سازمانها در تمام صنایع دارای الزامات پردازش داده پیچیده برای موارد استفاده تحلیلی خود در سیستمهای تحلیلی مختلف هستند، مانند دریاچه های داده در AWS، انبارهای داده (آمازون Redshift)، جستجو کردن (سرویس جستجوی باز آمازون), NoSQL (آمازون DynamoDB)، فراگیری ماشین (آمازون SageMaker)، و بیشتر. متخصصان تجزیه و تحلیل وظیفه دارند از داده های ذخیره شده در این سیستم های توزیع شده ارزش استخراج کنند تا تجربیات بهتر، ایمن و بهینه سازی شده برای مشتریان خود ایجاد کنند. برای مثال، شرکتهای رسانههای دیجیتال به دنبال ترکیب و پردازش مجموعه دادهها در پایگاههای داده داخلی و خارجی برای ایجاد دیدگاههای یکپارچه از پروفایلهای مشتریان خود، ایجاد ایدههایی برای ویژگیهای نوآورانه و افزایش تعامل پلت فرم هستند.
در این سناریوها، مشتریانی که به دنبال ارائه یکپارچه سازی داده های بدون سرور هستند، استفاده می کنند چسب AWS به عنوان یک جزء اصلی برای پردازش و فهرست نویسی داده ها. چسب AWS به خوبی با خدمات AWS و محصولات شریک ادغام شده است و گزینههای استخراج، تبدیل و بارگذاری (ETL) با کد/بدون کد پایین را برای فعال کردن گردشهای کاری تجزیه و تحلیل، یادگیری ماشین (ML) یا توسعه برنامه ارائه میکند. کارهای AWS Glue ETL ممکن است یکی از اجزای خط لوله پیچیده تر باشد. سازماندهی اجرا و مدیریت وابستگی بین این مؤلفه ها یک قابلیت کلیدی در استراتژی داده است. آمازون گردش های کاری را برای Apache Airflows مدیریت کرد (Amazon MWAA) خطوط لوله داده را با استفاده از فناوری های توزیع شده از جمله منابع داخلی، خدمات AWS و اجزای شخص ثالث هماهنگ می کند.
در این پست، ما نشان میدهیم که چگونه میتوان نظارت بر کار چسب AWS را که توسط Airflow تنظیم شده است، با استفاده از آخرین ویژگیهای Amazon MWAA ساده کرد.
بررسی اجمالی راه حل
این پست در مورد موارد زیر بحث می کند:
- نحوه ارتقاء محیط آمازون MWAA به نسخه 2.4.3.
- نحوه تنظیم یک کار چسب AWS از جریان هوا نمودار Acyclic کارگردانی شده است (DAG).
- بهبود قابلیت مشاهده بسته ارائه دهنده Airflow Amazon در آمازون MWAA. اکنون میتوانید گزارشهای اجرایی کارهای چسب AWS را در کنسول Airflow ادغام کنید تا عیبیابی خطوط لوله داده را ساده کنید. کنسول آمازون MWAA به یک مرجع واحد برای نظارت و تجزیه و تحلیل عملکردهای AWS Glue تبدیل می شود. قبلاً تیمهای پشتیبانی برای دسترسی به آن نیاز داشتند کنسول مدیریت AWS و مراحل دستی را برای این دید انجام دهید. این ویژگی به طور پیش فرض از Amazon MWAA نسخه 2.4.3 در دسترس است.
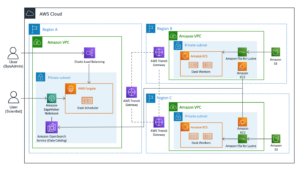
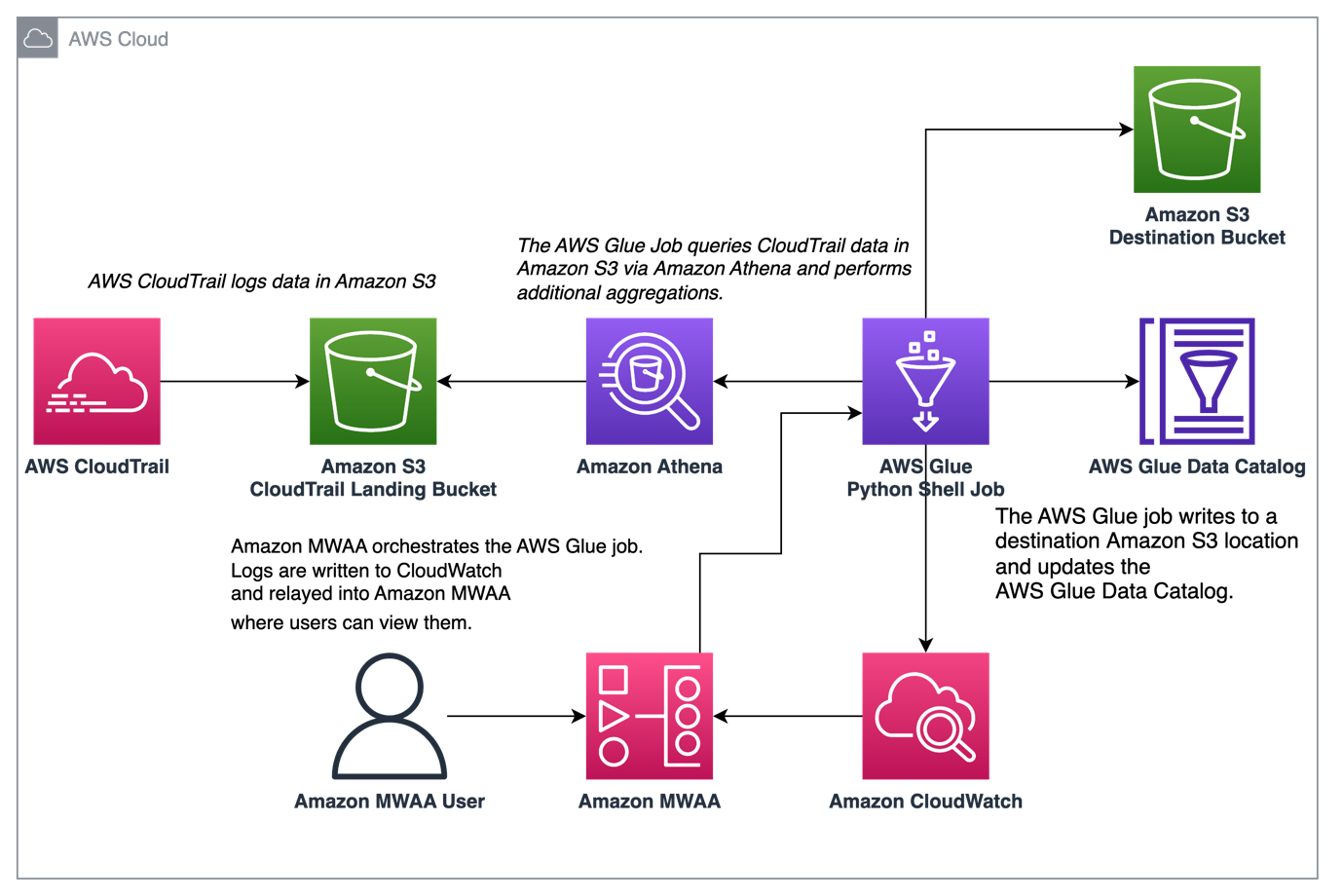
نمودار زیر معماری راه حل ما را نشان می دهد.
پیش نیازها
شما به پیش نیازهای زیر نیاز دارید:
محیط آمازون MWAA را تنظیم کنید
برای دستورالعمل های مربوط به ایجاد محیط خود، به یک محیط آمازون MWAA ایجاد کنید. برای کاربران فعلی، توصیه میکنیم به نسخه 2.4.3 ارتقا دهید تا از پیشرفتهای مشاهدهپذیری ارائه شده در این پست استفاده کنند.
مراحل ارتقاء آمازون MWAA به نسخه 2.4.3 بسته به اینکه نسخه فعلی 1.10.12 یا 2.2.2 باشد متفاوت است. ما در این پست به هر دو گزینه می پردازیم.
پیش نیازهای راه اندازی یک محیط آمازون MWAA
شما باید پیش نیازهای زیر را داشته باشید:
از نسخه 1.10.12 به 2.4.3 ارتقا دهید
اگر از نسخه آمازون MWAA استفاده می کنید 1.10.12، رجوع شود به مهاجرت به یک محیط جدید آمازون MWAA برای ارتقاء به 2.4.3.
از نسخه 2.0.2 یا 2.2.2 به 2.4.3 ارتقا دهید
اگر از محیط آمازون MWAA نسخه 2.2.2 یا پایین تر استفاده می کنید، مراحل زیر را انجام دهید:
- ایجاد یک requires.txt برای هر وابستگی سفارشی با نسخه های خاص مورد نیاز برای DAG های شما.
- فایل را در آمازون S3 آپلود کنید در محل مناسبی که محیط آمازون MWAA به الزامات.txt برای نصب وابستگی ها اشاره می کند.
- مراحل موجود را دنبال کنید مهاجرت به یک محیط جدید آمازون MWAA و نسخه 2.4.3 را انتخاب کنید.
DAG های خود را به روز کنید
مشتریانی که از یک محیط قدیمیتر آمازون MWAA ارتقا دادهاند، ممکن است نیاز به بهروزرسانی DAGهای موجود داشته باشند. در Airflow نسخه 2.4.3، محیط Airflow به طور پیش فرض از بسته ارائه دهنده آمازون نسخه 6.0.0 استفاده می کند. این بسته ممکن است شامل برخی تغییرات بالقوه شکسته شود، مانند تغییرات در نام اپراتورها. به عنوان مثال AWSGlueJobOperator منسوخ شده و با GlueJobOperator. برای حفظ سازگاری، DAG های جریان هوای خود را با جایگزین کردن اپراتورهای منسوخ یا پشتیبانی نشده از نسخه های قبلی با اپراتورهای جدید به روز کنید. مراحل زیر را کامل کنید:
- هدایت به اپراتورهای آمازون AWS.
- نسخه مناسب نصب شده در نمونه MWAA آمازون (به طور پیش فرض 6.0.0) را انتخاب کنید تا لیستی از اپراتورهای Airflow پشتیبانی شده را پیدا کنید.
- تغییرات لازم را در کد DAG موجود انجام دهید و فایل های اصلاح شده را در محل DAG در آمازون S3 آپلود کنید.
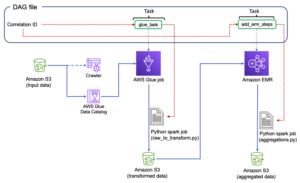
کار چسب AWS را از Airflow هماهنگ کنید
این بخش جزئیات تنظیم یک کار چسب AWS در DAG های جریان هوا را پوشش می دهد. جریان هوا توسعه خطوط لوله داده را با وابستگی بین سیستم های ناهمگن مانند فرآیندهای داخلی، وابستگی های خارجی، سایر خدمات AWS و موارد دیگر تسهیل می کند.
با AWS Glue و Amazon MWAA تجمیع گزارش CloudTrail را هماهنگ کنید
در این مثال، ما یک مورد استفاده از آمازون MWAA را برای سازماندهی یک کار AWS Glue Python Shell که معیارهای انبوه بر اساس گزارشهای CloudTrail را حفظ میکند، مرور میکنیم.
CloudTrail امکان مشاهده تماسهای AWS API را که در حساب AWS شما انجام میشود، فراهم میکند. یک مورد معمول استفاده از این دادهها، جمعآوری معیارهای استفاده از مدیرانی است که بر اساس منابع حساب شما برای نیازهای حسابرسی و نظارتی عمل میکنند.
همانطور که رویدادهای CloudTrail ثبت میشوند، بهعنوان فایلهای JSON در Amazon S3 تحویل داده میشوند که برای پرسوجوهای تحلیلی ایدهآل نیستند. ما میخواهیم این دادهها را جمعآوری کنیم و آنها را بهعنوان فایلهای Parquet حفظ کنیم تا عملکرد بهینه پرس و جو را فراهم کنیم. به عنوان گام اولیه، میتوانیم از Athena برای انجام جستجوی اولیه دادهها قبل از انجام تجمیعهای اضافی در کار چسب AWS خود استفاده کنیم. برای کسب اطلاعات بیشتر در مورد ایجاد جدول AWS Glue Data Catalog، مراجعه کنید ایجاد جدول برای گزارش های CloudTrail در آتنا با استفاده از طرح پارتیشن داده ها. بعد از اینکه داده ها را از طریق Athena بررسی کردیم و تصمیم گرفتیم که چه معیارهایی را می خواهیم در جداول جمع نگه داریم، می توانیم یک کار چسب AWS ایجاد کنیم.
یک جدول CloudTrail در آتنا ایجاد کنید
ابتدا باید جدولی در کاتالوگ داده خود ایجاد کنیم که به داده های CloudTrail از طریق Athena پرس و جو شود. پرس و جوی نمونه زیر یک جدول با دو پارتیشن در منطقه و تاریخ (به نام snapshot_date) ایجاد می کند. حتماً جایبانها را برای سطل CloudTrail، شناسه حساب AWS و نام جدول CloudTrail خود جایگزین کنید:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')کوئری قبلی را روی کنسول Athena اجرا کنید و نام جدول و پایگاه داده AWS Glue Data Catalog که در آن ایجاد شده است را یادداشت کنید. ما بعداً از این مقادیر در کد DAG Airflow استفاده می کنیم.
نمونه کار کد AWS Glue
کد زیر یک نمونه است AWS Glue Python Shell که کارهای زیر را انجام می دهد:
- استدلالهایی (که ما از آمازون MWAA DAG منتقل میکنیم) در مورد دادههای روز پردازش میگیرد
- استفاده می کند AWS SDK برای پانداها برای اجرای یک کوئری Athena برای انجام فیلتر اولیه داده های CloudTrail JSON خارج از AWS Glue
- از پانداها برای انجام تجمیع ساده روی داده های فیلتر شده استفاده می کند
- داده های جمع آوری شده را در جدولی به کاتالوگ داده چسب AWS خروجی می دهد
- از ورود به سیستم در طول پردازش استفاده می کند، که در آمازون MWAA قابل مشاهده خواهد بود
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
برخی از مزایای کلیدی این کار چسب AWS به شرح زیر است:
- ما از پرس و جوی Athena استفاده می کنیم تا مطمئن شویم که فیلتر اولیه خارج از کار چسب AWS ما انجام می شود. به این ترتیب، یک کار Python Shell با حداقل محاسبات هنوز برای جمعآوری یک مجموعه داده بزرگ CloudTrail کافی است.
- ما تضمین می کنیم گزینه analytics library-set هنگام ایجاد کار چسب AWS ما برای استفاده از AWS SDK برای کتابخانه پانداها روشن می شود.
یک کار چسب AWS ایجاد کنید
مراحل زیر را برای ایجاد کار چسب AWS خود تکمیل کنید:
- اسکریپت را در قسمت قبل کپی کرده و در یک فایل محلی ذخیره کنید. برای این پست، فایل نامیده می شود
script.py. - در کنسول AWS Glue، را انتخاب کنید مشاغل ETL در صفحه ناوبری
- یک کار جدید ایجاد کنید و انتخاب کنید ویرایشگر اسکریپت پایتون شل.
- انتخاب کنید یک اسکریپت موجود را آپلود و ویرایش کنید و فایلی را که ذخیره کرده اید به صورت محلی آپلود کنید.
- را انتخاب کنید ساختن.

- بر جزئیات شغل برگه، یک نام برای کار چسب AWS خود وارد کنید.
- برای نقش IAM، یک نقش موجود را انتخاب کنید یا یک نقش جدید ایجاد کنید که دارای مجوزهای لازم برای Amazon S3، AWS Glue و Athena باشد. نقش باید جدول CloudTrail را که قبلاً ایجاد کردهاید پرس و جو کند و در یک مکان خروجی بنویسد.
می توانید از نمونه کد خط مشی زیر استفاده کنید. مکانها را با سطل گزارشهای CloudTrail، نام جدول خروجی، پایگاه داده AWS Glue خروجی، سطل خروجی S3، نام جدول CloudTrail، پایگاه داده AWS Glue حاوی جدول CloudTrail و شناسه حساب AWS خود جایگزین کنید.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
برای نسخه پایتون، انتخاب کنید پایتون 3.9.
- انتخاب کنید بارگذاری کتابخانه های رایج تجزیه و تحلیل.
- برای واحدهای پردازش داده، انتخاب کنید 1 DPU.
- گزینه های دیگر را به عنوان پیش فرض بگذارید یا در صورت نیاز تنظیم کنید.

- را انتخاب کنید ذخیره برای ذخیره تنظیمات شغلی خود
یک آمازون MWAA DAG را برای هماهنگ کردن کار چسب AWS پیکربندی کنید
کد زیر برای یک DAG است که می تواند کار AWS Glue را که ما ایجاد کردیم هماهنگ کند. ما از ویژگی های کلیدی زیر در این DAG استفاده می کنیم:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
قابلیت مشاهده کارهای چسب AWS را در آمازون MWAA افزایش دهید
کارهای AWS Glue گزارشها را مینویسند CloudWatch آمازون. با پیشرفتهای اخیر قابلیت مشاهده در بسته ارائهدهنده آمازون Airflow، این گزارشها اکنون با گزارشهای کار Airflow یکپارچه شدهاند. این ادغام به کاربران Airflow امکان دید سرتاسری را مستقیماً در رابط کاربری Airflow فراهم میکند و نیاز به جستجو در CloudWatch یا کنسول AWS Glue را از بین میبرد.
برای استفاده از این ویژگی، مطمئن شوید که نقش IAM متصل به محیط آمازون MWAA دارای مجوزهای زیر برای بازیابی و نوشتن گزارشهای لازم است:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}اگر verbose=true، گزارشهای اجرای کار چسب AWS در گزارشهای کار جریان هوا نشان داده میشود. حالت پیش فرض غلط است. برای اطلاعات بیشتر مراجعه کنید پارامترهای.
وقتی فعال باشد، DAG ها از جریان گزارش CloudWatch کار چسب AWS خوانده و آنها را به گزارش مراحل کار چسب AWS Airflow ارسال می کنند. این اطلاعات بینش دقیقی را در مورد اجرای کار چسب AWS در زمان واقعی از طریق گزارشهای DAG ارائه میکند. توجه داشته باشید که کارهای چسب AWS به ترتیب بر اساس STDOUT و STDERR کار، یک گروه گزارش CloudWatch خروجی و خطا ایجاد می کنند. همه گزارشها در گروه گزارش خروجی و گزارشهای استثنا یا خطا از گروه ثبت خطا به آمازون MWAA منتقل میشوند.
مدیران AWS اکنون میتوانند دسترسی تیم پشتیبانی را فقط به Airflow محدود کنند، و آمازون MWAA را به شیشهای واحد در سازماندهی کار و مدیریت سلامت شغل تبدیل کنند. قبلاً، کاربران باید وضعیت اجرای کار AWS Glue را در مراحل Airflow DAG بررسی کرده و شناسه اجرای کار را بازیابی کنند. سپس آنها باید به کنسول AWS Glue دسترسی داشته باشند تا تاریخچه اجرای کار را پیدا کنند، شغل مورد علاقه را با استفاده از شناسه جستجو کنند، و در نهایت به گزارشهای CloudWatch کار برای عیبیابی پیمایش کنند.
DAG را ایجاد کنید
برای ایجاد DAG مراحل زیر را انجام دهید:
- کد DAG قبلی را در یک فایل .py محلی ذخیره کنید و جای جایبانهای مشخص شده را جایگزین کنید.
مقادیر شناسه حساب AWS شما، نام شغل AWS Glue، پایگاه داده AWS Glue با جدول CloudTrail و نام جدول CloudTrail باید از قبل مشخص باشد. میتوانید سطل خروجی S3، پایگاه داده AWS Glue خروجی و نام جدول خروجی را در صورت نیاز تنظیم کنید، اما مطمئن شوید که نقش IAM کار چسب AWS که قبلاً استفاده کردهاید، بر این اساس پیکربندی شده است.
- در کنسول آمازون MWAA، به محیط خود بروید تا ببینید کد DAG در کجا ذخیره شده است.
پوشه DAGs پیشوند درون سطل S3 است که فایل DAG شما باید در آن قرار گیرد.
- فایل ویرایش شده خود را در آنجا آپلود کنید.

- کنسول آمازون MWAA را باز کنید تا تأیید کنید که DAG در جدول ظاهر می شود.

DAG را اجرا کنید
برای اجرای DAG مراحل زیر را انجام دهید:
- از گزینه های زیر انتخاب کنید:
- ماشه DAG - این باعث می شود که از داده های دیروز به عنوان داده برای پردازش استفاده شود
- ماشه DAG با پیکربندی - با استفاده از این گزینه می توانید تاریخ متفاوتی را به طور بالقوه برای backfills ارسال کنید که با استفاده از آن بازیابی می شود
dag_run.confدر کد DAG و سپس به عنوان پارامتر به کار چسب AWS منتقل می شود

تصویر زیر در صورت انتخاب گزینه های پیکربندی اضافی را نشان می دهد ماشه DAG با پیکربندی.

- DAG را هنگام اجرا نظارت کنید.
- وقتی DAG کامل شد، جزئیات اجرا را باز کنید.
در قسمت سمت راست، میتوانید گزارشها را مشاهده کنید یا انتخاب کنید جزئیات نمونه کار برای مشاهده کامل

- مشاهده گزارش خروجی کار AWS Glue در آمازون MWAA بدون استفاده از کنسول AWS Glue به لطف
GlueJobOperatorپرچم پرمخاطب

کار چسب AWS نتایج نوشته شده در جدول خروجی که شما مشخص کرده اید خواهد داشت.
- برای تأیید موفقیت آمیز بودن جدول، از طریق آتنا پرس و جو کنید.
خلاصه
آمازون MWAA اکنون یک مکان واحد برای ردیابی وضعیت کار چسب AWS فراهم میکند و به شما امکان میدهد از کنسول Airflow بهعنوان شیشهای واحد برای هماهنگی کار و مدیریت سلامت استفاده کنید. در این پست، ما مراحل را برای هماهنگ کردن کارهای چسب AWS از طریق Airflow با استفاده از GlueJobOperator. با پیشرفتهای جدید قابلیت مشاهده، میتوانید بهطور یکپارچه کارهای چسب AWS را در یک تجربه یکپارچه عیبیابی کنید. ما همچنین نشان دادیم که چگونه میتوان محیط آمازون MWAA خود را به نسخهای سازگار ارتقا داد، وابستگیها را بهروزرسانی کرد و بر این اساس خطمشی نقش IAM را تغییر داد.
برای کسب اطلاعات بیشتر در مورد مراحل رایج عیب یابی، مراجعه کنید عیب یابی: ایجاد و به روز رسانی محیط آمازون MWAA. برای جزئیات عمیق مهاجرت به یک محیط آمازون MWAA، مراجعه کنید ارتقا از 1.10 به 2. برای اطلاع از تغییرات کد منبع باز برای افزایش قابلیت مشاهده کارهای چسب AWS در بسته ارائه دهنده Airflow Amazon، به رله سیاهههای مربوط از AWS Glue jobs.
در نهایت توصیه می کنیم از وبلاگ AWS Big Data برای سایر مطالب در مورد تجزیه و تحلیل، ML، و حاکمیت داده در AWS.
درباره نویسنده
 رشابه لوخنده یک مهندس داده و ML با تمرین تجزیه و تحلیل خدمات حرفه ای AWS است. او به مشتریان کمک می کند تا راه حل های کلان داده، یادگیری ماشین و تجزیه و تحلیل را پیاده سازی کنند. خارج از محل کار، او از گذراندن وقت با خانواده، مطالعه، دویدن و گلف لذت می برد.
رشابه لوخنده یک مهندس داده و ML با تمرین تجزیه و تحلیل خدمات حرفه ای AWS است. او به مشتریان کمک می کند تا راه حل های کلان داده، یادگیری ماشین و تجزیه و تحلیل را پیاده سازی کنند. خارج از محل کار، او از گذراندن وقت با خانواده، مطالعه، دویدن و گلف لذت می برد.
 رایان گومز یک مهندس داده و ML با تمرین تجزیه و تحلیل خدمات حرفه ای AWS است. او مشتاق کمک به مشتریان برای دستیابی به نتایج بهتر از طریق تجزیه و تحلیل و راه حل های یادگیری ماشین در فضای ابری است. خارج از محل کار، او از تناسب اندام، آشپزی و گذراندن زمان با کیفیت با دوستان و خانواده لذت می برد.
رایان گومز یک مهندس داده و ML با تمرین تجزیه و تحلیل خدمات حرفه ای AWS است. او مشتاق کمک به مشتریان برای دستیابی به نتایج بهتر از طریق تجزیه و تحلیل و راه حل های یادگیری ماشین در فضای ابری است. خارج از محل کار، او از تناسب اندام، آشپزی و گذراندن زمان با کیفیت با دوستان و خانواده لذت می برد.
 ویشوا گوپتا یک معمار ارشد داده با تمرین تجزیه و تحلیل خدمات حرفه ای AWS است. او به مشتریان کمک می کند تا راه حل های کلان داده و تجزیه و تحلیل را پیاده سازی کنند. خارج از محل کار، او از گذراندن وقت با خانواده، مسافرت و امتحان غذای جدید لذت می برد.
ویشوا گوپتا یک معمار ارشد داده با تمرین تجزیه و تحلیل خدمات حرفه ای AWS است. او به مشتریان کمک می کند تا راه حل های کلان داده و تجزیه و تحلیل را پیاده سازی کنند. خارج از محل کار، او از گذراندن وقت با خانواده، مسافرت و امتحان غذای جدید لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoAiStream. Web3 Data Intelligence دانش تقویت شده دسترسی به اینجا.
- ضرب کردن آینده با آدرین اشلی. دسترسی به اینجا.
- خرید و فروش سهام در شرکت های PRE-IPO با PREIPO®. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 10
- 100
- 12
- 8
- a
- درباره ما
- دسترسی
- بر این اساس
- حساب
- رسیدن
- در میان
- عمل
- حلقوی
- اضافی
- مزیت - فایده - سود - منفعت
- مزایای
- پس از
- تجمع
- معرفی
- اجازه دادن
- اجازه می دهد تا
- قبلا
- همچنین
- آمازون
- آمازون خدمات وب
- an
- تحلیلی
- علم تجزیه و تحلیل
- تحلیل
- و
- هر
- آپاچی
- API
- کاربرد
- برنامه توسعه
- مناسب
- معماری
- هستند
- استدلال
- استدلال
- AS
- At
- خواص
- حسابرسی
- در دسترس
- AWS
- چسب AWS
- خدمات حرفه ای AWS
- مستقر
- BE
- شود
- بوده
- قبل از
- بودن
- بهتر
- میان
- بزرگ
- بزرگ داده
- هر دو
- شکستن
- ساختن
- اما
- by
- نام
- تماس ها
- CAN
- مورد
- موارد
- کاتالوگ
- علل
- تغییر دادن
- تبادل
- بررسی
- را انتخاب کنید
- ابر
- رمز
- COM
- ترکیب
- توضیح
- مشترک
- شرکت
- سازگاری
- سازگار
- کامل
- پیچیده
- جزء
- اجزاء
- محاسبه
- پیکر بندی
- تکرار
- کنسول
- محکم کردن
- تثبیت
- پخت و پز
- هسته
- را پوشش می دهد
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- جاری
- سفارشی
- مشتری
- مشتریان
- DAG
- داده ها
- یکپارچه سازی داده ها
- پردازش داده ها
- استراتژی داده
- انبارهای داده
- پایگاه داده
- پایگاه های داده
- مجموعه داده ها
- تاریخ
- تاریخ
- زمان قرار
- روز
- مصمم
- به طور پیش فرض
- تحویل داده
- نشان
- بستگی دارد
- منسوخ
- دقیق
- جزئیات
- پروژه
- متفاوت است
- مختلف
- دیجیتال
- رسانه دیجیتال
- مستقیما
- بحث و تبادل نظر
- توزیع شده
- سیستم های توزیع شده
- do
- میکند
- عمل
- انجام شده
- در طی
- e
- پیش از آن
- سهولت
- اثر
- از بین بردن
- دیگر
- قادر ساختن
- فعال
- را قادر می سازد
- پشت سر هم
- نامزدی
- مهندس
- پیشرفت ها
- اطمینان حاصل شود
- وارد
- محیط
- خطا
- اتر (ETH)
- حوادث
- مثال
- جز
- استثنا
- وجود داشته باشد
- موجود
- وجود دارد
- تجربه
- تجارب
- کشف
- بیان
- خارجی
- عصاره
- ناموفق
- غلط
- خانواده
- ویژگی
- ویژه
- امکانات
- پرونده
- فایل ها
- فیلتر
- سرانجام
- پیدا کردن
- سازگاری
- پیروی
- غذا
- برای
- قالب
- دوستان
- از جانب
- کامل
- جمع آوری
- تولید می کنند
- شیشه
- Go
- گلف
- حکومت
- گروه
- هادوپ
- آیا
- he
- سلامتی
- کمک
- کمک می کند
- تاریخ
- کندو
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- IAM
- ID
- دلخواه
- ایده ها
- شناسه
- if
- نشان می دهد
- انجام
- واردات
- in
- در عمق
- شامل
- از جمله
- افزایش
- افزایش
- نشان داد
- لوازم
- اطلاعات
- اطلاعات
- اول
- ابتکاری
- بینش
- نصب کردن
- نمونه
- دستورالعمل
- یکپارچه
- ادغام
- علاقه
- داخلی
- به
- IT
- کار
- شغل ها
- JPG
- json
- کلید
- شناخته شده
- بزرگ
- بعد
- آخرین
- یاد گرفتن
- یادگیری
- کتابخانه
- محدود
- فهرست
- بار
- محلی
- به صورت محلی
- محل
- ورود به سیستم
- سیستم وارد
- ورود به سیستم
- به دنبال
- دستگاه
- فراگیری ماشین
- ساخته
- حفظ
- ساخت
- ساخت
- اداره می شود
- مدیریت
- مدیریت
- کتابچه راهنمای
- ماده
- ممکن است..
- رسانه ها
- دیدار
- پیام
- متریک
- مهاجرت
- حداقل
- ML
- اصلاح شده
- واحد
- مانیتور
- نظارت بر
- بیش
- باید
- نام
- نام
- هدایت
- جهت یابی
- لازم
- نیاز
- ضروری
- نیازهای
- جدید
- هیچ چی
- اکنون
- of
- ارائه
- on
- ONE
- آنهایی که
- فقط
- باز کن
- منبع باز
- کد منبع باز
- اپراتور
- اپراتور
- بهینه
- گزینه
- گزینه
- or
- هماهنگ شده
- تنظیم و ارکستراسیون
- دیگر
- ما
- نتایج
- تولید
- خارج از
- بسته
- پانداها
- قطعه
- پارامترهای
- شریک
- عبور
- گذشت
- احساساتی
- کارایی
- مجوز
- همچنان ادامه دارد
- خط لوله
- محل
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- سیاست
- پست
- بالقوه
- تمرین
- پیش نیازها
- قبلی
- قبلا
- روند
- فرآیندهای
- در حال پردازش
- محصولات
- حرفه ای
- حرفه ای
- پروفایل
- طرح
- ارائه دهنده
- ارائه دهندگان
- فراهم می کند
- پــایتــون
- کیفیت
- نمایش ها
- بالا بردن
- محدوده
- خواندن
- مطالعه
- واقعی
- زمان واقعی
- اخیر
- توصیه
- منطقه
- تنظیم کننده
- رله
- جایگزین کردن
- جایگزین
- ضروری
- مورد نیاز
- منابع
- منابع
- به ترتیب
- پاسخ
- نتایج
- نگه داشتن
- راست
- نقش
- ROW
- دویدن
- در حال اجرا
- s
- ذخیره
- سناریوها
- sdk
- یکپارچه
- جستجو
- بخش
- امن
- دیدن
- به دنبال
- ارشد
- بدون سرور
- خدمات
- محیط
- برپایی
- صدف
- باید
- نشان
- نشان می دهد
- ساده
- ساده کردن
- پس از
- تنها
- عکس فوری
- راه حل
- مزایا
- برخی از
- خاص
- مشخص شده
- هزینه
- بیانیه
- وضعیت
- گام
- مراحل
- هنوز
- ذخیره سازی
- ذخیره شده
- استراتژی
- جریان
- رشته
- موفق
- چنین
- کافی
- پشتیبانی
- پشتیبانی
- سیستم های
- جدول
- گرفتن
- مصرف
- کار
- تیم ها
- فن آوری
- قالب
- با تشکر
- که
- La
- شان
- آنها
- سپس
- آنجا.
- اینها
- آنها
- شخص ثالث
- این
- از طریق
- زمان
- به
- مسیر
- دگرگون کردن
- سفر
- درست
- امتحان
- سه شنبه
- تبدیل
- دو
- نوع
- ui
- یکپارچه
- واحد
- بروزرسانی
- به روز رسانی
- به روز رسانی
- ارتقاء
- به روز رسانی
- آپلود
- استفاده
- استفاده کنید
- مورد استفاده
- استفاده
- کاربران
- با استفاده از
- ارزش
- ارزشها
- نسخه
- از طريق
- چشم انداز
- نمایش ها
- دید
- قابل رویت
- راه می رفت
- می خواهم
- بود
- we
- وب
- خدمات وب
- خوب
- چی
- چه زمانی
- چه
- که
- WHO
- اراده
- با
- در داخل
- بدون
- مهاجرت کاری
- گردش کار
- خواهد بود
- نوشتن
- کتبی
- شما
- شما
- زفیرنت