Sissejuhatus tabeli väljavõtmisse
Kogutavate andmete hulk kasvab iga päevaga drastiliselt, kuna rakenduste, tarkvara ja veebiplatvormide arv kasvab.
Nende tohutute andmete tõhusaks käsitlemiseks/juurdepääsuks on vaja välja töötada väärtuslikud teabe hankimise tööriistad.
Üks alamvaldkondi, mis väljal Teabe väljavõtmine nõuab tähelepanu, on tabelite eraldamine piltidest või tabeliandmete tuvastamine vormidest, PDF-idest ja dokumentidest.
Tabeli ekstraheerimine on dokumendis tabeliteabe tuvastamise ja dekomponeerimise ülesanne.

Kujutage ette, et teil on palju tabeliandmetega dokumente, mida peate edasiseks töötlemiseks välja võtma. Tavaliselt saate neid käsitsi kopeerida (paberile) või laadida Exceli lehtedele.
Tabeli OCR-tarkvara abil saate tabeleid automaatselt tuvastada ja dokumentidest ühe korraga eraldada kõik tabeliandmed. See säästab palju aega ja ümbertöötamist.
Selles artiklis vaatleme esmalt, kuidas Nanonets saab piltidest või dokumentidest automaatselt tabeleid eraldada. Seejärel käsitleme mõnda populaarset DL-tehnikat dokumentides tabelite tuvastamiseks ja eraldamiseks.
Kas soovite arvetelt, kviitungitelt või mis tahes muud tüüpi dokumentidelt tabeliandmeid välja võtta? Vaadake Nanonetsi PDF tabeli ekstraktor tabeliandmete eraldamiseks. Ajakava demo automatiseerimise kohta lisateabe saamiseks laua väljatõmbamine.
Sisukord
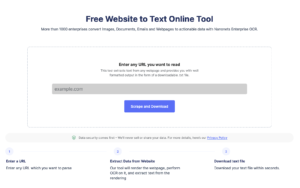
Ekstraktige tabel pildist koos Nanonets Table OCR-iga
-
Registreeri tasuta Nanonetsi konto jaoks
- Laadige pildid/failid üles Nanonets Table OCR-mudelisse
- Nanonets tuvastab ja ekstraheerib automaatselt kõik tabeliandmed
- Muutke ja vaadake andmeid (vajadusel)
- Eksportige töödeldud andmed Exceli, csv- või JSON-vormingus
Tahad kraapige andmed PDF-ist dokumendid, teisendada PDF-tabel Excelisse or automatiseerida tabeli väljavõtmist? Uuri välja kuidas Nanonets PDF-kaabits or PDF-i parser võib teie ettevõtet tootlikumaks muuta.
Nanonets Table OCR API

. Nanonets OCR API võimaldab hõlpsasti luua OCR-mudeleid. OCR-mudeli täpsuse suurendamiseks ei pea te muretsema oma piltide eeltöötlemise pärast ega muretsema mallide sobitamise pärast või reeglipõhiseid mootoreid ehitama.
Saate oma andmed üles laadida, märkmeid teha, mudelit treenima panna ja oodata ennustuste saamist brauseripõhise kasutajaliidese kaudu, kirjutamata ühtki koodirida, muretsemata GPU-de pärast või süvaõppemudelite abil tabeli tuvastamiseks õigeid arhitektuure otsimata.
Samuti saate hankida iga ennustuse JSON-i vastused, et integreerida see oma süsteemidega ja luua masinõppe toega rakendusi, mis põhinevad nüüdisaegsetel algoritmidel ja tugeval infrastruktuuril.
https://nanonets.com/documentation/
Kas teie ettevõte tegeleb andmete või tekstituvastusega digitaalsetes dokumentides, PDF-ides või piltides? Kas olete mõelnud, kuidas tabeliandmeid eraldada, piltidelt teksti ekstraheerimine , eraldage andmed PDF-ist or teksti väljavõtte PDF-failist täpselt ja tõhusalt?
Kellele on tabeli ekstraheerimine kasulik
Nagu eelmises jaotises mainitud, kasutatakse tabeleid sageli andmete esitamiseks puhtas vormingus. Näeme neid nii sageli mitmes valdkonnas, alustades oma töö korraldamisest andmete tabelite kaupa struktureerimise teel kuni ettevõtete tohutute varade hoidmiseni. On palju organisatsioone, mis peavad iga päev tegelema miljonite tabelitega. Selliste töömahukate ülesannete hõlbustamiseks, kui kõike käsitsi teha, peame kasutama kiiremaid tehnikaid. Arutleme mõne kasutusjuhtumi üle, kus tabelite väljavõtmine võib olla hädavajalik:

Isikliku kasutamise juhtumid
. laua väljatõmbamine protsess võib olla abiks ka väikeste isikliku kasutuse juhtumite puhul. Mõnikord jäädvustame dokumente mobiiltelefoni ja kopeerime need hiljem arvutisse. Selle protsessi kasutamise asemel saame dokumendid otse jäädvustada ja salvestada kohandatud mallidesse redigeeritavates vormingutes. Allpool on mõned kasutusjuhtumid selle kohta, kuidas saaksime laua väljatõmbamist oma isikliku rutiini jaoks sobitada –
Dokumentide skannimine telefoni: Tihti jäädvustame oluliste tabelite pilte telefoni ja salvestame, kuid tabelite väljatõmbamise tehnikaga saame tabelite pildid jäädvustada ja salvestada otse tabelivormingus, kas exceli või google lehtedesse. Sellega ei pea me pilte otsima ega tabeli sisu uutesse failidesse kopeerima, selle asemel saame otse imporditud tabeleid kasutada ja väljavõetud teabega tööd alustada.
Dokumendid HTML-i: Veebilehtedelt leiame palju teavet, mis on esitatud tabelite abil. Need aitavad meid andmetega võrrelda ja annavad meile organiseeritud viisil kiire ülevaate numbritest. Tabeli väljavõtmisprotsessi kasutades saame skannida PDF-dokumente või JPG/PNG-pilte ning laadida teabe otse kohandatud isekujundatud tabelivormingusse. Lisaks saame kirjutada skripte, et lisada olemasolevate tabelite põhjal täiendavaid tabeleid ja seeläbi infot digitaliseerida. See aitab meil sisu redigeerida ja kiirendab salvestusprotsessi.
Tööstusliku kasutuse juhud
Üle maailma on mitu tööstust, mis tegelevad tohutult paberimajanduse ja dokumentatsiooniga, eriti pangandus- ja kindlustussektoris. Tabeleid kasutatakse laialdaselt alates klientide andmete salvestamisest kuni klientide vajaduste rahuldamiseni. See teave edastatakse uuesti dokumendina (paberkoopiana) erinevatele filiaalidele kinnitamiseks, kus mõnikord võib valesti suhtlemine põhjustada tabelitest teabe hankimisel vigu. Selle asemel muudab automatiseerimise kasutamine meie elu palju lihtsamaks. Kui algandmed on kogutud ja kinnitatud, saame need dokumendid otse tabeliteks skaneerida ja digiteeritud andmetega edasi töötada. Rääkimata ajakulu ja rikete vähendamisest, saame kliente teavitada info töötlemise ajast ja kohast. Seetõttu tagab see andmete usaldusväärsuse ja lihtsustab meie toimingute lahendamist. Vaatame nüüd teisi võimalikke kasutusjuhtumeid:
Kvaliteedi kontroll: Kvaliteedikontroll on üks peamisi teenuseid, mida tipptööstused pakuvad. Tavaliselt tehakse seda ettevõttesiseselt ja sidusrühmade jaoks. Selle raames kogutakse tarbijatelt palju tagasisidevorme, et saada tagasisidet pakutava teenuse kohta. Tööstussektorites kasutavad nad tabeleid igapäevaste kontrollnimekirjade ja märkmete tegemiseks, et näha, kuidas tootmisliinid töötavad. Kõiki neid saab ühes kohas dokumenteerida, kasutades tabelit hõlpsalt väljavõtmist.
Varade jälgimine: Tootmistööstuses kasutavad inimesed kõvakoodiga tabeleid, et jälgida toodetud üksusi, nagu teras, raud, plast jne. Iga toodetud toode on märgistatud unikaalse numbriga, kus nad kasutavad tabeleid, et jälgida iga päev toodetud ja tarnitud esemeid. Automatiseerimine võib aidata säästa palju aega ja varasid valede paigutuste või andmete ebaühtluse tõttu.
Ärikasutusjuhtumid
On mitmeid ärivaldkondi, mis töötavad Exceli lehtedel ja võrguühenduseta vormidel. Kuid ühel ajahetkel on nende lehtede ja vormide otsimine keeruline. Kui sisestame need tabelid käsitsi, on see aeganõudev ja tõenäosus, et andmed sisestatakse valesti, on suur. Seetõttu on tabeli ekstraheerimine parem alternatiiv äriliste kasutusjuhtude lahendamiseks, kuna selliseid on allpool vähe.
Arve Automatiseerimine: On palju väike- ja suurtööstusi, mille arved genereeritakse endiselt tabelivormingus. Need ei anna korralikult turvatud maksuaruandeid. Selliste takistuste ületamiseks saame kõigi teisendamiseks kasutada tabeli ekstraheerimist arved redigeeritavasse vormingusse ja seeläbi uuendada need uuemale versioonile.
Vormi automatiseerimine: Veebivormid häirivad seda läbiproovitud meetodit, aidates ettevõtetel koguda vajalikku teavet ja ühendades selle samaaegselt teiste töövoogu sisseehitatud tarkvaraplatvormidega. Lisaks käsitsi andmete sisestamise vajaduse vähendamisele (koos automatiseeritud andmesisestus) ja järelmeilid, võib tabeli eraldamine kaotada traditsiooniliste paberi alternatiivide printimise, postitamise, säilitamise, korrastamise ja hävitamise kulud.
Kas teil on OCR-probleem meeles? Tahad digitaliseerida arved, PDF-id või numbrimärgid? Suunduge poole Nanonetid ja looge OCR-mudeleid tasuta!
Sügav õppimine tegevuses
Süvaõpe on osa tehisnärvivõrkudel põhinevate masinõppemeetodite laiemast perekonnast.
Neuraalvõrk on raamistik, mis tunneb ära antud andmete aluseks olevad seosed protsessi kaudu, mis jäljendab inimaju toimimist. Neil on erinevad tehiskihid, mille kaudu andmed läbivad, kus nad õpivad tundma funktsioone. Erinevat tüüpi andmete töötlemiseks on erinevaid arhitektuure, nagu Convolution NN-id, Recurrent NN-id, Autoencoders, Generative Adversarial NN-id. Need on keerulised, kuid kujutavad endast suurt jõudlust probleemide lahendamiseks reaalajas. Vaatame nüüd uuringuid, mis on läbi viidud tabeli väljavõtete valdkonnas, kasutades närvivõrke, ja vaatame neid ka lühidalt.
TableNet
Sissejuhatus: TableNet on kaasaegne süvaõppe arhitektuur, mille pakkus välja TCS Researchi aasta meeskond 2019. aastal. Peamine ajend oli skannitud tabelitest mobiiltelefonide või kaamerate kaudu teabe hankimine.
Nad pakkusid välja lahenduse, mis hõlmab pildi tabelipiirkonna täpset tuvastamist ning seejärel tuvastatud tabeli ridadest ja veergudest teabe tuvastamist ja eraldamist.
Andmekogum: Kasutatud andmestik oli Marmot. Sellel on 2000 lehekülge PDF-vormingus, mis on kogutud koos vastavate alustõdedega. See hõlmab ka hiinakeelseid lehti. Link - http://www.icst.pku.edu.cn/cpdp/sjzy/index.htm
Arhitektuur: Arhitektuur põhineb Long et al., semantilise segmenteerimise kodeerija-dekoodri mudelil. Sama kodeerija/dekoodri võrku kasutatakse tabeli väljavõtmiseks FCN-i arhitektuurina. Pilte on eeltöödeldud ja muudetud kasutades Tesseact OCR.
Mudel tuletatakse kahes faasis, allutades sisendi süvaõppe tehnikatele. Esimeses etapis on nad kasutanud eelnevalt treenitud VGG-19 võrgu raskusi. Nad on asendanud kasutatud VGG võrgu täielikult ühendatud kihid 1 × 1 konvolutsioonikihtidega. Kõigile konvolutsioonikihtidele järgneb ReLU aktiveerimine ja väljalangemise kiht tõenäosusega 0.8, 1. Nad nimetavad teist faasi dekodeeritud võrguks, mis koosneb kahest harust. See on intuitsiooni kohaselt, et veeru piirkond on tabeli piirkonna alamhulk. Seega saab üks kodeerimisvõrk aktiivsed piirkonnad parema täpsusega välja filtreerida, kasutades nii tabeli- kui ka veerupiirkondade funktsioone. Esimese võrgu väljund jaotatakse kahele harule. Esimeses harus rakendatakse kahte konvolutsioonioperatsiooni ja lõplikku objektikaarti suurendatakse, et see vastaks pildi esialgsetele mõõtmetele. Teises veergude tuvastamise harus on ReLU aktiveerimisfunktsiooniga täiendav konvolutsioonikiht ja sama väljalangemise tõenäosusega väljalangemise kiht, nagu eelnevalt mainitud. Objektide kaartide valimid võetakse pärast (1 × XNUMX) konvolutsioonikihti, kasutades fraktsioneerivaid keerdkäike. Allpool on pilt arhitektuurist:

Väljundid: Pärast dokumentide töötlemist mudeli abil genereeritakse tabelite ja veergude maskid. Neid maske kasutatakse tabeli ja selle veerupiirkondade pildilt välja filtreerimiseks. Nüüd, kasutades Tesseracti OCR-i, eraldatakse teave segmenteeritud piirkondadest. Allpool on pilt, mis näitab maske, mis genereeritakse ja hiljem tabelitest ekstraheeritakse:

Samuti pakkusid nad välja sama mudeli, mida on peenhäälestatud ICDAR-iga, mis toimis paremini kui algmudel. Peenhäälestatud mudeli meeldetuletus-, täpsus- ja F1-skoor on vastavalt 0.9628, 0.9697 ja 0.9662. Algmudelil on salvestatud mõõdikud 0.9621, 0.9547, 0.9583 samas järjekorras. Sukeldume nüüd veel ühte arhitektuuri.
DeepDeSRT
Paber: DeepDeSRT: sügav õpe dokumendipiltide tabelite tuvastamiseks ja struktuuri tuvastamiseks
Sissejuhatus: DeepDeSRT on närvivõrgu raamistik, mida kasutatakse dokumentides või piltides olevate tabelite tuvastamiseks ja mõistmiseks. Sellel on kaks lahendust, nagu pealkirjas mainitud:
- See pakub sügavat õppimispõhist lahendust tabeli tuvastamiseks dokumendikujutistes.
- See pakub välja uudse sügava õppimispõhise lähenemisviisi tabelistruktuuri tuvastamiseks, st tuvastatud tabelite ridade, veergude ja lahtrite positsioonide tuvastamiseks.
Pakutud mudel on täielikult andmepõhine, see ei nõua dokumentide või piltide heuristikat ega metaandmeid. Üks peamisi eeliseid koolituse osas on see, et nad ei kasutanud suuri koolitusandmekogumeid, selle asemel kasutasid nad nii tabeli tuvastamiseks kui ka tabeli struktuuri tuvastamiseks ülekande õppimise ja domeeni kohandamise kontseptsiooni.
Andmekogum: Kasutatud andmestik on ICDAR 2013 tabelivõistluste andmestik, mis sisaldab 67 dokumenti ja kokku 238 lehekülge.
Arhitektuur:
- Tabeli tuvastamine Kavandatud mudelis kasutati tabelite tuvastamise põhiraamistikuna Fast RCNN-i. Arhitektuur on jagatud kaheks erinevaks osaks. Esimeses osas genereerisid nad nn piirkonna ettepanekute võrgu (RPN) sisendpildi põhjal piirkonna ettepanekud. Teises osas klassifitseerisid nad piirkonnad Fast-RCNN-i abil. Selle arhitektuuri toetamiseks kasutasid nad ZFNet ja VGG-16 kaalud.
- Struktuuri äratundmine Kui tabel on edukalt tuvastatud ja selle asukoht on süsteemile teada, on järgmine väljakutse selle sisu mõistmisel tuvastada ja leida tabeli füüsilise struktuuri moodustavad read ja veerud. Seetõttu on nad kasutanud täielikult ühendatud võrku VGG-16 kaaluga, mis tõmbab teavet ridadest ja veergudest. Allpool on DeepDeSRT väljundid:
Väljundid:


Hindamistulemused näitavad, et DeepDeSRT ületab tabeli tuvastamise ja struktuurituvastuse tipptasemel meetodeid ning saavutab kuni 1. aastani F96.77-mõõdud vastavalt 91.44% ja 2015% tabeli tuvastamisel ja XNUMX%.
Graafik närvivõrgud
Paber: Tabelituvastuse ümbermõtestamine graafiku närvivõrkude abil
Sissejuhatus: Selles uuringus pakkusid riikliku tehisintellekti keskuse (NCAI) Deep Learning Laboratory'i autorid välja Graph Neural Networks tabelitest teabe hankimiseks. Nad väitsid, et graafivõrgud on nende probleemide jaoks loomulikum valik, ja uurisid täiendavalt kahte gradiendipõhist graafi närvivõrku.
See väljapakutud mudel ühendab mõlema, konvolutsiooniliste närvivõrkude eelised visuaalsete funktsioonide eraldamiseks ja graafivõrkude eelised probleemistruktuuriga tegelemiseks.
Andmekogum: Autorid pakkusid välja uue suure sünteetiliselt loodud andmestiku, mis koosneb 0.5 miljonist tabelist, mis on jagatud nelja kategooriasse.
- Pildid on lihtsad kujutised, millel puudub ühinemine ja valitsevad jooned
- Piltidel on erinevat tüüpi äärised, sealhulgas aeg-ajalt valitsevate joonte puudumine
- Tutvustab lahtrite ja veergude liitmist
- Kaamera jäädvustas pilte lineaarse perspektiivi teisendusega
Arhitektuur: Nad kasutasid madalat konvolutsioonivõrku, mis genereerib vastavad konvolutsioonilised tunnused. Kui väljundfunktsioonide ruumilised mõõtmed ei ole sisendpildiga samad, koguvad nad positsioonid, mida vähendatakse lineaarselt sõltuvalt sisend- ja väljundmõõtmete vahelisest suhtest, ja saadavad need interaktsioonivõrku, millel on kaks graafikuvõrku, mida nimetatakse DGCNN-iks. ja GravNet. Graafikvõrgu parameetrid on samad, mis algsel CNN-il. Lõpuks on nad ekstraheeritava sisu klassifitseerimiseks kasutanud käitusaegse paari proovivõttu, mis kasutas sisemiselt Monte Carlo-põhist algoritmi. Allpool on väljundid:
Väljundid:

Allpool on toodud tabelina esitatud täpsusnumbrid, mille võrgud genereerivad nelja võrgukategooria jaoks, nagu on esitatud Andmebaas lõik:

CGAN-id ja geneetilised algoritmid
Sissejuhatus: Selles uuringus kasutasid autorid alt-üles (joonte integreerimine lahtritesse, ridadesse või veergudesse) lähenemisviisi asemel ülalt-alla lähenemisviisi.
Selle meetodi puhul, kasutades generatiivset võistlevat võrku, kaardistasid nad tabelipildi standardiseeritud "skeleti" tabelivormiks. See tabeli skelett tähistab ligikaudseid ridade ja veerude piire ilma tabeli sisuta. Järgmisena sobitavad nad kandidaatide varjatud tabelistruktuuride renderdusi luustiku struktuuriga, kasutades geneetilise algoritmi abil optimeeritud kaugusmõõtu.
Andmekogum: Autorid kasutasid oma andmestikku, milles on 4000 tabelit.
Arhitektuur: Kavandatud mudel koosneb kahest osast. Esimeses osas abstraheeritakse sisendkujutised skeletitabeliteks, kasutades tingimuslikku generatiivset võistlevat närvivõrku. GAN-il on jälle kaks võrku: generaator, mis genereerib juhuslikke proove, ja diskriminaator, mis ütleb, kas loodud pildid on võltsitud või originaalsed. Generaator G on kodeerija-dekoodri võrk, kus sisendkujutis lastakse läbi järk-järgult alladiskreetiliste kihtide jada kuni pudelikaela kihini, kus protsess on vastupidine. Piisava teabe edastamiseks dekodeerimiskihtidele kasutatakse vahelejätmise ühendustega U-Neti arhitektuuri ning kihtide i ja n − i vahele lisatakse vahelejätmise ühendus konkateneerimise teel, kus n on kihtide koguarv ja i on kihi number. kodeerijas. Diskriminaatori D jaoks kasutatakse PatchGAN arhitektuuri. See karistab väljundpildi struktuuri plaastrite skaalal. Need toodavad väljundit skeletitabelina.
Teises osas optimeerivad nad kandidaatide varjatud andmestruktuuride sobitumist loodud skeleti kujutisega, kasutades iga kandidaadi ja skeleti vahelise kauguse mõõtmist. Nii ekstraheeritakse piltide sees olev tekst. Allpool on pilt, mis kujutab arhitektuuri:

Väljund: Hinnangulisi tabeli struktuure hinnatakse, võrreldes Rea ja veeru number , vasakpoolse ülanurga asukoht, ridade kõrgused ja veeru laiused
Geneetiline algoritm andis tabelitest teabe väljavõtmisel 95.5% täpsuse ridade kaupa ja 96.7% täpsust veergude kaupa.

Vajadus dokumendid digiteerida, laekumised or arved aga liiga laisk, et kodeerida? Suunduge poole Nanonetid ja looge OCR-mudeleid tasuta!
[Kood] Traditsioonilised lähenemisviisid
Selles jaotises õpime, kuidas süvaõppe ja OpenCV abil tabelitest teavet eraldada. Seda selgitust võib pidada sissejuhatuseks, kuid tipptasemel mudelite loomine nõuab palju kogemusi ja praktikat. See aitab teil mõista põhitõdesid, kuidas me saame treenida arvuteid erinevate võimalike lähenemisviiside ja algoritmidega.
Probleemi täpsemaks mõistmiseks määratleme mõned põhiterminid, mida kasutatakse kogu artiklis:
- Tekst: sisaldab stringi ja viit atribuuti (ülemine, vasak, laius, kõrgus, font)
- joon: sisaldab tekstiobjekte, mis eeldatakse olevat algfailis samal real
- Üherealine: reaobjekt ainult ühe tekstiobjektiga.
- Multi-Line: reaobjekt rohkem kui ühe tekstiobjektiga.
- Multi-Line Blokeerima: pidevate mitmerealiste objektide komplekt.
- Rida: Horisontaalsed plokid tabelis
- Veerg: Vertikaalsed plokid tabelis
- Rakk: rea ja veeru ristumiskoht
- Lahter – polsterdus: sisemine polster või ruum lahtri sees.
Tabeli tuvastamine OpenCV-ga
Kasutame skannitud tabelitest teabe eraldamiseks traditsioonilisi arvutinägemise tehnikaid. Siin on meie torujuhe; algul jäädvustame andmed (tabelid, kust peame teabe hankima) tavaliste kaameratega ja seejärel proovime arvutinägemise abil leida piire, servi ja lahtreid. Kasutame erinevaid filtreid ja kontuure ning tõstame esile tabelite põhiomadused.
Meil on vaja laua pilti. Saame selle telefoniga jäädvustada või kasutada mis tahes olemasolevat pilti. Allpool on koodilõik,
file = r’table.png’
table_image_contour = cv2.imread(file, 0)
table_image = cv2.imread(file)
Siin oleme laadinud sama pildipildi kaks muutujat, kuna kasutame tabeli_kujutise_kontuur kui joonistame meie tuvastatud kontuurid laaditud pildile. Allpool on pilt tabelist, mida me oma programmis kasutame:

Kasutame tehnikat, mida nimetatakse Inverse Image Thresholding mis täiustab antud pildil olevaid andmeid.
ret, thresh_value = cv2.threshold( table_image_contour, 180, 255, cv2.THRESH_BINARY_INV)
Teine oluline eeltöötlusetapp on pildi laienemine. Dilatatsioon on lihtne matemaatiline tehe, mida rakendatakse kahendkujutistele (must ja valge), mis suurendab järk-järgult esiplaani pikslite piirkondade piire (st tavaliselt valged pikslid).
kernel = np.ones((5,5),np.uint8)
dilated_value = cv2.dilate(thresh_value,kernel,iterations = 1)
OpenCV-s kasutame meetodit, kontuuride leidmine et saada praegusel pildil olevad kontuurid. Sellel meetodil on kolm argumenti, esimene on laiendatud kujutis (laiendatud kujutise genereerimiseks kasutatav pilt on table_image_contour – meetod findContours toetab ainult kahendkujutisi), teine on cv2.RETR_TREE mis käsib meil kasutada kontuuride otsimise režiimi, kolmas on cv2.CHAIN_APPROX_SIMPLE mis on kontuuri lähendamise režiim. The kontuuride leidmine pakib lahti kaks väärtust, seega lisame veel ühe muutuja nimega hierarhia. Kui kujutised on pesastatud, õhkuvad kontuurid vastastikust sõltuvust. Selliste suhete kujutamiseks kasutatakse hierarhiat.
contours, hierarchy = cv2.findContours( dilated_value, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
Kontuurid tähistavad täpselt, kus andmed pildil asuvad. Nüüd kordame eelmises etapis arvutatud kontuuride loendit ja arvutame ristkülikukujuliste kastide koordinaadid, nagu on näidatud originaalpildil, kasutades meetodit, cv2.boundingRect. Viimases iteratsioonis panime need kastid algsele pildile table_image, kasutades meetodit, cv2.ristkülik().
for cnt in contours: x, y, w, h = cv2.boundingRect(cnt) # bounding the images if y < 50: table_image = cv2.rectangle(table_image, (x, y), (x + w, y + h), (0, 0, 255), 1) See on meie viimane samm. Siin kasutame meetodit nimega Window et renderdada meie tabel koos sellele manustatud väljatõmmatud sisu ja kontuuridega. Allpool on koodilõik:
plt.imshow(table_image)
plt.show()
cv2.namedWindow('detecttable', cv2.WINDOW_NORMAL)

Muutke ülaltoodud koodilõigu y väärtus 300-ks, see on teie väljund:

Kui olete tabelid eraldanud, saate iga kontuuri kärpida läbi tesseract OCR mootori, mille õpetuse leiate siin. Kui meil on iga teksti kastid, saame need rühmitada nende x- ja y-koordinaatide alusel, et tuletada, millisesse vastavasse rida ja veergu need kuuluvad.
Lisaks on võimalik kasutada PDFMinerit, et muuta oma pdf-dokumendid HTML-failideks, mida saame tavaavaldiste abil parsida, et lõpuks oma tabelid kätte saada. Siin on, kuidas seda teha.
PDFMineri ja Regexi sõelumine
Väiksematest dokumentidest teabe hankimiseks kulub aega süvaõppemudelite konfigureerimiseks või arvutinägemise algoritmide kirjutamiseks. Selle asemel saame Pythonis kasutada regulaaravaldisi teksti väljavõte PDF-dokumentidest. Samuti pidage meeles, et see tehnika ei tööta piltide puhul. Saame seda kasutada ainult teabe eraldamiseks HTML-failidest või PDF-dokumentidest. Seda seetõttu, et regulaaravaldise kasutamisel peate sisu sobitama allikaga ja teabe välja võtma. Piltide puhul ei saa te teksti sobitada ja regulaaravaldised ebaõnnestuvad. Töötame nüüd lihtsa PDF-dokumendiga ja eraldame selles olevatest tabelitest teavet. Allpool on pilt:

Esimeses etapis laadime PDF-i oma programmi. Kui see on tehtud, teisendame PDF-i HTML-i, et saaksime otse regulaaravaldisi kasutada ja seeläbi tabelitest sisu eraldada. Selleks kasutame moodulit pdfminer. See aitab lugeda sisu PDF-ist ja teisendada selle HTML-failiks.
Allpool on koodilõik:
from pdfminer.pdfinterp import PDFResourceManager from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.converter import HTMLConverter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from cStringIO import StringIO
import re def convert_pdf_to_html(path): rsrcmgr = PDFResourceManager() retstr = StringIO() codec = 'utf-8' laparams = LAParams() device = HTMLConverter(rsrcmgr, retstr, codec=codec, laparams=laparams) fp = file(path, 'rb') interpreter = PDFPageInterpreter(rsrcmgr, device) password = "" maxpages = 0 #is for all caching = True pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages,password=password,caching=caching, check_extractable=True): interpreter.process_page(page) fp.close() device.close() str = retstr.getvalue() retstr.close() return str
Koodi krediidid: zevross
Importisime palju mooduleid, sealhulgas regulaaravaldise ja PDF-iga seotud teeke. Meetodis convert_pdf_to_html, saadame PDF-faili tee, mis tuleb teisendada HTML-failiks. Meetodi väljundiks on HTML-string, nagu allpool näidatud:
'<span style="font-family: XZVLBD+GaramondPremrPro-LtDisp; font-size:12px">Changing Echoesn<br>7632 Pool Station Roadn<br>Angels Camp, CA 95222n<br>(209) 785-3667n<br>Intake: (800) 633-7066n<br>SA </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> TX DT BU </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> RS RL OP PH </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> CO CJ n<br></span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> SF PI </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> AH SPn<br></span></div>' Regulaaravaldis on üks keerukamaid ja lahedamaid programmeerimistehnikaid, mida kasutatakse mustrite sobitamiseks. Neid kasutatakse laialdaselt mitmes rakenduses, näiteks koodi vormindamiseks, veebi kraapimiseks ja valideerimiseks. Enne kui hakkame oma HTML-i tabelitest sisu välja tõmbama, õppigem kiiresti mõned asjad regulaaravaldiste kohta.
See teek pakub erinevaid sisseehitatud meetodeid mustrite sobitamiseks ja otsimiseks. Allpool on mõned:
import re # Match the pattern in the string
re.match(pattern, string) # Search for a pattern in a string
re.search(pattern, string) # Finds all the pattern in a string
re.findall(pattern, string) # Splits string based on the occurrence of pattern
re.split(pattern, string, [maxsplit=0] # Search for the pattern and replace it with the given string
re.sub(pattern, replace, string)
Tähemärgid/väljendid, mida tavaliselt regulaaravaldistes näete, on järgmised:
- [A–Z] – mis tahes suur täht
- d - number
- w - sõnamärk (tähed, numbrid ja allkriipsud)
- s - tühik (tühikud, tabeldusmärgid ja tühik)
Nüüd HTML-is konkreetse mustri leidmiseks kasutame regulaaravaldisi ja kirjutame seejärel mustrid vastavalt. Esmalt jagame andmed nii, et aadressitükid eraldatakse vastavalt programmi nimele eraldi plokkideks (ANGELS CAMP, APPLE VALLEY jne):
pattern = '(?<=<span style="font-family: XZVLBD+GaramondPremrPro-LtDisp; font-size:12px">)(.*?)(?=<br></span></div>)' for programinfo in re.finditer(pattern, biginputstring, re.DOTALL): do looping stuff…
Hiljem leiame programmi nime, linna, osariigi ja sihtnumbri, mis järgivad alati sama mustrit (tekst, koma, kahekohalised suurtähed, 5 numbrit (või 5 numbrit sidekriips neli numbrit) – need on olemas PDF-failis, mis pidasime sisendiks). Kontrollige järgmist koodilõiku:
# To identify the program name
programname = re.search('^(?!<br>).*(?=\n)', programinfo.group(0))
# since some programs have odd characters in the name we need to escape
programname = re.escape(programname) citystatezip =re.search('(?<=>)([a-zA-Zs]+, [a-zA-Zs]{2} d{5,10})(?=\n)', programinfo.group(0))
mainphone =re.search('(?<=<br>)(d{3}) d{3}-d{4}x{0,1}d{0,}(?=\n)', programinfo.group(0))
altphones = re.findall('(?<=<br>)[a-zA-Zs]+: (d{3}) d{3}-d{4}x{0,1}d{0,}(?=\n)(?=\n)', programinfo.group(0)) See on lihtne näide, mis selgitab, kuidas eraldame regulaaravaldise abil teavet PDF-failidest. Pärast kogu vajaliku teabe väljavõtmist laadime need andmed CSV-faili.
def createDirectory(instring, outpath, split_program_pattern): i = 1 with open(outpath, 'wb') as csvfile: filewriter = csv.writer(csvfile, delimiter=',' , quotechar='"', quoting=csv.QUOTE_MINIMAL) # write the header row filewriter.writerow(['programname', 'address', 'addressxtra1', 'addressxtra2', 'city', 'state', 'zip', 'phone', 'altphone', 'codes']) # cycle through the programs for programinfo in re.finditer(split_program_pattern, instring, re.DOTALL): print i i=i+1 # pull out the pieces programname = getresult(re.search('^(?!<br>).*(?=\n)', programinfo.group(0))) programname = re.escape(programname) # some facilities have odd characters in the name
See on lihtne näide, mis selgitab, kuidas saate ekstraheeritud HTML-i CSV-faili lükata. Kõigepealt loome CSV-faili, leiame kõik oma atribuudid ja surume ükshaaval nende vastavatesse veergudesse. Allpool on ekraanipilt:

Mõnikord tunduvad ülalkirjeldatud tehnikad keerulised ja seavad programmeerijatele väljakutseid, kui kõik tabelid on pesastatud ja keerulised. Siin säästab CV või süvaõppe mudeli valimine palju aega. Vaatame, millised puudused ja väljakutsed takistavad nende traditsiooniliste meetodite kasutamist.
Väljakutsed traditsiooniliste meetoditega
Selles jaotises õpime põhjalikult tundma, kus tabeli ekstraheerimise protsessid võivad ebaõnnestuda, ja mõistame täiendavalt viise, kuidas neid takistusi ületada, kasutades süvaõppest sündinud kaasaegseid meetodeid. See protsess ei ole siiski kook. Põhjus on selles, et tabelid ei jää tavaliselt kogu aeg samaks. Neil on andmete esitamiseks erinev struktuur ja tabelites olevad andmed võivad olla mitmekeelsed ja erinevate vormindusstiilidega (fondi stiil, värv, fondi suurus ja kõrgus). Järelikult tuleb tugeva mudeli loomiseks kõigist neist väljakutsetest teadlik olla. Tavaliselt sisaldab see protsess kolme etappi: tabeli tuvastamine, ekstraheerimine ja teisendamine. Tuvastame probleemid kõigis etappides ükshaaval:
Tabeli tuvastamine
Selles faasis tuvastame, kus täpselt antud sisendis tabelid asuvad. Sisend võib olla mis tahes vormingus, näiteks pildid, PDF-/Word-dokumendid ja mõnikord ka videod. Tabelite tuvastamiseks kasutame erinevaid tehnikaid ja algoritme kas joonte või koordinaatide järgi. Mõnel juhul võime kohata ääristeta tabeleid, kus peame valima erinevad meetodid. Lisaks nendele on siin veel mõned väljakutsed:
- Pildi teisendus: Kujutise teisendamine on siltide tuvastamise peamine samm. See hõlmab tabelis olevate andmete ja piiride täiustamist. Peame valima õiged eeltöötlusalgoritmid tabelis esitatud andmete põhjal. Näiteks piltidega töötades peame rakendama läve- ja servadetektoreid. See teisendusetapp aitab meil sisu täpsemalt üles leida. Mõnel juhul võivad kontuurid valesti minna ja algoritmid ei suuda pilti täiustada. Seetõttu on õige pildi teisendamise sammude ja eeltöötluse valimine ülioluline.
- Pildikvaliteet: Kui skannime tabeleid teabe väljavõtmiseks, peame tagama, et neid dokumente skannitakse heledamas keskkonnas, mis tagab hea pildikvaliteedi. Halbade valgustingimuste korral ei pruugi CV- ja DL-algoritmid antud sisendites tabeleid tuvastada. Kui kasutame süvaõpet, peame tagama, et andmekogum oleks järjepidev ja sellel oleks hea standardkujutiste komplekt. Kui kasutame neid mudeleid vanades kortsunud paberites olevatel laudadel, siis tuleb esmalt eeltöödelda ja nende piltide müra kõrvaldada.
- Erinevad struktuursed paigutused ja mallid: Kõik tabelid ei ole ainulaadsed. Üks lahter võib ulatuda üle mitme lahtri, kas vertikaalselt või horisontaalselt, ja ulatuvate lahtrite kombinatsioonid võivad luua suure hulga struktuurseid variatsioone. Samuti rõhutavad mõned teksti tunnused ja tabeliread võivad mõjutada tabeli struktuuri mõistmist. Näiteks võivad horisontaalsed jooned või paksus kirjas tekst rõhutada mitut tabeli päist. Tabeli struktuur määrab visuaalselt lahtritevahelised seosed. Visuaalsed seosed tabelites muudavad seotud lahtrite arvutusliku leidmise ja neist teabe eraldamise keeruliseks. Seetõttu on oluline luua algoritme, mis on vastupidavad tabelite erinevate struktuuride käsitlemisel.
- Lahtri täitmine, veerised, äärised: Need on iga tabeli põhielemendid – polstrid, veerised ja äärised ei ole alati samad. Mõnel tabelil on lahtrites palju polsterdust ja mõnel mitte. Kvaliteetsete piltide ja eeltöötlusetappide kasutamine aitab tabeli ekstraheerimisel sujuvalt kulgeda.
Tabeli ekstraheerimine
See on faas, kus teave ekstraheeritakse pärast tabelite tuvastamist. Sisu ülesehituse ja tabelis sisalduva sisu kohta on palju tegureid. Seetõttu on enne algoritmi koostamist oluline mõista kõiki väljakutseid.
- Tihe sisu: Lahtrite sisu võib olla kas numbriline või tekstiline. Tekstiline sisu on aga tavaliselt tihe, sisaldades mitmetähenduslikke lühikesi tekstilõike koos akronüümide ja lühendite kasutamisega. Tabelite mõistmiseks tuleb tekst üheselt mõistetavaks teha ning lühendeid ja akronüüme laiendada.
- Erinevad fondid ja vormingud: Fondid on tavaliselt erineva stiili, värvi ja kõrgusega. Peame tagama, et need on üldised ja hõlpsasti tuvastatavad. Väheseid fondiperekondi, eriti neid, mis kuuluvad kursiivse või käsitsi kirjutatud fondi alla, on pisut raske eraldada. Seega aitab hea fondi ja õige vormingu kasutamine algoritmil teavet täpsemalt tuvastada.
- Mitme lehekülje PDF-id ja leheküljevahed: Tabelite tekstirida on tundlik eelmääratletud läve suhtes. Ka mitme lehe lahtrite ületamisel muutub tabeleid raskeks tuvastada. Mitme tabeliga lehel on erinevaid tabeleid raske üksteisest eristada. Hõredate ja ebakorrapäraste laudadega on raske töötada. Seetõttu tuleks graafilisi juhtjooni ja sisu paigutust kasutada koos oluliste allikatena tabelipiirkondade tuvastamisel.
Tabeli teisendamine
Viimane etapp hõlmab tabelitest eraldatud teabe teisendamist redigeeritavaks dokumendiks, kas excelis või muu tarkvara abil. Tutvume mõne väljakutsega.
- Paigutuste määramine: Kui skannitud dokumentidest eraldatakse erinevas vormingus tabelid, peab meil olema sisu sisestamiseks õige tabelipaigutus. Mõnikord ei õnnestu algoritmil lahtritest teavet eraldada. Seetõttu on sama oluline ka õige paigutuse kujundamine.
- Erinevad väärtuste esitamise mustrid: Lahtrites olevaid väärtusi saab esitada erinevate süntaktiliste esitusmustrite abil. Arvestage, et tabeli tekst on 6 ± 2. Algoritmil ei pruugi seda konkreetset teavet teisendada. Seega eeldab arvväärtuste eraldamine võimalike esitlusmustrite tundmist.
- Esitus visualiseerimiseks: Enamik tabelite esitusvorminguid, näiteks märgistuskeeled, milles saab tabeleid kirjeldada, on mõeldud visualiseerimiseks. Seetõttu on tabelite automaatne töötlemine keeruline.
Need on väljakutsed, millega seisame silmitsi traditsioonilisi tehnikaid kasutades laua ekstraheerimise protsessis. Nüüd vaatame, kuidas süvaõppe abil neist üle saada. Seda uuritakse laialdaselt erinevates sektorites.
Vaja digiteerida dokumendid, kviitungid või arved aga liiga laisk, et kodeerida? Suunduge poole Nanonetid ja looge OCR-mudeleid tasuta!
kokkuvõte
Selles artiklis käsitlesime üksikasjalikult tabelitest teabe hankimist. Oleme näinud, kuidas kaasaegsed tehnoloogiad, nagu Deep Learning ja Computer Vision, saavad automatiseerida igapäevaseid ülesandeid, luues täpsete tulemuste väljastamiseks tugevaid algoritme. Esialgsetes osades õppisime tabelite ekstraktimise rolli üksikisikute, tööstusharude ja ärisektorite ülesannete hõlbustamisel ning vaatasime läbi ka kasutusjuhtumid, mis käsitlevad tabelite ekstraheerimist PDF-idest/HTML-ist, vormide automatiseerimist, arve Automatiseerimine jne. Oleme arvutinägemise abil kodeerinud algoritmi teabe asukoha leidmiseks tabelites, kasutades läve, dilatatsiooni ja kontuuride tuvastamise tehnikaid. Oleme arutanud väljakutseid, millega võime tavapäraste tehnikate kasutamisel tabeli tuvastamise, ekstraheerimise ja teisendamise protsesside ajal kokku puutuda, ning selgitanud, kuidas sügav õppimine aitab meil neist probleemidest üle saada. Lõpuks oleme üle vaadanud mõned närvivõrgu arhitektuurid ja mõistnud nende viise tabeli väljavõtmiseks antud koolitusandmete põhjal.
Värskenda:
Lisatud on rohkem lugemismaterjali erinevate lähenemisviiside kohta tabeli tuvastamisel ja teabe hankimisel süvaõppe abil.
- &
- 2019
- 67
- MEIST
- Vastavalt
- vastavalt
- täpne
- omandama
- üle
- aktiivne
- Täiendavad lisad
- aadress
- ADEelis
- algoritm
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- alternatiiv
- alternatiive
- alati
- summa
- inglid
- õun
- rakendused
- kehtima
- lähenemine
- apps
- arhitektuur
- argumendid
- Kunst
- artikkel
- kunstlik
- tehisintellekti
- vara
- tähelepanu
- atribuudid
- autorid
- automatiseerima
- Automaatika
- tagapõhi
- Pangandus
- enne
- on
- alla
- Kasu
- Natuke
- Must
- piir
- puruneb
- brauseri
- ehitama
- Ehitus
- Ehitab
- äri
- ettevõtted
- helistama
- Kaamerad
- kandidaat
- kapital
- lüüa
- juhtudel
- väljakutse
- väljakutseid
- raske
- hiina
- valik
- Vali
- Linn
- CNN
- kood
- koguma
- Veerg
- kombinatsioonid
- Ettevõtted
- konkurents
- täiesti
- keeruline
- arvuti
- arvutid
- mõiste
- seotud
- ühendamine
- ühendus
- Side
- järjepidev
- Tarbijad
- tarbimine
- sisaldab
- sisu
- sisu
- kontrollida
- Konverteerimine
- tuum
- Vastav
- cover
- looma
- Autorid
- põllukultuur
- otsustav
- tava
- Kliendid
- andmed
- päev
- tegelema
- tegelema
- esitatud
- Olenevalt
- kirjeldatud
- kavandatud
- projekteerimine
- detail
- detailid
- tuvastatud
- Detection
- arendama
- seade
- DID
- erinev
- raske
- digitaalne
- digiteerida
- numbrit
- otse
- arutama
- kaugus
- jagatud
- dokumendid
- domeen
- alla
- puudused
- joonistus
- ajal
- serv
- tõhusalt
- kõrvaldama
- varjatud
- Lõpuks-lõpuni
- Mootor
- sisenes
- üksuste
- eriti
- oluline
- Essentials
- Hinnanguliselt
- jms
- kõik
- näide
- Excel
- olemasolevate
- laiendatud
- kogemus
- väljendeid
- Väljavõtted
- nägu
- tegurid
- võlts
- peredele
- pere
- KIIRE
- kiiremini
- tunnusjoon
- FUNKTSIOONID
- tagasiside
- Filtrid
- Lõpuks
- leidmine
- leiab
- esimene
- First Look
- sobima
- järgima
- Järel
- vorm
- formaat
- vormid
- avastatud
- Raamistik
- tasuta
- funktsioon
- Põhialused
- edasi
- tekitama
- generatiivne
- generaator
- saamine
- hea
- Kasvavad
- Käsitsemine
- juhataja
- kõrgus
- aitama
- kasulik
- aidates
- aitab
- siin
- hierarhia
- Suur
- Esile tõstma
- Horisontaalne
- Kuidas
- Kuidas
- aga
- HTTPS
- tohutu
- inim-
- Takistused
- identifitseerima
- identifitseerimiseks
- pilt
- oluline
- sisaldama
- hõlmab
- Kaasa arvatud
- Suurendama
- kasvav
- inimesed
- tööstus-
- tööstusharudes
- info
- Infrastruktuur
- sisend
- kindlustus
- integreerima
- Intelligentsus
- suhtlemist
- ristmik
- küsimustes
- IT
- teadmised
- teatud
- Labels
- Keeled
- suur
- kiht
- viima
- Õppida
- õppinud
- õppimine
- Raamatukogu
- joon
- LINK
- nimekiri
- koormus
- liising
- Pikk
- masin
- masinõpe
- TEEB
- käsiraamat
- käsitsi
- tootmine
- kaart
- kaardid
- märk
- Maskid
- Vastama
- sobitamine
- materjal
- matemaatika
- mõõtma
- mainitud
- meetodid
- Meetrika
- võib
- miljon
- miljonid
- meeles
- mobiilne
- mobiiltelefon
- mobiiltelefonid
- mudel
- mudelid
- kuu
- rohkem
- kõige
- mitmekordne
- riiklik
- Natural
- vajalik
- vajadustele
- võrk
- võrgustikud
- müra
- normaalne
- märkused
- number
- numbrid
- offline
- Internetis
- veebiplatvormidel
- töö
- Operations
- optimeerima
- optimeeritud
- valik
- et
- organisatsioonid
- Korraldatud
- korraldamine
- Muu
- üldine
- enda
- Paber
- osa
- eriline
- Parool
- Paikade
- Muster
- Inimesed
- jõudlus
- isiklik
- perspektiiv
- faas
- telefonid
- füüsiline
- plast
- Platvormid
- Punkt
- ujula
- vaene
- populaarne
- positsioon
- võimalik
- võim
- tava
- täpselt
- ennustus
- Ennustused
- esitada
- esitlus
- eelmine
- esmane
- Probleem
- probleeme
- protsess
- Protsessid
- töötlemine
- tootma
- Produktsioon
- Programm
- Programmeerijad
- Programming
- Programmid
- ettepanek
- pakutud
- anda
- annab
- eesmärkidel
- kvaliteet
- Kiire
- kiiresti
- RE
- Lugemine
- reaalajas
- tunnistama
- tunnistab
- vähendamine
- kohta
- regulaarne
- Suhted
- jääma
- asendatakse
- esindama
- esindamine
- nõudma
- nõutav
- Vajab
- teadustöö
- Resort
- Tulemused
- tagasipöördumine
- läbi
- jooks
- Skaala
- skaneerida
- Otsing
- Sektorid
- segmentatsioon
- Seeria
- teenus
- Teenused
- komplekt
- mitu
- Lühike
- näidatud
- lihtne
- alates
- SUURUS
- väike
- So
- tarkvara
- tahke
- lahendus
- Lahendused
- LAHENDAGE
- mõned
- Ruum
- tühikud
- jagada
- Poolitab
- standard
- algus
- riik
- modernne
- väljendatud
- avaldused
- jaam
- ladustamine
- salvestada
- tugev
- struktureeritud
- stiil
- Järgnevalt
- Edukalt
- Toetab
- süsteem
- süsteemid
- võtmine
- ülesanded
- maks
- meeskond
- tehnikat
- Tehnoloogiad
- ütleb
- malle
- Allikas
- seetõttu
- künnis
- Läbi
- läbi kogu
- aeg
- aega võttev
- korda
- Kapslid
- kokku
- töövahendid
- ülemine
- jälgida
- traditsiooniline
- koolitus
- üle
- Transformation
- TX
- liigid
- tüüpiliselt
- ui
- all
- mõistma
- mõistmine
- arusaadav
- ainulaadne
- us
- kasutama
- tavaliselt
- kinnitamine
- väärtus
- eri
- versioon
- Videod
- nägemus
- visualiseerimine
- W
- ootama
- web
- M
- kuigi
- jooksul
- ilma
- Töö
- töö
- kirjutamine
- X
- aasta
- youtube