Organisatsioonid üle kogu maailma – nii kasumit teenivad kui ka mittetulunduslikud – otsivad andmeanalüüsi võimendamist äritegevuse parandamiseks. Leiud a McKinsey uuring näitavad, et andmepõhised organisatsioonid omandavad kliente 23 korda tõenäolisemalt, säilitavad kuus korda tõenäolisemalt kliente ja on 19 korda kasumlikumad [1]. MIT-i uuring leidis, et digitaalselt küpsed ettevõtted on 26% kasumlikumad kui nende eakaaslased [2]. Kuid vaatamata andmerikkale ettevõttele on paljudel ettevõtetel raskusi andmeanalüütika rakendamisega ärivajaduste, olemasolevate võimaluste ja ressursside vastuoluliste prioriteetide tõttu. Gartneri uurimus leidis, et üle 85% andme- ja analüüsiprojektidest ebaõnnestub [3] ja a ühise aruande IBM ja Carnegie Melon näitavad, et 90% organisatsiooni andmetest ei kasutata kunagi edukalt ühelgi strateegilisel eesmärgil [4].
Selle taustaga tutvustame "andmeanalüütika struktuuri (DAF)" kontseptsiooni kui ökosüsteemi või struktuuri, mis võimaldab andmeanalüütika tõhusalt toimida, tuginedes (a) ärivajadustele või eesmärkidele, (b) olemasolevatele võimalustele, nagu inimesed/oskused. , protsessid, kultuur, tehnoloogiad, arusaamad, otsustuspädevused ja palju muud ning (c) ressursid (st komponendid, mida ettevõte vajab ettevõtte toimimiseks).
Meie peamine eesmärk andmeanalüütika struktuuri juurutamisel on vastata sellele põhiküsimusele: „Mida on vaja, et tõhusalt üles ehitada otsuste tegemise süsteem andmed Science algoritme ettevõtte tulemuslikkuse mõõtmiseks ja parandamiseks? Andmeanalüütika kangast ja selle viit peamist ilmingut näidatakse ja arutatakse allpool.
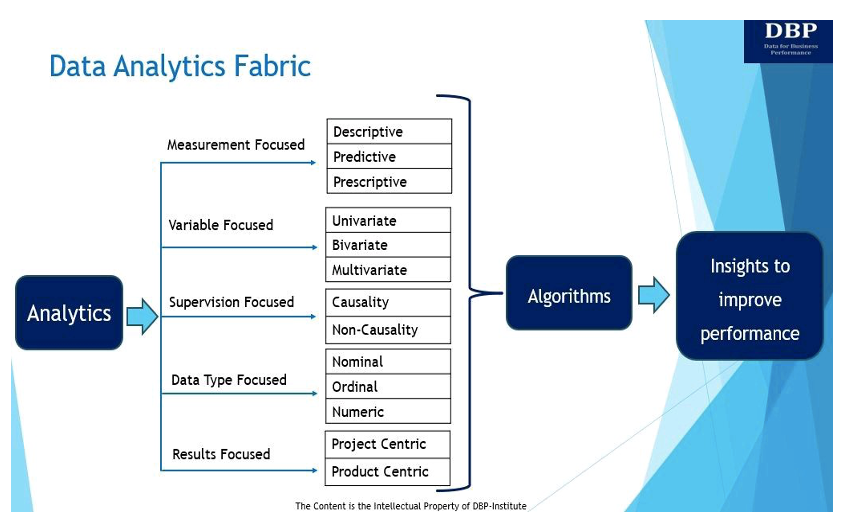
1. Mõõtmisele keskendunud
Analüütika põhiolemus seisneb andmete kasutamises, et saada teadmisi, mõõta ja parandada äritegevuse tulemuslikkust [5]. Ettevõtte toimivuse mõõtmiseks ja parandamiseks on kolm peamist tüüpi analüütikat:
- Kirjeldav analüüs küsib: "Mis juhtus?" Kirjeldavat analüütikat kasutatakse ajalooliste andmete analüüsimiseks, et tuvastada mustreid, suundumusi ja seoseid, kasutades uurimuslikke, assotsiatiivseid ja järelduslikke andmeanalüüsi meetodeid. Uurimusliku andmeanalüüsi tehnikad analüüsivad ja võtavad kokku andmekogumeid. Assotsiatiivne kirjeldav analüüs selgitab muutujate vahelisi seoseid. Järelduslikku kirjeldavat andmeanalüüsi kasutatakse näidisandmekogumi põhjal suurema populatsiooni trendide järeldamiseks või järelduste tegemiseks.
- Ennustav analüüs vaatab vastust küsimusele "Mis juhtub?" Põhimõtteliselt on ennustav analüütika protsess, mille käigus kasutatakse andmeid tulevaste suundumuste ja sündmuste prognoosimiseks. Ennustavat analüüsi saab läbi viia käsitsi (üldtuntud kui analüütikute juhitud ennustav analüütika) või kasutades masinõppe algoritmid (tuntud ka kui andmepõhine ennustav analüütika). Mõlemal juhul kasutatakse ajaloolisi andmeid tulevikuprognooside tegemiseks.
- Ettekirjutusanalüüs aitab vastata küsimusele "Kuidas me saame selle teoks teha?" Põhimõtteliselt soovitab ettekirjutav analüütika optimeerimis- ja simulatsioonitehnikate abil edasiliikumiseks parimat tegevussuunda. Tavaliselt käivad ennustav analüüs ja ettekirjutav analüüs koos, sest ennustav analüüs aitab leida potentsiaalseid tulemusi, samas kui ettekirjutav analüüs vaatab neid tulemusi ja leiab rohkem võimalusi.
2. Muutuv-keskne
Andmeid saab analüüsida ka saadaolevate muutujate arvu põhjal. Sellega seoses võivad andmeanalüüsi tehnikad muutujate arvu põhjal olla ühe-, kahe- või mitmemõõtmelised.
- Ühemõõtmeline analüüs: Ühemõõtmeline analüüs hõlmab ühes muutujas esineva mustri analüüsimist, kasutades tsentraalsuse (keskmine, mediaan, moodus jne) ja variatsiooni (standardhälve, standardviga, dispersioon ja nii edasi) mõõte.
- Kahe muutuja analüüs: On kaks muutujat, mille puhul analüüs on seotud põhjuse ja kahe muutuja vahelise seosega. Need kaks muutujat võivad olla üksteisest sõltuvad või sõltumatud. Korrelatsioonitehnika on enimkasutatav kahemõõtmelise analüüsi tehnika.
- Mitme muutujaga analüüs: Seda tehnikat kasutatakse enam kui kahe muutuja analüüsimiseks. Mitme muutujaga seadistuses töötame tavaliselt ennustava analüütika areenil ja enamikku tuntud masinõppe (ML) algoritme, nagu lineaarne regressioon, logistiline regressioon, regressioonipuud, tugivektori masinad ja närvivõrgud, rakendatakse tavaliselt mitme muutujaga. seadistus.
3. Supervisioonile keskendunud
Kolmandat tüüpi andmeanalüütika kangas tegeleb konkreetse väljundi (st sõltuva muutuja) jaoks märgistatud sisendandmete või sõltumatu muutuja andmete koolitamisega. Põhimõtteliselt on sõltumatu muutuja see, mida katsetaja kontrollib. Sõltuv muutuja on muutuja, mis muutub vastuseks sõltumatule muutujale. Järelevalvele keskendunud DAF võib olla üks kahest tüübist.
- Põhjuslik seos: Märgistatud andmed, mis on loodud automaatselt või käsitsi, on juhendatud õppimise jaoks hädavajalikud. Märgistatud andmed võimaldavad selgelt määratleda sõltuva muutuja ja seejärel on ennustava analüütika algoritmi ülesanne luua AI/ML tööriist, mis looks seose sildi (sõltuv muutuja) ja sõltumatute muutujate komplekti vahel. Asjaolu, et sõltuva muutuja mõiste ja sõltumatute muutujate hulk on selgelt eristatavad, lubame endal seose kõige paremaks selgitamiseks kasutusele võtta termini "põhjuslikkus".
- Mittepõhjuslik seos: Kui me märgime oma mõõtmena "järelevalvele keskendunud", peame silmas ka "supervisiooni puudumist" ja see toob arutelusse mittepõhjuslikud mudelid. Mainimist väärivad mittepõhjuslikud mudelid, kuna need ei vaja märgistatud andmeid. Põhitehnika on siin klasterdamine ja kõige populaarsemad meetodid on k-Means ja Hierarchical Clustering.
4. Andmetüübile keskenduv
See andmeanalüütika struktuuri mõõde või manifestatsioon keskendub kolmele erinevat tüüpi andmemuutujatele, mis on seotud nii sõltumatute kui ka sõltuvate muutujatega, mida kasutatakse andmeanalüütika tehnikates arusaamade saamiseks.
- Nominaalsed andmed kasutatakse andmete märgistamiseks või kategoriseerimiseks. See ei sisalda arvväärtust ja seetõttu pole nominaalandmetega statistilisi arvutusi võimalik teha. Nominaalseteks andmeteks on näiteks sugu, tootekirjeldus, kliendi aadress jms.
- Järjekorralised või järjestatud andmed on väärtuste järjekord, kuid erinevused nende vahel pole tegelikult teada. Levinud näideteks on ettevõtete järjestamine turukapitalisatsiooni, hankija maksetingimuste, klientide rahulolu skooride, tarneprioriteedi jms alusel.
- Numbrilised andmed ei vaja tutvustamist ja on numbrilise väärtusega. Need muutujad on kõige põhilisemad andmetüübid, mida saab kasutada igat tüüpi algoritmide modelleerimiseks.
5. Tulemustele keskendumine
Seda tüüpi andmeanalüütikakangas vaadeldakse viise, kuidas analüütikast saadud arusaamade põhjal äriväärtust pakkuda. Äriväärtust saab analüütika juhtida kahel viisil ja need on toodete või projektide kaudu. Kuigi toodetel võib olla vaja käsitleda kasutajakogemuse ja tarkvaratehnikaga seotud täiendavaid tagajärgi, on mudeli tuletamiseks tehtud modelleerimine nii projektis kui ka tootes sarnane.
- A andmeanalüütika toode on korduvkasutatav andmevara, mis teenindab ettevõtte pikaajalisi vajadusi. See kogub andmeid asjakohastest andmeallikatest, tagab andmete kvaliteedi, töötleb neid ja teeb need kättesaadavaks kõigile, kes neid vajavad. Tooted on tavaliselt mõeldud isikutele ja neil on mitu elutsükli etappi või iteratsiooni, mille käigus toote väärtus realiseerub.
- A andmeanalüüsi projekt on loodud konkreetse või ainulaadse ärivajaduse rahuldamiseks ja sellel on määratletud või kitsas kasutajaskond või eesmärk. Põhimõtteliselt on projekt ajutine ettevõtmine, mille eesmärk on pakkuda lahendust kindlaksmääratud ulatuses, eelarve piires ja õigeaegselt.
Maailma majandus muutub lähiaastatel dramaatiliselt, kuna organisatsioonid kasutavad üha enam andmeid ja analüütikat, et saada teadmisi ja teha otsuseid äritegevuse tulemuslikkuse mõõtmiseks ja parandamiseks. McKinsey avastas, et ettevõtted, mis põhinevad arusaamadel, näitavad EBITDA (kasum enne intressi, makse, amortisatsiooni ja amortisatsiooni) kasvu kuni 25% [5]. Paljud organisatsioonid ei ole aga edukad andmete ja analüütika võimendamisel äritulemuste parandamiseks. Kuid andmeanalüütika edastamiseks pole ühtset standardset viisi või lähenemisviisi. Andmeanalüüsi lahenduste juurutamine või juurutamine sõltub ärieesmärkidest, võimalustest ja ressurssidest. DAF ja selle viis siin käsitletud ilmingut võimaldavad analüütikat tõhusalt kasutusele võtta, lähtudes ettevõtte vajadustest, olemasolevatest võimalustest ja ressurssidest.
viited
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-morre-referable-than-their-their-peers/
- gartner.com/et/newsroom/press-releases/2018-02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- Southekal, Prashanth, „Analüütika parimad tavad”, Technics, 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Autod/elektrisõidukid, Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- ChartPrime. Tõsta oma kauplemismängu ChartPrime'iga kõrgemale. Juurdepääs siia.
- BlockOffsets. Keskkonnakompensatsiooni omandi ajakohastamine. Juurdepääs siia.
- Allikas: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- :on
- :on
- :mitte
- $ UP
- 1
- 19
- 23
- a
- MEIST
- juurdepääsetav
- omandama
- tegevus
- Täiendavad lisad
- aadress
- AI / ML
- algoritm
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- võimaldama
- võimaldab
- Ka
- amortisatsioon
- an
- analüüs
- analytics
- analüüsima
- analüüsitud
- analüüsides
- ja
- vastus
- mistahes
- keegi
- rakendatud
- lähenemine
- OLEME
- areen
- ümber
- AS
- eelis
- At
- automaatselt
- saadaval
- b
- taustaks
- baas
- põhineb
- põhiline
- Põhimõtteliselt
- BE
- sest
- olnud
- enne
- on
- alla
- BEST
- vahel
- mõlemad
- Toob
- eelarve
- ehitama
- äri
- äritegevus
- kuid
- by
- CAN
- võimeid
- Kapitaliseerimine
- kategoriseerimine
- Põhjus
- Keskus
- Vaidluste lahendamine
- selgelt
- Klastrite loomine
- kogub
- COM
- tulevad
- ühine
- tavaliselt
- Ettevõtted
- komponendid
- mõiste
- lõpetama
- läbi
- Vastuoluline
- kontrolli
- tuum
- Korrelatsioon
- võiks
- kursus
- kultuur
- klient
- Kliendi rahulolu
- Kliendid
- andmed
- andmete analüüs
- Andmete analüüs
- andmete kvaliteedi
- andmekogum
- andmekogumid
- andmepõhistele
- ANDMED
- Pakkumised
- Otsuse tegemine
- otsused
- määratlema
- määratletud
- tarnima
- esitatud
- tarne
- sõltuv
- sõltub
- lähetatud
- kasutuselevõtu
- Amortisatsioon
- Tuletatud
- kirjeldus
- väärivad
- kavandatud
- Vaatamata
- kõrvalekalle
- erinevused
- erinev
- digitaalselt
- mõõde
- arutatud
- arutelu
- eristatav
- do
- ei
- tehtud
- dramaatiliselt
- ajendatud
- kaks
- e
- iga
- Töötasu
- EBITDA
- majandus
- ökosüsteemi
- tõhusalt
- kumbki
- võimaldama
- võimaldab
- püüdma
- Inseneriteadus
- tagab
- viga
- oluline
- sündmused
- näited
- Teostama
- kogemus
- Selgitama
- Selgitab
- Uurimisandmete analüüs
- kangas
- asjaolu
- FAIL
- leidma
- järeldused
- leiab
- ettevõtetele
- viis
- keskendub
- eest
- Forbes
- Ennustus
- edasi
- avastatud
- Alates
- funktsioon
- põhiline
- tulevik
- Gartner
- SUGU
- loodud
- Go
- eesmärk
- juhtuda
- juhtus
- Olema
- aitab
- sellest tulenevalt
- siin
- ajalooline
- aga
- HTTPS
- i
- IBM
- identifitseerima
- rakendada
- täitmine
- parandama
- paranenud
- Paranemist
- in
- Tõstab
- üha rohkem
- sõltumatud
- näitama
- sisend
- teadmisi
- ette nähtud
- huvi
- kehtestama
- sisse
- Sissejuhatus
- kaasama
- hõlmab
- IT
- kordused
- ITS
- Võti
- teatud
- silt
- märgistamine
- suurem
- õppimine
- võimendav
- eluring
- nagu
- Tõenäoliselt
- pikaajaline
- otsin
- välimus
- masin
- masinõpe
- masinad
- põhiline
- tegema
- TEEB
- käsitsi
- palju
- Turg
- Turukapitalisatsioon
- küsimus
- küps
- max laiuse
- mai..
- McKinsey
- keskmine
- mõõtma
- meetmed
- mainima
- meetodid
- MIT
- ML
- viis
- mudel
- modelleerimine
- mudelid
- rohkem
- kõige
- Populaarseim
- liikuv
- mitmekordne
- Vajadus
- vajadustele
- võrgustikud
- Neural
- närvivõrgud
- mitte kunagi
- ei
- Mittetulundusühing
- Mõiste
- number
- eesmärgid
- of
- on
- ONE
- töötama
- optimeerimine
- Valikud
- or
- et
- organisatsioon
- organisatsioonid
- Muu
- meie
- ise
- tulemusi
- väljund
- üle
- eriline
- Muster
- mustrid
- makse
- jõudlus
- Platon
- Platoni andmete intelligentsus
- PlatoData
- populaarne
- rahvastik
- võimalik
- potentsiaal
- Ennustused
- ennustav
- Ennustav analüüs
- Ennustav analüüs
- esitada
- esmane
- prioriteet
- protsess
- Protsessid
- Toode
- Toodet
- Kasum
- tulutoov
- projekt
- projektid
- eesmärk
- kvaliteet
- küsimus
- tagajärjed
- reastatud
- Edetabel
- realiseeritud
- tõesti
- soovitab
- pidama
- regressioon
- seotud
- suhe
- Suhted
- asjakohane
- aru
- nõudma
- nõutav
- Vahendid
- vastus
- säilitama
- korduvkasutatav
- rahulolu
- ulatus
- hinded
- teenima
- komplekt
- Komplektid
- kehtestamine
- näidatud
- Näitused
- sarnane
- simuleerimine
- ühekordne
- SIX
- So
- tarkvara
- tarkvaraarendus
- lahendus
- Lahendused
- allikas
- Allikad
- etappidel
- standard
- statistiline
- Strateegiline
- struktuur
- võitlus
- edukas
- Edukalt
- selline
- Kokku võtta
- juhendatud õppimine
- järelevalve
- toetama
- süsteem
- Maksud
- tehnikat
- Tehnoloogiad
- ajutine
- termin
- tingimused
- kui
- et
- .
- maailm
- oma
- SIIS
- Seal.
- Need
- nad
- Kolmas
- see
- need
- kolm
- Läbi
- aeg
- korda
- et
- kokku
- tööriist
- koolitus
- Muutma
- Puud
- Trends
- kaks
- tüüp
- liigid
- tüüpiliselt
- ainulaadne
- kasutama
- Kasutatud
- Kasutaja
- User Experience
- kasutamine
- väärtus
- Väärtused
- muutuja
- müüja
- Tee..
- kuidas
- we
- hästi tuntud
- millal
- kas
- mis
- kuigi
- WHO
- will
- koos
- jooksul
- maailm
- maailma
- oleks
- aastat
- sephyrnet