معرفی
تصور کنید در یک کتابخانه کم نور ایستاده اید و در تلاش برای رمزگشایی یک سند پیچیده هستید در حالی که ده ها متن دیگر را جادو می کنید. این دنیای ترانسفورمرز بود قبل از اینکه روزنامه "توجه تنها چیزی است که شما نیاز دارید" از کانون توجه انقلابی خود رونمایی کند - مکانیسم توجه.
جدول محتوا
محدودیت های RNN
مدل های متوالی سنتی، مانند شبکه های عصبی مکرر (RNN)، زبان را کلمه به کلمه پردازش می کند که منجر به چندین محدودیت می شود:
- وابستگی کوتاه برد: RNN ها برای درک ارتباط بین کلمات دور تلاش می کردند و اغلب معنای جملاتی مانند "مردی که دیروز از باغ وحش بازدید کرد" را اشتباه تفسیر می کردند، جایی که فاعل و فعل بسیار از هم فاصله دارند.
- توازی محدود: پردازش اطلاعات به صورت متوالی ذاتا کند است و از آموزش کارآمد و استفاده از منابع محاسباتی، به ویژه برای توالی های طولانی جلوگیری می کند.
- تمرکز بر زمینه محلی: RNN ها در درجه اول همسایگان فوری را در نظر می گیرند و به طور بالقوه اطلاعات مهمی را از قسمت های دیگر جمله از دست می دهند.
این محدودیتها توانایی Transformers را برای انجام کارهای پیچیده مانند ترجمه ماشینی و درک زبان طبیعی با مشکل مواجه میکرد. سپس آمد مکانیسم توجه، یک نورافکن انقلابی که ارتباطات پنهان بین کلمات را روشن می کند و درک ما از پردازش زبان را دگرگون می کند. اما توجه دقیقاً چه چیزی را حل کرد و چگونه بازی Transformers را تغییر داد؟
بیایید روی سه حوزه اصلی تمرکز کنیم:
وابستگی طولانی مدت
- مشکل: در مدل های سنتی اغلب با جملاتی مانند "زنی که روی تپه زندگی می کرد دیشب یک ستاره در حال تیراندازی دید." آنها به دلیل دوریشان برای ارتباط «زن» و «ستاره تیرانداز» تلاش کردند، که منجر به تفسیرهای نادرست شد.
- مکانیسم توجه: تصور کنید که مدل یک پرتو روشن در سراسر جمله می تابد، "زن" را مستقیما به "ستاره تیرانداز" متصل می کند و جمله را به عنوان یک کل درک می کند. این توانایی برای ثبت روابط بدون در نظر گرفتن فاصله برای کارهایی مانند ترجمه ماشینی و خلاصه سازی بسیار مهم است.
همچنین خواندن: مروری بر حافظه بلند مدت کوتاه مدت (LSTM)
قدرت پردازش موازی
- مشکل: در مدلهای سنتی اطلاعات را بهطور متوالی پردازش میکردند، مانند خواندن یک کتاب صفحه به صفحه. این کار کند و ناکارآمد بود، به خصوص برای متون طولانی.
- مکانیسم توجه: چندین نورافکن را تصور کنید که کتابخانه را به طور همزمان اسکن می کنند و قسمت های مختلف متن را به صورت موازی تجزیه و تحلیل می کنند. این به طور چشمگیری سرعت کار مدل را افزایش می دهد و به آن اجازه می دهد تا حجم وسیعی از داده ها را به طور موثر مدیریت کند. این قدرت پردازش موازی برای آموزش مدل های پیچیده و پیش بینی های بلادرنگ ضروری است.
آگاهی از زمینه جهانی
- مشکل: در مدلهای سنتی اغلب بر روی کلمات تکی تمرکز میکردند و بافت وسیعتر جمله را از دست میدادند. این منجر به سوء تفاهم در مواردی مانند طعنه یا معانی دوگانه شد.
- مکانیسم توجه: تجسم کنید که نور مرکز کل کتابخانه را فراگرفته، هر کتابی را میبرد و میفهمد که چگونه با یکدیگر ارتباط دارند. این آگاهی از زمینه جهانی به مدل اجازه می دهد تا کل متن را هنگام تفسیر هر کلمه در نظر بگیرد و به درک غنی تر و ظریف تر منجر شود.
ابهام زدایی کلمات چند معنایی
- مشکل: در کلماتی مانند "بانک" یا "سیب" می توانند اسم، فعل یا حتی شرکت باشند و ابهامی را ایجاد کنند که مدل های سنتی برای حل آن تلاش می کردند.
- مکانیسم توجه: تصور کنید که این مدل به همه موارد کلمه "بانک" در یک جمله نورافشانی می کند، سپس بافت اطراف و روابط با کلمات دیگر را تجزیه و تحلیل می کند. با در نظر گرفتن ساختار دستوری، اسامی نزدیک و حتی جملات گذشته، مکانیسم توجه می تواند معنای مورد نظر را استنباط کند. این توانایی برای ابهامزدایی از کلمات چند معنایی برای کارهایی مانند ترجمه ماشینی، خلاصهسازی متن و سیستمهای گفتگو بسیار مهم است.
این چهار جنبه - وابستگی دوربرد، قدرت پردازش موازی، آگاهی از زمینه جهانی و ابهامزدایی - قدرت تغییردهنده مکانیسمهای توجه را به نمایش میگذارند. آنها Transformers را به خط مقدم پردازش زبان طبیعی سوق داده اند و آنها را قادر می سازند تا وظایف پیچیده را با دقت و کارایی قابل توجه انجام دهند.
همانطور که NLP و به طور خاص LLM ها به تکامل خود ادامه می دهند، مکانیسم های توجه بدون شک نقش مهم تری ایفا خواهند کرد. آنها پل بین توالی خطی کلمات و ملیله غنی زبان بشری هستند و در نهایت، کلید باز کردن پتانسیل واقعی این شگفتی های زبانی هستند. این مقاله به انواع مختلف مکانیسم های توجه و عملکرد آنها می پردازد.
1. توجه به خود: ستاره راهنمای ترانسفورماتور
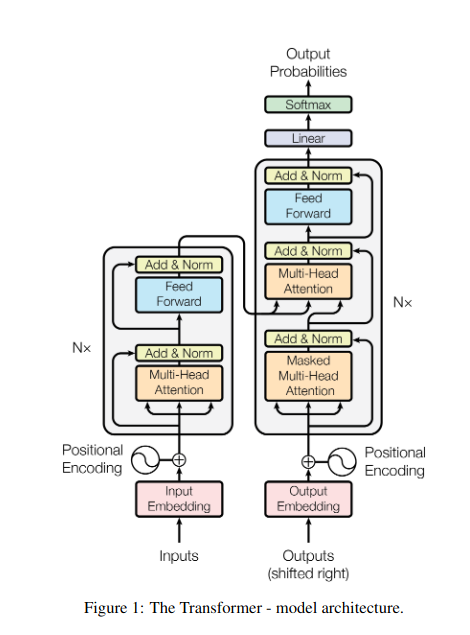
تصور کنید که در حال دستکاری چندین کتاب و نیاز به ارجاع قسمت های خاصی در هر کدام در حین نوشتن خلاصه هستید. توجه به خود یا Scaled Dot-Product توجه مانند یک دستیار هوشمند عمل می کند و به مدل ها کمک می کند تا همین کار را با داده های متوالی مانند جملات یا سری های زمانی انجام دهند. این به هر عنصر در دنباله اجازه می دهد تا به هر عنصر دیگری توجه کند و به طور موثر وابستگی های دوربرد و روابط پیچیده را به تصویر بکشد.
در اینجا نگاهی دقیق تر به جنبه های فنی اصلی آن داریم:
بازنمایی بردار
هر عنصر (کلمه، نقطه داده) به یک بردار با ابعاد بالا تبدیل می شود و محتوای اطلاعاتی خود را رمزگذاری می کند. این فضای برداری به عنوان پایه ای برای تعامل بین عناصر عمل می کند.
تبدیل QKV
سه ماتریس کلیدی تعریف شده است:
- پرس و جو (Q): "سوالی" را که هر عنصر برای دیگران مطرح می کند را نشان می دهد. Q نیازهای اطلاعاتی عنصر فعلی را جمعآوری میکند و جستجوی آن را برای اطلاعات مرتبط در داخل دنباله هدایت میکند.
- کلید (K): "کلید" را برای اطلاعات هر عنصر نگه می دارد. K ماهیت محتوای هر عنصر را رمزگذاری می کند و عناصر دیگر را قادر می سازد تا ارتباط بالقوه را بر اساس نیازهای خود شناسایی کنند.
- مقدار (V): محتوای واقعی را که هر عنصر می خواهد به اشتراک بگذارد را ذخیره می کند. V حاوی اطلاعات دقیقی است که سایر عناصر می توانند به آنها دسترسی داشته باشند و بر اساس امتیاز توجه خود از آنها استفاده کنند.
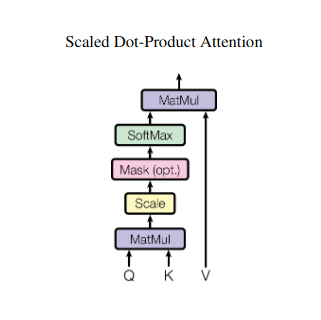
محاسبه امتیاز توجه
سازگاری بین هر جفت عنصر از طریق حاصل ضرب نقطه ای بین بردارهای Q و K مربوطه آنها اندازه گیری می شود. نمرات بالاتر نشان دهنده ارتباط بالقوه قوی تر بین عناصر است.
وزنه های توجه مقیاس شده
برای اطمینان از اهمیت نسبی، این امتیازات سازگاری با استفاده از یک تابع softmax عادی می شوند. این منجر به وزنهای توجه، از 0 تا 1 میشود که نشاندهنده اهمیت وزنی هر عنصر برای زمینه عنصر فعلی است.
تجمع بافت وزنی
وزن توجه به ماتریس V اعمال می شود و اساساً اطلاعات مهم هر عنصر را بر اساس ارتباط آن با عنصر فعلی برجسته می کند. این مجموع وزنی یک نمایش متنی برای عنصر فعلی ایجاد میکند و بینشهای جمعآوریشده از همه عناصر دیگر را در دنباله ترکیب میکند.
نمایش عنصر پیشرفته
با بازنمایی غنیشدهاش، این عنصر اکنون درک عمیقتری از محتوای خود و همچنین روابطش با عناصر دیگر در دنباله دارد. این نمایش تبدیل شده مبنایی را برای پردازش بعدی در مدل تشکیل می دهد.
این فرآیند چند مرحله ای، توجه به خود را به موارد زیر ممکن می سازد:
- وابستگی های دوربرد را ضبط کنید: روابط بین عناصر دور به آسانی آشکار می شود، حتی اگر توسط چندین عنصر مداخله گر از هم جدا شوند.
- مدلسازی تعاملات پیچیده: وابستگیها و همبستگیهای ظریف درون توالی آشکار میشوند که منجر به درک غنیتری از ساختار داده و پویایی میشود.
- متنی کردن هر عنصر: این مدل هر عنصر را نه به صورت مجزا، بلکه در چارچوب وسیعتر دنباله تحلیل میکند، که منجر به پیشبینیها یا نمایشهای دقیقتر و دقیقتر میشود.
توجه به خود انقلابی در نحوه پردازش دادههای متوالی توسط مدلها ایجاد کرده است و امکانهای جدیدی را در زمینههای مختلف مانند ترجمه ماشینی، تولید زبان طبیعی، پیشبینی سریهای زمانی و فراتر از آن باز میکند. توانایی آن در پرده برداری از روابط پنهان درون توالی ها ابزار قدرتمندی برای کشف بینش ها و دستیابی به عملکرد برتر در طیف گسترده ای از وظایف است.
2. توجه چند سر: دیدن از طریق لنزهای مختلف
توجه به خود یک دیدگاه جامع ارائه می دهد، اما گاهی اوقات تمرکز بر جنبه های خاص داده ها بسیار مهم است. اینجاست که توجه چند سر به میان می آید. تصور کنید دستیارهای متعددی دارید که هر کدام به لنز متفاوتی مجهز هستند:
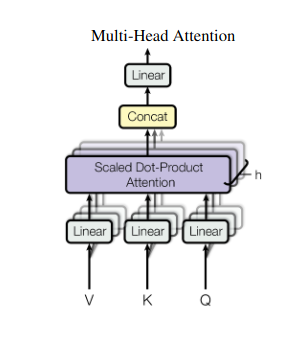
- چندین "سر" ایجاد می شوند و هر کدام از طریق ماتریس های Q، K و V به دنباله ورودی خود می پردازند.
- هر سر می آموزد که روی جنبه های مختلف داده ها تمرکز کند، مانند وابستگی های دوربرد، روابط نحوی یا تعاملات کلمه محلی.
- سپس خروجیهای هر هد به هم متصل شده و به نمایش نهایی نمایش داده میشوند و ماهیت چند وجهی ورودی را به تصویر میکشند.
این به مدل اجازه می دهد تا به طور همزمان دیدگاه های مختلف را در نظر بگیرد، که منجر به درک غنی تر و ظریف تر از داده ها می شود.
3. توجه متقابل: ایجاد پل بین دنباله ها
توانایی درک ارتباطات بین قطعات مختلف اطلاعات برای بسیاری از وظایف NLP بسیار مهم است. تصور کنید که یک نقد کتاب بنویسید - شما فقط متن را کلمه به کلمه خلاصه نمی کنید، بلکه بینش ها و ارتباطات بین فصل ها را ترسیم می کنید. وارد توجه متقابلیک مکانیسم قوی که بین توالیها پل میسازد و مدلها را برای استفاده از اطلاعات از دو منبع مجزا توانمند میسازد.
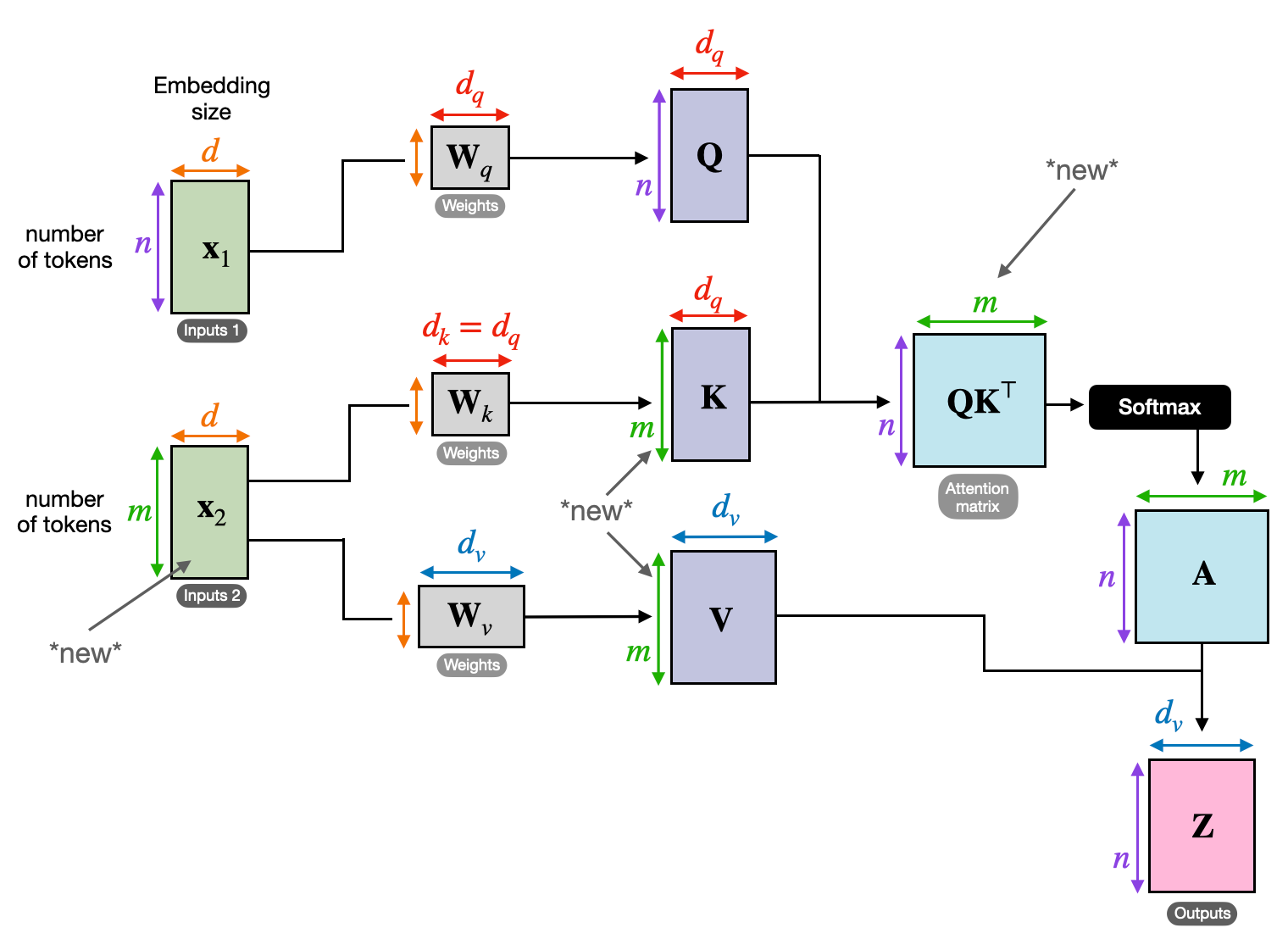
- در معماری رمزگذار-رمزگشا مانند ترانسفورماتورها، رمز گذار دنباله ورودی (کتاب) را پردازش می کند و یک نمایش پنهان تولید می کند.
- La رمز گشا از توجه متقاطع برای توجه به نمایش پنهان رمزگذار در هر مرحله در حین تولید دنباله خروجی (بررسی) استفاده می کند.
- ماتریس Q رمزگشا با ماتریسهای K و V رمزگذار در تعامل است و به آن اجازه میدهد در حین نوشتن هر جمله مرور، روی بخشهای مرتبط کتاب تمرکز کند.
این مکانیسم برای کارهایی مانند ترجمه ماشینی، خلاصه سازی و پاسخگویی به سؤال، که درک روابط بین توالی های ورودی و خروجی ضروری است، بسیار ارزشمند است.
4. توجه علّی: حفظ جریان زمان
تصور کنید کلمه بعدی را در یک جمله بدون نگاه کردن به جلو پیش بینی کنید. مکانیسمهای توجه سنتی با وظایفی که نیازمند حفظ نظم زمانی اطلاعات هستند، مانند تولید متن و پیشبینی سریهای زمانی، مبارزه میکنند. آنها بهآسانی در سکانس «به جلو نگاه میکنند» که منجر به پیشبینیهای نادرست میشود. توجه علّی با اطمینان از اینکه پیشبینیها صرفاً به اطلاعات پردازش شده قبلی بستگی دارند، این محدودیت را برطرف میکند.
در اینجا نحوه عملکرد آن آمده است
- مکانیسم پوشش: یک ماسک خاص روی وزنه های توجه اعمال می شود و به طور موثر دسترسی مدل را به عناصر بعدی در دنباله مسدود می کند. به عنوان مثال، هنگام پیشبینی کلمه دوم در «زنی که…»، مدل فقط میتواند «the» را در نظر بگیرد و نه «چه کسی» یا کلمات بعدی را.
- پردازش خود رگرسیون: اطلاعات به صورت خطی جریان می یابد و نمایش هر عنصر صرفاً از عناصر ظاهر شده قبل از آن ساخته می شود. این مدل توالی را کلمه به کلمه پردازش می کند و پیش بینی هایی را بر اساس زمینه ایجاد شده تا آن نقطه ایجاد می کند.
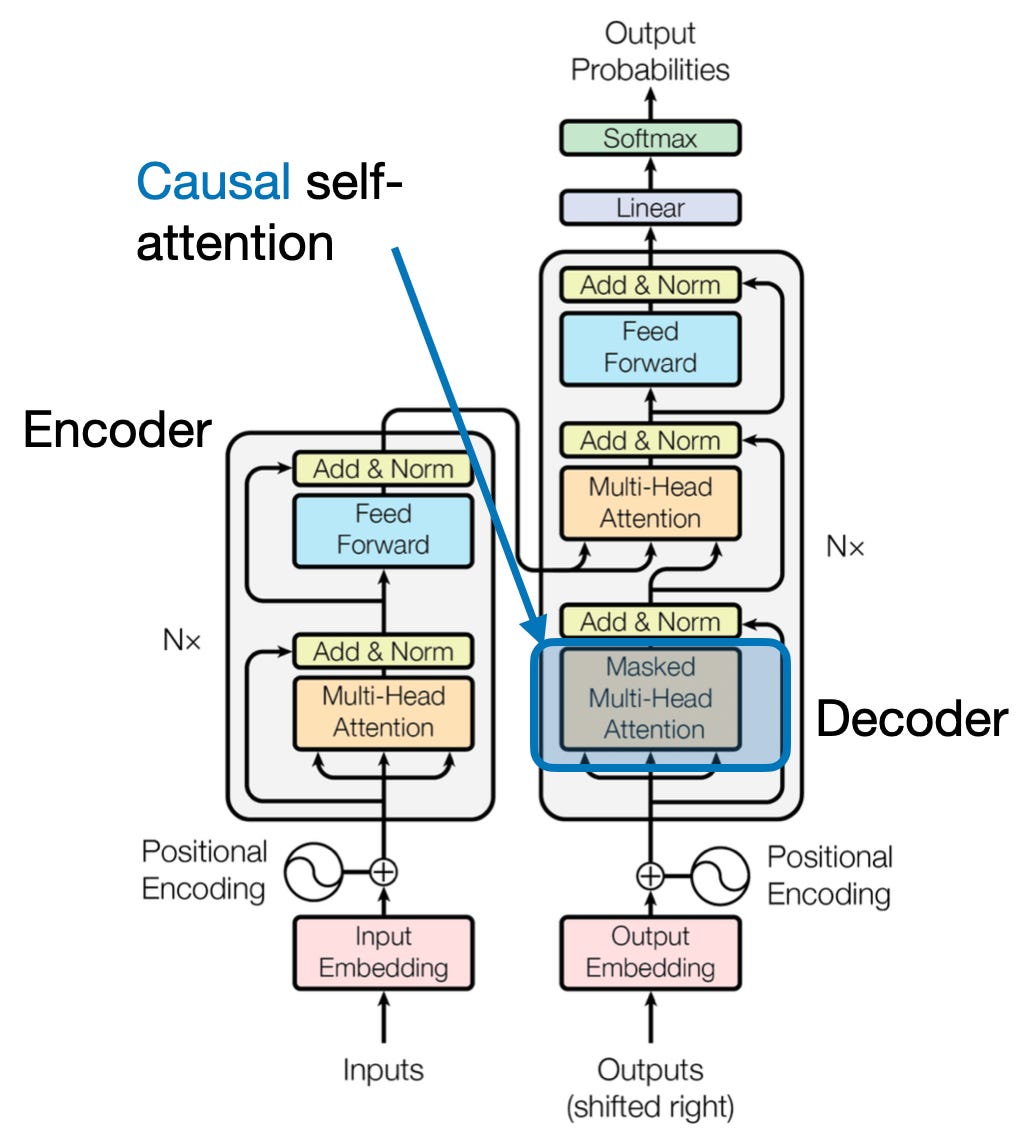
توجه علّی برای کارهایی مانند تولید متن و پیشبینی سریهای زمانی حیاتی است، جایی که حفظ نظم زمانی دادهها برای پیشبینیهای دقیق حیاتی است.
5. توجه جهانی در مقابل محلی: ایجاد تعادل
مکانیسمهای توجه با یک مبادله کلیدی روبرو هستند: گرفتن وابستگیهای دوربرد در مقابل حفظ محاسبات کارآمد. این امر در دو رویکرد اصلی آشکار می شود: توجه جهانی و توجه محلی. تصور کنید که یک کتاب کامل را در مقابل تمرکز بر یک فصل خاص بخوانید. توجه جهانی کل دنباله را به یکباره پردازش می کند، در حالی که توجه محلی روی یک پنجره کوچکتر متمرکز می شود:
- توجه جهانی وابستگی های دوربرد و زمینه کلی را به تصویر می کشد، اما می تواند از نظر محاسباتی برای دنباله های طولانی گران باشد.
- توجه محلی کارآمدتر است اما ممکن است روابط دور را از دست بدهد.
انتخاب بین توجه جهانی و محلی به عوامل مختلفی بستگی دارد:
- الزامات وظیفه: کارهایی مانند ترجمه ماشینی نیاز به گرفتن روابط دور، جلب توجه جهانی دارند، در حالی که تجزیه و تحلیل احساسات ممکن است به نفع تمرکز توجه محلی باشد.
- طول توالی: توالی های طولانی تر توجه جهانی را از نظر محاسباتی گران می کند و نیاز به رویکردهای محلی یا ترکیبی دارد.
- ظرفیت مدل: محدودیت های منابع ممکن است نیاز به توجه محلی حتی برای کارهایی که به زمینه جهانی نیاز دارند، داشته باشد.
برای دستیابی به تعادل بهینه، مدل ها می توانند از موارد زیر استفاده کنند:
- سوئیچینگ دینامیک: از توجه جهانی برای عناصر کلیدی و توجه محلی برای دیگران استفاده کنید و بر اساس اهمیت و فاصله تطبیق دهید.
- رویکردهای ترکیبی: هر دو مکانیسم را در یک لایه ترکیب کنید و از نقاط قوت آنها استفاده کنید.
همچنین خواندن: تحلیل انواع شبکه های عصبی در یادگیری عمیق
نتیجه
در نهایت، رویکرد ایده آل در طیفی بین توجه جهانی و محلی قرار دارد. درک این مبادلات و اتخاذ استراتژیهای مناسب به مدلها اجازه میدهد تا به طور مؤثر از اطلاعات مرتبط در مقیاسهای مختلف بهرهبرداری کنند، که منجر به درک دقیقتر و غنیتر از توالی میشود.
منابع
- راشکا، اس. (2023). "درک و کدگذاری توجه به خود، توجه چند سر، توجه متقاطع و توجه علّی در LLM."
- واسوانی، ا.، و همکاران. (2017). "توجه تنها چیزی است که نیاز دارید."
- رادفورد، ا.، و همکاران. (2019). "مدل های زبان، یادگیرندگان چند وظیفه ای بدون نظارت هستند."
مربوط
من عاشق داده هستم و عاشق استخراج و درک الگوهای پنهان در داده ها هستم. من می خواهم در زمینه یادگیری ماشین و علم داده یاد بگیرم و رشد کنم.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- توانایی
- دسترسی
- دقت
- دقیق
- رسیدن
- دستیابی به
- در میان
- اعمال
- واقعی
- آدرس
- تصویب
- پیش
- AL
- معرفی
- اجازه دادن
- اجازه می دهد تا
- am
- ابهام
- مقدار
- an
- تحلیل
- تجزیه و تحلیل
- تجزیه و تحلیل
- و
- پاسخ دادن
- جدا
- ظاهر
- اعمال می شود
- روش
- رویکردها
- هستند
- مناطق
- مقاله
- AS
- جنبه
- دستیار
- دستیاران
- At
- مراجعه كردن
- شرکت کننده
- توجه
- اطلاع
- برج میزان
- مستقر
- اساس
- BE
- پرتو
- شدن
- قبل از
- میان
- خارج از
- انسداد
- کتاب
- کتاب
- هر دو
- بریج
- پل
- روشن
- گسترده تر
- آورده
- بنا
- می سازد
- ساخته
- اما
- by
- آمد
- CAN
- گرفتن
- جلب
- ضبط
- موارد
- تغییر دادن
- فصل
- فصل ها
- انتخاب
- نزدیک
- برنامه نویسی
- ترکیب
- می آید
- شرکت
- سازگاری
- پیچیده
- محاسبه
- محاسباتی
- اتصال
- اتصال
- اتصالات
- در نظر بگیرید
- با توجه به
- محدودیت ها
- شامل
- محتوا
- زمینه
- ادامه دادن
- هسته
- همبستگی
- ایجاد شده
- ایجاد
- ایجاد
- بحرانی
- بسیار سخت
- جاری
- داده ها
- علم اطلاعات
- کشف کردن
- عمیق
- عمیق تر
- مشخص
- غوطه ور شدن
- بستگی دارد
- وابستگی
- وابستگی
- وابستگی
- بستگی دارد
- دقیق
- گفتگو
- DID
- مختلف
- مستقیما
- فاصله
- دور
- متمایز
- مختلف
- do
- سند
- DOT
- دو برابر
- ده ها
- به طور چشمگیری
- قرعه کشی
- دو
- دینامیک
- E&T
- هر
- به طور موثر
- بهره وری
- موثر
- موثر
- عنصر
- عناصر
- توانمندسازی
- را قادر می سازد
- را قادر می سازد
- پشتیبانی می کند
- غنی شده
- اطمینان حاصل شود
- حصول اطمینان از
- وارد
- تمام
- کل
- مجهز بودن
- به خصوص
- ماهیت
- ضروری است
- اساسا
- تاسیس
- حتی
- هر
- تکامل یابد
- کاملا
- گران
- بهره برداری
- عصاره
- چهره
- عوامل
- بسیار
- توجه
- رشته
- زمینه
- نهایی
- جریان
- جریانها
- تمرکز
- متمرکز شده است
- تمرکز
- تمرکز
- برای
- خط مقدم
- اشکال
- پایه
- چهار
- چارچوب
- از جانب
- تابع
- ویژگی های
- آینده
- بازی
- تولید می کند
- مولد
- نسل
- جهانی
- زمینه جهانی
- فهم
- شدن
- راهنما
- راهنمایی
- دسته
- آیا
- داشتن
- سر
- کمک
- پنهان
- زیاد
- بالاتر
- مشخص کردن
- دارای
- جامع
- چگونه
- HTTPS
- انسان
- ترکیبی
- i
- دلخواه
- شناسایی
- if
- تصور کنید
- فوری
- اهمیت
- مهم
- in
- نادرست
- گنجاندن
- نشان دادن
- فرد
- ناکارآمد
- اطلاعات
- ذاتا
- ورودی
- بینش
- نمونه
- هوشمند
- مورد نظر
- اثر متقابل
- فعل و انفعالات
- در ارتباط بودن
- مداخله
- به
- فوق العاده گرانبها
- انزوا
- IT
- ITS
- JPG
- تنها
- کلید
- مناطق کلیدی
- زبان
- نام
- لایه
- برجسته
- یاد گرفتن
- یاد بگیرید و رشد کنید
- زبان آموزان
- یادگیری
- رهبری
- عدسی
- لنز
- قدرت نفوذ
- بهره برداری
- کتابخانه
- نهفته است
- سبک
- پسندیدن
- محدودیت
- محدودیت
- محلی
- طولانی
- دیگر
- نگاه کنيد
- عشق
- دستگاه
- فراگیری ماشین
- ترجمه ماشین
- نگهداری
- ساخت
- ساخت
- مرد
- بسیاری
- ماسک
- ماتریس
- حداکثر عرض
- معنی
- معانی
- اندازه گیری
- مکانیزم
- مکانیسم
- حافظه
- قدرت
- از دست
- گم
- مدل
- مدل
- بیش
- کارآمدتر
- چند وجهی
- چندگانه
- طبیعی
- زبان طبیعی
- تولید زبان طبیعی
- پردازش زبان طبیعی
- درک زبان طبیعی
- طبیعت
- نیاز
- نیازمند
- نیازهای
- همسایه ها
- شبکه
- عصبی
- شبکه های عصبی
- جدید
- بعد
- شب
- nlp
- اسمها
- اکنون
- ظریف
- of
- غالبا
- on
- یک بار
- فقط
- بهینه
- or
- سفارش
- دیگر
- دیگران
- ما
- خارج
- تولید
- خروجی
- به طور کلی
- مروری
- خود
- با ما
- جفت
- مقاله
- موازی
- بخش
- معابر
- گذشته
- الگوهای
- انجام دادن
- کارایی
- دیدگاه
- قطعات
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- نقطه
- به شمار
- دارای
- فرصت
- قوی
- پتانسیل
- بالقوه
- قدرت
- قوی
- پیش بینی
- پیش بینی
- حفظ کردن
- جلوگیری
- قبلا
- در درجه اول
- اصلی
- روند
- پردازش
- فرآیندهای
- در حال پردازش
- قدرت پردازش
- محصول
- پیش بینی
- پیشران
- فراهم می کند
- سوال
- محدوده
- اعم
- نسبتا
- خواندن
- به راحتی
- مطالعه
- زمان واقعی
- مرجع
- بدون در نظر گرفتن
- روابط
- نسبی
- ربط
- مربوط
- قابل توجه
- نمایندگی
- نمایندگی
- نشان دهنده
- نیاز
- تصمیم
- منابع
- منابع
- قابل احترام
- نتایج
- این فایل نقد می نویسید:
- انقلابی
- انقلابی
- غنی
- نقش
- s
- همان
- طعنه
- دید
- مقیاس ها
- پویش
- علم
- نمره
- نمرات
- جستجو
- دوم
- مشاهده
- جمله
- احساس
- دنباله
- سلسله
- خدمت
- چند
- اشتراک گذاری
- درخشان
- تیراندازی کردن
- کوتاه
- نمایشگاه
- به طور همزمان
- کند
- کوچکتر
- فقط
- حل
- گاهی
- منابع
- فضا
- خاص
- به طور خاص
- طیف
- سرعت
- نور افکن
- ایستاده
- ستاره
- گام
- پرده
- استراتژی ها
- نقاط قوت
- قوی
- ساختار
- مبارزه
- تلاش
- موضوع
- متعاقب
- چنین
- مناسب
- مجموع
- خلاصه کردن
- خلاصه
- برتر
- اطراف
- سیستم های
- برخورد با
- مصرف
- ملیله
- وظایف
- فنی
- مدت
- متن
- تولید متن
- که
- La
- جهان
- شان
- آنها
- سپس
- اینها
- آنها
- این
- سه
- از طریق
- زمان
- سری زمانی
- به
- ابزار
- سنتی
- آموزش
- دگرگونی
- مبدل
- ترانسفورماتور
- ترانسفورماتور
- تبدیل شدن
- ترجمه
- درست
- دو
- انواع
- در نهایت
- فهمیدن
- درک
- بی شک
- باز کردن قفل
- پرده برداری
- پرده برداری کرد
- استفاده کنید
- استفاده
- با استفاده از
- مختلف
- وسیع
- در مقابل
- چشم انداز
- بازدید
- حیاتی
- vs
- می خواهم
- می خواهد
- بود
- خوب
- چی
- چه زمانی
- در حین
- WHO
- تمام
- وسیع
- دامنه گسترده
- اراده
- پنجره
- با
- در داخل
- بدون
- زن
- کلمه
- کلمات
- مهاجرت کاری
- جهان
- نوشته
- دیروز
- شما
- زفیرنت
- ZOO