Tänasel infoajastul kujutavad lugematutes dokumentides sisalduvad tohutud andmemahud ettevõtetele nii väljakutset kui ka võimalust. Traditsioonilised dokumenditöötlusmeetodid jäävad sageli alla tõhususe ja täpsuse osas, jättes ruumi uuendustele, kuluefektiivsusele ja optimeerimisele. Intelligentse dokumenditöötluse (IDP) tulekuga on dokumenditöötluses toimunud märkimisväärsed edusammud. IDP abil saavad ettevõtted muuta erinevat tüüpi dokumenditüüpide struktureerimata andmed struktureeritud ja teostatavateks ülevaadeteks, suurendades oluliselt tõhusust ja vähendades käsitsi tehtavaid jõupingutusi. Siiski potentsiaal sellega ei lõpe. Integreerides protsessi generatiivse tehisintellekti (AI), saame IRL-i võimalusi veelgi suurendada. Generatiivne AI ei paku mitte ainult täiustatud võimalusi dokumentide töötlemisel, vaid ka dünaamilist kohanemisvõimet muutuvate andmemustritega. See postitus viib teid läbi IDP ja generatiivse AI sünergia, paljastades, kuidas need esindavad dokumentide töötlemise järgmist piiri.
Me käsitleme IDP-d üksikasjalikult meie sarjas Arukas dokumenditöötlus AWS-i AI-teenustega (Osa 1 ja Osa 2). Selles postituses arutame, kuidas laiendada uut või olemasolevat IDP arhitektuuri suurte keelemudelitega (LLM). Täpsemalt arutame, kuidas saaksime integreeruda Amazoni tekst koos LangChain dokumendilaadurina ja Amazonase aluspõhi dokumentidest andmete eraldamiseks ja generatiivsete AI-võimaluste kasutamiseks IDP erinevates etappides.
Amazon Textract on masinõppeteenus (ML), mis eraldab skannitud dokumentidest automaatselt teksti, käsitsikirja ja andmed. Amazon Bedrock on täielikult hallatav teenus, mis pakub hõlpsasti kasutatavate API-de kaudu valikut suure jõudlusega alusmudeleid (FM-e).
Järgmine diagramm on kõrgetasemeline võrdlusarhitektuur, mis selgitab, kuidas saate IDP töövoogu vundamendimudelitega veelgi täiustada. LLM-e saate kasutada IDP ühes või kõigis faasides, olenevalt kasutusjuhtumist ja soovitud tulemusest.
Järgmistes jaotistes käsitleme üksikasjalikult, kuidas Amazon Textract integreeritakse generatiivsetesse AI töövoogudesse, kasutades LangChaini dokumentide töötlemiseks iga konkreetse ülesande jaoks. Siin esitatud koodiplokke on lühiduse huvides kärbitud. Vaadake meie GitHubi hoidla üksikasjalike Pythoni märkmike ja samm-sammulise ülevaate jaoks.
Dokumentidest teksti väljavõtmine on ülioluline aspekt dokumentide töötlemisel LLM-idega. Rakendust Amazon Textract saate kasutada dokumentidest struktureerimata toorteksti eraldamiseks ja originaalsete poolstruktureeritud või struktureeritud objektide (nt võtme-väärtuste paarid ja dokumendis olevad tabelid) säilitamiseks. Dokumendipaketid, nagu tervishoiu- ja kindlustusnõuded või hüpoteegid, koosnevad keerukatest vormidest, mis sisaldavad palju teavet struktureeritud, poolstruktureeritud ja struktureerimata vormingutes. Dokumentide ekstraheerimine on siin oluline samm, sest LLM-id saavad kasu rikkalikust sisust, et luua täpsemaid ja asjakohasemaid vastuseid, mis muidu võivad mõjutada LLM-ide väljundi kvaliteeti.
LangChain on võimas avatud lähtekoodiga raamistik LLM-idega integreerimiseks. LLM-id on üldiselt mitmekülgsed, kuid neil võib olla raskusi domeenispetsiifiliste ülesannetega, kus on vaja sügavamat konteksti ja nüansirikkaid vastuseid. LangChain annab selliste stsenaariumide arendajatele võimaluse luua agente, mis suudavad keerulised ülesanded väiksemateks alamülesanneteks jagada. Alamülesanded saavad seejärel lisada LLM-i konteksti ja mälu, ühendades ja aheldades LLM-i viipasid.
LangChain pakub dokumendilaadurid mis suudab dokumentidest andmeid laadida ja teisendada. Saate neid kasutada dokumentide struktureerimiseks eelistatud vormingutesse, mida saavad LLM-id töödelda. The AmazonTextractPDFLoader on teenuselaaduri tüüpi dokumendilaadur, mis pakub kiiret viisi dokumenditöötluse automatiseerimiseks, kasutades Amazon Textracti koos LangChainiga. Lisateabe saamiseks AmazonTextractPDFLoader, vaadake jaotist LangChain dokumentatsioon. Amazon Textracti dokumendilaaduri kasutamiseks importige see kõigepealt LangChaini teegist:
from langchain.document_loaders import AmazonTextractPDFLoaderhttps_loader = AmazonTextractPDFLoader("https://sample-website.com/sample-doc.pdf")
https_document = https_loader.load() s3_loader = AmazonTextractPDFLoader("s3://sample-bucket/sample-doc.pdf")
s3_document = s3_loader.load()Samuti saate Amazon S3-s dokumente salvestada ja neile viidata s3:// URL-i mustri abil, nagu on selgitatud Juurdepääs ämbrile, kasutades S3://ja edastage see S3 tee Amazon Textracti PDF-laadurile:
import boto3
textract_client = boto3.client('textract', region_name='us-east-2') file_path = "s3://amazon-textract-public-content/langchain/layout-parser-paper.pdf"
loader = AmazonTextractPDFLoader(file_path, client=textract_client)
documents = loader.load()Mitmeleheküljeline dokument sisaldab mitut lehekülge teksti, millele pääseb juurde dokumendiobjekti kaudu, mis on lehtede loend. Järgmine kood liigub läbi dokumendiobjekti lehtede ja prindib dokumendi teksti, mis on saadaval page_content atribuut:
print(len(documents)) for document in documents: print(document.page_content)Dokumentide klassifitseerimiseks saab tõhusalt kasutada Amazon Comprehendi ja LLM-e. Amazon Comprehend on loomuliku keele töötlemise (NLP) teenus, mis kasutab tekstist ülevaate saamiseks ML-i. Amazon Comprehend toetab ka kohandatud klassifitseerimismudelite koolitust koos paigutusteadlikkusega sellistes dokumentides nagu PDF-id, Word ja pildivormingud. Lisateavet Amazon Comprehendi dokumendiklassifikaatori kasutamise kohta leiate aadressilt Amazon Comprehend dokumendi klassifikaator lisab suurema täpsuse tagamiseks küljendustoe.
LLM-idega sidudes muutub dokumentide klassifikatsioon võimsaks lähenemisviisiks suurte dokumendimahtude haldamisel. LLM-id on abiks dokumentide klassifitseerimisel, kuna nad saavad analüüsida dokumendi teksti, mustreid ja kontekstuaalseid elemente, kasutades loomulikku keelt. Samuti saate neid täpsustada konkreetsete dokumendiklasside jaoks. Kui IDP-konveierisse lisatud uus dokumenditüüp vajab klassifitseerimist, saab LLM töödelda teksti ja kategoriseerida dokumendi klasside komplekti alusel. Järgnev on näidiskood, mis kasutab Amazon Textracti toel töötavat LangChaini dokumendilaadijat, et eraldada dokumendist teksti ja kasutada seda dokumendi klassifitseerimiseks. Me kasutame Antroopiline Claude v2 klassifikatsiooni tegemiseks Amazon Bedrocki kaudu.
Järgmises näites eraldame esmalt teksti patsiendi väljakirjutamise aruandest ja kasutame selle klassifitseerimiseks LLM-i, võttes arvesse kolme erinevat dokumenditüüpi.DISCHARGE_SUMMARY, RECEIPTja PRESCRIPTION. Järgmine ekraanipilt näitab meie aruannet.
from langchain.document_loaders import AmazonTextractPDFLoader
from langchain.llms import Bedrock
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain loader = AmazonTextractPDFLoader("./samples/document.png")
document = loader.load() template = """ Given a list of classes, classify the document into one of these classes. Skip any preamble text and just give the class name. <classes>DISCHARGE_SUMMARY, RECEIPT, PRESCRIPTION</classes>
<document>{doc_text}<document>
<classification>""" prompt = PromptTemplate(template=template, input_variables=["doc_text"])
bedrock_llm = Bedrock(client=bedrock, model_id="anthropic.claude-v2") llm_chain = LLMChain(prompt=prompt, llm=bedrock_llm)
class_name = llm_chain.run(document[0].page_content) print(f"The provided document is = {class_name}")
Kokkuvõte hõlmab antud teksti või dokumendi tihendamist lühemaks versiooniks, säilitades samal ajal selle põhiteabe. See meetod on kasulik tõhusaks teabeotsinguks, mis võimaldab kasutajatel kiiresti mõista dokumendi põhipunkte ilma kogu sisu lugemata. Kuigi Amazon Textract ei tee otseselt teksti kokkuvõtet, pakub see põhilisi võimalusi kogu teksti dokumentidest eraldamiseks. See ekstraheeritud tekst on sisendiks meie LLM-mudelisse teksti kokkuvõtete tegemiseks.
Kasutades sama tühjendusaruannet, kasutame AmazonTextractPDFLoader sellest dokumendist teksti eraldamiseks. Nagu varemgi, kasutame Amazon Bedrocki kaudu Claude v2 mudelit ja initsialiseerime selle viipaga, mis sisaldab juhiseid selle kohta, mida tekstiga teha (antud juhul kokkuvõtet). Lõpuks käivitame LLM-ahela, edastades dokumendilaadijast ekstraktitud teksti. See käivitab LLM-is järeldamistoimingu koos viipaga, mis koosneb kokkuvõtte tegemise juhistest ja dokumendi tekstist, mida tähistab Document. Vaadake järgmist koodi:
Kood loob patsiendi väljakirjutamise kokkuvõtliku aruande kokkuvõtte:
Eelmises näites kasutati kokkuvõtte tegemiseks üheleheküljelist dokumenti. Tõenäoliselt tegelete siiski dokumentidega, mis sisaldavad mitut lehekülge ja mis vajavad kokkuvõtet. Levinud viis mitmele lehele kokkuvõtete tegemiseks on esmalt koostada kokkuvõtted väiksematest tekstiosadest ja seejärel kombineerida väiksemaid kokkuvõtteid, et saada dokumendist lõplik kokkuvõte. Pange tähele, et see meetod nõuab LLM-ile mitu kõnet. Selle loogika saab hõlpsasti koostada; LangChain pakub aga sisseehitatud kokkuvõtete ahelat, mis suudab kokku võtta suuri tekste (mitmeleheküljelistest dokumentidest). Kokkuvõte võib toimuda mõlema kaudu map_reduce või stuff valikud, mis on saadaval mitme LLM-i kõne haldamiseks. Järgmises näites kasutame map_reduce mitmeleheküljelise dokumendi kokkuvõtte tegemiseks. Järgmine joonis illustreerib meie töövoogu.
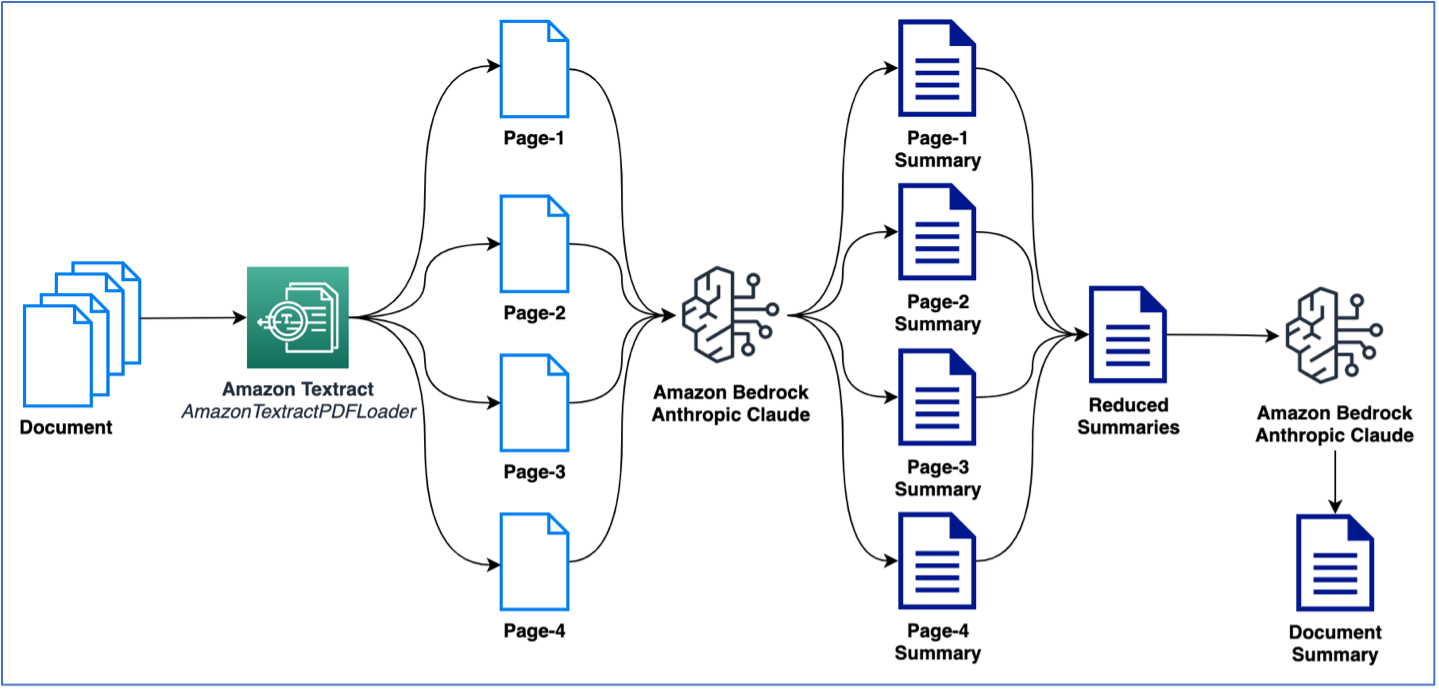
Alustuseks eraldame dokumendi ja vaatame žetoonide koguarvu lehekülje kohta ja lehekülgede koguarvu:
Järgmisena kasutame LangChaini sisseehitatud load_summarize_chain kogu dokumendi kokkuvõtteks:
from langchain.chains.summarize import load_summarize_chain summary_chain = load_summarize_chain(llm=bedrock_llm, chain_type='map_reduce')
output = summary_chain.run(document)
print(output.strip())Standardimine ning küsimused ja vastused
Selles jaotises käsitleme standardimist ning küsimuste ja vastuste ülesandeid.
Standardimine
Väljundi standardimine on teksti genereerimise ülesanne, mille puhul kasutatakse väljundteksti ühtse vormingu tagamiseks LLM-e. See ülesanne on eriti kasulik võtmeolemi ekstraheerimise automatiseerimiseks, mis nõuab väljundi joondamist soovitud vormingutega. Näiteks võime järgida kiireid inseneri parimaid tavasid, et viimistleda LLM-i, et vormindada kuupäevad KK/PP/AAAA vormingusse, mis võib ühilduda andmebaasi KUUPÄEV veeruga. Järgmine koodiplokk näitab näidet selle kohta, kuidas seda tehakse LLM-i ja kiire inseneri abil. Me mitte ainult ei standardiseeri kuupäevaväärtuste väljundvormingut, vaid palume mudelil genereerida lõplik väljund JSON-vormingus, et seda oleks lihtne kasutada ka meie järgnevates rakendustes. Me kasutame LangChaini väljenduskeel (LCEL) ühendada kaks tegevust. Esimene toiming palub LLM-il genereerida JSON-vormingus väljund ainult dokumendi kuupäevadest. Teine toiming võtab JSON-i väljundi ja standardib kuupäevavormingu. Pange tähele, et seda kaheastmelist toimingut saab teha ka ühes etapis õige kiire inseneritööga, nagu näeme normaliseerimisel ja mallimisel.
Eelneva koodinäidise väljundiks on JSON-struktuur kuupäevadega 07/09/2020 ja 08/09/2020, mis on vormingus DD/MM/YYYY ja on vastavalt patsiendi vastuvõtu ja haiglast lahkumise kuupäev. eelarve täitmise aruande koondaruande juurde.
Küsimused ja vastused koos otsingu laiendatud genereerimisega
On teada, et LLM-id säilitavad faktilist teavet, mida sageli nimetatakse nende maailmateadmiseks või maailmavaateks. Peenhäälestamisel võivad need anda tipptasemel tulemusi. Siiski on piiranguid, kui tõhusalt saab LLM neile teadmistele juurde pääseda ja nendega manipuleerida. Selle tulemusena ei pruugi ülesannete puhul, mis sõltuvad suuresti konkreetsetest teadmistest, olla nende toimivus teatud kasutusjuhtudel optimaalne. Näiteks küsimuste ja vastuste stsenaariumide puhul on oluline, et mudel järgiks rangelt dokumendis esitatud konteksti, tuginemata üksnes oma maailmateadmistele. Sellest kõrvalekaldumine võib põhjustada valeandmete esitamist, ebatäpsusi või isegi valesid vastuseid. Selle probleemi lahendamiseks kõige sagedamini kasutatav meetod on tuntud kui Täiustatud põlvkonna otsimine (RAG). See lähenemisviis sünergiseerib nii otsingumudelite kui ka keelemudelite tugevaid külgi, suurendades genereeritud vastuste täpsust ja kvaliteeti.
LLM-id võivad oma mälupiirangute ja kasutatava riistvara piirangute tõttu kehtestada ka märgipiiranguid. Selle probleemi lahendamiseks kasutatakse suurte dokumentide jagamiseks väiksemateks osadeks selliseid meetodeid nagu tükeldamine, mis mahuvad LLM-ide lubade piiridesse. Teisest küljest kasutatakse NLP-s manuseid peamiselt sõnade semantilise tähenduse ja nende suhete jäädvustamiseks teiste sõnadega suuremõõtmelises ruumis. Need manused muudavad sõnad vektoriteks, võimaldades mudelitel tekstiandmeid tõhusalt töödelda ja mõista. Mõistes sõnade ja fraaside vahelisi semantilisi nüansse, võimaldavad manustamine LLM-idel luua sidusaid ja kontekstipõhiseid väljundeid. Pange tähele järgmisi põhimõisteid:
- Raiumine – See protsess jagab suure hulga teksti dokumentidest väiksemateks sisukateks tekstilõikudeks.
- Manustamised – Need on iga tüki fikseeritud mõõtmetega vektorteisendused, mis säilitavad tükkide semantilise teabe. Need manustused laaditakse seejärel vektorandmebaasi.
- Vektori andmebaas – See on sõnade manustamise või vektorite andmebaas, mis esindab sõnade konteksti. See toimib teadmiste allikana, mis aitab NLP-ülesandeid dokumentide töötlemise torustikes. Vektorandmebaasi eeliseks on siin see, et see võimaldab teksti genereerimise ajal pakkuda LLM-idele ainult vajalikku konteksti, nagu selgitame järgmises jaotises.
RAG kasutab manustamist, et mõista ja tuua otsingufaasis asjakohaseid dokumendisegmente. Seda tehes saab RAG töötada LLM-ide piirangute piires, tagades, et genereerimiseks valitakse välja kõige asjakohasem teave, mille tulemuseks on täpsemad ja kontekstipõhised väljundid.
Järgmine diagramm illustreerib nende tehnikate integreerimist LLM-idele sisendi loomiseks, parandades nende konteksti mõistmist ja võimaldades asjakohasemaid kontekstisiseseid vastuseid. Üks lähenemisviis hõlmab sarnasuse otsingut, kasutades nii vektorandmebaasi kui ka tükeldamist. Vektorandmebaas salvestab semantilist teavet esindavaid manuseid ja tükeldamine jagab teksti hallatavateks osadeks. Kasutades seda sarnasuse otsingu konteksti, saavad LLM-id käivitada selliseid ülesandeid nagu küsimustele vastamine ja domeenispetsiifilised toimingud, nagu klassifitseerimine ja rikastamine.

Selle postituse puhul kasutame dokumentidega kontekstis küsimuste ja vastuste tegemiseks RAG-põhist lähenemist. Järgmises koodinäidis eraldame dokumendist teksti ja seejärel jagame dokumendi väiksemateks tekstilõikudeks. Tükeldamine on vajalik, kuna meil võivad olla suured mitmeleheküljelised dokumendid ja meie LLM-idel võivad olla märgipiirangud. Seejärel laaditakse need tükid vektorite andmebaasi, et järgmistes etappides sarnasusotsingut teha. Järgmises näites kasutame mudelit Amazon Titan Embed Text v1, mis teostab dokumenditükkide vektormanused:
Kood loob LLM-i jaoks asjakohase konteksti, kasutades vektorandmebaasist sarnasuse otsingutoiminguga tagastatud tekstitükke. Selle näite puhul kasutame avatud lähtekoodiga programmi FAISS vektorpood vektori näidisandmebaasina, et salvestada iga tekstitüki vektormanused. Seejärel määratleme vektorandmebaasi kui a LangChaini retriiver, mis kantakse edasi RetrievalQA kett. See käivitab sisemiselt vektorandmebaasis sarnasuse otsingupäringu, mis tagastab n (meie näites n = 3) tekstiosa, mis on küsimuse jaoks asjakohased. Lõpuks juhitakse LLM-i ahelat koos asjakohase kontekstiga (rühma asjakohaste tekstitükkidega) ja küsimusega, millele LLM peab vastama. RAG-iga seotud küsimuste ja vastuste samm-sammulise koodijuhise saamiseks vaadake Pythoni märkmikku aadressil GitHub.
FAISS-i alternatiivina võite kasutada ka Amazon OpenSearch Service'i vektorandmebaasi võimalused, Amazon Relational Database Service (Amazon RDS) PostgreSQL-i jaoks koos pgvector laiendust vektorandmebaasidena või avatud lähtekoodiga Chroma andmebaasina.
Küsimused ja vastused tabeliandmetega
Dokumentides sisalduvate tabeliandmete töötlemine võib nende struktuurse keerukuse tõttu osutuda LLM-i jaoks keeruliseks. Amazon Textracti saab täiendada LLM-idega, kuna see võimaldab eraldada dokumentidest tabeleid elementide (nt leht, tabel ja lahtrid) pesastatud vormingus. Tabeliandmetega küsimuste ja vastuste esitamine on mitmeetapiline protsess ja seda saab saavutada enesepäring. Järgnevalt on toodud sammude ülevaade.
- Tehke Amazon Textracti abil dokumentidest tabelid välja. Amazon Textracti abil saab dokumendist eraldada tabelistruktuuri (read, veerud, päised).
- Salvestage tabeliandmed vektorandmebaasi koos metaandmete teabega, nagu päise nimed ja iga päise kirjeldus.
- Kasutage viipa struktureeritud päringu koostamiseks, kasutades LLM-i, et tuletada tabelist andmed.
- Kasutage päringut vastavate tabeliandmete väljavõtmiseks vektorandmebaasist.
Näiteks pangakonto väljavõttes viipaga „Millised on tehingud, mille sissemakse on üle 1000 dollari” teeb LLM järgmised sammud.
- Koostage päring, nt
“Query: transactions” , “filter: greater than (Deposit$)”. - Teisendage päring struktureeritud päringuks.
- Rakendage struktureeritud päring vektorandmebaasi, kus meie tabeliandmed on salvestatud.
Küsimuste ja vastuste samm-sammulise näidiskoodi tabeliga tutvustuse saamiseks vaadake Pythoni märkmikku GitHub.
Mallimine ja normaliseerimised
Selles jaotises vaatleme, kuidas kasutada kiireid inseneritehnikaid ja LangChaini sisseehitatud mehhanismi, et luua väljund koos väljavõtetega dokumendist kindlas skeemis. Samuti teostame ekstraheeritud andmete standardimist, kasutades eelnevalt käsitletud tehnikaid. Alustuseks määratleme soovitud väljundi malli. See toimib skeemina ja sisaldab üksikasju iga üksuse kohta, mida soovime dokumendi tekstist eraldada.
Pange tähele, et iga olemi puhul kasutame kirjeldust, et selgitada, mis see olem on, et aidata LLM-il dokumendi tekstist väärtust eraldada. Järgmises näidiskoodis kasutame seda malli, et koostada LLM-i viip koos dokumendist eraldatud tekstiga, kasutades AmazonTextractPDFLoader ja seejärel teha mudeli põhjal järeldusi:
Nagu näete, siis {keys} osa viipast on meie malli võtmed ja {details} on võtmed koos nende kirjeldusega. Sel juhul ei küsi me mudelit sõnaselgelt väljundi vorminguga, välja arvatud juhises täpsustatud väljund JSON-vormingus genereerimiseks. See töötab enamasti; kuna aga LLM-ide väljund on mittedeterministlik tekstigenereerimine, tahame vormingu selgesõnaliselt määrata viipa juhiste osana. Selle lahendamiseks saame kasutada LangChaini struktureeritud väljundparser moodul, et kasutada ära automatiseeritud viipade projekteerimist, mis aitab teisendada meie malli vormingujuhiseks. Kasutame vormingujuhise loomiseks varem määratletud malli järgmiselt:
Seejärel kasutame seda muutujat oma algses viipas juhisena LLM-ile, et see eraldaks ja vormindaks väljundi soovitud skeemis, tehes meie viipa väikese muudatuse:
Seni oleme andmed dokumendist välja kaevanud ainult soovitud skeemis. Siiski peame siiski tegema mõningast standardimist. Näiteks soovime, et patsiendi vastuvõtukuupäev ja väljakirjutamise kuupäev eraldataks vormingus PP/KK/AAAA. Sel juhul suurendame description võti koos vormindamisjuhistega:
Vaadake Pythoni märkmikku GitHub täieliku samm-sammulise ülevaate ja selgituse saamiseks.
Õigekirjakontroll ja parandused
LLM-id on näidanud üles märkimisväärseid võimeid inimsarnase teksti mõistmisel ja genereerimisel. Üks vähem arutatud, kuid tohutult kasulikke LLM-ide rakendusi on nende potentsiaal grammatika kontrollimisel ja lausete parandamisel dokumentides. Erinevalt traditsioonilistest grammatikakontrollijatest, mis tuginevad eelnevalt määratletud reeglitele, kasutavad LLM-id mustreid, mille nad on tuvastanud suure hulga tekstiandmete põhjal, et teha kindlaks, mis on õige või ladus keel. See tähendab, et nad suudavad tuvastada nüansse, konteksti ja nüansse, mida reeglipõhised süsteemid võivad märkamata jätta.
Kujutage ette teksti, mis on välja võetud patsiendi väljakirjutamise kokkuvõttest, mis ütleb: „Patsiendi Jon Doe, kes võeti vastu raske kopsupõletikuga, paranemine on märgatav ja teda saab ohutult välja kirjutada. Järelkontrollid on kavandatud järgmisel nädalal. Traditsiooniline õigekirjakontroll võib vigadena ära tunda „admittd”, „pneumoonia”, „täiustused” ja „nex”. Nende vigade kontekst võib aga kaasa tuua täiendavaid vigu või üldisi soovitusi. LLM, kes on varustatud ulatusliku väljaõppega, võib soovitada: „Patsiendi John Doe, kes võeti vastu raske kopsupõletikuga, seisund on märgatavalt paranenud ja ta võib ohutult välja kirjutada. Järelkontrollid on kavandatud järgmisel nädalal."
Järgnev on halvasti käsitsi kirjutatud näidisdokument, millel on sama tekst, nagu eelnevalt selgitatud.

Eraldame dokumendi Amazon Textracti dokumendilaadijaga ja anname seejärel LLM-ile käsu parandada ekstraheeritud tekst, et parandada kõik kirja- ja/või grammatikavead:
Eelmise koodi väljund näitab originaalteksti, mille on eraldanud dokumendilaadija, millele järgneb LLM-i loodud parandatud tekst:
Pidage meeles, et nii võimsad kui ka LLM-id on, on oluline vaadata nende ettepanekuid just sellistena – soovitustena. Kuigi need tabavad muljetavaldavalt hästi keele keerukust, pole nad eksimatud. Mõned soovitused võivad muuta originaalteksti kavandatud tähendust või tooni. Seetõttu on ülioluline, et arvustajad kasutaksid LLM-i loodud parandusi juhisena, mitte absoluutsena. Inimese intuitsiooni koostöö LLM-i võimalustega tõotab tulevikku, kus meie kirjalik suhtlus pole mitte ainult vigadeta, vaid ka rikkalikum ja nüansirikkam.
Järeldus
Generatiivne AI muudab seda, kuidas saate dokumente IDP-ga töödelda, et saada teadmisi. Postituses AWS-i intelligentse dokumenditöötluse täiustamine generatiivse AI-ga, arutasime torujuhtme erinevaid etappe ja seda, kuidas AWS-i klient Ricoh täiustab oma IDP-konveieri LLM-idega. Selles postituses arutasime erinevaid mehhanisme IDP töövoo täiustamiseks LLM-idega Amazon Bedrocki, Amazon Textracti ja populaarse LangChaini raamistiku kaudu. Saate juba täna alustada uue Amazon Textracti dokumendilaadijaga LangChainiga, kasutades meie veebisaidil saadaolevaid näidismärkmikke. GitHubi hoidla. Lisateavet generatiivse AI-ga töötamise kohta AWS-is leiate aadressilt Teatame uutest tööriistadest generatiivse AI-ga ehitamiseks AWS-is.
Autoritest
 Sonali Sahu juhib intelligentset dokumenditöötlust koos AI/ML teenuste meeskonnaga AWS-is. Ta on autor, mõttejuht ja kirglik tehnoloog. Tema põhivaldkonnaks on AI ja ML ning ta esineb sageli AI ja ML konverentsidel ja kohtumistel üle maailma. Tal on nii laialdane kui ka sügav kogemus tehnoloogias ja tehnoloogiatööstuses ning tervishoiu, finantssektori ja kindlustuse valdkonnas.
Sonali Sahu juhib intelligentset dokumenditöötlust koos AI/ML teenuste meeskonnaga AWS-is. Ta on autor, mõttejuht ja kirglik tehnoloog. Tema põhivaldkonnaks on AI ja ML ning ta esineb sageli AI ja ML konverentsidel ja kohtumistel üle maailma. Tal on nii laialdane kui ka sügav kogemus tehnoloogias ja tehnoloogiatööstuses ning tervishoiu, finantssektori ja kindlustuse valdkonnas.
 Anjan Biswas on tehisintellektiteenuste lahenduste vanemarhitekt, kes keskendub tehisintellektile/ML-ile ja andmeanalüüsile. Anjan on osa ülemaailmsest AI-teenuste meeskonnast ja teeb koostööd klientidega, et aidata neil mõista ja arendada lahendusi tehisintellekti ja ML-ga seotud äriprobleemidele. Anjanil on üle 14-aastane globaalse tarneahela, tootmis- ja jaemüügiorganisatsioonidega töötamise kogemus ning ta aitab aktiivselt klientidel AWS-i tehisintellekti teenustega algust teha ja laiendada.
Anjan Biswas on tehisintellektiteenuste lahenduste vanemarhitekt, kes keskendub tehisintellektile/ML-ile ja andmeanalüüsile. Anjan on osa ülemaailmsest AI-teenuste meeskonnast ja teeb koostööd klientidega, et aidata neil mõista ja arendada lahendusi tehisintellekti ja ML-ga seotud äriprobleemidele. Anjanil on üle 14-aastane globaalse tarneahela, tootmis- ja jaemüügiorganisatsioonidega töötamise kogemus ning ta aitab aktiivselt klientidel AWS-i tehisintellekti teenustega algust teha ja laiendada.
 Chinmayee Rane on AI/ML spetsialistilahenduste arhitekt ettevõttes Amazon Web Services. Ta on kirglik rakendusmatemaatika ja masinõppe vastu. Ta keskendub intelligentse dokumenditöötluse ja generatiivsete AI-lahenduste kavandamisele AWS-i klientidele. Väljaspool tööd naudib ta salsat ja bachata tantsu.
Chinmayee Rane on AI/ML spetsialistilahenduste arhitekt ettevõttes Amazon Web Services. Ta on kirglik rakendusmatemaatika ja masinõppe vastu. Ta keskendub intelligentse dokumenditöötluse ja generatiivsete AI-lahenduste kavandamisele AWS-i klientidele. Väljaspool tööd naudib ta salsat ja bachata tantsu.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/intelligent-document-processing-with-amazon-textract-amazon-bedrock-and-langchain/
- :on
- :on
- :mitte
- : kus
- .nex
- $1000
- $ UP
- 1
- 10
- 100
- 11
- 12
- 13
- 14
- 15%
- 16
- 22
- 23
- 33
- 35%
- 7
- 9
- a
- võimeid
- MEIST
- absoluutne
- juurdepääs
- pääses
- Vastavalt
- täpsus
- täpne
- saavutada
- üle
- tegevus
- meetmete
- aktiivselt
- tegevus
- õigusaktid
- Ad
- aadress
- Lisab
- kinni pidama
- tunnistama
- tunnistas
- edusammud
- ADEelis
- Advent
- vanus
- ained
- AI
- AI teenused
- AI / ML
- joondatud
- Materjal: BPA ja flataatide vaba plastik
- Lubades
- võimaldab
- mööda
- Ka
- alternatiiv
- Kuigi
- Amazon
- Amazoni mõistmine
- Amazoni RDS
- Amazoni tekst
- Amazon Web Services
- summad
- an
- analytics
- analüüsima
- ja
- vastus
- Antroopne
- Antibiootikumid
- mistahes
- API-liidesed
- rakendused
- rakendatud
- Kohtumised
- lähenemine
- arhitektuur
- OLEME
- PIIRKOND
- ümber
- Kunst
- kunstlik
- tehisintellekti
- Tehisintellekt (AI)
- AS
- aspekt
- abistama
- assistent
- At
- suurendama
- suurendatud
- autor
- automatiseerima
- Automatiseeritud
- automaatselt
- Automaatika
- saadaval
- teadlikkus
- AWS
- AWS-i klient
- Pank
- BE
- sest
- muutub
- olnud
- enne
- kasulik
- kasu
- BEST
- parimaid tavasid
- vahel
- Blokeerima
- Plokid
- mõlemad
- laius
- Murdma
- puruneb
- ehitama
- Ehitus
- sisseehitatud
- äri
- ettevõtted
- kuid
- by
- Kutsub
- CAN
- Saab
- võimeid
- lüüa
- juhul
- juhtudel
- Rakke
- kindel
- kett
- ketid
- väljakutse
- raske
- muutma
- Vaidluste lahendamine
- muutuv
- Kontroll
- valik
- nõuete
- klass
- klassid
- klassifikatsioon
- Klassifitseerige
- kood
- SIDUS
- koostöö
- Veerg
- Veerud
- kombinatsioon
- ühendama
- tuleb
- ühine
- tavaliselt
- KOMMUNIKATSIOON
- kokkusobiv
- täitma
- keeruline
- keerukus
- mõista
- lühike
- konverentsid
- ühendamine
- järjepidev
- koosneb
- piiranguid
- ehitama
- sisaldama
- sisaldub
- sisaldab
- sisu
- kontekst
- kontekstuaalne
- muutma
- tuum
- parandada
- Parandatud
- Parandused
- võiks
- käsitöö
- meisterdatud
- loob
- otsustav
- tava
- klient
- Kliendid
- Dancing
- andmed
- Andmete analüüs
- andmebaas
- andmebaasid
- kuupäev
- Kuupäevad
- tegelema
- sügav
- sügavam
- määratlema
- määratletud
- määratlemisel
- Näidatud
- Olenevalt
- hoiused
- sügavus
- kirjeldatud
- kirjeldus
- projekteerimine
- soovitud
- detail
- üksikasjalik
- detailid
- avastama
- Määrama
- arendama
- Arendajad
- Dieet
- erinev
- otse
- arutama
- arutatud
- sukelduma
- jagama
- jagab
- do
- Arst
- dokument
- dokumentatsioon
- dokumendid
- DOE
- Ei tee
- teeme
- don
- tehtud
- Ära
- alla
- dramaatiliselt
- kaks
- ajal
- dünaamiline
- e
- iga
- Ajalugu
- kergesti
- lihtne-to-use
- tõhusalt
- efektiivsus
- tõhus
- tõhusalt
- jõupingutusi
- kumbki
- elemendid
- Embed
- töötavad
- annab volitusi
- võimaldama
- võimaldab
- võimaldades
- lõpp
- Inseneriteadus
- suurendama
- tõhustatud
- suurendamine
- tagama
- tagades
- Kogu
- üksuste
- üksus
- varustatud
- vead
- oluline
- Eeter (ETH)
- Isegi
- näide
- Välja arvatud
- erand
- olemasolevate
- kogemus
- teadmised
- Selgitama
- selgitas
- Selgitab
- selgitus
- selgesõnaliselt
- väljend
- laiendama
- laiendamine
- ulatuslik
- väljavõte
- kaevandamine
- Väljavõtted
- Fakt
- Langema
- vale
- kaugele
- väsimus
- Valdkonnad
- Joonis
- lõplik
- Lõpuks
- finants-
- Finantssektor
- esimene
- sobima
- Keskenduma
- keskendub
- järgima
- Järgneb
- Järel
- järgneb
- eest
- formaat
- vormid
- avastatud
- Sihtasutus
- Raamistik
- tasuta
- sageli
- Alates
- Piir
- täis
- täielikult
- edasi
- tulevik
- Üldine
- tekitama
- loodud
- genereerib
- teeniva
- põlvkond
- generatiivne
- Generatiivne AI
- saama
- Andma
- antud
- Globaalne
- Grammatika
- haarake
- suurem
- Grupp
- suunata
- käsi
- käepide
- juhtuda
- Juhtub
- riistvara
- Olema
- päised
- tervishoid
- tugevalt
- aitama
- kasulik
- aidates
- aitab
- siin
- siin
- kõrgetasemeline
- suure jõudlusega
- rohkem
- omab
- Haigla
- Kuidas
- Kuidas
- aga
- HTML
- HTTPS
- inim-
- i
- ID
- tuvastatud
- if
- illustreerib
- pilt
- tohutult
- mõju
- import
- oluline
- importivate
- kehtestama
- paranemine
- in
- Kaasa arvatud
- indeks
- tööstus
- info
- Infoajastu
- Innovatsioon
- sisend
- teadmisi
- Näiteks
- juhised
- kindlustus
- integreerima
- integreeritud
- Integreerimine
- integratsioon
- Intelligentsus
- Intelligentne
- Arukas dokumenditöötlus
- ette nähtud
- sisemiselt
- sisse
- nõtkused
- kehtestama
- sisse
- Tutvustab
- intuitsioon
- hõlmab
- IT
- ITS
- Jackson
- John
- JOHN DOE
- Jon
- jpg
- Json
- lihtsalt
- Võti
- võtmed
- Teadma
- teadmised
- teatud
- keel
- suur
- Layout
- viima
- juht
- juhtivate
- õppimine
- jätmine
- Raamatukogu
- nagu
- Tõenäoliselt
- piirangud
- piirid
- nimekiri
- koormus
- laadur
- loogika
- Vaata
- Partii
- masin
- masinõpe
- Tegemine
- juhtima
- juhitud
- juhtiv
- käsiraamat
- tootmine
- märgitud
- matemaatika
- mai..
- me
- tähendus
- tähendusrikas
- vahendid
- mehhanism
- mehhanismid
- kokkusaamistele
- Mälu
- Meta
- Metaandmed
- meetod
- meetodid
- võib
- meeles
- miss
- vigu
- ML
- mudel
- mudelid
- moodul
- rohkem
- hüpoteegid
- kõige
- mitmekordne
- nimi
- nimed
- Natural
- Loomulik keel
- Natural Language Processing
- Loomuliku keele mõistmine
- vajalik
- Vajadus
- vaja
- vajadustele
- Uus
- järgmine
- järgmine nädal
- nlp
- meeles
- märkmik
- märkmikud
- nüüd
- varjutamine
- number
- objekt
- esemeid
- of
- Pakkumised
- sageli
- on
- ONE
- ainult
- avatud lähtekoodiga
- Operations
- Võimalus
- optimaalselt
- Valikud
- or
- organisatsioonid
- originaal
- Muu
- muidu
- meie
- välja
- Tulemus
- väljund
- väljundid
- väljaspool
- üle
- ülevaade
- pakette
- lehekülg
- lehekülge
- Valu
- paaristatud
- paari
- osa
- eriti
- sooritama
- Vastu võetud
- Mööduv
- kirglik
- tee
- patsient
- Muster
- mustrid
- kohta
- täitma
- jõudlus
- teostatud
- esitades
- täidab
- faas
- phd
- fraasid
- torujuhe
- kava
- Platon
- Platoni andmete intelligentsus
- PlatoData
- palun
- kopsupõletik
- võrra
- populaarne
- võimalik
- post
- potentsiaal
- võim
- sisse
- võimas
- tavad
- täpselt
- Täpsus
- eelistatud
- esitada
- varem
- eelkõige
- trükk
- pildid
- Probleem
- probleeme
- protsess
- töödeldud
- töötlemine
- tootma
- Lubadused
- korralik
- anda
- tingimusel
- tarnija
- annab
- Python
- Küsimused ja vastused
- kvaliteet
- küsimus
- Kiire
- kiiresti
- Töötlemata
- Lugemine
- tunnistama
- vähendamine
- viitama
- viide
- nimetatud
- Suhted
- asjakohane
- lootma
- tuginedes
- tähelepanuväärne
- aru
- esindama
- esindavad
- nõutav
- Vajab
- vastavalt
- vastuste
- piirangud
- kaasa
- tulemuseks
- Tulemused
- jaemüük
- säilitama
- säilitamine
- Tulu
- Rikas
- ruum
- eeskirjade
- jooks
- jookseb
- s
- ohutult
- sama
- ütlema
- Skaala
- stsenaariumid
- plaanitud
- Otsing
- Teine
- Osa
- lõigud
- sektor
- vaata
- segmendid
- väljavalitud
- vanem
- Lause
- Seeria
- teenima
- teenib
- teenus
- Teenused
- komplekt
- raske
- ta
- Lühike
- peaks
- näidatud
- Näitused
- märkimisväärne
- ühekordne
- väike
- väiksem
- jupp
- So
- Ainult
- Lahendused
- LAHENDAGE
- mõned
- allikas
- Ruum
- Räägib
- spetsialist
- konkreetse
- eriti
- määratletud
- õigekiri
- jagada
- etappidel
- standardimine
- algus
- alustatud
- modernne
- väljavõte
- Samm
- Sammud
- Veel
- salvestada
- ladustatud
- kauplustes
- tugevused
- nöör
- struktuuriline
- struktuur
- struktureeritud
- võitlus
- järgnev
- Järgnevalt
- selline
- soovitama
- Kokku võtta
- KOKKUVÕTE
- varustama
- tarneahelas
- toetama
- Toetab
- sünergia
- süsteemid
- T
- tabel
- Võtma
- võtab
- Ülesanne
- ülesanded
- meeskond
- tehnika
- tehnikat
- tehnoloog
- Tehnoloogia
- šabloon
- tingimused
- tekst
- teksti genereerimine
- tekstiline
- kui
- et
- .
- maailm
- oma
- Neile
- SIIS
- Seal.
- seetõttu
- Need
- nad
- see
- arvasin
- kolm
- Läbi
- Titan
- et
- täna
- tänane
- kokku
- sümboolne
- märgid
- TONE
- töövahendid
- ülemine
- Summa
- traditsiooniline
- koolitus
- Tehingud
- Muutma
- muundumised
- tõsi
- püüdma
- kaks
- tüüp
- liigid
- mõistma
- mõistmine
- erinevalt
- avamine
- URL
- kasutama
- kasutage juhtumit
- Kasutatud
- Kasutajad
- kasutusalad
- kasutamine
- kasutatud
- kasutades
- v1
- väärtus
- Väärtused
- muutuja
- eri
- suur
- mitmekülgne
- versioon
- kaudu
- vaade
- mahud
- läbikäiguks
- tahan
- oli
- Tee..
- we
- web
- veebiteenused
- nädal
- Hästi
- M
- millal
- mis
- kuigi
- WHO
- will
- koos
- jooksul
- ilma
- tunnistajaks
- sõna
- sõnad
- Töö
- töövoog
- Töövoogud
- töö
- töötab
- maailm
- oleks
- kirjalik
- X
- aastat
- sa
- sephyrnet