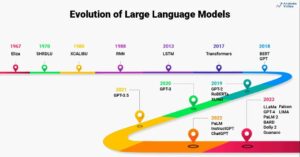
Sissejuhatus
Kujutage ette, et seisate hämaras raamatukogus ja näete vaeva keeruka dokumendi dešifreerimisega, samal ajal žongleerides kümnete muude tekstidega. See oli Transformerite maailm enne, kui ajaleht "Tähelepanu on kõik, mida vajate" oma revolutsioonilise tähelepanu keskpunkti avalikustas. tähelepanu mehhanism.
Sisukord
RNN-ide piirangud
Traditsioonilised järjestikused mudelid, nagu Korduvad närvivõrgud (RNN), töödeldi keelt sõna haaval, mis toob kaasa mitmeid piiranguid:
- Lühiajaline sõltuvus: RNN-idel oli raskusi kaugete sõnade vaheliste seoste mõistmisel, tõlgendades sageli valesti selliste lausete tähendust nagu "mees, kes külastas eile loomaaeda", kus teema ja tegusõna on üksteisest kaugel.
- Piiratud paralleelsus: Teabe järjestikune töötlemine on oma olemuselt aeglane, takistades tõhusat koolitust ja arvutusressursside kasutamist, eriti pikkade jadade puhul.
- Keskenduge kohalikule kontekstile: RNN-id arvestavad peamiselt vahetuid naabreid, kellel võib puududa oluline teave lause muudest osadest.
Need piirangud takistasid Transformerite võimet täita keerulisi ülesandeid, nagu masintõlge ja loomuliku keele mõistmine. Siis tuli tähelepanu mehhanism, revolutsiooniline prožektor, mis valgustab sõnade vahelisi peidetud seoseid, muutes meie arusaama keeletöötlusest. Aga mida tähelepanu täpselt lahendas ja kuidas see Transformersi mängu muutis?
Keskendume kolmele põhivaldkonnale:
Pikaajaline sõltuvus
- Probleem: Traditsioonilised modellid komistasid sageli selliste lausete peale nagu "naine, kes elas mäel, nägi eile õhtul langevat tähte". Neil oli kauguse tõttu raskusi "naise" ja "lendava tähe" ühendamisega, mis viis väärtõlgendusteni.
- Tähelepanu mehhanism: Kujutage ette, et modell särab üle lause, ühendab sõna "naise" otse "lendava tähega" ja mõistab lauset tervikuna. See võime jäädvustada suhteid kaugusest sõltumata on ülioluline selliste ülesannete jaoks nagu masintõlge ja kokkuvõtete tegemine.
Samuti loe: Pika lühiajalise mälu (LSTM) ülevaade
Paralleeltöötluse võimsus
- Probleem: Traditsioonilised mudelid töötlesid teavet järjestikku, näiteks lugesid raamatut lehekülgede kaupa. See oli aeglane ja ebaefektiivne, eriti pikkade tekstide puhul.
- Tähelepanu mehhanism: Kujutage ette, et mitu prožektorit skannivad raamatukogu üheaegselt, analüüsides paralleelselt erinevaid tekstiosi. See kiirendab märkimisväärselt mudeli tööd, võimaldades tal tõhusalt käsitleda tohutuid andmemahtusid. See paralleelne töötlemisvõimsus on keerukate mudelite koolitamiseks ja reaalajas prognooside tegemiseks hädavajalik.
Globaalne konteksti teadlikkus
- Probleem: Traditsioonilised mudelid keskendusid sageli üksikutele sõnadele, jättes vahele lause laiema konteksti. See põhjustas arusaamatusi sellistel juhtudel nagu sarkasm või kahekordne tähendus.
- Tähelepanu mehhanism: Kujutage ette, et tähelepanu keskpunkt pühib üle kogu raamatukogu, võtab vastu iga raamatu ja mõistab, kuidas need on üksteisega seotud. See globaalne kontekstiteadlikkus võimaldab mudelil iga sõna tõlgendamisel arvestada teksti tervikuga, mis viib rikkama ja nüansirikkama arusaamiseni.
Polüseemsete sõnade täpsustus
- Probleem: Sellised sõnad nagu "pank" või "õun" võivad olla nimisõnad, tegusõnad või isegi ettevõtted, tekitades ebaselgust, mida traditsioonilised mudelid püüdsid lahendada.
- Tähelepanu mehhanism: Kujutage ette, et mudel heidab tähelepanu kõikidele sõna „pank” esinemistele lauses, seejärel analüüsib ümbritsevat konteksti ja suhteid teiste sõnadega. Võttes arvesse grammatilist struktuuri, läheduses olevaid nimisõnu ja isegi minevikulauseid, saab tähelepanumehhanism tuletada kavandatud tähenduse. See polüseemsete sõnade ühemõtteline eristamine on ülioluline selliste ülesannete jaoks nagu masintõlge, teksti kokkuvõte ja dialoogisüsteemid.
Need neli aspekti – pikaajaline sõltuvus, paralleeltöötlusjõud, globaalse konteksti teadlikkus ja ühemõttelisus – näitavad tähelepanumehhanismide transformeerivat jõudu. Need on viinud Transformersi loomuliku keele töötlemise esirinnas, võimaldades neil keeruliste ülesannetega toime tulla märkimisväärse täpsuse ja tõhususega.
Kuna NLP ja eriti LLM-id arenevad edasi, mängivad tähelepanumehhanismid kahtlemata veelgi kriitilisemat rolli. Need on sillaks lineaarse sõnajada ja inimkeele rikkaliku seinavaiba vahel ning lõpuks võti nende keeleliste imede tõelise potentsiaali avamiseks. Selles artiklis käsitletakse erinevaid tähelepanumehhanisme ja nende funktsioone.
1. Enesetähelepanu: Transformeri juhttäht
Kujutage ette, et žongleerite mitme raamatuga ja peate kokkuvõtte kirjutamise ajal viidata konkreetsetele lõikudele. Enesetähelepanu või skaleeritud punktitoote tähelepanu toimib intelligentse abilisena, aidates mudelitel teha sama järjestikuste andmetega, nagu laused või aegridad. See võimaldab jada igal elemendil käsitleda kõiki teisi elemente, tabades tõhusalt pikamaa sõltuvusi ja keerulisi seoseid.
Siin on selle peamised tehnilised aspektid lähemalt.
Vektori kujutamine
Iga element (sõna, andmepunkt) teisendatakse kõrgmõõtmeliseks vektoriks, mis kodeerib selle infosisu. See vektorruum on elementidevahelise interaktsiooni aluseks.
QKV ümberkujundamine
Määratletakse kolm võtmemaatriksit:
- Päring (Q): Esindab "küsimust", mille iga element teistele esitab. Q püüab kinni praeguse elemendi teabevajadused ja suunab selle jadas asjakohase teabe otsimist.
- Võti (K): Hoiab iga elemendi teabe "võtit". K kodeerib iga elemendi sisu olemuse, võimaldades teistel elementidel tuvastada võimalikku asjakohasust oma vajaduste põhjal.
- Väärtus (V): Salvestab tegeliku sisu, mida iga element soovib jagada. V sisaldab üksikasjalikku teavet, millele teised elemendid saavad oma tähelepanuskooride põhjal juurde pääseda ja mida kasutada.
Tähelepanu skoori arvutamine
Iga elemendipaari ühilduvust mõõdetakse nende vastavate Q- ja K-vektorite punktkorrutise kaudu. Kõrgemad hinded näitavad elementide tugevamat potentsiaalset asjakohasust.
Skaalatud tähelepanu kaalud
Suhtelise tähtsuse tagamiseks normaliseeritakse need ühilduvusskoorid funktsiooni softmax abil. Selle tulemuseks on tähelepanu kaalud vahemikus 0 kuni 1, mis tähistavad iga elemendi kaalutud tähtsust praeguse elemendi kontekstis.
Kaalutud konteksti koondamine
V-maatriksile rakendatakse tähelepanu kaalu, tuues sisuliselt esile iga elemendi olulise teabe, lähtudes selle asjakohasusest praeguse elemendi suhtes. See kaalutud summa loob praeguse elemendi kontekstipõhise esituse, mis sisaldab kõigist teistest jada elementidest kogutud teadmisi.
Täiustatud elementide esitus
Tänu rikastatud esitusviisile mõistab element nüüd sügavamalt nii oma sisu kui ka suhteid jada teiste elementidega. See teisendatud esitus loob aluse edasisele töötlemisele mudelis.
See mitmeastmeline protsess võimaldab enesetähelepanu:
- Jäädvustage pikamaa sõltuvused: Kaugete elementide vahelised seosed muutuvad kergesti nähtavaks, isegi kui neid eraldab mitu sekkuvat elementi.
- Komplekssete interaktsioonide modelleerimine: Jadasisesed peened sõltuvused ja korrelatsioonid tuuakse päevavalgele, mis toob kaasa andmestruktuuri ja dünaamika rikkalikuma mõistmise.
- Kontekstualiseerige iga element: Mudel analüüsib iga elementi mitte eraldi, vaid järjestuse laiemas raamistikus, mis viib täpsemate ja nüansirikkamate prognooside või esitusteni.
Enesetähelepanu on muutnud pöördeliselt seda, kuidas mudelid töötlevad järjestikuseid andmeid, avades uusi võimalusi erinevates valdkondades, nagu masintõlge, loomuliku keele genereerimine, aegridade prognoosimine ja mujal. Selle võime paljastada järjestustes peidetud seoseid on võimas tööriist arusaamade avastamiseks ja suurepärase jõudluse saavutamiseks paljudes ülesannetes.
2. Mitmepealine tähelepanu: nägemine läbi erinevate objektiivide
Enesetähelepanu annab tervikliku vaate, kuid mõnikord on andmete konkreetsetele aspektidele keskendumine ülioluline. Siin tulebki esile mitmepealine tähelepanu. Kujutage ette, et teil on mitu assistenti, millest igaüks on varustatud erineva objektiiviga:
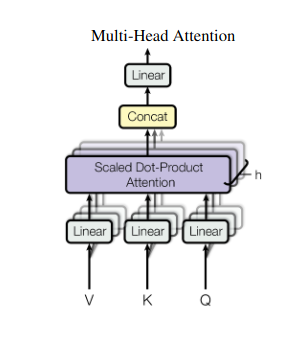
- Mitu "pead" luuakse, igaüks jälgib sisendjada läbi oma Q-, K- ja V-maatriksite.
- Iga juht õpib keskenduma andmete erinevatele aspektidele, nagu kaugsõltuvused, süntaktilised suhted või kohalikud sõnade vastasmõjud.
- Seejärel ühendatakse iga pea väljundid ja projitseeritakse lõplikuks esituseks, jäädvustades sisendi mitmetahulisuse.
See võimaldab mudelil samaaegselt kaaluda erinevaid vaatenurki, mis viib andmete rikkalikuma ja nüansirikkama mõistmiseni.
3. Rist-tähelepanu: sildade ehitamine järjestuste vahel
Võimalus mõista seoseid erinevate infokildude vahel on paljude NLP ülesannete jaoks ülioluline. Kujutage ette, et kirjutate raamatuarvustuse – te ei teeks teksti sõna-sõnalt kokkuvõtet, vaid tõmbaksite peatükkide lõikes arusaamu ja seoseid. Sisenema risttähelepanu, võimas mehhanism, mis loob sildu jadade vahel, andes mudelitele võimaluse kasutada teavet kahest erinevast allikast.
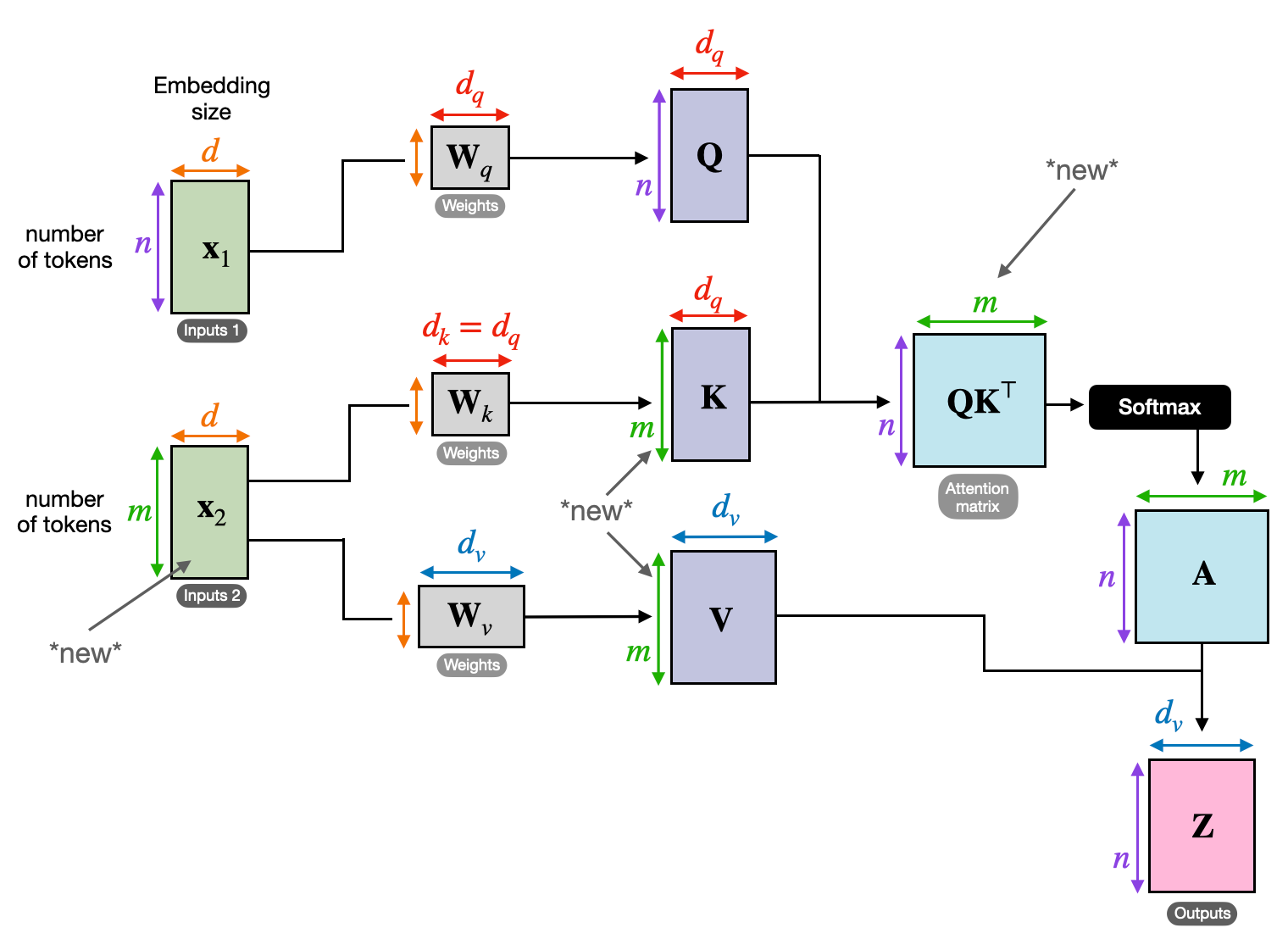
- Kodeerija-dekoodri arhitektuurides, nagu Transformers, on kodeerija töötleb sisendjada (raamatu) ja genereerib peidetud esituse.
- . dekooder kasutab risttähelepanu, et jälgida kodeerija peidetud esitust igal etapil väljundjada (ülevaate) loomisel.
- Dekoodri Q-maatriks suhtleb kodeerija K- ja V-maatriksitega, võimaldades tal keskenduda arvustuse iga lause kirjutamise ajal raamatu asjakohastele osadele.
See mehhanism on hindamatu selliste ülesannete jaoks nagu masintõlge, kokkuvõtete tegemine ja küsimustele vastamine, mille puhul on oluline mõista sisend- ja väljundjärjestuste vahelisi seoseid.
4. Põhjuslik tähelepanu: aja voolu säilitamine
Kujutage ette, et ennustate lause järgmist sõna ilma ette piilumata. Traditsioonilised tähelepanumehhanismid võitlevad ülesannetega, mis nõuavad teabe ajalise järjekorra säilitamist, nagu teksti genereerimine ja aegridade prognoosimine. Nad piiluvad järjestuses hõlpsalt ette, mis viib ebatäpsete ennustusteni. Põhjuslik tähelepanu kõrvaldab selle piirangu, tagades, et ennustused sõltuvad ainult eelnevalt töödeldud teabest.
See toimib järgmiselt
- Maskeerimismehhanism: Tähelepanu kaaludele rakendatakse spetsiifilist maski, mis blokeerib tõhusalt mudeli juurdepääsu jada tulevastele elementidele. Näiteks teise sõna ennustamisel "naine, kes..." saab mudel arvestada ainult "the" ja mitte "kes" või järgnevate sõnadega.
- Autoregressiivne töötlemine: Teave liigub lineaarselt, kusjuures iga elemendi esitus on üles ehitatud ainult enne seda ilmuvatest elementidest. Mudel töötleb jada sõna-sõnalt, genereerides ennustusi, mis põhinevad seni loodud kontekstil.
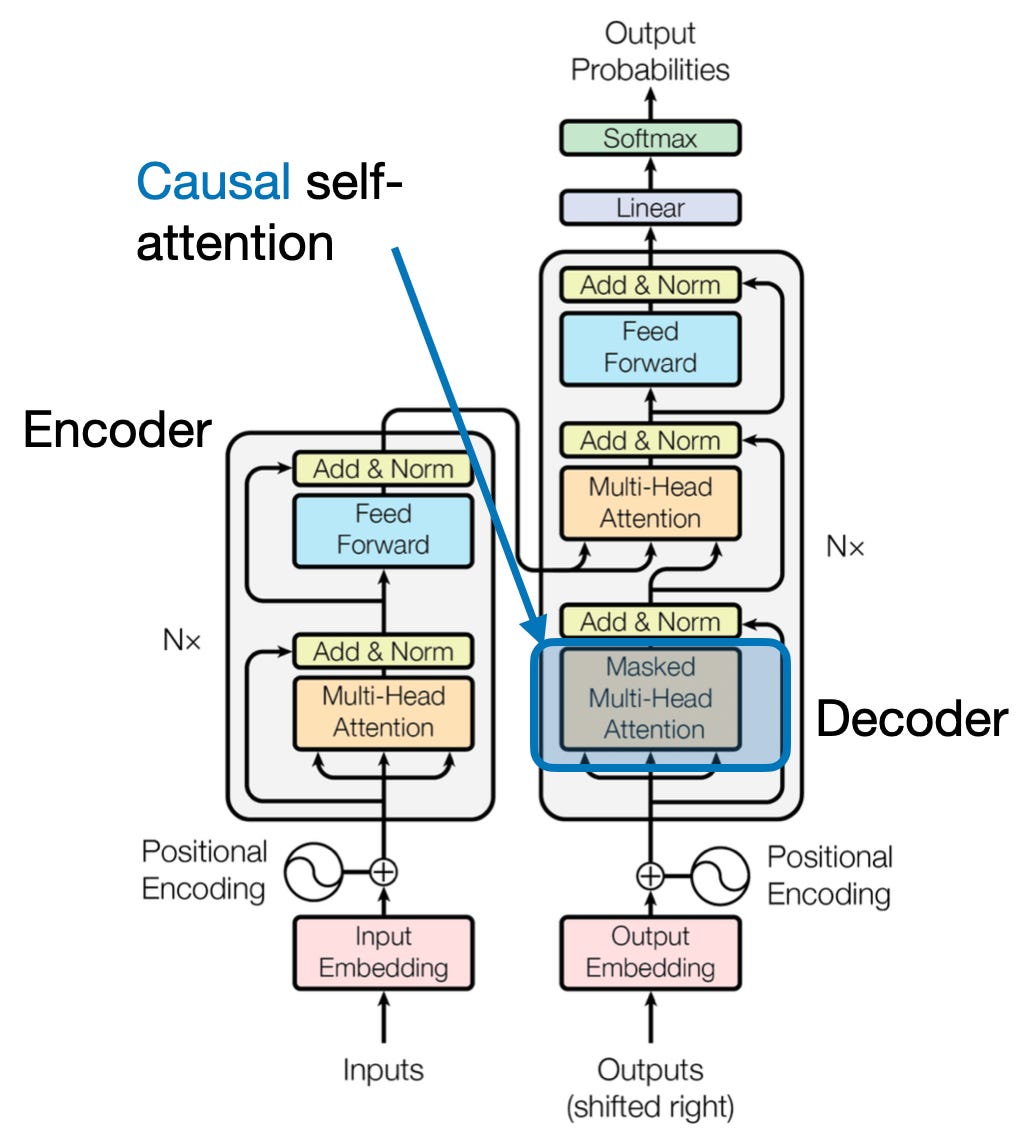
Põhjuslik tähelepanu on ülioluline selliste ülesannete puhul nagu teksti genereerimine ja aegridade prognoosimine, kus andmete ajalise järjekorra säilitamine on täpsete prognooside jaoks ülioluline.
5. Globaalne vs. kohalik tähelepanu: tasakaalu leidmine
Tähelepanumehhanismid seisavad silmitsi olulise kompromissiga: pikamaa sõltuvuste tabamine versus tõhusa arvutuse säilitamine. See väljendub kahes peamises lähenemisviisis: globaalset tähelepanu ja kohalik tähelepanu. Kujutage ette, et loete tervet raamatut, mitte keskendute konkreetsele peatükile. Globaalne tähelepanu töötleb korraga kogu jada, samas kui kohalik tähelepanu keskendub väiksemale aknale:
- Globaalne tähelepanu fikseerib pikamaa sõltuvused ja üldise konteksti, kuid võib pikkade jadade puhul olla arvutuslikult kulukas.
- Kohalik tähelepanu on tõhusam, kuid võib jääda ilma kaugetest suhetest.
Valik globaalse ja kohaliku tähelepanu vahel sõltub mitmest tegurist:
- Ülesande nõuded: Sellised ülesanded nagu masintõlge nõuavad kaugete suhete jäädvustamist, soodustades globaalset tähelepanu, samas kui meeleoluanalüüs võib soodustada kohaliku tähelepanu keskendumist.
- Järjestuse pikkus: Pikemad järjestused muudavad globaalse tähelepanu arvutuslikult kulukaks, mistõttu on vaja kohalikke või hübriidseid lähenemisviise.
- Mudeli mahutavus: Ressursipiirangud võivad nõuda kohalikku tähelepanu isegi globaalset konteksti nõudvate ülesannete puhul.
Optimaalse tasakaalu saavutamiseks võivad mudelid kasutada:
- Dünaamiline ümberlülitamine: kasutage globaalset tähelepanu põhielementidele ja kohalikku tähelepanu teistele, kohanedes tähtsuse ja kauguse alusel.
- Hübriidsed lähenemisviisid: kombineerige mõlemad mehhanismid samas kihis, kasutades nende vastavaid tugevusi.
Samuti loe: Närvivõrkude tüüpide analüüsimine süvaõppes
Järeldus
Lõppkokkuvõttes on ideaalne lähenemisviis globaalse ja kohaliku tähelepanu vahelisel spektril. Nende kompromisside mõistmine ja sobivate strateegiate vastuvõtmine võimaldab mudelitel asjakohast teavet tõhusalt kasutada erinevates skaalades, mis viib järjestuse rikkalikumaks ja täpsemaks mõistmiseni.
viited
- Raschka, S. (2023). "Enesetähelepanu, mitme peaga tähelepanu, risttähelepanu ja põhjusliku tähelepanu mõistmine ja kodeerimine LLM-ides."
- Vaswani, A. et al. (2017). "Tähelepanu on kõik, mida vajate."
- Radford, A. et al. (2019). "Keelemudelid on järelevalveta mitme ülesandega õppijad."
seotud
Olen andmesõber ja mulle meeldib andmete peidetud mustreid eraldada ja mõista. Soovin õppida ja kasvada masinõppe ja andmeteaduse valdkonnas.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :on
- :on
- :mitte
- : kus
- $ UP
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- võime
- juurdepääs
- täpsus
- täpne
- Saavutada
- saavutamisel
- üle
- õigusaktid
- tegelik
- aadressid
- Vastuvõtmine
- eespool
- AL
- Materjal: BPA ja flataatide vaba plastik
- Lubades
- võimaldab
- am
- Mitmetähenduslikkus
- summad
- an
- analüüs
- analüüse
- analüüsides
- ja
- vastamine
- lahus
- ilmne
- rakendatud
- lähenemine
- lähenemisviisid
- OLEME
- valdkondades
- artikkel
- AS
- aspektid
- assistent
- assistendid
- At
- osalema
- osalemine
- tähelepanu
- teadlikkus
- Saldo
- põhineb
- alus
- BE
- Laius
- muutuma
- enne
- vahel
- Peale
- blokeerimine
- raamat
- Raamatud
- mõlemad
- BRIDGE
- sillad
- Ere
- laiem
- tõi kaasa
- Ehitus
- Ehitab
- ehitatud
- kuid
- by
- tuli
- CAN
- lüüa
- lööb
- Püüdmine
- juhtudel
- muutma
- Peatükk
- peatükid
- valik
- lähemale
- Kodeerimine
- ühendama
- tuleb
- Ettevõtted
- ühilduvus
- keeruline
- arvutamine
- arvutuslik
- Võta meiega ühendust
- ühendamine
- Side
- Arvestama
- arvestades
- piiranguid
- sisaldab
- sisu
- kontekst
- jätkama
- tuum
- korrelatsioonid
- loodud
- loob
- loomine
- kriitiline
- otsustav
- Praegune
- andmed
- andmeteadus
- Dešifreerige
- sügav
- sügavam
- määratletud
- süveneb
- sõltuvad
- sõltuvus
- sõltuvused
- Sõltuvus
- sõltub
- üksikasjalik
- Dialoog
- DID
- erinev
- otse
- kaugus
- Kaugel
- eristatav
- mitu
- do
- dokument
- DOT
- kahekordistada
- kümneid
- dramaatiliselt
- juhtida
- kaks
- dünaamika
- E&T
- iga
- tõhusalt
- efektiivsus
- tõhus
- tõhusalt
- element
- elemendid
- volitamine
- võimaldab
- võimaldades
- kodeerimine
- rikastatud
- tagama
- tagades
- sisene
- Kogu
- tervikuna
- varustatud
- eriti
- olemus
- oluline
- põhiliselt
- asutatud
- Isegi
- Iga
- arenema
- täpselt
- kallis
- Ekspluateeri
- väljavõte
- nägu
- tegurid
- kaugele
- soodustama
- väli
- Valdkonnad
- lõplik
- voog
- Voolud
- Keskenduma
- keskendunud
- keskendub
- keskendumine
- eest
- esirinnas
- vormid
- Sihtasutus
- neli
- Raamistik
- Alates
- funktsioon
- funktsionaalsused
- tulevik
- mäng
- genereerib
- teeniva
- põlvkond
- Globaalne
- globaalses kontekstis
- haarake
- Kasvama
- juhendid
- suunav
- käepide
- Olema
- võttes
- juhataja
- aidates
- varjatud
- Suur
- rohkem
- esiletõstmine
- omab
- terviklikku
- Kuidas
- HTTPS
- inim-
- hübriid
- i
- ideaalne
- identifitseerima
- if
- kujutage ette
- Vahetu
- tähtsus
- oluline
- in
- ebatäpne
- kaasates
- näitama
- eraldi
- ebaefektiivne
- info
- olemuselt
- sisend
- teadmisi
- Näiteks
- Intelligentne
- ette nähtud
- suhtlemist
- interaktsioonid
- interaktiivne
- sekkumas
- sisse
- hindamatu
- isolatsioon
- IT
- ITS
- jpg
- lihtsalt
- Võti
- Võtmevaldkonnad
- keel
- viimane
- kiht
- juhtivate
- Õppida
- Õpi ja kasva
- õppijad
- õppimine
- Led
- KLAAS
- läätsed
- Finantsvõimendus
- võimendav
- Raamatukogu
- peitub
- valgus
- nagu
- piiramine
- piirangud
- kohalik
- Pikk
- enam
- Vaata
- armastus
- masin
- masinõpe
- masintõlge
- säilitamine
- tegema
- Tegemine
- mees
- palju
- mask
- maatriks
- max laiuse
- tähendus
- tähendused
- mõõdetud
- mehhanism
- mehhanismid
- Mälu
- võib
- miss
- puuduvad
- mudel
- mudelid
- rohkem
- tõhusam
- mitmetahuline
- mitmekordne
- Natural
- Loomulik keel
- Loomuliku keele genereerimine
- Natural Language Processing
- Loomuliku keele mõistmine
- loodus
- Vajadus
- vajav
- vajadustele
- naabrid
- võrgustikud
- Neural
- närvivõrgud
- Uus
- järgmine
- öö
- nlp
- nimisõnad
- nüüd
- nüansirikas
- of
- sageli
- on
- kunagi
- ainult
- optimaalselt
- or
- et
- Muu
- teised
- meie
- välja
- väljund
- väljundid
- üldine
- ülevaade
- enda
- lehekülg
- paar
- Paber
- Parallel
- osad
- lõigud
- minevik
- mustrid
- täitma
- jõudlus
- perspektiivid
- tükki
- Platon
- Platoni andmete intelligentsus
- PlatoData
- mängima
- Punkt
- tekitab
- valdab
- võimalused
- tugev
- potentsiaal
- potentsiaalselt
- võim
- võimas
- prognoosimine
- Ennustused
- säilitamine
- ennetada
- varem
- eelkõige
- esmane
- protsess
- töödeldud
- Protsessid
- töötlemine
- Töötlemise võimsus
- Toode
- Prognooside
- liikumapanev
- annab
- küsimus
- valik
- alates
- pigem
- Lugenud
- kergesti
- Lugemine
- reaalajas
- viide
- Sõltumata sellest
- Suhted
- suhteline
- asjakohasus
- asjakohane
- tähelepanuväärne
- esindamine
- esindavad
- esindab
- nõudma
- lahendama
- ressurss
- Vahendid
- need
- Tulemused
- läbi
- revolutsiooniline
- revolutsiooniliselt
- Rikas
- Roll
- s
- sama
- Sarkasm
- nägin
- Kaalud
- skaneerimine
- teadus
- skoor
- hinded
- Otsing
- Teine
- nägemine
- Lause
- tunne
- Jada
- Seeria
- teenib
- mitu
- Jaga
- särav
- shooting
- Lühike
- presentatsioon
- üheaegselt
- aeglane
- väiksem
- Ainult
- LAHENDAGE
- mõnikord
- Allikad
- Ruum
- konkreetse
- eriti
- spekter
- kiirused
- prožektor
- alaline
- täht
- Samm
- kauplustes
- strateegiad
- tugevused
- tugevam
- struktuur
- võitlus
- Võitlemine
- teema
- järgnev
- selline
- sobiv
- summa
- Kokku võtta
- KOKKUVÕTE
- parem
- ümbritsev
- süsteemid
- lahendada
- võtmine
- seinavaip
- ülesanded
- Tehniline
- termin
- tekst
- teksti genereerimine
- et
- .
- maailm
- oma
- Neile
- SIIS
- Need
- nad
- see
- kolm
- Läbi
- aeg
- Ajaseeria
- et
- tööriist
- traditsiooniline
- koolitus
- muundav
- ümber
- trafo
- trafod
- transformeerivate
- Tõlge
- tõsi
- kaks
- liigid
- lõpuks
- mõistma
- mõistmine
- kahtlemata
- avamine
- avalikustama
- Avalikustas
- kasutama
- kasutusalad
- kasutamine
- eri
- suur
- Versus
- vaade
- külastatud
- tähtis
- vs
- tahan
- tahab
- oli
- Hästi
- M
- millal
- kuigi
- WHO
- kogu
- lai
- Lai valik
- will
- aken
- koos
- jooksul
- ilma
- naine
- sõna
- sõnad
- Töö
- maailm
- kirjutamine
- eile
- sa
- sephyrnet
- ZOO