این وبلاگ با همکاری Josh Reini، Shayak Sen و Anupam Datta از TruEra نوشته شده است.
Amazon SageMaker JumpStart انواع مدل های پایه از پیش آموزش دیده مانند Llama-2 و Mistal 7B را ارائه می دهد که می توانند به سرعت در یک نقطه پایانی مستقر شوند. این مدلهای پایه با وظایف مولد، از ساخت متن و خلاصه، پاسخ به سؤالات، تا تولید تصاویر و ویدیوها، به خوبی عمل میکنند. علیرغم قابلیت های تعمیم زیاد این مدل ها، اغلب موارد استفاده ای وجود دارد که این مدل ها باید با وظایف یا حوزه های جدید تطبیق داده شوند. یکی از راههای آشکارسازی این نیاز، ارزیابی مدل در برابر مجموعه دادههای حقیقت پایه است. پس از مشخص شدن نیاز به انطباق مدل پایه، می توانید از مجموعه ای از تکنیک ها برای انجام آن استفاده کنید. یک رویکرد رایج، تنظیم دقیق مدل با استفاده از مجموعه دادهای است که متناسب با مورد استفاده است. تنظیم دقیق می تواند مدل پایه را بهبود بخشد و کارایی آن را می توان دوباره در برابر مجموعه داده های حقیقت زمین اندازه گیری کرد. این دفتر یادداشت نحوه تنظیم دقیق مدل ها با SageMaker JumpStart را نشان می دهد.
یکی از چالشهای این رویکرد این است که ایجاد مجموعه دادههای حقیقت پایه گران قیمت است. در این پست، با تقویت این گردش کار با چارچوبی برای ارزیابیهای خودکار و قابل توسعه، به این چالش میپردازیم. ما با یک مدل پایه پایه از SageMaker JumpStart شروع می کنیم و آن را با آن ارزیابی می کنیم TruLens، یک کتابخانه منبع باز برای ارزیابی و ردیابی برنامه های مدل زبان بزرگ (LLM). پس از شناسایی نیاز به سازگاری، میتوانیم از تنظیم دقیق در SageMaker JumpStart استفاده کنیم و بهبود را با TruLens تأیید کنیم.

ارزیابی های TruLens از انتزاع استفاده می کنند توابع بازخورد. این توابع را میتوان به روشهای مختلفی پیادهسازی کرد، از جمله مدلهای به سبک BERT، LLMهای مناسب و غیره. ادغام TruLens با بستر آمازون به شما امکان می دهد ارزیابی ها را با استفاده از LLM های موجود از Amazon Bedrock انجام دهید. قابلیت اطمینان زیرساخت Amazon Bedrock به ویژه برای استفاده در انجام ارزیابیها در توسعه و تولید بسیار ارزشمند است.
این پست هم به عنوان مقدمه ای برای جایگاه TruEra در پشته برنامه مدرن LLM و هم یک راهنمای عملی برای استفاده است. آمازون SageMaker و TruEra برای استقرار، تنظیم دقیق و تکرار در برنامه های LLM. اینجا کامل است دفتر یادداشت با نمونه کد برای نشان دادن ارزیابی عملکرد با استفاده از TruLens
TruEra در پشته برنامه LLM
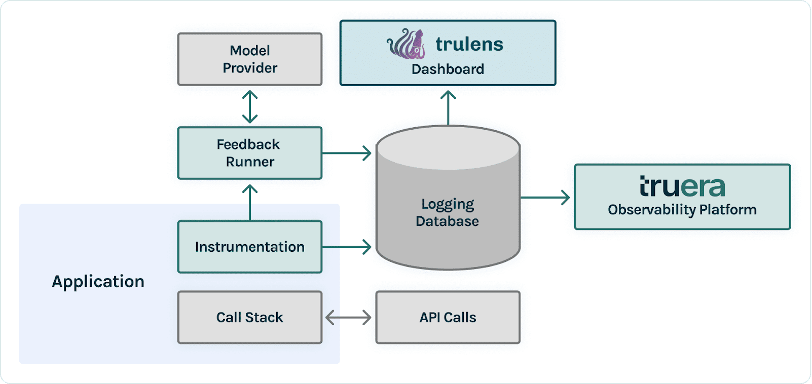
TruEra در لایه مشاهده پذیری برنامه های LLM زندگی می کند. اگرچه مؤلفههای جدید راه خود را در لایه محاسباتی (تنظیم دقیق، مهندسی سریع، APIهای مدل) و لایه ذخیرهسازی (پایگاههای اطلاعاتی برداری) راهاندازی کردهاند، نیاز به مشاهدهپذیری همچنان وجود دارد. این نیاز از توسعه تا تولید را در بر می گیرد و به قابلیت های به هم پیوسته ای برای آزمایش، اشکال زدایی و نظارت بر تولید نیاز دارد، همانطور که در شکل زیر نشان داده شده است.

در توسعه، شما می توانید استفاده کنید TruLens منبع باز برای ارزیابی سریع، اشکال زدایی و تکرار برنامه های LLM در محیط خود. مجموعه جامعی از معیارهای ارزیابی، شامل معیارهای مبتنی بر LLM و معیارهای سنتی موجود در TruLens، به شما این امکان را میدهد که برنامه خود را با معیارهای مورد نیاز برای انتقال برنامه به تولید اندازهگیری کنید.
در تولید، این گزارشها و معیارهای ارزیابی میتوانند در مقیاس با نظارت بر تولید TruEra پردازش شوند. با اتصال نظارت بر تولید با تست و اشکال زدایی، می توان افت عملکرد مانند توهم، ایمنی، امنیت و موارد دیگر را شناسایی و اصلاح کرد.
استقرار مدل های پایه در SageMaker
شما می توانید مدل های بنیادی مانند Llama-2 را در SageMaker تنها با دو خط کد پایتون مستقر کنید:
نقطه پایانی مدل را فراخوانی کنید
پس از استقرار، می توانید با ایجاد یک بارگذاری حاوی ورودی ها و پارامترهای مدل، نقطه پایانی مدل مستقر شده را فراخوانی کنید:
سپس می توانید به سادگی این بار را به روش پیش بینی نقطه پایانی منتقل کنید. توجه داشته باشید که هر بار که مدل را فراخوانی می کنید، باید این ویژگی را برای پذیرش قرارداد مجوز کاربر نهایی ارسال کنید:
ارزیابی عملکرد با TruLens
اکنون می توانید از TruLens برای تنظیم ارزیابی خود استفاده کنید. TruLens یک ابزار مشاهدهپذیری است که مجموعهای از عملکردهای بازخورد را برای ردیابی و ارزیابی برنامههای مبتنی بر LLM ارائه میدهد. عملکردهای بازخورد در اینجا برای تأیید عدم وجود توهم در برنامه ضروری است. این توابع بازخورد با استفاده از مدل های خارج از قفسه از ارائه دهندگانی مانند Amazon Bedrock پیاده سازی می شوند. مدلهای بستر آمازون در اینجا به دلیل کیفیت تأیید شده و قابلیت اطمینان آنها یک مزیت هستند. می توانید ارائه دهنده را با TruLens از طریق کد زیر تنظیم کنید:
در این مثال، ما از سه تابع بازخورد استفاده میکنیم: مرتبط بودن پاسخ، ارتباط متنی و زمینهسازی. این ارزیابیها به سرعت تبدیل به استانداردی برای تشخیص توهم در برنامههای کاربردی پاسخدهی به سؤالات فعال شدهاند و بهویژه برای برنامههای بدون نظارت، که اکثریت قریب به اتفاق برنامههای LLM امروزی را پوشش میدهند، مفید هستند.

بیایید هر یک از این عملکردهای بازخورد را مرور کنیم تا بفهمیم چگونه می توانند برای ما مفید باشند.
ارتباط با زمینه
متن ورودی مهمی برای کیفیت پاسخهای برنامه ما است، و اطمینان از اینکه زمینه ارائه شده به درخواست ورودی مرتبط است، میتواند به صورت برنامهنویسی مفید باشد. این بسیار مهم است زیرا این زمینه توسط LLM برای شکل دادن به یک پاسخ استفاده می شود، بنابراین هر گونه اطلاعات نامربوط در زمینه می تواند به یک توهم تبدیل شود. TruLens شما را قادر می سازد تا ارتباط متن را با استفاده از ساختار رکورد سریالی ارزیابی کنید:
از آنجایی که زمینه ارائه شده به LLM ها مهم ترین مرحله یک خط لوله بازیابی نسل افزوده (RAG) است، ارتباط زمینه برای درک کیفیت بازیابی ها حیاتی است. با کار کردن با مشتریان در بخشها، انواع مختلفی از حالتهای شکست را با استفاده از این ارزیابی مشاهده کردهایم، مانند زمینه ناقص، زمینه نامربوط خارجی، یا حتی فقدان زمینه کافی در دسترس. با شناسایی ماهیت این حالتهای خرابی، کاربران ما میتوانند نمایهسازی (مانند جاسازی مدل و قطعهسازی) و استراتژیهای بازیابی (مانند پنجرهسازی جملات و خودکارسازی) خود را برای کاهش این مشکلات تطبیق دهند.
زمینه سازی
پس از بازیابی متن، توسط یک LLM به یک پاسخ تبدیل می شود. LLM ها اغلب مستعد دور شدن از حقایق ارائه شده هستند، اغراق می کنند یا به یک پاسخ درست می رسند. برای تأیید مبنایی بودن برنامه، باید پاسخ را به عبارات جداگانه جدا کنید و به طور مستقل شواهدی را جستجو کنید که هر کدام را در زمینه بازیابی شده پشتیبانی می کند.
مسائل مربوط به زمینهسازی اغلب میتواند اثر پایین دستی مربوط به زمینه باشد. زمانی که LLM فاقد زمینه کافی برای شکل دادن به یک پاسخ مبتنی بر شواهد باشد، در تلاش برای ایجاد یک پاسخ قابل قبول، به احتمال زیاد دچار توهم می شود. حتی در مواردی که زمینه کامل و مرتبط ارائه شده است، LLM میتواند در مشکلاتی با پایه قرار گیرد. به ویژه، این امر در برنامههایی که LLM به سبک خاصی پاسخ میدهد یا برای تکمیل کاری که برای آن مناسب نیست استفاده میشود، دیده میشود. ارزیابیهای مبنایی به کاربران TruLens اجازه میدهد تا پاسخهای LLM را با ادعای ادعا تجزیه کنند تا بفهمند LLM اغلب توهمآور است. انجام این کار به ویژه برای روشن کردن راه رو به جلو در حذف توهم از طریق تغییرات سمت مدل (مانند درخواست، انتخاب مدل و پارامترهای مدل) مفید است.
مرتبط بودن را پاسخ دهید
در نهایت، پاسخ همچنان نیاز به پاسخ مفید به سوال اصلی دارد. شما می توانید این موضوع را با ارزیابی ارتباط پاسخ نهایی به ورودی کاربر تأیید کنید:
با رسیدن به ارزیابی های رضایت بخش برای این سه گانه، می توانید یک بیانیه ظریف در مورد صحت برنامه خود ارائه دهید. این برنامه بدون توهم تا حد پایه دانش خود تأیید شده است. به عبارت دیگر، اگر پایگاه داده برداری فقط حاوی اطلاعات دقیق باشد، پاسخهای ارائهشده توسط اپلیکیشن پاسخدهی به پرسشهای فعال در زمینه نیز دقیق هستند.
ارزیابی حقیقت پایه
علاوه بر این توابع بازخورد برای تشخیص توهم، ما یک مجموعه داده آزمایشی داریم، DataBricks-Dolly-15k، که ما را قادر می سازد شباهت حقیقت پایه را به عنوان معیار ارزیابی چهارم اضافه کنیم. کد زیر را ببینید:
اپلیکیشن را بسازید
بعد از اینکه ارزیاب های خود را تنظیم کردید، می توانید برنامه خود را بسازید. در این مثال، ما از یک برنامه QA با قابلیت متن استفاده می کنیم. در این برنامه، دستورالعمل و زمینه را به موتور تکمیل ارائه دهید:
پس از ایجاد برنامه و عملکردهای بازخورد، ایجاد یک برنامه پیچیده با TruLens ساده است. این برنامه پیچیده، که ما نام آن را base_recorder میگذاریم، هر بار که برنامه فراخوانی میشود، آن را ثبت و ارزیابی میکند:
نتایج با پایه Llama-2
پس از اجرای برنامه در هر رکورد در مجموعه داده آزمایشی، می توانید نتایج را در نوت بوک SageMaker خود با tru.get_leaderboard(). تصویر زیر نتایج ارزیابی را نشان می دهد. ارتباط پاسخ به طرز نگران کننده ای کم است، که نشان می دهد مدل در تلاش است تا دستورالعمل های ارائه شده را به طور مداوم دنبال کند.

Llama-2 را با استفاده از SageMaker Jumpstart تنظیم کنید
مراحل تنظیم دقیق مدل Llama-2 با استفاده از SageMaker Jumpstart نیز در این ارائه شده است دفتر یادداشت.
برای تنظیم دقیق، ابتدا باید مجموعه آموزشی را دانلود کرده و یک الگو برای دستورالعمل ها تنظیم کنید
سپس، هم مجموعه داده و هم دستورالعمل ها را در یک آپلود کنید سرویس ذخیره سازی ساده آمازون سطل (Amazon S3) برای آموزش:
برای تنظیم دقیق SageMaker، می توانید از SageMaker JumpStart Estimator استفاده کنید. ما در اینجا بیشتر از هایپرپارامترهای پیش فرض استفاده می کنیم، به جز اینکه تنظیم دستورالعمل را روی true تنظیم می کنیم:
پس از اینکه مدل را آموزش دادید، می توانید آن را مستقر کرده و برنامه خود را درست مانند قبل ایجاد کنید:
مدل دقیق تنظیم شده را ارزیابی کنید
می توانید دوباره مدل را در مجموعه آزمایشی خود اجرا کنید و نتایج را در مقایسه با پایه Llama-2 مشاهده کنید:

مدل جدید و دقیق Llama-2 به طور گسترده ای در ارتباط و زمینی بودن پاسخ، همراه با شباهت به مجموعه تست حقیقت زمینی، بهبود یافته است. این بهبود قابل توجه در کیفیت به قیمت افزایش جزئی تاخیر انجام می شود. این افزایش تاخیر نتیجه مستقیم تنظیم دقیق افزایش اندازه مدل است.
نه تنها میتوانید این نتایج را در نوت بوک مشاهده کنید، بلکه میتوانید نتایج را در TruLens UI با اجرای tru.run_dashboard(). انجام این کار میتواند نتایج جمعآوری شده یکسانی را در صفحه امتیازات ارائه دهد، اما همچنین به شما این امکان را میدهد که عمیقتر در سوابق مشکلدار غوطهور شوید و حالتهای خرابی برنامه را شناسایی کنید.

برای درک بهبود برنامه در سطح رکورد، می توانید به صفحه ارزیابی ها بروید و نمرات بازخورد را در سطحی دقیق تر بررسی کنید.
برای مثال، اگر از پایه LLM این سوال را بپرسید که "قوی ترین موتور فلت شش پورشه چیست"، مدل توهم زیر را دارد.

علاوه بر این، می توانید ارزیابی برنامه ای این رکورد را برای درک عملکرد برنامه در برابر هر یک از عملکردهای بازخوردی که تعریف کرده اید، بررسی کنید. با بررسی نتایج بازخورد پایه در TruLens، میتوانید تفکیک دقیق شواهد موجود برای حمایت از هر ادعایی که توسط LLM ارائه شده است را مشاهده کنید.

اگر همان رکورد را برای LLM تنظیمشده خود در TruLens صادر کنید، میتوانید ببینید که تنظیم دقیق با SageMaker JumpStart به طور چشمگیری میزان پاسخ را بهبود بخشیده است.

با استفاده از گردش کار ارزیابی خودکار با TruLens، می توانید برنامه خود را در مجموعه وسیع تری از معیارها اندازه گیری کنید تا عملکرد آن را بهتر درک کنید. مهمتر از همه، شما اکنون می توانید این عملکرد را به صورت پویا برای هر موردی درک کنید - حتی برای مواردی که حقیقت اصلی را جمع آوری نکرده اید.
TruLens چگونه کار می کند
پس از اینکه برنامه LLM خود را نمونه سازی کردید، می توانید TruLens (که قبلا نشان داده شد) را برای ابزاردهی پشته تماس آن ادغام کنید. پس از اینکه پشته تماس ابزارسازی شد، میتوان آن را در هر بار اجرا به یک پایگاه داده ورود به سیستم که در محیط شما زندگی میکند وارد کرد.
علاوه بر قابلیت های ابزار دقیق و گزارش، ارزیابی یک جزء اصلی ارزش برای کاربران TruLens است. این ارزیابیها در TruLens توسط توابع بازخورد پیادهسازی میشوند تا در بالای پشته تماس ابزاری شما اجرا شوند و به نوبه خود از ارائهدهندگان مدل خارجی برای تولید بازخورد استفاده میکنند.
پس از استنباط بازخورد، نتایج بازخورد در پایگاه داده ورود به سیستم نوشته می شود، که می توانید داشبورد TruLens را اجرا کنید. داشبورد TruLens که در محیط شما اجرا می شود، به شما امکان می دهد برنامه LLM خود را کاوش، تکرار و اشکال زدایی کنید.
در مقیاس، این گزارشها و ارزیابیها میتوانند به TruEra منتقل شوند قابلیت مشاهده تولید که می تواند میلیون ها مشاهده را در دقیقه پردازش کند. با استفاده از پلتفرم مشاهدهپذیری TruEra، میتوانید به سرعت توهم و سایر مشکلات عملکرد را تشخیص دهید و با تشخیص یکپارچه در عرض چند ثانیه روی یک رکورد بزرگنمایی کنید. حرکت به دیدگاه تشخیصی به شما این امکان را می دهد که به راحتی حالت های خرابی برنامه LLM خود را مانند توهم، کیفیت پایین بازیابی، مسائل ایمنی و موارد دیگر را شناسایی و کاهش دهید.
برای پاسخ های صادقانه، بی ضرر و مفید ارزیابی کنید
با رسیدن به ارزیابی های رضایت بخش برای این سه گانه، می توانید به درجه بالاتری از اطمینان در صحت پاسخ هایی که ارائه می دهد، برسید. فراتر از حقیقت، TruLens پشتیبانی گسترده ای از ارزیابی های مورد نیاز برای درک عملکرد LLM شما در محور "صادقانه، بی ضرر و مفید" دارد. کاربران ما از توانایی شناسایی نه تنها توهم همانطور که قبلاً صحبت کردیم، بلکه همچنین مسائل مربوط به ایمنی، امنیت، تطابق زبان، انسجام و موارد دیگر را بسیار سود بردهاند. همه اینها مشکلات درهم و برهم و واقعی هستند که توسعه دهندگان برنامه LLM با آن مواجه هستند و می توان آنها را با TruLens خارج از جعبه شناسایی کرد.

نتیجه
این پست در مورد چگونگی تسریع تولید برنامه های کاربردی هوش مصنوعی و استفاده از مدل های پایه در سازمان خود بحث می کند. با SageMaker JumpStart، Amazon Bedrock و TruEra، می توانید مدل های پایه را برای برنامه LLM خود استقرار، تنظیم دقیق و تکرار کنید. این رو چک کن پیوند برای کسب اطلاعات بیشتر در مورد TruEra و امتحان کنید دفتر یادداشت خودتان.
درباره نویسندگان
 جاش رینی یکی از مشارکتکنندگان اصلی TruLens منبع باز و موسس دانشمند دادههای روابط توسعهدهنده در TruEra است، جایی که او مسئول ابتکارات آموزشی و پرورش جامعهای پر رونق از متخصصان کیفیت هوش مصنوعی است.
جاش رینی یکی از مشارکتکنندگان اصلی TruLens منبع باز و موسس دانشمند دادههای روابط توسعهدهنده در TruEra است، جایی که او مسئول ابتکارات آموزشی و پرورش جامعهای پر رونق از متخصصان کیفیت هوش مصنوعی است.
 شایاک سن مدیر ارشد فناوری و یکی از بنیانگذاران TruEra است. Shayak بر روی ساختن سیستمها و تحقیقات پیشرو برای توضیح بیشتر، سازگاری با حریم خصوصی و منصفانهتر کردن سیستمهای یادگیری ماشین متمرکز است.
شایاک سن مدیر ارشد فناوری و یکی از بنیانگذاران TruEra است. Shayak بر روی ساختن سیستمها و تحقیقات پیشرو برای توضیح بیشتر، سازگاری با حریم خصوصی و منصفانهتر کردن سیستمهای یادگیری ماشین متمرکز است.
 آنوپام داتا یکی از بنیانگذاران، رئیس و دانشمند ارشد TruEra است. قبل از TruEra، او 15 سال را در دانشکده دانشگاه کارنگی ملون (2007-22) گذراند، که اخیراً به عنوان پروفسور رسمی مهندسی برق و کامپیوتر و علوم کامپیوتر بود.
آنوپام داتا یکی از بنیانگذاران، رئیس و دانشمند ارشد TruEra است. قبل از TruEra، او 15 سال را در دانشکده دانشگاه کارنگی ملون (2007-22) گذراند، که اخیراً به عنوان پروفسور رسمی مهندسی برق و کامپیوتر و علوم کامپیوتر بود.
 ویوک گانگاسانی یک معمار راهحلهای راهاندازی AI/ML برای استارتآپهای هوش مصنوعی مولد در AWS است. او به استارتآپهای نوظهور GenAI کمک میکند تا با استفاده از خدمات AWS و محاسبات تسریع، راهحلهای نوآورانه بسازند. در حال حاضر، او بر توسعه استراتژیهایی برای تنظیم دقیق و بهینهسازی عملکرد استنتاج مدلهای زبان بزرگ متمرکز است. ویوک در اوقات فراغت خود از پیاده روی، تماشای فیلم و امتحان غذاهای مختلف لذت می برد.
ویوک گانگاسانی یک معمار راهحلهای راهاندازی AI/ML برای استارتآپهای هوش مصنوعی مولد در AWS است. او به استارتآپهای نوظهور GenAI کمک میکند تا با استفاده از خدمات AWS و محاسبات تسریع، راهحلهای نوآورانه بسازند. در حال حاضر، او بر توسعه استراتژیهایی برای تنظیم دقیق و بهینهسازی عملکرد استنتاج مدلهای زبان بزرگ متمرکز است. ویوک در اوقات فراغت خود از پیاده روی، تماشای فیلم و امتحان غذاهای مختلف لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/deploy-foundation-models-with-amazon-sagemaker-iterate-and-monitor-with-truera/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 10
- 100
- 11
- 12
- 120
- 125
- 14
- سال 15
- ٪۱۰۰
- 16
- 179
- 72
- 8
- 9
- a
- توانایی
- قادر
- درباره ما
- انتزاع - مفهوم - برداشت
- شتاب دادن
- تسریع شد
- پذیرفتن
- دقیق
- در میان
- وفق دادن
- انطباق
- سازگار
- اضافه کردن
- اضافه
- نشانی
- مزیت - فایده - سود - منفعت
- پس از
- از نو
- در برابر
- توافق
- AI
- AI / ML
- معرفی
- اجازه دادن
- اجازه می دهد تا
- در امتداد
- همچنین
- هر چند
- آمازون
- آمازون SageMaker
- آمازون خدمات وب
- an
- و
- پاسخ
- پاسخ
- هر
- رابط های برنامه کاربردی
- نرم افزار
- کاربرد
- برنامه های کاربردی
- روش
- به درستی
- برنامه های
- هستند
- AS
- پرسیدن
- At
- کوشش
- افزوده شده
- خودکار
- در دسترس
- AWS
- محور
- پایه
- خط مقدم
- BE
- زیرا
- شدن
- قبل از
- بودن
- باور
- در زیر
- سود
- بهتر
- میان
- خارج از
- بلاگ
- هر دو
- جعبه
- شکستن
- تفکیک
- پهن
- ساختن
- بنا
- اما
- by
- صدا
- نام
- CAN
- قابلیت های
- کارنگی ملون
- دانشگاه کارنگی ملون
- حمل
- مورد
- موارد
- دسته بندی
- به چالش
- تبادل
- وارسی
- رئیس
- انتخاب
- ادعا
- کلاس
- واضح
- بنیانگذاران
- رمز
- مجموعه
- ستون ها
- می آید
- انجمن
- مقایسه
- کامل
- تکمیل شده
- اتمام
- موافق
- جزء
- اجزاء
- جامع
- محاسبه
- کامپیوتر
- مهندسی رایانه
- علم کامپیوتر
- اعتماد به نفس
- تکرار
- اتصال
- دارای اهمیت
- همواره
- شامل
- زمینه
- شرکت کننده
- تبدیل
- هسته
- مشارکت کننده اصلی
- اصلاح شده
- میتوانست
- پوشش
- ایجاد
- ایجاد شده
- ایجاد
- ضوابط
- بحرانی
- CTO
- سرپرستی
- در حال حاضر
- مشتریان
- داشبورد
- داده ها
- دانشمند داده
- پایگاه داده
- پایگاه های داده
- مجموعه داده ها
- عمیق تر
- به طور پیش فرض
- مشخص
- درجه
- گسترش
- مستقر
- گسترش
- توصیف
- با وجود
- دقیق
- تشخیص
- کشف
- توسعه دهنده
- توسعه دهندگان
- در حال توسعه
- پروژه
- امکانات عیب شناسی
- DID
- مختلف
- مستقیم
- بحث کردیم
- شیرجه رفتن
- عمل
- حوزه
- پایین
- دانلود
- به طور چشمگیری
- بطور پویا
- هر
- پیش از آن
- به آسانی
- آموزش
- اثر
- اثر
- از بین بردن
- تعبیه کردن
- سنگ سنباده
- را قادر می سازد
- پایان
- نقطه پایانی
- موتور
- مهندسی
- اطمینان حاصل شود
- محیط
- به خصوص
- ضروری است
- اتر (ETH)
- ارزیابی
- ارزیابی
- ارزیابی
- ارزیابی
- حتی
- مدرک
- معاینه کردن
- در حال بررسی
- مثال
- جز
- گسترش
- گران
- اکتشاف
- صادرات
- خارجی
- استخراج
- چهره
- حقایق
- شکست
- منصفانه
- سقوط
- غلط
- باز خورد
- شکل
- پرونده
- نهایی
- پیدا کردن
- پایان
- نام خانوادگی
- صاف
- متمرکز شده است
- به دنبال
- پیروی
- برای
- فرم
- تشکیل
- به جلو
- پایه
- تاسیس
- چهارم
- چارچوب
- رایگان
- از جانب
- تابع
- توابع
- بیشتر
- تولید می کنند
- نسل
- مولد
- هوش مصنوعی مولد
- می دهد
- Go
- بزرگ
- زمین
- راهنمایی
- دست
- آیا
- he
- مفید
- کمک می کند
- اینجا کلیک نمایید
- بالاتر
- پیاده روی
- خود را
- صادق
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- i
- شناسایی
- شناسایی
- شناسایی
- if
- درخشان
- تصاویر
- اجرا
- واردات
- مهمتر
- بهبود
- بهبود یافته
- بهبود
- in
- در دیگر
- از جمله
- افزایش
- افزایش
- به طور مستقل
- نشان دادن
- اطلاعات
- شالوده
- ابتکارات
- ابتکاری
- ورودی
- ورودی
- دستورالعمل
- سند
- ادغام
- یکپارچه
- ادغام
- به هم پیوسته
- به
- معرفی
- مسائل
- IT
- ITS
- خود
- JPG
- json
- تنها
- کلید
- دانش
- عدم
- زبان
- بزرگ
- تاخیر
- لایه
- برجسته
- یادگیری
- سطح
- کتابخانه
- مجوز
- زندگی
- احتمالا
- محدود
- لاین
- خطوط
- فهرست
- زندگی
- زندگی
- محلی
- ورود به سیستم
- سیستم وارد
- ورود به سیستم
- کم
- دستگاه
- فراگیری ماشین
- ساخته
- اکثریت
- ساخت
- انبوه
- مسابقه
- معنی
- اندازه
- اندازه گیری
- ملون
- روش
- متری
- متریک
- میلیون ها نفر
- دقیقه
- کاهش
- ML
- مدل
- مدل
- مدرن
- حالت های
- مانیتور
- نظارت بر
- بیش
- اکثر
- اغلب
- حرکت
- فیلم ها
- متحرک
- باید
- نام
- طبیعت
- نیاز
- ضروری
- نیازهای
- جدید
- بعد
- توجه داشته باشید
- دفتر یادداشت
- اکنون
- پرورش دادن
- هدف
- مشاهدات
- of
- خاموش
- ارائه
- غالبا
- on
- ONE
- فقط
- باز کن
- منبع باز
- بهینه سازی
- or
- کدام سازمان ها
- اصلی
- دیگر
- ما
- خارج
- تولید
- با ما
- زوج
- پارامترهای
- ویژه
- ویژه
- عبور
- انجام دادن
- کارایی
- انجام
- خط لوله
- محل
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- محتمل
- بازی
- فقیر
- محبوب
- پورشه
- پست
- قوی
- پیش بینی
- رئيس جمهور
- خلوت
- مشکلات
- روند
- پردازش
- تولید کردن
- تولید
- تولید
- معلم
- برنامه ریزی شده
- ارائه
- ارائه
- ارائه دهنده
- ارائه دهندگان
- فراهم می کند
- تحت فشار قرار دادند
- پــایتــون
- پرسش و پاسخ
- کیفیت
- سوال
- سوالات
- به سرعت
- تصادفی
- سریعا
- رسیدن به
- رسیدن به
- دنیای واقعی
- تازه
- رکورد
- ضبط
- سوابق
- روابط
- ربط
- مربوط
- قابلیت اطمینان
- بقایای
- جایگزین کردن
- درخواست
- ضروری
- نیاز
- تحقیق
- پاسخ
- پاسخ
- مسئوليت
- نتیجه
- نتایج
- برگشت
- دویدن
- در حال اجرا
- ایمنی
- حکیم ساز
- همان
- مقیاس
- علم
- دانشمند
- نمرات
- جستجو
- ثانیه
- بخش ها
- تیم امنیت لاتاری
- دیدن
- مشاهده گردید
- را انتخاب کنید
- جمله
- جداگانه
- خدمت
- خدمات
- تنظیم
- برپایی
- چند
- باید
- نشان
- نشان داده شده
- نشان می دهد
- ساده
- به سادگی
- تنها
- شش
- اندازه
- So
- مزایا
- منبع
- دهانه ها
- ویژه
- صرف
- انشعاب
- پشته
- استاندارد
- شروع
- شروع
- نوپا
- بیانیه
- اظهارات
- گام
- هنوز
- ذخیره سازی
- ساده
- استراتژی ها
- ولگرد
- ساختار
- تلاش
- سبک
- چنین
- کافی
- دنباله
- پشتیبانی
- پشتیبانی از
- سطح
- سیستم های
- طراحی شده
- کار
- وظایف
- تکنیک
- قالب
- آزمون
- تست
- متن
- که
- La
- شان
- سپس
- آنجا.
- اینها
- آنها
- این
- کسانی که
- سه
- پر رونق
- از طریق
- بدین ترتیب
- زمان
- به
- امروز
- ابزار
- بالا
- مسیر
- پیگردی
- سنتی
- قطار
- آموزش دیده
- آموزش
- فوق العاده
- TRU
- درست
- حقیقت
- امتحان
- تلاش
- دور زدن
- دو
- ui
- فهمیدن
- درک
- دانشگاه
- بر
- us
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- کاربران
- با استفاده از
- ارزشمند
- ارزش
- تنوع
- وسیع
- تایید
- بررسی
- تایید
- از طريق
- فیلم های
- چشم انداز
- W
- تماشای
- مسیر..
- راه
- we
- وب
- خدمات وب
- خوب
- چه زمانی
- که
- گسترده تر
- اراده
- با
- در داخل
- کلمات
- مشغول به کار
- گردش کار
- کارگر
- پیچیده
- نوشتن
- کتبی
- سال
- شما
- شما
- خودت
- زفیرنت
- زوم