
همانطور که هوش مصنوعی از ابر به Edge مهاجرت می کند، ما شاهد استفاده از این فناوری در انواع موارد استفاده رو به گسترش هستیم - از تشخیص ناهنجاری گرفته تا برنامه هایی از جمله خرید هوشمند، نظارت، روباتیک و اتوماسیون کارخانه. از این رو، هیچ راه حلی برای همه وجود ندارد. اما با رشد سریع دستگاههای مجهز به دوربین، هوش مصنوعی به طور گستردهای برای تجزیه و تحلیل دادههای ویدئویی بلادرنگ به منظور خودکارسازی نظارت ویدئویی به منظور افزایش ایمنی، بهبود کارایی عملیاتی، و ارائه تجربیات بهتر برای مشتریان و در نهایت به دست آوردن مزیت رقابتی در صنایع خود مورد استفاده قرار گرفته است. . برای پشتیبانی بهتر از تجزیه و تحلیل ویدیو، باید استراتژی های بهینه سازی عملکرد سیستم در استقرار هوش مصنوعی لبه را درک کنید.
- انتخاب موتورهای محاسباتی با اندازه مناسب برای برآوردن یا فراتر رفتن از سطوح عملکرد مورد نیاز. برای یک برنامه هوش مصنوعی، این موتورهای محاسباتی باید عملکردهای کل خط لوله بینایی را انجام دهند (به عنوان مثال، پیش و پس پردازش ویدئو، استنتاج شبکه عصبی).
ممکن است به یک شتابدهنده هوش مصنوعی اختصاصی، چه گسسته یا یکپارچه در یک SoC (برخلاف اجرای استنباط هوش مصنوعی بر روی یک CPU یا GPU) نیاز باشد.
- درک تفاوت بین توان عملیاتی و تأخیر؛ به موجب آن توان عملیاتی نرخی است که دادهها میتوانند در یک سیستم پردازش شوند و تأخیر تأخیر پردازش دادهها را از طریق سیستم اندازهگیری میکند و اغلب با پاسخگویی بلادرنگ مرتبط است. به عنوان مثال، یک سیستم می تواند داده های تصویری را با سرعت 100 فریم در ثانیه تولید کند، اما 100 میلی ثانیه (تأخیر) طول می کشد تا یک تصویر از سیستم عبور کند.
- با در نظر گرفتن توانایی مقیاسسازی آسان عملکرد هوش مصنوعی در آینده برای پاسخگویی به نیازهای رو به رشد، نیازمندیهای در حال تغییر و فناوریهای در حال تکامل (به عنوان مثال، مدلهای پیشرفتهتر هوش مصنوعی برای افزایش عملکرد و دقت). شما می توانید مقیاس عملکرد را با استفاده از شتاب دهنده های هوش مصنوعی در قالب ماژول یا با تراشه های شتاب دهنده هوش مصنوعی اضافی انجام دهید.
الزامات عملکرد واقعی به برنامه وابسته است. به طور معمول، می توان انتظار داشت که برای تجزیه و تحلیل ویدئویی، سیستم باید جریان های داده ای را که از دوربین ها با سرعت 30 تا 60 فریم بر ثانیه و با وضوح 1080p یا 4k دریافت می شود، پردازش کند. یک دوربین مجهز به هوش مصنوعی یک جریان واحد را پردازش می کند. یک دستگاه لبه چندین جریان را به صورت موازی پردازش می کند. در هر صورت، سیستم هوش مصنوعی لبه باید از عملکردهای پیش پردازش پشتیبانی کند تا داده های حسگر دوربین را به قالبی تبدیل کند که با الزامات ورودی بخش استنتاج هوش مصنوعی مطابقت داشته باشد (شکل 1).
توابع پیش پردازش داده های خام را دریافت می کنند و کارهایی مانند تغییر اندازه، عادی سازی و تبدیل فضای رنگی را قبل از وارد کردن ورودی به مدل در حال اجرا در شتاب دهنده هوش مصنوعی انجام می دهند. پیش پردازش می تواند از کتابخانه های پردازش تصویر کارآمد مانند OpenCV برای کاهش زمان پیش پردازش استفاده کند. پس پردازش شامل تجزیه و تحلیل خروجی استنتاج است. از وظایفی مانند سرکوب غیر حداکثری (NMS خروجی اکثر مدلهای تشخیص اشیا را تفسیر میکند) و نمایش تصویر برای ایجاد بینشهای عملی، مانند جعبههای محدود، برچسبهای کلاس، یا امتیازات اطمینان استفاده میکند.

شکل 1. برای استنباط مدل هوش مصنوعی، عملکردهای پیش و پس پردازش معمولاً بر روی یک پردازنده برنامه ها انجام می شود.
استنتاج مدل AI می تواند چالش اضافی پردازش چندین مدل شبکه عصبی در هر فریم را داشته باشد، بسته به قابلیت های برنامه. برنامههای بینایی رایانه معمولاً شامل چندین کار هوش مصنوعی هستند که به خط لولهای از مدلهای متعدد نیاز دارند. علاوه بر این، خروجی یک مدل اغلب ورودی مدل بعدی است. به عبارت دیگر، مدل ها در یک برنامه اغلب به یکدیگر وابسته هستند و باید به صورت متوالی اجرا شوند. مجموعه دقیق مدلهایی که باید اجرا شوند ممکن است ایستا نباشند و به صورت پویا، حتی بر اساس فریم به فریم، متفاوت باشند.
چالش اجرای چند مدل به صورت پویا به یک شتاب دهنده هوش مصنوعی خارجی با حافظه اختصاصی و به اندازه کافی بزرگ برای ذخیره مدل ها نیاز دارد. اغلب شتابدهنده هوش مصنوعی یکپارچه در یک SoC به دلیل محدودیتهای اعمال شده توسط زیرسیستم حافظه مشترک و سایر منابع در SoC قادر به مدیریت حجم کاری چند مدل نیست.
به عنوان مثال، ردیابی شی مبتنی بر پیشبینی حرکت، برای تعیین بردار که برای شناسایی شی ردیابی شده در موقعیت آینده استفاده میشود، به تشخیصهای پیوسته متکی است. اثربخشی این رویکرد محدود است زیرا فاقد قابلیت شناسایی مجدد واقعی است. با پیشبینی حرکت، مسیر یک شی میتواند به دلیل عدم شناسایی، انسداد یا خروج جسم از میدان دید، حتی به صورت لحظهای، گم شود. پس از گم شدن، هیچ راهی برای ارتباط مجدد مسیر شی وجود ندارد. افزودن شناسایی مجدد این محدودیت را حل می کند، اما به تعبیه ظاهری بصری (یعنی اثر انگشت تصویر) نیاز دارد. تعبیههای ظاهری به شبکه دوم نیاز دارند تا با پردازش تصویر موجود در جعبه مرزی شی شناسایی شده توسط شبکه اول، یک بردار ویژگی ایجاد کند. این تعبیه را می توان برای شناسایی مجدد شی، صرف نظر از زمان یا مکان، استفاده کرد. از آنجایی که باید برای هر شی شناسایی شده در میدان دید، تعبیهها ایجاد شود، با شلوغ شدن صحنه، نیازهای پردازش افزایش مییابد. ردیابی اشیاء با شناسایی مجدد مستلزم بررسی دقیق بین انجام تشخیص با دقت بالا / وضوح بالا / نرخ فریم بالا و ذخیره سربار کافی برای مقیاسپذیری جاسازیها است. یکی از راههای حل نیاز پردازش، استفاده از شتابدهنده هوش مصنوعی اختصاصی است. همانطور که قبلا ذکر شد، موتور AI SoC می تواند از کمبود منابع حافظه مشترک رنج ببرد. بهینه سازی مدل همچنین می تواند برای کاهش نیاز پردازش استفاده شود، اما می تواند بر عملکرد و/یا دقت تأثیر بگذارد.
در یک دوربین هوشمند یا دستگاه لبه، SoC یکپارچه (یعنی پردازنده میزبان) فریم های ویدئویی را بدست می آورد و مراحل پیش پردازشی را که قبلا توضیح دادیم انجام می دهد. این عملکردها را میتوان با هستههای CPU یا GPU SoC (در صورت موجود بودن) انجام داد، اما میتوان آنها را توسط شتابدهندههای سختافزاری اختصاصی در SoC (مثلاً پردازشگر سیگنال تصویر) انجام داد. پس از تکمیل این مراحل پیش پردازش، شتاب دهنده هوش مصنوعی که در SoC ادغام شده است می تواند مستقیماً به این ورودی کوانتیزه شده از حافظه سیستم دسترسی داشته باشد، یا در مورد یک شتاب دهنده هوش مصنوعی گسسته، ورودی برای استنتاج، معمولاً از طریق رابط USB یا PCIe.
یک SoC یکپارچه میتواند شامل طیف وسیعی از واحدهای محاسباتی، از جمله پردازندههای مرکزی، پردازندههای گرافیکی، شتابدهنده هوش مصنوعی، پردازندههای بینایی، رمزگذار/رمزگشاهای ویدئو، پردازنده سیگنال تصویر (ISP) و غیره باشد. این واحدهای محاسباتی همگی یک گذرگاه حافظه مشترک دارند و در نتیجه به حافظه یکسانی دسترسی دارند. علاوه بر این، CPU و GPU نیز ممکن است نقشی در استنتاج داشته باشند و این واحدها مشغول اجرای وظایف دیگر در یک سیستم مستقر هستند. منظور ما از سربار در سطح سیستم (شکل 2) است.
بسیاری از توسعه دهندگان به اشتباه عملکرد شتاب دهنده هوش مصنوعی داخلی در SoC را بدون در نظر گرفتن تأثیر سربار سطح سیستم بر عملکرد کل ارزیابی می کنند. به عنوان مثال، اجرای یک معیار YOLO را روی یک شتاب دهنده هوش مصنوعی 50 TOPS یکپارچه در یک SoC در نظر بگیرید، که ممکن است نتیجه معیار 100 استنتاج در ثانیه (IPS) را به دست آورد. اما در یک سیستم مستقر با تمام واحدهای محاسباتی دیگر آن فعال، آن 50 TOPS می تواند به چیزی در حدود 12 TOPS کاهش یابد و عملکرد کلی تنها 25 IPS را با فرض ضریب استفاده سخاوتمندانه 25٪ به دست می آورد. اگر پلتفرم به طور مداوم جریان های ویدئویی را پردازش می کند، سربار سیستم همیشه یک عامل است. روش دیگر، با یک شتابدهنده هوش مصنوعی مجزا (به عنوان مثال، Kinara Ara-1، Hailo-8، Intel Myriad X)، استفاده در سطح سیستم میتواند بیشتر از 90٪ باشد، زیرا هنگامی که SoC میزبان عملکرد استنتاج را آغاز کرده و ورودی مدل AI را منتقل میکند. داده ها، شتاب دهنده به طور مستقل با استفاده از حافظه اختصاصی خود برای دسترسی به وزن ها و پارامترهای مدل کار می کند.
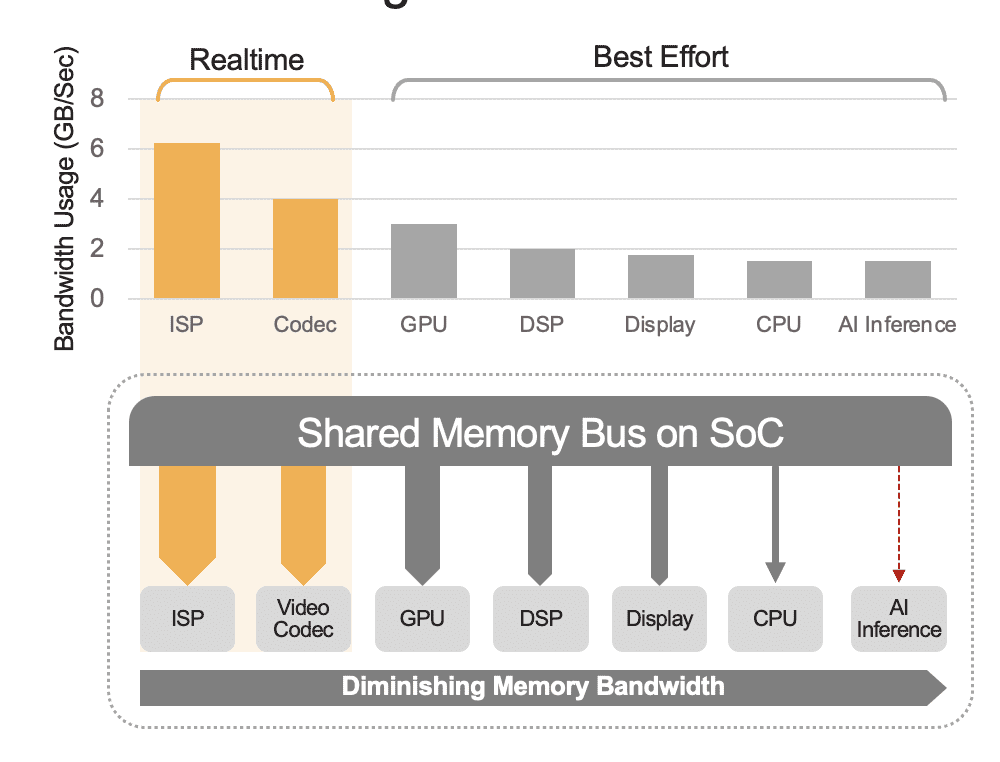
شکل 2. گذرگاه حافظه مشترک، عملکرد سطح سیستم را که در اینجا با مقادیر تخمینی نشان داده شده است، کنترل می کند. مقادیر واقعی بر اساس مدل استفاده از برنامه شما و پیکربندی واحد محاسباتی SoC متفاوت خواهد بود.
تا این مرحله، عملکرد هوش مصنوعی را از نظر فریم در ثانیه و تاپ ها مورد بحث قرار داده ایم. اما تاخیر کم یکی دیگر از نیازهای مهم برای ارائه پاسخگویی بلادرنگ سیستم است. به عنوان مثال، در بازی، تاخیر کم برای یک تجربه بازی بدون درز و پاسخگو، به ویژه در بازیهای کنترلشده با حرکت و سیستمهای واقعیت مجازی (VR) بسیار مهم است. در سیستمهای رانندگی خودمختار، تأخیر کم برای تشخیص واقعی اشیا، تشخیص عابر پیاده، تشخیص خط و تشخیص علائم راهنمایی و رانندگی برای جلوگیری از به خطر انداختن ایمنی حیاتی است. سیستمهای رانندگی خودران معمولاً به تأخیر سرتاسری کمتر از 150 میلیثانیه از تشخیص تا عمل واقعی نیاز دارند. به طور مشابه، در تولید، تأخیر کم برای تشخیص بلادرنگ عیب ضروری است، تشخیص ناهنجاری، و هدایت رباتیک به تجزیه و تحلیل ویدیویی با تأخیر کم برای اطمینان از عملکرد کارآمد و به حداقل رساندن زمان توقف تولید، بستگی دارد.
به طور کلی، سه مؤلفه تأخیر در یک برنامه تحلیل ویدیویی وجود دارد (شکل 3):
- تأخیر ثبت داده، زمان از سنسور دوربین که یک فریم ویدیویی را می گیرد تا در دسترس بودن فریم به سیستم تجزیه و تحلیل برای پردازش است. شما می توانید این تاخیر را با انتخاب دوربینی با سنسور سریع و پردازنده کم تاخیر، انتخاب نرخ فریم بهینه و استفاده از فرمت های فشرده سازی کارآمد ویدئو بهینه کنید.
- تأخیر انتقال داده زمانی است که دادههای ویدئویی ضبطشده و فشردهشده از دوربین به دستگاههای لبه یا سرورهای محلی منتقل میشوند. این شامل تاخیرهای پردازش شبکه است که در هر نقطه پایانی رخ می دهد.
- تأخیر پردازش داده به زمانی اشاره دارد که دستگاههای لبه وظایف پردازش ویدیویی مانند رفع فشردهسازی فریم و الگوریتمهای تحلیلی را انجام میدهند (به عنوان مثال، ردیابی شی مبتنی بر پیشبینی حرکت، تشخیص چهره). همانطور که قبلاً اشاره شد، تأخیر پردازش برای برنامههایی که باید چندین مدل هوش مصنوعی را برای هر فریم ویدیو اجرا کنند، مهمتر است.
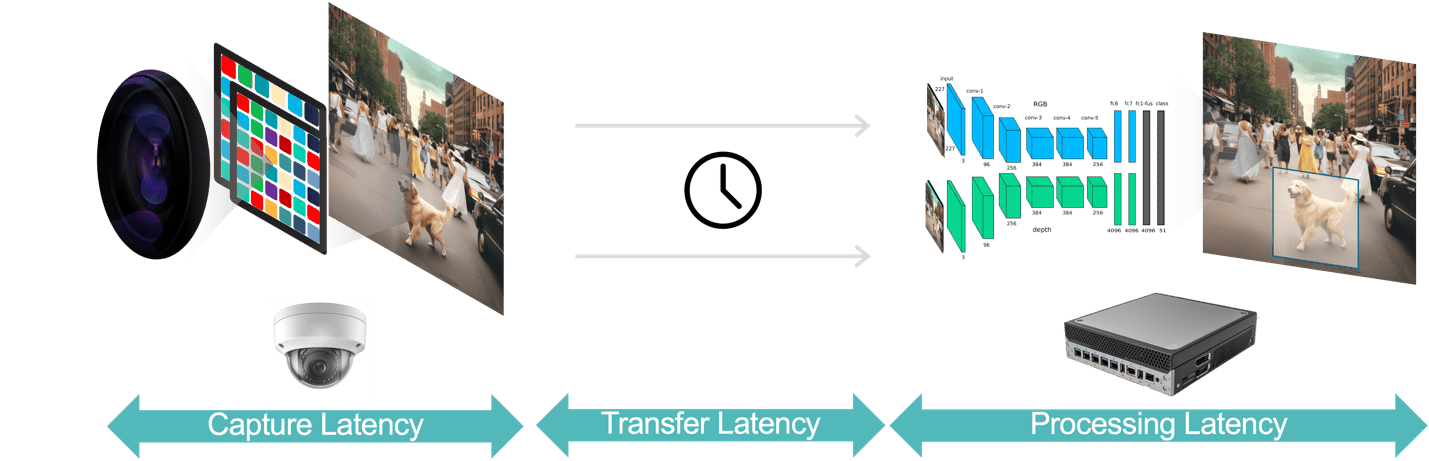
شکل 3. خط لوله تجزیه و تحلیل ویدئویی شامل جمع آوری داده، انتقال داده و پردازش داده است.
تأخیر پردازش داده ها را می توان با استفاده از یک شتاب دهنده هوش مصنوعی با معماری طراحی شده برای به حداقل رساندن حرکت داده ها در سراسر تراشه و بین محاسبات و سطوح مختلف سلسله مراتب حافظه بهینه کرد. همچنین، برای بهبود تأخیر و کارایی در سطح سیستم، معماری باید از زمان سوئیچینگ صفر (یا نزدیک به صفر) بین مدلها پشتیبانی کند تا از برنامههای چند مدلی که قبلاً بحث کردیم، بهتر پشتیبانی شود. عامل دیگر برای بهبود عملکرد و تأخیر به انعطافپذیری الگوریتمی مربوط میشود. به عبارت دیگر، برخی از معماریها برای رفتار بهینه فقط در مدلهای هوش مصنوعی خاص طراحی شدهاند، اما با تغییر سریع محیط هوش مصنوعی، مدلهای جدیدی برای عملکرد بالاتر و دقت بهتر در هر روز ظاهر میشوند. بنابراین، یک پردازنده هوش مصنوعی لبه ای بدون محدودیت عملی در توپولوژی مدل، عملگرها و اندازه انتخاب کنید.
عوامل زیادی برای به حداکثر رساندن عملکرد در یک ابزار هوش مصنوعی لبهای وجود دارد که شامل عملکرد و الزامات تأخیر و سربار سیستم میشود. یک استراتژی موفق باید یک شتاب دهنده هوش مصنوعی خارجی را برای غلبه بر محدودیت های حافظه و عملکرد در موتور هوش مصنوعی SoC در نظر بگیرد.
CH Chee Chee یک مدیر بازاریابی و مدیریت محصول موفق است، Chee دارای تجربه گسترده ای در ترویج محصولات و راه حل ها در صنعت نیمه هادی است که بر هوش مصنوعی مبتنی بر دید، اتصالات و رابط های ویدئویی برای بازارهای مختلف از جمله شرکت و مصرف کننده تمرکز دارد. چی به عنوان یک کارآفرین، دو استارت آپ نیمه هادی ویدئویی را تأسیس کرد که توسط یک شرکت نیمه هادی عمومی خریداری شدند. Chee تیم های بازاریابی محصول را رهبری می کند و از کار با تیم کوچکی که بر دستیابی به نتایج عالی تمرکز دارد لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- : دارد
- :است
- :نه
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- توانایی
- شتاب دهنده
- شتاب دهنده ها
- دسترسی
- دسترسی
- تطبیق
- انجام دادن
- دقت
- دستیابی به
- به دست آورد
- کسب می کند
- در میان
- عمل
- فعال
- واقعی
- اضافه کردن
- اضافی
- به تصویب رسید
- پیشرفته
- پس از
- از نو
- AI
- موتور هوش مصنوعی
- مدل های هوش مصنوعی
- الگوریتمی
- الگوریتم
- معرفی
- همچنین
- همیشه
- an
- تحلیل
- علم تجزیه و تحلیل
- تجزیه و تحلیل
- و
- تشخیص ناهنجاری
- دیگر
- کاربرد
- برنامه های کاربردی
- روش
- معماری
- هستند
- AS
- مرتبط است
- At
- خودکار بودن
- اتوماسیون
- خود مختار
- بصورت خودگردان
- دسترس پذیری
- در دسترس
- اجتناب از
- مستقر
- اساس
- BE
- زیرا
- شود
- بوده
- قبل از
- بودن
- محک
- بهتر
- میان
- هر دو
- جعبه
- جعبه
- ساخته شده در
- اتوبوس
- مشغول
- اما
- by
- دوربین
- دوربین
- CAN
- قابلیت های
- قابلیت
- گرفتن
- اسیر
- ضبط
- دقیق
- مورد
- موارد
- به چالش
- متغیر
- تراشه
- چیپس
- انتخاب
- کلاس
- ابر
- رنگ
- آینده
- شرکت
- رقابتی
- تکمیل شده
- اجزاء
- مصالحه
- محاسبه
- محاسباتی
- محاسبه
- کامپیوتر
- چشم انداز کامپیوتر
- برنامه های کاربردی بینایی کامپیوتر
- اعتماد به نفس
- پیکر بندی
- اتصال
- در نتیجه
- در نظر بگیرید
- توجه
- در نظر گرفته
- با توجه به
- تشکیل شده است
- محدودیت ها
- مصرف کننده
- شامل
- موجود
- مداوم
- به طور مداوم
- تبدیل
- میتوانست
- پردازنده
- بحرانی
- مشتری
- داده ها
- پردازش داده ها
- روز
- اختصاصی
- تاخیر
- تاخیر
- ارائه
- تحویل داده
- وابسته
- بستگی دارد
- مستقر
- اعزام ها
- شرح داده شده
- طراحی
- شناسایی شده
- کشف
- مشخص کردن
- توسعه دهندگان
- دستگاه ها
- تفاوت
- مستقیما
- بحث کردیم
- نمایش دادن
- مدت از کار افتادگی
- رانندگی
- دو
- بطور پویا
- e
- هر
- پیش از آن
- به آسانی
- لبه
- اثر
- اثر
- بازده
- بهره وری
- موثر
- هر دو
- تعبیه کردن
- پایان
- پشت سر هم
- موتور
- موتورهای حرفه ای
- بالا بردن
- اطمینان حاصل شود
- سرمایه گذاری
- تمام
- موسس شرکت
- محیط
- ضروری است
- برآورد
- ارزیابی
- حتی
- هر
- در حال تحول
- مثال
- تجاوز
- اجرا کردن
- اجرا شده
- اجرایی
- انتظار
- تجربه
- تجارب
- وسیع
- تجربه گسترده
- خارجی
- چهره
- تشخیص چهره
- عامل
- عوامل
- کارخانه
- FAST
- ویژگی
- تغذیه
- رشته
- شکل
- اثر انگشت
- نام خانوادگی
- انعطاف پذیری
- تمرکز
- تمرکز
- برای
- قالب
- FRAME
- از جانب
- تابع
- قابلیت
- توابع
- بعلاوه
- آینده
- به دست آوردن
- بازیها
- بازی
- تجربه بازی
- سوالات عمومی
- تولید می کنند
- تولید
- سخاوتمندانه
- Go
- GPU
- GPU ها
- بزرگ
- بیشتر
- در حال رشد
- رشد
- راهنمایی
- سخت افزار
- آیا
- از این رو
- اینجا کلیک نمایید
- سلسله مراتب
- زیاد
- بالاتر
- میزبان
- HTTPS
- i
- شناسایی
- if
- تصویر
- تأثیر
- مهم
- تحمیل
- بهبود
- بهبود یافته
- in
- در دیگر
- شامل
- از جمله
- افزایش
- افزایش
- لوازم
- صنعت
- شروع می کند
- ورودی
- داخل
- بینش
- یکپارچه
- اینتل
- رابط
- رابط
- به
- شامل
- شامل
- قطع نظر از
- ISP
- IT
- ITS
- kdnuggets
- برچسب ها
- عدم
- لین
- بزرگ
- تاخیر
- ترک
- رهبری
- کمتر
- سطح
- کتابخانه ها
- پسندیدن
- محدودیت
- محدودیت
- محدود شده
- لینک
- محلی
- از دست رفته
- کم
- کاهش
- مدیریت
- مدیریت
- تولید
- بسیاری
- بازار یابی (Marketing)
- بازارها
- بیشینه ساختن
- به حداکثر رساندن
- ممکن است..
- متوسط
- معیارهای
- دیدار
- حافظه
- ذکر شده
- قدرت
- از دست رفته
- مدل
- مدل
- واحد
- نظارت بر
- بیش
- اکثر
- حرکت
- جنبش
- چندگانه
- باید
- بی شمار
- نزدیک
- نیازهای
- شبکه
- عصبی
- شبکه های عصبی
- جدید
- بعد
- نه
- هدف
- تشخیص شی
- رخ می دهد
- of
- غالبا
- on
- یک بار
- ONE
- فقط
- OpenCV
- عمل
- قابل استفاده
- اپراتور
- مخالف
- بهینه
- بهینه سازی
- بهینه سازی
- بهینه
- بهینه سازی
- or
- دیگر
- خارج
- تولید
- روی
- به طور کلی
- غلبه بر
- موازی
- پارامترهای
- ویژه
- برای
- انجام دادن
- کارایی
- انجام
- انجام
- انجام می دهد
- خط لوله
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- نقطه
- موقعیت
- پردازش پس از
- عملی
- پیش گویی
- روند
- پردازش
- در حال پردازش
- پردازنده
- پردازنده ها
- محصول
- تولید
- محصولات
- ترویج
- ارائه
- عمومی
- محدوده
- اعم
- سریع
- سریعا
- نرخ
- نرخ
- خام
- داده های خام
- واقعی
- زمان واقعی
- واقعیت
- به رسمیت شناختن
- كاهش دادن
- اشاره دارد
- نیاز
- ضروری
- نیاز
- مورد نیاز
- نیاز
- وضوح
- منابع
- پاسخگو
- محدودیت های
- نتیجه
- نتایج
- رباتیک
- نقش
- دویدن
- در حال اجرا
- اجرا می شود
- ایمنی
- همان
- مقیاس پذیری
- مقیاس
- مقیاس Ai
- مقیاس گذاری
- صحنه
- نمرات
- بدون درز
- دوم
- بخش
- دیدن
- به نظر می رسد
- انتخاب
- نیمه هادی
- تنظیم
- اشتراک گذاری
- به اشتراک گذاشته شده
- خريد كردن
- باید
- نشان داده شده
- امضاء
- سیگنال
- به طور مشابه
- پس از
- تنها
- اندازه
- کوچک
- هوشمند
- راه حل
- مزایا
- حل
- حل می کند
- برخی از
- چیزی
- فضا
- خاص
- شروع یو پی اس
- مراحل
- opbevare
- استراتژی ها
- استراتژی
- جریان
- جریان
- موفق
- چنین
- کافی
- پشتیبانی
- سرکوب
- نظارت
- سیستم
- سیستم های
- گرفتن
- طول می کشد
- وظایف
- تیم
- تیم ها
- فن آوری
- پیشرفته
- قوانین و مقررات
- نسبت به
- که
- La
- آینده
- شان
- سپس
- آنجا.
- از این رو
- اینها
- آنها
- این
- کسانی که
- سه
- از طریق
- توان
- زمان
- بار
- به
- تاپس
- جمع
- مسیر
- پیگردی
- ترافیک
- انتقال
- نقل و انتقالات
- دگرگون کردن
- سفر
- درست
- دو
- به طور معمول
- در نهایت
- ناتوان
- فهمیدن
- واحد
- واحد
- استفاده
- USB
- استفاده کنید
- استفاده
- استفاده
- با استفاده از
- معمولا
- با استفاده از
- ارزشها
- تنوع
- مختلف
- تصویری
- چشم انداز
- مجازی
- واقعیت مجازی
- دید
- حیاتی
- vr
- مسیر..
- we
- بود
- چی
- چه
- که
- به طور گسترده ای
- اراده
- با
- بدون
- کلمات
- کارگر
- خواهد بود
- X
- بازده
- یولو
- شما
- شما
- زفیرنت
- صفر







