Imagen del autor
En esta publicación, exploraremos el nuevo modelo de código abierto de última generación llamado Mixtral 8x7b. También aprenderemos cómo acceder a él utilizando la biblioteca LLaMA C++ y cómo ejecutar modelos de lenguaje grandes en computación y memoria reducidas.
Mixtral 8x7b es un modelo de mezcla escasa de expertos (SMoE) de alta calidad con pesos abiertos, creado por Mistral AI. Tiene licencia Apache 2.0 y supera a Llama 2 70B en la mayoría de los puntos de referencia y, al mismo tiempo, tiene una inferencia 6 veces más rápida. Mixtral iguala o supera a GPT3.5 en la mayoría de los puntos de referencia estándar y es el mejor modelo de peso abierto en cuanto a costo/rendimiento.
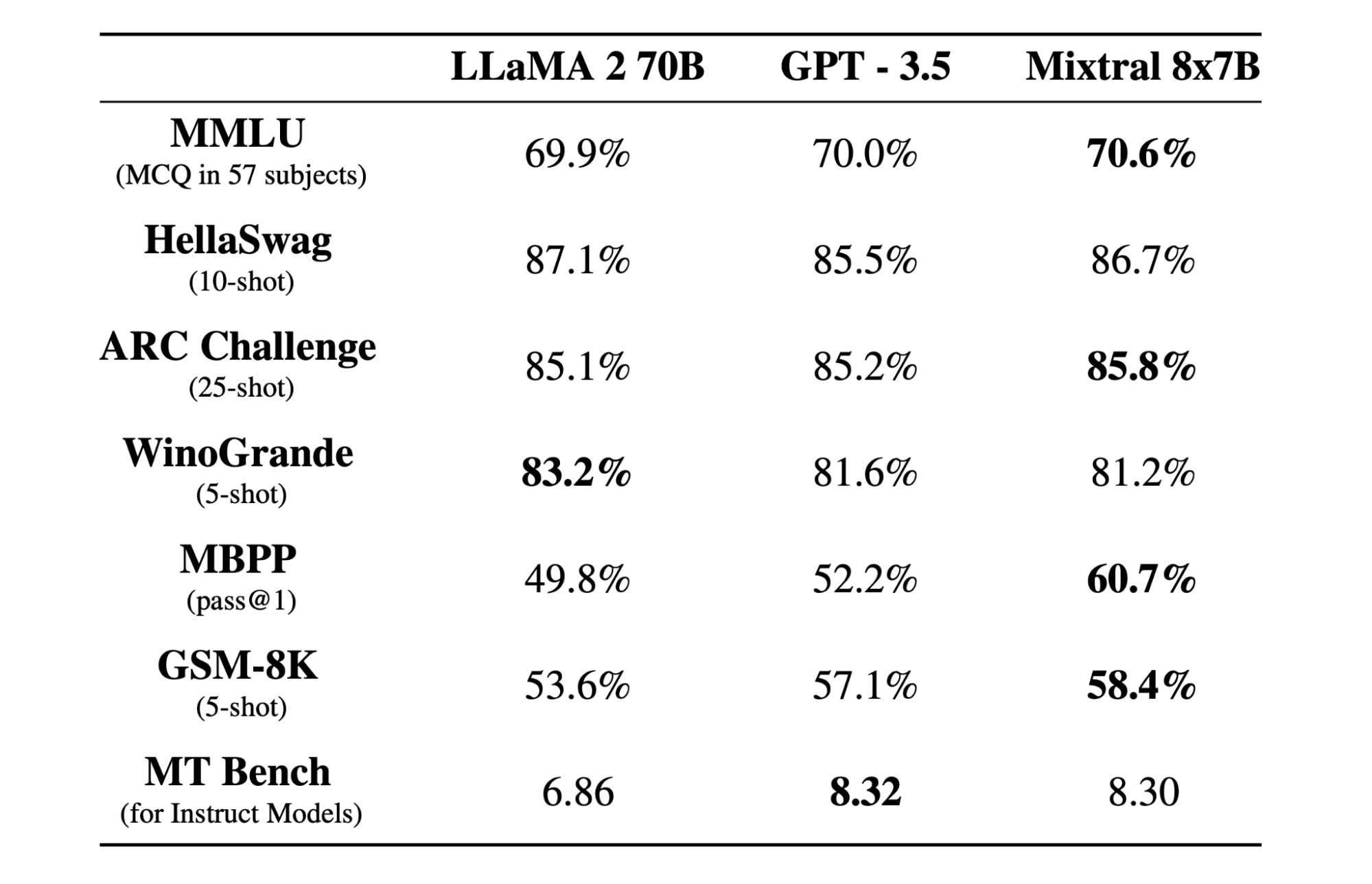
Imagen de Mixtral de expertos
Mixtral 8x7B utiliza una red dispersa de expertos únicamente en decodificadores. Esto implica un bloque de avance que selecciona entre 8 grupos de parámetros, con una red de enrutadores que elige dos de estos grupos para cada token, combinando sus salidas de manera aditiva. Este método mejora el recuento de parámetros del modelo al tiempo que gestiona el costo y la latencia, lo que lo hace tan eficiente como un modelo de 12.9 mil millones, a pesar de tener 46.7 mil millones de parámetros totales.
El modelo Mixtral 8x7B se destaca en el manejo de un amplio contexto de 32k tokens y admite múltiples idiomas, incluidos inglés, francés, italiano, alemán y español. Demuestra un sólido rendimiento en la generación de código y se puede ajustar en un modelo de seguimiento de instrucciones, logrando puntuaciones altas en pruebas comparativas como MT-Bench.
LLaMA.cpp es una biblioteca C/C++ que proporciona una interfaz de alto rendimiento para modelos de lenguaje grandes (LLM) basados en la arquitectura LLM de Facebook. Es una biblioteca liviana y eficiente que se puede utilizar para una variedad de tareas, incluida la generación de texto, la traducción y la respuesta a preguntas. LLaMA.cpp admite una amplia gama de LLM, incluidos LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B y GPT4ALL. Es compatible con todos los sistemas operativos y puede funcionar tanto en CPU como en GPU.
En esta sección, ejecutaremos la aplicación web llama.cpp en Colab. Al escribir unas pocas líneas de código, podrá experimentar el rendimiento del nuevo modelo de última generación en su PC o en Google Colab.
Cómo Empezar
Primero, descargaremos el repositorio de GitHub llama.cpp usando la siguiente línea de comando:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitDespués de eso, cambiaremos el directorio al repositorio e instalaremos llama.cpp usando el comando `make`. Estamos instalando llama.cpp para la GPU NVidia con CUDA instalado.
%cd llama.cpp
!make LLAMA_CUBLAS=1Descarga el Modelo
Podemos descargar el modelo desde Hugging Face Hub seleccionando la versión apropiada del archivo de modelo `.gguf`. Puede encontrar más información sobre las distintas versiones en TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
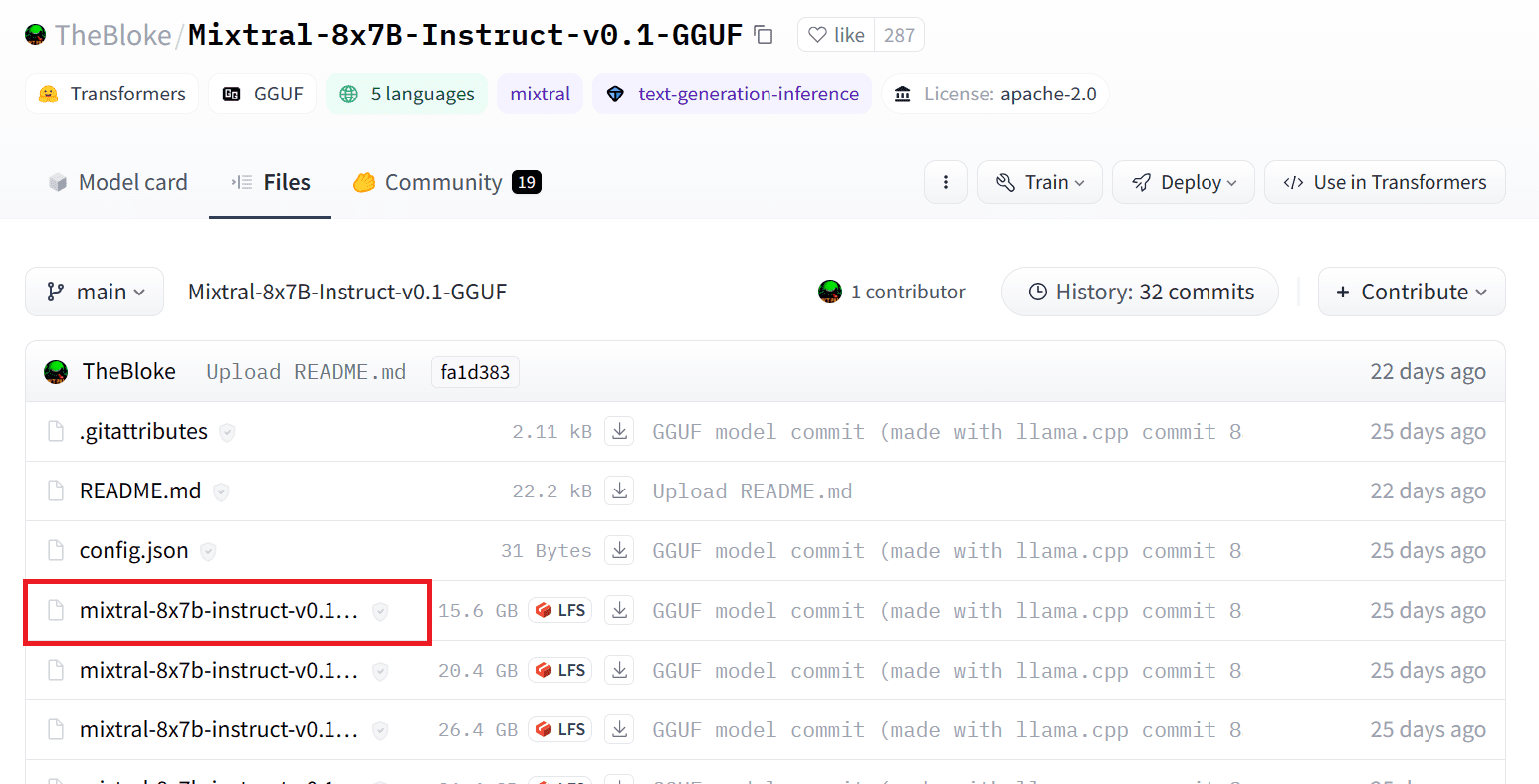
Imagen de TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
Puede utilizar el comando `wget` para descargar el modelo en el directorio actual.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufDirección externa para el servidor LLaMA
Cuando ejecutamos el servidor LLaMA, nos dará una IP de host local que es inútil para nosotros en Colab. Necesitamos la conexión al proxy localhost mediante el puerto de proxy del kernel de Colab.
Después de ejecutar el código siguiente, obtendrá el hipervínculo global. Usaremos este enlace para acceder a nuestra aplicación web más adelante.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/Ejecutando el servidor
Para ejecutar el servidor LLaMA C++, debe proporcionar al comando del servidor la ubicación del archivo del modelo y el número de puerto correcto. Es importante asegurarse de que el número de puerto coincida con el que iniciamos en el paso anterior para el puerto proxy.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
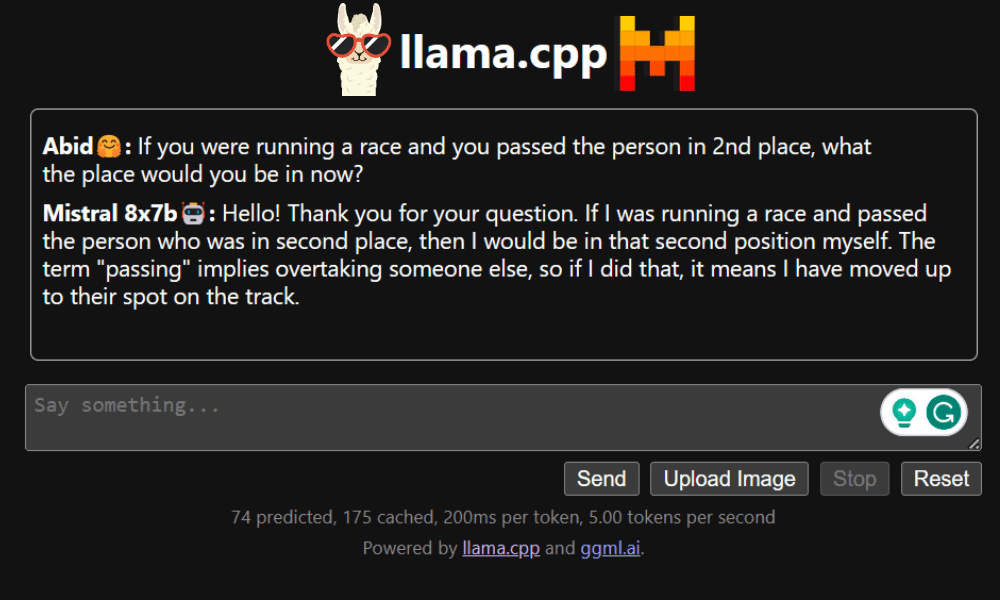
Se puede acceder a la aplicación web de chat haciendo clic en el hipervínculo del puerto proxy en el paso anterior, ya que el servidor no se ejecuta localmente.
Aplicación web LLaMA C++
Antes de comenzar a utilizar el chatbot, debemos personalizarlo. Reemplace "LLaMA" con el nombre de su modelo en la sección de mensajes. Además, modifique el nombre de usuario y el nombre del bot para distinguir entre las respuestas generadas.
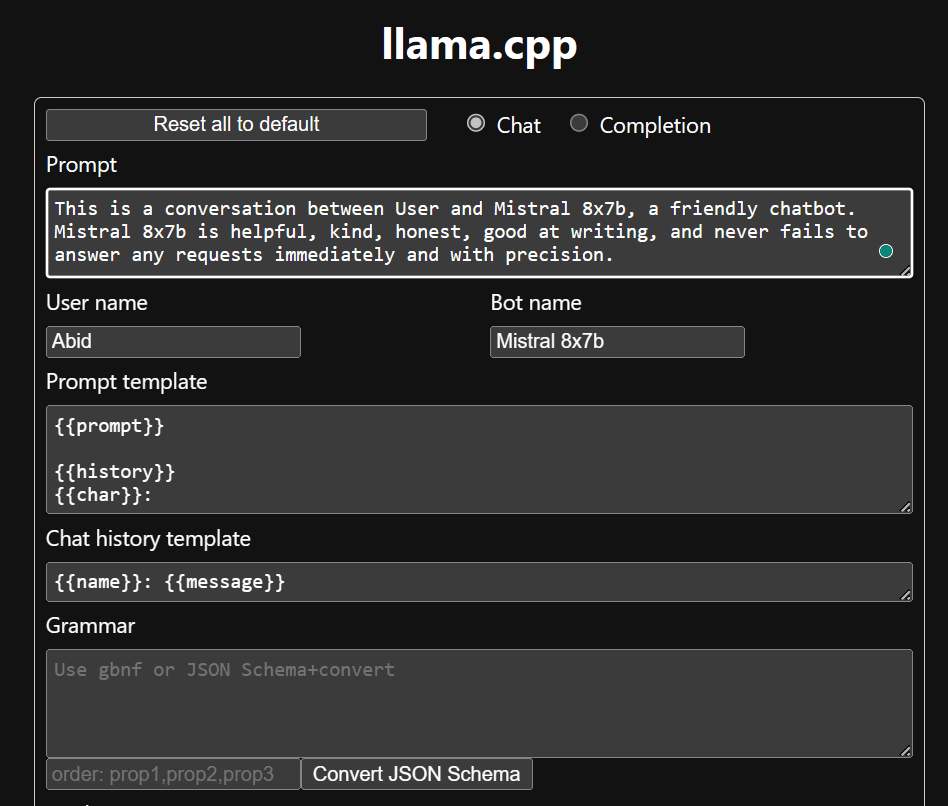
Comience a chatear desplazándose hacia abajo y escribiendo en la sección de chat. No dude en hacer preguntas técnicas que otros modelos de código abierto no hayan respondido adecuadamente.
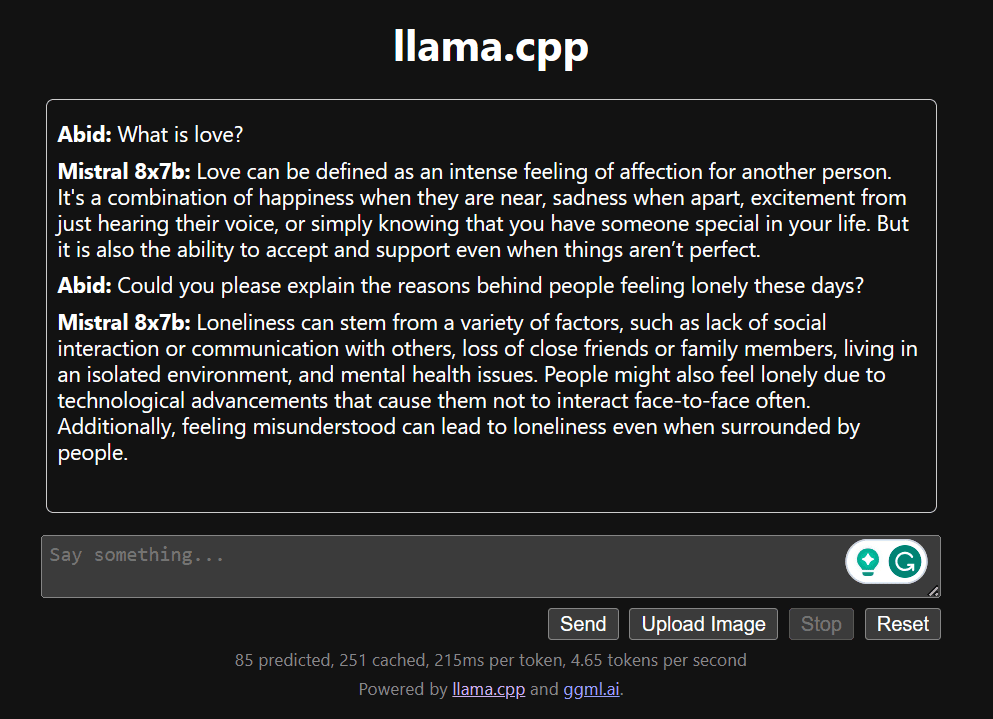
Si tiene problemas con la aplicación, puede intentar ejecutarla usted mismo usando mi Google Colab: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
Este tutorial proporciona una guía completa sobre cómo ejecutar el modelo avanzado de código abierto, Mixtral 8x7b, en Google Colab utilizando la biblioteca LLaMA C++. En comparación con otros modelos, Mixtral 8x7b ofrece rendimiento y eficiencia superiores, lo que lo convierte en una excelente solución para quienes desean experimentar con modelos de lenguaje grandes pero no cuentan con amplios recursos computacionales. Puede ejecutarlo fácilmente en su computadora portátil o en una computadora en la nube gratuita. Es fácil de usar e incluso puedes implementar tu aplicación de chat para que otros la usen y experimenten.
Espero que esta sencilla solución para ejecutar el modelo grande le haya resultado útil. Siempre estoy buscando opciones simples y mejores. Si tiene una solución aún mejor, hágamelo saber y la cubriré la próxima vez.
Abid Ali Awan (@ 1abidaliawan) es un profesional científico de datos certificado al que le encanta crear modelos de aprendizaje automático. Actualmente, se está enfocando en la creación de contenido y escribiendo blogs técnicos sobre aprendizaje automático y tecnologías de ciencia de datos. Abid tiene una Maestría en Gestión de Tecnología y una licenciatura en Ingeniería de Telecomunicaciones. Su visión es construir un producto de IA utilizando una red neuronal gráfica para estudiantes que luchan contra enfermedades mentales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :es
- :no
- 1
- 12
- 27
- 46
- 7
- 8
- a
- Poder
- de la máquina
- visitada
- el logro de
- Adicionalmente
- dirección
- avanzado
- AI
- Todos
- también
- hacerlo
- am
- an
- y
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- APACHE
- applicación
- Aplicación
- adecuado
- arquitectura
- somos
- AS
- contacta
- basado
- BE
- comenzar
- a continuación
- los puntos de referencia
- MEJOR
- mejores
- entre
- Bloquear
- Blogs
- Bot
- ambas
- build
- Construir la
- pero
- by
- C + +
- , que son
- PUEDEN
- Ingenieros
- el cambio
- chat
- chatterbot
- en el chat
- la elección de
- Soluciones
- código
- combinar
- en comparación con
- compatible
- exhaustivo
- computational
- Calcular
- informática
- conexión
- contenido
- creación de contenido
- contexto
- correcta
- Cost
- Protectora
- creado
- creación
- Current
- En la actualidad
- personalizan
- datos
- Ciencia de los datos
- científico de datos
- Grado
- entrega
- demuestra
- desplegar
- A pesar de las
- distinguir
- do
- DE INSCRIPCIÓN
- descargar
- cada una
- pasan fácilmente
- eficiencia
- eficiente
- encuentro
- Ingeniería
- Inglés
- Mejora
- Incluso
- excelente,
- experience
- experimento
- expertos
- explorar
- en los detalles
- Cara
- Fallidos
- halcón
- más rápida
- sentir
- pocos
- Archive
- enfoque
- encontrado
- Gratis
- Francés
- Desde
- función
- generado
- generación de AHSS
- Alemán
- obtener
- GitHub
- Donar
- Buscar
- GPU
- GPU
- gráfica
- Red neuronal gráfica
- Grupo
- guía
- Manejo
- Tienen
- es
- he
- serviciales
- Alta
- Alto rendimiento
- alta calidad
- su
- mantiene
- esperanza
- Cómo
- Como Hacer
- HTTPS
- Bujes
- i
- if
- enfermedad
- importar
- importante
- in
- Incluye
- información
- iniciado
- instalar
- instalando
- Interfaz
- dentro
- implica
- IP
- cuestiones
- IT
- Italiano
- nuggets
- Saber
- idioma
- Idiomas
- portátil
- large
- Estado latente
- luego
- APRENDE:
- aprendizaje
- dejar
- Biblioteca
- Con licencia
- ligero
- como
- línea
- líneas
- LINK
- Etiqueta LinkedIn
- Llama
- localmente
- Ubicación
- mirando
- ama
- máquina
- máquina de aprendizaje
- para lograr
- Realizar
- Management
- administrar
- dominar
- cerillas
- me
- Salud Cerebral
- mental
- Enfermedad mental
- Método
- mezcla
- modelo
- modelos
- modificar
- más,
- MEJOR DE TU
- múltiples
- my
- nombre
- ¿ Necesita ayuda
- del sistema,
- Neural
- red neural
- Nuevo
- Next
- número
- Nvidia
- of
- on
- ONE
- habiertos
- de código abierto
- funcionamiento
- sistemas operativos
- Opciones
- or
- Otro
- Otros
- "nuestr
- Supera
- salida
- salidas
- EL DESARROLLADOR
- parámetro
- parámetros
- PC
- actuación
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Por favor
- Publicación
- anterior
- Producto
- Profesional
- correctamente
- proporcionar
- proporciona un
- apoderado
- pregunta
- Preguntas
- distancia
- Reducción
- con respecto a
- reemplazar
- repositorio
- la investigación
- Recursos
- respuestas
- enrutador
- Ejecutar
- correr
- s
- Ciencia:
- Científico
- puntuaciones
- desplazamiento
- Sección
- seleccionar
- servidor
- sencillos
- desde
- a medida
- Fuente
- Español
- estándar
- el estado de la técnica
- paso
- fuerte
- Luchando
- Estudiantes
- superior
- soportes
- seguro
- Todas las funciones a su disposición
- tareas
- Técnico
- Tecnologías
- Tecnología
- telecomunicación
- texto
- generación de texto
- esa
- La
- su
- Estas
- así
- aquellos
- equipo
- a
- ficha
- Tokens
- Total
- Traducción
- try
- tutoriales
- dos
- bajo
- us
- utilizan el
- usado
- Usuario
- fácil de utilizar
- usos
- usando
- variedad
- diversos
- versión
- visión
- quieres
- we
- web
- Aplicación web
- que
- mientras
- QUIENES
- amplio
- Amplia gama
- seguirá
- la escritura
- Usted
- tú
- zephyrnet