Täna on meil hea meel teatada, et Laama valvur mudel on nüüd klientidele saadaval Amazon SageMaker JumpStart. Llama Guard pakub sisend- ja väljundkaitseid suure keelemudeli (LLM) juurutamisel. See on üks Purple Llama, Meta algatuse komponentidest, mis sisaldab avatud usaldus- ja ohutustööriistu ning hinnanguid, mis aitavad arendajatel AI-mudeleid vastutustundlikult kasutada. Purple Llama koondab tööriistad ja hinnangud, mis aitavad kogukonnal generatiivsete AI mudelite abil vastutustundlikult üles ehitada. Esialgne väljalase keskendub küberturvalisusele ning LLM-i sisend- ja väljundkaitsemeetmetele. Purple Llama projekti komponendid, sealhulgas mudel Llama Guard, on litsentsitud, võimaldades nii uurimistööd kui ka ärilist kasutamist.
Nüüd saate SageMaker JumpStartis kasutada mudelit Llama Guard. SageMaker JumpStart on masinõppe (ML) keskus Amazon SageMaker mis pakub juurdepääsu alusmudelitele lisaks sisseehitatud algoritmidele ja täielikele lahendusmallidele, mis aitavad teil ML-iga kiiresti alustada.
Selles postituses käsitleme Llama Guard mudeli juurutamist ja vastutustundlike generatiivsete AI-lahenduste loomist.
Laama Guard mudel
Llama Guard on Meta uus mudel, mis pakub sisend- ja väljundpiirdeid LLM-i juurutamiseks. Llama Guard on avalikult saadaval olev mudel, mis toimib konkurentsivõimeliselt tavaliste avatud etalonide alusel ja pakub arendajatele eelkoolitatud mudelit, mis aitab kaitsta potentsiaalselt riskantsete väljundite eest. Seda mudelit on koolitatud avalikult kättesaadavate andmekogumite põhjal, et võimaldada tuvastada levinumaid potentsiaalselt riskantse või rikkuva sisu tüüpe, mis võivad olla olulised mitme arendaja kasutusjuhtumi puhul. Lõppkokkuvõttes on mudeli visioon võimaldada arendajatel seda mudelit kohandada, et toetada asjakohaseid kasutusjuhtumeid ning muuta parimate tavade kasutuselevõtt ja avatud ökosüsteemi täiustamine lihtsaks.
Llama Guardi saab kasutada täiendava tööriistana, et arendajad saaksid integreerida oma leevendusstrateegiatesse, nagu vestlusrobotid, sisu modereerimine, klienditeenindus, sotsiaalmeedia jälgimine ja haridus. Edastades kasutajate loodud sisu enne avaldamist või sellele vastamist Llama Guardi kaudu, saavad arendajad märgistada ebaturvalise või sobimatu keelekasutusse ning võtta meetmeid turvalise ja lugupidava keskkonna säilitamiseks.
Uurime, kuidas saame SageMaker JumpStartis mudelit Llama Guard kasutada.
Vundamendi mudelid SageMakeris
SageMaker JumpStart pakub juurdepääsu paljudele mudelitele populaarsetest mudelikeskustest, sealhulgas Hugging Face, PyTorch Hub ja TensorFlow Hub, mida saate kasutada SageMakeri ML-i arendamise töövoo raames. Hiljutised edusammud ML-is on toonud kaasa uue mudelite klassi, mida tuntakse kui vundamendi mudelid, mis on tavaliselt koolitatud miljarditele parameetritele ja on kohandatavad laia kategooria kasutusjuhtumitega, nagu teksti kokkuvõte, digitaalse kunsti genereerimine ja keele tõlkimine. Kuna nende mudelite koolitamine on kallis, soovivad kliendid kasutada olemasolevaid eelkoolitatud vundamendimudeleid ja neid vastavalt vajadusele peenhäälestada, mitte neid mudeleid ise koolitada. SageMaker pakub kureeritud mudelite loendit, mille hulgast saate SageMakeri konsoolil valida.
Nüüd leiate SageMaker JumpStartist erinevate mudelipakkujate vundamendimudeleid, mis võimaldavad teil vundamendimudelitega kiiresti alustada. Saate leida vundamendimudeleid, mis põhinevad erinevatel ülesannetel või mudelipakkujatel, ning hõlpsasti vaadata üle mudeli omadused ja kasutustingimused. Saate neid mudeleid proovida ka kasutajaliidese testvidina abil. Kui soovite vundamendimudelit mastaapselt kasutada, saate seda hõlpsalt teha SageMakerist lahkumata, kasutades mudelipakkujate eelehitatud märkmikke. Kuna mudeleid hostitakse ja juurutatakse AWS-is, võite olla kindel, et teie andmeid, olenemata sellest, kas neid kasutatakse mudeli hindamiseks või ulatuslikuks kasutamiseks, ei jagata kunagi kolmandate osapooltega.
Uurime, kuidas saame SageMaker JumpStartis mudelit Llama Guard kasutada.
Avastage Llama Guard mudel SageMaker JumpStartis
Code Llama alusmudelitele pääsete juurde SageMakeri JumpStarti kaudu SageMaker Studio kasutajaliideses ja SageMaker Python SDK-s. Selles jaotises räägime sellest, kuidas mudeleid avastada Amazon SageMaker Studio.
SageMaker Studio on integreeritud arenduskeskkond (IDE), mis pakub ühtset veebipõhist visuaalset liidest, kus pääsete juurde sihipäraselt loodud tööriistadele, et sooritada kõiki ML-i arendusetappe alates andmete ettevalmistamisest kuni ML-mudelite loomise, koolitamise ja juurutamiseni. Lisateavet SageMaker Studio alustamise ja seadistamise kohta leiate aadressilt Amazon SageMaker Studio.
SageMaker Studios pääsete juurde SageMaker JumpStartile, mis sisaldab eelkoolitatud mudeleid, märkmikke ja eelehitatud lahendusi. Eelehitatud ja automatiseeritud lahendused.
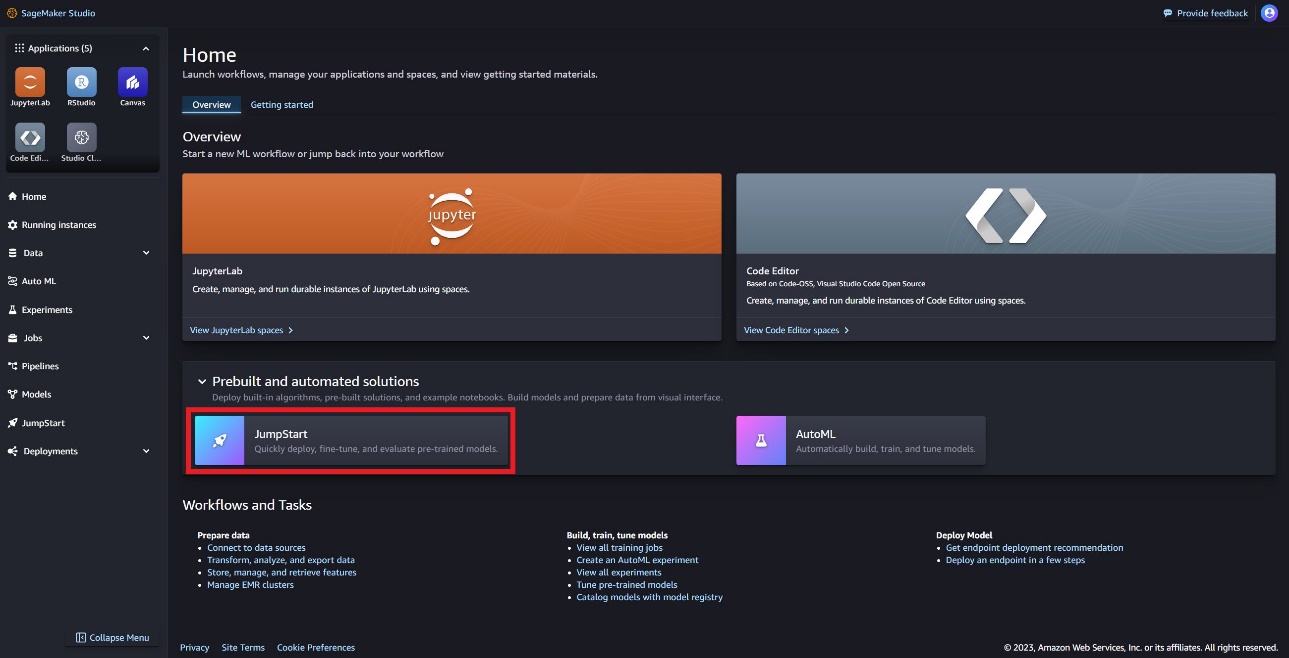
SageMaker JumpStarti sihtlehel leiate mudeli Llama Guard, valides Meta jaoturi või otsides Llama Guard.

Saate valida mitmesuguste Llama mudelite variantide hulgast, sealhulgas Llama Guard, Llama-2 ja Code Llama.

Saate valida mudelikaardi, et vaadata mudeli üksikasju, nagu litsents, koolituseks kasutatud andmed ja kasutusviis. Samuti leiate a juurutada valik, mis viib teid sihtlehele, kus saate testida järeldusi kasuliku koormuse näite abil.

Juurutage mudel SageMaker Python SDK-ga
Koodi, mis näitab Llama Guardi juurutamist Amazon JumpStartis, ja näite selle kohta, kuidas kasutada juurutatud mudelit see GitHubi märkmik.
Järgmises koodis määrame SageMakeri mudeli jaoturi mudeli ID ja mudeli versiooni, mida kasutatakse Llama Guardi juurutamisel:
Nüüd saate mudeli juurutada, kasutades SageMaker JumpStart. Järgmine kood kasutab järelduse lõpp-punkti jaoks vaikeeksemplari ml.g5.2xlarge. Saate mudeli juurutada muudele eksemplaritüüpidele, kui annate edasi instance_type aasta JumpStartModel klass. Juurutamine võib võtta mõne minuti. Edukaks juurutamiseks peate käsitsi muutma accept_eula argument mudeli juurutusmeetodis True.
See mudel on juurutatud teksti genereerimise järelduse (TGI) süvaõppe konteineri abil. Järelduspäringud toetavad paljusid parameetreid, sealhulgas järgmist:
- max_pikkus – Mudel genereerib teksti, kuni väljundi pikkus (mis sisaldab sisendkonteksti pikkust) jõuab
max_length. Kui see on määratud, peab see olema positiivne täisarv. - max_uued_märgid – Mudel genereerib teksti, kuni väljundi pikkus (välja arvatud sisendkonteksti pikkus) jõuab
max_new_tokens. Kui see on määratud, peab see olema positiivne täisarv. - kiirte_arv – See näitab ahnes otsingus kasutatud kiirte arvu. Kui see on määratud, peab see olema täisarv, mis on suurem või võrdne sellega
num_return_sequences. - no_repeat_ngram_size – Mudel tagab, et sõnade jada
no_repeat_ngram_sizeväljundjärjestuses ei korrata. Kui see on määratud, peab see olema positiivne täisarv, mis on suurem kui 1. - temperatuur – See parameeter juhib väljundi juhuslikkust. A kõrgem
temperaturetulemuseks on väljundjada madala tõenäosusega sõnadega ja madalama tõenäosusegatemperaturetulemuseks on suure tõenäosusega sõnadega väljundjada. Kuitemperatureon 0, tulemuseks on ahne dekodeerimine. Kui see on määratud, peab see olema positiivne ujuk. - varajane_peatus - Kui
True, teksti genereerimine on lõppenud, kui kõik kiirhüpoteesid jõuavad lausemärgi lõppu. Kui see on määratud, peab see olema tõeväärtus. - do_sample - Kui
True, valib mudel järgmise sõna vastavalt tõenäosusele. Kui see on määratud, peab see olema tõeväärtus. - top_k – Igas teksti genereerimise etapis võtab mudel näidiseid ainult
top_kkõige tõenäolisemad sõnad. Kui see on määratud, peab see olema positiivne täisarv. - top_p – Mudel valib teksti genereerimise igas etapis võimalikult väikesest kumulatiivse tõenäosusega sõnade hulgast
top_p. Kui see on määratud, peab see olema ujuk vahemikus 0–1. - tagasta_täielik_tekst - Kui
True, on sisendtekst osa väljundi loodud tekstist. Kui see on määratud, peab see olema tõeväärtus. Vaikeväärtus onFalse. - peatus – Kui see on määratud, peab see olema stringide loend. Teksti genereerimine peatub, kui genereeritakse mõni määratud stringidest.
Kutsuge SageMakeri lõpp-punkt
Saate programmiliselt laadida näidiskoormusi failist JumpStartModel objektiks. See aitab teil kiiresti alustada, järgides eelnevalt vormindatud juhiseid, mida Llama Guard saab alla neelata. Vaadake järgmist koodi:
Pärast eelmise näite käivitamist näete, kuidas Llama Guard teie sisendi ja väljundi vormindaks:
Sarnaselt Llama-2-ga kasutab Llama Guard spetsiaalseid märke, et näidata mudelile ohutusjuhiseid. Üldiselt peaks kasulik koormus järgima järgmist vormingut:
Kasutaja viip kuvatakse kujul {user_prompt} ülaltoodud, võib lisaks sisaldada jaotisi sisukategooriate määratluste ja vestluste jaoks, mis näeb välja järgmine:
Järgmises jaotises käsitleme ülesande, sisukategooria ja juhiste definitsioonide soovitatud vaikeväärtusi. Vestlus peaks toimuma vaheldumisi User ja Agent tekst järgmiselt:
Modereerige vestlust Llama-2 Chatiga
Nüüd saate vestlusvestluse jaoks juurutada Llama-2 7B Chati mudeli lõpp-punkti ja seejärel kasutada Llama Guardit Llama-2 7B Chati sisend- ja väljundteksti modereerimiseks.
Näitame teile näidet Llama-2 7B vestlusmudeli sisendist ja väljundist, mida modereeritakse Llama Guardi kaudu, kuid võite kasutada Llama Guardi modereerimiseks mis tahes oma valitud LLM-iga.
Juurutage mudel järgmise koodiga:
Nüüd saate määratleda Llama Guard ülesandemalli. Ebaturvalisi sisukategooriaid võidakse vastavalt teie konkreetsele kasutusjuhule kohandada. Saate lihttekstis määratleda iga sisukategooria tähenduse, sealhulgas selle, milline sisu tuleks märgistada kui ebaturvaline ja milline sisu tuleks lubada ohutuks. Vaadake järgmist koodi:
Järgmisena määratleme abifunktsioonid format_chat_messages ja format_guard_messages vestlusmudeli ja spetsiaalseid märke vajava mudeli Llama Guard viipa vormindamiseks:
Seejärel saate kasutada neid abifunktsioone näidissisestusviibal, et käivitada näidissisendi kaudu Llama Guard, et teha kindlaks, kas sõnumi sisu on ohutu:
Järgmine väljund näitab, et teade on ohutu. Võite märgata, et viip sisaldab sõnu, mida võidakse seostada vägivallaga, kuid sel juhul suudab Llama Guard mõista konteksti seoses juhistega ja ohtlike kategooriate määratlustega, mille me varem esitasime, ning otsustab, et see on ohutu viip, mitte aga vägivallaga seotud.
Nüüd, kui olete kinnitanud, et sisendtekst on teie Llama Guardi sisukategooriate suhtes ohutu, saate teksti genereerimiseks edastada selle kasuliku koormuse juurutatud mudelile Llama-2 7B:
Mudeli vastus on järgmine:
Lõpuks võite soovida kinnitada, et mudeli vastusetekst sisaldab ohutut sisu. Siin laiendate LLM-i väljundvastust sisendsõnumitele ja käivitate kogu selle vestluse läbi Llama Guardi, et tagada vestluse ohutus teie rakenduse jaoks:
Võite näha järgmist väljundit, mis näitab, et vestlusmudeli vastus on ohutu:
Koristage
Pärast lõpp-punktide testimist kustutage tasude vältimiseks kindlasti SageMakeri järelduse lõpp-punktid ja mudel.
Järeldus
Selles postituses näitasime teile, kuidas saate Llama Guardi abil sisendeid ja väljundeid modereerida ning SageMaker JumpStartis LLM-ide sisendite ja väljundite jaoks kaitsepiirdeid paigaldada.
Kuna AI areneb jätkuvalt, on ülioluline seada esikohale vastutustundlik arendus ja kasutuselevõtt. Sellised tööriistad nagu Purple Llama’s CyberSecEval ja Llama Guard aitavad kaasa ohutu innovatsiooni edendamisele, pakkudes keelemudelite jaoks varajase riski tuvastamise ja maandamise juhiseid. Need tuleks juurutada tehisintellekti kujundamise protsessi, et kasutada ära LLM-ide täielik potentsiaal eetiliselt alates 1. päevast.
Proovige juba täna SageMaker JumpStartis Llama Guardi ja teisi alusmudeleid ning andke meile oma tagasisidest teada!
See juhend on mõeldud ainult informatiivsel eesmärgil. Peaksite siiski läbi viima oma sõltumatu hindamise ja võtma meetmeid tagamaks, et järgite oma konkreetseid kvaliteedikontrolli tavasid ja standardeid ning kohalikke eeskirju, seadusi, määrusi, litsentse ja kasutustingimusi, mis kehtivad teie, teie sisu, ja käesolevas juhendis viidatud kolmanda osapoole mudel. AWS-il ei ole käesolevas juhendis viidatud kolmanda osapoole mudeli üle kontrolli ega volitusi ning ta ei kinnita ega garanteeri, et kolmanda osapoole mudel on turvaline, viirusevaba, töökorras või teie tootmiskeskkonna ja standarditega ühilduv. AWS ei anna mingeid kinnitusi, garantiisid ega garantiisid, et mis tahes selles juhendis sisalduv teave toob kaasa konkreetse tulemuse või tulemuse.
Autoritest
 Dr Kyle Ulrich on rakendusteadlane Amazon SageMakeri sisseehitatud algoritmid meeskond. Tema uurimishuvide hulka kuuluvad skaleeritavad masinõppe algoritmid, arvutinägemine, aegridad, Bayesi mitteparameetrid ja Gaussi protsessid. Tema doktorikraad on pärit Duke'i ülikoolist ja ta on avaldanud töid NeurIPSis, Cell ja Neuron.
Dr Kyle Ulrich on rakendusteadlane Amazon SageMakeri sisseehitatud algoritmid meeskond. Tema uurimishuvide hulka kuuluvad skaleeritavad masinõppe algoritmid, arvutinägemine, aegridad, Bayesi mitteparameetrid ja Gaussi protsessid. Tema doktorikraad on pärit Duke'i ülikoolist ja ta on avaldanud töid NeurIPSis, Cell ja Neuron.
 Evan Kravitz on Amazon Web Servicesi tarkvarainsener, kes töötab SageMaker JumpStart. Teda huvitab masinõppe ja pilvandmetöötluse ühinemine. Evan omandas bakalaureusekraadi Cornelli ülikoolist ja magistrikraadi California ülikoolist Berkeleys. 2021. aastal esitas ta ICLR konverentsil ettekande võistlevate närvivõrkude kohta. Vabal ajal naudib Evan kokkamist, reisimist ja New Yorgis jooksmas käimist.
Evan Kravitz on Amazon Web Servicesi tarkvarainsener, kes töötab SageMaker JumpStart. Teda huvitab masinõppe ja pilvandmetöötluse ühinemine. Evan omandas bakalaureusekraadi Cornelli ülikoolist ja magistrikraadi California ülikoolist Berkeleys. 2021. aastal esitas ta ICLR konverentsil ettekande võistlevate närvivõrkude kohta. Vabal ajal naudib Evan kokkamist, reisimist ja New Yorgis jooksmas käimist.
 Rachna Chadha on AWS-i strateegiliste kontode pealahendusarhitekt AI/ML. Rachna on optimist, kes usub, et tehisintellekti eetiline ja vastutustundlik kasutamine võib tulevikus ühiskonda parandada ning tuua majanduslikku ja sotsiaalset õitsengut. Vabal ajal meeldib Rachnale perega aega veeta, matkata ja muusikat kuulata.
Rachna Chadha on AWS-i strateegiliste kontode pealahendusarhitekt AI/ML. Rachna on optimist, kes usub, et tehisintellekti eetiline ja vastutustundlik kasutamine võib tulevikus ühiskonda parandada ning tuua majanduslikku ja sotsiaalset õitsengut. Vabal ajal meeldib Rachnale perega aega veeta, matkata ja muusikat kuulata.
 Dr Ashish Khetan on vanemrakendusteadlane, kellel on Amazon SageMaker sisseehitatud algoritmid ja aitab välja töötada masinõppe algoritme. Ta sai doktorikraadi Illinoisi Urbana-Champaigni ülikoolist. Ta on aktiivne masinõppe ja statistiliste järelduste uurija ning avaldanud palju artikleid NeurIPS, ICML, ICLR, JMLR, ACL ja EMNLP konverentsidel.
Dr Ashish Khetan on vanemrakendusteadlane, kellel on Amazon SageMaker sisseehitatud algoritmid ja aitab välja töötada masinõppe algoritme. Ta sai doktorikraadi Illinoisi Urbana-Champaigni ülikoolist. Ta on aktiivne masinõppe ja statistiliste järelduste uurija ning avaldanud palju artikleid NeurIPS, ICML, ICLR, JMLR, ACL ja EMNLP konverentsidel.
 Karl Albertsen juhib Amazon SageMaker Algorithms ja JumpStart, SageMakeri masinõppekeskuse tooteid, tehnikat ja teadust. Ta on kirglik masinõppe rakendamisest äriväärtuse avamiseks.
Karl Albertsen juhib Amazon SageMaker Algorithms ja JumpStart, SageMakeri masinõppekeskuse tooteid, tehnikat ja teadust. Ta on kirglik masinõppe rakendamisest äriväärtuse avamiseks.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/
- :on
- :on
- :mitte
- : kus
- $ UP
- 1
- 10
- 100
- 11
- 12
- 13
- 2021
- 39
- 7
- 8
- 9
- a
- Võimalik
- MEIST
- üle
- aktsepteerima
- juurdepääs
- Vastavalt
- Kontod
- tegu
- tegevus
- meetmete
- aktiivne
- tegevus
- tegelik
- lisamine
- Kohandatud
- vastu võtma
- edendama
- ettemaksed
- võistlev
- nõuanne
- vastu
- Agent
- AI
- AI mudelid
- AI / ML
- Alkohol
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- Ka
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- an
- ja
- Teatama
- vastus
- mistahes
- taotlus
- rakendatud
- kehtima
- Rakendades
- asjakohane
- OLEME
- argument
- argumendid
- Kunst
- AS
- hindamine
- abistama
- assistent
- seotud
- Kindel
- At
- asutus
- Automatiseeritud
- saadaval
- vältima
- AWS
- põhineb
- põhiline
- Bayesi
- BE
- Laius
- sest
- olnud
- enne
- alustama
- käitumine
- usub,
- alla
- kriteeriumid
- Berkeley
- BEST
- parimaid tavasid
- vahel
- miljardeid
- keha
- mõlemad
- tooma
- Toob
- ehitama
- Ehitus
- sisseehitatud
- äri
- kuid
- by
- California
- CAN
- Kanepi
- kaart
- juhul
- juhtudel
- kategooriad
- Kategooria
- rakk
- väljakutseid
- võimalus
- muutma
- omadused
- koormuste
- vestlus
- jututoad
- kontrollima
- keemiline
- valik
- Vali
- valimine
- Linn
- klass
- puhastama
- Cloud
- cloud computing
- kood
- värv
- tulevad
- kaubandus-
- toime pandud
- ühine
- kogukond
- kokkusobiv
- täitma
- komponendid
- koostis
- arvuti
- Arvuti visioon
- arvutustehnika
- Konverents
- konverentsid
- Kinnitama
- KINNITATUD
- ühinemine
- konsool
- tarbimine
- sisaldama
- Konteiner
- sisaldab
- sisu
- sisu modereerimine
- kontekst
- pidev
- kontrollida
- kontrollitud
- kontrolli
- Vestlus
- jutukas
- vestlused
- cooking
- cornell
- võiks
- looma
- loomine
- Kuriteod
- Criminal
- kriitiline
- kureeritud
- klient
- Kasutajatugi
- Kliendid
- kohandada
- cyber
- küberturvalisus
- tsükkel
- andmed
- andmekogumid
- päev
- dekodeerimine
- sügav
- sügav õpe
- vaikimisi
- määratlema
- mõisted
- Kraad
- juurutada
- lähetatud
- juurutamine
- kasutuselevõtu
- kasutuselevõtt
- Disain
- projekteerimisprotsess
- soov
- soovitud
- üksikasjalik
- detailid
- Detection
- Määrama
- kindlaksmääratud
- arendama
- arendaja
- Arendajad
- & Tarkvaraarendus
- DIKT
- erinev
- digitaalne
- digital Art
- Puue
- avastama
- Diskrimineerimine
- arutama
- do
- ei
- Narkootikumide
- Hertsog
- hertsogi ülikool
- e
- iga
- Ajalugu
- Varajane
- kergesti
- Majanduslik
- ökosüsteemi
- Käsitöö
- mõju
- vaevata
- võimaldama
- võimaldades
- julgustama
- lõpp
- Lõpuks-lõpuni
- Lõpp-punkt
- lõpp-punktid
- tegelema
- insener
- Inseneriteadus
- tagama
- tagab
- keskkond
- võrdne
- eriti
- Eeter (ETH)
- eetiline
- hindamine
- hindamised
- sündmused
- näide
- Välja arvatud
- erand
- erutatud
- välja arvatud
- täitmine
- olemasolevate
- kallis
- uurima
- ekspress
- laiendama
- nägu
- silmitsi seisnud
- vale
- pere
- Lisaks
- vähe
- finants-
- finantskuriteod
- leidma
- Tulirelvade
- esimene
- märgistatud
- Float
- Keskenduma
- järgima
- Järgneb
- Järel
- järgneb
- eest
- formaat
- edendamine
- Sihtasutus
- tasuta
- Alates
- täis
- funktsioonid
- edasi
- tulevik
- SUGU
- Üldine
- tekitama
- loodud
- genereerib
- teeniva
- põlvkond
- generatiivne
- Generatiivne AI
- saama
- GitHub
- antud
- andmine
- Go
- läheb
- sain
- suurem
- Ahne
- garantiid
- valvur
- juhised
- GUNS
- kahju
- rakmed
- viha
- Olema
- he
- Tervis
- aitama
- aitab
- siin
- siin
- rohkem
- matkamine
- tema
- ajalooline
- võõrustas
- Kuidas
- Kuidas
- HTML
- HTTPS
- Keskus
- rummud
- i
- ICLR
- ID
- Identifitseerimine
- Identity
- if
- ebaseaduslik
- Illinois
- kohe
- import
- parandama
- in
- sisaldama
- hõlmab
- Kaasa arvatud
- sõltumatud
- näitama
- näitab
- Näitab
- info
- Informatsiooniline
- juurdunud
- esialgne
- algatus
- Innovatsioon
- sisend
- sisendite
- Näiteks
- juhised
- instrumentaal-
- integreerima
- integreeritud
- huvitatud
- el
- Interface
- sisse
- kaasates
- IT
- ITS
- jpg
- tapma
- Teadma
- teatud
- Kyle
- maandumine
- kodulehe
- keel
- suur
- viimane
- Seadused
- Leads
- õppimine
- jätmine
- Pikkus
- laskma
- litsents
- Litsentseeritud
- Litsentsid
- nagu
- tõenäosus
- Tõenäoliselt
- meeldib
- piiratud
- joon
- Linux
- nimekiri
- Kuulamine
- Laama
- kohalik
- välimus
- vähendada
- masin
- masinõpe
- säilitada
- tegema
- käsitsi
- valmistatud
- palju
- meistrid
- mai..
- tähendus
- meetmed
- Meedia
- vaimne
- Vaimse tervise
- sõnum
- kirjad
- Meta
- meetod
- meetodid
- võib
- protokoll
- leevendamine
- segu
- ML
- mudel
- mudelid
- mõõduka
- mõõdukus
- järelevalve
- rohkem
- kõige
- muusika
- peab
- Pead lugema
- riiklik
- vaja
- võrgustikud
- Neural
- närvivõrgud
- NeurIPS
- mitte kunagi
- Uus
- New York
- New York City
- järgmine
- ei
- märkmik
- märkmikud
- Märka..
- nüüd
- number
- objekt
- of
- pakkumine
- on
- ONE
- ainult
- avatud
- avalikult
- töökorras
- valik
- Valikud
- or
- päritolu
- Muu
- meie
- välja
- Tulemus
- väljund
- väljundid
- üle
- enda
- omandiõigus
- lehekülg
- Paber
- dokumendid
- parameeter
- parameetrid
- osa
- eriline
- isikutele
- sooritama
- Mööduv
- kirglik
- Inimesed
- kohta
- täitma
- täidab
- inimene
- isiklik
- phd
- tavaline
- kava
- planeerimine
- Platon
- Platoni andmete intelligentsus
- PlatoData
- poliitika
- populaarne
- positiivne
- võimalik
- post
- potentsiaal
- potentsiaalselt
- tavad
- eelnev
- Predictor
- ettevalmistamisel
- esitatud
- vältida
- Peamine
- Prioriteet
- tõenäosus
- protsess
- Protsessid
- Toode
- Produktsioon
- projekt
- küsib
- heaolu
- anda
- tingimusel
- pakkujad
- annab
- avalikult
- avaldatud
- Kirjastamine
- eesmärkidel
- panema
- Python
- pütorch
- kvaliteet
- kiiresti
- Rass
- juhuslikkus
- valik
- pigem
- jõudma
- Jõuab
- Lugenud
- saadud
- hiljuti
- soovitatav
- viitama
- kohta
- reguleeritud
- määrused
- seotud
- vabastama
- asjakohane
- religioon
- korduv
- asendama
- Taotlusi
- nõutav
- teadustöö
- uurija
- Vahendid
- suhtes
- vastates
- vastus
- vastutav
- vastutustundlikult
- REST
- kaasa
- Tulemused
- tagasipöördumine
- läbi
- Tõusma
- Oht
- Riskantne
- tegevuskava
- Roll
- rollid
- eeskirjade
- jooks
- jookseb
- ohutu
- tagatisi
- ohutus
- salveitegija
- SageMakeri järeldus
- skaalautuvia
- Skaala
- teadus
- teadlane
- SDK
- Otsing
- otsimine
- Teine
- Osa
- lõigud
- kindlustama
- turvalisus
- vaata
- valima
- vanem
- tundlik
- Lause
- tunded
- Jada
- Seeria
- teenus
- Teenused
- komplekt
- Seksuaalne
- jagatud
- peaks
- näitama
- näitas
- näidates
- näidatud
- ühekordne
- So
- sotsiaalmeedia
- Sotsiaalse meedia
- Ühiskond
- tarkvara
- Tarkvara insener
- lahendus
- Lahendused
- eriline
- konkreetse
- määratletud
- Kulutused
- standardite
- alustatud
- Käivitus
- statistiline
- statistika
- Samm
- Sammud
- Veel
- Peatab
- Strateegiline
- strateegiad
- stuudio
- edukas
- selline
- Enesetapp
- toetama
- Toetab
- kindel
- süntaks
- süsteem
- süsteemid
- Võtma
- Ülesanne
- ülesanded
- meeskond
- šabloon
- malle
- tensorivool
- tingimused
- test
- katsetatud
- tekst
- teksti genereerimine
- kui
- et
- .
- Tulevik
- teave
- vargus
- oma
- Neile
- ennast
- SIIS
- Seal.
- Need
- nad
- Kolmas
- kolmandad isikud
- kolmanda osapoole
- see
- need
- Läbi
- aeg
- Ajaseeria
- et
- tubakas
- täna
- kokku
- sümboolne
- märgid
- tööriist
- töövahendid
- Teemasid
- inimkaubanduse
- Rong
- koolitatud
- koolitus
- Tõlge
- Reisimine
- tõsi
- Usalda
- püüdma
- Pöörake
- liigid
- tüüpiliselt
- ui
- lõpuks
- all
- mõistma
- Ülikool
- California Ülikool
- avamine
- kuni
- us
- Kasutus
- kasutama
- kasutage juhtumit
- Kasutatud
- Kasutaja
- kasutusalad
- kasutamine
- väärtus
- Väärtused
- sort
- versioon
- vaade
- rikutud
- Rikub
- nägemus
- visuaalne
- kõndima
- tahan
- Tee..
- we
- Relvad
- web
- veebiteenused
- Veebipõhine
- M
- millal
- kas
- mis
- WHO
- kogu
- lai
- will
- koos
- jooksul
- ilma
- sõna
- sõnad
- Töö
- töövoog
- töö
- oleks
- york
- sa
- Sinu
- sephyrnet