
در پایان، ما مجبور شدیم برخی از نمونهها را اصلاح کنیم که استراتژی تعیین نشده بودند، اما حداقل بودند. ما همچنین یک حلکننده متغیر توسعه دادیم که هر دنباله را مجبور میکند، به طور بالقوه با padding، بستهبندی شود و وزنی وابسته به بالشتک داشته باشد. خیلی بیشتر طول کشید و راه حل خیلی بهتر نبود.
بسته بندی هیستوگرام Shortest-Pack-First
NNLSHP یک رویکرد بسته بندی کافی برای ما ارائه کرد. با این حال، ما فکر میکردیم که آیا میتوانیم از نظر تئوری رویکرد آنلاین سریعتری داشته باشیم و محدودیت کنار هم قرار دادن تنها 3 دنباله را حذف کنیم.
بنابراین، ما از الگوریتمهای بستهبندی موجود الهام گرفتیم، اما همچنان بر روی هیستوگرامها تمرکز کردیم.
چهار عنصر برای اولین الگوریتم ما، بسته بندی هیستوگرام کوتاه ترین بسته اول (SPFHP) وجود دارد:
- بر روی شمارش هیستوگرام از طولانی ترین دنباله تا کوتاه ترین عمل کنید
- اگر طول دنباله فعلی در هیچ بسته ای مناسب نیست، مجموعه جدیدی از بسته ها را شروع کنید
- اگر چند تناسب وجود دارد، بستهای را بگیرید که مجموع طول دنباله کوتاهترین است و به ترتیب تعداد را تغییر دهید.
- دوباره برای تناسب تعداد باقیمانده بررسی کنید
این روش ساده ترین روش برای اجرا بود و تنها 0.02 ثانیه طول کشید.
یک نوع دیگر این بود که بهجای کوتاهترین و تقسیمشمار، بیشترین مجموع طول دنباله را برای برازشهای کاملتر در نظر بگیریم. به طور کلی، این کارایی را زیاد تغییر نداد، اما پیچیدگی کد را بسیار افزایش داد.
نحوه عملکرد بسته بندی هیستوگرام کوتاه ترین بسته اول انیمیشن توسط نویسنده
ویکیپدیا، SQuAD 1.1، نتایج بستهبندی GLUE
جدول 1، 2 و 3 نتایج بسته بندی دو الگوریتم پیشنهادی ما را نشان می دهد. عمق بسته بندی حداکثر تعداد توالی های بسته بندی شده را توصیف می کند. عمق بسته بندی 1 اجرای BERT خط پایه است. حداکثر عمق بستهبندی رخداده، بدون محدودیت با یک «حداکثر» نشان داده میشود. در تعداد بسته ها طول مجموعه داده بسته بندی شده جدید را توصیف می کند. بهره وری درصد نشانه های واقعی در مجموعه داده های بسته بندی شده است. در فاکتور بسته بندی سرعت بالقوه حاصل را در مقایسه با عمق بسته بندی 1 توضیح می دهد.
ما چهار مشاهدات اصلی داشتیم:
- هر چه توزیع اریب بیشتر باشد، مزایای بسته بندی بیشتر است.
- همه مجموعه داده ها از بسته بندی سود می برند. برخی حتی بیش از ضریب 2.
- زمانی که عمق بسته بندی محدود نباشد SPFHP کارآمدتر می شود.
- برای حداکثر تعداد 3 دنباله بسته بندی شده، هرچه NNLSHP پیچیده تر باشد، کارآمدتر است (99.75 در مقابل 89.44).

جدول 1: نتایج عملکرد کلیدی الگوریتم های بسته بندی پیشنهادی (SPFHP و NNLSHP) در ویکی پدیا. تصویر توسط نویسنده

جدول 2: نتایج عملکرد الگوریتمهای بستهبندی پیشنهادی برای پیشآموزش SQUaD 1.1 BERT. تصویر توسط نویسنده

جدول 3: نتایج عملکرد الگوریتم های بسته بندی پیشنهادی برای مجموعه داده GLUE. فقط نتایج بسته بندی پایه و SPFHP بدون محدود کردن عمق بسته بندی نمایش داده می شود. تصویر توسط نویسنده
تنظیم پردازش BERT
نکته جالب در مورد معماری BERT این است که بیشتر پردازش ها در سطح رمزی اتفاق می افتد، به این معنی که در بسته بندی ما تداخلی ایجاد نمی کند. فقط چهار جزء وجود دارد که نیاز به تنظیم دارند: ماسک توجه، فقدان MLM، از دست دادن NSP و دقت.
کلید هر چهار رویکرد برای رسیدگی به تعداد مختلف توالی، برداری و استفاده از حداکثر تعداد دنبالههایی بود که میتوان آنها را به هم متصل کرد. برای توجه، ما قبلاً ماسکی برای پرداختن به بالشتک داشتیم. همانطور که در شبه کد TensorFlow زیر مشاهده می شود، گسترش این به چندین توالی ساده بود. مفهوم این است که ما مطمئن شدیم که توجه به دنباله های جداگانه محدود می شود و نمی تواند فراتر از آن گسترش یابد.
نمونه کد ماسک توجه.

شکل 5: نمونه ماسک صفر و یک
برای محاسبه ضرر، در اصل توالیها را باز میکنیم و تلفات جداگانه را محاسبه میکنیم و در نهایت میانگین تلفات روی دنبالهها (به جای بسته) را به دست میآوریم.
برای از دست دادن MLM، کد به نظر می رسد:
نمونه کد محاسبه ضرر.
برای از دست دادن NSP و دقت، اصل یکسان است. در نمونه های عمومی ما، می توانید کد مربوطه را در داخل ما پیدا کنید چارچوب PopART.
برآورد سربار و افزایش سرعت ویکی پدیا
با اصلاح BERT ما دو سوال داشتیم:
- چقدر سربار با خود می آورد؟
- سربار چقدر به حداکثر تعداد دنباله هایی که در یک بسته قرار می گیرند بستگی دارد؟
از آنجایی که آماده سازی داده ها در BERT می تواند دست و پا گیر باشد، ما از یک میانبر استفاده کردیم و کد را برای چندین عمق بسته بندی مختلف گردآوری کردیم و چرخه های مربوطه (اندازه گیری شده) را مقایسه کردیم. نتایج در جدول 4 نشان داده شده است در بالای سر، درصد کاهش توان را به دلیل تغییرات در مدل برای فعال کردن بسته بندی نشان می دهیم (مانند طرح پوشش برای توجه و محاسبه تلفات تغییر یافته). در متوجه افزایش سرعت شد ترکیبی از افزایش سرعت به دلیل بسته بندی است ( فاکتور بسته بندی) و کاهش توان عملیاتی ناشی از در بالای سر.

جدول 4: مقایسه سرعت تخمینی الگوریتم های بسته بندی پیشنهادی (SPFHP و NNLSHP) در ویکی پدیا. تصویر توسط نویسنده
به لطف تکنیک برداری، سربار به طور شگفت انگیزی کوچک است و هیچ ضرری از بسته بندی بسیاری از دنباله ها با هم وجود ندارد.
تعدیل های فراپارامتر
با بسته بندی، اندازه دسته موثر را دو برابر می کنیم (به طور متوسط). این بدان معناست که ما باید فراپارامترهای آموزشی را تنظیم کنیم. یک ترفند ساده این است که تعداد انباشتگی گرادیان را به نصف کاهش دهید تا همان اندازه متوسط مؤثر دسته ای را که قبل از تمرین بود حفظ کنید. با استفاده از یک تنظیم معیار با نقاط بازرسی از پیش آموزش دیده، میتوان دید که منحنیهای دقت کاملاً مطابقت دارند.

شکل 6: مقایسه منحنی های یادگیری برای پردازش بسته بندی شده و بدون بسته بندی با کاهش اندازه دسته برای رویکرد بسته بندی شده تصاویر توسط نویسنده
دقت منطبق است: از دست دادن آموزش MLM ممکن است در ابتدا کمی متفاوت باشد اما به سرعت فرا می رسد. این تفاوت اولیه می تواند ناشی از تنظیمات جزئی لایه های توجه باشد که ممکن است در آموزش قبلی نسبت به دنباله های کوتاه تعصب داشته باشند.
برای جلوگیری از کاهش سرعت، گاهی اوقات کمک میکند که اندازه دسته اصلی ثابت بماند و فراپارامترها با افزایش اندازه موثر دسته (دوبرابر) تنظیم شوند. فراپارامترهای اصلی که باید در نظر گرفته شوند، پارامترهای بتا و نرخ یادگیری هستند. یک رویکرد رایج دو برابر کردن اندازه دسته است که در مورد ما باعث کاهش عملکرد می شود. با نگاهی به آمار بهینهساز LAMB، میتوانیم ثابت کنیم که افزایش پارامتر بتا به قدرت ضریب بستهبندی با تمرین چندین دسته متوالی برای حفظ حرکت و سرعت قابل مقایسه است.

شکل 7: مقایسه منحنی های یادگیری برای پردازش بسته بندی شده و بدون بسته بندی با اکتشافات کاربردی. تصاویر توسط نویسنده
آزمایشهای ما نشان داد که گرفتن بتا به توان دو یک اکتشافی خوب است. در این سناریو، انتظار نمیرود منحنیها مطابقت داشته باشند، زیرا افزایش اندازه دسته معمولاً سرعت همگرایی را به معنای نمونهها/دوران کاهش میدهد تا زمانی که به دقت هدف برسد.
حال سؤال این است که آیا در سناریوی عملی، آیا واقعاً به سرعت پیشبینیشده میرسیم؟

شکل 8: مقایسه منحنی های یادگیری برای پردازش بسته بندی شده و بدون بسته بندی در راه اندازی بهینه. تصاویر توسط نویسنده
بله ما انجام میدهیم! به دلیل اینکه انتقال داده را فشرده کردیم، سرعت بیشتری به دست آوردیم.
نتیجه
بسته بندی جملات در کنار هم می تواند باعث صرفه جویی در تلاش محاسباتی و محیط زیست شود. این تکنیک را می توان در هر چارچوبی از جمله PyTorch و TensorFlow پیاده سازی کرد. ما یک افزایش 2 برابری واضح به دست آوردیم و در طول مسیر، وضعیت هنر را در الگوریتم های بسته بندی گسترش دادیم.
کاربردهای دیگری که ما در مورد آنها کنجکاو هستیم، ژنومیک و تاشو پروتئین است که در آن توزیع داده های مشابهی قابل مشاهده است. ترانسفورماتورهای بینایی همچنین می توانند یک منطقه جالب برای اعمال تصاویر بسته بندی شده با اندازه های متفاوت باشند. به نظر شما کدام برنامه ها به خوبی کار می کنند؟ دوست داریم بیشتر از شما بشنویم!
به کد در GitHub دسترسی داشته باشید
با تشکر از شما
از همکاران ما در تیم مهندسی برنامه های کاربردی Graphcore، شنگ فو و مرینال ایر، برای مشارکت در این کار و تشکر از داگلاس اور از تیم تحقیقاتی Graphcore برای بازخورد ارزشمندش.
منابع
[1] M. Kosec، S. Fu، MM Krell، بسته بندی: به سمت شتاب 2 برابری NLP BERT (2021)، arXiv
دکتر ماریو مایکل کرل پیشرو اصلی یادگیری ماشین در Graphcore است. ماریو بیش از 12 سال است که در حال تحقیق و توسعه الگوریتمهای یادگیری ماشین بوده و نرمافزاری را برای صنایع مختلفی مانند رباتیک، خودرو، مخابرات و مراقبتهای بهداشتی ایجاد کرده است. در Graphcore، او به تاثیرگذار ما کمک کرد ارسالی MLPerf و علاقه زیادی به سرعت بخشیدن به مدل های غیر استاندارد جدید مانند محاسبات تقریبی بیزی برای تجزیه و تحلیل داده های آماری COVID-19 دارد.
Matej Kosec یک متخصص برنامه های کاربردی هوش مصنوعی در Graphcore در پالو آلتو است. او قبلاً به عنوان دانشمند هوش مصنوعی در زمینه رانندگی خودکار در NIO در سن خوزه کار کرده است و دارای مدرک کارشناسی ارشد در رشته هوانوردی و فضانوردی از دانشگاه استنفورد است.
اصلی. مجدداً با اجازه دوباره ارسال شد.
مرتبط:
| داستانهای برتر 30 روز گذشته | |||||
|---|---|---|---|---|---|
|
|
||||
- "
- &
- 2021
- 7
- اضافی
- دانش هوانوردی
- AI
- الگوریتم
- الگوریتم
- معرفی
- اجازه دادن
- تحلیل
- انیمیشن
- کاربرد
- برنامه های کاربردی
- معماری
- محدوده
- دور و بر
- هنر
- خودکار
- خودرو
- خود مختار
- خط مقدم
- محک
- بتا
- تغییر دادن
- رمز
- ستون
- مشترک
- محاسبه
- کمک
- Covid-19
- ایجاد
- جاری
- مشتریان
- داده ها
- تحلیل داده ها
- علم اطلاعات
- یادگیری عمیق
- توسعه
- DID
- بعد
- مدیر
- اسناد و مدارک
- رانندگی
- موثر
- بهره وری
- مهندس
- مهندسی
- محیط
- نام خانوادگی
- مناسب
- رفع
- تمرکز
- چارچوب
- ژنومیک
- خوب
- GPU ها
- بهداشت و درمان
- زیاد
- چگونه
- HTTPS
- تصویر
- تأثیر
- از جمله
- افزایش
- لوازم
- صنعت
- الهام
- مصاحبه
- بررسی
- IT
- کار
- کلید
- دانش
- زبان
- بزرگ
- رهبری
- یاد گرفتن
- یادگیری
- سطح
- محدود شده
- لینک
- عشق
- فراگیری ماشین
- ساخت
- ماسک
- مسابقه
- میلیون
- ML
- مدل
- حرکت
- زبان طبیعی
- پردازش زبان طبیعی
- مرتب
- عصبی
- nlp
- تعداد
- آنلاین
- باز کن
- منبع باز
- دیگر
- مقاله
- کارایی
- قدرت
- اصلی
- برنامه
- پروتئين
- عمومی
- پــایتــون
- مارماهی
- نرخ
- زمان واقعی
- دلایل
- كاهش دادن
- رگرسیون
- تحقیق
- نتایج
- رباتیک
- سان
- سن خوزه
- صرفه جویی کردن
- مقیاس
- علم
- دانشمندان
- جستجو
- انتخاب شد
- حس
- تنظیم
- محیط
- کوتاه
- ساده
- اندازه
- کوچک
- So
- نرم افزار
- سرعت
- انشعاب
- استنفورد
- دانشگاه استنفورد
- شروع
- دولت
- ارقام
- داستان
- استراتژی
- پشتیبانی
- هدف
- ارتباط از راه دور
- جریان تنسور
- رمز
- نشانه
- بالا
- آموزش
- دانشگاه
- us
- VeloCity
- دید
- ویکیپدیا
- در داخل
- مهاجرت کاری
- با این نسخهها کار
- با ارزش
- X
- سال