Image by Freepik
Vestluspõhine tehisintellekt viitab virtuaalsetele agentidele ja vestlusrobotidele, mis jäljendavad inimestevahelist suhtlust ja võivad inimesi vestlusesse kaasata. Vestluspõhise AI kasutamine on kiiresti muutumas eluviisiks – alates Alexa küsimisest kuni „leidke lähim restoran" et paluda Siril "luua meeldetuletus," Virtuaalseid assistente ja vestlusroboteid kasutatakse sageli tarbijate küsimustele vastamiseks, kaebuste lahendamiseks, broneeringute tegemiseks ja paljuks muuks.
Nende virtuaalsete assistentide arendamine nõuab suuri jõupingutusi. Peamiste väljakutsete mõistmine ja nendega tegelemine võib aga arendusprotsessi sujuvamaks muuta. Olen kasutanud oma vahetut kogemust värbamisplatvormi jaoks küpse vestlusroboti loomisel lähtepunktina, et selgitada peamisi väljakutseid ja neile vastavaid lahendusi.
Vestluspõhise AI vestlusroboti loomiseks saavad arendajad kasutada vestlusrobotite loomiseks selliseid raamistikke nagu RASA, Amazoni Lex või Google'i Dialogflow. Enamik eelistab RASA-d, kui nad kavandavad kohandatud muudatusi või robot on küpses faasis, kuna see on avatud lähtekoodiga raamistik. Lähtepunktiks sobivad ka teised raamistikud.
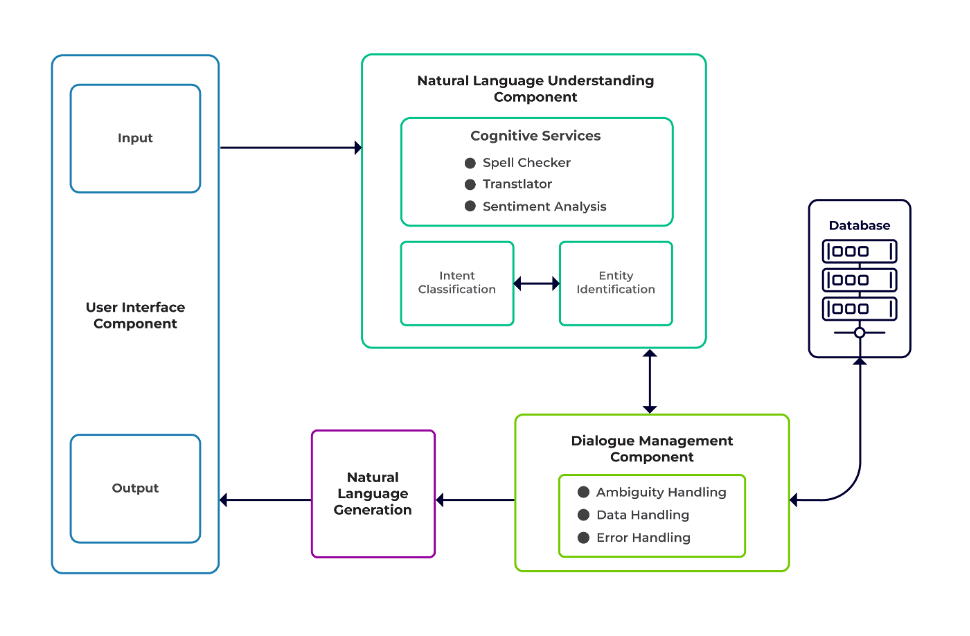
Väljakutsed võib liigitada vestlusroboti kolmeks peamiseks komponendiks.
Loomuliku keele mõistmine (NLU) on roboti võime mõista inimeste dialoogi. See teostab kavatsuste klassifitseerimist, olemi eraldamist ja vastuste otsimist.
Dialoogi juht vastutab tegevuste komplekti eest, mis tuleb sooritada vastavalt kasutaja praegusele ja varasemale sisendikomplektile. See võtab sisendiks (eelmise vestluse osana) kavatsuse ja olemid ning tuvastab järgmise vastuse.
Loomuliku keele genereerimine (NLG) on etteantud andmete põhjal kirjalike või suuliste lausete genereerimise protsess. See raamib vastuse, mis seejärel kasutajale esitatakse.
Pilt Talentica tarkvarast
Andmeid pole piisavalt
Kui arendajad asendavad KKK-d või muud tugisüsteemid vestlusrobotiga, saavad nad korraliku hulga koolitusandmeid. Kuid sama ei juhtu, kui nad loovad roboti nullist. Sellistel juhtudel genereerivad arendajad treeningandmeid sünteetiliselt.
Mida teha?
Mallipõhine andmegeneraator võib genereerida koolituse jaoks korraliku hulga kasutajapäringuid. Kui vestlusbot on valmis, saavad projekti omanikud selle avaldada piiratud arvule kasutajatele, et treeningandmeid täiustada ja teatud aja jooksul täiendada.
Sobimatu mudelivalik
Sobivad mudelivalik ja koolitusandmed on parimate kavatsuste ja üksuste ekstraheerimise tulemuste saavutamiseks üliolulised. Arendajad koolitavad tavaliselt vestlusroboteid kindlas keeles ja domeenis ning enamik saadaolevatest eelkoolitatud mudelitest on sageli domeenispetsiifilised ja ühes keeles.
Võib esineda ka segakeelte juhtumeid, kus inimesed on polüglotid. Nad võivad sisestada päringuid segakeeles. Näiteks piirkonnas, kus domineerib prantslane, võivad inimesed kasutada teatud tüüpi inglise keelt, mis on segu prantsuse ja inglise keelest.
Mida teha?
Mitmes keeles koolitatud mudelite kasutamine võib probleemi vähendada. Sellistel juhtudel võib abiks olla eelkoolitatud mudel, nagu LaBSE (keeleagnostiline Berti lause manustamine). LaBSE-d õpetatakse rohkem kui 109 keeles lause sarnasuse ülesande täitmiseks. Mudel juba teab sarnaseid sõnu teises keeles. Meie projektis töötas see väga hästi.
Vale olemi ekstraheerimine
Vestlusbotid nõuavad, et üksused tuvastaksid, milliseid andmeid kasutaja otsib. Need olemid hõlmavad kellaaega, kohta, isikut, üksust, kuupäeva jne. Kuid robotid ei suuda olemit loomulikust keelest tuvastada.
Sama kontekst, kuid erinevad olemid. Näiteks võivad robotid koha kui olemi segi ajada, kui kasutaja sisestab „IIT Delhi õpilaste nimi” ja seejärel „Bengaluru õpilaste nimi”.
Stsenaariumid, kus üksusi ennustatakse valesti ja madala usaldusväärsusega. Näiteks suudab bot tuvastada IIT Delhi vähese enesekindlusega linnana.
Olemi osaline ekstraheerimine masinõppemudeli abil. Kui kasutaja sisestab sõna „üliõpilased IIT Delhist”, saab mudel „IIT Delhi” asemel identifitseerida ainult „IIT” kui üksust.
Ühesõnalised sisendid, millel puudub kontekst, võivad masinõppe mudelid segadusse ajada. Näiteks sõna nagu "Rishikesh" võib tähendada nii inimese kui ka linna nime.
Mida teha?
Lahenduseks võiks olla rohkemate koolitusnäidete lisamine. Kuid on piir, mille järel rohkem lisamine ei aitaks. Pealegi on see lõputu protsess. Teine lahendus võib olla regex-mustrite määratlemine eelmääratletud sõnadega, et aidata välja võtta teadaolevate võimalike väärtustega üksusi, nagu linn, riik jne.
Mudelid jagavad madalamat usaldusväärsust alati, kui nad pole olemi ennustamises kindlad. Arendajad saavad seda kasutada käivitajana, et kutsuda välja kohandatud komponent, mis suudab parandada madala enesekindlusega olemit. Vaatleme ülaltoodud näidet. Kui IIT Delhi on ennustatud madala usaldusväärsusega linnaks, siis saab kasutaja seda alati andmebaasist otsida. Pärast seda, kui ennustatud olemit ei leitud Linn tabelis, jätkaks mudel teistesse tabelitesse ja lõpuks leiaks selle tabelist Instituut tabel, mille tulemuseks on olemi parandus.
Vale kavatsuste klassifikatsioon
Iga kasutaja sõnumiga on seotud mingi kavatsus. Kuna kavatsused tuletavad roboti järgmist tegevussuunda, on kasutajapäringute õige kavatsusega klassifitseerimine ülioluline. Kuid arendajad peavad kavatsused tuvastama nii, et kavatsused oleksid minimaalsed. Vastasel juhul võib juhtumeid segadusse ajada. Näiteks, "Näita mulle avatud töökohti” vs.Näita mulle avatud ametikoha kandidaate.
Mida teha?
Segadust tekitavate päringute eristamiseks on kaks võimalust. Esiteks saab arendaja tutvustada alamkavatsust. Teiseks saavad mudelid käsitleda päringuid tuvastatud üksuste põhjal.
Domeenispetsiifiline vestlusbot peaks olema suletud süsteem, kus see peaks selgelt tuvastama, milleks ta on võimeline ja milleks mitte. Arendajad peavad domeenispetsiifilisi vestlusroboteid kavandades arendama etapiviisiliselt. Igas etapis saavad nad tuvastada vestlusroboti toetamata funktsioonid (toetamata kavatsuse kaudu).
Samuti saavad nad tuvastada, millega vestlusbot ei saa hakkama, kui kavatsus on "ulatusest väljas". Kuid võib esineda juhtumeid, kus robot on segaduses, kuna seda ei toetata ega kavatsus reguleerimisalast välja jääda. Selliste stsenaariumide puhul peaks olema paigas varumehhanism, kus juhul, kui kavatsuse usaldus on alla läve, saab mudel segadusjuhtumite lahendamiseks graatsiliselt töötada koos varukavatsusega.
Kui robot tuvastab kasutaja sõnumi kavatsuse, peab ta vastuse tagasi saatma. Bot otsustab vastuse teatud kindlate reeglite ja lugude alusel. Näiteks võib reegel olla nii lihtne kui täielik "Tere hommikust" kui kasutaja tervitab "Tere". Enamasti hõlmavad vestlusrobotidega vestlused siiski järeltegevust ja nende vastused sõltuvad vestluse üldisest kontekstist.
Mida teha?
Sellega toimetulemiseks toidetakse vestlusroboteid tõeliste vestlusnäidetega, mida nimetatakse lugudeks. Kuid kasutajad ei suhtle alati nii, nagu ette nähtud. Täiskasvanud vestlusbot peaks kõigi selliste kõrvalekalletega toime tulema graatsiliselt. Disainerid ja arendajad saavad selle garanteerida, kui nad ei keskendu lugude kirjutamise ajal ainult õnnelikule teele, vaid töötavad ka õnnetutel teedel.
Kasutajate seotus vestlusrobotidega sõltub suuresti vestlusrobotite vastustest. Kasutajad võivad huvi kaotada, kui vastused on liiga robotlikud või liiga tuttavad. Näiteks ei pruugi kasutajale meeldida vale sisendi vastus, nagu "Te sisestasite vale päringu", kuigi vastus on õige. Siinne vastus ei ühti assistendi isikuga.
Mida teha?
Vestlusbot toimib assistendina ning sellel peaks olema konkreetne isiksus ja hääletoon. Nad peaksid olema vastutulelikud ja alandlikud ning arendajad peaksid vestlusi ja lausungeid vastavalt kujundama. Vastused ei tohiks kõlada robotlikult ega mehaaniliselt. Näiteks võib bot öelda: "Kahjuks tundub, et mul pole üksikasju. Kas saaksite palun oma päringu uuesti sisestada?" vale sisendi kõrvaldamiseks.
LLM-il (Large Language Model) põhinevad vestlusrobotid, nagu ChatGPT ja Bard, on mängu muutvad uuendused ja on parandanud vestluse AI-de võimalusi. Nad ei ole head mitte ainult avatud inimlike vestluste loomisel, vaid suudavad täita erinevaid ülesandeid, nagu teksti kokkuvõte, lõikude kirjutamine jne, mida varem oli võimalik saavutada ainult konkreetsete mudelite abil.
Traditsiooniliste vestlusrobotite süsteemide üks väljakutseid on iga lause kategoriseerimine kavatsusteks ja vastuse otsustamine. Selline lähenemine ei ole praktiline. Sellised vastused nagu „Vabandust, ma ei saanud sind kätte” on sageli ärritavad. Tahtmatud vestlusrobotite süsteemid on tee edasi ja LLM-id saavad selle reaalsuseks muuta.
LLM-id saavad hõlpsasti saavutada tipptasemel tulemusi üldise nimega olemituvastuses, mis keelab teatud domeenispetsiifiliste üksuste tuvastamise. Segatud lähenemisviis LLM-ide kasutamisele mis tahes vestlusroti raamistikuga võib inspireerida küpsemat ja jõulisemat vestlusrobotite süsteemi.
Tänu uusimatele edusammudele ja pidevale vestlusliku AI uurimisele muutuvad vestlusrobotid iga päevaga paremaks. Palju tähelepanu pälvivad sellised valdkonnad nagu mitme kavatsusega keeruliste ülesannete lahendamine, näiteks „Broneerige lend Mumbaisse ja korraldage takso Dadarisse”.
Peagi toimuvad isikupärastatud vestlused, mis põhinevad kasutaja omadustel, et hoida kasutaja seotuna. Näiteks kui robot leiab, et kasutaja pole rahul, suunab see vestluse ümber tõelise agendi juurde. Lisaks saavad süvaõppetehnikad, nagu ChatGPT, koos pidevalt suurenevate vestlusrobotite andmetega teadmistebaasi abil päringutele automaatselt vastuseid genereerida.
Suman Saurav on tarkvaratoodete arendusettevõtte Talentica Software andmeteadlane. Ta on NIT Agartala vilistlane, kellel on üle 8-aastane kogemus revolutsiooniliste AI-lahenduste kavandamisel ja rakendamisel, kasutades NLP-d, vestluslikku AI-d ja generatiivset AI-d.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :on
- :on
- :mitte
- : kus
- 8
- a
- võime
- MEIST
- üle
- vastavalt
- Saavutada
- saavutada
- üle
- meetmete
- lisades
- Lisaks
- aadress
- adresseerimine
- edusammud
- pärast
- Agent
- ained
- AI
- AI vestlusrobot
- Alexa
- Materjal: BPA ja flataatide vaba plastik
- juba
- Ka
- vilistlane
- alati
- summa
- an
- ja
- Teine
- vastus
- mistahes
- lähenemine
- OLEME
- valdkondades
- AS
- küsib
- assistent
- assistendid
- seotud
- At
- tähelepanu
- automaatselt
- saadaval
- vältima
- tagasi
- baas
- põhineb
- BE
- saada
- olendid
- alla
- BEST
- Parem
- Bot
- mõlemad
- eest
- ehitama
- kuid
- by
- helistama
- kutsutud
- CAN
- ei saa
- võimeid
- võimeline
- juhtudel
- kategoriseerimine
- kindel
- väljakutseid
- Vaidluste lahendamine
- omadused
- chatbot
- jututoad
- ChatGPT
- Linn
- klassifikatsioon
- salastatud
- selgelt
- suletud
- ettevõte
- kaebuste
- keeruline
- komponent
- komponendid
- mõista
- usaldus
- segaduses
- segane
- segadus
- Arvestama
- kontekst
- pidev
- Vestlus
- jutukas
- jutukas AI
- vestlused
- parandada
- õigesti
- Vastav
- võiks
- riik
- kursus
- looma
- loomine
- otsustav
- Praegune
- tava
- andmed
- andmeteadlane
- andmebaas
- kuupäev
- päev
- korralik
- Otsustamine
- sügav
- sügav õpe
- määratlema
- määratletud
- Delhi
- sõltuvad
- kõrvalekalle
- Disain
- disainerid
- projekteerimine
- detailid
- arendaja
- Arendajad
- & Tarkvaraarendus
- dialoogivoog
- Dialoog
- erinev
- eristada
- do
- Ei tee
- domeen
- Ära
- iga
- Ajalugu
- kergesti
- jõupingutusi
- kinnistamine
- Lõputu
- tegelema
- hõivatud
- tegevus
- Inglise
- suurendama
- sisene
- üksuste
- üksus
- jms
- Isegi
- lõpuks
- aina suurenev
- Iga
- iga päev
- näide
- näited
- kogemus
- Selgitama
- väljavõte
- kaevandamine
- FAIL
- vastasel
- tuttav
- KIIRE
- FUNKTSIOONID
- Toidetud
- leidma
- leiab
- lend
- Keskenduma
- eest
- edasi
- Raamistik
- raamistikud
- prantsuse
- Alates
- Üldine
- tekitama
- teeniva
- põlvkond
- generatiivne
- Generatiivne AI
- generaator
- saama
- saamine
- antud
- hea
- garantii
- käepide
- Käsitsemine
- juhtuda
- õnnelik
- Olema
- võttes
- he
- tugevalt
- aitama
- kasulik
- siin
- Kuidas
- Kuidas
- aga
- HTTPS
- inim-
- tagasihoidlik
- i
- tuvastatud
- identifitseerib
- identifitseerima
- if
- rakendamisel
- paranenud
- in
- sisaldama
- uuendusi
- sisend
- sisendite
- inspireerima
- Näiteks
- selle asemel
- ette nähtud
- tahtlus
- suhelda
- suhtlemist
- interaktsioonid
- huvi
- sisse
- kehtestama
- IT
- jpg
- lihtsalt
- KDnuggets
- hoidma
- Võti
- Laps
- teadmised
- teatud
- teab
- keel
- Keeled
- suur
- hiljemalt
- õppimine
- elu
- nagu
- LIMIT
- piiratud
- kaotama
- Madal
- vähendada
- masin
- masinõpe
- peamine
- tegema
- Tegemine
- Vastama
- küps
- mai..
- me
- keskmine
- mehaaniline
- mehhanism
- sõnum
- võib
- minimaalne
- segu
- segatud
- mudel
- mudelid
- rohkem
- Pealegi
- kõige
- palju
- mitmekordne
- Mumbai
- peab
- my
- nimi
- Nimega
- Natural
- Loomulik keel
- järgmine
- NLG
- nlp
- nlu
- ei
- number
- of
- sageli
- on
- kunagi
- ainult
- avatud
- avatud lähtekoodiga
- or
- Muu
- muidu
- meie
- üle
- üldine
- omanikud
- osa
- tee
- teed
- mustrid
- Inimesed
- täitma
- teostatud
- täidab
- periood
- inimene
- Isikliku
- faas
- faasi
- Koht
- kava
- planeerimine
- inimesele
- Platon
- Platoni andmete intelligentsus
- PlatoData
- palun
- Punkt
- positsioon
- omama
- võimalik
- Praktiline
- ennustada
- ennustus
- eelistama
- esitatud
- eelmine
- Probleem
- jätkama
- protsess
- Toode
- tootearendus
- projekt
- päringud
- Küsimused
- R
- rasa
- valmis
- reaalne
- Reaalsus
- tõesti
- tunnustamine
- värbamine
- vähendama
- viide
- viitab
- piirkond
- lootma
- meeldetuletus
- asendama
- nõudma
- Vajab
- teadustöö
- lahendama
- vastus
- vastuste
- vastutav
- tulemuseks
- Tulemused
- revolutsiooniline
- jõuline
- Eeskiri
- eeskirjade
- sama
- ütlema
- stsenaariumid
- teadlane
- kriimustada
- Otsing
- otsimine
- tundub
- valik
- saatma
- Lause
- teenib
- komplekt
- Jaga
- peaks
- sarnane
- lihtne
- alates
- ühekordne
- Siri
- tarkvara
- lahendus
- Lahendused
- mõned
- heli
- konkreetse
- räägitud
- Stage
- Käivitus
- modernne
- Lood
- kiirendama
- Õpilased
- mahukas
- selline
- sobiv
- toetama
- Tugisüsteemid
- kindel
- sünteetiliselt
- süsteem
- süsteemid
- T
- tabel
- Võtma
- võtab
- Ülesanne
- ülesanded
- tehnikat
- tekst
- kui
- et
- .
- oma
- Neile
- SIIS
- Seal.
- Need
- nad
- see
- kuigi?
- kolm
- künnis
- aeg
- et
- TONE
- Hääletoon
- liiga
- traditsiooniline
- Rong
- koolitatud
- koolitus
- vallandada
- kaks
- tüüp
- liigid
- mõistmine
- upgrade
- kasutama
- Kasutatud
- Kasutaja
- Kasutajad
- kasutamine
- tavaliselt
- Väärtused
- kaudu
- virtuaalne
- Hääl
- vs
- W
- Tee..
- kuidas
- tervitades
- Hästi
- M
- millal
- millal iganes
- mis
- kuigi
- will
- koos
- sõna
- sõnad
- Töö
- töötas
- oleks
- kirjutamine
- kirjalik
- Vale
- aastat
- sa
- Sinu
- sephyrnet