امروز، ما مشتاقیم که در دسترس بودن Llama 2 inference و پشتیبانی تنظیم دقیق را اعلام کنیم. AWS Trainium و استنتاج AWS نمونه در Amazon SageMaker JumpStart. استفاده از نمونههای مبتنی بر AWS Trainium و Inferentia، از طریق SageMaker، میتواند به کاربران کمک کند تا هزینههای تنظیم دقیق را تا 50 درصد کاهش دهند و هزینههای استقرار را تا 4.7 برابر کاهش دهند، در حالی که تأخیر هر توکن را کاهش میدهند. Llama 2 یک مدل زبان متنی مولد رگرسیون خودکار است که از معماری ترانسفورماتور بهینه شده استفاده می کند. به عنوان یک مدل در دسترس عموم، Llama 2 برای بسیاری از وظایف NLP مانند طبقه بندی متن، تجزیه و تحلیل احساسات، ترجمه زبان، مدل سازی زبان، تولید متن و سیستم های گفتگو طراحی شده است. تنظیم دقیق و استقرار LLM ها، مانند Llama 2، برای رسیدن به عملکرد زمان واقعی برای ارائه تجربه خوب به مشتری می تواند پرهزینه یا چالش برانگیز باشد. Trainium و AWS Inferentia، فعال شده توسط نورون AWS کیت توسعه نرم افزار (SDK)، گزینه ای با کارایی بالا و مقرون به صرفه برای آموزش و استنتاج مدل های Llama 2 ارائه می دهد.
در این پست، نحوه استقرار و تنظیم دقیق Llama 2 را در نمونههای Trainium و AWS Inferentia در SageMaker JumpStart نشان میدهیم.
بررسی اجمالی راه حل
در این وبلاگ سناریوهای زیر را بررسی خواهیم کرد:
- Llama 2 را بر روی نمونه های AWS Inferentia در هر دو مورد استقرار دهید Amazon SageMaker Studio UI، با تجربه استقرار با یک کلیک، و SageMaker Python SDK.
- Llama 2 را در نمونههای Trainium در رابط کاربری SageMaker Studio و SageMaker Python SDK بهخوبی تنظیم کنید.
- برای نشان دادن اثربخشی تنظیم دقیق، عملکرد مدل Llama 2 تنظیم شده را با مدل از پیش آموزش دیده مقایسه کنید.
برای دستیابی به آن، به نمونه نوت بوک GitHub.
Llama 2 را با استفاده از SageMaker Studio UI و Python SDK روی نمونه های AWS Inferentia استقرار دهید.
در این بخش، نحوه استقرار Llama 2 را در نمونههای AWS Inferentia با استفاده از SageMaker Studio UI برای استقرار با یک کلیک و Python SDK نشان میدهیم.
مدل Llama 2 را در رابط کاربری SageMaker Studio کشف کنید
SageMaker JumpStart دسترسی به هر دو در دسترس عمومی و اختصاصی را فراهم می کند مدل های پایه. مدل های بنیاد از ارائه دهندگان شخص ثالث و اختصاصی نصب و نگهداری می شوند. به این ترتیب، آنها تحت مجوزهای مختلفی که توسط منبع مدل مشخص شده است منتشر می شوند. حتماً مجوز هر مدل فونداسیونی را که استفاده می کنید بررسی کنید. شما مسئول بررسی و پیروی از هرگونه شرایط مجوز قابل اجرا و اطمینان از قابل قبول بودن آنها برای موارد استفاده شما قبل از دانلود یا استفاده از محتوا هستید.
می توانید از طریق SageMaker JumpStart در SageMaker Studio UI و SageMaker Python SDK به مدل های پایه Llama 2 دسترسی داشته باشید. در این بخش به نحوه کشف مدل ها در SageMaker Studio می پردازیم.
SageMaker Studio یک محیط توسعه یکپارچه (IDE) است که یک رابط بصری مبتنی بر وب را فراهم می کند که در آن می توانید به ابزارهای ساخته شده برای انجام تمام مراحل توسعه یادگیری ماشین (ML)، از آماده سازی داده ها تا ساخت، آموزش و به کارگیری ML خود دسترسی داشته باشید. مدل ها. برای جزئیات بیشتر در مورد نحوه شروع و راه اندازی SageMaker Studio، مراجعه کنید Amazon SageMaker Studio.
بعد از اینکه در استودیوی SageMaker هستید، می توانید به SageMaker JumpStart که شامل مدل های از پیش آموزش دیده، نوت بوک ها و راه حل های از پیش ساخته شده است، دسترسی پیدا کنید. راه حل های از پیش ساخته شده و خودکار. برای اطلاعات دقیق تر در مورد نحوه دسترسی به مدل های اختصاصی، مراجعه کنید از مدل های پایه اختصاصی Amazon SageMaker JumpStart در Amazon SageMaker Studio استفاده کنید.
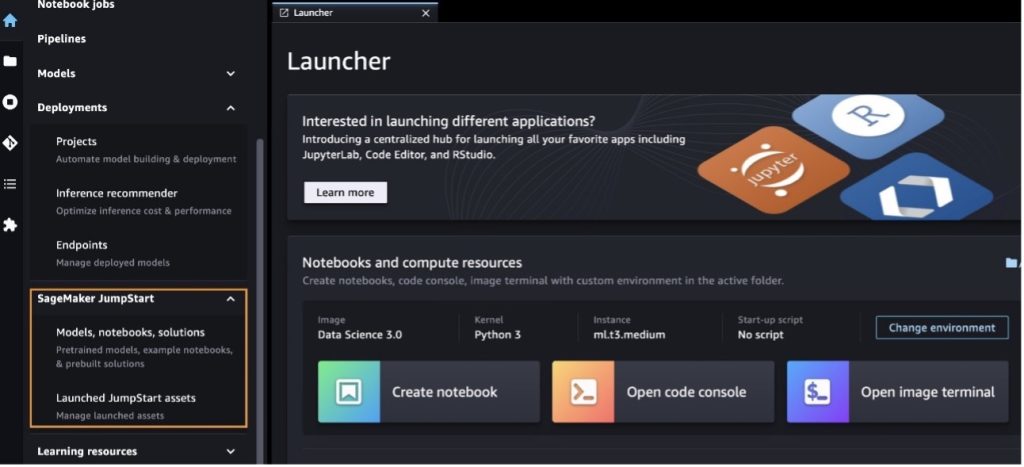
از صفحه فرود SageMaker JumpStart، می توانید راه حل ها، مدل ها، نوت بوک ها و منابع دیگر را جستجو کنید.
اگر مدلهای Llama 2 را نمیبینید، نسخه SageMaker Studio خود را با خاموش کردن و راهاندازی مجدد بهروزرسانی کنید. برای اطلاعات بیشتر در مورد به روز رسانی نسخه، مراجعه کنید برنامه های کلاسیک استودیو را خاموش و به روز کنید.

شما همچنین می توانید مدل های دیگر را با انتخاب پیدا کنید تمام مدل های تولید متن را کاوش کنید یا جستجو برای llama or neuron در کادر جستجو شما می توانید مدل های نورون Llama 2 را در این صفحه مشاهده کنید.
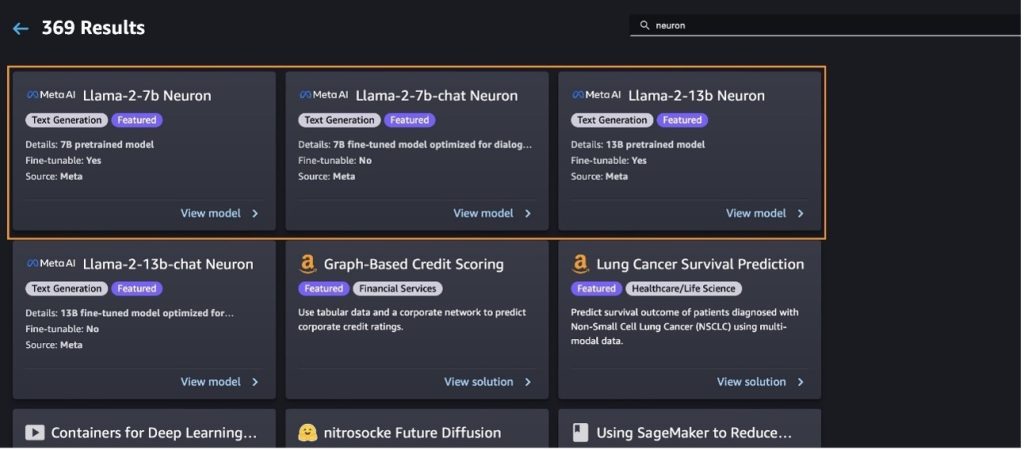
مدل Llama-2-13b را با SageMaker Jumpstart اجرا کنید
میتوانید کارت مدل را برای مشاهده جزئیات مدل مانند مجوز، دادههای مورد استفاده برای آموزش و نحوه استفاده از آن انتخاب کنید. همچنین می توانید دو دکمه را پیدا کنید، گسترش و نوت بوک را باز کنید، که به شما کمک می کند با استفاده از این مثال بدون کد از مدل استفاده کنید.
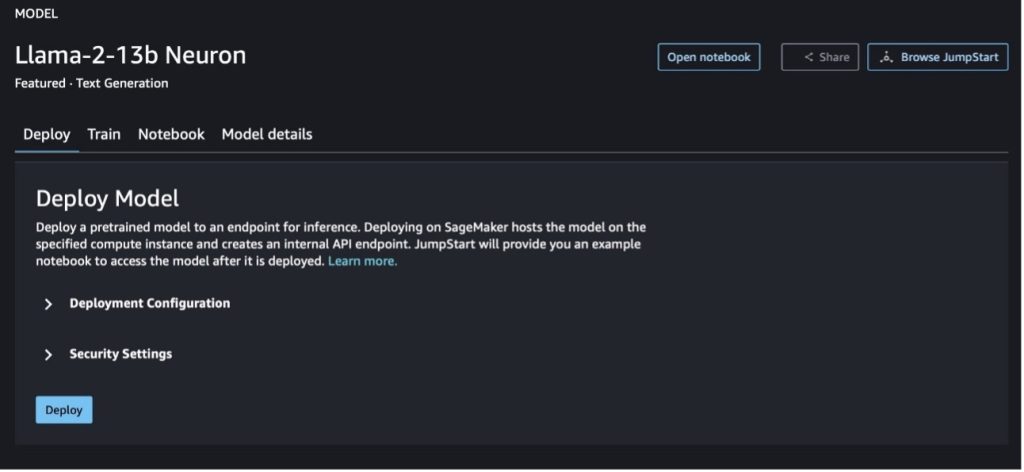
وقتی یکی از دکمهها را انتخاب میکنید، یک پنجره بازشو توافقنامه مجوز کاربر نهایی و خطمشی استفاده قابل قبول (AUP) را برای تأیید شما نشان میدهد.
پس از تایید خطمشیها، میتوانید نقطه پایانی مدل را مستقر کرده و از طریق مراحل بخش بعدی از آن استفاده کنید.
مدل Llama 2 Neuron را از طریق Python SDK مستقر کنید
وقتی انتخاب کردید گسترش و شرایط را بپذیرید، استقرار مدل آغاز خواهد شد. از طرف دیگر، می توانید با انتخاب از طریق دفترچه یادداشت نمونه مستقر شوید نوت بوک را باز کنید. دفترچه یادداشت نمونه راهنمایی سرتاسری در مورد نحوه استقرار مدل برای استنتاج و پاکسازی منابع ارائه می دهد.
برای استقرار یا تنظیم دقیق یک مدل در نمونههای Trainium یا AWS Inferentia، ابتدا باید PyTorch Neuron را فراخوانی کنید.مشعل نورونکس) برای کامپایل مدل در یک نمودار خاص نورون، که آن را برای هسته های عصبی Inferentia بهینه می کند. کاربران می توانند به کامپایلر دستور دهند که بسته به اهداف برنامه، کمترین تأخیر یا بالاترین توان را بهینه کند. در JumpStart، ما نمودارهای نورون را برای پیکربندیهای مختلف از پیش کامپایل کردیم تا به کاربران اجازه دهیم مراحل کامپایل را بگذرانند و تنظیم دقیقتر و استقرار مدلها را امکانپذیر میسازند.
توجه داشته باشید که نمودار از پیش کامپایل شده Neuron بر اساس نسخه خاصی از نسخه کامپایلر نورون ایجاد شده است.
دو راه برای استقرار LIama 2 در نمونه های مبتنی بر AWS Inferentia وجود دارد. روش اول از پیکربندی از پیش ساخته شده استفاده می کند و به شما امکان می دهد مدل را فقط در دو خط کد مستقر کنید. در مرحله دوم، شما کنترل بیشتری بر پیکربندی دارید. بیایید با روش اول شروع کنیم، با پیکربندی از پیش ساخته شده، و به عنوان مثال از Llama 2 13B Neuron Model از پیش آموزش دیده استفاده کنیم. کد زیر نحوه استقرار Llama 13B را تنها با دو خط نشان می دهد:
برای انجام استنتاج بر روی این مدل ها، باید آرگومان را مشخص کنید accept_eula به True به عنوان بخشی از model.deploy() زنگ زدن. با تنظیم این استدلال برای درست بودن، تصدیق می کند که EULA مدل را خوانده و پذیرفته اید. EULA را می توان در توضیحات کارت مدل یا از قسمت پیدا کرد وب سایت متا.
نوع نمونه پیش فرض برای Llama 2 13B ml.inf2.8xlarge است. همچنین میتوانید شناسههای دیگر مدلهای پشتیبانیشده را امتحان کنید:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(مدل چت)meta-textgenerationneuron-llama-2-13b-f(مدل چت)
از طرف دیگر، اگر میخواهید کنترل بیشتری بر پیکربندیهای استقرار داشته باشید، مانند طول زمینه، درجه موازی تانسور و حداکثر اندازه دسته غلتشی، میتوانید آنها را از طریق متغیرهای محیطی تغییر دهید، همانطور که در این بخش نشان داده شده است. کانتینر یادگیری عمیق (DLC) زیربنایی این استقرار است استنتاج مدل بزرگ (LMI) NeuronX DLC. متغیرهای محیطی به شرح زیر است:
- OPTION_N_POSITIONS - حداکثر تعداد توکن های ورودی و خروجی. برای مثال، اگر مدل را با
OPTION_N_POSITIONSبه عنوان 512، سپس می توانید از یک نشانه ورودی 128 (اندازه اعلان ورودی) با حداکثر نشانه خروجی 384 استفاده کنید (مجموع توکن های ورودی و خروجی باید 512 باشد). برای حداکثر نشانه خروجی، هر مقدار زیر 384 خوب است، اما شما نمی توانید از آن فراتر بروید (به عنوان مثال، ورودی 256 و خروجی 512). - OPTION_TENSOR_PARALLEL_DEGREE - تعداد NeuronCores برای بارگذاری مدل در نمونه های AWS Inferentia.
- OPTION_MAX_ROLLING_BATCH_SIZE - حداکثر اندازه دسته برای درخواست های همزمان.
- OPTION_DTYPE – نوع تاریخ برای بارگذاری مدل.
کامپایل نمودار نورون به طول زمینه (OPTION_N_POSITIONS، درجه موازی تانسور (OPTION_TENSOR_PARALLEL_DEGREE)، حداکثر اندازه دسته (OPTION_MAX_ROLLING_BATCH_SIZEو نوع داده (OPTION_DTYPE) برای بارگذاری مدل. SageMaker JumpStart نمودارهای نورون را برای پیکربندی های مختلف برای پارامترهای قبلی از پیش کامپایل کرده است تا از کامپایل زمان اجرا جلوگیری کند. تنظیمات نمودارهای از پیش کامپایل شده در جدول زیر آمده است. تا زمانی که متغیرهای محیطی در یکی از دستههای زیر قرار میگیرند، از گردآوری نمودارهای نورون صرفنظر میشود.
| چت LIama-2 7B و LIama-2 7B | ||||
| نوع نمونه | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| چت LIama-2 13B و LIama-2 13B | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
در زیر نمونه ای از استقرار Llama 2 13B و تنظیم تمام تنظیمات موجود است.
اکنون که مدل Llama-2-13b را به کار گرفتهایم، میتوانیم استنتاج با آن را با فراخوانی نقطه پایانی اجرا کنیم. قطعه کد زیر استفاده از پارامترهای استنتاج پشتیبانی شده را برای کنترل تولید متن نشان می دهد:
- بیشترین طول – مدل تا زمانی که طول خروجی (که شامل طول متن ورودی است) برسد، متن تولید می کند
max_length. اگر مشخص شود، باید یک عدد صحیح مثبت باشد. - max_new_tokens – مدل تا زمانی که طول خروجی (به استثنای طول زمینه ورودی) به آن برسد، متن تولید می کند
max_new_tokens. اگر مشخص شود، باید یک عدد صحیح مثبت باشد. - num_beams – این نشان دهنده تعداد پرتوهای استفاده شده در جستجوی حریصانه است. اگر مشخص شود، باید یک عدد صحیح بزرگتر یا مساوی باشد
num_return_sequences. - no_repeat_ngram_size - مدل تضمین می کند که دنباله ای از کلمات
no_repeat_ngram_sizeدر توالی خروجی تکرار نمی شود. اگر مشخص شده باشد، باید یک عدد صحیح مثبت بزرگتر از 1 باشد. - درجه حرارت - این تصادفی بودن خروجی را کنترل می کند. دمای بالاتر منجر به یک دنباله خروجی با کلمات کم احتمال می شود. دمای پایین تر منجر به یک دنباله خروجی با کلمات با احتمال بالا می شود. اگر
temperatureبرابر با 0، منجر به رمزگشایی حریصانه می شود. اگر مشخص شود، باید شناور مثبت باشد. - زود_توقف - اگر
True، تولید متن زمانی به پایان می رسد که همه فرضیه های پرتو به پایان نشانه جمله برسند. اگر مشخص شده باشد، باید Boolean باشد. - do_sample - اگر
True، مدل کلمه بعدی را بر اساس احتمال نمونه برداری می کند. اگر مشخص شده باشد، باید Boolean باشد. - top_k – در هر مرحله از تولید متن، مدل فقط از متن نمونه برداری می کند
top_kبه احتمال زیاد کلمات اگر مشخص شود، باید یک عدد صحیح مثبت باشد. - top_p - در هر مرحله از تولید متن، مدل از کوچکترین مجموعه ممکن کلمات با احتمال تجمعی نمونه برداری می کند.
top_p. اگر مشخص شده باشد، باید شناور بین 0-1 باشد. - متوقف کردن – اگر مشخص شده باشد، باید فهرستی از رشته ها باشد. اگر هر یک از رشته های مشخص شده تولید شود، تولید متن متوقف می شود.
کد زیر یک مثال را نشان می دهد:
تولید:
برای اطلاعات بیشتر در مورد پارامترهای موجود در محموله، به پارامترهای مفصل.
شما همچنین می توانید پیاده سازی پارامترها را در دفتر یادداشت برای اضافه کردن اطلاعات بیشتر در مورد لینک دفترچه یادداشت.
با استفاده از SageMaker Studio UI و SageMaker Python SDK مدل های Llama 2 را در نمونه های Trainium تنظیم کنید
مدلهای پایه هوش مصنوعی مولد به تمرکز اصلی در ML و AI تبدیل شدهاند، با این حال، تعمیم گسترده آنها میتواند در حوزههای خاصی مانند مراقبتهای بهداشتی یا خدمات مالی، که در آن مجموعه دادههای منحصربهفردی دخیل است، کوتاهی کند. این محدودیت نیاز به تنظیم دقیق این مدلهای هوش مصنوعی مولد با دادههای خاص دامنه را برای افزایش عملکرد آنها در این حوزههای تخصصی برجسته میکند.
اکنون که نسخه از پیش آموزشدیدهشده مدل Llama 2 را به کار گرفتهایم، بیایید ببینیم چگونه میتوانیم آن را با دادههای خاص دامنه تنظیم کنیم تا دقت را افزایش دهیم، مدل را از نظر تکمیلهای سریع بهبود بخشیم، و مدل را با آن تطبیق دهیم. مورد استفاده و داده های خاص کسب و کار شما. می توانید مدل ها را با استفاده از SageMaker Studio UI یا SageMaker Python SDK تنظیم دقیق کنید. ما در این بخش به هر دو روش می پردازیم.
مدل Llama-2-13b Neuron را با استودیوی SageMaker تنظیم کنید
در SageMaker Studio، به مدل Llama-2-13b Neuron بروید. در گسترش تب، می توانید به آن اشاره کنید سرویس ذخیره سازی ساده آمازون سطل (Amazon S3) حاوی مجموعه دادههای آموزشی و اعتبارسنجی برای تنظیم دقیق. علاوه بر این، میتوانید پیکربندی استقرار، فراپارامترها و تنظیمات امنیتی را برای تنظیم دقیق پیکربندی کنید. سپس انتخاب کنید قطار برای شروع کار آموزشی در یک نمونه SageMaker ML.

برای استفاده از مدل های Llama 2، باید EULA و AUP را بپذیرید. زمانی که شما انتخاب می کنید نشان داده می شود قطار. انتخاب کنید EULA و AUP را خوانده و قبول کرده ام برای شروع کار تنظیم دقیق
می توانید وضعیت کار آموزشی خود را برای مدل تنظیم شده در زیر کنسول SageMaker با انتخاب مشاهده کنید. مشاغل آموزشی در صفحه ناوبری
شما می توانید مدل Llama 2 Neuron خود را با استفاده از این مثال بدون کد تنظیم کنید، یا همانطور که در بخش بعدی نشان داده شده است، از طریق Python SDK تنظیم دقیق کنید.
تنظیم دقیق مدل Llama-2-13b Neuron از طریق SageMaker Python SDK
شما می توانید مجموعه داده را با فرمت تطبیق دامنه یا به دقت تنظیم کنید تنظیم دقیق مبتنی بر دستورالعمل قالب در زیر دستورالعملهایی برای نحوه قالببندی دادههای آموزشی قبل از ارسال به تنظیم دقیق آمده است:
- ورودی - A
trainدایرکتوری حاوی یک فایل قالب بندی شده با خطوط JSON (.jsonl) یا متن (txt.).- برای فایل خطوط JSON (jsonl.)، هر خط یک شی JSON جداگانه است. هر شیء JSON باید به عنوان یک جفت کلید-مقدار، جایی که کلید باید باشد، ساختار یافته باشد
text، و ارزش محتوای یک مثال آموزشی است. - تعداد فایل های زیر دایرکتوری قطار باید برابر با 1 باشد.
- برای فایل خطوط JSON (jsonl.)، هر خط یک شی JSON جداگانه است. هر شیء JSON باید به عنوان یک جفت کلید-مقدار، جایی که کلید باید باشد، ساختار یافته باشد
- تولید - یک مدل آموزش دیده که می تواند برای استنتاج به کار گرفته شود.
در این مثال از زیرمجموعه ای استفاده می کنیم مجموعه داده دالی در قالب تنظیم دستورالعمل مجموعه داده دالی شامل تقریباً 15,000 رکورد زیر دستورالعمل برای دستههای مختلف، مانند پاسخ به سؤال، خلاصهسازی و استخراج اطلاعات است. تحت مجوز Apache 2.0 در دسترس است. ما استفاده می کنیم information_extraction نمونه هایی برای تنظیم دقیق
- مجموعه داده Dolly را بارگیری کنید و آن را به آن تقسیم کنید
train(برای تنظیم دقیق) وtest(برای ارزیابی):
- از یک الگوی سریع برای پیش پردازش داده ها در قالب دستورالعمل برای کار آموزشی استفاده کنید:
- هایپرپارامترها را بررسی کنید و آنها را برای مورد استفاده خود بازنویسی کنید:
- مدل را دقیق تنظیم کنید و یک کار آموزشی SageMaker را شروع کنید. اسکریپت های تنظیم دقیق بر اساس neuronx-nemo-megatron مخزن، که نسخه های اصلاح شده بسته ها هستند نمو و اوج که برای استفاده با نمونه های Neuron و EC2 Trn1 سازگار شده اند. این neuronx-nemo-megatron مخزن دارای موازی سازی سه بعدی (داده، تانسور و خط لوله) است تا به شما امکان می دهد LLM ها را در مقیاس دقیق تنظیم کنید. نمونه های پشتیبانی شده Trainium عبارتند از ml.trn3xlarge و ml.trn1.32n.1xlarge.
- در نهایت، مدل تنظیم شده را در یک نقطه پایانی SageMaker مستقر کنید:
پاسخها را بین مدلهای Llama 2 Neuron از پیش آموزشدیده و تنظیمشده دقیق مقایسه کنید
اکنون که نسخه از پیش آموزشدیدهشده مدل Llama-2-13b را مستقر کردهایم و آن را بهخوبی تنظیم کردهایم، میتوانیم برخی از مقایسههای عملکرد تکمیلهای سریع هر دو مدل را همانطور که در جدول زیر نشان داده شده است مشاهده کنیم. ما همچنین یک مثال برای تنظیم دقیق Llama 2 در مجموعه داده فایل SEC در قالب txt. ارائه می دهیم. برای جزئیات، نگاه کنید به نمونه نوت بوک GitHub.
| مورد | ورودی ها | حقیقت زمینی | پاسخ از مدل غیر دقیق | پاسخ از مدل دقیق تنظیم شده |
| 1 | در زیر دستورالعملی است که یک کار را توصیف می کند، همراه با ورودی که زمینه بیشتری را ارائه می دهد. پاسخی بنویسید که بهطور مناسب درخواست را تکمیل کند. و تحصیلات خود را در مقطع کارشناسی در École Polytechnique Fédérale de Lozanne (EPFL) انجام داد و در سال 1953 فارغ التحصیل شد. او به تحصیلات تکمیلی در دانشگاه تنسی ادامه داد و مدرک Ph.D. در سال 1975. سپس به هیئت علمی دانشگاه نیومکزیکو پیوست و تا سال 1980 در آنجا ماند و به EPFL رفت. او در دسامبر 2006 از EPFL بازنشسته شد. nnدر سال 2016، مورت مجله ACM Experimental Algorithmics را تأسیس کرد و تا سال 1996 سردبیر مجله باقی ماند. در سال 2003، مورت کارگاه الگوریتمها برای بیوانفورماتیک و باقی مانده در بیوانفورماتیک (WABI) را تأسیس کرد. کمیته راهبری کنفرانس.nnدر سال 2001، مورت به دلیل مشارکت برجسته خود در زمینه های زیست شناسی محاسباتی و بیوانفورماتیک به عنوان عضو انجمن بین المللی زیست شناسی محاسباتی انتخاب شد.nn### پاسخ:n | * École Polytechnique Fédérale de Lozanne (EPFL) (فارغ التحصیل 1975) N* دانشگاه تنسی (فارغ التحصیل 1980) | مورت در École Polytechnique Fédérale de Lozanne (EPFL) و دانشگاه تنسی تحصیل کرد و به ترتیب در 1975 و 1980 فارغ التحصیل شد. از تابع 'split' برای تقسیم هر جمله به لیستی از کلمات استفاده کنید.n- از تابع 'split' برای تقسیم استفاده کنید. | – École Polytechnique Fédérale de Lozanne (EPFL), 1975n- University of Tennessee, 1980n- University of New Mexico- École Polytechnique Fédérale de Lozanne (EPFL), 2006nn در زیر دستورالعملی ارائه شده است که به شرح آن می پردازد. زمینه بیشتری را فراهم می کند. پاسخی بنویسید که به طور مناسب درخواست را تکمیل کند.n |
| 2 | در زیر دستورالعملی است که یک کار را توصیف می کند، همراه با ورودی که زمینه بیشتری را ارائه می دهد. پاسخی بنویسید که به طور مناسب درخواست را تکمیل کند. نتایج را با فرمت جدا شده با کاما نشان دهید.nn### ورودی:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnخدای شراب، باروری، مهمانی ها، جشن ها، جنون، هرج و مرج، مستی، گیاه، وجد، و تئاتر او دو بار پسر زئوس و سمله است، به این ترتیب که زئوس او را از شکم مادرش ربود و دیونیسوس را به ران خود بخیه زد و او را حمل کرد تا آماده به دنیا آمدن شود. در هنر، او را یا به عنوان یک خدای ریش دار مسن تر (مخصوصاً قبل از 430 قبل از میلاد) یا یک جوان زنانه و مو بلند (به ویژه پس از 430 قبل از میلاد) نشان می دهند. از صفات او می توان به تیرسوس، جام آبخوری، تاک انگور و تاج پیچک اشاره کرد. او اغلب در جمع تیاسوس های خود، گروهی از خادمین از جمله ساتیرها، مائنادها و معلم قدیمی خود سیلنوس است. همسر دیونیسوس آریادنه بود. زمانی تصور میشد که دیونیسیوس بعداً به پانتئون یونان اضافه شده است، اما کشف الواح خط B وضعیت او را به عنوان یک خدا از دوران اولیه تأیید میکند. باکوس نام دیگر او در یونانی بود و در میان رومی ها رایج شد. حیوانات مقدس او شامل دلفین ها، مارها، ببرها و الاغ ها هستند.nn### پاسخ:n | تیرسوس، فنجان آبخوری، تاک انگور، تاجی از پیچک | دیونوسوس (Διόνυσος, Diónusos) nnخدای شراب، ثمربخشی، مهمانی ها، جشن ها، جنون، هرج و مرج، مستی، پوشش گیاهی، وجد و تئاتر. او دو بار پسر زئوس و سمله است که زئوس او را از شکم مادرش ربود و دیونوسوس را به ران خود بخیه زد. | تیرسوس، فنجان نوشیدنی، تاک انگور، تاجی از ivynn در زیر دستورالعملی است که یک کار را توصیف می کند، همراه با ورودی که زمینه بیشتری را فراهم می کند. پاسخی بنویسید که درخواست را کامل کند.nn### دستورالعمل:nتفاوت بین امپراتوری اشکانی و اشکانی چیست؟ |
| 3 | در زیر دستورالعملی است که یک کار را توصیف می کند، همراه با ورودی که زمینه بیشتری را ارائه می دهد. پاسخی بنویسید که درخواست را به درستی تکمیل کند.nn### دستورالعمل:nچرا پایتخت ازبکستان دارای بزرگترین جامعه یونانی است؟ این جامعه متشکل از یونانیان روسیه است که در دهه 9,000 به زور از آن کشور به ازبکستان تبعید شدند و پناهندگان سیاسی از یونان. حدود 1940 یونانی قبل از جنگ جهانی دوم در این کشور زندگی می کردند و 30,000 نفر دیگر پس از جنگ داخلی یونان و شکست ارتش دموکراتیک یونان وارد این کشور شدند. تعداد آنها از 11,000 نفر در دهه 40,000 کاهش یافته است. دلیل اصلی مهاجرت به یونان پس از پایان جنگ سرد است، زمانی که قوانین اجازه بازگشت همه یونانیهای قومی را که به دلایل سیاسی پس از جنگ داخلی یونان تبعید شده بودند را میداد. بزرگترین جامعه یونانی در این کشور در پایتخت تاشکند است که اکثر پناهندگان سیاسی یونانی توسط مقامات شوروی به آنجا منتقل شدند. در دوران باستان، جنوب این کشور بخشی از پادشاهی سلوکی هلنیستی بود، اما تعداد کمی از جوامع یونانی در آنجا جذب شدند. مهمترین سازمانی که یونانیان قومی را نمایندگی می کند، انجمن فرهنگی یونانی تاشکند است. فعالیت های این سازمان شامل آموزش زبان یونانی (1960 کلاس با 19 دانش آموز، کلاس برای بزرگسالان) و آموزش رقص و موسیقی یونانی است.nn### پاسخ:n | بیشتر پناهندگان سیاسی یونانی در ازبکستان توسط مقامات شوروی به پایتخت تاشکند منتقل شدند. | پایتخت ازبکستان دارای بزرگترین جامعه یونانی است، زیرا تعداد یونانیان ازبکستان تقریباً 9,000 نفر است. این جامعه متشکل از یونانیان روسیه است که در دهه 1940 به زور از آن کشور به ازبکستان تبعید شدند و پناهندگان سیاسی از یونان. حدود 30,000 یونانی قبل از جنگ جهانی دوم و 11,00 نفر دیگر در این کشور زندگی می کردند | پایتخت ازبکستان دارای بزرگترین جامعه یونانی است زیرا اکثر پناهندگان سیاسی یونانی پس از اخراج از یونان توسط مقامات شوروی به آنجا منتقل شدند. زمینه بیشتر پاسخی بنویسید که درخواست را به درستی تکمیل کند.nn### دستورالعمل:nتفاوت بین امپراتوری اشکانی و اشکانی چیست؟ |
میتوانیم ببینیم که پاسخهای مدل تنظیمشده بهبود قابلتوجهی در دقت، ارتباط و وضوح در مقایسه با پاسخهای مدل از پیش آموزشدیده نشان میدهند. در برخی موارد، استفاده از مدل از پیش آموزشدیدهشده برای مورد استفاده شما ممکن است کافی نباشد، بنابراین تنظیم دقیق آن با استفاده از این تکنیک، راهحل را برای مجموعه داده شما شخصیتر میکند.
پاک کردن
بعد از اینکه کار آموزشی خود را کامل کردید و دیگر نمیخواهید از منابع موجود استفاده کنید، منابع را با استفاده از کد زیر حذف کنید:
نتیجه
استقرار و تنظیم دقیق مدلهای Llama 2 Neuron در SageMaker پیشرفت چشمگیری را در مدیریت و بهینهسازی مدلهای هوش مصنوعی مولد در مقیاس بزرگ نشان میدهد. این مدلها، از جمله انواعی مانند Llama-2-7b و Llama-2-13b، از Neuron برای آموزش کارآمد و استنتاج بر روی نمونههای مبتنی بر AWS Inferentia و Trainium استفاده میکنند و عملکرد و مقیاسپذیری آنها را افزایش میدهند.
توانایی استقرار این مدل ها از طریق SageMaker JumpStart UI و Python SDK انعطاف پذیری و سهولت استفاده را ارائه می دهد. Neuron SDK با پشتیبانی از چارچوبهای محبوب ML و قابلیتهای با کارایی بالا، مدیریت کارآمد این مدلهای بزرگ را ممکن میسازد.
تنظیم دقیق این مدل ها بر روی داده های دامنه خاص برای افزایش ارتباط و دقت آنها در زمینه های تخصصی بسیار مهم است. فرآیندی که می توانید از طریق SageMaker Studio UI یا Python SDK انجام دهید، امکان سفارشی سازی برای نیازهای خاص را فراهم می کند که منجر به بهبود عملکرد مدل از نظر تکمیل سریع و کیفیت پاسخ می شود.
در مقایسه، نسخههای از پیش آموزشدیدهشده این مدلها، اگرچه قدرتمند هستند، اما ممکن است پاسخهای کلی یا تکراریتری ارائه دهند. تنظیم دقیق مدل را با زمینههای خاص تطبیق میدهد، که منجر به پاسخهای دقیقتر، مرتبطتر و متنوعتر میشود. این سفارشیسازی بهویژه هنگام مقایسه پاسخهای مدلهای از پیش آموزشدیده و تنظیمشده، که مدل دوم بهبود قابلتوجهی را در کیفیت و ویژگی خروجی نشان میدهد، مشهود است. در نتیجه، استقرار و تنظیم دقیق مدلهای Neuron Llama 2 در SageMaker یک چارچوب قوی برای مدیریت مدلهای پیشرفته هوش مصنوعی ارائه میکند که بهبودهای قابل توجهی را در عملکرد و کاربرد، بهویژه زمانی که برای حوزهها یا وظایف خاص طراحی شده باشد، ارائه میکند.
امروز با ارجاع به نمونه SageMaker شروع کنید دفتر یادداشت.
برای اطلاعات بیشتر در مورد استقرار و تنظیم دقیق مدل های Llama 2 از پیش آموزش دیده در نمونه های مبتنی بر GPU، به Llama 2 را برای تولید متن در Amazon SageMaker JumpStart تنظیم کنید و مدلهای پایه Llama 2 از متا اکنون در Amazon SageMaker JumpStart در دسترس هستند.
نویسندگان مایلند از کمک های فنی ایوان کراویتز، کریستوفر ویتن، آدام کوزدرویچ، منان شاه، جاناتان گینهگن و مایک جیمز قدردانی کنند.
درباره نویسنده
 شین هوانگ یک دانشمند کاربردی ارشد برای آمازون SageMaker JumpStart و آمازون SageMaker الگوریتم های داخلی است. او بر توسعه الگوریتمهای یادگیری ماشینی مقیاسپذیر تمرکز دارد. علایق تحقیقاتی او در زمینه پردازش زبان طبیعی، یادگیری عمیق قابل توضیح بر روی داده های جدولی، و تجزیه و تحلیل قوی خوشه بندی ناپارامتری فضا-زمان است. او مقالات زیادی را در کنفرانسهای ACL، ICDM، KDD، و انجمن آماری سلطنتی: سری A منتشر کرده است.
شین هوانگ یک دانشمند کاربردی ارشد برای آمازون SageMaker JumpStart و آمازون SageMaker الگوریتم های داخلی است. او بر توسعه الگوریتمهای یادگیری ماشینی مقیاسپذیر تمرکز دارد. علایق تحقیقاتی او در زمینه پردازش زبان طبیعی، یادگیری عمیق قابل توضیح بر روی داده های جدولی، و تجزیه و تحلیل قوی خوشه بندی ناپارامتری فضا-زمان است. او مقالات زیادی را در کنفرانسهای ACL، ICDM، KDD، و انجمن آماری سلطنتی: سری A منتشر کرده است.
 نیتین اوسبیوس یک معمار راه حل های سازمانی Sr. در AWS، با تجربه در مهندسی نرم افزار، معماری سازمانی، و AI/ML است. او عمیقاً مشتاق کشف امکانات هوش مصنوعی مولد است. او با مشتریان همکاری می کند تا به آنها کمک کند تا برنامه های کاربردی با معماری خوب بر روی پلت فرم AWS بسازند، و به حل چالش های فناوری و کمک به سفر ابری آنها اختصاص دارد.
نیتین اوسبیوس یک معمار راه حل های سازمانی Sr. در AWS، با تجربه در مهندسی نرم افزار، معماری سازمانی، و AI/ML است. او عمیقاً مشتاق کشف امکانات هوش مصنوعی مولد است. او با مشتریان همکاری می کند تا به آنها کمک کند تا برنامه های کاربردی با معماری خوب بر روی پلت فرم AWS بسازند، و به حل چالش های فناوری و کمک به سفر ابری آنها اختصاص دارد.
 مادور پراشانت در فضای هوش مصنوعی مولد در AWS کار می کند. او مشتاق تلاقی تفکر انسان و هوش مصنوعی مولد است. علایق او در هوش مصنوعی مولد نهفته است، بهویژه ساخت راهحلهایی مفید و بیضرر و مهمتر از همه برای مشتریان بهینه. خارج از محل کار، او عاشق انجام یوگا، پیاده روی، گذراندن وقت با دوقلو خود و نواختن گیتار است.
مادور پراشانت در فضای هوش مصنوعی مولد در AWS کار می کند. او مشتاق تلاقی تفکر انسان و هوش مصنوعی مولد است. علایق او در هوش مصنوعی مولد نهفته است، بهویژه ساخت راهحلهایی مفید و بیضرر و مهمتر از همه برای مشتریان بهینه. خارج از محل کار، او عاشق انجام یوگا، پیاده روی، گذراندن وقت با دوقلو خود و نواختن گیتار است.
 دوان چودوری یک مهندس توسعه نرم افزار با خدمات وب آمازون است. او روی الگوریتمهای Amazon SageMaker و پیشنهادات JumpStart کار میکند. جدا از ساخت زیرساختهای AI/ML، او همچنین مشتاق ساختن سیستمهای توزیعشده مقیاسپذیر است.
دوان چودوری یک مهندس توسعه نرم افزار با خدمات وب آمازون است. او روی الگوریتمهای Amazon SageMaker و پیشنهادات JumpStart کار میکند. جدا از ساخت زیرساختهای AI/ML، او همچنین مشتاق ساختن سیستمهای توزیعشده مقیاسپذیر است.
 هائو ژو یک دانشمند محقق با Amazon SageMaker است. قبل از آن، او روی توسعه روشهای یادگیری ماشینی برای تشخیص تقلب برای Amazon Fraud Detector کار میکرد. او مشتاق به کارگیری تکنیکهای یادگیری ماشین، بهینهسازی و هوش مصنوعی برای مشکلات مختلف دنیای واقعی است. او دارای مدرک دکترای مهندسی برق از دانشگاه نورث وسترن است.
هائو ژو یک دانشمند محقق با Amazon SageMaker است. قبل از آن، او روی توسعه روشهای یادگیری ماشینی برای تشخیص تقلب برای Amazon Fraud Detector کار میکرد. او مشتاق به کارگیری تکنیکهای یادگیری ماشین، بهینهسازی و هوش مصنوعی برای مشکلات مختلف دنیای واقعی است. او دارای مدرک دکترای مهندسی برق از دانشگاه نورث وسترن است.
 چینگ لان مهندس توسعه نرم افزار در AWS است. او روی چندین محصول چالش برانگیز در آمازون کار کرده است، از جمله راه حل های استنتاج ML با کارایی بالا و سیستم ثبت گزارش با کارایی بالا. تیم Qing با موفقیت اولین مدل میلیارد پارامتر را در تبلیغات آمازون با تاخیر بسیار کم مورد نیاز راه اندازی کرد. Qing دانش عمیقی در مورد بهینه سازی زیرساخت و شتاب یادگیری عمیق دارد.
چینگ لان مهندس توسعه نرم افزار در AWS است. او روی چندین محصول چالش برانگیز در آمازون کار کرده است، از جمله راه حل های استنتاج ML با کارایی بالا و سیستم ثبت گزارش با کارایی بالا. تیم Qing با موفقیت اولین مدل میلیارد پارامتر را در تبلیغات آمازون با تاخیر بسیار کم مورد نیاز راه اندازی کرد. Qing دانش عمیقی در مورد بهینه سازی زیرساخت و شتاب یادگیری عمیق دارد.
 دکتر آشیش ختان یک دانشمند کاربردی ارشد با الگوریتم های داخلی Amazon SageMaker است و به توسعه الگوریتم های یادگیری ماشین کمک می کند. او دکترای خود را از دانشگاه ایلینویز Urbana-Champaign گرفت. او یک محقق فعال در یادگیری ماشین و استنتاج آماری است و مقالات زیادی در کنفرانس های NeurIPS، ICML، ICLR، JMLR، ACL و EMNLP منتشر کرده است.
دکتر آشیش ختان یک دانشمند کاربردی ارشد با الگوریتم های داخلی Amazon SageMaker است و به توسعه الگوریتم های یادگیری ماشین کمک می کند. او دکترای خود را از دانشگاه ایلینویز Urbana-Champaign گرفت. او یک محقق فعال در یادگیری ماشین و استنتاج آماری است و مقالات زیادی در کنفرانس های NeurIPS، ICML، ICLR، JMLR، ACL و EMNLP منتشر کرده است.
 دکتر لی ژانگ یک مدیریت فنی اصلی برای آمازون SageMaker JumpStart و الگوریتمهای داخلی Amazon SageMaker است، سرویسی که به دانشمندان داده و متخصصان یادگیری ماشین کمک میکند آموزش و استقرار مدلهای خود را شروع کنند و از یادگیری تقویتی با Amazon SageMaker استفاده کنند. کارهای قبلی او به عنوان یک کارمند اصلی پژوهشی و مخترع اصلی در IBM Research برنده جایزه آزمون زمان کاغذ در IEEE INFOCOM شده است.
دکتر لی ژانگ یک مدیریت فنی اصلی برای آمازون SageMaker JumpStart و الگوریتمهای داخلی Amazon SageMaker است، سرویسی که به دانشمندان داده و متخصصان یادگیری ماشین کمک میکند آموزش و استقرار مدلهای خود را شروع کنند و از یادگیری تقویتی با Amazon SageMaker استفاده کنند. کارهای قبلی او به عنوان یک کارمند اصلی پژوهشی و مخترع اصلی در IBM Research برنده جایزه آزمون زمان کاغذ در IEEE INFOCOM شده است.
 کامران خان، Sr مدیر توسعه کسب و کار فنی برای AWS Inferentina/Trianium در AWS. او بیش از یک دهه تجربه در کمک به مشتریان برای استقرار و بهینه سازی آموزش یادگیری عمیق و بارهای کاری استنتاج با استفاده از AWS Inferentia و AWS Trainium دارد.
کامران خان، Sr مدیر توسعه کسب و کار فنی برای AWS Inferentina/Trianium در AWS. او بیش از یک دهه تجربه در کمک به مشتریان برای استقرار و بهینه سازی آموزش یادگیری عمیق و بارهای کاری استنتاج با استفاده از AWS Inferentia و AWS Trainium دارد.
 جو سنرشیا مدیر محصول ارشد در AWS است. او نمونه های آمازون EC2 را برای یادگیری عمیق، هوش مصنوعی و بارهای کاری محاسباتی با کارایی بالا تعریف کرده و می سازد.
جو سنرشیا مدیر محصول ارشد در AWS است. او نمونه های آمازون EC2 را برای یادگیری عمیق، هوش مصنوعی و بارهای کاری محاسباتی با کارایی بالا تعریف کرده و می سازد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- ٪۱۰۰
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- توانایی
- قادر
- درباره ما
- شتاب
- پذیرفتن
- قابل قبول
- پذیرفته
- دسترسی
- دقت
- دقیق
- اذعان
- ACM
- فعال
- فعالیت ها
- آدم
- وفق دادن
- انطباق
- سازگار
- اضافه کردن
- اضافه
- بزرگسالان
- پیشرفته
- پیشرفت
- تبلیغات
- پس از
- توافق
- AI
- مدل های هوش مصنوعی
- AI / ML
- الگوریتم
- معرفی
- اجازه دادن
- مجاز
- اجازه می دهد تا
- همچنین
- آمازون
- آمازون EC2
- ردیاب تقلب آمازون
- آمازون SageMaker
- Amazon SageMaker JumpStart
- آمازون خدمات وب
- در میان
- an
- تحلیل
- باستانی
- و
- حیوانات
- اعلام
- دیگر
- هر
- دیگر
- آپاچی
- جدا
- مربوط
- کاربرد
- برنامه های کاربردی
- اعمال می شود
- با استفاده از
- به درستی
- تقریبا
- معماری
- هستند
- محدوده
- مناطق
- استدلال
- ارتش
- وارد
- هنر
- مصنوعی
- هوش مصنوعی
- AS
- کمک کردن
- انجمن
- At
- همراهان، خدمه
- خواص
- مقامات
- نویسندگان
- خودکار
- دسترس پذیری
- در دسترس
- اجتناب از
- AWS
- استنتاج AWS
- b
- مستقر
- BE
- پرتو
- زیرا
- شدن
- بوده
- قبل از
- بودن
- باور
- در زیر
- میان
- خارج از
- بزرگترین
- زیست شناسی
- بلاگ
- متولد
- هر دو
- جعبه
- پهن
- ساختن
- بنا
- می سازد
- ساخته شده در
- کسب و کار
- توسعه تجاری
- اما
- دکمه
- دکمه ها
- by
- صدا
- آمد
- CAN
- قابلیت های
- سرمایه
- کارت
- انجام
- مورد
- موارد
- دسته
- دسته بندی
- چالش ها
- به چالش کشیدن
- تغییر دادن
- هرج و مرج
- گپ
- رئیس
- انتخاب
- را انتخاب کنید
- انتخاب
- کریستوفر
- شهر:
- مدنی
- وضوح
- کلاس ها
- کلاسیک
- طبقه بندی
- تمیز
- ابر
- خوشه بندی
- رمز
- سرد
- کمیسیون
- مشترک
- جوامع
- انجمن
- شرکت
- مقایسه
- مقایسه
- مقایسه
- تکمیل شده
- تکمیل شده
- محاسباتی
- محاسبه
- نتیجه
- رقیب
- رفتار
- کنفرانس
- همایش ها
- پیکر بندی
- تکرار
- کنسول
- شامل
- ظرف
- شامل
- محتوا
- زمینه
- زمینه ها
- مشارکت
- کنترل
- گروه شاهد
- هزینه
- گران
- هزینه
- کشور
- ایجاد شده
- تاج
- بسیار سخت
- فرهنگی
- فنجان
- مشتری
- تجربه مشتری
- مشتریان
- سفارشی سازی
- داده ها
- مجموعه داده ها
- تاریخ
- de
- دهه
- دسامبر
- رمز گشایی
- اختصاصی
- عمیق
- یادگیری عمیق
- عمیقا
- به طور پیش فرض
- تعریف می کند
- درجه
- ارائه
- دموکراتیک
- نشان دادن
- نشان
- نشان می دهد
- بستگی دارد
- بستگی دارد
- گسترش
- مستقر
- استقرار
- گسترش
- توصیف
- شرح
- تعیین شده
- طراحی
- دقیق
- جزئیات
- کشف
- توسعه
- در حال توسعه
- پروژه
- گفتگو
- DID
- تفاوت
- مختلف
- كشف كردن
- کشف
- بحث و تبادل نظر
- نمایش دادن
- توزیع شده
- سیستم های توزیع شده
- مختلف
- میکند
- عمل
- عروسک
- دامنه
- حوزه
- آیا
- پایین
- هر
- در اوایل
- سود
- سهولت
- راحتی در استفاده
- سردبیر
- موثر
- اثر
- موثر
- هر دو
- انتخاب شده
- مهندسی برق
- امپراطوری
- فعال
- را قادر می سازد
- را قادر می سازد
- پایان
- پشت سر هم
- نقطه پایانی
- مهندس
- مهندسی
- بالا بردن
- افزایش
- کافی
- تضمین می کند
- سرمایه گذاری
- راه حل های سازمانی
- محیط
- محیطی
- برابر
- برابر
- به خصوص
- اتر (ETH)
- ارزیابی
- ارزیابی
- واضح است
- مثال
- مثال ها
- برانگیخته
- به استثنای
- موجود
- تجربه
- با تجربه
- تجربی
- اکتشاف
- بررسی
- استخراج
- سقوط
- غلط
- سریعتر
- همکار
- جشنواره
- کمی از
- زمینه
- پرونده
- فایل ها
- بایگانی
- مالی
- خدمات مالی
- پیدا کردن
- پایان
- نام خانوادگی
- انعطاف پذیری
- شناور
- تمرکز
- تمرکز
- پیروی
- به دنبال آن است
- برای
- استحکام
- قالب
- یافت
- پایه
- تاسیس
- چارچوب
- چارچوب
- تقلب
- کشف تقلب
- از جانب
- تابع
- بیشتر
- تولید
- تولید می کند
- نسل
- مولد
- هوش مصنوعی مولد
- دریافت کنید
- Go
- خوب
- خوب
- کردم
- فارغ التحصیل
- گراف
- نمودار ها
- بیشتر
- یونان
- حریص
- یونانی
- گروه
- راهنمایی
- گیتار
- بود
- اداره
- دست ها
- خوشحال
- آیا
- he
- بهداشت و درمان
- برگزار شد
- کمک
- مفید
- کمک
- کمک می کند
- زیاد
- عملکرد بالا
- بالاتر
- بالاترین
- های لایت
- پیاده روی
- او را
- خود را
- دارای
- چگونه
- چگونه
- اما
- HTML
- HTTP
- HTTPS
- انسان
- i
- آی بی ام
- ICLR
- شناسایی
- شناسه
- IEEE
- if
- ii
- ایلینوی
- پیاده سازی
- واردات
- مهم
- بهبود
- بهبود یافته
- بهبود
- ارتقاء
- in
- در عمق
- شامل
- شامل
- از جمله
- افزایش
- نشان می دهد
- اطلاعات
- استخراج اطلاعات
- شالوده
- شالوده
- ورودی
- ورودی
- نمونه
- نمونه ها
- دستورالعمل
- یکپارچه
- اطلاعات
- منافع
- رابط
- بین المللی
- تقاطع
- به
- گرفتار
- IT
- ITS
- جیمز
- کار
- شغل ها
- پیوست
- جاناتان
- روزنامه
- سفر
- JPG
- json
- تنها
- کلید
- پادشاهی
- بسته لوازم
- کیت (SDK)
- دانش
- شناخته شده
- فرود
- صفحه فرود
- زبان
- بزرگ
- در مقیاس بزرگ
- تاخیر
- بعد
- راه اندازی
- قوانین
- برجسته
- یادگیری
- طول
- li
- مجوز
- مجوزها
- دروغ
- زندگی
- پسندیدن
- احتمال
- احتمالا
- محدودیت
- لاین
- خطوط
- ارتباط دادن
- فهرست
- ذکر شده
- پشم لاما
- بار
- محلی
- ورود به سیستم
- طولانی
- نگاه کنيد
- دوست دارد
- کم
- کاهش
- پایین آوردن
- پایین ترین
- دستگاه
- فراگیری ماشین
- ساخته
- اصلی
- ساخت
- ساخت
- مدیر
- مدیریت
- منان شاه
- بسیاری
- استاد
- بیشترین
- ممکن است..
- معنی
- دیدار
- عضو
- متا
- روش
- روش
- مکزیک
- قدرت
- مخفف کلمه میکروفون
- ذهن
- ML
- مدل
- مدل سازی
- مدل
- اصلاح شده
- تغییر
- بیش
- اکثر
- نقل مکان کرد
- موسیقی
- باید
- نام
- طبیعی
- زبان طبیعی
- پردازش زبان طبیعی
- هدایت
- جهت یابی
- نیاز
- نیازهای
- NeurIPS
- جدید
- بعد
- nlp
- دانشگاه نورث وسترن
- دفتر یادداشت
- نوت بوک
- اکنون
- عدد
- تعداد
- هدف
- اهداف
- of
- ارائه
- ارائه
- پیشنهادات
- پیشنهادات
- غالبا
- قدیمی
- بزرگتر
- on
- یک بار
- ONE
- فقط
- بهینه
- بهینه سازی
- بهینه سازی
- بهینه
- بهینه سازی
- گزینه
- or
- کدام سازمان ها
- دیگر
- تولید
- خارج از
- برجسته
- روی
- خود
- بسته
- با ما
- جفت
- زوج
- قطعه
- مقاله
- اوراق
- موازی
- پارامترهای
- بخش
- ویژه
- احزاب
- عبور
- احساساتی
- گذشته
- برای
- انجام دادن
- کارایی
- دوره
- شخصی
- دکترا
- خط لوله
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- لطفا
- نقطه
- سیاست
- سیاست
- سیاسی
- پاپ آپ
- محبوب
- مثبت
- فرصت
- ممکن
- پست
- قوی
- ماقبل
- دقت
- آماده
- اصلی
- اصلی
- احتمال
- مشکلات
- روند
- در حال پردازش
- محصول
- مدیر تولید
- محصولات
- اختصاصی
- ارائه
- ارائه دهندگان
- فراهم می کند
- عمومی
- منتشر شده
- قرار دادن
- پــایتــون
- مارماهی
- کیفیت
- سوال
- تصادفی بودن
- رسیدن به
- می رسد
- خواندن
- اماده
- واقعی
- دنیای واقعی
- زمان واقعی
- دلیل
- دلایل
- سوابق
- مراجعه
- ارجاع
- پناهندگان
- منتشر شد
- ربط
- مربوط
- نقل مکان کرد
- باقی مانده است
- بقایای
- مکرر
- تکراری
- جایگزین کردن
- مخزن
- نشان دادن
- نمایندگی
- درخواست
- درخواست
- ضروری
- تحقیق
- پژوهشگر
- منابع
- به ترتیب
- پاسخ
- پاسخ
- مسئوليت
- نتیجه
- نتایج
- برگشت
- این فایل نقد می نویسید:
- بازبینی
- تنومند
- نورد
- سلطنتی
- دویدن
- روسیه
- حکیم ساز
- مقیاس پذیری
- مقیاس پذیر
- مقیاس
- سناریوها
- دانشمند
- دانشمندان
- اسکریپت
- sdk
- جستجو
- جستجو
- SEC
- تأیید SEC
- دوم
- بخش
- تیم امنیت لاتاری
- دیدن
- ارشد
- فرستاده
- جمله
- احساس
- جداگانه
- دنباله
- سلسله
- سری A
- سرویس
- خدمات
- تنظیم
- محیط
- تنظیمات
- چند
- کوتاه
- باید
- نشان
- نشان داده شده
- نشان می دهد
- قابل توجه
- ساده
- پس از
- تنها
- اندازه
- قطعه
- So
- جامعه
- نرم افزار
- توسعه نرم افزار
- بسته توسعه نرم افزار
- مهندسی نرم افزار
- راه حل
- مزایا
- حل کردن
- برخی از
- آن
- منبع
- جنوب
- شوروی
- فضا
- تخصصی
- خاص
- به طور خاص
- اختصاصی
- مشخص شده
- هزینه
- انشعاب
- کارکنان
- شروع
- آغاز شده
- دولت
- آماری
- وضعیت
- فرمان
- گام
- مراحل
- توقف
- ذخیره سازی
- ساخت یافته
- دانشجویان
- مورد مطالعه قرار
- مطالعات
- استودیو
- موفقیت
- چنین
- پشتیبانی
- پشتیبانی
- مطمئن
- سویس
- سیستم
- سیستم های
- جدول
- طراحی شده
- کار
- وظایف
- تعلیم
- تیم
- فنی
- تکنیک
- تکنیک
- پیشرفته
- قالب
- تنسی
- قوانین و مقررات
- آزمون
- متن
- طبقه بندی متن
- تولید متن
- نسبت به
- که
- La
- محوطه
- پایتخت
- تئاتر
- شان
- آنها
- سپس
- آنجا.
- اینها
- آنها
- تفکر
- شخص ثالث
- این
- کسانی که
- از طریق
- توان
- ببر
- زمان
- بار
- به
- امروز
- رمز
- نشانه
- ابزار
- جمع
- قطار
- آموزش دیده
- آموزش
- ترانسفورماتور
- ترجمه
- درست
- امتحان
- دوقلو
- دو
- نوع
- ui
- زیر
- اساسی
- منحصر به فرد
- دانشگاه ها
- دانشگاه
- تا
- بروزرسانی
- به روز رسانی
- استفاده
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- کاربران
- استفاده
- با استفاده از
- استفاده می کند
- uzbekistan
- اعتبار سنجی
- ارزش
- تنوع
- مختلف
- نسخه
- بسیار
- از طريق
- چشم انداز
- تاک
- بصری
- راه رفتن
- می خواهم
- جنگ
- بود
- راه
- we
- وب
- خدمات وب
- مبتنی بر وب
- رفت
- بود
- چه زمانی
- که
- در حین
- WHO
- اراده
- شراب
- با
- برنده شد
- کلمه
- کلمات
- مهاجرت کاری
- مشغول به کار
- کارگر
- با این نسخهها کار
- کارگاه
- جهان
- خواهد بود
- نوشتن
- سال
- ریاضت
- شما
- شما
- جوانان
- زفیرنت
- زئوس