Image by jcomp on Freepik
Aegrida on andmeteaduse valdkonnas ainulaadne andmestik. Andmed salvestatakse ajaliselt (nt päevane, iganädalane, igakuine jne) ja iga vaatlus on omavahel seotud. Aegridade andmed on väärtuslikud, kui soovite analüüsida, mis teie andmetega aja jooksul juhtub, ja luua tulevikuprognoose.
Aegridade prognoosimine on meetod ajalooliste aegridade andmete põhjal tulevikuennustuste loomiseks. Aegridade prognoosimiseks on palju statistilisi meetodeid, nt ARIMA or Eksponentsiaalne silumine.
Ettevõtluses kohtab aegridade prognoosimist sageli, seega on andmeteadlasel kasulik teada, kuidas aegrea mudelit välja töötada. Selles artiklis õpime, kuidas prognoosida aegridu, kasutades kahte populaarset Pythoni prognoosipaketti; statsmodels ja Prohvet. Lähme sellesse.
. statistikamudelid Pythoni pakett on avatud lähtekoodiga pakett, mis pakub erinevaid statistilisi mudeleid, sealhulgas aegridade prognoosimudelit. Proovime paketti näidisandmestikuga. See artikkel kasutab Digitaalse valuuta ajaseeria andmed Kaggle'ist (CC0: avalik domeen).
Puhastame andmed ja vaatame olemasolevat andmekogumit.
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
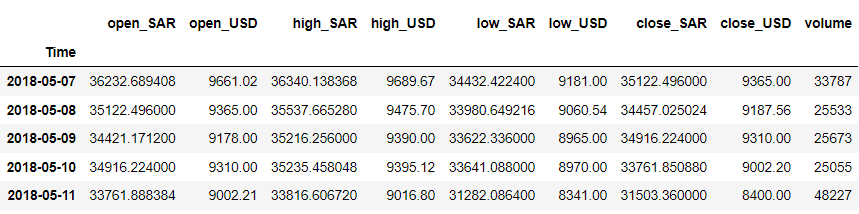
Oletame näiteks, et tahame prognoosida muutujat „close_USD”. Vaatame, kuidas andmemuster aja jooksul muutub.
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
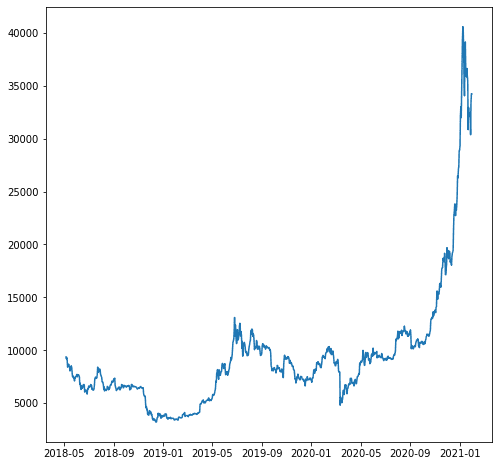
Ehitame ülaltoodud andmete põhjal prognoosimudeli. Enne modelleerimist jagame andmed rongi- ja katseandmeteks.
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
Me ei jaga andmeid juhuslikult, kuna need on aegridade andmed ja me peame järjekorra säilitama. Selle asemel püüame hankida rongiandmed varasematest ja katseandmed viimastest andmetest.
Kasutame prognoosimudeli koostamiseks statistikamudeleid. The statistikamudel pakub palju aegridade mudeli API-sid, kuid me kasutaksime näitena ARIMA mudelit.
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
Ülaltoodud näites kasutame prognoosimudelina statistikamudelite ARIMA mudelit ja proovime ennustada järgmist 200 päeva.
Kas mudeli tulemus on hea? Proovime neid hinnata. Aegridade mudeli hindamisel kasutatakse tavaliselt visualiseerimisgraafikut, et võrrelda tegelikku ja ennustust regressioonimõõdikutega, nagu keskmine absoluutne viga (MAE), ruutkeskmine viga (RMSE) ja MAPE (keskmise absoluutse protsendi viga).
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
Ülaltoodud skoor näeb hea välja, kuid vaatame, kuidas see on, kui me neid visualiseerime.
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
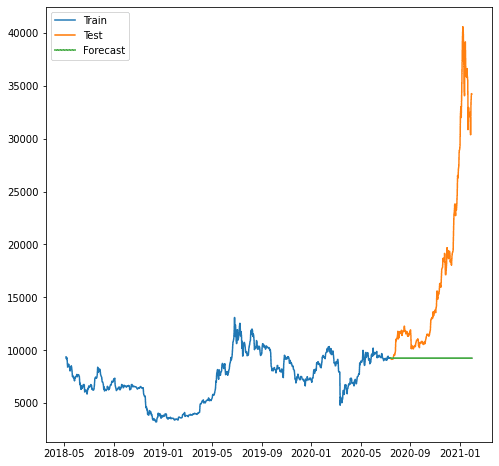
Nagu näeme, oli prognoos kehvem, kuna meie mudel ei suuda prognoosida kasvutrendi. Meie kasutatav mudel ARIMA tundub prognoosimiseks liiga lihtne.
Võib-olla on parem, kui prooviksime kasutada mõnda muud mudelit väljaspool statsmodeles. Proovime kuulsat prohvetipaketti Facebookist.
prohvet on aegridade prognoosimismudelite pakett, mis töötab kõige paremini hooajaliste mõjudega andmete puhul. Prohhet peeti ka tugevaks prognoosimudeliks, kuna see suutis käsitleda puuduvaid andmeid ja kõrvalekaldeid.
Proovime Prophet paketti. Esiteks peame installima paketi.
pip install prophet
Pärast seda peame oma andmestiku prognoosimudeli koolituseks ette valmistama. Prohvetil on konkreetne nõue: aja veeru nimi peab olema "ds" ja väärtus "y".
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
Kui meie andmed on valmis, proovime koostada andmete põhjal prognoosiprognoosi.
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
Prohveti puhul oli suurepärane see, et iga prognoositav andmepunkt oli meile, kasutajatele, üksikasjalikult kirjeldatud. Kuid ainult andmete põhjal on tulemust raske mõista. Seega võiksime proovida neid visualiseerida Prophet kasutades.
model.plot(predictions)
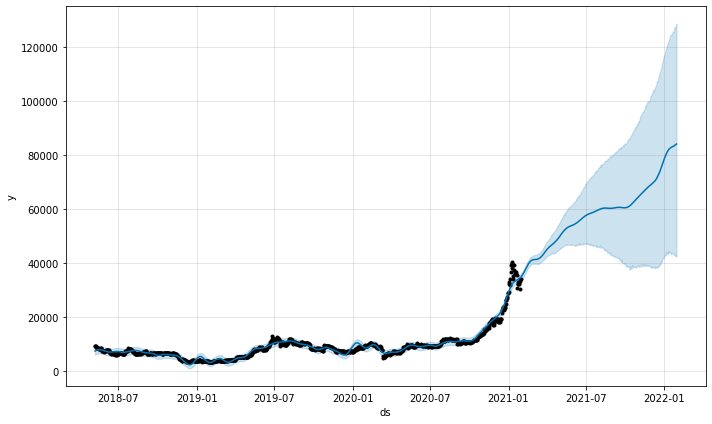
Mudeli ennustusgraafiku funktsioon annaks meile teada, kui kindlad ennustused olid. Ülaltoodud jooniselt näeme, et ennustusel on tõusutrend, kuid seda suurema ebakindlusega, mida pikemad on ennustused.
Prognoosikomponente on võimalik uurida ka järgmise funktsiooniga.
model.plot_components(predictions)
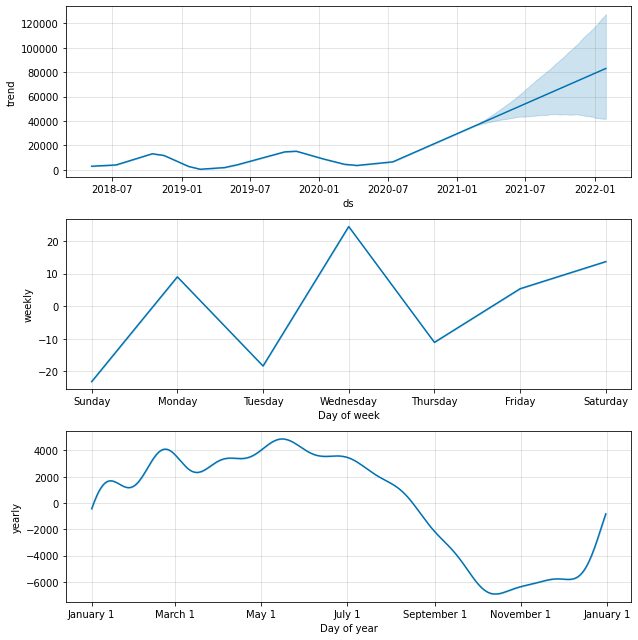
Vaikimisi saame andmete trendi aastase ja iganädalase hooajalisusega. See on hea viis selgitada, mis meie andmetega juhtub.
Kas oleks võimalik hinnata ka Prohveti mudelit? Absoluutselt. Prohvet sisaldab diagnostilist mõõtmist, mida saame kasutada: aegridade ristvalideerimine. Meetod kasutab osa ajaloolistest andmetest ja sobib mudeliga iga kord, kasutades andmeid kuni lõikepunktini. Seejärel võrdles prohvet ennustusi tegelikega. Proovime koodi kasutada.
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
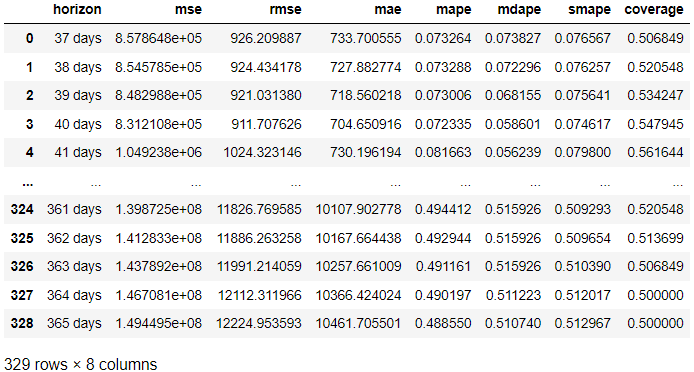
Ülaltoodud tulemuses saime hindamistulemuse tegelikust tulemusest võrreldes prognoosiga igal prognoosipäeval. Tulemust on võimalik visualiseerida ka järgmise koodiga.
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
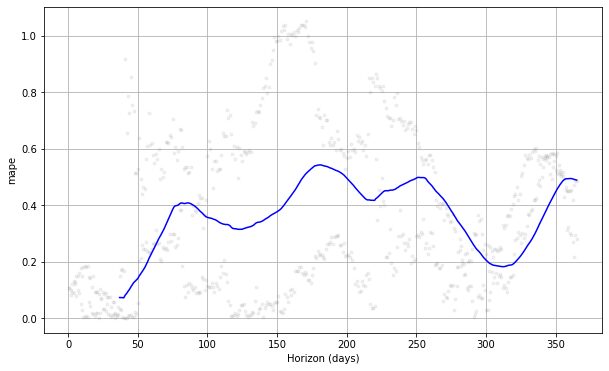
Kui näeme ülaltoodud graafikut, näeme, et ennustusviga oli päevade järel erinev ja võib mõnel hetkel saavutada 50% vea. Sel moel soovime võib-olla mudelit vea parandamiseks veelgi kohandada. Saate kontrollida dokumentatsioon edasiseks uurimiseks.
Prognoosimine on üks levinumaid juhtumeid, mis ettevõttes ette tuleb. Üks lihtne viis prognoosimudeli väljatöötamiseks on pakettide statsforecast ja Prophet Python kasutamine. Sellest artiklist õpime, kuidas luua prognoosimudelit ja hinnata neid statsforecasti ja Prophet abil.
Cornelius Yudha Wijaya on andmeteaduse juhi assistent ja andmete kirjutaja. Allianz Indonesias täiskohaga töötades armastab ta sotsiaalmeedia ja kirjutamismeedia kaudu Pythoni ja Data näpunäiteid jagada.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. Juurdepääs siia.
- Allikas: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- :on
- $ UP
- 1
- 11
- 7
- 8
- 9
- a
- MEIST
- üle
- absoluutne
- absoluutselt
- Saavutada
- omandatud
- Allianz
- analüüsima
- ja
- Teine
- API-liidesed
- OLEME
- artikkel
- AS
- assistent
- At
- põhineb
- BE
- sest
- enne
- kasulik
- BEST
- Parem
- vahel
- ehitama
- äri
- by
- arvutama
- CAN
- juhtudel
- CC0
- kontrollima
- kood
- Veerg
- Veerud
- ühine
- võrdlema
- võrreldes
- komponendid
- kindel
- kaaluda
- võiks
- katmine
- looma
- valuuta
- iga päev
- andmed
- andmeteadus
- andmeteadlane
- kuupäev
- päev
- Päeva
- dc
- vaikimisi
- üksikasjalik
- arendama
- domeen
- Ära
- e
- iga
- Ajalugu
- mõju
- viga
- jms
- hindama
- hindamine
- Iga
- näide
- Selgitama
- uurimine
- kuulus
- väli
- lõpp
- esimene
- sobima
- Määrama
- Järel
- eest
- Ennustus
- Alates
- funktsioon
- edasi
- tulevik
- saama
- GitHub
- hea
- graafik
- suur
- käepide
- juhtub
- Raske
- Olema
- ajalooline
- silmapiir
- Kuidas
- Kuidas
- aga
- HTML
- HTTPS
- import
- in
- hõlmab
- Kaasa arvatud
- kasvanud
- kasvav
- indeks
- Indoneesia
- esialgne
- paigaldama
- selle asemel
- IT
- jpg
- KDnuggets
- Teadma
- hiljemalt
- Õppida
- enam
- Vaata
- välimus
- tegema
- juht
- palju
- matplotlib
- Meedia
- meetod
- meetodid
- Meetrika
- võib
- puuduvad
- mudel
- modelleerimine
- mudelid
- igakuine
- Nimega
- Vajadus
- vajadustele
- järgmine
- tuim
- saama
- of
- pakkumine
- on
- ONE
- avatud lähtekoodiga
- et
- Muu
- väljaspool
- pakend
- pakette
- pandas
- parameetrid
- osa
- Muster
- protsent
- täitma
- Platon
- Platoni andmete intelligentsus
- PlatoData
- Punkt
- võrra
- populaarne
- võimalik
- ennustada
- ennustus
- Ennustused
- Valmistama
- anda
- annab
- avalik
- Python
- valmis
- dokumenteeritud
- regressioon
- seotud
- nõue
- kaasa
- Tulemused
- jõuline
- juur
- teadus
- teadlane
- tundub
- Seeria
- komplekt
- Jaga
- lihtne
- So
- sotsiaalmeedia
- Sotsiaalse meedia
- mõned
- konkreetse
- jagada
- ruut
- statistiline
- selline
- Võtma
- test
- et
- .
- Neile
- aeg
- Ajaseeria
- nõuanded
- et
- liiga
- Rong
- koolitus
- Trend
- Ebakindlus
- mõistma
- ainulaadne
- NIMETAMATA
- ülespoole
- us
- kasutama
- Kasutajad
- tavaliselt
- väärtuslik
- väärtus
- eri
- kaudu
- visualiseerimine
- Tee..
- iga nädal
- Hästi
- M
- kuigi
- Wikipedia
- will
- koos
- jooksul
- töö
- töötab
- oleks
- kirjanik
- kirjutamine
- Sinu
- sephyrnet