Suure keelemudeli (LLM) juurutamisel hoolivad masinõppe (ML) praktikud mudeli esitamise jõudluse jaoks tavaliselt kahest mõõtmisest: latentsus, mis on määratud ühe loa genereerimiseks kuluva aja järgi, ja läbilaskevõime, mis on määratletud genereeritud märkide arvuga. sekundis. Kuigi ühe juurutatud lõpp-punkti päringu läbilaskevõime oleks ligikaudu võrdne mudeli latentsuse pöördväärtusega, ei pruugi see nii olla, kui lõpp-punktile saadetakse samaaegselt mitu samaaegset päringut. Mudelite serveerimistehnikate (nt kliendipoolne samaaegsete päringute pidev komplekteerimine) tõttu on latentsusel ja läbilaskevõimel keeruline seos, mis varieerub oluliselt sõltuvalt mudeli arhitektuurist, teeninduskonfiguratsioonidest, eksemplari tüübi riistvarast, samaaegsete päringute arvust ja sisendkoormuste variatsioonidest, näiteks sisend- ja väljundmärkide arvuna.
See postitus uurib neid suhteid Amazon SageMaker JumpStartis saadaolevate LLM-ide põhjaliku võrdlusuuringu kaudu, sealhulgas Llama 2, Falconi ja Mistrali variandid. SageMaker JumpStartiga saavad ML-i praktikud valida laia valiku avalikult saadaolevate vundamendimudelite hulgast, mida kasutada selleks spetsiaalselt Amazon SageMaker võrgust eraldatud keskkonnas. Pakume teoreetilisi põhimõtteid selle kohta, kuidas kiirendi spetsifikatsioonid mõjutavad LLM-i võrdlusuuringuid. Samuti demonstreerime ühe lõpp-punkti taga mitme eksemplari juurutamise mõju. Lõpuks anname praktilisi soovitusi SageMaker JumpStart juurutusprotsessi kohandamiseks, et see vastaks teie nõuetele latentsusaja, läbilaskevõime, kulude ja saadaolevate eksemplaritüüpide piirangute osas. Kõik võrdlusuuringu tulemused ja soovitused põhinevad mitmekülgsel märkmik mida saate oma kasutusjuhtumile kohandada.
Kasutatud lõpp-punktide võrdlusuuringud
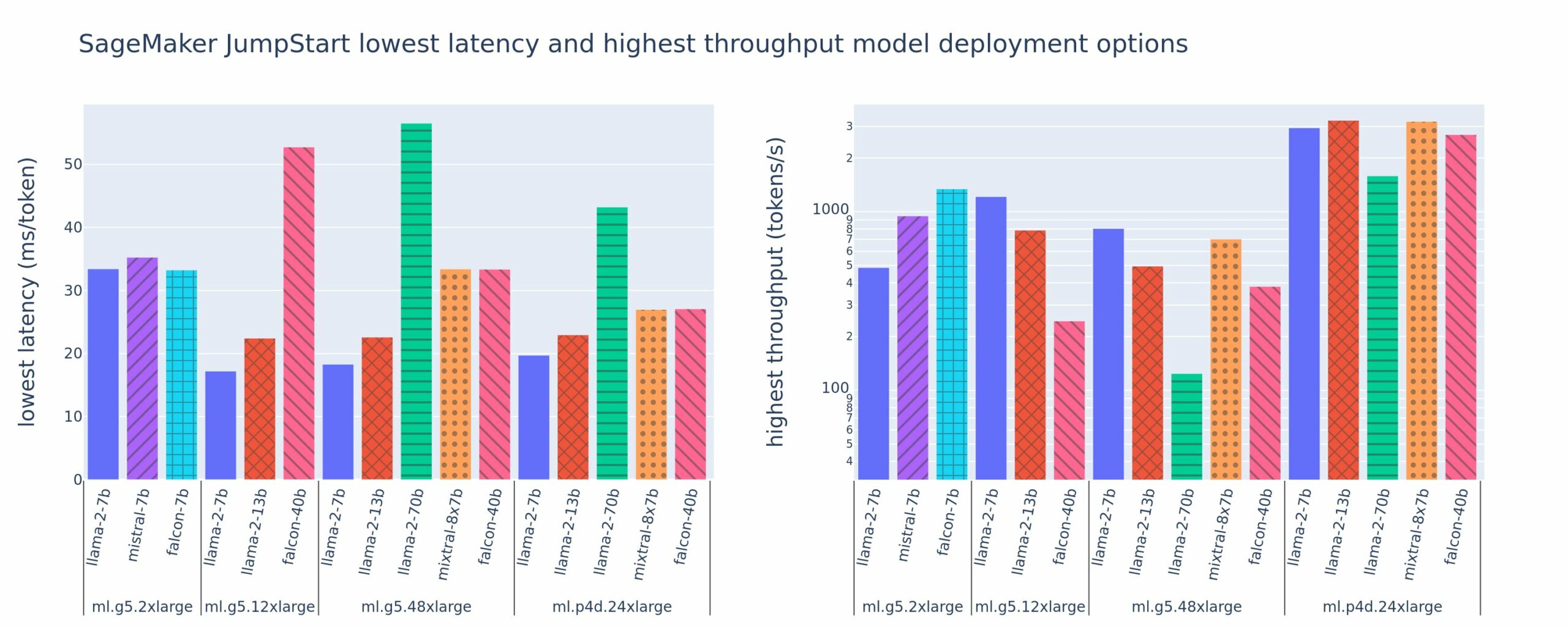
Järgmisel joonisel on näidatud juurutuskonfiguratsioonide madalaimad latentsusajad (vasakul) ja suurima läbilaskevõime (paremal) väärtused mitmesuguste mudelitüüpide ja eksemplaritüüpide puhul. Oluline on see, et kõik need mudeli juurutused kasutavad vaikekonfiguratsioone, mille pakub SageMaker JumpStart, võttes arvesse juurutamiseks soovitud mudeli ID ja eksemplari tüüpi.
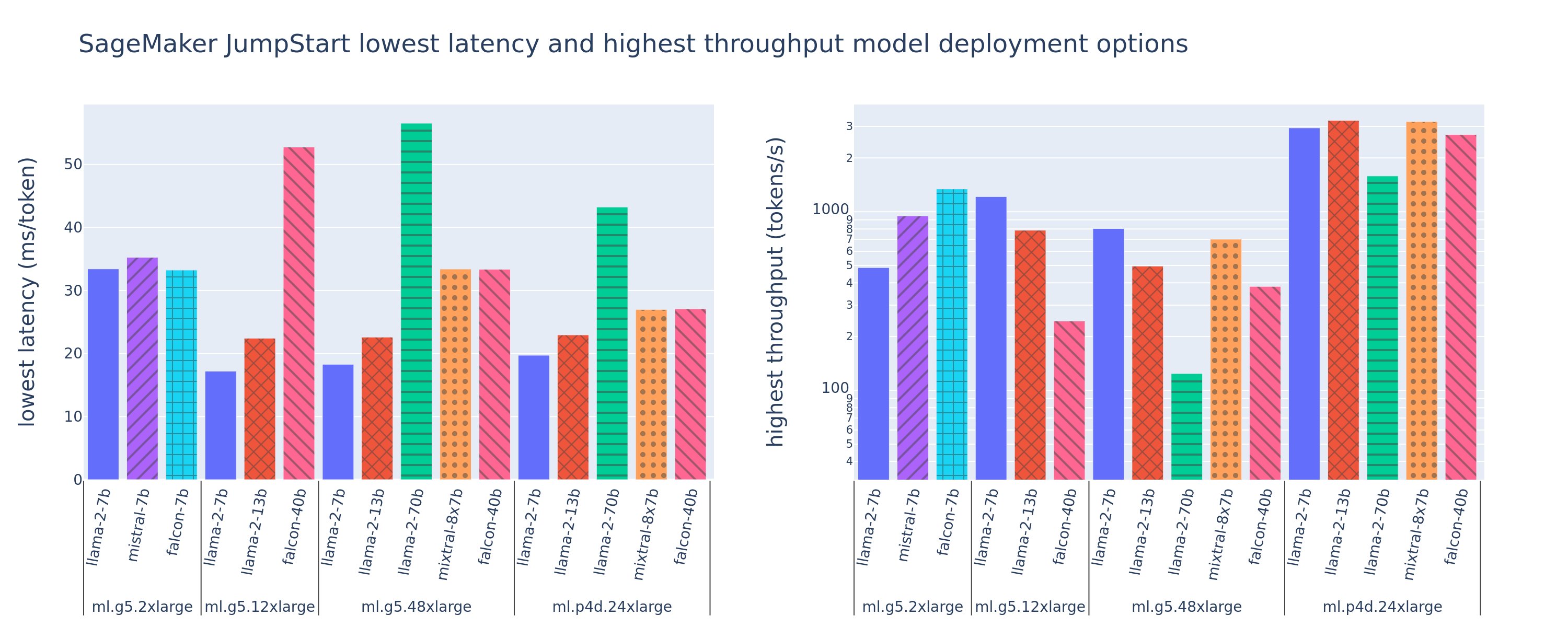
Need latentsus- ja läbilaskevõime väärtused vastavad 256 sisend- ja 256 väljundmärgiga kasulikele koormustele. Väikseima latentsusaja konfiguratsioon piirab mudeli esitamist ühele samaaegsele päringule ja suurim läbilaskevõime konfiguratsioon maksimeerib samaaegsete päringute võimaliku arvu. Nagu näeme meie võrdlusuuringust, suurendab samaaegsete päringute arvu suurendamine monotoonselt läbilaskevõimet, samas kui suurte samaaegsete päringute puhul väheneb täiustus. Lisaks on mudelid toetatud eksemplaril täielikult killustatud. Näiteks kuna eksemplaril ml.g5.48xlarge on 8 GPU-d, on kõik seda eksemplari kasutavad SageMaker JumpStart mudelid jaotatud tensorparalleelsuse abil kõigis kaheksas saadaolevas kiirendis.
Sellelt jooniselt võime märkida mõningaid väljavõtteid. Esiteks ei toetata kõiki mudeleid kõigil juhtudel; mõned väiksemad mudelid, nagu Falcon 7B, ei toeta mudelite jagamist, samas kui suurematel mudelitel on suuremad arvutusressursinõuded. Teiseks, kui killustatus suureneb, paraneb jõudlus tavaliselt, kuid väikeste mudelite puhul ei pruugi see tingimata paraneda. Selle põhjuseks on asjaolu, et väikesed mudelid, nagu 7B ja 13B, tekitavad liiga paljudele kiirenditele eraldades märkimisväärse sidekulu. Arutame seda hiljem põhjalikumalt. Lõpuks on ml.p4d.24xlarge eksemplaridel märkimisväärselt parem läbilaskevõime tänu A100 mälu ribalaiuse täiustustele võrreldes A10G GPU-dega. Nagu me hiljem arutame, sõltub konkreetse eksemplaritüübi kasutamise otsus teie juurutusnõuetest, sealhulgas latentsusest, läbilaskevõimest ja kulupiirangutest.
Kuidas saada need väikseima latentsusaja ja suurima läbilaskevõime konfiguratsiooniväärtused? Alustuseks joonistame Llama 2 7B lõpp-punkti latentsusaja ja läbilaskevõime väärtuse ml.g5.12xsuurel eksemplaril 256 sisendmärgiga ja 256 väljundmärgiga kasuliku koormuse jaoks, nagu on näha järgmisel kõveral. Sarnane kõver on olemas iga juurutatud LLM-i lõpp-punkti jaoks.

Samaaegsuse suurenedes suurenevad monotoonselt ka läbilaskevõime ja latentsusaeg. Seetõttu esineb madalaim latentsuspunkt samaaegse päringu väärtuse 1 korral ja samaaegsete päringute arvu suurendamisega saate kulutõhusalt suurendada süsteemi läbilaskevõimet. Sellel kõveral on selge "põlv", kus on ilmne, et täiendava samaaegsusega seotud läbilaskevõime suurenemine ei kaalu üles sellega seotud latentsusaja suurenemist. Selle põlve täpne asukoht on kasutusjuhtumipõhine; mõned praktikud võivad määratleda põlve kohas, kus eelnevalt kindlaksmääratud latentsusnõue on ületatud (nt 100 ms/token), samas kui teised võivad kasutada koormustesti võrdlusaluseid ja järjekorrateooria meetodeid, nagu poollatentsuse reegel, ja teised võivad kasutada teoreetilised kiirendi spetsifikatsioonid.
Samuti märgime, et samaaegsete taotluste maksimaalne arv on piiratud. Eelmisel joonisel lõpeb rea jälg 192 samaaegse päringuga. Selle piirangu allikaks on SageMakeri kutsumise ajalõpu limiit, mille puhul SageMaker seab väljakutse vastuse ajalõpu 60 sekundi pärast. See säte on kontopõhine ja seda ei saa konfigureerida üksiku lõpp-punkti jaoks. LLM-ide puhul võib suure hulga väljundmärkide loomine võtta sekundeid või isegi minuteid. Seetõttu võivad suured sisend- või väljundkoormused kutsumistaotluste ebaõnnestumise põhjustada. Lisaks, kui samaaegsete päringute arv on väga suur, on paljudel päringutel pikk järjekord, mis pikendab 60-sekundilist ajalõpu piirangut. Selle uuringu jaoks kasutame mudeli juurutamise maksimaalse võimaliku läbilaskevõime määratlemiseks ajalõpupiirangut. Oluline on see, et kuigi SageMakeri lõpp-punkt võib käsitleda suurt hulka samaaegseid päringuid ilma kutsumisvastuse ajalõpu jälgimiseta, võiksite latentsus-läbilaskevõime kõvera põlve suhtes määrata maksimaalsed samaaegsed päringud. See on tõenäoliselt hetk, kus hakkate kaaluma horisontaalset skaleerimist, kus üks lõpp-punkt varustab mitu eksemplari mudelikoopiatega ja tasakaalustab koopiate vahel sissetulevad päringud, et toetada rohkem samaaegseid taotlusi.
Kui võtta see samm edasi, sisaldab järgmine tabel Llama 2 7B mudeli erinevate konfiguratsioonide võrdlusuuringu tulemusi, sealhulgas erinevat arvu sisend- ja väljundmärke, eksemplari tüüpe ja samaaegsete päringute arvu. Pange tähele, et eelnev joonis kujutab ainult selle tabeli ühte rida.
| . | Läbilaskevõime (märke/s) | Latentsus (ms/märk) | ||||||||||||||||||
| Samaaegsed taotlused | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Märkide arv kokku: 512, väljundmärkide arv: 256 | ||||||||||||||||||||
| ml.g5.2xsuur | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xsuur | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xsuur | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Märkide arv kokku: 4096, väljundmärkide arv: 256 | ||||||||||||||||||||
| ml.g5.2xsuur | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xsuur | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xsuur | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
Jälgime nendes andmetes mõningaid täiendavaid mustreid. Konteksti suuruse suurendamisel suureneb latentsus ja läbilaskevõime väheneb. Näiteks failis ml.g5.2xlarge, mille samaaegsus on 1, on läbilaskevõime 30 märki sekundis, kui žetoonide koguarv on 512, võrreldes 20 žetooniga sekundis, kui žetoonide koguarv on 4,096. Seda seetõttu, et suurema sisendi töötlemiseks kulub rohkem aega. Samuti näeme, et GPU võimekuse suurendamine ja jagamine mõjutavad maksimaalset läbilaskevõimet ja maksimaalselt toetatud samaaegseid taotlusi. Tabel näitab, et Llama 2 7B maksimaalse läbilaskevõime väärtused on erinevate eksemplaritüüpide jaoks märkimisväärselt erinevad ja need maksimaalsed läbilaskevõime väärtused esinevad samaaegsete päringute erinevate väärtuste korral. Need omadused ajendaksid ML-praktikat õigustama ühe eksemplari maksumust teisega võrreldes. Näiteks madala latentsusaja nõude tõttu võib arst valida ml.g5.12xsuure eksemplari (4 A10G GPU-d) ml.g5.2x suure eksemplari (1 A10G GPU) asemel. Kõrge läbilaskevõimenõude korral oleks ml.p4d.24xlarge eksemplari (8 A100 GPU-d) kasutamine täieliku jaotusega õigustatud ainult suure samaaegsuse korral. Pange tähele, et sageli on kasulik laadida 7B mudeli mitu järelduskomponenti ühele ml.p4d.24xlarge eksemplarile; sellist mitme mudeli toetust käsitletakse selles postituses hiljem.
Eelnevad vaatlused tehti Llama 2 7B mudeli kohta. Sarnased mustrid jäävad aga paika ka teiste mudelite puhul. Peamine järeldus on see, et latentsus- ja läbilaskevõime numbrid sõltuvad kasulikust koormusest, eksemplari tüübist ja samaaegsete päringute arvust, seega peate leidma oma konkreetse rakenduse jaoks ideaalse konfiguratsiooni. Eelnevate numbrite genereerimiseks oma kasutusjuhtumi jaoks saate käivitada lingitud märkmik, kus saate konfigureerida selle koormustesti analüüsi oma mudeli, eksemplari tüübi ja kasuliku koormuse jaoks.
Kiirendi spetsifikatsioonide mõtestamine
LLM-i järelduse jaoks sobiva riistvara valimine sõltub suuresti konkreetsetest kasutusjuhtudest, kasutajakogemuse eesmärkidest ja valitud LLM-ist. Selles jaotises püütakse luua arusaama põlvest latentsus-läbilaskevõime kõveras, pidades silmas kiirendi spetsifikatsioonidel põhinevaid kõrgetasemelisi põhimõtteid. Nendest põhimõtetest üksi otsuse tegemiseks ei piisa: vajalikud on tõelised võrdlusalused. Termin seade kasutatakse siin kõigi ML-i riistvarakiirendite hõlmamiseks. Väidame, et latentsus-läbilaskvuskõvera põlve on ajendatud ühest kahest tegurist:
- Kiirendil on KV maatriksite vahemällu salvestamiseks ammendatud mälu, mistõttu järgnevad päringud pannakse järjekorda
- Kiirendil on veel vaba mälu KV vahemälu jaoks, kuid see kasutab piisavalt suurt partii mahtu, et töötlemisaega juhib pigem arvutustoimingu latentsus kui mälu ribalaius
Tavaliselt eelistame, et meid piirab teine tegur, kuna see tähendab, et kiirendi ressursid on küllastunud. Põhimõtteliselt maksimeerite ressursse, mille eest maksite. Uurime seda väidet üksikasjalikumalt.
KV vahemälu ja seadme mälu
Standardsed trafo tähelepanumehhanismid arvutavad tähelepanu iga uue märgi jaoks võrreldes kõigi eelnevate märkidega. Enamik kaasaegseid ML-servereid salvestab tähelepanu võtmed ja väärtused seadme mällu (DRAM), et vältida igal sammul ümberarvutamist. Seda nimetatakse KV vahemäluja see kasvab koos partii suuruse ja järjestuse pikkusega. See määratleb, mitu kasutajapäringut saab paralleelselt teenindada, ja määrab latentsus-läbilaskevõime kõvera põlve, kui varem mainitud teise stsenaariumi arvutuslik režiim ei ole veel täidetud, võttes arvesse saadaolevat DRAM-i. Järgmine valem on KV vahemälu maksimaalse suuruse ligikaudne väärtus.

Selles valemis on B partii suurus ja N on kiirendite arv. Näiteks Llama 2 7B mudel FP16-s (2 baiti/parameetri kohta), mida teenindatakse A10G GPU-ga (24 GB DRAM), tarbib umbes 14 GB, jättes KV vahemälu jaoks 10 GB. Kui ühendate mudeli kogu konteksti pikkuse (N = 4096) ja ülejäänud parameetrid (n_layers = 32, n_kv_attention_heads = 32 ja d_attention_head = 128), näitab see avaldis, et DRAM-i piirangute tõttu piirdume nelja kasutajaga paralleelse partii teenindamisega. . Kui jälgite eelmises tabelis vastavaid võrdlusnäitajaid, on see latentsus-läbilaskvuskõvera vaadeldud põlve jaoks hea ligikaudne hinnang. Sellised meetodid nagu rühmitatud päring tähelepanu (GQA) võib vähendada KV vahemälu suurust, GQA puhul sama teguri võrra vähendab see KV peade arvu.
Aritmeetiline intensiivsus ja seadme mälu ribalaius
ML-kiirendite arvutusvõimsuse kasv on ületanud nende mälu ribalaiust, mis tähendab, et nad saavad iga andmebaidi kohta teha palju rohkem arvutusi selle aja jooksul, mis kulub sellele baidile juurdepääsuks.
. aritmeetiline intensiivsus, või arvutustoimingute ja mälupöörduste suhe, määrab toimingu puhul, kas seda piirab valitud riistvara mälu ribalaius või arvutusmaht. Näiteks 10 TFLOPS FP5 ja 70 GB/sek ribalaiusega A16G GPU (g600 eksemplari tüüpide perekond) suudab arvutada ligikaudu 116 ops/baidi kohta. A100 GPU (p4d eksemplaritüüpide perekond) suudab arvutada ligikaudu 208 operatsiooni baidi kohta. Kui trafo mudeli aritmeetiline intensiivsus on sellest väärtusest väiksem, on see mäluga seotud; kui see on ülevalpool, on see arvutatud. Llama 2 7B tähelepanumehhanism nõuab partii suuruse 62 jaoks 1 ops/bait (selgitust vt Juhend LLM-i järelduste ja toimivuse kohta), mis tähendab, et see on mäluga seotud. Kui tähelepanumehhanism on mäluga seotud, jäävad kallid FLOPSid kasutamata.
Kiirendi paremaks kasutamiseks ja aritmeetilise intensiivsuse suurendamiseks on kaks võimalust: vähendada operatsiooni jaoks vajalikke mälupöördusi (see on see, mis FlashTähelepanu keskendub) või suurendage partii suurust. Kui meie DRAM on aga vastava KV vahemälu mahutamiseks liiga väike, ei pruugi me oma partii suurust arvutusliku režiimi saavutamiseks piisavalt suurendada. Kriitilise partii suuruse B* umbkaudset lähendust, mis eraldab arvutamise ja mäluga seotud režiimid standardse GPT dekoodri järelduse jaoks, kirjeldatakse järgmise avaldisega, kus A_mb on kiirendi mälu ribalaius, A_f on kiirendi FLOPS ja N on arv. kiirenditest. Selle kriitilise partii suuruse saab tuletada, leides, kus mälu juurdepääsuaeg võrdub arvutusajaga. Viitama see blogipostitus võrrandi 2 ja selle eelduste üksikasjalikumaks mõistmiseks.

See on sama operatsioonide/baidi suhe, mille me varem A10G jaoks arvutasime, nii et selle GPU jaoks on kriitiline partii suurus 116. Üks võimalus sellele teoreetilisele kriitilisele partii suurusele läheneda on suurendada mudeli jaotust ja jagada vahemälu rohkema N kiirendi vahel. See suurendab tõhusalt nii KV vahemälu mahtu kui ka mäluga seotud partii suurust.
Mudeli jagamise teine eelis on mudeli parameetrite ja andmete laadimistöö jagamine N kiirendi vahel. Seda tüüpi killustatus on mudeli paralleelsuse tüüp, millele viidatakse ka kui tensori paralleelsus. Naiivselt öeldes on mälu ribalaius ja arvutusvõimsus kokku N korda suurem. Eeldades, et pole mingeid üldkulusid (side, tarkvara jne), vähendaks see dekodeerimise latentsust märgi kohta N võrra, kui oleme mäluga seotud, kuna selles režiimis on märgi dekodeerimise latentsus seotud mudeli laadimiseks kuluva ajaga. kaalud ja vahemälu. Reaalses elus suurendab killustatuse suurendamine aga seadmete vahelist suhtlust, et jagada vahepealseid aktiveerimisi igal mudelikihil. Seda sidekiirust piirab seadme ühenduse ribalaius. Selle mõju on raske täpselt hinnata (üksikasju vt Mudeli paralleelsus), kuid see võib lõpuks lõpetada eeliste andmise või jõudluse halvenemise – see kehtib eriti väiksemate mudelite puhul, kuna väiksemad andmeedastused põhjustavad madalamaid edastuskiirusi.
ML-kiirendite võrdlemiseks nende tehniliste andmete põhjal soovitame järgmist. Esiteks arvutage iga kiirendi tüübi ligikaudne kriitiline partii suurus vastavalt teisele võrrandile ja KV vahemälu suurus kriitilise partii suuruse jaoks vastavalt esimesele võrrandile. Seejärel saate kasutada kiirendil saadaolevat DRAM-i, et arvutada minimaalne kiirendite arv, mis on vajalik KV vahemälu ja mudeli parameetrite sobitamiseks. Kui otsustate mitme kiirendi vahel, seadke kiirendid prioriteediks vastavalt väikseima kulu GB/s mälu ribalaiuse kohta. Lõpuks tehke nende konfiguratsioonide võrdlusanalüüs ja kontrollige, milline on teie soovitud latentsusaja ülempiiri jaoks parim kulu/märk.
Valige lõpp-punkti juurutamise konfiguratsioon
Paljud LLM-id, mida levitab SageMaker JumpStart, kasutavad seda teksti genereerimine-järeldus (TGI) SageMaker konteiner mudeli serveerimiseks. Järgmises tabelis kirjeldatakse, kuidas kohandada mitmesuguseid mudeli esitamise parameetreid, et mõjutada mudeli esitamist, mis mõjutab latentsus- ja läbilaskevõime kõverat, või kaitsta lõpp-punkti päringute eest, mis võiksid lõpp-punkti üle koormata. Need on peamised parameetrid, mida saate kasutada lõpp-punkti juurutamise konfigureerimiseks oma kasutusjuhtumi jaoks. Kui pole teisiti määratud, kasutame vaikimisi teksti genereerimise kasuliku koormuse parameetrid ja TGI keskkonnamuutujad.
| Keskkonnamuutuja | Kirjeldus | SageMaker JumpStarti vaikeväärtus |
| Mudelite esitamise konfiguratsioonid | . | . |
MAX_BATCH_PREFILL_TOKENS |
Piirab märkide arvu eeltäitmistoimingus. See toiming loob KV vahemälu uue sisendviiba jada jaoks. See on mälumahukas ja arvutuslik, seega piirab see väärtus ühe eeltäitetoiminguga lubatud märkide arvu. Muude päringute dekodeerimise etapid peatuvad eeltäidete ajal. | 4096 (TGI vaikimisi) või mudelispetsiifiline maksimaalne toetatud konteksti pikkus (kaasas on SageMaker JumpStart), olenevalt sellest, kumb on suurem. |
MAX_BATCH_TOTAL_TOKENS |
Juhib dekodeerimise või mudeli ühekordse edasiliikumise ajal partiisse kaasatavate žetoonide maksimaalset arvu. Ideaalis on see seatud kogu saadaoleva riistvara kasutamise maksimeerimiseks. | Pole määratud (TGI vaikimisi). TGI määrab selle väärtuse mudeli soojenemise ajal järelejäänud CUDA mälu suhtes. |
SM_NUM_GPUS |
Kasutatavate kildude arv. See tähendab, GPU-de arv, mida kasutatakse mudeli käitamiseks tensorparalleelsust kasutades. | Sõltub eksemplarist (saage kaasas SageMaker JumpStart). Antud mudeli iga toetatud eksemplari jaoks pakub SageMaker JumpStart parimaid sätteid tensori paralleelsuse jaoks. |
| Konfiguratsioonid teie lõpp-punkti kaitsmiseks (määrake need oma kasutusjuhtumi jaoks) | . | . |
MAX_TOTAL_TOKENS |
See piirab ühe kliendi päringu mälueelarvet, piirates sisendjärjestuses olevate märkide arvu pluss märkide arvu väljundjadas ( max_new_tokens kasuliku koormuse parameeter). |
Mudelipõhine maksimaalne toetatud konteksti pikkus. Näiteks 4096 Llama 2 jaoks. |
MAX_INPUT_LENGTH |
Tuvastab ühe kliendipäringu sisendjärjestuses maksimaalse lubatud märkide arvu. Asjad, mida selle väärtuse suurendamisel arvesse võtta, on järgmised: pikemad sisendjadad nõuavad rohkem mälu, mis mõjutab pidevat komplekteerimist, ja paljudel mudelitel on toetatud konteksti pikkus, mida ei tohiks ületada. | Mudelipõhine maksimaalne toetatud konteksti pikkus. Näiteks 4095 Llama 2 jaoks. |
MAX_CONCURRENT_REQUESTS |
Juurutatud lõpp-punkti poolt lubatud samaaegsete päringute maksimaalne arv. Uued päringud, mis ületavad seda limiiti, tekitavad kohe mudeli ülekoormatud vea, et vältida praeguste töötlemistaotluste halba latentsust. | 128 (TGI vaikeväärtus). See säte võimaldab teil saavutada suure läbilaskevõime erinevatel kasutusjuhtudel, kuid SageMakeri kutsumise ajalõpu vigade leevendamiseks peaksite vajadusel kinnitama. |
TGI-server kasutab pidevat komplekteerimist, mis koondab samaaegsed päringud dünaamiliselt kokku, et jagada ühtse mudeli järelduste edasipääsu. Edasipääse on kahte tüüpi: eeltäitmine ja dekodeerimine. Iga uus päring peab käivitama ühe eeltäitmise edasipääsu, et täita KV vahemälu sisendjärjestuse lubade jaoks. Pärast KV vahemälu täitmist teostab dekodeerimise edasipääs kõigi paketttaotluste jaoks ühe järgmise märgi ennustuse, mida korratakse väljundjada saamiseks iteratiivselt. Kui serverisse saadetakse uusi päringuid, peab järgmine dekodeerimise etapp ootama, et eeltäidet saaks käivitada uute päringute jaoks. See peab toimuma enne, kui need uued päringud kaasatakse järgmistesse pidevalt komplekteeritud dekodeerimisetappidesse. Riistvaraliste piirangute tõttu ei pruugi dekodeerimiseks kasutatav pidev pakkimine hõlmata kõiki taotlusi. Sel hetkel sisenevad päringud töötlemisjärjekorda ja järelduste latentsus hakkab märkimisväärselt suurenema, kuid läbilaskevõime on väike.
LLM-i latentsusaja võrdlusanalüüsid on võimalik jagada eeltäitmise latentsusajaks, dekodeerimise latentsusajaks ja järjekorra latentsusajaks. Kõigi nende komponentide kuluv aeg on oma olemuselt põhimõtteliselt erinev: eeltäitmine on ühekordne arvutus, dekodeerimine toimub üks kord iga väljundjada märgi jaoks ja järjekord hõlmab serveri partiiprotsesse. Kui töödeldakse mitut samaaegset päringut, muutub latentsusajad igast komponendist keeruliseks, kuna iga kliendipäringu latentsusaeg hõlmab järjekorra latentsusaega, mis on tingitud vajadusest täita uusi samaaegseid päringuid, samuti järjekorra latentsusaega, mis on tingitud kaasamisest. pakettdekodeerimise protsessides. Sel põhjusel keskendub see postitus täielikule töötlemise latentsusele. Latentsus-läbilaskevõime kõvera põlv tekib küllastuspunktis, kus järjekorra latentsusaeg hakkab märkimisväärselt suurenema. See nähtus esineb iga mudeli järeldusserveri puhul ja seda juhivad kiirendi spetsifikatsioonid.
Levinud nõuded juurutamise ajal hõlmavad minimaalse nõutava läbilaskevõime, maksimaalse lubatud latentsuse, maksimaalse tunnikulu ja 1 miljoni loa genereerimise maksimaalset kulu. Peaksite neid nõudeid seadma kasulikele koormustele, mis esindavad lõppkasutaja taotlusi. Nendele nõuetele vastav disain peaks arvestama paljude teguritega, sealhulgas konkreetse mudeli arhitektuuri, mudeli suurust, eksemplaritüüpe ja eksemplaride arvu (horisontaalne skaleerimine). Järgmistes jaotistes keskendume lõpp-punktide juurutamisele, et minimeerida latentsust, maksimeerida läbilaskevõimet ja minimeerida kulusid. See analüüs võtab arvesse 512 märki ja 256 väljundmärki.
Minimeeri latentsusaeg
Latentsus on oluline nõue paljudel reaalajas kasutusel. Järgmises tabelis vaatleme iga mudeli ja iga eksemplari tüübi minimaalset latentsust. Seadistades saate saavutada minimaalse latentsuse MAX_CONCURRENT_REQUESTS = 1.
| Minimaalne latentsusaeg (ms/märk) | |||||
| Mudeli ID | ml.g5.2xsuur | ml.g5.12xsuur | ml.g5.48xsuur | ml.p4d.24xlarge | ml.p4de.24xsuur |
| Laama 2 7B | 33 | 17 | 18 | 20 | - |
| Laama 2 7B Vestlus | 33 | 17 | 18 | 20 | - |
| Laama 2 13B | - | 22 | 23 | 23 | - |
| Laama 2 13B Vestlus | - | 23 | 23 | 23 | - |
| Laama 2 70B | - | - | 57 | 43 | - |
| Laama 2 70B Vestlus | - | - | 57 | 45 | - |
| Mistral 7B | 35 | - | - | - | - |
| Mistral 7B juhendamine | 35 | - | - | - | - |
| Mixtral 8x7B | - | - | 33 | 27 | - |
| Falcon 7B | 33 | - | - | - | - |
| Falcon 7B juhendamine | 33 | - | - | - | - |
| Falcon 40B | - | 53 | 33 | 27 | - |
| Falcon 40B juhendamine | - | 53 | 33 | 28 | - |
| Falcon 180B | - | - | - | - | 42 |
| Falcon 180B vestlus | - | - | - | - | 42 |
Mudeli minimaalse latentsusaja saavutamiseks võite soovitud mudeli ID ja eksemplari tüübi asendamisel kasutada järgmist koodi.
Pange tähele, et latentsusaja numbrid muutuvad sõltuvalt sisend- ja väljundmärkide arvust. Juurutusprotsess jääb aga samaks, välja arvatud keskkonnamuutujad MAX_INPUT_TOKENS ja MAX_TOTAL_TOKENS. Siin on need keskkonnamuutujad seatud tagama lõpp-punkti latentsusnõudeid, kuna suuremad sisendjärjestused võivad latentsusnõuet rikkuda. Pange tähele, et SageMaker JumpStart pakub eksemplari tüübi valimisel juba teisi optimaalseid keskkonnamuutujaid; näiteks kasutades ml.g5.12xlarge määrab SM_NUM_GPUS mudelikeskkonnas 4-le.
Maksimeerige läbilaskevõimet
Selles jaotises maksimeerime genereeritud žetoonide arvu sekundis. Tavaliselt saavutatakse see mudeli ja eksemplari tüübi maksimaalse kehtivate samaaegsete päringute korral. Järgmises tabelis kirjeldame läbilaskevõimet, mis saavutati suurima samaaegse päringu väärtusega, mis saavutati enne SageMakeri kutsumise ajalõpu ilmnemist mis tahes päringu puhul.
| Maksimaalne läbilaskevõime (märke/s), samaaegsed taotlused | |||||
| Mudeli ID | ml.g5.2xsuur | ml.g5.12xsuur | ml.g5.48xsuur | ml.p4d.24xlarge | ml.p4de.24xsuur |
| Laama 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Laama 2 7B Vestlus | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Laama 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Laama 2 13B Vestlus | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Laama 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Laama 2 70B Vestlus | - | - | 114 (16) | 1546 (256) | - |
| Mistral 7B | 947 (64) | - | - | - | - |
| Mistral 7B juhendamine | 986 (128) | - | - | - | - |
| Mixtral 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Falcon 7B | 1340 (128) | - | - | - | - |
| Falcon 7B juhendamine | 1313 (128) | - | - | - | - |
| Falcon 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Falcon 40B juhendamine | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Falcon 180B | - | - | - | - | 1100 (128) |
| Falcon 180B vestlus | - | - | - | - | 1081 (128) |
Mudeli maksimaalse läbilaskevõime saavutamiseks võite kasutada järgmist koodi.
Pange tähele, et samaaegsete päringute maksimaalne arv sõltub mudeli tüübist, eksemplari tüübist, sisendmärkide maksimaalsest arvust ja maksimaalsest väljundlubade arvust. Seetõttu peaksite need parameetrid enne seadistamist määrama MAX_CONCURRENT_REQUESTS.
Pange tähele ka seda, et latentsusaja minimeerimisest huvitatud kasutaja on sageli vastuolus läbilaskevõime maksimeerimisest huvitatud kasutajaga. Esimene on huvitatud reaalajas vastustest, samas kui teine on huvitatud paketttöötlusest, nii et lõpp-punkti järjekord on alati küllastunud, minimeerides sellega töötlemise seisakuid. Kasutajad, kes soovivad latentsusnõuetest tulenevat läbilaskevõimet maksimeerida, on sageli huvitatud latentsus-läbilaskevõime kõvera põlvest töötamisest.
Minimeerige kulud
Esimene võimalus kulude minimeerimiseks hõlmab tunnikulu minimeerimist. Selle abil saate valitud mudeli SageMakeri eksemplaris juurutada madalaima tunnikuluga. SageMakeri eksemplaride reaalajas hinnakujunduse kohta vaadake Amazon SageMakeri hinnakujundus. Üldiselt on SageMaker JumpStart LLM-ide vaikeeksemplari tüüp madalaima kuluga juurutusvalik.
Teine võimalus kulude minimeerimiseks hõlmab 1 miljoni märgi genereerimise kulude minimeerimist. See on läbilaskevõime maksimeerimiseks varem käsitletud tabeli lihtne teisendus, kus saate esmalt arvutada aja, mis kulub tundides 1 miljoni märgi genereerimiseks (1e6 / läbilaskevõime / 3600). Seejärel saate selle aja korrutada, et genereerida määratud SageMakeri eksemplari tunnihinnaga 1 miljon märki.
Pange tähele, et väikseima tunnikuluga eksemplarid ei ole samad, mis kõige madalama hinnaga 1 miljoni märgi genereerimiseks. Näiteks kui kutsumistaotlused on juhuslikud, võib madalaima tunnikuluga eksemplar olla optimaalne, samas kui piiramisstsenaariumide korral võib miljoni märgi genereerimise madalaim kulu olla sobivam.
Tensori paralleel vs. mitme mudeli kompromiss
Kõigis varasemates analüüsides kaalusime ühe mudeli koopia juurutamist, mille tensori paralleelaste on võrdne juurutuseksemplari tüübi GPU-de arvuga. See on SageMakeri JumpStarti vaikekäitumine. Kuid nagu eelnevalt märgitud, võib mudeli jagamine parandada mudeli latentsust ja läbilaskevõimet ainult teatud piirini, millest ületamisel domineerivad arvutusajal seadmetevahelised sidenõuded. See tähendab, et sageli on kasulik juurutada mitu madalama tensori paralleelastmega mudelit ühele eksemplarile, mitte ühele kõrgema tensori paralleelastmega mudelile.
Siin juurutame Llama 2 7B ja 13B lõpp-punktid ml.p4d.24xlarge eksemplaridel, mille tensori paralleelsed (TP) kraadid on 1, 2, 4 ja 8. Mudeli käitumise selguse huvides laadivad kõik need lõpp-punktid ainult ühe mudeli.
| . | Läbilaskevõime (märke/s) | Latentsus (ms/märk) | ||||||||||||||||||
| Samaaegsed taotlused | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| TP kraad | Laama 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Laama 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Meie varasemad analüüsid näitasid juba ml.p4d.24xlarge eksemplaride puhul olulisi läbilaskevõime eeliseid, mis tähendab sageli paremat jõudlust kulude osas, et genereerida g1 eksemplariperekonnaga võrreldes suure samaaegse päringu laadimistingimuste korral miljon luba. See analüüs näitab selgelt, et peaksite kaaluma kompromissi mudeli jagamise ja mudeli replikatsiooni vahel ühes eksemplaris; see tähendab, et täielikult killustatud mudel ei ole tavaliselt parim ml.p5d.4xlarge arvutusressursside kasutamine 24B ja 7B mudeliperekondade jaoks. Tegelikult saate 13B mudeliperekonna puhul parima läbilaskevõime ühe mudeli koopia jaoks, mille tensori paralleelaste on 7, mitte 4.
Siit saate ekstrapoleerida, et 7B mudeli suurim läbilaskevõime konfiguratsioon hõlmab tensori paralleelastet 1 kaheksa mudeli koopiaga ja 13B mudeli suurim läbilaskevõime konfiguratsioon on tõenäoliselt tensori paralleelaste 2 nelja mudeli koopiaga. Lisateavet selle kohta, kuidas seda teha, leiate artiklist Amazon SageMakeri uusimate funktsioonide abil vähendage mudeli juurutamise kulusid keskmiselt 50%., mis demonstreerib järelduskomponendipõhiste lõpp-punktide kasutamist. Koormuse tasakaalustamise tehnikate, serveri marsruutimise ja protsessori ressursside jagamise tõttu ei pruugi te täielikult saavutada läbilaskevõime täiustusi, mis on täpselt võrdne koopiate arvu ja ühe koopia läbilaskevõimega.
Horisontaalne skaleerimine
Nagu varem märgitud, on igal lõpp-punkti juurutamisel samaaegsete päringute arvu piirang, mis sõltub sisend- ja väljundlubade arvust ning eksemplari tüübist. Kui see ei vasta teie läbilaskevõime või samaaegse taotluse nõudele, saate seda suurendada, et kasutada juurutatud lõpp-punkti taga rohkem kui ühte eksemplari. SageMaker teostab automaatselt eksemplaride vahel päringute koormuse tasakaalustamise. Näiteks järgmine kood juurutab lõpp-punkti, mida toetab kolm eksemplari:
Järgmises tabelis on näidatud läbilaskevõime suurenemine mudeli Llama 2 7B eksemplaride arvu tegurina.
| . | . | Läbilaskevõime (märke/s) | Latentsus (ms/märk) | ||||||||||||||
| . | Samaaegsed taotlused | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Eksemplaride arv | Juhtumi tüüp | Märkide arv kokku: 512, väljundmärkide arv: 256 | |||||||||||||||
| 1 | ml.g5.2xsuur | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xsuur | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xsuur | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Eelkõige nihkub latentsus- ja läbilaskevõime kõvera põlv paremale, kuna suurem eksemplaride arv suudab käsitleda suuremat arvu samaaegseid taotlusi mitme eksemplari lõpp-punktis. Selle tabeli puhul kehtib samaaegse päringu väärtus kogu lõpp-punkti kohta, mitte iga üksiku eksemplari samaaegsete päringute arv.
Saate kasutada ka automaatset skaleerimist – funktsiooni, mis võimaldab jälgida oma töökoormust ja dünaamiliselt reguleerida võimsust, et säilitada ühtlane ja prognoositav jõudlus võimalikult madalate kuludega. See ei kuulu selle postituse ulatusse. Automaatse skaleerimise kohta lisateabe saamiseks vaadake Automaatse skaleerimise järelduste lõpp-punktide konfigureerimine rakenduses Amazon SageMaker.
Kutsuge lõpp-punkt samaaegsete päringutega
Oletame, et teil on suur hulk päringuid, mida soovite kasutada suure läbilaskevõime tingimustes juurutatud mudelist vastuste genereerimiseks. Näiteks järgmises koodiplokis koostame loendi 1,000 kasulikust koormast, kusjuures iga kasulik koormus nõuab 100 märgi genereerimist. Kokku taotleme 100,000 XNUMX märgi loomist.
Kui saadate SageMakeri käitusaegsele API-le suure hulga taotlusi, võib teil esineda tõrkeid. Selle leevendamiseks saate luua kohandatud SageMakeri käitusaja kliendi, mis suurendab korduskatsete arvu. Saate tulemuseks oleva SageMakeri seansiobjekti anda mõlemale JumpStartModel konstruktor või sagemaker.predictor.retrieve_default kui soovite juba juurutatud lõpp-punktile lisada uue ennustaja. Järgmises koodis kasutame seda seansiobjekti Llama 2 mudeli juurutamisel SageMaker JumpStart vaikekonfiguratsioonidega:
Sellel juurutatud lõpp-punktil on MAX_CONCURRENT_REQUESTS = 128 algselt. Järgmises plokis kasutame samaaegset futuuriteeki, et itereerida kõigi 128 töötaja lõimega kasulike koormuste lõpp-punkti. Lõpp-punkt töötleb maksimaalselt 128 samaaegset päringut ja kui päring tagastab vastuse, saadab täitja lõpp-punktile kohe uue päringu.
Selle tulemusel genereeritakse ühel ml.g100,000xsuurel eksemplaril kokku 1255 5.2 žetoonit läbilaskevõimega 80 märki sekundis. Selle töötlemiseks kulub umbes XNUMX sekundit.
Pange tähele, et see läbilaskevõime väärtus erineb oluliselt selle postituse eelmistes tabelites olevast Llama 2 7B maksimaalsest läbilaskevõimest (5.2 märki sekundis 486 samaaegse päringu korral) ml.g64xlarge. Selle põhjuseks on asjaolu, et sisendkoormus kasutab 8 asemel 256 märki, väljundmärkide arv on 100 asemel 256 ja väiksem lubade arv võimaldab 128 samaaegset taotlust. See on viimane meeldetuletus, et kõik latentsus- ja läbilaskevõime numbrid sõltuvad kasulikust koormusest! Kasuliku koormuse lubade arvu muutmine mõjutab mudelite esitamise ajal partiiprotsesse, mis omakorda mõjutab teie rakenduse tekkivat eeltäitmist, dekodeerimist ja järjekorda.
Järeldus
Selles postituses tutvustasime SageMaker JumpStart LLM-ide, sealhulgas Llama 2, Mistral ja Falcon, võrdlusuuringuid. Esitasime ka juhendi lõpp-punkti juurutamise konfiguratsiooni latentsuse, läbilaskevõime ja kulude optimeerimiseks. Saate alustada, käivitades rakenduse seotud märkmik oma kasutusjuhtumi võrdlemiseks.
Autoritest
 Dr Kyle Ulrich on Amazon SageMaker JumpStart meeskonna rakendusteadlane. Tema uurimishuvide hulka kuuluvad skaleeritavad masinõppe algoritmid, arvutinägemine, aegridad, Bayesi mitteparameetrid ja Gaussi protsessid. Tema doktorikraad on pärit Duke'i ülikoolist ja ta on avaldanud töid NeurIPSis, Cell ja Neuron.
Dr Kyle Ulrich on Amazon SageMaker JumpStart meeskonna rakendusteadlane. Tema uurimishuvide hulka kuuluvad skaleeritavad masinõppe algoritmid, arvutinägemine, aegridad, Bayesi mitteparameetrid ja Gaussi protsessid. Tema doktorikraad on pärit Duke'i ülikoolist ja ta on avaldanud töid NeurIPSis, Cell ja Neuron.
 Dr. Vivek Madan on Amazon SageMaker JumpStart meeskonna rakendusteadlane. Ta sai doktorikraadi Illinoisi ülikoolist Urbana-Champaignis ja oli Georgia Techi järeldoktor. Ta on aktiivne masinõppe ja algoritmide kujundamise uurija ning avaldanud ettekandeid EMNLP, ICLR, COLT, FOCS ja SODA konverentsidel.
Dr. Vivek Madan on Amazon SageMaker JumpStart meeskonna rakendusteadlane. Ta sai doktorikraadi Illinoisi ülikoolist Urbana-Champaignis ja oli Georgia Techi järeldoktor. Ta on aktiivne masinõppe ja algoritmide kujundamise uurija ning avaldanud ettekandeid EMNLP, ICLR, COLT, FOCS ja SODA konverentsidel.
 Dr Ashish Khetan on Amazon SageMaker JumpStarti vanemrakendusteadlane ja aitab välja töötada masinõppe algoritme. Ta sai doktorikraadi Illinoisi Urbana-Champaigni ülikoolist. Ta on aktiivne masinõppe ja statistiliste järelduste uurija ning avaldanud palju artikleid NeurIPS, ICML, ICLR, JMLR, ACL ja EMNLP konverentsidel.
Dr Ashish Khetan on Amazon SageMaker JumpStarti vanemrakendusteadlane ja aitab välja töötada masinõppe algoritme. Ta sai doktorikraadi Illinoisi Urbana-Champaigni ülikoolist. Ta on aktiivne masinõppe ja statistiliste järelduste uurija ning avaldanud palju artikleid NeurIPS, ICML, ICLR, JMLR, ACL ja EMNLP konverentsidel.
 João Moura on AWS-i AI/ML-lahenduste vanemarhitekt. João aitab AWS-i klientidel – alates väikestest alustavatest ettevõtetest kuni suurte ettevõteteni – tõhusalt koolitada ja juurutada suuri mudeleid ning laiemalt luua AWS-ile ML-platvorme.
João Moura on AWS-i AI/ML-lahenduste vanemarhitekt. João aitab AWS-i klientidel – alates väikestest alustavatest ettevõtetest kuni suurte ettevõteteni – tõhusalt koolitada ja juurutada suuri mudeleid ning laiemalt luua AWS-ile ML-platvorme.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/
- :on
- :on
- :mitte
- : kus
- $ UP
- 000
- 1
- 10
- 100
- 11
- 116
- 12
- 14
- 150
- 16
- 17
- 20
- 24
- 28
- 30
- 32
- 60
- 600
- 70
- 8
- 80
- a
- A100
- Võimalik
- MEIST
- üle
- kiirendi
- kiirendid
- vastuvõtmine
- juurdepääs
- täitma
- Vastavalt
- Saavutada
- saavutada
- üle
- aktiveerimised
- aktiivne
- kohandama
- Täiendavad lisad
- Lisaks
- kohandama
- eelised
- mõjutada
- pärast
- vastu
- agregaat
- AI / ML
- algoritm
- algoritme
- viia
- Materjal: BPA ja flataatide vaba plastik
- võimaldama
- lubatud
- võimaldab
- üksi
- juba
- Ka
- Kuigi
- alati
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- summa
- an
- analüüsid
- analüüs
- ja
- Teine
- mistahes
- API
- taotlus
- rakendatud
- lähenemine
- asjakohane
- ligikaudne
- umbes
- arhitektuur
- OLEME
- AS
- seotud
- eeldused
- At
- kinnitage
- Katsed
- tähelepanu
- automaatselt
- saadaval
- keskmine
- vältima
- AWS
- b
- saldod
- tasakaalustamine
- Bandwidth
- põhineb
- Põhimõtteliselt
- partii
- Bayesi
- BE
- sest
- muutub
- enne
- käitumine
- taga
- on
- Uskuma
- võrrelda
- võrdlusuuringud
- kriteeriumid
- kasulik
- kasu
- Kasu
- BEST
- Parem
- vahel
- Peale
- Blokeerima
- Blogi
- seotud
- lai
- üldjoontes
- eelarve
- ehitama
- kuid
- by
- vahemälu
- arvutama
- arvutatud
- kutsutud
- CAN
- Saab
- võime
- Võimsus
- mütsid
- mis
- juhul
- juhtudel
- Põhjus
- rakk
- kindel
- muutma
- muutuv
- omadused
- Vali
- valitud
- selgus
- selgelt
- klient
- kood
- KOMMUNIKATSIOON
- võrdlema
- keeruline
- komponendid
- terviklik
- arvutamine
- arvutuslik
- arvutusjõud
- arvutused
- Arvutama
- arvuti
- Arvuti visioon
- konkurent
- seisund
- Tingimused
- konverentsid
- konfiguratsioon
- Arvestama
- kaaluda
- arvab
- piiranguid
- tarbitud
- sisaldab
- kontekst
- pidev
- pidevalt
- Vastav
- Maksma
- kulud
- loe
- Protsessor
- looma
- kriitiline
- toores
- Praegune
- kõver
- tava
- Kliendid
- andmed
- Otsustamine
- otsus
- dekodeerimine
- vähenema
- väheneb
- pühendunud
- vaikimisi
- määratlema
- määratletud
- Määratleb
- Kraad
- näitama
- näitab
- sõltuv
- Olenevalt
- sõltub
- juurutada
- lähetatud
- juurutamine
- kasutuselevõtu
- kasutuselevõtt
- juurutab
- sügavus
- Tuletatud
- kirjeldatud
- Disain
- soovitud
- detail
- detailid
- Määrama
- määrab
- arendama
- seade
- seadmed
- erinev
- raske
- väheneb
- arutama
- arutatud
- eristatav
- jagatud
- Ei tee
- domineerima
- Ära
- seisakuaeg
- dr
- ajam
- ajendatud
- sõidu
- kaks
- Hertsog
- hertsogi ülikool
- ajal
- dünaamiliselt
- iga
- Ajalugu
- tõhusalt
- tõhusalt
- kaheksa
- kumbki
- hõlmab
- kohtumine
- Lõpuks-lõpuni
- Lõpp-punkt
- lõpp-punktid
- lõppeb
- piisavalt
- sisene
- ettevõtete
- Kogu
- keskkond
- võrdne
- Võrdub
- viga
- vead
- eriti
- hinnata
- Eeter (ETH)
- Isegi
- lõpuks
- Iga
- täpselt
- näide
- ületanud
- Välja arvatud
- näitama
- olemas
- kallis
- kogemus
- kogenud
- selgitus
- uurima
- uurib
- väljend
- asjaolu
- faktor
- tegurid
- FAIL
- pistrik
- peredele
- pere
- teostatav
- tunnusjoon
- FUNKTSIOONID
- vähe
- Joonis
- lõplik
- Lõpuks
- leidma
- leidmine
- esimene
- sobima
- Keskenduma
- keskendub
- Järel
- eest
- endine
- valem
- edasi
- Sihtasutus
- neli
- Alates
- täis
- täielikult
- põhimõtteliselt
- edasi
- Pealegi
- Futuurid
- kasu
- Kasum
- Üldine
- tekitama
- loodud
- genereerib
- teeniva
- põlvkond
- Georgia
- saama
- antud
- Eesmärgid
- hea
- sain
- GPU
- GPU
- suurem
- Kasvab
- Kasv
- garantii
- valvur
- suunata
- käepide
- riistvara
- Olema
- he
- pea
- tugevalt
- aitama
- aitab
- siin
- Suur
- kõrgetasemeline
- rohkem
- kõrgeim
- tema
- hoidma
- Horisontaalne
- tund
- Lahtiolekuajad
- Kuidas
- Kuidas
- aga
- HTTPS
- i
- ICLR
- ID
- ideaalne
- ideaalis
- identifitseerima
- if
- Illinois
- kohe
- mõju
- Mõjud
- import
- oluline
- tähtsam
- parandama
- paranemine
- parandusi
- parandab
- in
- sisaldama
- lisatud
- Kaasa arvatud
- kaasamine
- Sissetulev
- Suurendama
- kasvanud
- Tõstab
- kasvav
- eraldi
- sisend
- sisendite
- Näiteks
- juhtumid
- selle asemel
- huvitatud
- el
- Kesktaseme
- sisse
- hõlmab
- IT
- ITS
- jpg
- õigustatud
- võtmed
- Laps
- Kyle
- keel
- suur
- Suured ettevõtted
- suurem
- suurim
- Hilinemine
- pärast
- hiljemalt
- kiht
- viima
- Õppida
- õppimine
- jätmine
- lahkus
- Pikkus
- Raamatukogu
- elu
- nagu
- Tõenäoliselt
- LIMIT
- piiramine
- piiratud
- piirid
- joon
- nimekiri
- Laama
- koormus
- laadimine
- liising
- enam
- Vaata
- Madal
- vähendada
- madalaim
- masin
- masinõpe
- tehtud
- säilitada
- tegema
- palju
- Maksimeerima
- maksimeerib
- maksimeerimine
- maksimaalne
- mai..
- tähendus
- vahendid
- mõõdud
- mehhanism
- mehhanismid
- Vastama
- Mälu
- mainitud
- mõdu
- meetodid
- võib
- miljon
- minimeerima
- minimeerimine
- miinimum
- alaealine
- protokoll
- Leevendada
- ML
- viis
- mudel
- mudelid
- Kaasaegne
- Jälgida
- rohkem
- kõige
- mitmekordne
- peab
- loodus
- tingimata
- vajalik
- Vajadus
- NeurIPS
- Uus
- järgmine
- ei
- eelkõige
- meeles
- märkida
- number
- numbrid
- objekt
- märkused
- jälgima
- vaadeldud
- saama
- Ilmne
- esineda
- esineb
- Ennustus
- of
- sageli
- on
- ONE
- ainult
- tegutsevad
- töö
- Operations
- optimaalselt
- optimeerima
- valik
- or
- et
- Muu
- teised
- muidu
- meie
- väljund
- üle
- dokumendid
- Parallel
- parameeter
- parameetrid
- eriline
- sooritama
- möödub
- mustrid
- paus
- kohta
- täitma
- jõudlus
- täidab
- phd
- nähtus
- Platvormid
- Platon
- Platoni andmete intelligentsus
- PlatoData
- pluss
- Punkt
- vaene
- asustatud
- võimalik
- post
- võim
- Praktiline
- eelnev
- täpselt
- ennustada
- ennustatav
- ennustus
- Predictor
- eelistama
- esitatud
- vältida
- eelmine
- varem
- hind
- hinnapoliitika
- esmane
- põhimõtted
- Prioriteet
- protsess
- töödeldud
- Protsessid
- töötlemine
- tootma
- kaitsma
- anda
- tingimusel
- annab
- avalikult
- avaldatud
- eesmärk
- päringud
- tõstma
- Rates
- pigem
- suhe
- jõudma
- reaalne
- päris elu
- reaalajas
- põhjus
- saab
- soovitama
- soovitused
- vähendama
- vähendab
- viitama
- nimetatud
- kord
- režiimid
- suhe
- Suhted
- jääma
- ülejäänud
- jäänused
- meeldetuletus
- korduv
- vastus
- replikatsioon
- aru
- esindama
- taotleda
- taotledes
- Taotlusi
- nõudma
- nõutav
- nõue
- Nõuded
- Vajab
- teadustöö
- uurija
- ressurss
- Vahendid
- suhtes
- vastus
- vastuste
- tulemuseks
- Tulemused
- Tulu
- õige
- Marsruutimine
- ROW
- Eeskiri
- jooks
- jooksmine
- salveitegija
- sama
- skaalautuvia
- Skaala
- ketendamine
- stsenaarium
- stsenaariumid
- teadlane
- ulatus
- Teine
- sekundit
- Osa
- lõigud
- vaata
- nähtud
- valima
- väljavalitud
- valides
- valik
- saatma
- saatmine
- vanem
- tunne
- Saadetud
- eri
- Jada
- Seeria
- serveeritud
- server
- serverid
- Teenused
- teenindavad
- istung
- komplekt
- kehtestamine
- kildudeks
- varitsus
- Jaga
- jagamine
- Vahetused
- peaks
- näitas
- Näitused
- märkimisväärne
- märgatavalt
- sarnane
- lihtne
- üheaegselt
- ühekordne
- SUURUS
- väike
- väiksem
- So
- tarkvara
- Lahendused
- mõned
- allikas
- spetsialist
- konkreetse
- spetsifikatsioonid
- määratletud
- specs
- kiirus
- jagada
- juhuslik
- standard
- algus
- alustatud
- algab
- Alustavatel
- statistiline
- stabiilne
- Samm
- Sammud
- Veel
- Peatus
- Uuring
- järgnev
- mahukas
- selline
- sobiv
- toetama
- Toetatud
- süsteem
- tabel
- kohandamine
- Võtma
- Takeaways
- võtab
- meeskond
- tech
- tehnikat
- kipuvad
- termin
- tingimused
- test
- kui
- et
- .
- Allikas
- oma
- SIIS
- teoreetiline
- teooria
- Seal.
- sellega
- seetõttu
- Need
- nad
- asjad
- see
- need
- kolm
- Läbi
- läbilaskevõime
- aeg
- Ajaseeria
- korda
- et
- kokku
- sümboolne
- märgid
- liiga
- Summa
- tp
- jälgida
- Rong
- üle
- ülekandeid
- Transformation
- trafo
- tõsi
- Pöörake
- kaks
- tüüp
- liigid
- tüüpiliselt
- all
- mõistma
- mõistmine
- Ülikool
- Kasutus
- kasutama
- kasutage juhtumit
- Kasutatud
- Kasutaja
- User Experience
- Kasutajad
- kasutusalad
- kasutamine
- ära kasutama
- kehtiv
- väärtus
- Väärtused
- variatsioonid
- sort
- kontrollima
- mitmekülgne
- väga
- kaudu
- nägemus
- vs
- ootama
- tahan
- soe
- oli
- Tee..
- kuidas
- we
- web
- veebiteenused
- Hästi
- olid
- M
- Mis on
- millal
- millal iganes
- samas kui
- mis
- kuigi
- WHO
- will
- koos
- jooksul
- ilma
- Töö
- töötaja
- oleks
- veel
- saagikus
- sa
- Sinu
- sephyrnet