تصویر فریموفیلم ها on Freepik
این دورانی است که پیشرفت هوش مصنوعی هر روز در حال رخ دادن است. ما چند سال پیش هوش مصنوعی زیادی نداشتیم که به صورت عمومی تولید شده باشد، اما اکنون این فناوری برای همه قابل دسترسی است. برای بسیاری از سازندگان یا شرکتهایی که میخواهند به طور قابل توجهی از این فناوری برای توسعه چیزی پیچیده استفاده کنند، عالی است، که ممکن است زمان زیادی طول بکشد.
یکی از باورنکردنیترین پیشرفتهایی که نحوه کار ما را تغییر میدهد، انتشار آن است مدل GPT-3.5 توسط OpenAI. مدل GPT-3.5 چیست؟ اگر بگذارم مدل برای خودشان صحبت کنند. در این صورت، پاسخ این استیک مدل هوش مصنوعی بسیار پیشرفته در زمینه پردازش زبان طبیعی، با پیشرفت های گسترده در تولید متن دقیق و مرتبط با زمینهتی "
OpenAI یک API برای مدل GPT-3.5 ارائه میکند که میتوانیم از آن برای توسعه یک برنامه ساده، مانند خلاصهکننده متن استفاده کنیم. برای انجام این کار، میتوانیم از Python برای ادغام API مدل در برنامه مورد نظر خود به طور یکپارچه استفاده کنیم. فرآیند به چه صورت است؟ بیایید وارد آن شویم.
قبل از دنبال کردن این آموزش، چند پیش نیاز وجود دارد، از جمله:
- دانش پایتون، از جمله دانش استفاده از کتابخانه های خارجی و IDE
- درک API ها و مدیریت نقطه پایانی با پایتون
– دسترسی به API های OpenAI
برای دسترسی به OpenAI APIها، باید در آن ثبت نام کنیم پلتفرم توسعه دهنده OpenAI و از مشاهده کلیدهای API در نمایه خود دیدن کنید. در وب، روی دکمه «ایجاد کلید مخفی جدید» کلیک کنید تا دسترسی API به دست آورید (تصویر زیر را ببینید). به یاد داشته باشید که کلیدها را ذخیره کنید، زیرا پس از آن کلیدها به آنها نشان داده نمی شود.

تصویر توسط نویسنده
با همه آماده سازی ها، بیایید سعی کنیم اساس مدل API های OpenAI را درک کنیم.
La مدل خانواده GPT-3.5 برای بسیاری از وظایف زبانی مشخص شد و هر مدل در خانواده در برخی از وظایف برتری دارد. برای این مثال آموزشی، ما از gpt-3.5-turbo همانطور که در زمان نگارش این مقاله به دلیل قابلیت و مقرون به صرفه بودن، مدل فعلی توصیه شده بود.
ما اغلب از text-davinci-003 در آموزش OpenAI، اما ما از مدل فعلی برای این آموزش استفاده خواهیم کرد. ما بر آن تکیه می کنیم تکمیل چت نقطه پایان به جای Completion زیرا مدل پیشنهادی فعلی یک مدل چت است. حتی اگر نام یک مدل چت باشد، برای هر کار زبانی کار می کند.
بیایید سعی کنیم بفهمیم که API چگونه کار می کند. ابتدا باید بسته های OpenAI فعلی را نصب کنیم.
pip install openai
پس از اتمام نصب بسته، سعی می کنیم با اتصال از طریق نقطه پایانی ChatCompletion از API استفاده کنیم. با این حال، قبل از ادامه باید محیط را تنظیم کنیم.
در IDE مورد علاقه خود (برای من، VS Code است)، دو فایل به نام ایجاد کنید .env و summarizer_app.py، مشابه تصویر زیر.
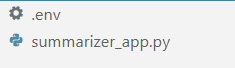
تصویر توسط نویسنده
La summarizer_app.py جایی است که ما برنامه خلاصه ساز ساده خود را می سازیم، و .env فایل جایی است که ما کلید API خود را ذخیره می کنیم. به دلایل امنیتی، همیشه توصیه میشود که کلید API خود را در فایل دیگری جدا کنیم، نه اینکه آنها را در فایل پایتون کدگذاری کنیم.
در .env فایل سینتکس زیر را قرار داده و فایل را ذخیره کنید. your_api_key_here را با کلید API واقعی خود جایگزین کنید. کلید API را به یک شی رشته تغییر ندهید. اجازه دهید آنها را همانطور که هست.
OPENAI_API_KEY=your_api_key_here
برای درک بهتر GPT-3.5 API؛ ما از کد زیر برای تولید کلمه summarizer استفاده می کنیم.
openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages=[ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ],
)
کد بالا نحوه تعامل ما با مدل OpenAI APIs GPT-3.5 است. با استفاده از ChatCompletion API یک مکالمه ایجاد می کنیم و پس از عبور از اعلان نتیجه مورد نظر را دریافت می کنیم.
بیایید هر بخش را تجزیه کنیم تا آنها را بهتر درک کنیم. در خط اول از openai.ChatCompletion.create کدی برای ایجاد پاسخ از اعلانی که به API ارسال می کنیم.
در خط بعدی، ما فراپارامترهای خود را داریم که از آنها برای بهبود وظایف متنی خود استفاده می کنیم. در اینجا خلاصه ای از هر تابع هایپرپارامتر آمده است:
model: خانواده مدلی که می خواهیم استفاده کنیم. در این آموزش از مدل پیشنهادی فعلی استفاده می کنیم (gpt-3.5-turbo).max_tokens: حد بالای کلمات تولید شده توسط مدل. این کمک می کند تا طول متن تولید شده را محدود کنید.temperature: تصادفی بودن خروجی مدل با دمای بالاتر به معنای نتیجه متنوع تر و خلاقانه تر است. محدوده مقادیر بین 0 تا بی نهایت است، اگرچه مقادیر بیش از 2 رایج نیستند.top_p: نمونه برداری Top P یا top-k یا نمونه برداری هسته پارامتری برای کنترل مخزن نمونه برداری از توزیع خروجی است. به عنوان مثال، مقدار 0.1 به این معنی است که مدل تنها خروجی را از 10 درصد بالای توزیع نمونه برداری می کند. محدوده مقدار بین 0 و 1 بود. مقادیر بالاتر به معنای نتیجه متنوع تر است.frequency_penalty: جریمه علامت تکرار از خروجی. محدوده مقدار بین 2- تا 2 است، که در آن مقادیر مثبت مدل را از تکرار توکن سرکوب می کند در حالی که مقادیر منفی مدل را تشویق می کند تا از کلمات تکراری بیشتری استفاده کند. 0 یعنی بدون پنالتیmessages: پارامتری که در آن اعلان متن خود را ارسال می کنیم تا با مدل پردازش شود. ما فهرستی از فرهنگ لغتها را ارسال میکنیم که در آن کلید شیء نقش است (اعم از «سیستم»، «کاربر» یا «دستیار») که به مدل کمک میکند تا زمینه و ساختار را درک کند، در حالی که مقادیر، زمینه هستند.- نقش «سیستم» دستورالعملهای مجموعهای برای رفتار «دستیار» مدل است.
- نقش "کاربر" نشان دهنده درخواست شخصی است که با مدل در تعامل است،
- نقش "دستیار" پاسخ به درخواست "کاربر" است
با توضیح پارامتر بالا، می بینیم که messages پارامتر بالا دارای دو شی فرهنگ لغت است. اولین فرهنگ لغت این است که چگونه مدل را به عنوان خلاصه کننده متن تنظیم می کنیم. مورد دوم جایی است که ما متن خود را ارسال می کنیم و خروجی خلاصه سازی را می گیریم.
در فرهنگ لغت دوم نیز متغیر را مشاهده خواهید کرد person_type و prompt. person_type متغیری است که برای کنترل سبک خلاصه شده استفاده کردم که در آموزش نشان خواهم داد. در حالی که prompt جایی است که ما متن خود را ارسال می کنیم تا خلاصه شود.
در ادامه آموزش، کد زیر را در قسمت قرار دهید summarizer_app.py فایل و ما سعی خواهیم کرد نحوه عملکرد تابع زیر را بررسی کنیم.
import openai
import os
from dotenv import load_dotenv load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY") def generate_summarizer( max_tokens, temperature, top_p, frequency_penalty, prompt, person_type,
): res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages= [ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ], ) return res["choices"][0]["message"]["content"]
کد بالا جایی است که ما یک تابع پایتون ایجاد می کنیم که پارامترهای مختلفی را که قبلاً در مورد آنها صحبت کردیم را می پذیرد و خروجی خلاصه متن را برمی گرداند.
تابع بالا را با پارامتر خود امتحان کنید و خروجی را ببینید. سپس آموزش را ادامه می دهیم تا با بسته streamlit یک اپلیکیشن ساده بسازیم.
Streamlit یک بسته منبع باز پایتون است که برای ایجاد یادگیری ماشین و برنامه های وب علم داده طراحی شده است. استفاده از آن آسان و شهودی است، بنابراین برای بسیاری از مبتدیان توصیه می شود.
بیایید قبل از ادامه آموزش، بسته streamlit را نصب کنیم.
pip install streamlit
پس از اتمام نصب، کد زیر را در آن قرار دهید summarizer_app.py.
import streamlit as st #Set the application title
st.title("GPT-3.5 Text Summarizer") #Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200) #Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3) #Slider to control the model hyperparameter
with col1: token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0) temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01) top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01) f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01) #Selection box to select the summarization style
with col2: option = st.selectbox( "How do you like to be explained?", ( "Second-Grader", "Professional Data Scientist", "Housewives", "Retired", "University Student", ), ) #Showing the current parameter used for the model with col3: with st.expander("Current Parameter"): st.write("Current Token :", token) st.write("Current Temperature :", temp) st.write("Current Nucleus Sampling :", top_p) st.write("Current Frequency Penalty :", f_pen) #Creating button for execute the text summarization
if st.button("Summarize"): st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
سعی کنید کد زیر را در خط فرمان خود برای راه اندازی برنامه اجرا کنید.
streamlit run summarizer_app.py
اگر همه چیز به خوبی کار کند، برنامه زیر را در مرورگر پیش فرض خود خواهید دید.
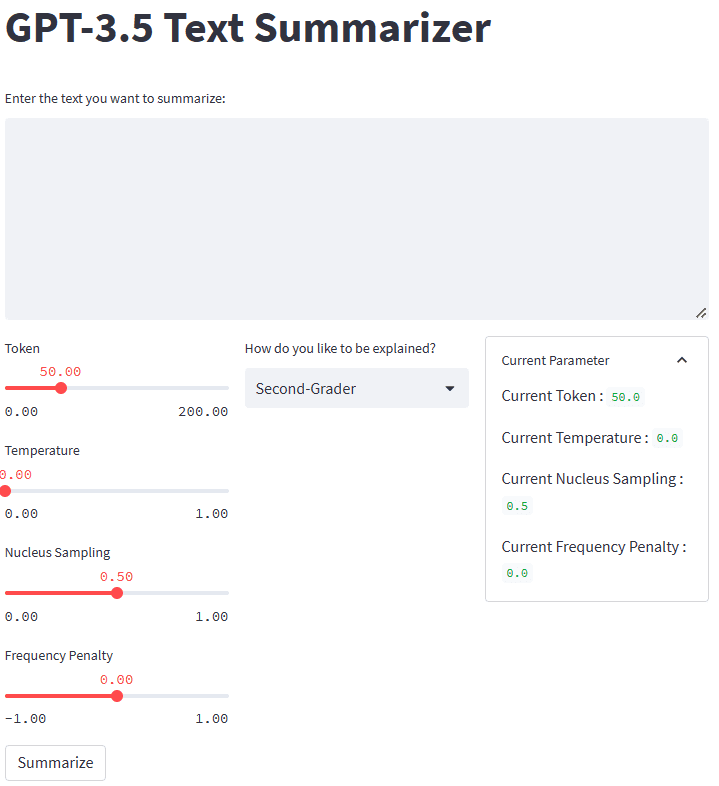
تصویر توسط نویسنده
بنابراین، در کد بالا چه اتفاقی افتاده است؟ اجازه دهید به طور خلاصه هر تابعی را که استفاده کردیم توضیح دهم:
.st.title: متن عنوان برنامه وب را ارائه دهید..st.write: آرگومان را در برنامه می نویسد. این می تواند هر چیزی باشد به جز یک متن رشته ای..st.text_area: ناحیه ای را برای ورودی متن ارائه دهید که می تواند در متغیر ذخیره شود و برای دستور خلاصه کننده متن ما استفاده شود.st.columns: ظروف را برای ارائه تعامل کنار هم قرار دهید..st.slider: یک ویجت لغزنده با مقادیر تنظیم شده ارائه کنید که کاربر بتواند با آن تعامل داشته باشد. مقدار روی متغیری که به عنوان پارامتر مدل استفاده می شود ذخیره می شود..st.selectbox: ویجت انتخابی را برای کاربران فراهم کنید تا سبک خلاصه سازی مورد نظر خود را انتخاب کنند. در مثال بالا، ما از پنج سبک مختلف استفاده می کنیم..st.expander: محفظه ای را فراهم کنید که کاربران بتوانند چندین شی را بسط دهند و نگه دارند..st.button: دکمه ای را ارائه کنید که وقتی کاربر آن را فشار می دهد عملکرد مورد نظر را اجرا می کند.
از آنجایی که streamlit به طور خودکار UI را با پیروی از کد داده شده از بالا به پایین طراحی می کند، می توانیم بیشتر روی تعامل تمرکز کنیم.
با وجود همه قطعات، بیایید برنامه خلاصه سازی خود را با یک مثال متنی امتحان کنیم. برای مثال ما، من از آن استفاده می کنم صفحه نظریه نسبیت ویکی پدیا متنی که باید خلاصه شود با یک پارامتر پیش فرض و سبک کلاس دوم، نتیجه زیر را به دست می آوریم.
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
ممکن است نتیجه ای متفاوت از آنچه در بالا بدست آورید. بیایید سبک Housewives را امتحان کنیم و پارامتر را کمی تغییر دهیم (Token 100، دما 0.5، Nucleus Sampling 0.5، Frequency Penalty 0.3).
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
همانطور که می بینیم، برای همان متنی که ارائه می دهیم، تفاوت در سبک وجود دارد. با یک فرمان و پارامتر تغییر، برنامه ما می تواند کاربردی تر باشد.
نمای کلی برنامه خلاصهنویس متن ما را میتوانید در تصویر زیر مشاهده کنید.
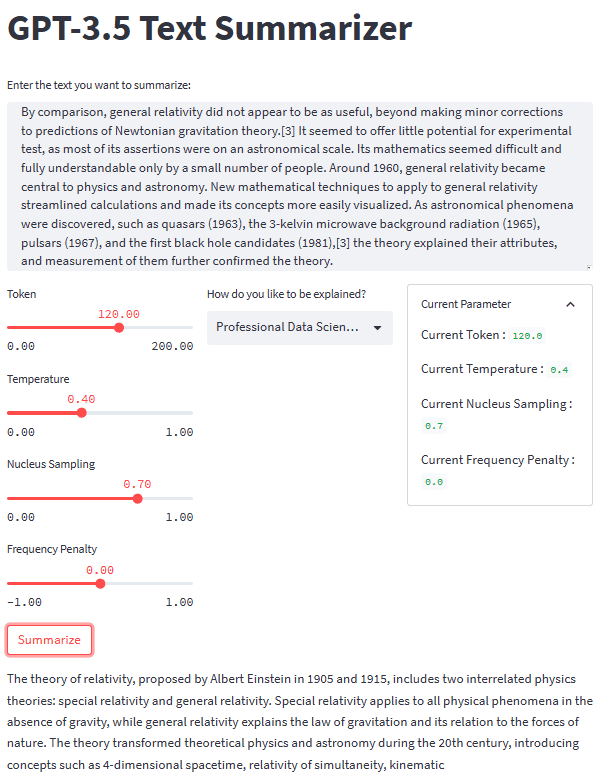
تصویر توسط نویسنده
این آموزش ایجاد توسعه برنامه خلاصه کننده متن با GPT-3.5 است. می توانید برنامه را حتی بیشتر بهینه کنید و برنامه را مستقر کنید.
هوش مصنوعی مولد در حال افزایش است و ما باید با ایجاد یک اپلیکیشن فوق العاده از این فرصت استفاده کنیم. در این آموزش، نحوه عملکرد API های OpenAI GPT-3.5 و نحوه استفاده از آنها برای ایجاد یک برنامه خلاصه کننده متن با کمک Python و بسته streamlit را خواهیم آموخت.
کورنلیوس یودا ویجایا دستیار مدیر علوم داده و نویسنده داده است. در حالی که به طور تمام وقت در آلیانز اندونزی کار می کند، دوست دارد نکات Python و Data را از طریق رسانه های اجتماعی و رسانه های نوشتاری به اشتراک بگذارد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html?utm_source=rss&utm_medium=rss&utm_campaign=text-summarization-development-a-python-tutorial-with-gpt-3-5
- :است
- ][پ
- $UP
- 1
- 100
- 28
- 7
- a
- درباره ما
- بالاتر
- پذیرفتن
- دسترسی
- در دسترس
- دقیق
- به دست آوردن
- پیشرفته
- مزیت - فایده - سود - منفعت
- پس از
- AI
- معرفی
- آلیانز
- هر چند
- همیشه
- و
- دیگر
- پاسخ
- API
- دسترسی به API
- رابط های برنامه کاربردی
- نرم افزار
- کاربرد
- برنامه توسعه
- برنامه های
- هستند
- محدوده
- استدلال
- مقاله
- AS
- دستیار
- ستاره شناسی
- At
- بطور خودکار
- اساسی
- BE
- زیرا
- قبل از
- مبتدی ها
- در زیر
- بهتر
- میان
- بیت
- سیاه پوست
- سیاه چاله ها
- پایین
- جعبه
- شکستن
- دستیابی به موفقیت
- پیشرفت ها
- بطور خلاصه
- مرورگر
- ساختن
- دکمه
- by
- نام
- CAN
- مورد
- قرن
- تغییر دادن
- انتخاب
- کلیک
- رمز
- ستون ها
- آینده
- مشترک
- شرکت
- اتمام
- پیچیده
- مفاهیم
- اتصال
- ظرف
- ظروف
- محتوا
- زمینه
- ادامه دادن
- کنترل
- گفتگو
- میتوانست
- ایجاد
- ایجاد
- خالق
- سازندگان
- جاری
- روزانه
- داده ها
- علم اطلاعات
- دانشمند داده
- به طور پیش فرض
- گسترش
- طرح
- طراحی
- توسعه
- توسعه دهنده
- پروژه
- تفاوت
- مختلف
- كشف كردن
- بحث کردیم
- توزیع
- مختلف
- آیا
- پایین
- هر
- هر دو
- تشویق
- نقطه پایانی
- وارد
- محیط
- عصر
- اتر (ETH)
- حتی
- هر کس
- همه چیز
- مثال
- عالی
- اجرا کردن
- گسترش
- توضیح دهید
- توضیح داده شده
- توضیح می دهد
- خارجی
- خانواده
- خارق العاده
- محبوب
- کمی از
- رشته
- پرونده
- فایل ها
- نام خانوادگی
- تمرکز
- پیروی
- برای
- نیروهای
- فرکانس
- از جانب
- تابع
- تابعی
- بیشتر
- سوالات عمومی
- تولید می کنند
- تولید
- مولد
- دریافت کنید
- داده
- گرانشی
- امواج گرانشی
- جاذبه زمین
- دستورالعمل ها
- اداره
- اتفاق افتاده است
- آیا
- داشتن
- کمک
- کمک کرد
- مفید
- کمک می کند
- اینجا کلیک نمایید
- بالاتر
- خیلی
- نگه داشتن
- سوراخ
- چگونه
- چگونه
- همکاری با ما
- اما
- HTTPS
- i
- ایده ها
- تصویر
- واردات
- مهم
- بهبود
- ارتقاء
- in
- شامل
- از جمله
- باور نکردنی
- فرد
- اندونزی
- ابدیت
- وارد کردن
- ورودی
- نصب
- نصب کردن
- در عوض
- ادغام
- تعامل
- تعامل
- اثر متقابل
- معرفی
- حسی
- IT
- ITS
- JPG
- kdnuggets
- کلید
- کلید
- دانش
- زبان
- قانون
- یاد گرفتن
- یادگیری
- طول
- کتابخانه ها
- پسندیدن
- محدود
- لاین
- لینک
- فهرست
- طولانی
- مدت زمان طولانی
- نگاه کنيد
- شبیه
- دستگاه
- فراگیری ماشین
- مدیر
- بسیاری
- به معنی
- رسانه ها
- پیام
- قدرت
- مدل
- بیش
- اکثر
- حرکت
- چندگانه
- نام
- طبیعی
- زبان طبیعی
- پردازش زبان طبیعی
- طبیعت
- نیاز
- منفی
- جدید
- بعد
- هدف
- اشیاء
- گرفتن
- of
- on
- ONE
- منبع باز
- OpenAI
- فرصت
- گزینه
- OS
- دیگر
- تولید
- به طور کلی
- بسته
- بسته
- پارامتر
- پارامترهای
- بخش
- عبور
- شخص
- فیزیکی
- فیزیک
- قطعات
- محل
- سیارات
- افلاطون
- هوش داده افلاطون
- PlatoData
- استخر
- مثبت
- پیش بینی
- پیش نیازها
- قبلا
- روند
- در حال پردازش
- حرفه ای
- مشخصات
- پیشنهاد شده
- ارائه
- فراهم می کند
- عمومی
- قرار دادن
- پــایتــون
- تصادفی بودن
- محدوده
- نسبتا
- اماده
- دلایل
- توصیه می شود
- ثبت نام
- ارتباط
- آزاد
- مربوط
- به یاد داشته باشید
- تکراری
- جایگزین کردن
- نشان دهنده
- پاسخ
- نتیجه
- برگشت
- طلوع
- نقش
- دویدن
- همان
- ذخیره
- علم
- دانشمند
- یکپارچه
- دوم
- راز
- بخش
- تیم امنیت لاتاری
- انتخاب
- جداگانه
- تنظیم
- اشتراک گذاری
- باید
- نشان
- نشان داده شده
- به طور قابل توجهی
- مشابه
- ساده
- لغزنده
- هوشمند
- So
- آگاهی
- رسانه های اجتماعی
- برخی از
- چیزی
- فضا
- ویژه
- مشخص شده
- ستاره
- opbevare
- ذخیره شده
- رشته
- ساختار
- دانشجو
- سبک
- سبک
- چنین
- خلاصه کردن
- خلاصه
- نحو
- سیستم
- گرفتن
- صحبت
- مذاکرات
- کار
- وظایف
- پیشرفته
- که
- La
- قانون
- جهان
- آنها
- خودشان
- نظری
- اینها
- اشیاء
- سه
- از طریق
- زمان
- نکات
- عنوان
- به
- رمز
- بالا
- مبدل
- آموزش
- ui
- فهمیدن
- درک
- دانشگاه
- us
- استفاده کنید
- کاربر
- کاربران
- استفاده کنید
- ارزش
- ارزشها
- مختلف
- وسیع
- از طريق
- چشم انداز
- بازدید
- vs
- در مقابل کد
- امواج
- وب
- برنامه تحت وب
- خوب
- چی
- چه شده است
- که
- در حین
- WHO
- ویکیپدیا
- اراده
- با
- در داخل
- بدون
- کلمه
- کلمات
- مهاجرت کاری
- کارگر
- با این نسخهها کار
- جهان
- خواهد بود
- نویسنده
- نوشته
- کتبی
- سال
- شما
- زفیرنت