یکی از کاربردیترین الگوهای کاربردی برای بارهای کاری هوش مصنوعی مولد، Retrieval Augmented Generation (RAG) است. در الگوی RAG، با انجام جستجوهای مشابه در جاسازیها، قطعاتی از محتوای مرجع مربوط به یک اعلان ورودی را پیدا میکنیم. تعبیهها محتوای اطلاعاتی را در بدنه متن ضبط میکنند و به مدلهای پردازش زبان طبیعی (NLP) اجازه میدهند با زبان به شکل عددی کار کنند. جاسازیها فقط بردارهای اعداد ممیز شناور هستند، بنابراین میتوانیم آنها را برای پاسخ به سه سؤال مهم تجزیه و تحلیل کنیم: آیا دادههای مرجع ما در طول زمان تغییر میکنند؟ آیا سوالاتی که کاربران می پرسند در طول زمان تغییر می کنند؟ و در نهایت، داده های مرجع ما تا چه اندازه سوالات پرسیده شده را پوشش می دهد؟
در این پست، با برخی از ملاحظات مربوط به تعبیه تحلیل برداری و تشخیص سیگنالهای دریفت تعبیه شده آشنا خواهید شد. از آنجایی که جاسازیها منبع مهمی از دادهها برای مدلهای NLP به طور کلی و راهحلهای هوش مصنوعی مولد هستند، ما به راهی برای اندازهگیری اینکه آیا جاسازیهای ما در طول زمان تغییر میکنند (دریفت) نیاز داریم. در این پست، نمونهای از انجام تشخیص دریفت در جاسازی بردارها با استفاده از تکنیک خوشهبندی با مدلهای زبان بزرگ (LLMS) مستقر شده از Amazon SageMaker JumpStart. همچنین میتوانید این مفاهیم را از طریق دو مثال ارائه شده، از جمله یک نمونه برنامه کاربردی سرتاسر یا، به صورت اختیاری، زیر مجموعهای از برنامه مورد بررسی قرار دهید.
نمای کلی RAG
La الگوی RAG به شما امکان می دهد دانش را از منابع خارجی بازیابی کنید، مانند اسناد PDF، مقالات ویکی، یا رونوشت تماس ها، و سپس از آن دانش برای تقویت دستورات ارسال شده به LLM استفاده کنید. این به LLM اجازه می دهد تا در هنگام ایجاد پاسخ به اطلاعات مرتبط تری ارجاع دهد. برای مثال، اگر از یک LLM بپرسید که چگونه کوکیهای شکلاتی درست کند، میتواند شامل اطلاعاتی از کتابخانه دستور پخت شما باشد. در این الگو، متن دستور پخت با استفاده از مدل جاسازی به بردارهای تعبیه شده تبدیل شده و در یک پایگاه داده برداری ذخیره می شود. سؤالات دریافتی به جاسازی ها تبدیل می شوند و سپس پایگاه داده برداری جستجوی مشابهی را برای یافتن محتوای مرتبط اجرا می کند. سپس سؤال و داده های مرجع وارد اعلان LLM می شوند.
بیایید نگاهی دقیقتر به بردارهای تعبیهشدهای که ایجاد میشوند و نحوه انجام تحلیل دریفت روی آن بردارها بیاندازیم.
تحلیل بردارهای تعبیه شده
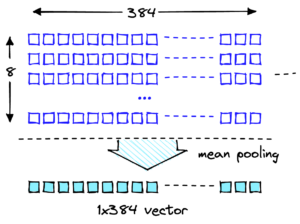
بردارهای جاسازی شده نمایش عددی دادههای ما هستند، بنابراین تجزیه و تحلیل این بردارها میتواند بینشی در مورد دادههای مرجع ما ارائه دهد که بعداً میتواند برای تشخیص سیگنالهای بالقوه رانش استفاده شود. بردارهای جاسازی یک آیتم را در فضای n بعدی نشان می دهند، جایی که n اغلب بزرگ است. به عنوان مثال، مدل GPT-J 6B، که در این پست استفاده شده است، بردارهایی با اندازه 4096 ایجاد می کند. برای اندازه گیری دریفت، فرض کنید که برنامه ما بردارهای جاسازی شده را برای داده های مرجع و اعلان های دریافتی می گیرد.
ما با انجام کاهش ابعاد با استفاده از تجزیه و تحلیل مؤلفه اصلی (PCA) شروع می کنیم. PCA سعی می کند تعداد ابعاد را کاهش دهد و در عین حال بیشتر واریانس داده ها را حفظ کند. در این مورد، ما سعی می کنیم تعداد ابعادی را پیدا کنیم که 95٪ از واریانس را حفظ کند، که باید هر چیزی را در دو انحراف استاندارد ثبت کند.
سپس از K-Means برای شناسایی مجموعه ای از مراکز خوشه استفاده می کنیم. K-Means سعی می کند نقاط را با هم در خوشه هایی دسته بندی کند که هر خوشه نسبتا فشرده باشد و خوشه ها تا حد امکان از یکدیگر دور باشند.
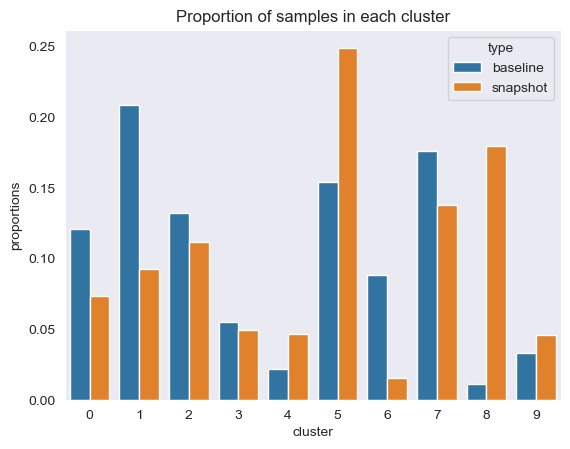
ما اطلاعات زیر را بر اساس خروجی خوشه بندی نشان داده شده در شکل زیر محاسبه می کنیم:
- تعداد ابعاد در PCA که 95 درصد واریانس را توضیح می دهد
- مکان هر مرکز خوشه یا مرکز
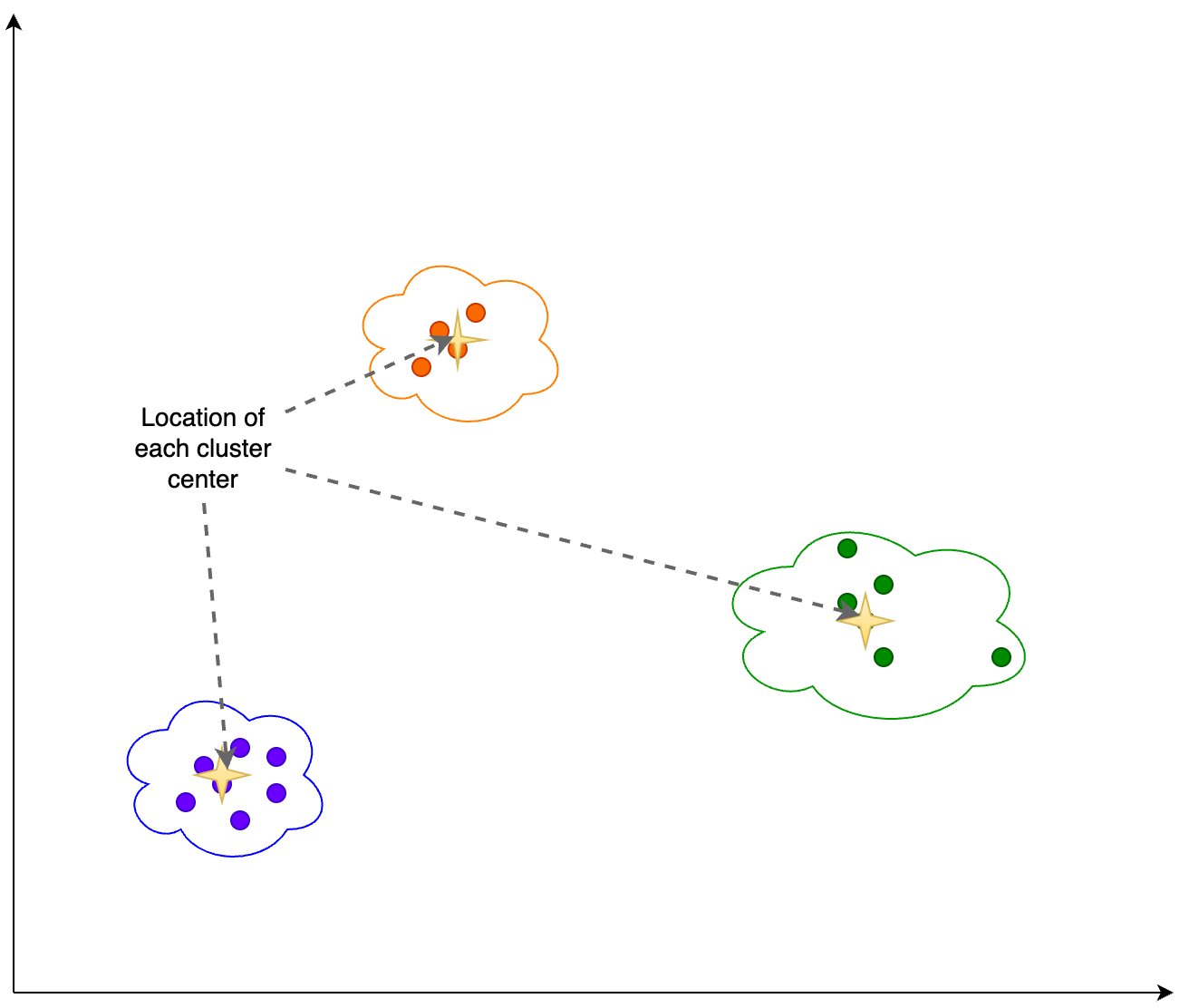
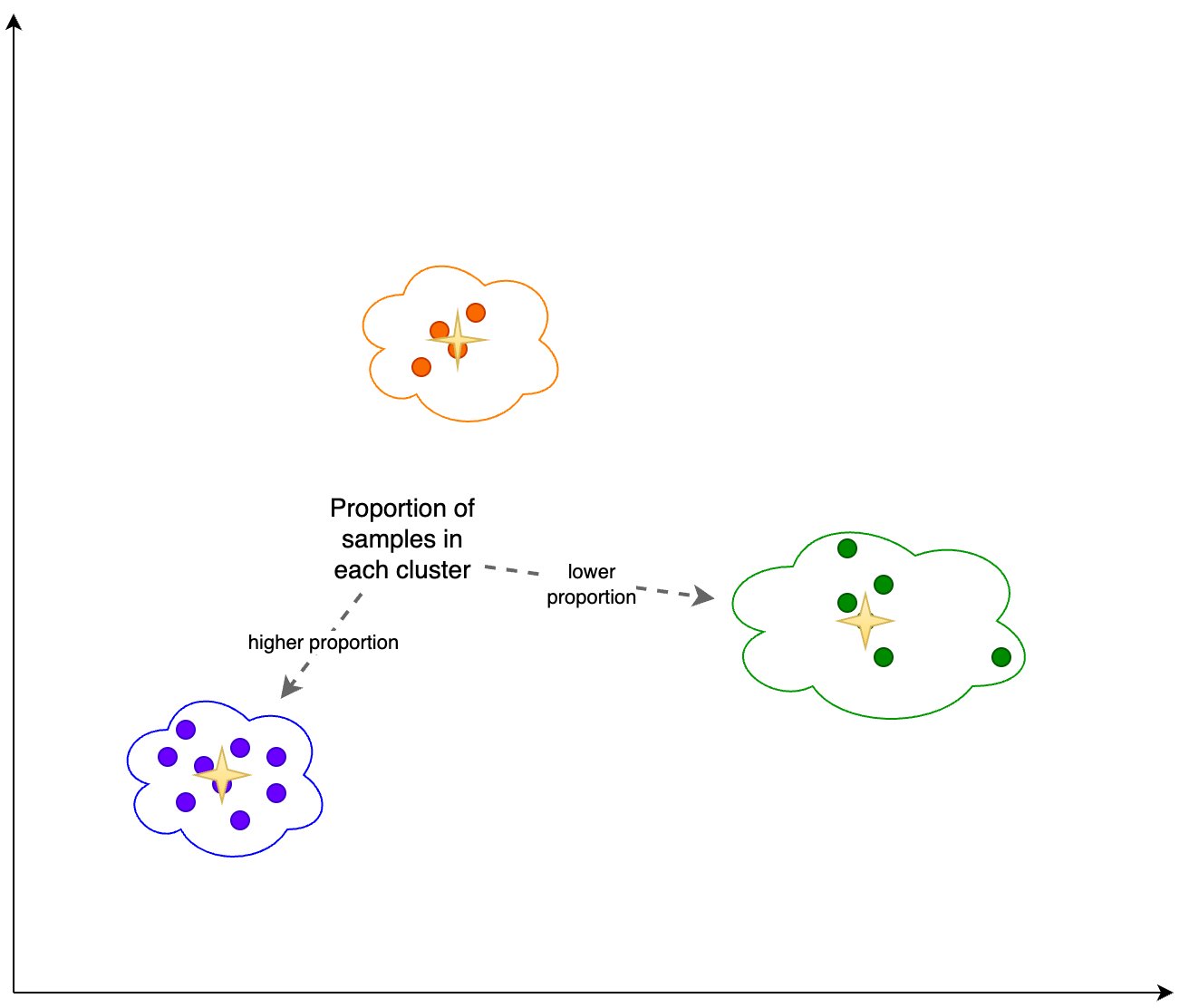
به علاوه، همانطور که در شکل زیر نشان داده شده است، به نسبت (بالاتر یا کمتر) نمونه ها در هر خوشه نگاه می کنیم.
در نهایت از این تحلیل برای محاسبه موارد زیر استفاده می کنیم:
- جبر - اینرسی مجموع فاصله های مجذور از مرکزهای خوشه ای است که میزان خوشه بندی داده ها را با استفاده از K-Means اندازه گیری می کند.
- نمره سیلوئت - امتیاز silhouette معیاری برای اعتبارسنجی سازگاری در خوشه ها است و از 1- تا 1 متغیر است. مقدار نزدیک به 1 به این معنی است که نقاط یک خوشه نزدیک به سایر نقاط در همان خوشه و دور از آن هستند. نقاط دیگر خوشه ها در شکل زیر نمایش تصویری امتیاز silhouette قابل مشاهده است.

ما میتوانیم بهطور دورهای این اطلاعات را برای عکسهای فوری جاسازیها هم برای دادههای مرجع منبع و هم برای درخواستها ضبط کنیم. گرفتن این داده ها به ما امکان می دهد سیگنال های بالقوه رانش تعبیه شده را تجزیه و تحلیل کنیم.
تشخیص رانش تعبیه شده
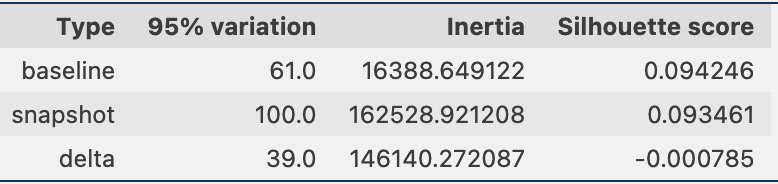
به صورت دورهای، میتوانیم اطلاعات خوشهبندی را از طریق عکسهای فوری دادهها، که شامل جاسازیهای دادههای مرجع و جاسازیهای سریع است، مقایسه کنیم. ابتدا، میتوانیم تعداد ابعاد مورد نیاز برای توضیح 95 درصد از تغییرات در دادههای جاسازی، اینرسی و امتیاز شبح را از کار خوشهبندی مقایسه کنیم. همانطور که در جدول زیر می بینید، در مقایسه با یک خط مبنا، آخرین عکس فوری از جاسازی ها به 39 بعد بیشتر برای توضیح واریانس نیاز دارد، که نشان می دهد داده های ما پراکنده تر هستند. اینرسی افزایش یافته است، که نشان می دهد که نمونه ها در مجموع دورتر از مراکز خوشه خود هستند. علاوه بر این، امتیاز silhouette کاهش یافته است، که نشان می دهد خوشه ها به خوبی تعریف نشده اند. برای داده های سریع، این ممکن است نشان دهد که انواع سؤالات وارد شده به سیستم موضوعات بیشتری را پوشش می دهند.
در ادامه در شکل زیر مشاهده می کنیم که نسبت نمونه ها در هر خوشه در طول زمان چگونه تغییر کرده است. این می تواند به ما نشان دهد که آیا داده های مرجع جدیدتر ما به طور کلی مشابه مجموعه قبلی است یا حوزه های جدیدی را پوشش می دهد.
در نهایت، میتوانیم ببینیم که آیا مراکز خوشهای در حال حرکت هستند یا خیر، که نشاندهنده انحراف در اطلاعات در خوشهها، همانطور که در جدول زیر نشان داده شده است.

پوشش داده های مرجع برای سؤالات دریافتی
ما همچنین میتوانیم ارزیابی کنیم که دادههای مرجع ما چقدر با سؤالات ورودی مطابقت دارند. برای انجام این کار، هر تعبیه سریع را به یک خوشه داده مرجع اختصاص می دهیم. ما فاصله هر اعلان تا مرکز مربوطه را محاسبه می کنیم و به میانگین، میانه و انحراف استاندارد آن فواصل نگاه می کنیم. ما می توانیم آن اطلاعات را ذخیره کنیم و ببینیم که چگونه در طول زمان تغییر می کند.
شکل زیر نمونه ای از تجزیه و تحلیل فاصله بین مراکز داده مرجع و جاسازی سریع را در طول زمان نشان می دهد.

همانطور که می بینید، میانگین، میانه و آمار فاصله انحراف استاندارد بین جاسازی سریع و مراکز داده مرجع بین خط پایه اولیه و آخرین عکس فوری در حال کاهش است. اگرچه تفسیر قدر مطلق فاصله دشوار است، اما میتوانیم از روندها برای تعیین اینکه آیا همپوشانی معنایی بین دادههای مرجع و سؤالات ورودی در طول زمان بهتر یا بدتر میشود، استفاده کنیم.
نمونه برنامه
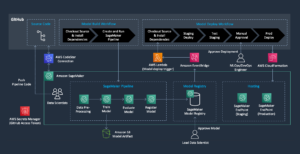
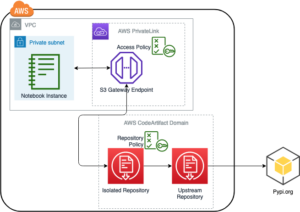
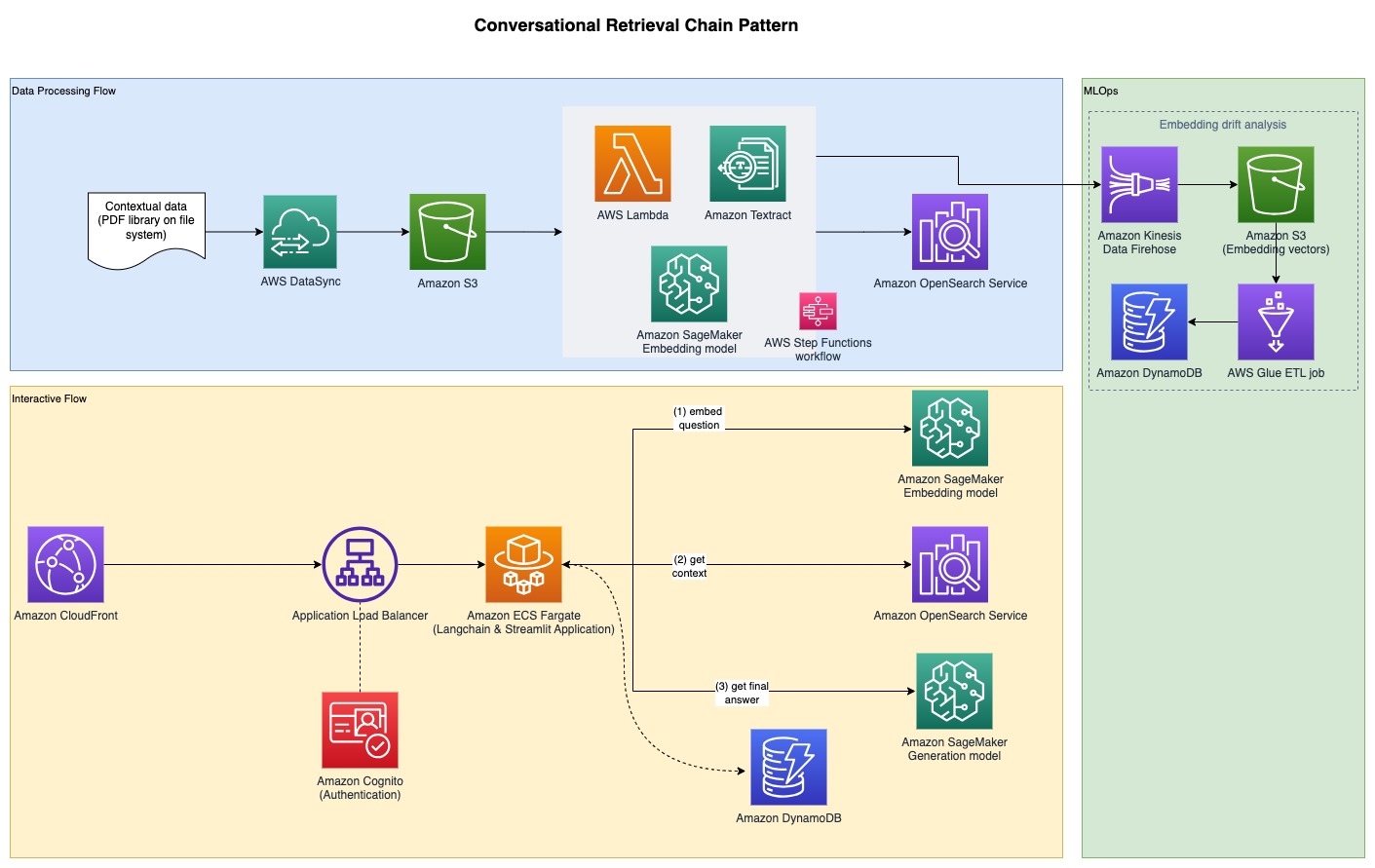
به منظور جمعآوری نتایج تجربی که در بخش قبل مورد بحث قرار گرفت، یک نمونه برنامه کاربردی ساختیم که الگوی RAG را با استفاده از مدلهای جاسازی و تولید که از طریق SageMaker JumpStart مستقر شده و در میزبانی میشوند، پیادهسازی میکند. آمازون SageMaker نقاط پایانی بلادرنگ
برنامه دارای سه جزء اصلی است:
- ما از یک جریان تعاملی استفاده می کنیم که شامل یک رابط کاربری برای گرفتن اعلان ها، همراه با یک لایه ارکستراسیون RAG، با استفاده از LangChain است.
- جریان پردازش داده ها داده ها را از اسناد PDF استخراج می کند و جاسازی هایی ایجاد می کند که در آن ذخیره می شوند سرویس جستجوی باز آمازون. ما همچنین از اینها در مولفه تجزیه و تحلیل رانش تعبیه نهایی برنامه استفاده می کنیم.
- تعبیه ها در گرفته شده اند سرویس ذخیره سازی ساده آمازون (Amazon S3) از طریق Amazon Kinesis Data Firehose، و ترکیبی از چسب AWS استخراج، تبدیل و بارگذاری (ETL) و نوت بوک های Jupyter برای انجام تجزیه و تحلیل جاسازی.
نمودار زیر معماری انتها به انتها را نشان می دهد.
کد نمونه کامل در دسترس است GitHub. کد ارائه شده در دو الگوی مختلف موجود است:
- نمونه برنامه full-stack با ظاهر Streamlit - این یک برنامه کاربردی سرتاسر، از جمله یک رابط کاربری با استفاده از Streamlit برای گرفتن دستورات، همراه با لایه ارکستراسیون RAG، با استفاده از LangChain در حال اجرا در سرویس کانتینر الاستیک آمازون (Amazon ECS) با AWS Fargate
- برنامه Backend - برای کسانی که نمی خواهند پشته کامل برنامه را مستقر کنند، می توانید به صورت اختیاری انتخاب کنید که فقط backend را مستقر کنید. کیت توسعه ابری AWS (AWS CDK) را پشته کنید، و سپس از نوت بوک Jupyter ارائه شده برای اجرای ارکستراسیون RAG با استفاده از LangChain استفاده کنید.
برای ایجاد الگوهای ارائه شده، پیش نیازهای متعددی وجود دارد که در بخشهای بعدی به تفصیل شرح داده شده است، که با استقرار مدلهای مولد و جاسازی متن شروع میشود و سپس به پیشنیازهای اضافی میروید.
استقرار مدل ها از طریق SageMaker JumpStart
هر دو الگوی استقرار یک مدل تعبیه شده و مدل مولد را فرض می کنند. برای این کار، دو مدل از SageMaker JumpStart را مستقر خواهید کرد. مدل اول، GPT-J 6B، به عنوان مدل جاسازی و مدل دوم، Falcon-40b، برای تولید متن استفاده می شود.
شما می توانید هر یک از این مدل ها را از طریق SageMaker JumpStart از طریق SageMaker استقرار دهید کنسول مدیریت AWS, Amazon SageMaker Studio، یا به صورت برنامه ای برای اطلاعات بیشتر مراجعه کنید نحوه استفاده از مدل های فونداسیون جامپ استارت. برای ساده کردن استقرار، می توانید از دفترچه ارائه شده برگرفته از نوتبوکهایی که بهطور خودکار توسط SageMaker JumpStart ایجاد میشوند. این نوت بوک مدل ها را از هاب SageMaker JumpStart ML بیرون می کشد و آنها را در دو نقطه پایانی SageMaker مجزا مستقر می کند.
دفترچه نمونه دارای قسمت پاکسازی نیز می باشد. هنوز آن بخش را اجرا نکنید، زیرا نقاط پایانی را که به تازگی مستقر شده اند حذف می کند. شما پاکسازی را در پایان راهپیمایی کامل خواهید کرد.
پس از تأیید استقرار موفقیت آمیز نقاط پایانی، آماده استقرار برنامه نمونه کامل هستید. با این حال، اگر بیشتر به کاوش در دفترچههای پشتیبان و نوتبوکهای تجزیه و تحلیل علاقه دارید، میتوانید به صورت اختیاری فقط آن را که در بخش بعدی پوشش داده شده است، گسترش دهید.
گزینه 1: فقط برنامه Backend را استقرار دهید
این الگو به شما این امکان را میدهد که تنها راهحل باطن را اجرا کنید و با استفاده از یک نوت بوک Jupyter با راهحل تعامل داشته باشید. اگر نمیخواهید رابط کاربری کامل را ایجاد کنید، از این الگو استفاده کنید.
پیش نیازها
شما باید پیش نیازهای زیر را داشته باشید:
- یک نقطه پایانی مدل SageMaker JumpStart مستقر شد - طبق آنچه که قبلا ذکر شد، مدل ها را با استفاده از SageMaker JumpStart در نقاط پایانی بلادرنگ SageMaker مستقر کنید.
- پارامترهای استقرار - موارد زیر را ثبت کنید:
- نام نقطه پایانی مدل متنی – نام نقطه پایانی مدل تولید متن که با SageMaker JumpStart مستقر شده است
- نام نقطه پایانی مدل جاسازیها - نام نقطه پایانی مدل تعبیه شده با SageMaker JumpStart
منابع را با استفاده از AWS CDK مستقر کنید
از پارامترهای استقرار ذکر شده در بخش قبل برای استقرار پشته AWS CDK استفاده کنید. برای اطلاعات بیشتر در مورد نصب AWS CDK، مراجعه کنید شروع کار با AWS CDK.
مطمئن شوید که Docker روی ایستگاه کاری که برای استقرار AWS CDK استفاده میشود، نصب و اجرا میشود. رجوع شود به داکر را دریافت کنید برای راهنمایی بیشتر
همچنین می توانید مقادیر متن را در فایلی به نام وارد کنید cdk.context.json در pattern1-rag/cdk دایرکتوری و اجرا کنید cdk deploy BackendStack --exclusively.
استقرار خروجی هایی را چاپ می کند که برخی از آنها برای اجرای نوت بوک مورد نیاز است. قبل از شروع پرسش و پاسخ، اسناد مرجع را همانطور که در بخش بعدی نشان داده شده است، درج کنید.
اسناد مرجع را جاسازی کنید
برای این رویکرد RAG، اسناد مرجع ابتدا با یک مدل جاسازی متن جاسازی شده و در یک پایگاه داده برداری ذخیره می شوند. در این راه حل، یک خط لوله جذب ساخته شده است که اسناد PDF را دریافت می کند.
An ابر محاسبه الاستیک آمازون نمونه (Amazon EC2) برای جذب سند PDF و یک ایجاد شده است سیستم فایل الاستیک آمازون سیستم فایل (Amazon EFS) روی نمونه EC2 برای ذخیره اسناد PDF نصب شده است. یک AWS DataSync این کار هر ساعت اجرا می شود تا اسناد PDF موجود در مسیر فایل سیستم EFS و آپلود آنها در سطل S3 برای شروع فرآیند جاسازی متن انجام شود. این فرآیند اسناد مرجع را جاسازی می کند و جاسازی ها را در سرویس OpenSearch ذخیره می کند. همچنین یک آرشیو جاسازی شده را از طریق Kinesis Data Firehose در یک سطل S3 برای تجزیه و تحلیل بعدی ذخیره می کند.
برای دریافت اسناد مرجع، مراحل زیر را انجام دهید:
- نمونه شناسه نمونه EC2 ایجاد شده را بازیابی کنید (خروجی AWS CDK را ببینید
JumpHostId) و با استفاده از آن متصل شوید مدیر جلسه، قابلیتی از مدیر سیستم های AWS. برای دستورالعمل، مراجعه کنید با AWS Systems Manager Session Manager به نمونه لینوکس خود متصل شوید. - به دایرکتوری بروید
/mnt/efs/fs1که محل نصب فایل سیستم EFS است و پوشه ای به نام ایجاد کنیدingest: - اسناد PDF مرجع خود را به
ingestدایرکتوری.
وظیفه DataSync به گونهای پیکربندی شده است که تمام فایلهای موجود در این فهرست را در Amazon S3 آپلود کند تا فرآیند جاسازی آغاز شود.
وظیفه DataSync بر اساس یک برنامه ساعتی اجرا می شود. می توانید به صورت اختیاری کار را به صورت دستی شروع کنید تا فرآیند جاسازی فوراً برای اسناد PDF که اضافه کرده اید آغاز شود.
- برای شروع کار، شناسه وظیفه را از خروجی AWS CDK پیدا کنید
DataSyncTaskIDو کار را شروع کنید با پیش فرض ها
پس از ایجاد تعبیهها، میتوانید همانطور که در بخش بعدی نشان داده شده است، سؤال و پاسخ RAG را از طریق یک دفترچه یادداشت Jupyter شروع کنید.
پرسش و پاسخ با استفاده از دفترچه یادداشت Jupyter
مراحل زیر را انجام دهید:
- نام نمونه نوت بوک SageMaker را از خروجی AWS CDK بازیابی کنید
NotebookInstanceNameو از کنسول SageMaker به JupyterLab متصل شوید. - به دایرکتوری بروید
fmops/full-stack/pattern1-rag/notebooks/. - نوت بوک را باز کرده و اجرا کنید
query-llm.ipynbدر نوت بوک برای انجام پرسش و پاسخ با استفاده از RAG.
حتما استفاده کنید conda_python3 هسته برای نوت بوک
این الگو برای کشف راه حل باطن بدون نیاز به ارائه پیش نیازهای اضافی که برای برنامه فول استک مورد نیاز است مفید است. بخش بعدی اجرای یک برنامه فول استک را پوشش میدهد، که شامل هر دو قسمت جلویی و پشتیبان میشود تا یک رابط کاربری برای تعامل با برنامه هوش مصنوعی مولد شما فراهم کند.
گزینه 2: برنامه نمونه full-stack را با یک بخش ظاهری Streamlit اجرا کنید
این الگو به شما اجازه می دهد تا راه حل را با رابط کاربری ظاهری برای پرسش و پاسخ مستقر کنید.
پیش نیازها
برای استقرار برنامه نمونه، باید پیش نیازهای زیر را داشته باشید:
- نقطه پایانی مدل SageMaker JumpStart مستقر شد – همانطور که در بخش قبل ذکر شد، با استفاده از نوت بوک های ارائه شده، مدل ها را با استفاده از SageMaker JumpStart در نقاط پایانی بلادرنگ SageMaker خود مستقر کنید.
- منطقه میزبان مسیر 53 آمازون - ایجاد کنید مسیر آمازون 53 منطقه میزبان عمومی برای این محلول استفاده کنید. همچنین میتوانید از یک منطقه میزبان عمومی Route 53 استفاده کنید، مانند
example.com. - گواهی مدیر گواهی AWS - ارائه یک مدیر گواهی AWS گواهی TLS (ACM) برای نام دامنه منطقه میزبان Route 53 و زیر دامنه های قابل اجرا آن، مانند
example.comو*.example.comبرای همه زیر دامنه ها برای دستورالعمل، مراجعه کنید درخواست گواهی عمومی. این گواهی برای پیکربندی HTTPS در استفاده می شود آمازون CloudFront و بار متعادل کننده مبدا. - پارامترهای استقرار - موارد زیر را ثبت کنید:
- نام دامنه سفارشی برنامه Frontend - یک نام دامنه سفارشی که برای دسترسی به برنامه نمونه frontend استفاده می شود. نام دامنه ارائه شده برای ایجاد یک رکورد Route 53 DNS استفاده می شود که به توزیع CloudFront frontend اشاره می کند. مثلا،
app.example.com. - نام دامنه سفارشی مبدا متعادل کننده بار – یک نام دامنه سفارشی که برای مبدأ متعادل کننده بار توزیع CloudFront استفاده می شود. نام دامنه ارائه شده برای ایجاد یک رکورد Route 53 DNS استفاده می شود که به متعادل کننده بار مبدا اشاره می کند. مثلا،
app-lb.example.com. - شناسه منطقه میزبان مسیر 53 – شناسه منطقه میزبان مسیر 53 برای میزبانی نام دامنه سفارشی ارائه شده؛ مثلا،
ZXXXXXXXXYYYYYYYYY. - نام منطقه میزبان مسیر 53 - نام منطقه میزبان مسیر 53 برای میزبانی نام دامنه های سفارشی ارائه شده؛ مثلا،
example.com. - گواهی ACM ARN – ARN گواهی ACM برای استفاده با دامنه سفارشی ارائه شده.
- نام نقطه پایانی مدل متنی – نام نقطه پایانی مدل تولید متن که با SageMaker JumpStart مستقر شده است.
- نام نقطه پایانی مدل جاسازیها - نام نقطه پایانی مدل تعبیه شده با SageMaker JumpStart.
- نام دامنه سفارشی برنامه Frontend - یک نام دامنه سفارشی که برای دسترسی به برنامه نمونه frontend استفاده می شود. نام دامنه ارائه شده برای ایجاد یک رکورد Route 53 DNS استفاده می شود که به توزیع CloudFront frontend اشاره می کند. مثلا،
منابع را با استفاده از AWS CDK مستقر کنید
برای استقرار پشته AWS CDK از پارامترهای استقرار که در پیش نیازها ذکر کردید استفاده کنید. برای اطلاعات بیشتر مراجعه کنید شروع کار با AWS CDK.
مطمئن شوید که Docker روی ایستگاه کاری که برای استقرار AWS CDK استفاده میشود، نصب و اجرا میشود.
در کد قبلی، -c یک مقدار زمینه را در قالب پیش نیازهای مورد نیاز، ارائه شده در ورودی نشان می دهد. همچنین می توانید مقادیر متن را در فایلی به نام وارد کنید cdk.context.json در pattern1-rag/cdk دایرکتوری و اجرا کنید cdk deploy --all.
توجه داشته باشید که در فایل، Region را مشخص می کنیم bin/cdk.ts. پیکربندی گزارشهای دسترسی ALB به یک منطقه مشخص نیاز دارد. شما می توانید این منطقه را قبل از استقرار تغییر دهید.
استقرار URL را برای دسترسی به برنامه Streamlit چاپ می کند. قبل از اینکه بتوانید پرسش و پاسخ را شروع کنید، باید اسناد مرجع را همانطور که در بخش بعدی نشان داده شده است، جاسازی کنید.
اسناد مرجع را جاسازی کنید
برای رویکرد RAG، اسناد مرجع ابتدا با یک مدل جاسازی متن جاسازی شده و در یک پایگاه داده برداری ذخیره می شوند. در این راه حل، یک خط لوله جذب ساخته شده است که اسناد PDF را دریافت می کند.
همانطور که در اولین گزینه استقرار بحث کردیم، یک نمونه EC2 برای انتقال سند PDF ایجاد شده است و یک سیستم فایل EFS برای ذخیره اسناد PDF روی نمونه EC2 نصب شده است. یک کار DataSync هر ساعت اجرا می شود تا اسناد PDF موجود در مسیر سیستم فایل EFS را دریافت کرده و آنها را در یک سطل S3 برای شروع فرآیند جاسازی متن آپلود کند. این فرآیند اسناد مرجع را جاسازی می کند و جاسازی ها را در سرویس OpenSearch ذخیره می کند. همچنین یک آرشیو جاسازی شده را از طریق Kinesis Data Firehose در یک سطل S3 برای تجزیه و تحلیل بعدی ذخیره می کند.
برای دریافت اسناد مرجع، مراحل زیر را انجام دهید:
- نمونه شناسه نمونه EC2 ایجاد شده را بازیابی کنید (خروجی AWS CDK را ببینید
JumpHostId) و با استفاده از Session Manager متصل شوید. - به دایرکتوری بروید
/mnt/efs/fs1که محل نصب فایل سیستم EFS است و پوشه ای به نام ایجاد کنیدingest: - اسناد PDF مرجع خود را به
ingestدایرکتوری.
وظیفه DataSync به گونهای پیکربندی شده است که تمام فایلهای موجود در این فهرست را در Amazon S3 آپلود کند تا فرآیند جاسازی آغاز شود.
وظیفه DataSync بر اساس یک برنامه ساعتی اجرا می شود. شما می توانید به صورت اختیاری کار را به صورت دستی شروع کنید تا فرآیند جاسازی بلافاصله برای اسناد PDF که اضافه کرده اید شروع شود.
- برای شروع کار، شناسه وظیفه را از خروجی AWS CDK پیدا کنید
DataSyncTaskIDو کار را شروع کنید با پیش فرض ها
پرسش و پاسخ
پس از جاسازی اسناد مرجع، می توانید با مراجعه به URL برای دسترسی به برنامه Streamlit، پرسش و پاسخ RAG را شروع کنید. یک Cognito آمازون لایه احراز هویت استفاده می شود، بنابراین نیاز به ایجاد یک حساب کاربری در مجموعه کاربری آمازون Cognito است که از طریق CDK AWS مستقر شده است (خروجی AWS CDK را برای نام استخر کاربر ببینید) برای اولین بار دسترسی به برنامه. برای دستورالعملهای مربوط به ایجاد کاربر آمازون Cognito، مراجعه کنید ایجاد یک کاربر جدید در کنسول مدیریت AWS.
تعبیه تجزیه و تحلیل رانش
در این بخش، ما به شما نشان میدهیم که چگونه با ایجاد یک خط پایه از جاسازیهای دادههای مرجع و تعبیههای سریع، و سپس ایجاد یک عکس فوری از جاسازیها در طول زمان، آنالیز دریفت را انجام دهید. این به شما امکان می دهد جاسازی های پایه را با جاسازی های عکس فوری مقایسه کنید.
یک خط پایه جاسازی برای داده های مرجع و درخواست ایجاد کنید
برای ایجاد خط پایه جاسازی شده از داده های مرجع، کنسول AWS Glue را باز کنید و کار ETL را انتخاب کنید. embedding-drift-analysis. پارامترهای مربوط به کار ETL را به صورت زیر تنظیم کنید و کار را اجرا کنید:
- تنظیم
--job_typeبهBASELINE. - تنظیم
--out_tableبه آمازون DynamoDB جدول برای داده های جاسازی مرجع (خروجی AWS CDK را ببینیدDriftTableReferenceبرای نام جدول.) - تنظیم
--centroid_tableبه جدول DynamoDB برای مرجع داده های centroid. (خروجی AWS CDK را ببینیدCentroidTableReferenceبرای نام جدول.) - تنظیم
--data_pathبه سطل S3 با پیشوند؛ مثلا،s3:///embeddingarchive/. (خروجی AWS CDK را ببینیدBucketNameبرای نام سطل.)
به طور مشابه، با استفاده از کار ETL embedding-drift-analysis، یک خط پایه تعبیه شده از دستورات ایجاد کنید. پارامترهای مربوط به کار ETL را به صورت زیر تنظیم کنید و کار را اجرا کنید:
- تنظیم
--job_typeبهBASELINE - تنظیم
--out_tableبه جدول DynamoDB برای جاسازی سریع داده ها. (خروجی AWS CDK را ببینیدDriftTablePromptsNameبرای نام جدول.) - تنظیم
--centroid_tableبه جدول DynamoDB برای داده های سریع Centroid. (خروجی AWS CDK را ببینیدCentroidTablePromptsبرای نام جدول.) - تنظیم
--data_pathبه سطل S3 با پیشوند؛ مثلا،s3:///promptarchive/. (خروجی AWS CDK را ببینیدBucketNameبرای نام سطل.)
یک عکس فوری جاسازی شده برای داده های مرجع و درخواست ایجاد کنید
بعد از اینکه اطلاعات اضافی را در OpenSearch Service وارد کردید، کار ETL را اجرا کنید embedding-drift-analysis دوباره برای گرفتن عکس از جاسازی های داده مرجع. پارامترها مانند کار ETL خواهند بود که برای ایجاد خط پایه جاسازی داده های مرجع اجرا کردید همانطور که در بخش قبل نشان داده شده است، به استثنای تنظیم --job_type پارامتر به SNAPSHOT.
به طور مشابه، برای گرفتن عکس فوری از تعبیههای سریع، کار ETL را اجرا کنید embedding-drift-analysis از نو. پارامترها مانند کار ETL خواهند بود که برای ایجاد خط پایه جاسازی برای دستورات اجرا کردید، به استثنای تنظیم --job_type پارامتر به SNAPSHOT.
خط مبنا را با عکس فوری مقایسه کنید
برای مقایسه خط مبنا و عکس فوری برای داده های مرجع و درخواست ها، از نوت بوک ارائه شده استفاده کنید. pattern1-rag/notebooks/drift-analysis.ipynb.
برای مشاهده مقایسه جاسازی برای داده های مرجع یا درخواست ها، متغیرهای نام جدول DynamoDB را تغییر دهید (tbl و c_tbl) در نوت بوک به جدول DynamoDB مناسب برای هر اجرا از نوت بوک.
متغیر نوت بوک tbl باید به نام جدول دریفت مناسب تغییر کند. در زیر نمونه ای از محل پیکربندی متغیر در نوت بوک آورده شده است.

نام جدول را می توان به صورت زیر بازیابی کرد:
- برای داده های جاسازی مرجع، نام جدول دریفت را از خروجی AWS CDK بازیابی کنید
DriftTableReference - برای داده های جاسازی سریع، نام جدول دریفت را از خروجی AWS CDK بازیابی کنید.
DriftTablePromptsName
علاوه بر این، متغیر نوت بوک c_tbl باید به نام جدول مرکز مناسب تغییر کند. در زیر نمونه ای از محل پیکربندی متغیر در نوت بوک آورده شده است.

نام جدول را می توان به صورت زیر بازیابی کرد:
- برای داده های جاسازی مرجع، نام جدول مرکز را از خروجی AWS CDK بازیابی کنید
CentroidTableReference - برای داده های جاسازی سریع، نام جدول مرکز را از خروجی AWS CDK بازیابی کنید.
CentroidTablePrompts
فاصله سریع از داده های مرجع را تجزیه و تحلیل کنید
ابتدا کار چسب AWS را اجرا کنید embedding-distance-analysis. این کار از ارزیابی K-Means از جاسازیهای داده مرجع، متوجه میشود که هر درخواست متعلق به کدام خوشه است. سپس میانگین، میانه و انحراف استاندارد فاصله از هر فرمان تا مرکز خوشه مربوطه را محاسبه می کند.
می توانید نوت بوک را اجرا کنید pattern1-rag/notebooks/distance-analysis.ipynb برای مشاهده روند متریک های فاصله در طول زمان. این به شما احساسی از روند کلی در توزیع فواصل جاسازی سریع می دهد.
دفترچه یادداشت pattern1-rag/notebooks/prompt-distance-outliers.ipynb یک نوت بوک AWS Glue است که به دنبال موارد پرت است، که می تواند به شما کمک کند تشخیص دهید که آیا درخواست های بیشتری دریافت می کنید که به داده های مرجع مرتبط نیستند یا خیر.
نمرات شباهت را رصد کنید
همه نمرات شباهت از سرویس OpenSearch وارد سیستم شده اند CloudWatch آمازون تحت rag فضای نام داشبورد RAG_Scores میانگین امتیاز و تعداد کل نمرات دریافت شده را نشان می دهد.
پاک کردن
برای جلوگیری از تحمیل هزینههای آتی، تمام منابعی را که ایجاد کردهاید حذف کنید.
مدل های SageMaker مستقر را حذف کنید
به بخش پاکسازی مراجعه کنید نمونه دفترچه یادداشت ارائه شده است برای حذف مدل های SageMaker JumpStart مستقر شده، یا می توانید مدل های موجود در کنسول SageMaker را حذف کنید.
منابع AWS CDK را حذف کنید
اگر پارامترهای خود را در a وارد کرده باشید cdk.context.json فایل را به صورت زیر پاک کنید:
اگر پارامترهای خود را در خط فرمان وارد کرده اید و فقط برنامه Backend (پشته AWS CDK backend) را اجرا کرده اید، به صورت زیر پاک کنید:
اگر پارامترهای خود را در خط فرمان وارد کرده اید و راه حل کامل را اجرا کرده اید (پشته های AWS CDK frontend و backend)، به صورت زیر پاک کنید:
نتیجه
در این پست، ما یک مثال کاربردی از برنامهای ارائه کردیم که بردارهای تعبیهشده را هم برای دادههای مرجع و هم برای اعلانهای الگوی RAG برای هوش مصنوعی مولد ضبط میکند. ما نشان دادیم که چگونه تجزیه و تحلیل خوشهبندی را برای تعیین اینکه آیا دادههای مرجع یا سریع در طول زمان جابجا میشوند و اینکه دادههای مرجع تا چه حد انواع سؤالاتی را که کاربران میپرسند را پوشش میدهند، انجام دهیم. اگر دریفت را تشخیص دهید، میتواند سیگنالی را ارائه دهد که محیط تغییر کرده و مدل شما ورودیهای جدیدی دریافت میکند که ممکن است برای مدیریت آن بهینهسازی نشده باشد. این امکان ارزیابی پیشگیرانه مدل فعلی را در مقابل تغییر ورودی ها فراهم می کند.
درباره نویسنده
 عبدالله اولائی یک معمار ارشد راه حل در خدمات وب آمازون (AWS) است. عبداللهی دارای مدرک MSC در شبکه های کامپیوتری از دانشگاه ایالتی ویچیتا است و نویسنده منتشر شده ای است که در حوزه های مختلف فناوری مانند DevOps، نوسازی زیرساخت و هوش مصنوعی نقش داشته است. او در حال حاضر روی هوش مصنوعی مولد متمرکز است و نقشی کلیدی در کمک به شرکتها برای معمار و ساخت راهحلهای پیشرفته با استفاده از هوش مصنوعی مولد ایفا میکند. فراتر از قلمرو فناوری، او در هنر کاوش لذت می برد. وقتی راهحلهای هوش مصنوعی نمیسازد، از سفر با خانوادهاش برای کشف مکانهای جدید لذت میبرد.
عبدالله اولائی یک معمار ارشد راه حل در خدمات وب آمازون (AWS) است. عبداللهی دارای مدرک MSC در شبکه های کامپیوتری از دانشگاه ایالتی ویچیتا است و نویسنده منتشر شده ای است که در حوزه های مختلف فناوری مانند DevOps، نوسازی زیرساخت و هوش مصنوعی نقش داشته است. او در حال حاضر روی هوش مصنوعی مولد متمرکز است و نقشی کلیدی در کمک به شرکتها برای معمار و ساخت راهحلهای پیشرفته با استفاده از هوش مصنوعی مولد ایفا میکند. فراتر از قلمرو فناوری، او در هنر کاوش لذت می برد. وقتی راهحلهای هوش مصنوعی نمیسازد، از سفر با خانوادهاش برای کشف مکانهای جدید لذت میبرد.
 رندی دیفاو یک معمار ارشد راه حل در AWS است. او دارای مدرک MSEE از دانشگاه میشیگان است، جایی که روی بینایی کامپیوتری برای وسایل نقلیه خودران کار می کرد. او همچنین دارای مدرک MBA از دانشگاه ایالتی کلرادو است. رندی موقعیت های مختلفی را در فضای فناوری از مهندسی نرم افزار گرفته تا مدیریت محصول داشته است. In در سال 2013 وارد فضای Big Data شد و به کاوش در آن منطقه ادامه می دهد. او به طور فعال روی پروژه هایی در فضای ML کار می کند و در کنفرانس های متعددی از جمله Strata و GlueCon ارائه کرده است.
رندی دیفاو یک معمار ارشد راه حل در AWS است. او دارای مدرک MSEE از دانشگاه میشیگان است، جایی که روی بینایی کامپیوتری برای وسایل نقلیه خودران کار می کرد. او همچنین دارای مدرک MBA از دانشگاه ایالتی کلرادو است. رندی موقعیت های مختلفی را در فضای فناوری از مهندسی نرم افزار گرفته تا مدیریت محصول داشته است. In در سال 2013 وارد فضای Big Data شد و به کاوش در آن منطقه ادامه می دهد. او به طور فعال روی پروژه هایی در فضای ML کار می کند و در کنفرانس های متعددی از جمله Strata و GlueCon ارائه کرده است.
 شلبی ایگنبرود یک معمار اصلی راه حل های تخصصی هوش مصنوعی و یادگیری ماشین در خدمات وب آمازون (AWS) است. او 24 سال است که در زمینه فناوری فعالیت می کند و صنایع، فناوری ها و نقش های متعددی را در بر می گیرد. او در حال حاضر بر ترکیب پیشینه DevOps و ML خود در حوزه MLOps تمرکز دارد تا به مشتریان در ارائه و مدیریت حجم کاری ML در مقیاس کمک کند. با بیش از 35 پتنت اعطا شده در حوزه های مختلف فناوری، او اشتیاق به نوآوری مداوم و استفاده از داده ها برای هدایت نتایج کسب و کار دارد. Shelbee یکی از خالقان و مربیان تخصص عملی علم داده در Coursera است. او همچنین مدیر مشترک زنان در داده های بزرگ (WiBD)، بخش دنور است. او در اوقات فراغت خود دوست دارد با خانواده، دوستان و سگ های پرکارش وقت بگذراند.
شلبی ایگنبرود یک معمار اصلی راه حل های تخصصی هوش مصنوعی و یادگیری ماشین در خدمات وب آمازون (AWS) است. او 24 سال است که در زمینه فناوری فعالیت می کند و صنایع، فناوری ها و نقش های متعددی را در بر می گیرد. او در حال حاضر بر ترکیب پیشینه DevOps و ML خود در حوزه MLOps تمرکز دارد تا به مشتریان در ارائه و مدیریت حجم کاری ML در مقیاس کمک کند. با بیش از 35 پتنت اعطا شده در حوزه های مختلف فناوری، او اشتیاق به نوآوری مداوم و استفاده از داده ها برای هدایت نتایج کسب و کار دارد. Shelbee یکی از خالقان و مربیان تخصص عملی علم داده در Coursera است. او همچنین مدیر مشترک زنان در داده های بزرگ (WiBD)، بخش دنور است. او در اوقات فراغت خود دوست دارد با خانواده، دوستان و سگ های پرکارش وقت بگذراند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/monitor-embedding-drift-for-llms-deployed-from-amazon-sagemaker-jumpstart/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 10
- 100
- 2%
- 2013
- 24
- ٪۱۰۰
- 39
- 4
- 53
- 62
- 7
- 9
- 90
- ٪۱۰۰
- a
- قادر
- درباره ما
- مطلق
- دسترسی
- حساب
- ACM
- در میان
- فعالانه
- اضافه
- اضافه
- اضافی
- اطلاعات اضافی
- علاوه بر این
- از نو
- در برابر
- تجمیع
- AI
- تراز می کند
- معرفی
- اجازه دادن
- اجازه می دهد تا
- همچنین
- هر چند
- آمازون
- Cognito آمازون
- آمازون EC2
- آمازون SageMaker
- Amazon SageMaker JumpStart
- آمازون خدمات وب
- خدمات وب آمازون (AWS)
- an
- تحلیل
- تحلیل
- تجزیه و تحلیل
- و
- پاسخ
- پاسخ دادن
- هر چیزی
- مربوط
- کاربرد
- روش
- مناسب
- معماری
- بایگانی
- هستند
- محدوده
- مناطق
- هنر
- مقالات
- AS
- پرسیدن
- خواهان
- کمک کردن
- فرض
- At
- تقویت کردن
- افزوده شده
- تصدیق
- نویسنده
- بطور خودکار
- خود مختار
- خودروهای خودمختار
- در دسترس
- میانگین
- اجتناب از
- دور
- AWS
- چسب AWS
- بخش مدیریت
- زمینه
- متعادل کننده
- مستقر
- خط مقدم
- BE
- زیرا
- بوده
- قبل از
- بودن
- متعلق
- بهتر
- میان
- خارج از
- بزرگ
- بزرگ داده
- بدن
- هر دو
- گسترده
- ساختن
- ساخته
- کسب و کار
- by
- محاسبه
- محاسبه می کند
- صدا
- نام
- CAN
- قابلیت
- گرفتن
- اسیر
- جلب
- ضبط
- مورد
- CD
- مرکز
- مراکز
- گواهی نامه
- تغییر دادن
- تغییر
- تبادل
- متغیر
- فصل
- بار
- تراشه
- شکلات
- را انتخاب کنید
- تمیز
- نزدیک
- نزدیک
- ابر
- خوشه
- خوشه بندی
- رمز
- کلرادو
- ترکیب
- ترکیب شده
- ترکیب
- آینده
- جمع و جور
- مقايسه كردن
- مقایسه
- مقایسه
- کامل
- جزء
- اجزاء
- محاسبه
- کامپیوتر
- چشم انداز کامپیوتر
- مفاهیم
- همایش ها
- پیکربندی
- پیکربندی
- اتصال
- ملاحظات
- ثبات
- کنسول
- ظرف
- محتوا
- زمینه
- ادامه
- مداوم
- مبدل
- بیسکویت ها
- هسته
- متناظر
- Coursera
- پوشش
- پوشش داده شده
- پوشش
- را پوشش می دهد
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- جاری
- در حال حاضر
- سفارشی
- مشتریان
- لبه برش
- داشبورد
- داده ها
- مرکز دادهها
- پردازش داده ها
- علم اطلاعات
- پایگاه داده
- کاهش
- پیش فرض
- مشخص
- حذف کردن
- ارائه
- دنور
- گسترش
- مستقر
- استقرار
- گسترش
- مستقر می کند
- نشات گرفته
- از بین بردن
- دقیق
- تشخیص
- کشف
- مشخص کردن
- پروژه
- انحراف
- DevOps
- نمودار
- مختلف
- مشکل
- بعد
- ابعاد
- بحث کردیم
- پراکنده
- فاصله
- دور
- توزیع
- دی ان اس
- do
- کارگر بارانداز
- سند
- اسناد و مدارک
- سگ
- دامنه
- نام دامنه
- نام های دامنه
- حوزه
- آیا
- پایین
- راندن
- هر
- جاسازی کردن
- جاسازی شده
- تعبیه کردن
- پایان
- پشت سر هم
- نقطه پایانی
- نقاط پایان
- مهندسی
- وارد
- وارد
- شرکت
- محیط
- اتر (ETH)
- ارزیابی
- ارزیابی
- هر
- مثال
- مثال ها
- استثنا
- موجود
- تجربی
- توضیح دهید
- اکتشاف
- اکتشاف
- بررسی
- خارجی
- عصاره
- عصاره ها
- خانواده
- بسیار
- شکل
- پرونده
- فایل ها
- نهایی
- سرانجام
- پیدا کردن
- پیدا می کند
- نام خانوادگی
- شناور
- جریان
- متمرکز شده است
- تمرکز
- پیروی
- به دنبال آن است
- برای
- فرم
- یافت
- پایه
- دوستان
- از جانب
- ظاهر
- کامل
- آینده
- جمع آوری
- سوالات عمومی
- مولد
- نسل
- مولد
- هوش مصنوعی مولد
- مدل مولد
- دریافت کنید
- گرفتن
- دادن
- Go
- رفته
- اعطا شده
- گروه
- راهنمایی
- دسته
- آیا
- he
- برگزار شد
- کمک
- او
- بالاتر
- خود را
- دارای
- میزبان
- میزبانی
- ساعت
- چگونه
- چگونه
- اما
- HTML
- HTTP
- HTTPS
- قطب
- ID
- شناسایی
- if
- نشان می دهد
- بلافاصله
- پیاده سازی
- پیاده سازی می کند
- مهم
- in
- شامل
- شامل
- از جمله
- وارد شونده
- نشان دادن
- نشان دادن
- لوازم
- اینرسی
- اطلاعات
- شالوده
- اول
- ابداع
- ورودی
- ورودی
- بینش
- نصب و راه اندازی
- نمونه
- دستورالعمل
- تعامل
- تعامل
- تعاملی
- علاقه مند
- رابط
- به
- IT
- ITS
- کار
- شغل ها
- لذت
- JPG
- نوت بوک ژوپیتر
- تنها
- کلید
- کینسیس دیتا فایرهوز
- دانش
- زبان
- بزرگ
- بعد
- آخرین
- لایه
- یاد گرفتن
- یادگیری
- اجازه می دهد تا
- کتابخانه
- دوست دارد
- لاین
- لینوکس
- llm
- بار
- محل
- سیستم وارد
- نگاه کنيد
- مطالب
- کاهش
- دستگاه
- فراگیری ماشین
- ساخت
- مدیریت
- مدیریت
- مدیر
- دستی
- ممکن است..
- MBA
- متوسط
- به معنی
- اندازه
- معیارهای
- متریک
- میشیگان
- قدرت
- ML
- MLO ها
- مدل
- مدل
- نوسازی
- مانیتور
- بیش
- اکثر
- متحرک
- چندگانه
- باید
- نام
- نام
- طبیعی
- زبان طبیعی
- پردازش زبان طبیعی
- نیاز
- ضروری
- نیازمند
- شبکه
- جدید
- جدیدتر
- بعد
- nlp
- دفتر یادداشت
- نوت بوک
- اشاره کرد
- عدد
- تعداد
- متعدد
- of
- غالبا
- on
- فقط
- باز کن
- بهینه
- گزینه
- or
- تنظیم و ارکستراسیون
- سفارش
- منشاء
- دیگر
- ما
- خارج
- نتایج
- مشخص شده
- تولید
- خروجی
- روی
- به طور کلی
- همپوشانی
- خود
- پارامتر
- پارامترهای
- ویژه
- شور
- اختراعات
- مسیر
- الگو
- الگوهای
- انجام دادن
- انجام
- قطعات
- خط لوله
- اماکن
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقش
- نقطه
- نقطه
- استخر
- موقعیت
- ممکن
- پست
- پتانسیل
- صفحه اصلی
- عملی
- ماقبل
- پیش نیازها
- ارائه شده
- حفظ می کند
- حفظ کردن
- قبلی
- قبلا
- اصلی
- چاپ
- بلادرنگ
- روند
- در حال پردازش
- محصول
- مدیریت تولید
- پروژه ها
- پرسیدن
- نسبت
- ارائه
- ارائه
- فراهم می کند
- تدارک
- عمومی
- منتشر شده
- کشد
- سوال
- سوالات
- پارچه
- محدوده ها
- اعم
- اماده
- زمان واقعی
- قلمرو
- دستور العمل
- رکورد
- كاهش دادن
- کاهش
- مراجعه
- مرجع
- منطقه
- مربوط
- نسبتا
- مربوط
- نشان دادن
- نمایندگی
- نشان دهنده
- ضروری
- نیاز
- منابع
- پاسخ
- نتایج
- بازیابی
- نقش
- نقش
- مسیر
- دویدن
- در حال اجرا
- اجرا می شود
- حکیم ساز
- همان
- ذخیره
- مقیاس
- برنامه
- علم
- نمره
- نمرات
- جستجو
- جستجو
- دوم
- بخش
- بخش
- دیدن
- مشاهده گردید
- را انتخاب کنید
- معنایی
- ارشد
- حس
- فرستاده
- جداگانه
- سرویس
- خدمات
- جلسه
- تنظیم
- محیط
- چند
- او
- باید
- نشان
- نشان داد
- نشان داده شده
- نشان می دهد
- سیگنال
- سیگنال
- مشابه
- ساده
- ساده کردن
- اندازه
- عکس فوری
- So
- نرم افزار
- مهندسی نرم افزار
- راه حل
- مزایا
- برخی از
- منبع
- منابع
- فضا
- تنش
- متخصص
- مشخص شده
- خرج کردن
- مربع
- پشته
- پشته
- استاندارد
- شروع
- آغاز شده
- راه افتادن
- دولت
- ارقام
- مراحل
- ذخیره سازی
- opbevare
- ذخیره شده
- موفق
- چنین
- مجموع
- مطمئن
- سیستم
- سیستم های
- جدول
- گرفتن
- کار
- تکنیک
- فن آوری
- پیشرفته
- متن
- تولید متن
- که
- La
- اطلاعات
- منبع
- شان
- آنها
- سپس
- آنجا.
- اینها
- این
- کسانی که
- سه
- از طریق
- زمان
- TLS
- به
- با هم
- تاپیک
- جمع
- دگرگون کردن
- سفر
- روند
- روند
- تلاش می کند
- امتحان
- دو
- انواع
- زیر
- دانشگاه
- دانشگاه میشیگان
- URL
- us
- استفاده کنید
- استفاده
- مفید
- کاربر
- رابط کاربری
- کاربران
- با استفاده از
- اعتبار سنجی
- ارزش
- ارزشها
- متغیر
- متغیرها
- تنوع
- مختلف
- بردار
- بردار
- وسایل نقلیه
- از طريق
- دید
- بصری
- خرید
- می خواهم
- بود
- مسیر..
- we
- وب
- خدمات وب
- خوب
- چه زمانی
- چه
- که
- در حین
- اراده
- با
- در داخل
- بدون
- زنان
- مهاجرت کاری
- مشغول به کار
- کارگر
- ایستگاه های کاری
- بدتر
- خواهد بود
- سال
- هنوز
- شما
- شما
- زفیرنت
- منطقه