امروز، ما در حال ارائه یک قابلیت جدید از چسب AWS کاتالوگ داده ها که امکان تولید آمار در سطح ستون برای جداول AWS Glue را فراهم می کند. این آمار اکنون با بهینه سازهای مبتنی بر هزینه (CBO) یکپارچه شده است آمازون آتنا و آمازون طیف انتقال به قرمز، منجر به بهبود عملکرد پرس و جو و صرفه جویی در هزینه بالقوه می شود.
دریاچه های داده برای ذخیره مقادیر زیادی از داده های خام، بدون ساختار یا نیمه ساختار یافته با هزینه کم طراحی شده اند و سازمان ها این مجموعه داده ها را در چندین بخش و تیم به اشتراک می گذارند. پرس و جوهای موجود در این مجموعه دادههای بزرگ، حجم وسیعی از دادهها را میخوانند و میتوانند عملیات اتصال پیچیده را روی مجموعههای داده متعدد انجام دهند. هنگام صحبت با مشتریانمان، متوجه شدیم که یکی از جنبه های چالش برانگیز عملکرد دریاچه داده این است که چگونه این پرس و جوهای تحلیلی را برای اجرای سریعتر بهینه کنیم.
بهینهسازی عملکرد دریاچه داده بهویژه برای پرسوجوهایی با اتصالهای متعدد مهم است و اینجاست که بهینهسازهای مبتنی بر هزینه بیشترین کمک را میکنند. برای اینکه CBO کار کند، آمار ستون باید بر اساس تغییرات داده ها جمع آوری و به روز شود. ما در حال راه اندازی قابلیت تولید آمار در سطح ستون مانند تعداد متمایز، تعداد تهی، حداکثر و حداقل در فایل هایی مانند پارکت، ORC، JSON، Amazon ION، CSV، XML در جداول چسب AWS هستیم. با این راهاندازی، مشتریان اکنون تجربه یکپارچهای دارند که در آن آمار جداول چسب جمعآوری و در کاتالوگ چسب AWS ذخیره میشود و برای برنامهریزی و اجرای پرس و جو بهبود یافته در دسترس خدمات تحلیلی قرار میگیرد.
با استفاده از این آمار، بهینه سازهای مبتنی بر هزینه، طرح های اجرای پرس و جو را بهبود می بخشند و عملکرد پرس و جوهای اجرا شده در Amazon Athena و Amazon Redshift Spectrum را افزایش می دهند. به عنوان مثال، CBO می تواند از آمار ستونی مانند تعداد مقادیر متمایز و تعداد تهی برای بهبود پیش بینی ردیف استفاده کند. پیشبینی ردیف تعداد ردیفهایی از یک جدول است که در مرحله برنامهریزی پرس و جو با یک مرحله مشخص بازگردانده میشود. هرچه پیشبینیهای ردیف دقیقتر باشد، مراحل اجرای پرس و جو کارآمدتر است. این منجر به اجرای سریعتر پرس و جو و کاهش بالقوه هزینه می شود. برخی از بهینهسازیهای خاصی که CBO میتواند به کار گیرد، شامل مرتبسازی مجدد پیوستن و کاهش تجمعات بر اساس آمار موجود برای هر جدول و ستون است.
برای مشتریان با استفاده از مش داده با سازند دریاچه AWS مجوزها، جداول از تولیدکنندگان مختلف داده در حسابهای حاکمیت متمرکز فهرستبندی میشوند. از آنجایی که آنها آمار جداول موجود در کاتالوگ متمرکز را تولید می کنند و آن جداول را با مصرف کنندگان به اشتراک می گذارند، پرس و جوهای موجود در آن جداول در حساب های مصرف کننده به طور خودکار شاهد بهبود عملکرد پرس و جو خواهند بود. در این پست، ما توانایی AWS Glue Data Catalog برای تولید آمار ستونی برای جداول نمونه خود را نشان خواهیم داد.
بررسی اجمالی راه حل
برای نشان دادن اثربخشی این قابلیت، ما از مجموعه داده استاندارد صنعتی TPC-DS 3 TB ذخیره شده در یک سرویس ذخیره سازی ساده آمازون استفاده می کنیم.آمازون S3) سطل عمومی. ما عملکرد پرس و جو را قبل و بعد از ایجاد آمار ستونی برای جداول با اجرای پرس و جوها در Amazon Athena و Amazon Redshift Spectrum مقایسه می کنیم. ما در حال ارائه پرس و جوهایی هستیم که در این پست از آنها استفاده کرده ایم و تشویق می کنیم پرس و جوهای خود را پس از گردش کار همانطور که در جزئیات زیر نشان داده شده است امتحان کنید.
گردش کار شامل مراحل سطح بالا زیر است:
- فهرست بندی سطل آمازون S3: از AWS Glue Crawler برای خزیدن در سطل تعیین شده Amazon S3، استخراج ابرداده و ذخیره یکپارچه آن در کاتالوگ داده AWS Glue استفاده کنید. ما این جداول را با استفاده از Amazon Athena و Amazon Redshift Spectrum پرس و جو خواهیم کرد.
- ایجاد آمار ستونی: از قابلیتهای پیشرفته کاتالوگ داده چسب AWS برای تولید آمار ستونی جامع برای دادههای خزیده شده استفاده کنید و در نتیجه بینشهای ارزشمندی را در مورد مجموعه دادهها ارائه دهید.
- پرس و جو با آمازون آتنا و آمازون Redshift Spectrum: با استفاده از Amazon Athena و Amazon Redshift Spectrum برای اجرای پرسوجوها بر روی مجموعه داده، تأثیر آمار ستونها را بر عملکرد پرسوجو ارزیابی کنید.
نمودار زیر معماری راه حل را نشان می دهد.
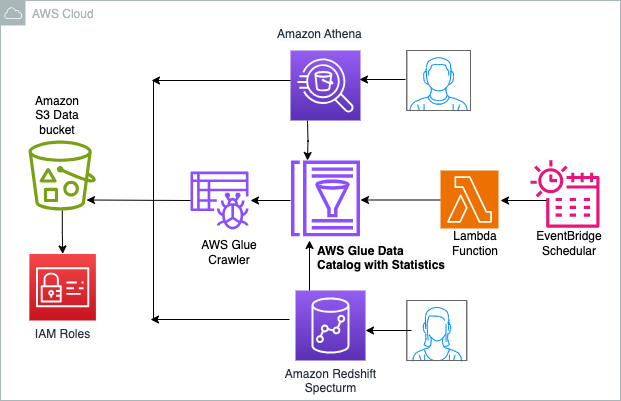
خرید
برای پیاده سازی راه حل، مراحل زیر را انجام می دهیم:
- راه اندازی منابع با AWS CloudFormation.
- AWS Glue Crawler را روی سطل Public Amazon S3 اجرا کنید تا مجموعه داده TPC-DS 3TB را فهرست کنید.
- پرس و جوها را در Amazon Athena و Amazon Redshift اجرا کنید و مدت زمان درخواست را یادداشت کنید
- ایجاد آمار برای جداول AWS Glue Data Catalog
- پرس و جوها را در Amazon Athena و Amazon Redshift اجرا کنید و مدت زمان درخواست را با اجرای قبلی مقایسه کنید
- اختیاری: کارهای آمار ستون AWS Glue را با استفاده از AWS Lambda و Amazon EventBridge Scheduler برنامه ریزی کنید
منابع را با AWS CloudFormation تنظیم کنید
این پست شامل یک AWS CloudFormation قالب برای راه اندازی سریع شما می توانید آن را مطابق با نیاز خود بررسی و سفارشی کنید. الگو منابع زیر را تولید می کند:
- یک ابر خصوصی مجازی آمازون (آمازون VPC، زیرشبکه عمومی، زیرشبکه های خصوصی و جداول مسیر.
- یک گروه کاری و فضای نام بدون سرور Amazon Redshift.
- یک خزنده چسب AWS برای خزیدن در سطل عمومی Amazon S3 و ایجاد جدولی برای کاتالوگ داده های چسب برای مجموعه داده TPC-DS
- پایگاه داده ها و جداول کاتالوگ AWS Glue
- یک سطل آمازون S3 برای ذخیره نتیجه آتنا.
- هویت AWS و مدیریت دسترسی کاربران و خطمشیهای (AWS IAM).
- برنامهریزی AWS Lambda و Amazon Event Bridge برای زمانبندی آمار ستون چسب AWS
برای راه اندازی پشته AWS CloudFormation، مراحل زیر را انجام دهید:
توجه داشته باشید: جداول کاتالوگ داده AWS Glue با استفاده از سطل عمومی تولید می شوند s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/، میزبانی شده در us-east-1 منطقه اگر قصد دارید این الگوی AWS CloudFormation را در منطقه دیگری استقرار دهید، لازم است داده ها را در منطقه مربوطه کپی کنید یا داده ها را در منطقه مستقر خود به اشتراک بگذارید تا از Amazon Redshift قابل دسترسی باشد.
- وارد شوید کنسول مدیریت AWS به عنوان AWS Identity and Access Management (AWS IAM) مدیر
- برای استقرار یک الگوی AWS CloudFormation، Launch Stack را انتخاب کنید.

- را انتخاب کنید بعدی.
- در صفحه بعد، تمام گزینه ها را به عنوان پیش فرض نگه دارید یا تغییرات مناسب را بر اساس نیاز خود انتخاب کنید بعدی.
- جزئیات صفحه آخر را بررسی کرده و انتخاب کنید من تصدیق می کنم که AWS CloudFormation ممکن است منابع IAM را ایجاد کند.
- را انتخاب کنید ساختن.
تکمیل این پشته ممکن است حدود 10 دقیقه طول بکشد، پس از آن می توانید پشته مستقر شده را در کنسول AWS CloudFormation مشاهده کنید.
AWS Glue Crawlers ایجاد شده توسط پشته AWS CloudFormation را اجرا کنید
برای اجرای خزندهها، مراحل زیر را انجام دهید:
- روی کنسول AWS Glue to کنسول چسب AWS، خزنده ها را در زیر کاتالوگ داده در صفحه پیمایش انتخاب کنید.
- دو خزنده را پیدا کرده و اجرا کنید
tpcdsdb-without-statsوtpcdsdb-with-stats. ممکن است چند دقیقه طول بکشد تا تکمیل شود.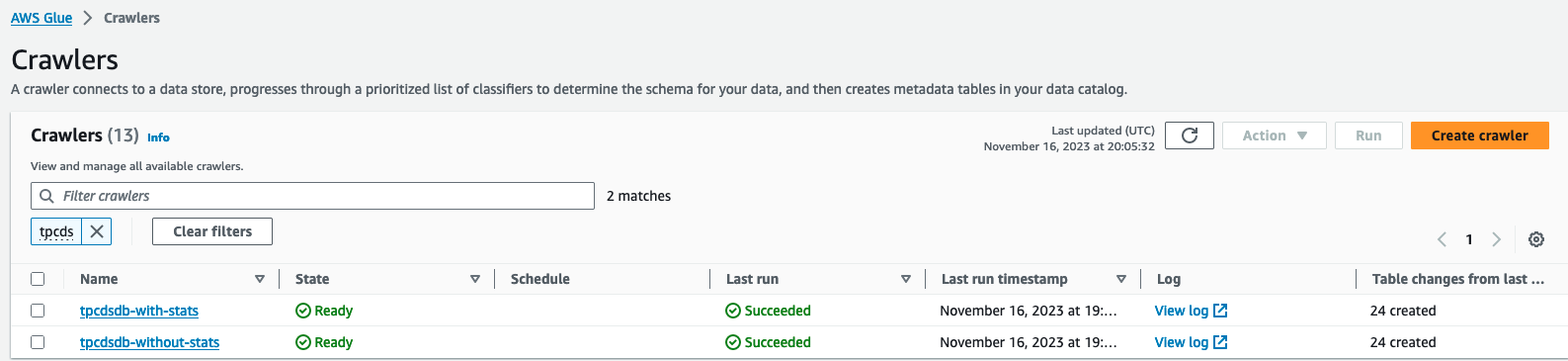
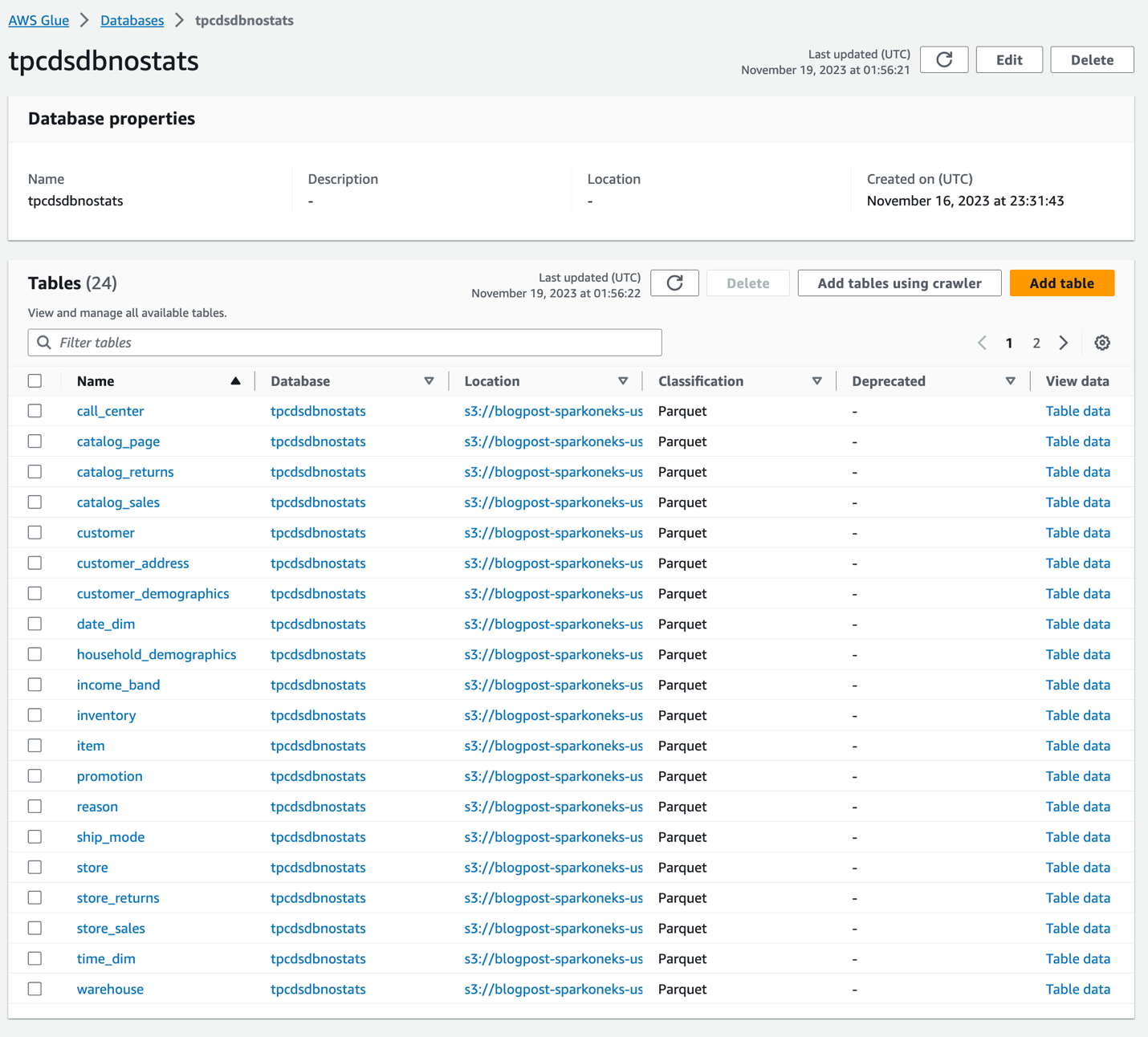
هنگامی که خزنده با موفقیت کامل شد، دو پایگاه داده یکسان ایجاد می کند tpcdsdbnostats و tpcdsdbwithstats. جداول در tpcdsdbnostats هیچ آماری نخواهد داشت و ما از آنها به عنوان مرجع استفاده خواهیم کرد. ما آمار را بر روی جداول در تولید می کنیم tpcdsdbwithstats. لطفاً بررسی کنید که آن دو پایگاه داده و جداول زیرین را از کنسول چسب AWS دارید. پایگاه داده tpcdsdbnostats مانند زیر خواهد بود. در حال حاضر هیچ آماری روی این جداول ایجاد نشده است.
پرس و جو ارائه شده را با استفاده از آمازون آتنا در جداول بدون آمار اجرا کنید
برای اجرای درخواست خود در آمازون آتنا بر روی جداول بدون آمار، مراحل زیر را انجام دهید:
- سوالات آتنا را دانلود کنید اینجا.
- در آمازون کنسول آتنا، پرس و جو ارائه شده را یکی یکی برای جداول در پایگاه داده انتخاب کنید
tpcdsdbnostats. - پرس و جو را اجرا کنید و آن را یادداشت کنید زمان اجرا برای هر پرس و جو

پرس و جو ارائه شده را با استفاده از آمازون Redshift Spectrum در جداول بدون آمار اجرا کنید
برای اجرای درخواست خود در Amazon Redshift، مراحل زیر را انجام دهید:
- درخواست های Amazon Redshift را از اینجا دانلود کنید اینجا کلیک نمایید.
- بر ویرایشگر کوئری Redshift v2، اجرا کنید درخواست Redshift برای جداول بدون آمار بخش از پرس و جو دانلود شده
- پرس و جو را اجرا کنید و اجرای پرس و جو هر پرس و جو را یادداشت کنید.
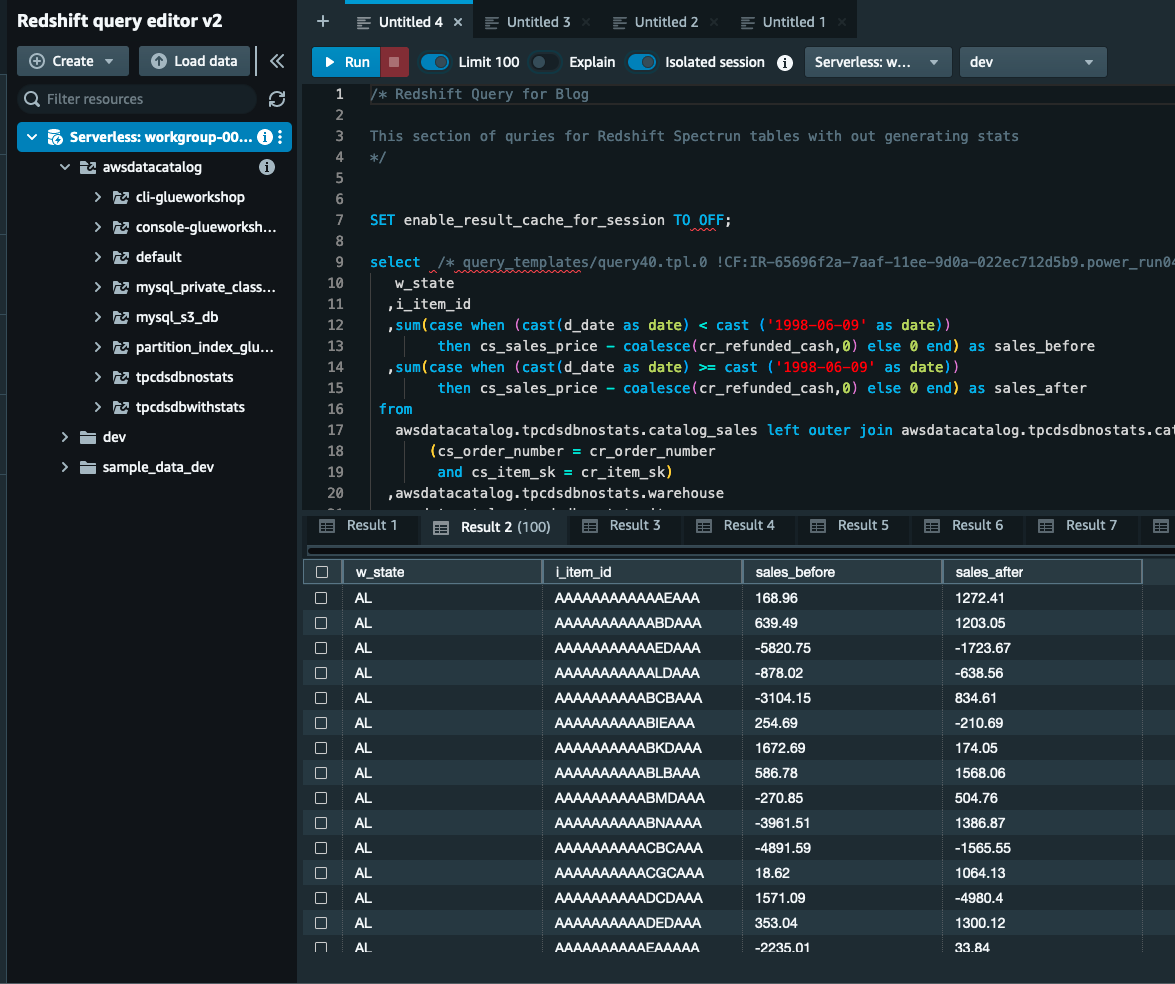
ایجاد آمار در جداول AWS Glue Catalog
برای ایجاد آمار در جداول AWS Glue Catalog مراحل زیر را انجام دهید:
- حرکت به کنسول چسب AWS و پایگاه داده های زیر را انتخاب کنید کاتالوگ داده ها
- با کلیک بر روی
tpcdsdbwithstatsپایگاه داده و تمام جداول موجود را فهرست می کند. - یکی از این جداول را انتخاب کنید (مثلا
call_center). - رفتن به آمار ستون - جدید برگه را انتخاب کنید و انتخاب کنید آمار تولید کنید.
- گزینه پیش فرض را نگه دارید. زیر ستون ها را انتخاب کنید نگه داشتن جدول (همه ستون ها) و زیر گزینه های نمونه برداری ردیف نگاه داشتن همه ردیف ها، زیر IAM انتخاب نقش وبلاگ AWSGluestats را انتخاب کنید و آمار تولید کنید.
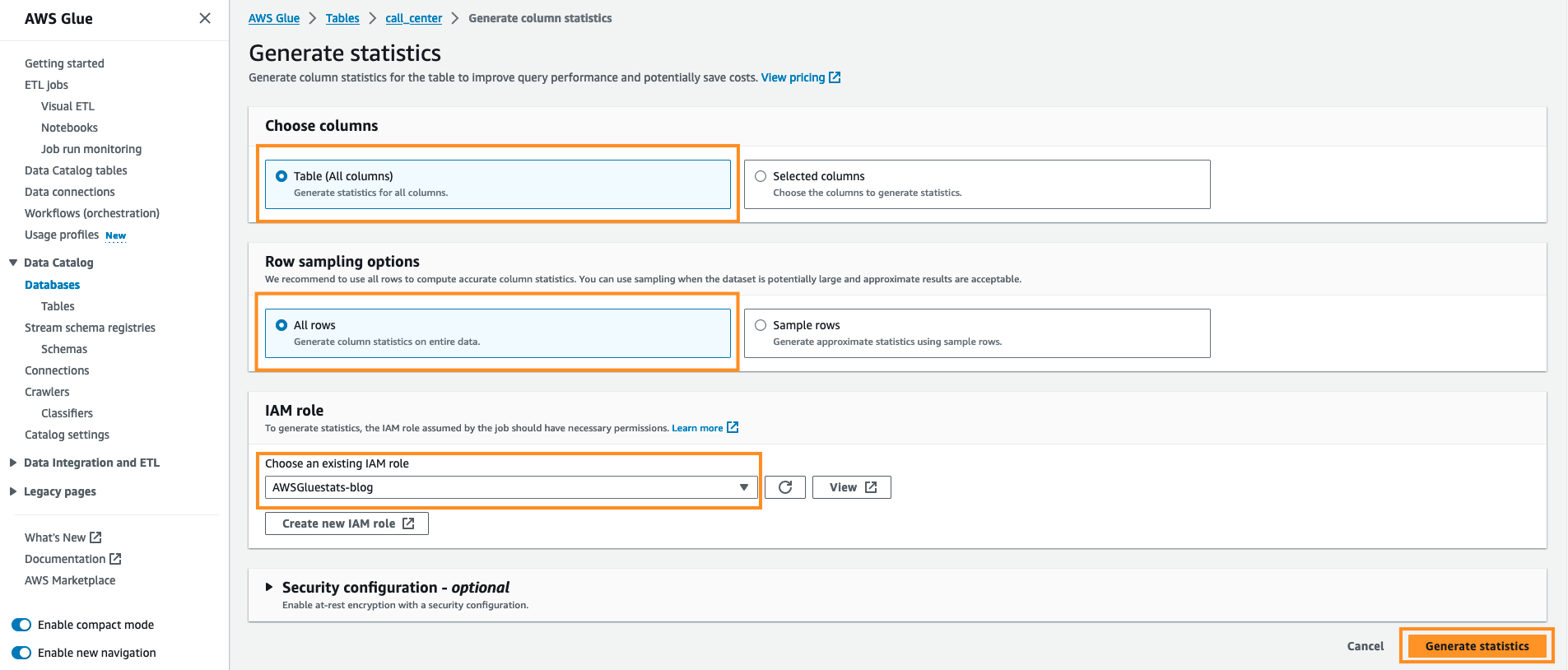
شما می توانید وضعیت تولید آمار را همانطور که در تصویر زیر نشان داده شده است مشاهده کنید:

پس از ایجاد آمار در جداول AWS Glue Catalog، باید بتوانید آمار ستون های مفصل را برای آن جدول مشاهده کنید:
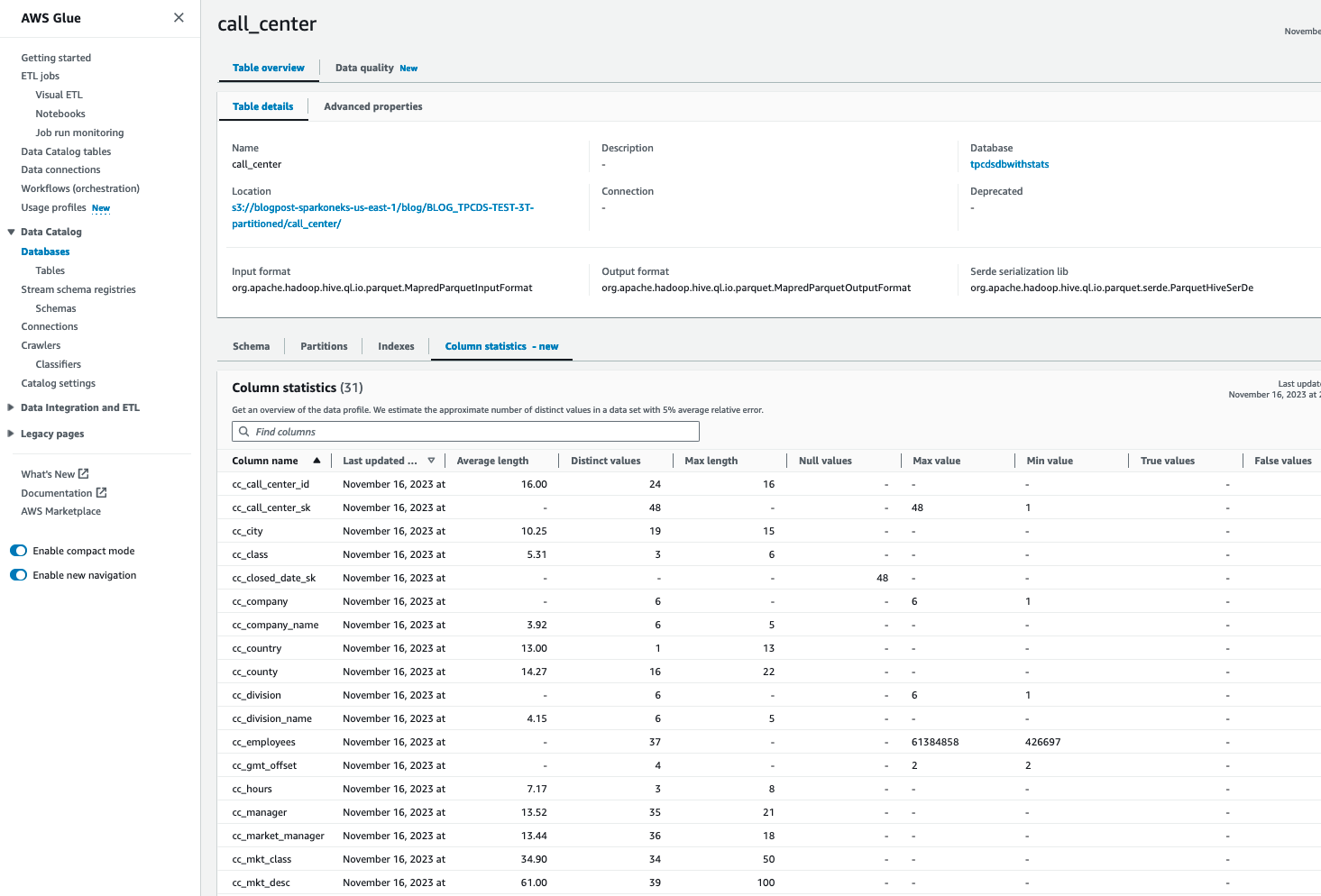
مراحل 2 تا 5 را برای ایجاد آمار برای همه جداول ضروری تکرار کنید catalog_sales, catalog_returns, warehouse, item, date_dim, store_sales, customer, customer_address, web_sales, time_dim, ship_mode, web_site, web_returns. از طرف دیگر، میتوانید «اجرای آمار چسب AWS را برنامه ریزی کنیدبخش ” نزدیک انتهای این وبلاگ برای تولید آمار برای همه جداول. پس از انجام، عملکرد پرس و جو را برای هر پرس و جو ارزیابی کنید.
پرس و جو ارائه شده را با استفاده از کنسول آتنا روی جداول آمار اجرا کنید
- در آمازون کنسول آتنا، اجرا کنید پرس و جوی آتنا برای جداول با آمار بخش از پرس و جو دانلود شده
- اجرای کوئری هر کوئری را اجرا کرده و یادداشت کنید.
در اجرای نمونه پرس و جوهای روی جداول، زمان اجرای پرس و جو را مطابق جدول زیر مشاهده کردیم. ما شاهد بهبود واضحی در عملکرد پرس و جو، از 13 تا 55 درصد بودیم.
بهبود زمان پرس و جو آتنا
| پرس و جوهای TPC-DS 3T | بدون آمار چسب (ثانیه) | با آمار چسب (ثانیه) | ارتقای کارایی (٪) |
| پرس و جو 2 | 33.62 | 15.17 | ٪۱۰۰ |
| پرس و جو 4 | 132.11 | 72.94 | ٪۱۰۰ |
| پرس و جو 14 | 134.77 | 91.48 | ٪۱۰۰ |
| پرس و جو 28 | 55.99 | 39.36 | ٪۱۰۰ |
| پرس و جو 38 | 29.32 | 25.58 | ٪۱۰۰ |
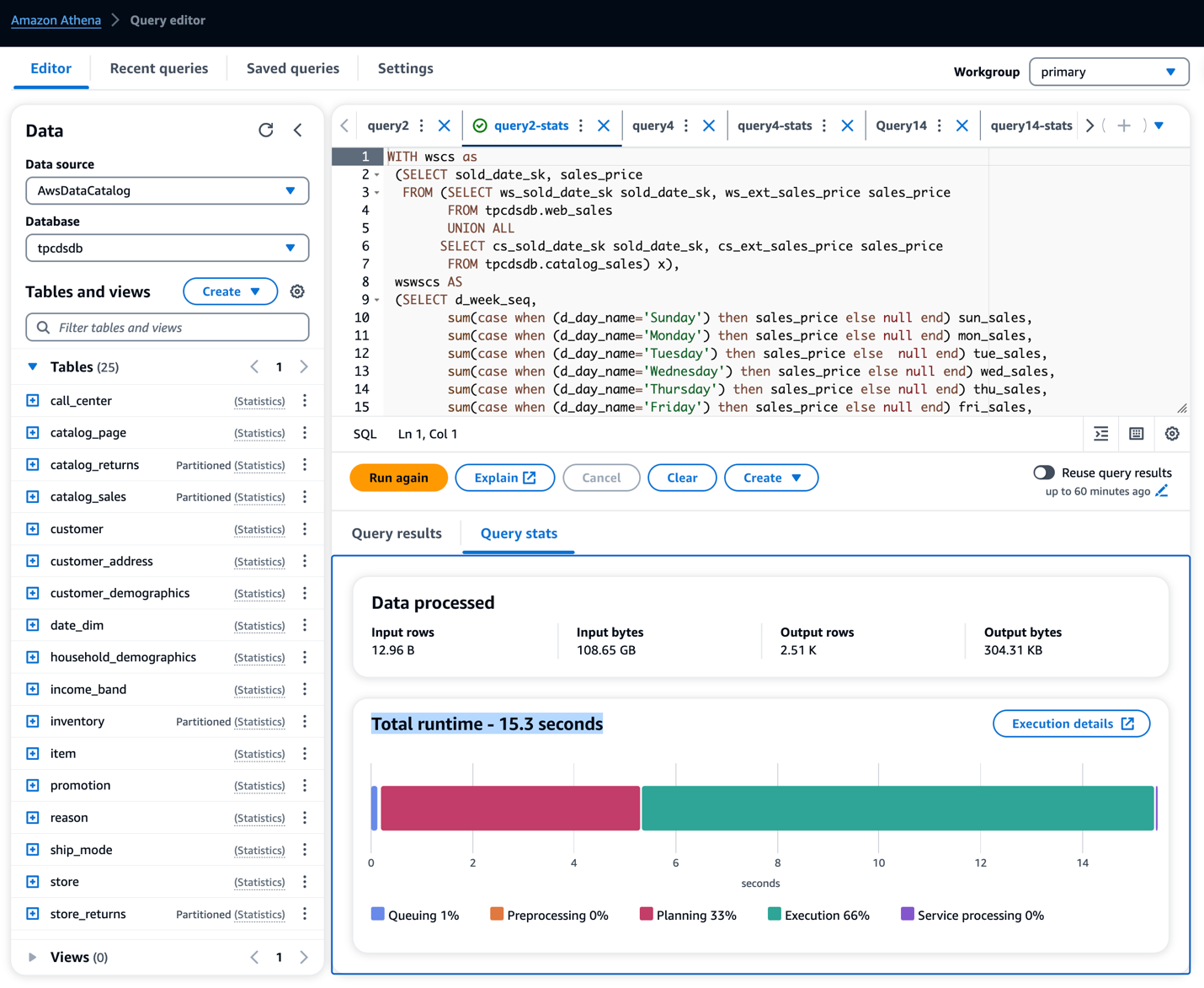
پرس و جو ارائه شده را با استفاده از Amazon Redshift Spectrum روی جداول آمار اجرا کنید
- در آمازون ویرایشگر کوئری Redshift v2، اجرا کنید درخواست Redshift برای جداول با آمار بخش از پرس و جو دانلود شده
- پرس و جو را اجرا کنید و اجرای پرس و جو هر پرس و جو را یادداشت کنید.
در اجرای نمونه پرس و جوهای روی جداول، زمان اجرای پرس و جو را مطابق جدول زیر مشاهده کردیم. ما شاهد بهبود واضحی در عملکرد پرس و جو، از 13 تا 89 درصد بودیم.
بهبود زمان جستجوی طیف Redshift آمازون
| پرس و جوهای TPC-DS 3T | بدون آمار چسب (ثانیه) | با آمار چسب (ثانیه) | ارتقای کارایی (٪) |
| پرس و جو 40 | 124.156 | 13.12 | ٪۱۰۰ |
| پرس و جو 60 | 29.52 | 16.97 | ٪۱۰۰ |
| پرس و جو 66 | 18.914 | 16.39 | ٪۱۰۰ |
| پرس و جو 95 | 308.806 | 200 | ٪۱۰۰ |
| پرس و جو 99 | 20.064 | 16 | ٪۱۰۰ |
برنامه آماری AWS Glue اجرا می شود
در این بخش از پست، ما شما را از طریق مراحل زمانبندی اجرای آمار ستون چسب AWS با استفاده از AWS لامبدا و پل رویداد آمازون برنامه ریز. برای سادهسازی این فرآیند، یک تابع AWS Lambda و یک برنامهریز رویداد Amazon Amazon به عنوان بخشی از استقرار پشته CloudFormation ایجاد شد.
- تنظیم عملکرد AWS Lambda:
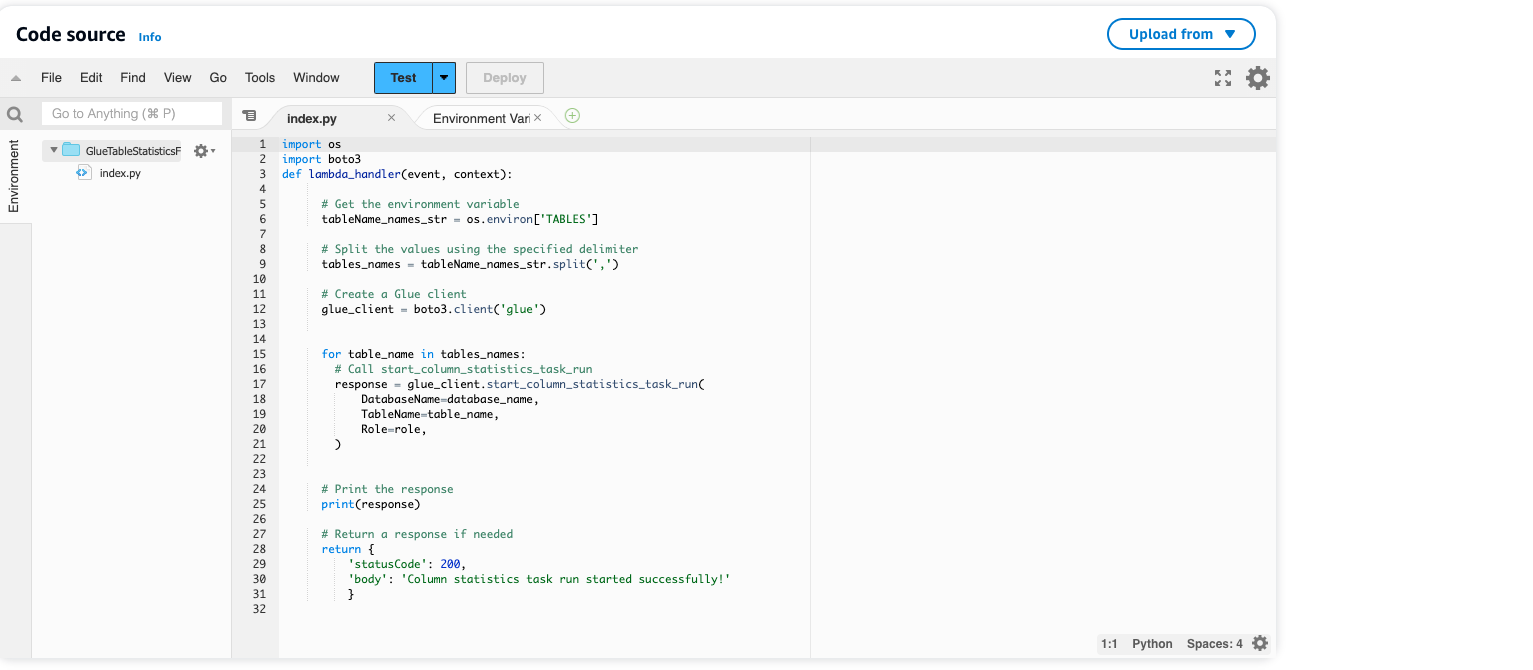
برای شروع، ما از یک تابع AWS Lambda برای شروع اجرای کار آمار ستون چسب AWS استفاده می کنیم. تابع AWS Lambda را فراخوانی می کند start_column_statistics_task_run API از طریق کتابخانه boto3 (AWS SDK for Python). این زمینه را برای خودکارسازی به روز رسانی آمار ستون ها تنظیم می کند.
بیایید تابع AWS Lambda را بررسی کنیم:
-
- رفتن به کنسول AWS Glue Lambda.
- انتخاب کنید توابع و پیدا کردن
GlueTableStatisticsFunctionv1. - برای درک واضح تر از عملکرد AWS Lambda، توصیه می کنیم کد موجود در آن را مرور کنید رمز بخش و بررسی متغیرهای محیطی در زیر پیکر بندی.
- پیکربندی برنامه زمانبندی Amazon EventBridge
مرحله بعدی شامل برنامه ریزی فراخوانی تابع AWS Lambda با استفاده از آمازون است EventBridge Scheduler. زمانبند به گونهای پیکربندی شده است که عملکرد AWS Lambda را روزانه در یک زمان خاص فعال کند - در این مورد، ساعت 08:00 بعد از ظهر. این تضمین می کند که کار آمار ستون چسب AWS به طور منظم و قابل پیش بینی اجرا می شود.
اکنون، بیایید بررسی کنیم که چگونه می توانید برنامه را به روز کنید:
تمیز کردن
برای جلوگیری از هزینه های ناخواسته به حساب AWS خود، منابع AWS را حذف کنید:
- به عنوان سرپرست AWS IAM که برای ایجاد پشته AWS CloudFormation استفاده میکند، وارد کنسول AWS CloudFormation شوید.
- پشته AWS CloudFormation را که ایجاد کردید حذف کنید.
نتیجه
در این پست به شما نشان دادیم که چگونه می توانید از آن استفاده کنید کاتالوگ داده چسب AWS برای تولید آمار در سطح ستون برای چسب AWS جداول این آمار اکنون با بهینه ساز مبتنی بر هزینه از یکپارچه شده است آمازون آتنا و آمازون طیف انتقال به قرمز، منجر به بهبود عملکرد پرس و جو و صرفه جویی در هزینه های بالقوه می شود. رجوع شود به اسناد برای پشتیبانی از آمار کاتالوگ چسب در سرویس های مختلف تحلیلی AWS.
اگر سوال یا پیشنهادی دارید در قسمت نظرات مطرح کنید.
درباره نویسنده
 ساندیپ ادوانکار یک مدیر ارشد محصول فنی در AWS است. او که در منطقه خلیج کالیفرنیا مستقر است، با مشتریان در سراسر جهان کار می کند تا الزامات تجاری و فنی را به محصولاتی تبدیل کند که مشتریان را قادر می سازد نحوه مدیریت، ایمن سازی و دسترسی به داده ها را بهبود بخشند.
ساندیپ ادوانکار یک مدیر ارشد محصول فنی در AWS است. او که در منطقه خلیج کالیفرنیا مستقر است، با مشتریان در سراسر جهان کار می کند تا الزامات تجاری و فنی را به محصولاتی تبدیل کند که مشتریان را قادر می سازد نحوه مدیریت، ایمن سازی و دسترسی به داده ها را بهبود بخشند.
 ناونیت شوکلا به عنوان یک معمار راه حل متخصص AWS با تمرکز بر تجزیه و تحلیل عمل می کند. او اشتیاق زیادی برای کمک به مشتریان در کشف بینش های ارزشمند از داده های آنها دارد. او از طریق تخصص خود، راه حل های نوآورانه ای ایجاد می کند که کسب و کارها را برای دستیابی به انتخاب های آگاهانه و مبتنی بر داده ها توانمند می کند. قابل ذکر است که ناونیت شوکلا نویسنده موفق کتابی با عنوان Data Wrangling در AWS است. می توان با او تماس گرفت لینک.
ناونیت شوکلا به عنوان یک معمار راه حل متخصص AWS با تمرکز بر تجزیه و تحلیل عمل می کند. او اشتیاق زیادی برای کمک به مشتریان در کشف بینش های ارزشمند از داده های آنها دارد. او از طریق تخصص خود، راه حل های نوآورانه ای ایجاد می کند که کسب و کارها را برای دستیابی به انتخاب های آگاهانه و مبتنی بر داده ها توانمند می کند. قابل ذکر است که ناونیت شوکلا نویسنده موفق کتابی با عنوان Data Wrangling در AWS است. می توان با او تماس گرفت لینک.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/enhance-query-performance-using-aws-glue-data-catalog-column-level-statistics/
- :است
- :جایی که
- $UP
- 08
- 1
- 10
- 100
- 13
- 264
- 30
- a
- قادر
- دسترسی
- مدیریت دسترسی
- در دسترس
- انجام
- حساب
- حساب ها
- دقیق
- اذعان
- در میان
- پس از
- معرفی
- اجازه می دهد تا
- آمازون
- آمازون آتنا
- آمازون خدمات وب
- مقدار
- an
- تحلیلی
- علم تجزیه و تحلیل
- و
- هر
- API
- مناسب
- معماری
- هستند
- محدوده
- دور و بر
- AS
- ظاهر
- ارزیابی کنید
- کمک کردن
- At
- نویسنده
- بطور خودکار
- اتوماسیون
- در دسترس
- اجتناب از
- AWS
- AWS CloudFormation
- چسب AWS
- AWS لامبدا
- مستقر
- اساس
- سرخ مایل به قرمز
- BE
- قبل از
- شروع
- در زیر
- بلاگ
- کتاب
- تقویت می کند
- بریج
- کسب و کار
- کسب و کار
- by
- کالیفرنیا
- CAN
- قابلیت های
- قابلیت
- مورد
- کاتالوگ
- متمرکز
- معین
- به چالش کشیدن
- تبادل
- بار
- انتخاب
- را انتخاب کنید
- واضح
- واضح تر
- مشتریان
- ابر
- رمز
- ستون
- ستون ها
- نظرات
- مقايسه كردن
- کامل
- تکمیل شده
- پیچیده
- جامع
- پیکربندی
- تشکیل شده است
- کنسول
- مصرف کننده
- مصرف کنندگان
- متناظر
- هزینه
- صرفه جویی در هزینه
- هزینه
- خزنده
- ایجاد
- ایجاد شده
- ایجاد
- مشتریان
- سفارشی
- روزانه
- داده ها
- دریاچه دریاچه
- داده محور
- پایگاه داده
- پایگاه های داده
- مجموعه داده ها
- به طور پیش فرض
- نشان دادن
- گروه ها
- گسترش
- مستقر
- گسترش
- تعیین شده
- طراحی
- دقیق
- جزئیات
- مختلف
- کشف
- متمایز
- انجام شده
- پایین
- مدت
- در طی
- e
- هر
- سردبیر
- اثر
- موثر
- هر دو
- قدرت دادن
- قادر ساختن
- تشویق
- پایان
- پشت سر هم
- بالا بردن
- افزایش
- تضمین می کند
- اشتیاق
- محیط
- به خصوص
- اتر (ETH)
- ارزیابی
- واقعه
- در حال بررسی
- مثال
- اجرا کردن
- اعدام
- تجربه
- تخصص
- اکتشاف
- سریعتر
- کمی از
- فایل ها
- نهایی
- تمرکز
- به دنبال
- پیروی
- برای
- از جانب
- تابع
- تولید می کنند
- تولید
- تولید می کند
- مولد
- نسل
- زمین
- حکومت
- زمینه سازی
- راهنمایی
- آیا
- he
- کمک می کند
- زیاد
- خود را
- میزبانی
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- IAM
- یکسان
- هویت
- هویت و مدیریت دسترسی
- if
- نشان می دهد
- تأثیر
- انجام
- مهم
- بهبود
- بهبود یافته
- بهبود
- ارتقاء
- را بهبود می بخشد
- in
- شامل
- شامل
- اطلاع
- ابتکاری
- بینش
- یکپارچه
- قصد
- به
- فراخوانی میکند
- شامل
- IT
- کار
- شغل ها
- پیوستن
- می پیوندد
- JPG
- json
- نگاه داشتن
- دریاچه
- دریاچه ها
- بزرگ
- راه اندازی
- راه اندازی
- منجر می شود
- آموخته
- سطح
- کتابخانه
- پسندیدن
- لینک
- فهرست
- نگاه کنيد
- شبیه
- کم
- ساخته
- ساخت
- ساخت
- مدیریت
- مدیریت
- مدیر
- حداکثر
- ممکن است..
- متاداده
- قدرت
- دقیقه
- دقیقه
- بیش
- کارآمدتر
- اکثر
- چندگانه
- جهت یابی
- نزدیک
- لازم
- نیاز
- نیازهای
- جدید
- بعد
- نه
- به ویژه
- توجه داشته باشید
- اکنون
- عدد
- مشاهده
- of
- on
- یک بار
- ONE
- عملیات
- بهینه سازی
- بهینه سازی
- گزینه
- or
- سفارش
- سازمان های
- ما
- خارج
- خود
- با ما
- قطعه
- بخش
- برای
- انجام دادن
- کارایی
- مجوز
- برنامه ریزی
- برنامه
- افلاطون
- هوش داده افلاطون
- PlatoData
- لطفا
- pm
- سیاست
- دارای
- پست
- پتانسیل
- بالقوه
- قابل پیش بینی
- پیش گویی
- پیش بینی
- قبلی
- خصوصی
- روند
- تولید
- محصول
- مدیر تولید
- محصولات
- ارائه
- ارائه
- عمومی
- پــایتــون
- نمایش ها
- سوالات
- سریع
- اعم
- خام
- رسیده
- خواندن
- توصیه
- کاهش
- مراجعه
- مرجع
- منطقه
- منظم
- نیاز
- مورد نیاز
- منابع
- نتیجه
- نتیجه
- این فایل نقد می نویسید:
- بازبینی
- نقش
- مسیر
- ROW
- دویدن
- در حال اجرا
- اجرا می شود
- پس انداز
- دید
- برنامه
- زمان بندی
- sdk
- یکپارچه
- SEC
- بخش
- امن
- دیدن
- بخش
- را انتخاب کنید
- ارشد
- بدون سرور
- خدمت
- سرویس
- خدمات
- مجموعه
- برپایی
- اشتراک گذاری
- باید
- نشان داد
- نشان داده شده
- ساده
- راه حل
- مزایا
- برخی از
- متخصص
- خاص
- طیف
- SQL
- پشته
- صحنه
- ارقام
- آمار
- وضعیت
- گام
- مراحل
- ذخیره سازی
- opbevare
- ذخیره شده
- ساده کردن
- قوی
- ارسال
- زیر شبکه
- زیرشبکه ها
- موفقیت
- چنین
- کت و شلوار
- پشتیبانی
- جدول
- گرفتن
- سخنگو
- تیم ها
- فنی
- قالب
- که
- La
- شان
- آنها
- آنجا.
- در نتیجه
- اینها
- آنها
- این
- کسانی که
- از طریق
- زمان
- با عنوان
- به
- ترجمه کردن
- ماشه
- امتحان
- دو
- زیر
- اساسی
- درک
- ناخواسته
- بروزرسانی
- به روز شده
- استفاده کنید
- استفاده
- کاربران
- با استفاده از
- استفاده کنید
- با استفاده از
- ارزشمند
- ارزشها
- مختلف
- وسیع
- بررسی
- چشم انداز
- مجازی
- we
- وب
- خدمات وب
- بود
- چه زمانی
- که
- اراده
- با
- در داخل
- بدون
- مهاجرت کاری
- گردش کار
- کارگروه
- با این نسخهها کار
- خواهد بود
- XML
- یامل
- شما
- شما
- زفیرنت