تصویر توسط ویرایشگر
گیرنده های کلیدی
- آزمون t یک آزمون آماری است که با استفاده از آن می توان تفاوت معنی داری بین میانگین دو نمونه مستقل از داده ها را تعیین کرد.
- ما نشان میدهیم که چگونه آزمون t را میتوان با استفاده از مجموعه داده iris و کتابخانه Scipy پایتون اعمال کرد.
آزمون t یک آزمون آماری است که با استفاده از آن می توان تفاوت معنی داری بین میانگین دو نمونه مستقل از داده ها را تعیین کرد. در این آموزش، ابتداییترین نسخه آزمون t را نشان میدهیم، که برای آن فرض میکنیم که دو نمونه دارای واریانس مساوی هستند. سایر نسخه های پیشرفته آزمون t شامل آزمون t Welch است که اقتباسی از آزمون t است و زمانی که دو نمونه دارای واریانس نابرابر و احتمالاً حجم نمونه نابرابر باشند قابل اعتمادتر است.
آماره t یا t-value به صورت زیر محاسبه می شود:
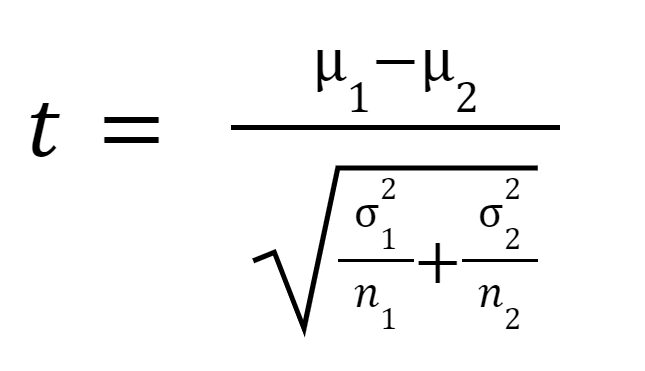
جایی که
میانگین نمونه 1 است،
میانگین نمونه 2 است،
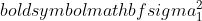 واریانس نمونه 1 است،
واریانس نمونه 1 است، 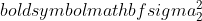 واریانس نمونه 2 است،
واریانس نمونه 2 است، 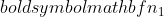 حجم نمونه نمونه 1 است و
حجم نمونه نمونه 1 است و 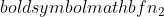 حجم نمونه نمونه 2 است.
حجم نمونه نمونه 2 است.
برای نشان دادن استفاده از آزمون t، یک مثال ساده با استفاده از مجموعه داده عنبیه نشان خواهیم داد. فرض کنید ما دو نمونه مستقل مانند طول کاسبرگ گل را مشاهده می کنیم و در نظر داریم که آیا این دو نمونه از یک جمعیت (مثلاً یک گونه گل یا دو گونه با ویژگی های کاسبرگ مشابه) گرفته شده اند یا از دو جمعیت متفاوت.
آزمون t تفاوت بین میانگین های حسابی دو نمونه را کمی می کند. p-value احتمال به دست آوردن نتایج مشاهده شده را با فرض صحت فرضیه صفر (که نمونه ها از جمعیت هایی با میانگین جمعیت یکسان گرفته شده اند) کمی می کند. مقدار p بزرگتر از یک آستانه انتخاب شده (مثلاً 5٪ یا 0.05) نشان می دهد که مشاهده ما چندان بعید نیست که تصادفی رخ داده باشد. بنابراین، فرضیه صفر میانگین جمعیت برابر را می پذیریم. اگر مقدار p کوچکتر از آستانه ما باشد، ما شواهدی علیه فرضیه صفر میانگین جمعیت برابر داریم.
ورودی T-Test
ورودی ها یا پارامترهای لازم برای انجام آزمون t عبارتند از:
- دو آرایه a و b حاوی داده های نمونه 1 و نمونه 2 است
خروجی های T-Test
آزمون t موارد زیر را برمی گرداند:
- آمار t محاسبه شده
- مقدار p
کتابخانه های لازم را وارد کنید
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
مجموعه داده Iris را بارگیری کنید
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
میانگین نمونه و واریانس نمونه را محاسبه کنید
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
اجرای آزمون t
stats.ttest_ind(a_1, b_1, equal_var = False)
تولید
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
تولید
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
تولید
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)مشاهدات
مشاهده می کنیم که استفاده از "درست" یا "نادرست" برای پارامتر "equal-var" نتایج آزمون t را چندان تغییر نمی دهد. همچنین مشاهده میکنیم که تعویض ترتیب آرایههای نمونه a_1 و b_1 یک مقدار آزمون t منفی به دست میدهد، اما آنطور که انتظار میرود، بزرگی مقدار آزمون t را تغییر نمیدهد. از آنجایی که مقدار p محاسبه شده بسیار بزرگتر از مقدار آستانه 0.05 است، میتوانیم فرضیه صفر را رد کنیم که تفاوت بین میانگینهای نمونه 1 و نمونه 2 معنیدار است. این نشان می دهد که طول کاسبرگ برای نمونه 1 و نمونه 2 از داده های جمعیت یکسان گرفته شده است.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
میانگین نمونه و واریانس نمونه را محاسبه کنید
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
اجرای آزمون t
stats.ttest_ind(a_1, b_1, equal_var = False)
تولید
stats.ttest_ind(a_1, b_1, equal_var = False)مشاهدات
مشاهده میکنیم که استفاده از نمونههایی با اندازه نابرابر، آمار t و p-value را بهطور معنیداری تغییر نمیدهد.
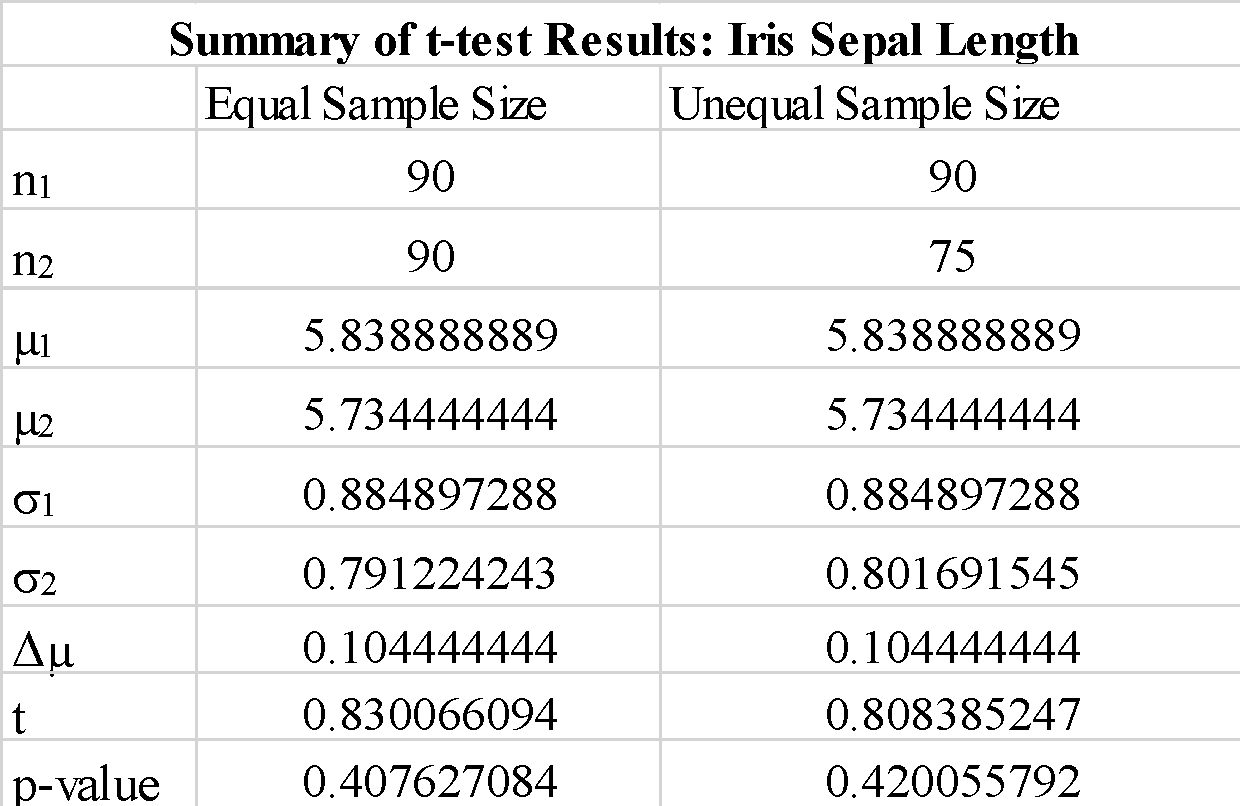
به طور خلاصه، ما نشان دادیم که چگونه یک آزمون t ساده را می توان با استفاده از کتابخانه scipy در پایتون پیاده سازی کرد.
بنجامین او تایو یک فیزیکدان، مدرس علوم داده، و نویسنده، و همچنین مالک DataScienceHub است. پیش از این، بنجامین مهندسی و فیزیک را در U. of Central Oklahoma، Grand Canyon U. و Pittsburgh State U تدریس می کرد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- پذیرفتن
- پیشرفته
- در برابر
- و
- اعمال می شود
- اساسی
- بنیامین
- میان
- محاسبه
- مرکزی
- شانس
- تغییر دادن
- مشخصات
- برگزیده
- با توجه به
- میتوانست
- داده ها
- علم اطلاعات
- مجموعه داده ها
- مشخص کردن
- تفاوت
- مختلف
- کشیده شده
- مهندسی
- مدرک
- مثال
- انتظار می رود
- گل
- پیروی
- به دنبال آن است
- از جانب
- چگونه
- HTTPS
- اجرا
- واردات
- in
- شامل
- مستقل
- نشان می دهد
- kdnuggets
- بزرگتر
- کتابخانه
- لینک
- ماتپلوتلب
- به معنی
- بیش
- اکثر
- لازم
- منفی
- بی حس
- مشاهده کردن
- بدست آوردن
- رخ داده است
- اوکلاهما
- سفارش
- دیگر
- مالک
- پارامتر
- پارامترهای
- انجام
- فیزیک
- پیتزبورگ
- افلاطون
- هوش داده افلاطون
- PlatoData
- جمعیت
- جمعیت
- قبلا
- احتمال
- پــایتــون
- قابل اعتماد
- نتایج
- بازده
- همان
- علم
- نشان
- نشان داده شده
- نشان می دهد
- قابل توجه
- به طور قابل توجهی
- مشابه
- ساده
- پس از
- اندازه
- اندازه
- کوچکتر
- So
- دولت
- آماری
- آمار
- خلاصه
- تعلیم
- آزمون
- La
- از این رو
- آستانه
- به
- درست
- آموزش
- استفاده کنید
- ارزش
- نسخه
- چه
- که
- اراده
- نویسنده
- بازده
- زفیرنت