آمازون Redshift یک انبار داده ابری سریع و کاملاً مدیریت شده در مقیاس پتابایت است که تجزیه و تحلیل تمام داده های شما را با استفاده از SQL استاندارد و ابزارهای هوش تجاری (BI) موجود شما ساده و مقرون به صرفه می کند. امروزه ده ها هزار مشتری از Amazon Redshift برای تجزیه و تحلیل اگزابایت داده و اجرای پرس و جوهای تحلیلی استفاده می کنند که آن را به پرکاربردترین انبار داده ابری تبدیل می کند. Amazon Redshift در هر دو پیکربندی بدون سرور و ارائه شده در دسترس است.
Amazon Redshift شما را قادر می سازد مستقیماً به داده های ذخیره شده در آن دسترسی داشته باشید سرویس ذخیره سازی ساده آمازون (Amazon S3) با استفاده از پرس و جوهای SQL و پیوستن به داده ها در انبار داده و دریاچه داده شما. با Amazon Redshift، میتوانید دادههای موجود در دریاچه داده S3 خود را با استفاده از یک مرکز جستجو کنید چسب AWS metastore از انبار داده Redshift شما.
Amazon Redshift از پرس و جو از طیف گسترده ای از فرمت های داده مانند CSV، JSON، Parquet و ORC و فرمت های جدول مانند Apache Hudi و Delta پشتیبانی می کند. Amazon Redshift همچنین از پرس و جو داده های تو در تو با انواع داده های پیچیده مانند ساختار، آرایه و نقشه پشتیبانی می کند.
با این قابلیت، Amazon Redshift انبار داده در مقیاس پتابایت شما را به یک دریاچه داده در مقیاس اگزابایت در Amazon S3 به روشی مقرون به صرفه گسترش می دهد.
Apache Iceberg آخرین فرمت جدول است که اکنون در پیش نمایش توسط Amazon Redshift پشتیبانی می شود. در این پست، ما به شما نشان می دهیم که چگونه با استفاده از Amazon Redshift جداول Iceberg را پرس و جو کنید، و پشتیبانی و گزینه های Iceberg را بررسی کنید.
بررسی اجمالی راه حل
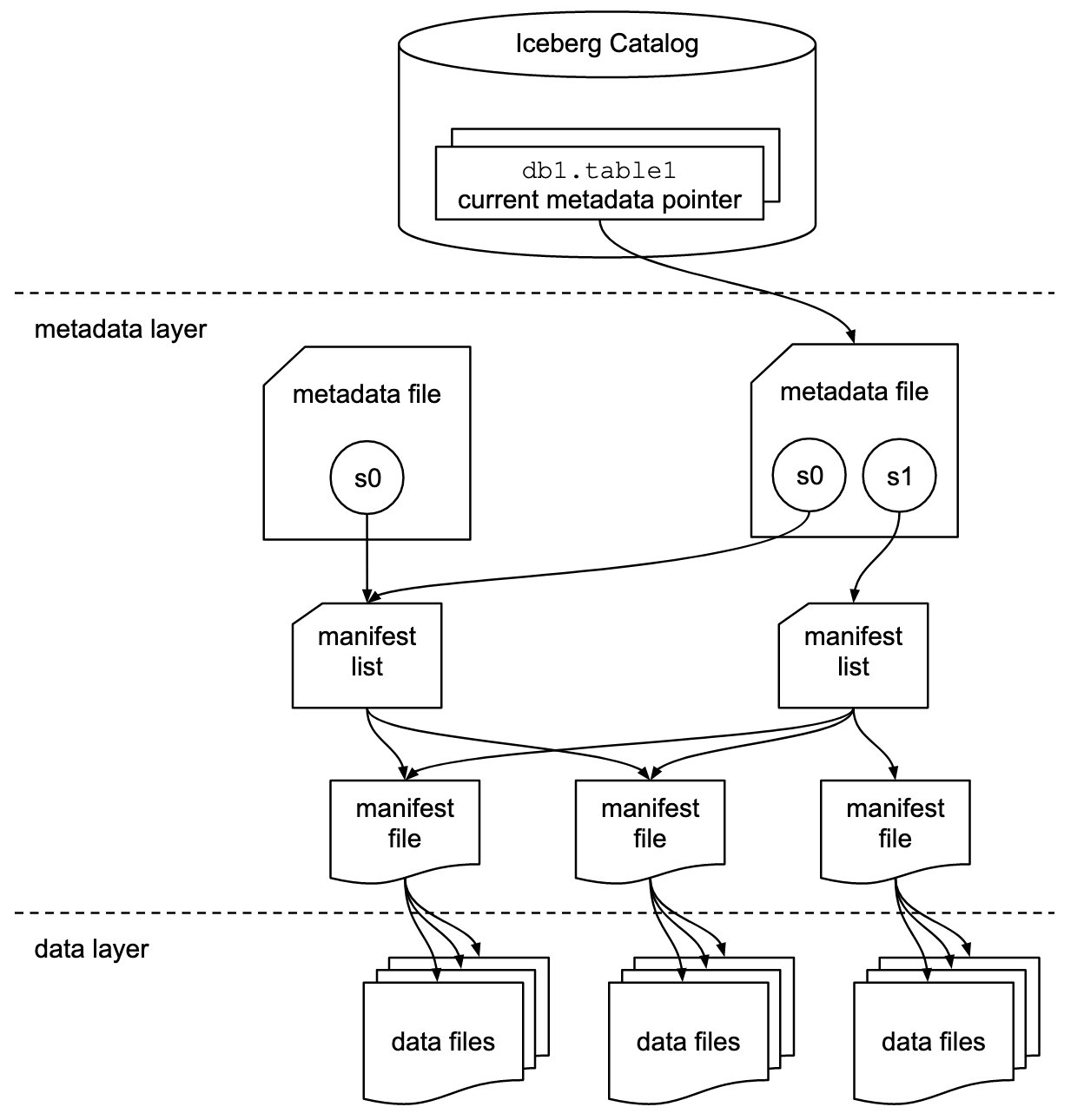
کوه یخ آپاچی یک قالب جدول باز برای مجموعه داده های تحلیلی بسیار بزرگ در مقیاس پتابایت است. Iceberg مجموعههای بزرگی از فایلها را بهعنوان جداول مدیریت میکند و از عملیاتهای دریاچه دادههای تحلیلی مدرن مانند درج سطح رکورد، بهروزرسانی، حذف، و درخواستهای سفر در زمان پشتیبانی میکند. مشخصات Iceberg امکان تکامل جدول بدون درز مانند تکامل طرحواره و پارتیشن را فراهم می کند و طراحی آن برای استفاده در Amazon S3 بهینه شده است.
Iceberg نشانگر فراداده را برای همه فایل های ابرداده ذخیره می کند. هنگامی که یک کوئری SELECT در حال خواندن جدول Iceberg است، موتور پرس و جو ابتدا به کاتالوگ Iceberg می رود، سپس ورودی محل آخرین فایل ابرداده را بازیابی می کند، همانطور که در نمودار زیر نشان داده شده است.
Amazon Redshift اکنون از جداول Apache Iceberg پشتیبانی می کند، که به مشتریان دریاچه داده اجازه می دهد تا پرس و جوهای تجزیه و تحلیل فقط خواندنی را به روشی سازگار از نظر تراکنش اجرا کنند. این به شما امکان می دهد به راحتی جداول خود را در دریاچه های داده تراکنشی مدیریت و نگهداری کنید.
Amazon Redshift از طرح بومی Apache Iceberg و قابلیت های تکامل پارتیشن با استفاده از کاتالوگ داده چسب AWS، حذف نیاز به تغییر تعاریف جدول برای افزودن پارتیشن های جدید یا جابجایی و پردازش مقادیر زیادی از داده ها برای تغییر طرح جدول دریاچه داده های موجود. Amazon Redshift از آمار ستون های ذخیره شده در ابرداده جدول Apache Iceberg برای بهینه سازی طرح های پرس و جو و کاهش اسکن فایل مورد نیاز برای اجرای پرس و جوها استفاده می کند.
در این پست از مجموعه داده عمومی تاکسی زرد از کمیسیون تاکسی و لیموزین نیویورک به عنوان داده های منبع ما مجموعه داده شامل فایل های داده در است پارکت آپاچی فرمت در آمازون S3. ما استفاده می کنیم آمازون آتنا برای تبدیل این مجموعه داده پارکت و سپس استفاده از آمازون Redshift Spectrum برای پرس و جو و پیوستن به یک جدول محلی Redshift، انجام حذفها و بهروزرسانیها و تکامل پارتیشن در سطح ردیف، همه از طریق کاتالوگ داده چسب AWS در دریاچه داده S3 هماهنگ شدهاند.
پیش نیازها
شما باید پیش نیازهای زیر را داشته باشید:
تبدیل داده های پارکت به میز کوه یخی
برای این پست، شما نیاز دارید مجموعه داده عمومی تاکسی زرد از کمیسیون تاکسی و لیموزین نیویورک در قالب Iceberg موجود است. می توانید فایل ها را دانلود کنید و سپس از Athena برای تبدیل مجموعه داده های پارکت به جدول Iceberg استفاده کنید یا به با استفاده از آمازون آتنا، آمازون EMR و چسب AWS یک دریاچه دادههای کوه یخ آپاچی بسازید. پست وبلاگ برای ایجاد جدول کوه یخ.
در این پست از آتنا برای تبدیل داده ها استفاده می کنیم. مراحل زیر را کامل کنید:
- فایل ها را با استفاده از لینک قبلی دانلود کنید یا از آن استفاده کنید رابط خط فرمان AWS (AWS CLI) برای کپی کردن فایل ها از سطل عمومی S3 برای سال 2020 و 2021 در سطل S3 خود با استفاده از دستور زیر:
برای اطلاعات بیشتر به مراجعه کنید راه اندازی Amazon Redshift CLI.
- یک پایگاه داده ایجاد کنید
Icebergdbو یک جدول با استفاده از Athena ایجاد کنید که به فایل های فرمت Parquet اشاره می کند با استفاده از عبارت زیر: - داده های جدول پارکت را با استفاده از SQL زیر اعتبار سنجی کنید:

- با کد زیر یک جدول Iceberg در آتنا ایجاد کنید. در ادامه می توانید ویژگی های نوع جدول را به صورت جدول Iceberg با فرمت پارکت و فشرده سازی سریع مشاهده کنید.
create tableبیانیه. قبل از اجرای SQL باید مکان S3 را به روز کنید. همچنین توجه داشته باشید که جدول Iceberg با پارتیشن بندی شده استYearکلیدی - پس از ایجاد جدول، داده ها را با استفاده از جدول پارکت بارگذاری شده قبلی در جدول Iceberg بارگذاری کنید
nyc_taxi_yellow_parquetبا SQL زیر: - هنگامی که دستور SQL کامل شد، داده های جدول Iceberg را تأیید کنید
nyc_taxi_yellow_iceberg. این مرحله قبل از رفتن به مرحله بعدی الزامی است. - می توانید تأیید کنید که جدول nyc_taxi_yellow_iceberg در جدول فرمت Iceberg است و با استفاده از دستور زیر در ستون Year تقسیم شده است:



یک طرح واره خارجی در Amazon Redshift ایجاد کنید
در این بخش، نحوه ایجاد یک طرحواره خارجی در آمازون Redshift با اشاره به پایگاه داده AWS Glue را نشان می دهیم. icebergdb برای پرس و جو از جدول کوه یخ nyc_taxi_yellow_iceberg که در قسمت قبل با استفاده از آتنا دیدیم.
از طریق Redshift وارد شوید ویرایشگر Query v2 یا یک کلاینت SQL و دستور زیر را اجرا کنید (توجه داشته باشید که پایگاه داده AWS Glue icebergdb و اطلاعات منطقه استفاده می شود):

برای آشنایی با ایجاد طرحواره های خارجی در Amazon Redshift به ادامه مطلب مراجعه کنید ایجاد طرحواره خارجی
پس از ایجاد طرحواره خارجی spectrum_iceberg_schema، می توانید جدول Iceberg را در Amazon Redshift جستجو کنید.
جدول Iceberg را در Amazon Redshift جستجو کنید
کوئری زیر را در Query Editor v2 اجرا کنید. توجه داشته باشید که spectrum_iceberg_schema نام طرحواره خارجی ایجاد شده در Amazon Redshift و nyc_taxi_yellow_iceberg جدول موجود در پایگاه داده AWS Glue مورد استفاده در پرس و جو است:
خروجی دادههای پرس و جو در تصویر زیر نشان میدهد که جدول چسب AWS با فرمت Iceberg با استفاده از Redshift Spectrum قابل استعلام است.

طرح توضیحی پرس و جو از جدول کوه یخ را بررسی کنید
می توانید از کوئری زیر برای دریافت خروجی توضیح طرح استفاده کنید که فرمت آن را نشان می دهد ICEBERG:

اعتبارسنجی به روز رسانی ها برای سازگاری داده ها
پس از تکمیل بهروزرسانی در جدول Iceberg، میتوانید از Amazon Redshift پرس و جو کنید تا نمای منسجم تراکنش دادهها را ببینید. بیایید یک پرس و جو را با انتخاب a اجرا کنیم vendorid و برای یک حمل و نقل خاص:

در مرحله بعد، مقدار را به روز کنید passenger_count به 4 و trip_distance به 9.4 برای یک vendorid و برخی از تاریخ های تحویل و تحویل در آتنا:

در نهایت، کوئری زیر را در Query Editor v2 اجرا کنید تا مقدار به روز شده را ببینید passenger_count و trip_distance:
همانطور که در تصویر زیر نشان داده شده است، عملیات به روز رسانی در جدول Iceberg در Amazon Redshift موجود است.

یک نمای یکپارچه از جدول محلی و داده های تاریخی در Amazon Redshift ایجاد کنید
به عنوان یک استراتژی معماری داده مدرن، میتوانید دادههای تاریخی یا دادههایی که کمتر به آنها دسترسی دارند را در دریاچه داده سازماندهی کنید و دادههایی را که به طور مکرر در دسترس هستند را در انبار داده Redshift نگهداری کنید. این انعطاف پذیری را برای مدیریت تجزیه و تحلیل در مقیاس و یافتن مقرون به صرفه ترین راه حل معماری فراهم می کند.
در این مثال، داده های 2 ساله را در جدول Redshift بارگذاری می کنیم. بقیه دادهها در دریاچه داده S3 باقی میمانند زیرا این مجموعه داده کمتر مورد پرسش قرار میگیرد.
- از کد زیر برای بارگیری داده های 2 ساله در برنامه استفاده کنید
nyc_taxi_yellow_recentجدول در آمازون Redshift، منبع یابی از جدول Iceberg:
- در مرحله بعد، می توانید داده های 2 سال گذشته را از جدول Iceberg با استفاده از دستور زیر در Athena حذف کنید زیرا در مرحله قبل داده ها را در جدول Redshift بارگذاری کرده اید:

پس از انجام این مراحل، جدول Redshift دارای 2 سال داده است و بقیه داده ها در جدول Iceberg در آمازون S3 است.
- با استفاده از
nyc_taxi_yellow_icebergمیز کوه یخ وnyc_taxi_yellow_recentجدول در آمازون Redshift: - اکنون نما را جستجو کنید، بسته به شرایط فیلتر، Redshift Spectrum داده های Iceberg، جدول Redshift یا هر دو را اسکن می کند. کوئری مثال زیر تعدادی رکورد از هر یک از جداول منبع را با اسکن هر دو جدول برمی گرداند:

تکامل پارتیشن
کوه یخ استفاده می کند پارتیشن بندی مخفی، به این معنی که شما نیازی به اضافه کردن دستی پارتیشن برای جداول Apache Iceberg خود ندارید. مقادیر پارتیشن جدید یا مشخصات پارتیشن جدید (افزودن یا حذف ستون های پارتیشن) در جداول Apache Iceberg به طور خودکار توسط Amazon Redshift شناسایی می شوند و برای به روز رسانی پارتیشن ها در تعریف جدول نیازی به عملیات دستی نیست. مثال زیر این را نشان می دهد.
در مثال ما، اگر جدول کوه یخ nyc_taxi_yellow_iceberg در ابتدا بر اساس سال و بعداً ستون تقسیم شد vendorid به عنوان یک ستون پارتیشن اضافی اضافه شد، سپس Amazon Redshift می تواند به طور یکپارچه جدول Iceberg را جستجو کند nyc_taxi_yellow_iceberg با دو طرح پارتیشن مختلف در یک دوره زمانی.

ملاحظات در هنگام استعلام جداول Iceberg با استفاده از Amazon Redshift
در طول دوره پیش نمایش، هنگام استفاده از Amazon Redshift با جداول Iceberg موارد زیر را در نظر بگیرید:
- فقط جداول Iceberg تعریف شده در کاتالوگ داده چسب AWS پشتیبانی می شود.
- دستورات جدول خارجی CREATE یا ALTER پشتیبانی نمی شوند، به این معنی که جدول Iceberg باید از قبل در پایگاه داده AWS Glue وجود داشته باشد.
- درخواست های سفر در زمان پشتیبانی نمی شود.
- Iceberg نسخه 1 و 2 پشتیبانی می شود. برای جزئیات بیشتر در مورد نسخه های فرمت Iceberg، مراجعه کنید قالب بندی نسخه.
- برای لیستی از انواع داده های پشتیبانی شده با جداول Iceberg، مراجعه کنید انواع داده های پشتیبانی شده با جداول Apache Iceberg (پیش نمایش).
- قیمت پرس و جو از جدول Iceberg مانند دسترسی به سایر فرمت های داده با استفاده از Amazon Redshift است.
برای جزئیات بیشتر در مورد ملاحظات مربوط به پیش نمایش جداول قالب Iceberg، مراجعه کنید استفاده از جداول Apache Iceberg با Amazon Redshift (پیش نمایش).
بازخورد مشتری
Tinuiti، بزرگترین شرکت بازاریابی عملکرد مستقل، حجم زیادی از دادهها را به صورت روزانه مدیریت میکند و باید یک استراتژی قوی داده و انبار داده برای تیمهای اطلاعاتی بازار ما برای ذخیره و تجزیه و تحلیل تمام دادههای مشتریان ما به صورت آسان، مقرون به صرفه و ایمن داشته باشد. جاستین مانوس، مدیر ارشد فناوری در Tinuiti میگوید. «پشتیبانی آمازون Redshift از جداول Apache Iceberg در دریاچه داده ما، که تنها منبع حقیقت است، به چالشی حیاتی در بهینهسازی عملکرد و دسترسپذیری میپردازد و خطوط لوله یکپارچهسازی دادههای ما را برای دسترسی به تمام دادههای دریافت شده از منابع مختلف و تامین انرژی ما سادهتر میکند. پتانسیل برند مشتریان.”
نتیجه
در این پست، نمونه ای از پرس و جو از جدول Iceberg در Redshift با استفاده از فایل های ذخیره شده در آمازون S3، فهرست بندی شده به عنوان جدول در کاتالوگ داده های چسب AWS، و برخی از ویژگی های کلیدی مانند به روز رسانی و حذف کارآمد در سطح ردیف را به شما نشان دادیم. و تجربه تکامل طرحواره برای کاربران برای باز کردن قدرت داده های بزرگ با استفاده از Athena.
می توانید از Amazon Redshift برای اجرای پرس و جو در جداول دریاچه داده در فایل ها و فرمت های مختلف جدول مانند آپاچی هودی و دریاچه دلتا، و اکنون با کوه یخ آپاچی (پیش نمایش)، که گزینه های اضافی را برای نیازهای معماری داده های مدرن شما فراهم می کند.
ما امیدواریم که این یک نقطه شروع عالی برای استعلام جداول Iceberg در Amazon Redshift باشد.
درباره نویسنده
 روهیت بانسال یک معمار راه حل های متخصص تجزیه و تحلیل در AWS است. او در Amazon Redshift تخصص دارد و با مشتریان برای ساخت راه حل های تحلیلی نسل بعدی با استفاده از سایر خدمات AWS Analytics کار می کند.
روهیت بانسال یک معمار راه حل های متخصص تجزیه و تحلیل در AWS است. او در Amazon Redshift تخصص دارد و با مشتریان برای ساخت راه حل های تحلیلی نسل بعدی با استفاده از سایر خدمات AWS Analytics کار می کند.
 ساتیش ساتیا یک مهندس ارشد محصول در Amazon Redshift است. او یک مشتاق مشتاق کلان داده است که با مشتریان در سراسر جهان برای دستیابی به موفقیت و برآورده کردن نیازهای انبار داده و معماری دریاچه داده آنها همکاری می کند.
ساتیش ساتیا یک مهندس ارشد محصول در Amazon Redshift است. او یک مشتاق مشتاق کلان داده است که با مشتریان در سراسر جهان برای دستیابی به موفقیت و برآورده کردن نیازهای انبار داده و معماری دریاچه داده آنها همکاری می کند.
 رنجان برمن یک معمار راه حل های متخصص تجزیه و تحلیل در AWS است. او در Amazon Redshift تخصص دارد و به مشتریان کمک می کند تا راه حل های تحلیلی مقیاس پذیر بسازند. وی بیش از 16 سال تجربه در زمینه فناوری های مختلف پایگاه داده و انبار داده دارد. او مشتاق اتوماسیون و حل مشکلات مشتریان با راه حل های ابری است.
رنجان برمن یک معمار راه حل های متخصص تجزیه و تحلیل در AWS است. او در Amazon Redshift تخصص دارد و به مشتریان کمک می کند تا راه حل های تحلیلی مقیاس پذیر بسازند. وی بیش از 16 سال تجربه در زمینه فناوری های مختلف پایگاه داده و انبار داده دارد. او مشتاق اتوماسیون و حل مشکلات مشتریان با راه حل های ابری است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. خودرو / خودروهای الکتریکی، کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- ChartPrime. بازی معاملاتی خود را با ChartPrime ارتقا دهید. دسترسی به اینجا.
- BlockOffsets. نوسازی مالکیت افست زیست محیطی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- درباره ما
- دسترسی
- قابل دسترسی است
- دسترسی
- دسترسی
- رسیدن
- در میان
- اضافه کردن
- اضافه
- اضافی
- آدرس
- مقرون به صرفه
- معرفی
- اجازه می دهد تا
- قبلا
- همچنین
- آمازون
- آمازون آتنا
- آمازون EMR
- آمازون خدمات وب
- مقدار
- an
- تحلیلی
- تحلیلی
- علم تجزیه و تحلیل
- تحلیل
- و
- هر
- آپاچی
- معماری
- هستند
- دور و بر
- صف
- AS
- At
- بطور خودکار
- اتوماسیون
- در دسترس
- AWS
- چسب AWS
- اساس
- زیرا
- قبل از
- بودن
- بزرگ
- بزرگ داده
- الزام آور
- بلاگ
- هر دو
- نام تجاری
- ساختن
- کسب و کار
- هوش تجاری
- by
- CAN
- قابلیت های
- قابلیت
- کاتالوگ
- مرکزی
- معین
- به چالش
- تغییر دادن
- رئیس
- مدیر ارشد فناوری
- مشتری
- ابر
- رمز
- مجموعه
- ستون
- ستون ها
- کامل
- پیچیده
- شرایط
- در نظر بگیرید
- ملاحظات
- استوار
- شامل
- تبدیل
- هماهنگ
- مقرون به صرفه
- ایجاد
- ایجاد شده
- ایجاد
- بحرانی
- مشتری
- اطلاعات مشتری
- مشتریان
- روزانه
- داده ها
- یکپارچه سازی داده ها
- دریاچه دریاچه
- انبار داده
- پایگاه داده
- مجموعه داده ها
- تاریخ
- به طور پیش فرض
- مشخص
- تعریف
- تعاریف
- دلتا
- نشان دادن
- نشان
- نشان می دهد
- بستگی دارد
- طرح
- جزئیات
- شناسایی شده
- برنامه نویس
- مختلف
- مستقیما
- آیا
- دو برابر
- دانلود
- هر
- به آسانی
- ساده
- سردبیر
- موثر
- هر دو
- از بین بردن
- را قادر می سازد
- موتور
- مهندس
- علاقهمند
- ورود
- اتر (ETH)
- تکامل
- مثال
- وجود داشته باشد
- موجود
- تجربه
- توضیح دهید
- اکتشاف
- گسترش می یابد
- خارجی
- اضافی
- FAST
- امکانات
- پرونده
- فایل ها
- فیلتر
- پیدا کردن
- شرکت
- نام خانوادگی
- انعطاف پذیری
- پیروی
- برای
- قالب
- غالبا
- از جانب
- کاملا
- بیشتر
- دریافت کنید
- می دهد
- زمین
- می رود
- بزرگ
- گروه
- دستگیره
- آیا
- he
- کمک می کند
- تاریخی
- امید
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- if
- in
- مستقل
- اطلاعات
- ادغام
- اطلاعات
- به
- IT
- ITS
- پیوستن
- JPG
- json
- جاستین
- نگاه داشتن
- کلید
- دریاچه
- بزرگ
- بزرگترین
- نام
- بعد
- آخرین
- یاد گرفتن
- کمتر
- پسندیدن
- محدود
- لاین
- ارتباط دادن
- فهرست
- بار
- محلی
- محل
- حفظ
- باعث می شود
- ساخت
- مدیریت
- اداره می شود
- مدیریت می کند
- روش
- کتابچه راهنمای
- دستی
- نقشه
- بازار
- بازار یابی (Marketing)
- به معنی
- دیدار
- متاداده
- مدرن
- بیش
- اکثر
- حرکت
- متحرک
- باید
- نام
- بومی
- نیاز
- ضروری
- نیازهای
- جدید
- بعد
- نسل بعدی
- نه
- توجه داشته باشید
- اکنون
- عدد
- نیویورک
- of
- افسر
- on
- باز کن
- عمل
- عملیات
- بهینه سازی
- بهینه
- بهینه سازی
- گزینه
- or
- در اصل
- دیگر
- ما
- تولید
- روی
- با ما
- احساساتی
- انجام دادن
- کارایی
- دوره
- برنامه
- برنامه
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- پست
- پتانسیل
- قدرت
- پیش نیازها
- پیش نمایش
- قبلی
- قبلا
- مشکلات
- روند
- محصول
- املاک
- فراهم می کند
- عمومی
- نمایش ها
- مطالعه
- سوابق
- كاهش دادن
- منطقه
- برداشتن
- جایگزین کردن
- ضروری
- REST
- بازده
- تنومند
- دویدن
- در حال اجرا
- همان
- دید
- می گوید:
- مقیاس پذیر
- مقیاس
- اسکن
- پویش
- اسکن
- طرح ها
- بدون درز
- یکپارچه
- بخش
- امن
- دیدن
- ارشد
- بدون سرور
- خدمات
- تنظیم
- باید
- نشان
- نشان داد
- نشان داده شده
- نشان می دهد
- ساده
- تنها
- راه حل
- مزایا
- حل کردن
- برخی از
- منبع
- منابع
- سپارش
- متخصص
- تخصص دارد
- مشخصات
- مشخصات
- طیف
- SQL
- استاندارد
- راه افتادن
- بیانیه
- ارقام
- گام
- مراحل
- ذخیره سازی
- opbevare
- ذخیره شده
- پرده
- استراتژی
- رشته
- موفقیت
- چنین
- پشتیبانی
- پشتیبانی
- پشتیبانی از
- جدول
- تیم ها
- فن آوری
- پیشرفته
- ده ها
- نسبت به
- که
- La
- منبع
- شان
- سپس
- اینها
- این
- هزاران نفر
- از طریق
- زمان
- سفر در زمان
- برچسب زمان
- به
- امروز
- ابزار
- معامله ای
- سفر
- حقیقت
- دو
- نوع
- انواع
- یکپارچه
- اتحادیه
- باز
- بروزرسانی
- به روز شده
- به روز رسانی
- استفاده
- استفاده کنید
- استفاده
- کاربران
- استفاده
- با استفاده از
- تصدیق
- ارزش
- ارزشها
- تنوع
- مختلف
- بسیار
- از طريق
- چشم انداز
- جلد
- انبار کالا
- انبارداری
- بود
- مسیر..
- we
- وب
- خدمات وب
- چه زمانی
- که
- WHO
- وسیع
- به طور گسترده ای
- اراده
- با
- با این نسخهها کار
- سال
- سال
- شما
- شما
- زفیرنت