در پست ابزار TCO کیت تحویل AWS ProServe Hadoop Migration را معرفی می کنیم، ابزار TCO AWS ProServe Hadoop Migration Delivery Kit (HMDK) و مزایای انتقال بارهای کاری Hadoop در محل به آمازون EMR. در این پست، ما عمیقاً در ابزار غوطه ور می شویم و تمام مراحل از ورود به سیستم، تبدیل، تجسم و طراحی معماری تا محاسبه TCO را طی می کنیم.
بررسی اجمالی راه حل
بیایید به طور خلاصه از ویژگی های کلیدی ابزار HMDK TCO بازدید کنیم. این ابزار یک جمعآوری گزارش YARN برای اتصال Hadoop Resource Manager برای جمعآوری سیاهههای YARN فراهم میکند. یک تحلیلگر حجم کار Hadoop مبتنی بر پایتون، به نام تحلیلگر گزارش YARN، برنامههای Hadoop را به دقت بررسی میکند. آمازون QuickSight داشبوردها نتایج حاصل از تحلیلگر را به نمایش می گذارند. همین نتایج همچنین طراحی نمونه های EMR آینده را تسریع می بخشد. علاوه بر این، یک ماشین حساب TCO تخمین TCO را از یک خوشه EMR بهینه برای تسهیل مهاجرت تولید می کند.
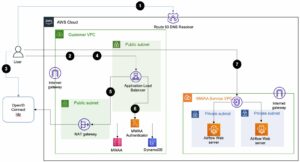
حال بیایید نحوه عملکرد ابزار را بررسی کنیم. نمودار زیر روند کار انتها به انتها را نشان می دهد.

در بخشهای بعدی، پنج مرحله اصلی ابزار را طی میکنیم:
- سیاهههای مربوط به سابقه کار YARN را جمع آوری کنید.
- گزارش های سابقه کار را از JSON به CSV تبدیل کنید.
- گزارش های سابقه کار را تجزیه و تحلیل کنید.
- یک خوشه EMR برای مهاجرت طراحی کنید.
- TCO را محاسبه کنید.
پیش نیازها
قبل از شروع، حتماً پیش نیازهای زیر را تکمیل کنید:
- کلون کنید مخزن hadoop-migration-assessment-tco.
- پایتون 3 را روی ماشین محلی خود نصب کنید.
- یک حساب AWS با مجوز فعال داشته باشید AWS لامبدا، QuickSight (نسخه Enterprise) و AWS CloudFormation.
سیاهههای مربوط به سابقه کار YARN را جمع آوری کنید
اول، شما اجرا می کنید جمع کننده چوب نخ، start-collector.sh، در دستگاه محلی شما. این مرحله لاگ های Hadoop YARN را جمع آوری می کند و سیاهه ها را روی دستگاه محلی شما قرار می دهد. اسکریپت ماشین محلی شما را با گره اولیه Hadoop متصل می کند و با Resource Manager ارتباط برقرار می کند. سپس با فراخوانی API برنامه YARN ResourceManager، اطلاعات تاریخچه شغلی (گزارش های YARN از مدیران برنامه) را بازیابی می کند.
قبل از اجرای جمعآوری گزارش YARN، باید اتصال را پیکربندی و برقرار کنید (HTTP: 8088 یا HTTPS: 8090؛ مورد دوم توصیه میشود) تا دسترسی به YARN ResourceManager و فعال کردن YARN Timeline Server (سرور تایم لاین نسخه 1 یا جدیدتر پشتیبانی میشود) را تأیید کنید. ). ممکن است لازم باشد خط مشی بازه جمع آوری و حفظ گزارش های YARN را تعریف کنید. برای اطمینان از جمعآوری گزارشهای متوالی YARN، میتوانید از cron job برای برنامهریزی جمعآوری گزارش در یک بازه زمانی مناسب استفاده کنید. به عنوان مثال، برای یک خوشه Hadoop با 2,000 برنامه روزانه و تنظیمات yarn.resourcemanager.max-completed-applications روی 1,000 تنظیم شده است، از نظر تئوری، شما باید حداقل دو بار کلکتور log را اجرا کنید تا همه لاگ های YARN را دریافت کنید. علاوه بر این، توصیه میکنیم حداقل ۷ روز از سیاهههای YARN را برای تجزیه و تحلیل حجم کاری کلنگر جمعآوری کنید.
برای جزئیات بیشتر در مورد نحوه پیکربندی و زمانبندی جمعآوری گزارش، به قسمت مراجعه کنید مخزن yarn-log-collector GitHub.
گزارشهای سابقه کار YARN را از JSON به CSV تبدیل کنید
پس از به دست آوردن گزارشهای YARN، یک سازماندهنده گزارش YARN، yarn-log-organizer.py را اجرا میکنید، که تجزیهکنندهای برای تبدیل گزارشهای مبتنی بر JSON به فایلهای CSV است. این فایلهای خروجی CSV ورودیهای تحلیلگر لاگ YARN هستند. تجزیه کننده قابلیت های دیگری نیز دارد، از جمله مرتب سازی رویدادها بر اساس زمان، حذف اختصاصی ها و ادغام چندین گزارش.
برای اطلاعات بیشتر در مورد نحوه استفاده از سازماندهنده گزارش YARN، به آدرس زیر مراجعه کنید مخزن yarn-log-organizer GitHub.
گزارشهای سابقه شغلی YARN را تجزیه و تحلیل کنید
در مرحله بعد، تحلیلگر گزارش YARN را برای تجزیه و تحلیل سیاهههای مربوط به YARN در قالب CSV راه اندازی می کنید.
با QuickSight، میتوانید دادههای گزارش YARN را تجسم کنید و تجزیه و تحلیل را بر اساس مجموعه دادههای تولید شده توسط الگوهای داشبورد از پیش ساخته شده و یک ویجت انجام دهید. ویجت به طور خودکار داشبوردهای QuickSight را در حساب هدف AWS ایجاد می کند که در قالب CloudFormation پیکربندی شده است.
نمودار زیر معماری HMDK TCO را نشان می دهد.

تحلیلگر لاگ YARN چهار قابلیت کلیدی را ارائه می دهد:
- گزارشهای تاریخچه شغلی تغییریافته YARN را در قالب CSV بارگذاری کنید (به عنوان مثال،
cluster_yarn_logs_*.csv) به سرویس ذخیره سازی ساده آمازون سطل (Amazon S3). این فایلهای CSV خروجیهای سازماندهنده گزارش YARN هستند. - یک فایل JSON مانیفست ایجاد کنید (به عنوان مثال،
yarn-log-manifest.json) برای QuickSight و آپلود آن در سطل S3: - داشبوردهای QuickSight را با استفاده از یک الگوی CloudFormation، که در قالب YAML است، مستقر کنید. پس از استقرار، نماد تازه سازی را انتخاب کنید تا زمانی که وضعیت پشته را به عنوان مشاهده کنید
CREATE_COMPLETE. این مرحله مجموعه داده هایی را در داشبوردهای QuickSight در حساب هدف AWS شما ایجاد می کند.
- در داشبورد QuickSight، می توانید بینش هایی از بارهای کاری Hadoop تجزیه و تحلیل شده را از نمودارهای مختلف بیابید. این اطلاعات به شما کمک میکند تا نمونههای EMR آینده را برای تسریع مهاجرت طراحی کنید، همانطور که در مرحله بعد نشان داده شد.

یک خوشه EMR برای مهاجرت طراحی کنید
نتایج تحلیلگر لاگ YARN به شما کمک می کند تا بارهای کاری واقعی Hadoop را در سیستم موجود درک کنید. این مرحله طراحی نمونه های EMR آینده برای مهاجرت را با استفاده از یک تسریع می کند قالب اکسل. این الگو شامل چک لیستی برای انجام تحلیل حجم کار و برنامه ریزی ظرفیت است:
- آیا برنامه های در حال اجرا بر روی خوشه به طور مناسب با ظرفیت فعلی خود استفاده می شوند؟
- آیا خوشه در زمان خاصی تحت بار است یا خیر؟ اگر چنین است، زمان آن چه زمانی است؟
- چه نوع برنامهها و موتورهایی (مانند MR، TEZ یا Spark) روی خوشه اجرا میشوند، و استفاده از منابع برای هر نوع چقدر است؟
- آیا چرخه های اجرای مشاغل مختلف (زمان واقعی، دسته ای، موقت) در یک خوشه اجرا می شوند؟
- آیا هر شغلی به صورت دستهای منظم اجرا میشود، و اگر چنین است، این فواصل زمانبندی چیست؟ (به عنوان مثال، هر 10 دقیقه، 1 ساعت، 1 روز.) آیا مشاغلی دارید که از منابع زیادی در مدت زمان طولانی استفاده می کنند؟
- آیا هر شغلی نیاز به بهبود عملکرد دارد؟
- آیا سازمان ها یا افراد خاصی در انحصار خوشه هستند؟
- آیا هر شغل مختلط توسعه و بهره برداری در یک خوشه عمل می کند؟
پس از تکمیل چک لیست، درک بهتری از نحوه طراحی معماری آینده خواهید داشت. برای بهینه سازی اثربخشی هزینه خوشه EMR، جدول زیر دستورالعمل های کلی برای انتخاب نوع مناسب خوشه EMR و ابر محاسبه الاستیک آمازون خانواده (Amazon EC2).

برای انتخاب نوع خوشه و خانواده نمونه مناسب، باید چندین دور تجزیه و تحلیل را در برابر سیاهههای YARN بر اساس معیارهای مختلف انجام دهید. بیایید به برخی از معیارهای کلیدی نگاه کنیم.
گاهشمار
می توانید الگوهای بار کاری را بر اساس تعداد برنامه های Hadoop اجرا شده در یک پنجره زمانی پیدا کنید. به عنوان مثال، نمودارهای روزانه یا ساعتی "تعداد رکوردها بر اساس زمان شروع" بینش های زیر را ارائه می دهند:
- در نمودارهای سری زمانی روزانه، تعداد اجرای برنامه ها را بین روزهای کاری و تعطیلات و بین روزهای تقویم مقایسه می کنید. اگر اعداد مشابه باشند، به این معنی است که استفاده روزانه از خوشه قابل مقایسه است. از سوی دیگر، اگر انحراف زیاد باشد، نسبت مشاغل موردی قابل توجه است. شما همچنین می توانید مشاغل احتمالی هفتگی یا ماهانه را در روزهای خاص مشخص کنید. در این شرایط به راحتی می توانید روزهای خاصی را در یک هفته یا یک ماه با تمرکز بار کاری بالا ببینید.
- در نمودارهای سری زمانی ساعتی، شما بیشتر درک می کنید که چگونه برنامه ها در پنجره های ساعتی اجرا می شوند. شما می توانید ساعات اوج بار و غیر اوج بار را در یک روز پیدا کنید.
کاربران
گزارش های YARN شامل شناسه کاربری هر برنامه است. این اطلاعات به شما کمک می کند بفهمید چه کسی یک برنامه را در صف ارسال می کند. بر اساس آمار اجرای برنامه های جداگانه و انبوه در هر صف و به ازای هر کاربر، می توانید توزیع حجم کار موجود را بر اساس کاربر تعیین کنید. معمولاً کاربران یک تیم صف های مشترک دارند. گاهی اوقات، تیم های متعددی صف های مشترکی دارند. هنگام طراحی صف برای کاربران، اکنون بینش هایی دارید که به شما کمک می کند تا بارهای کاری برنامه را طراحی و توزیع کنید که نسبت به قبل در بین صف ها متعادل تر باشد.
انواع برنامه
می توانید بارهای کاری را بر اساس انواع مختلف برنامه (مانند Hive، Spark، Presto، یا HBase) تقسیم بندی کنید و موتورها (مانند MR، Spark یا Tez) را اجرا کنید. برای بارهای کاری سنگین مانند کارهای MapReduce یا Hive-on-MR، از نمونه های بهینه سازی شده برای CPU استفاده کنید. برای کارهای پرحافظه مانند کارهای Hive-on-TEZ، Presto، و Spark، از نمونه های بهینه شده برای حافظه استفاده کنید.
گذشت زمان
می توانید برنامه ها را بر اساس زمان اجرا دسته بندی کنید. الگوی جاسازی شده CloudFormation به طور خودکار یک فیلد elapsedGroup را در داشبورد QuickSight ایجاد می کند. این یک ویژگی کلیدی را فعال می کند تا به شما امکان می دهد کارهای طولانی مدت را در یکی از چهار نمودار داشبورد QuickSight مشاهده کنید. بنابراین، می توانید معماری های آینده را برای این مشاغل بزرگ طراحی کنید.
داشبورد QuickSight مربوطه شامل چهار نمودار است. شما می توانید هر نمودار را که به یک گروه مرتبط است، مشخص کنید.
| گروه شماره |
زمان اجرا/زمان سپری شده یک کار |
| 1 | کمتر از 10 دقیقه |
| 2 | بین 10 دقیقه تا 30 دقیقه |
| 3 | بین 30 دقیقه تا 1 ساعت |
| 4 | بیشتر از 1 ساعت |
در نمودار گروه 4، می توانید بر اساس معیارهای مختلف، از جمله کاربر، صف، نوع برنامه، جدول زمانی، استفاده از منابع و غیره، روی بررسی دقیق مشاغل بزرگ تمرکز کنید. بر اساس این ملاحظات، ممکن است برای کارهای بزرگ، صف های اختصاصی روی یک کلاستر یا یک خوشه EMR اختصاصی داشته باشید. در همین حال، می توانید مشاغل کوچک را در صف های مشترک ارسال کنید.
منابع
بر اساس الگوهای مصرف منابع (CPU، حافظه)، اندازه و خانواده مناسب نمونه های EC2 را برای عملکرد و مقرون به صرفه بودن انتخاب می کنید. برای برنامههای محاسباتی فشرده، نمونههایی از خانوادههای بهینهشده برای CPU را توصیه میکنیم. برای برنامههای فشرده حافظه، خانوادههای نمونه بهینهشده برای حافظه توصیه میشوند.
علاوه بر این، بر اساس ماهیت بارهای کاری برنامه و استفاده از منابع در طول زمان، می توانید یک خوشه EMR پایدار یا گذرا را انتخاب کنید. آمازون EMR در EKS، یا آمازون EMR بدون سرور.
پس از تجزیه و تحلیل سیاهه های YARN با معیارهای مختلف، شما آماده طراحی معماری های EMR آینده هستید. جدول زیر نمونه هایی از خوشه های EMR پیشنهادی را فهرست می کند. شما می توانید جزئیات بیشتر را در بهینه سازی-tco-calculator مخزن GitHub.

محاسبه TCO
در نهایت، در ماشین محلی خود، tco-input-generator.py را اجرا کنید تا پیش از استفاده از یک الگوی اکسل برای محاسبه TCO بهینه شده، گزارشهای سابقه کار YARN را به صورت ساعتی جمعآوری کنید. این مرحله بسیار مهم است زیرا نتایج بارهای کاری Hadoop را در نمونههای EMR آینده شبیهسازی میکنند.
پیش نیاز شبیه سازی TCO اجرای آن است tco-input-generator.py، که گزارش های جمع آوری ساعتی را ایجاد می کند. در مرحله بعد، یک فایل قالب اکسل را باز می کنید تا ماکروها را فعال کنید و ورودی های خود را در سلول های سبز برای محاسبه TCO ارائه دهید. با توجه به داده های ورودی، اندازه واقعی داده ها را بدون تکرار و مشخصات سخت افزاری (vCore، mem) گره اولیه Hadoop و گره های داده را وارد می کنید. همچنین باید گزارشهای جمعآوری شده ساعتی قبلاً ایجاد شده را انتخاب و آپلود کنید. پس از تنظیم متغیرهای شبیه سازی TCO، مانند منطقه، نوع EC2، دسترسی بالا آمازون EMR، اثر موتور، تخفیف EC2 آمازون و آمازون EBS (EDP)، تخفیف حجمی آمازون S3، نرخ ارز محلی، و نسبت قیمت گذاری وظیفه/هسته EMR EC2 و قیمت/ساعت، شبیه ساز TCO به طور خودکار هزینه بهینه نمونه های EMR آینده را در Amazon EC2 محاسبه می کند. تصاویر زیر نمونه ای از نتایج HMDK TCO را نشان می دهد.

برای اطلاعات بیشتر و دستورالعمل های محاسبات HMDK TCO، مراجعه کنید بهینه سازی-tco-calculator مخزن GitHub.
پاک کردن
پس از انجام تمام مراحل و اتمام تست، مراحل زیر را برای حذف منابع برای جلوگیری از تحمیل هزینه انجام دهید:
- در کنسول AWS CloudFormation، پشته ای را که ایجاد کردید انتخاب کنید.
- را انتخاب کنید حذف.
- را انتخاب کنید پشته را حذف کنید.
- صفحه را بازخوانی کنید تا وضعیت را ببینید
DELETE_COMPLETE. - در کنسول آمازون S3، سطل S3 را که ایجاد کرده اید حذف کنید.
نتیجه
ابزار AWS ProServe HMDK TCO به طور قابل توجهی تلاشهای برنامهریزی مهاجرت را کاهش میدهد، که وظایف زمانبر و چالش برانگیز ارزیابی حجم کاری Hadoop شماست. با ابزار HMDK TCO، ارزیابی معمولاً 2 تا 3 هفته طول می کشد. همچنین می توانید TCO محاسبه شده معماری های EMR آینده را تعیین کنید. با ابزار HMDK TCO، می توانید به سرعت بارهای کاری و الگوهای استفاده از منابع خود را درک کنید. با بینش های تولید شده توسط این ابزار، شما برای طراحی معماری های EMR بهینه آینده مجهز هستید. در بسیاری از موارد استفاده، یک TCO 1 ساله از معماری بازسازیشده بهینهشده، صرفهجویی قابلتوجهی در هزینه (64 تا 80 درصد کاهش) در محاسبات و ذخیرهسازی، در مقایسه با مهاجرتهای Hadoop با لیفت و تغییر ایجاد میکند.
برای کسب اطلاعات بیشتر در مورد تسریع مهاجرت Hadoop به آمازون EMR و ابزار HMDK CTO، به Hadoop Migration Delivery Kit مخزن TCO GitHub، یا تماس بگیرید AWS-HMDK@amazon.com.
درباره نویسندگان
 پارک سونگ یول یک مدیر ارشد تمرین در AWS ProServe است. او به مشتریان کمک می کند تا کسب و کار خود را با خدمات AWS Analytics، IoT و AI/ML نوآوری کنند. او در خدمات و فناوری های کلان داده تخصص دارد و به ایجاد نتایج تجاری مشتری با هم علاقه دارد.
پارک سونگ یول یک مدیر ارشد تمرین در AWS ProServe است. او به مشتریان کمک می کند تا کسب و کار خود را با خدمات AWS Analytics، IoT و AI/ML نوآوری کنند. او در خدمات و فناوری های کلان داده تخصص دارد و به ایجاد نتایج تجاری مشتری با هم علاقه دارد.
 جیسونگ کیم یک معمار ارشد داده در AWS ProServe است. او عمدتاً با مشتریان سازمانی کار میکند تا به مهاجرت و نوسازی دادهها کمک کند، و در پروژههای کلان داده مانند Hadoop، Spark، انبار دادهها، پردازش بیدرنگ دادهها و یادگیری ماشینی در مقیاس بزرگ راهنمایی و کمک فنی ارائه میکند. او همچنین میداند که چگونه از فناوریها برای حل مشکلات کلان داده و ایجاد یک معماری داده با طراحی خوب استفاده کند.
جیسونگ کیم یک معمار ارشد داده در AWS ProServe است. او عمدتاً با مشتریان سازمانی کار میکند تا به مهاجرت و نوسازی دادهها کمک کند، و در پروژههای کلان داده مانند Hadoop، Spark، انبار دادهها، پردازش بیدرنگ دادهها و یادگیری ماشینی در مقیاس بزرگ راهنمایی و کمک فنی ارائه میکند. او همچنین میداند که چگونه از فناوریها برای حل مشکلات کلان داده و ایجاد یک معماری داده با طراحی خوب استفاده کند.
 جورج ژائو یک معمار ارشد داده در AWS ProServe است. او یک رهبر باتجربه تحلیلی است که با مشتریان AWS برای ارائه راه حل های داده مدرن کار می کند. او همچنین یک متخصص دامنه ProServe Amazon EMR است که مشاوران ProServe را در مورد بهترین شیوه ها و کیت های تحویل برای مهاجرت Hadoop به Amazon EMR قادر می سازد. حوزه علایق او دریاچه های داده و تحویل معماری داده های مدرن ابری است.
جورج ژائو یک معمار ارشد داده در AWS ProServe است. او یک رهبر باتجربه تحلیلی است که با مشتریان AWS برای ارائه راه حل های داده مدرن کار می کند. او همچنین یک متخصص دامنه ProServe Amazon EMR است که مشاوران ProServe را در مورد بهترین شیوه ها و کیت های تحویل برای مهاجرت Hadoop به Amazon EMR قادر می سازد. حوزه علایق او دریاچه های داده و تحویل معماری داده های مدرن ابری است.
 کالن ژانگ رهبر فناوری بخش جهانی داده های شریک و تجزیه و تحلیل در AWS بود. او بهعنوان مشاور قابل اعتماد دادهها و تحلیلها، ابتکارات استراتژیک برای تبدیل دادهها را مدیریت کرد، برنامههای مهاجرت و نوسازی حجم کار دادهها و تحلیلها را رهبری کرد و سفرهای مهاجرت مشتری را با شرکای در مقیاس تسریع کرد. او در سیستم های توزیع شده، مدیریت داده های سازمانی، تجزیه و تحلیل پیشرفته، و ابتکارات استراتژیک در مقیاس بزرگ تخصص دارد.
کالن ژانگ رهبر فناوری بخش جهانی داده های شریک و تجزیه و تحلیل در AWS بود. او بهعنوان مشاور قابل اعتماد دادهها و تحلیلها، ابتکارات استراتژیک برای تبدیل دادهها را مدیریت کرد، برنامههای مهاجرت و نوسازی حجم کار دادهها و تحلیلها را رهبری کرد و سفرهای مهاجرت مشتری را با شرکای در مقیاس تسریع کرد. او در سیستم های توزیع شده، مدیریت داده های سازمانی، تجزیه و تحلیل پیشرفته، و ابتکارات استراتژیک در مقیاس بزرگ تخصص دارد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- قادر
- درباره ما
- شتاب دادن
- تسریع شد
- تسریع می شود
- تسریع
- شتاب
- دسترسی
- حساب
- در میان
- Ad
- اضافه
- اضافی
- اطلاعات اضافی
- علاوه بر این
- پیشرفته
- مشاور
- پس از
- در برابر
- AI / ML
- معرفی
- آمازون
- آمازون EC2
- آمازون EMR
- در میان
- تحلیل
- علم تجزیه و تحلیل
- تحلیل
- تجزیه و تحلیل
- و
- API
- کاربرد
- برنامه های کاربردی
- درخواست
- به درستی
- معماری
- محدوده
- ارزیابی
- کمک
- مرتبط است
- بطور خودکار
- دسترس پذیری
- AWS
- AWS CloudFormation
- مستقر
- اساس
- زیرا
- بودن
- مزایای
- بهترین
- بهترین شیوه
- بهتر
- میان
- بزرگ
- بزرگ داده
- بطور خلاصه
- ساختن
- بنا
- کسب و کار
- محاسبه
- محاسبه
- محاسبه می کند
- محاسبه
- تقویم
- نام
- فراخوانی
- قابلیت های
- ظرفیت
- موارد
- سلول ها
- معین
- به چالش کشیدن
- چارت سازمانی
- نمودار
- را انتخاب کنید
- انتخاب
- ابر
- خوشه
- جمع آوری
- جمع آوری
- مجموعه
- جمع کننده
- جمع می کند
- COM
- قابل مقایسه
- مقايسه كردن
- مقایسه
- کامل
- محاسبه
- تمرکز
- غلظت
- رفتار
- انجام
- اتصال
- ارتباط
- متصل
- متوالی
- توجه
- کنسول
- مشاوران
- مصرف
- شامل
- متناظر
- هزینه
- صرفه جویی در هزینه
- هزینه
- پردازنده
- ایجاد شده
- ایجاد
- ضوابط
- بسیار سخت
- CTO
- سرپرستی
- واحد پول
- جاری
- مشتری
- مشتریان
- چرخه
- روزانه
- داشبورد
- داده ها
- دریاچه دریاچه
- مدیریت اطلاعات
- پردازش داده ها
- مجموعه داده ها
- روز
- روز
- اختصاصی
- عمیق
- شیرجه عمیق
- ارائه
- تحویل
- نشان
- استقرار
- طرح
- طراحی
- جزئیات
- مشخص کردن
- پروژه
- انحراف
- مختلف
- تخفیف
- توزیع کردن
- توزیع شده
- سیستم های توزیع شده
- توزیع
- دامنه
- پایین
- در طی
- هر
- به آسانی
- ebs
- چاپ
- اثر
- اثر
- تلاش
- جاسازی شده
- قادر ساختن
- فعال
- را قادر می سازد
- پشت سر هم
- موتور
- موتورهای حرفه ای
- اطمینان حاصل شود
- وارد
- سرمایه گذاری
- مشتریان سازمانی
- مجهز بودن
- ایجاد
- اتر (ETH)
- حوادث
- هر
- مثال
- مثال ها
- اکسل
- موجود
- با تجربه
- تسهیل کننده
- خانواده
- خانواده
- ویژگی
- امکانات
- رشته
- شکل
- پرونده
- فایل ها
- پیدا کردن
- پایان
- پیروی
- قالب
- از جانب
- ویژگی های
- بیشتر
- آینده
- سوالات عمومی
- تولید
- تولید می کند
- دریافت کنید
- گرفتن
- GitHub
- جهانی
- سبز
- گروه
- دستورالعمل ها
- هادوپ
- سخت افزار
- کمک
- کمک می کند
- زیاد
- تاریخ
- کندو
- تعطیلات
- جامع
- ساعت ها
- چگونه
- چگونه
- HTML
- HTTPS
- ICON
- بهبود
- in
- شامل
- از جمله
- فرد
- افراد
- اطلاعات
- ابتکارات
- نوآوری
- ورودی
- بینش
- نمونه
- دستورالعمل
- علاقه
- منافع
- معرفی
- اینترنت اشیا
- IT
- کار
- شغل ها
- سفرها
- json
- کلید
- بسته لوازم
- دریاچه
- بزرگ
- در مقیاس بزرگ
- راه اندازی
- رهبری
- رهبر
- یاد گرفتن
- یادگیری
- رهبری
- داده های LED
- لیست
- بار
- محلی
- طولانی
- مدت زمان طولانی
- نگاه کنيد
- خیلی
- دستگاه
- فراگیری ماشین
- ماکرو
- اصلی
- ساخت
- مدیریت
- مدیر
- مدیران
- بسیاری
- به معنی
- در ضمن
- حافظه
- ادغام
- متریک
- مهاجرت
- دقیقه
- مخلوط
- مدرن
- نوسازی
- ماه
- ماهیانه
- بیش
- چندگانه
- طبیعت
- نیاز
- بعد
- گره
- گره
- عدد
- تعداد
- مشاهده کردن
- بدست آوردن
- ONE
- باز کن
- عملیاتی
- عمل
- بهینه
- بهینه
- بهینه سازی
- بهینه
- سازمان های
- دیگر
- ویژه
- شریک
- شرکای
- الگوهای
- اوج
- انجام دادن
- کارایی
- دوره
- اجازه
- اماکن
- برنامه ریزی
- افلاطون
- هوش داده افلاطون
- PlatoData
- سیاست
- ممکن
- پست
- تمرین
- شیوه های
- پیش نیازها
- قبلا
- قیمت گذاری
- اصلی
- قبلا
- مشکلات
- در حال پردازش
- برنامه ها
- پروژه ها
- مناسب
- پیشنهاد شده
- ارائه
- فراهم می کند
- پــایتــون
- به سرعت
- نرخ
- نسبت
- رسیدن به
- اماده
- زمان واقعی
- داده های زمان واقعی
- توصیه
- توصیه می شود
- سوابق
- را کاهش می دهد
- با توجه
- منطقه
- منظم
- از بین بردن
- تکرار
- منابع
- منابع
- نتایج
- نگهداری
- دور
- دویدن
- در حال اجرا
- همان
- پس انداز
- مقیاس
- برنامه
- تصاویر
- بخش
- بخش
- ارشد
- سلسله
- خدمات
- تنظیم
- محیط
- چند
- به اشتراک گذاشته شده
- نشان
- نمایشگاه
- قابل توجه
- به طور قابل توجهی
- مشابه
- ساده
- شبیه سازی
- شبیه ساز
- وضعیت
- اندازه
- کوچک
- So
- مزایا
- حل
- برخی از
- جرقه
- متخصص
- تخصص دارد
- تخصص
- خاص
- مشخصات
- پشته
- آغاز شده
- ارقام
- وضعیت
- گام
- مراحل
- ذخیره سازی
- استراتژیک
- ارسال
- چنین
- پشتیبانی
- سیستم
- سیستم های
- جدول
- طراحی شده
- طول می کشد
- هدف
- وظایف
- تیم
- تیم ها
- فن آوری
- فنی
- فن آوری
- قالب
- قالب
- تست
- La
- آینده
- شان
- از این رو
- از طریق
- زمان
- سری زمانی
- زمان بر
- جدول زمانی
- به
- با هم
- ابزار
- دگرگون کردن
- دگرگونی
- مبدل
- درست
- مورد اعتماد
- انواع
- زیر
- فهمیدن
- درک
- درک می کند
- استفاده
- استفاده کنید
- کاربر
- کاربران
- معمولا
- مختلف
- بررسی
- تجسم
- حجم
- راه رفتن
- انبارداری
- هفته
- هفتگی
- هفته
- چی
- چه شده است
- که
- WHO
- پنجره
- بدون
- گردش کار
- کارگر
- با این نسخهها کار
- یامل
- شما
- زفیرنت