Pandas on võimas ja laialdaselt kasutatav avatud lähtekoodiga teek andmete töötlemiseks ja analüüsimiseks Pythoni abil. Üks selle põhifunktsioone on võime rühmitada andmeid, kasutades funktsiooni groupby, jagades DataFrame'i rühmadeks ühe või mitme veeru alusel ja rakendades seejärel igaühele neist erinevaid liitmisfunktsioone.

Pilt Unsplash
. groupby funktsioon on uskumatult võimas, kuna võimaldab suuri andmekogumeid kiiresti kokku võtta ja analüüsida. Näiteks saate rühmitada andmestiku konkreetse veeru järgi ja arvutada iga rühma ülejäänud veergude keskmise, summa või arvu. Andmete täpsemaks mõistmiseks saate rühmitada ka mitme veeru järgi. Lisaks võimaldab see rakendada kohandatud koondamisfunktsioone, mis võib olla väga võimas tööriist keerukate andmeanalüüsi ülesannete jaoks.
Sellest õpetusest saate teada, kuidas kasutada Pandas funktsiooni groupby, et rühmitada erinevat tüüpi andmeid ja teha erinevaid koondamistoiminguid. Selle õpetuse lõpuks peaksite saama seda funktsiooni kasutada andmete mitmel viisil analüüsimiseks ja kokkuvõtmiseks.
Mõisted võetakse arvesse, kui neid hästi harjutada, ja seda me järgmisena teemegi, st Pandade grupipõhise funktsiooniga käed külge panema. Soovitatav on kasutada a Jupyteri sülearvuti selle õpetuse jaoks, kuna näete iga etapi väljundit.
Loo näidisandmed
Importige järgmised teegid:
- Pandas: andmeraami loomiseks ja rühma rakendamiseks
- Random – To generate random data
- Pprint – To print dictionaries
import pandas as pd
import random
import pprint
Järgmisena initsialiseerime tühja andmeraami ja täidame iga veeru väärtused, nagu allpool näidatud:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Boonusnõuanne – puhtam viis sama ülesande tegemiseks on luua kõigi muutujate ja väärtuste sõnastik ning hiljem see andmeraamiks teisendada.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
Andmeraam näeb välja selline, nagu allpool näidatud. Selle koodi käitamisel mõned väärtused ei ühti, kuna kasutame juhuslikku valimit.
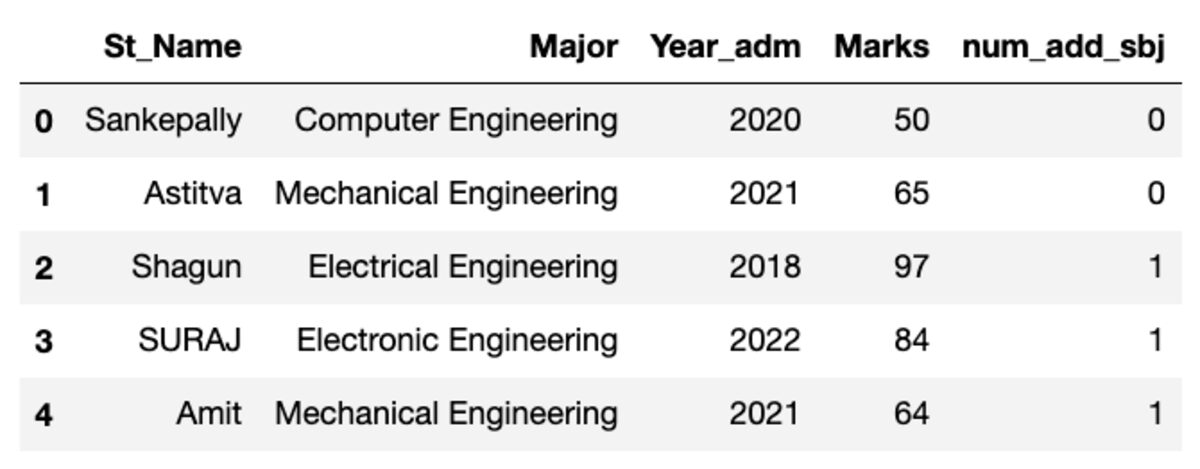
Gruppide tegemine
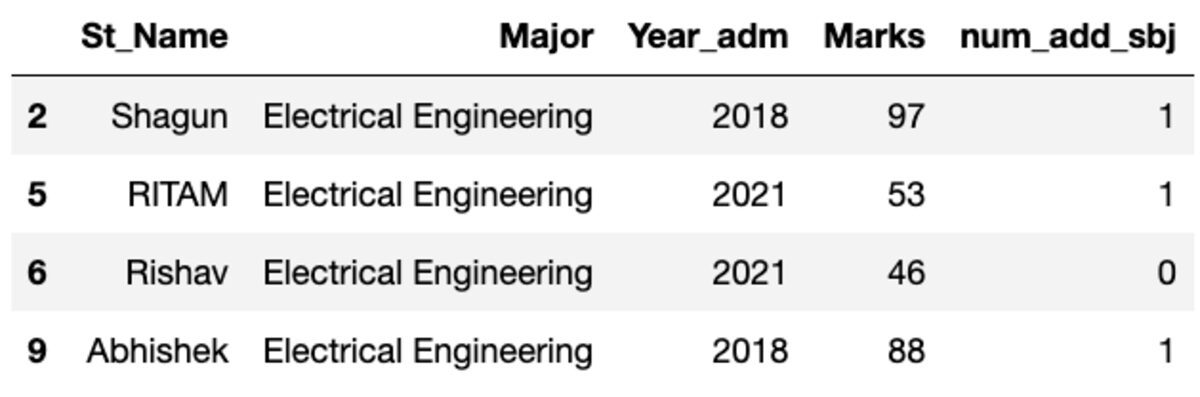
Rühmitame andmed teema „Põhi” järgi ja rakendame rühmafiltrit, et näha, kui palju kirjeid sellesse rühma kuuluvad.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Niisiis kuulub elektrotehnika erialale neli tudengit.
Saate rühmitada ka rohkem kui ühe veeru järgi (antud juhul Major ja num_add_sbj).
groups = df.groupby(['Major', 'num_add_sbj'])
Pange tähele, et kõiki koondfunktsioone, mida saab rakendada ühe veeruga rühmadele, saab rakendada mitme veeruga rühmadele. Ülejäänud õpetuses keskendume erinevat tüüpi koondamistele, kasutades näitena ühte veergu.
Loome rühmad, kasutades veerus “Major” valikut groupby.
groups = df.groupby('Major')Otseste funktsioonide rakendamine
Oletame, et soovite leida iga eriala keskmised hinded. Mida sa teeksid?
- Valige veerg Marks
- Rakenda keskmist funktsiooni
- Ümarfunktsiooni rakendamine märkide ümardamiseks kahe kümnendkohani (valikuline)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Agregeeritud
Teine võimalus sama tulemuse saavutamiseks on kasutada alltoodud koondfunktsiooni.
groups['Marks'].aggregate('mean').round(2)
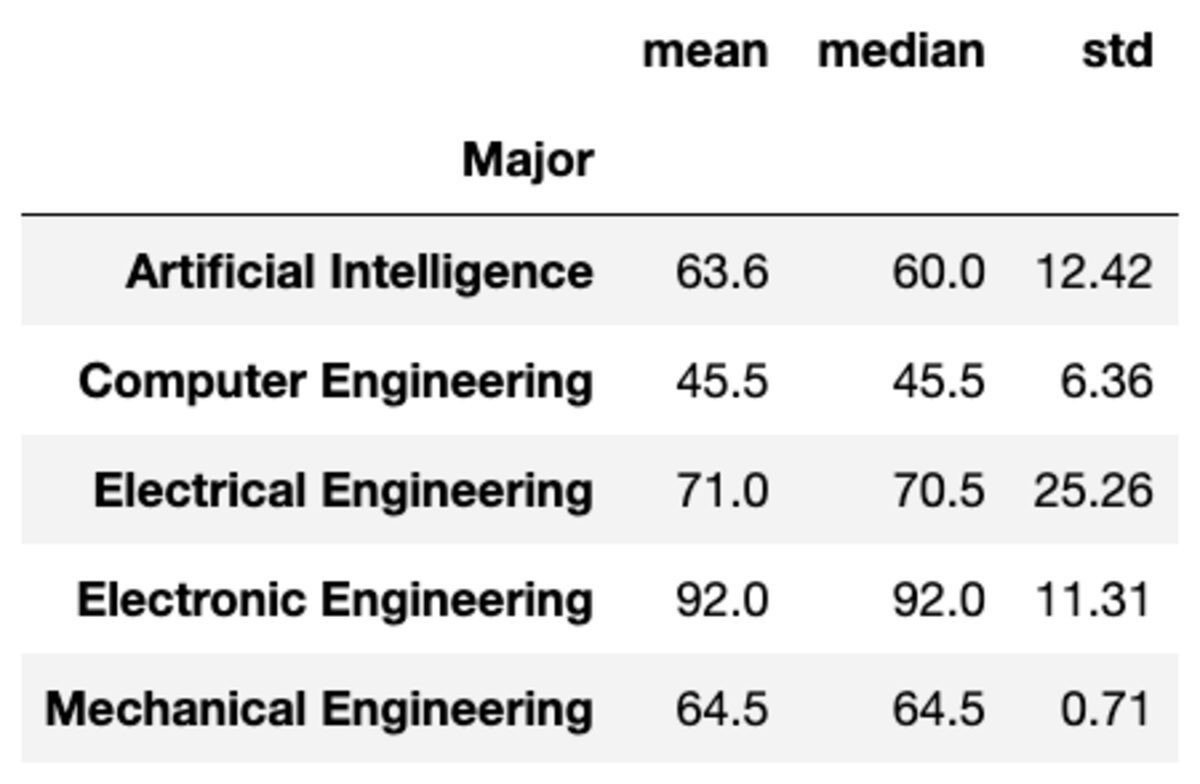
Samuti saate rühmadele rakendada mitut liitmist, edastades funktsioonid stringide loendina.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
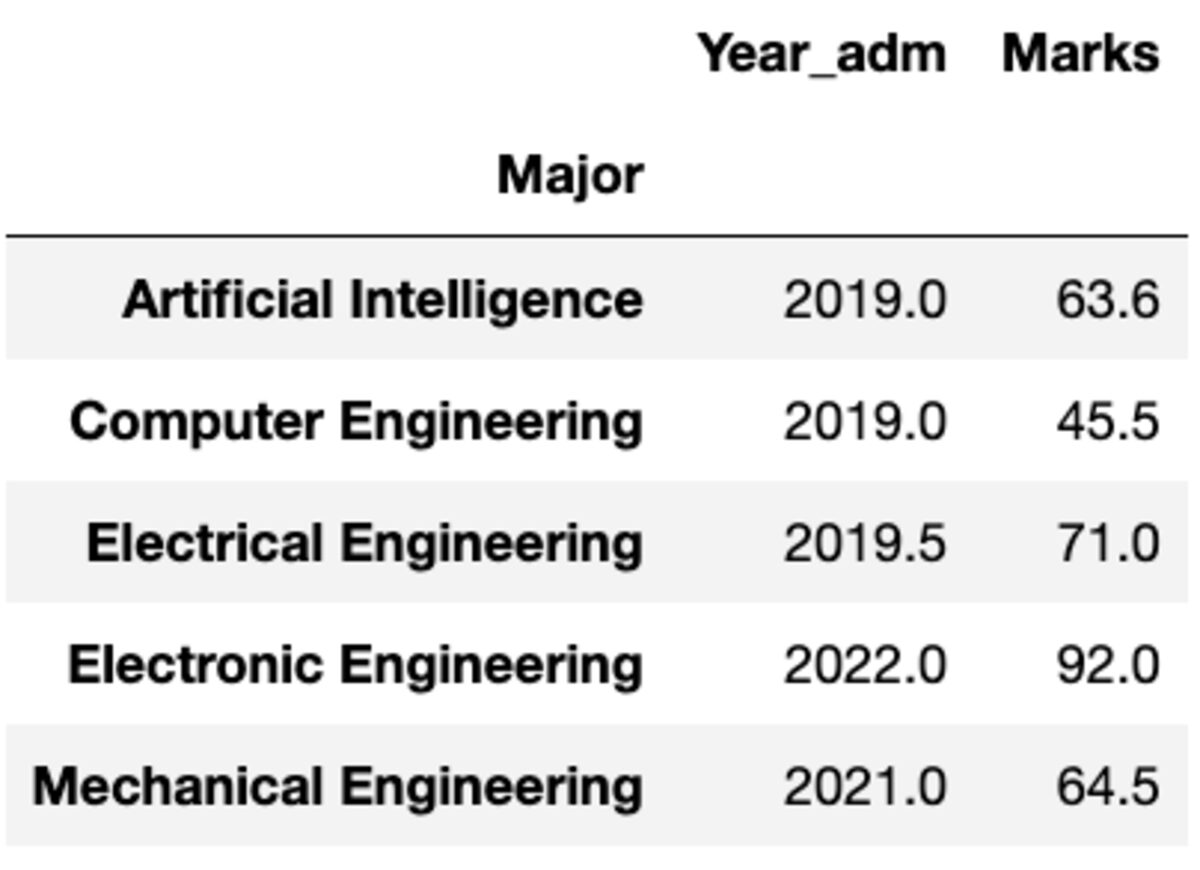
Aga mis siis, kui teil on vaja erinevale veerule rakendada teistsugust funktsiooni. Ära muretse. Seda saate teha ka paari {column:function} edastamisega.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Transformeerub
Võimalik, et peate tegema konkreetse veeru kohandatud teisendusi, mida saab hõlpsasti teha, kasutades groupby(). Defineerime standardskalaari, mis on sarnane sklearni eeltöötlusmoodulis saadaolevaga. Kõiki veerge saate teisendada, kutsudes välja teisendusmeetodi ja edastades kohandatud funktsiooni.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
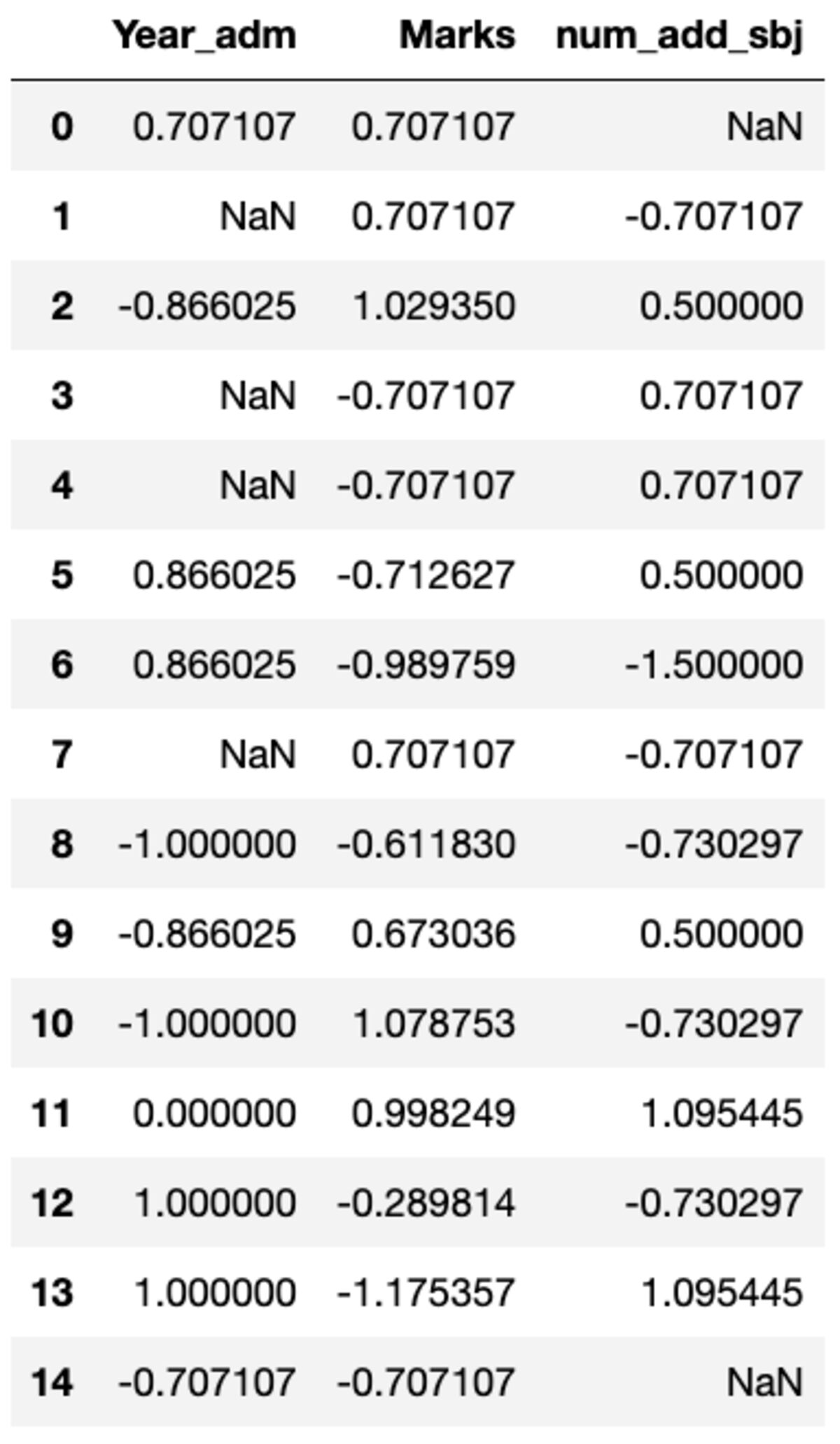
Pange tähele, et "NaN" tähistab null standardhälbega rühmi.
filtrid
Võib-olla soovite kontrollida, milline "Major" on halvem, st see, kus keskmine õpilase hind on alla 60. See nõuab filtrimeetodi rakendamist rühmadele, mille sees on funktsioon. Allpool olev kood kasutab a lambda funktsioon filtreeritud tulemuste saavutamiseks.
groups.filter(lambda x: x['Marks'].mean() 60)

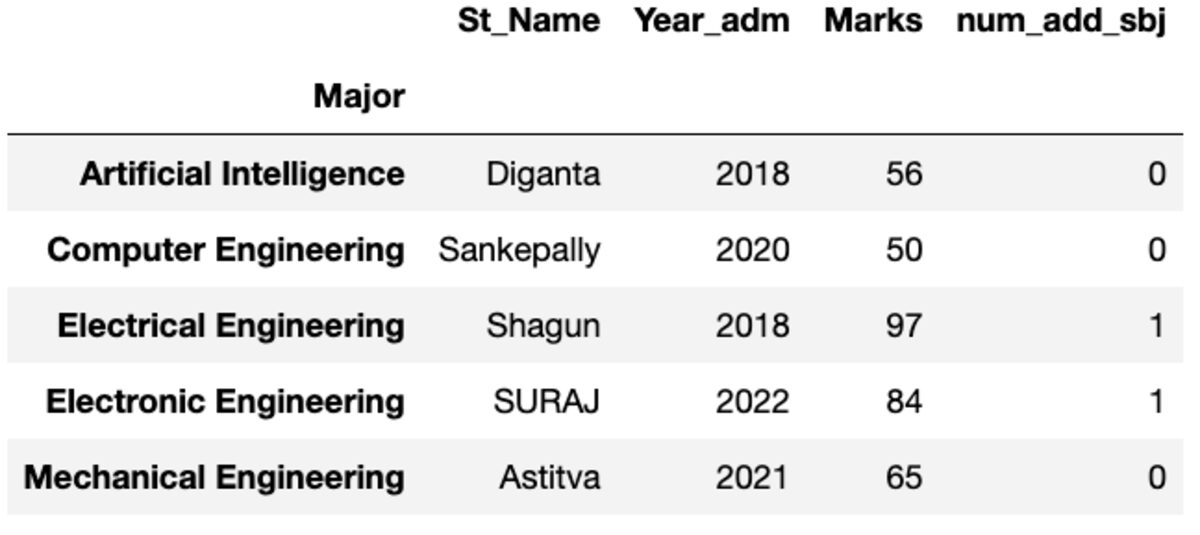
esimene
See annab teile selle esimese eksemplari, mis on sorteeritud indeksi järgi.
groups.first()
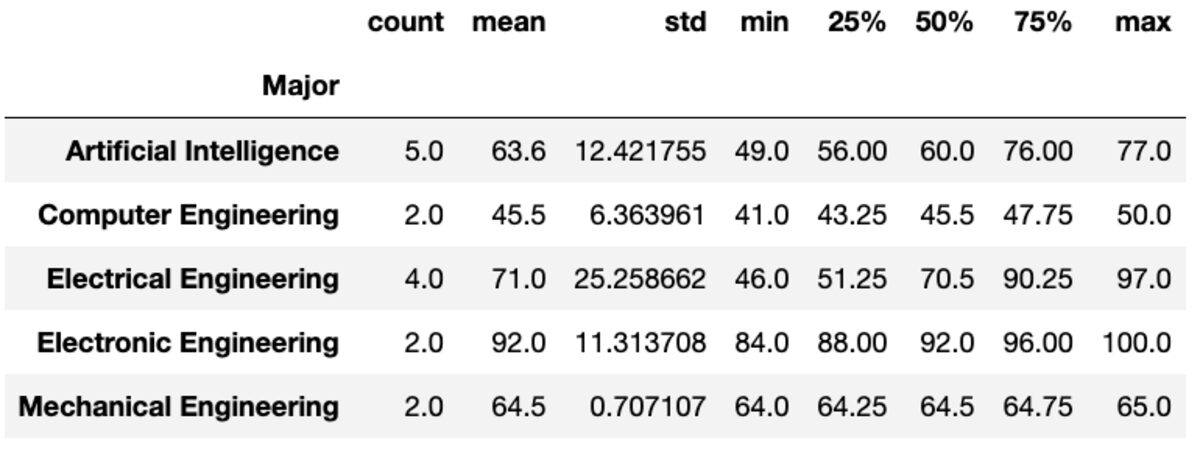
Kirjeldama
"Kirjeldamise" meetod tagastab antud veergude kohta põhistatistika, nagu arv, keskmine, std, min, max jne.
groups['Marks'].describe()
SUURUS
Suurus, nagu nimigi ütleb, tagastab iga grupi suuruse kirjete arvu järgi.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64Krahv ja Nunique
"Count" tagastab kõik väärtused, samas kui "Nunique" tagastab ainult selle rühma kordumatud väärtused.
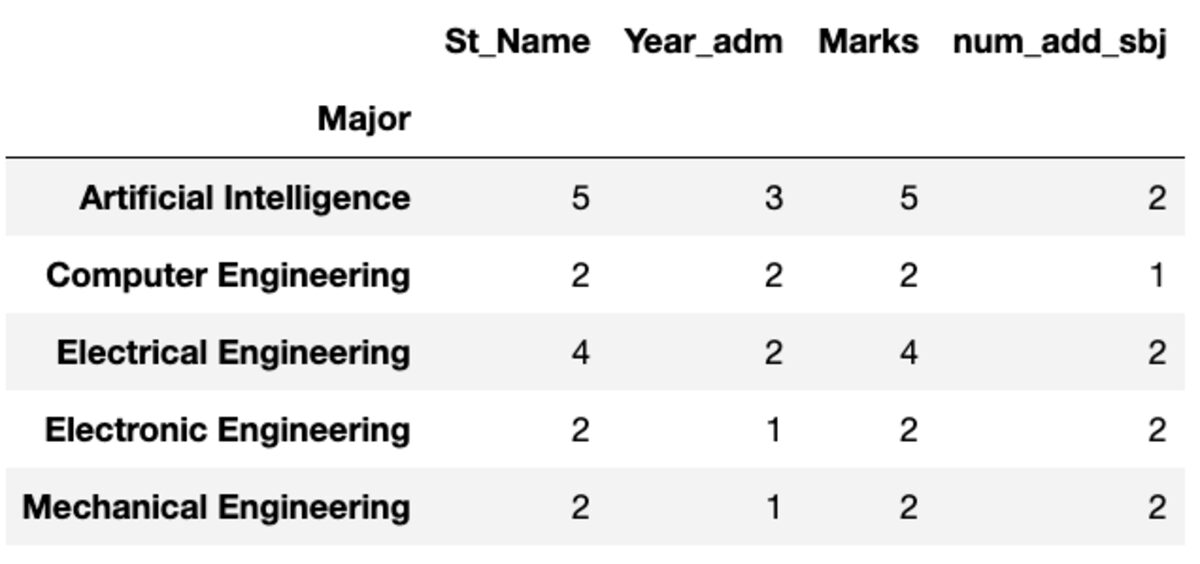
groups.count()
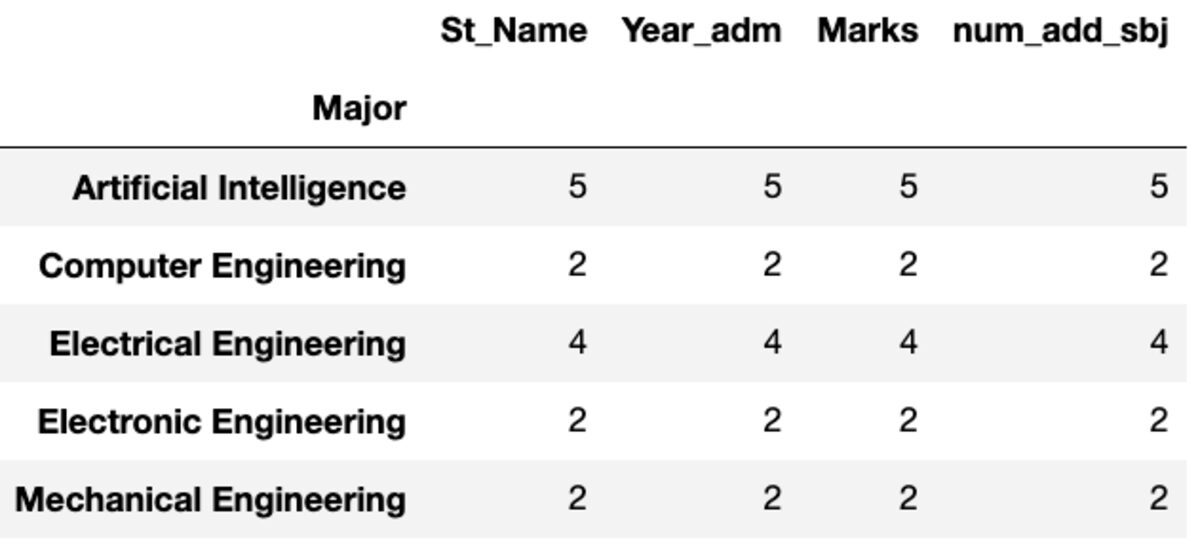
groups.nunique()
Nimeta
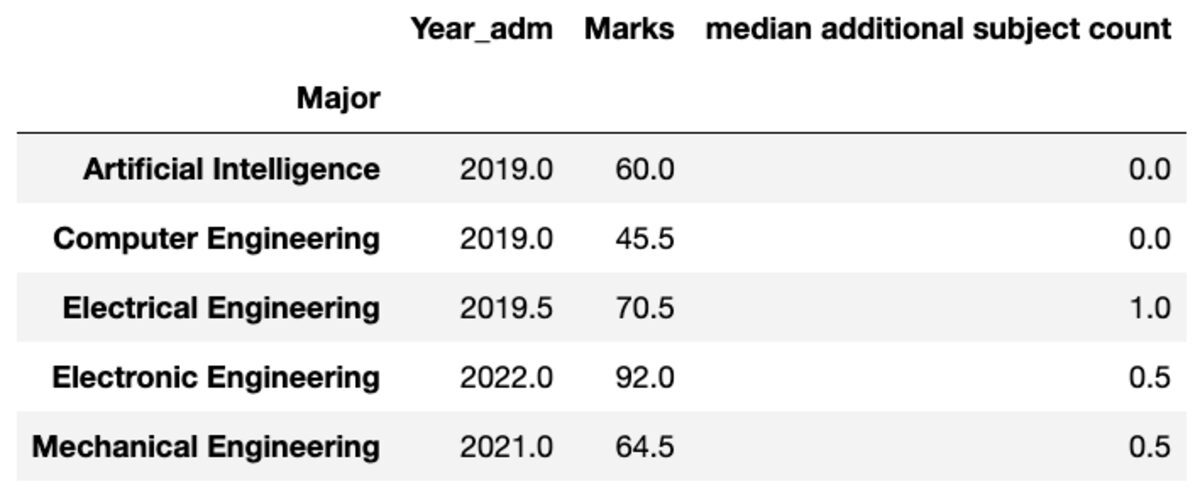
You can also rename the aggregated columns’ name as per your preference.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Tehke grupi eesmärk selgeks: Kas proovite rühmitada andmeid ühe veeru järgi, et saada teise veeru keskmine? Või proovite rühmitada andmeid mitme veeru järgi, et saada iga rühma ridade arv?
- Andmeraami indekseerimise mõistmine: Funktsioon groupby kasutab andmete rühmitamiseks indeksit. Kui soovite andmeid rühmitada veeru järgi, veenduge, et veerg oleks määratud indeksiks või võite kasutada .set_index()
- Kasutage sobivat koondfunktsiooni: Seda saab kasutada erinevate liitmisfunktsioonidega, nagu keskmine (), summa (), count (), min (), max ()
- Kasutage parameetrit as_index: Kui see on seatud väärtusele Väär, käsib see parameeter pandadel kasutada grupeeritud veerge indeksi asemel tavaliste veergudena.
Saate kasutada ka groupby() koos teiste pandafunktsioonidega, nagu pivot_table(), crosstab() ja cut(), et oma andmetest rohkem teavet hankida.
Groupby funktsioon on võimas tööriist andmete analüüsiks ja töötlemiseks, kuna see võimaldab teil rühmitada andmeridasid ühe või mitme veeru alusel ja seejärel teha rühmade kohta koondarvutusi. Õpetus demonstreeris koodinäidete abil erinevaid võimalusi groupby funktsiooni kasutamiseks. Loodetavasti annab see teile ülevaate erinevatest sellega kaasnevatest võimalustest ja ka sellest, kuidas need aitavad andmete analüüsimisel.
Vidhi Chugh on AI strateeg ja digitaalse ümberkujundamise juht, kes töötab toote, teaduse ja inseneriteaduste ristumiskohas, et luua skaleeritavaid masinõppesüsteeme. Ta on auhinnatud innovatsioonijuht, autor ja rahvusvaheline esineja. Tema ülesanne on demokratiseerida masinõpet ja murda kõnepruuki, et kõik saaksid sellest muutusest osa.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. Juurdepääs siia.
- Allikas: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- võime
- Võimalik
- Saavutada
- saavutada
- Täiendavad lisad
- Lisaks
- koondamine
- AI
- Materjal: BPA ja flataatide vaba plastik
- võimaldab
- analüüs
- analüüsima
- ja
- Teine
- rakendatud
- kehtima
- Rakendades
- asjakohane
- kunstlik
- tehisintellekti
- autor
- saadaval
- keskmine
- auhinnatud
- põhineb
- põhiline
- alla
- biotehnoloogia
- Murdma
- ehitama
- arvutama
- kutsudes
- juhul
- kontrollima
- selge
- kood
- Veerg
- Veerud
- Tulema
- keeruline
- arvuti
- Arvutitehnika
- looma
- loomine
- tava
- andmed
- andmete analüüs
- andmekogumid
- demokratiseerima
- Näidatud
- kõrvalekalle
- erinev
- digitaalne
- Digitaalne Transformation
- otsene
- Ära
- iga
- kergesti
- tõhusalt
- Elektrotehnika
- Elektrooniline
- Inseneriteadus
- jms
- igaüks
- näide
- näited
- väljavõte
- Langema
- FUNKTSIOONID
- täitma
- filtreerida
- leidma
- esimene
- Keskenduma
- Järel
- FRAME
- Alates
- funktsioon
- funktsioonid
- tekitama
- saama
- antud
- annab
- läheb
- Grupp
- Grupi omad
- käed-
- aitama
- lootus
- Kuidas
- Kuidas
- HTML
- HTTPS
- import
- in
- uskumatult
- indeks
- Innovatsioon
- teadmisi
- Näiteks
- selle asemel
- Intelligentsus
- rahvusvaheliselt
- ristmik
- IT
- erikeel
- KDnuggets
- Võti
- suur
- juht
- Õppida
- õppimine
- raamatukogud
- Raamatukogu
- nimekiri
- välimus
- masin
- masinõpe
- peamine
- tegema
- Manipuleerimine
- palju
- Vastama
- max
- mehaaniline
- masinaehitus
- keskmine
- meetod
- missioon
- moodul
- rohkem
- mitmekordne
- nimi
- nimed
- Vajadus
- järgmine
- number
- ONE
- avatud lähtekoodiga
- Operations
- Valikud
- Muu
- pandas
- parameeter
- osa
- eriline
- Mööduv
- täitma
- Kohad
- Platon
- Platoni andmete intelligentsus
- PlatoData
- võimas
- trükk
- Toode
- annab
- eesmärk
- Python
- kiiresti
- juhuslik
- soovitatav
- andmed
- regulaarne
- ülejäänud
- esindab
- Vajab
- REST
- kaasa
- Tulemused
- tagasipöördumine
- Tulu
- Richard
- ümber
- jooksmine
- sama
- skaalautuvia
- TEADUSED
- komplekt
- peaks
- näidatud
- sarnane
- ühekordne
- SUURUS
- mõned
- Kõneleja
- konkreetse
- standard
- statistika
- Samm
- Strateeg
- õpilane
- Õpilased
- teema
- Soovitab
- Kokku võtta
- süsteemid
- Ülesanne
- ülesanded
- ütleb
- tingimused
- .
- ots
- et
- tööriist
- Muutma
- Transformation
- muundumised
- juhendaja
- liigid
- mõistmine
- ainulaadne
- kasutama
- Väärtused
- eri
- kuidas
- M
- mis
- will
- töö
- oleks
- X
- aasta
- Sinu
- sephyrnet
- null








