یک مقاله فنی با عنوان "راه حل استنتاج کارآمد LLM در پردازنده گرافیکی اینتل" توسط محققان شرکت اینتل منتشر شد.
چکیده:
مدلهای زبان بزرگ مبتنی بر ترانسفورماتور (LLM) به طور گسترده در بسیاری از زمینهها مورد استفاده قرار گرفتهاند و کارایی استنتاج LLM به موضوع داغ در کاربردهای واقعی تبدیل میشود. با این حال، LLM ها معمولاً به طور پیچیده در ساختار مدل با عملیات عظیم طراحی می شوند و استنتاج را در حالت رگرسیون خودکار انجام می دهند، که طراحی یک سیستم با کارایی بالا را به یک کار چالش برانگیز تبدیل می کند.
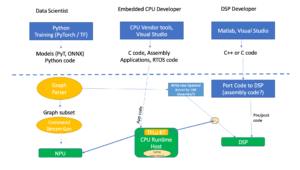
در این مقاله، ما یک راهحل استنتاج LLM کارآمد با تأخیر کم و توان عملیاتی بالا پیشنهاد میکنیم. در مرحله اول، ما لایه رمزگشای LLM را با ترکیب حرکت داده و عملیات عنصری برای کاهش فرکانس دسترسی به حافظه و کاهش تأخیر سیستم ساده می کنیم. ما همچنین یک خطمشی کش KV را پیشنهاد میکنیم تا کلید/مقدار توکنهای درخواست و پاسخ را در حافظه فیزیکی جداگانه برای مدیریت موثر حافظه دستگاه نگهداری کنیم، که به بزرگتر کردن اندازه دستهای زمان اجرا و بهبود توان عملیاتی سیستم کمک میکند. یک هسته Scaled-Dot-Product-Attention سفارشی شده برای مطابقت با خط مشی ترکیبی ما بر اساس راه حل کش بخش KV طراحی شده است. ما راه حل استنتاج LLM خود را بر روی پردازنده گرافیکی اینتل پیاده سازی می کنیم و آن را به صورت عمومی منتشر می کنیم. در مقایسه با اجرای استاندارد HuggingFace، راه حل پیشنهادی تا 7 برابر تاخیر توکن کمتر و 27 برابر توان عملیاتی بیشتر برای برخی از LLM های محبوب در پردازنده گرافیکی اینتل به دست می آورد.
یافتن مقاله فنی اینجا منتشر شده در دسامبر 2023 (پیش چاپ).
وو، هوی، یی گان، فنگ یوان، جینگ ما، وی ژو، یوتائو ژو، هونگ ژو، یوهوا ژو، شیائولی لیو، و جینگ هوی گو. "راه حل کارآمد استنتاج LLM در پردازنده گرافیکی اینتل." پیش چاپ arXiv arXiv:2401.05391 (2023).
خواندن مرتبط
استنتاج LLM در CPU (اینتل)
یک مقاله فنی با عنوان "استنتاج کارآمد LLM در CPU" توسط محققان اینتل منتشر شد.
هوش مصنوعی تا لبه مسابقه می دهد
با گسترش هوش مصنوعی به برنامه های جدید، استنتاج و برخی آموزش ها به دستگاه های کوچکتر منتقل می شوند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://semiengineering.com/llm-inference-on-gpus-intel/
- :است
- $UP
- 2023
- a
- دسترسی
- دستیابی به
- AI
- همچنین
- an
- و
- برنامه های کاربردی
- هستند
- AS
- At
- مستقر
- شود
- بوده
- بودن
- by
- نهانگاه
- به چالش کشیدن
- مقایسه
- شرکت
- سفارشی
- داده ها
- دسامبر
- طرح
- طراحی
- دستگاه
- دستگاه ها
- موثر
- بهره وری
- موثر
- بزرگنمایی کنید
- زمینه
- برای
- فرکانس
- فیوز کردن
- ادغام
- GPU
- GPU ها
- آیا
- کمک
- اینجا کلیک نمایید
- زیاد
- بالاتر
- هنگ
- HOT
- اما
- HTTPS
- صورت در آغوش گرفته
- انجام
- پیاده سازی
- بهبود
- in
- اینتل
- IT
- JPG
- نگاه داشتن
- زبان
- بزرگ
- تاخیر
- لایه
- llm
- کم
- کاهش
- ساخت
- مدیریت
- بسیاری
- عظیم
- مسابقه
- حافظه
- حالت
- مدل
- مدل
- جنبش
- جدید
- of
- on
- باز کن
- عملیات
- ما
- مقاله
- انجام دادن
- فیزیکی
- افلاطون
- هوش داده افلاطون
- PlatoData
- سیاست
- محبوب
- پیشنهادات
- پیشنهاد شده
- عمومی
- منتشر کردن
- منتشر شده
- تحت فشار قرار دادند
- نژادها
- واقعی
- كاهش دادن
- درخواست
- محققان
- پاسخ
- بخش
- جداگانه
- ساده کردن
- اندازه
- کوچکتر
- راه حل
- برخی از
- گسترش
- استاندارد
- ساختار
- سیستم
- کار
- فنی
- La
- این
- توان
- با عنوان
- به
- رمز
- نشانه
- موضوع
- آموزش
- استفاده
- معمولا
- بود
- we
- به طور گسترده ای
- با
- یوان
- زفیرنت