Análisis de datos automatizado (ADA) en AWS es una solución de AWS que le permite obtener información valiosa a partir de los datos en cuestión de minutos a través de una interfaz de usuario sencilla e intuitiva. ADA ofrece una plataforma de análisis de datos nativa de AWS que está lista para ser utilizada de inmediato por analistas de datos para una variedad de casos de uso. Con ADA, los equipos pueden ingerir, transformar, gobernar y consultar diversos conjuntos de datos de una variedad de fuentes de datos sin requerir habilidades técnicas especializadas. ADA proporciona un conjunto de conectores pre-construidos para ingerir datos de una amplia gama de fuentes, incluidas Servicio de almacenamiento simple de Amazon (Amazon S3), Secuencias de datos de Amazon Kinesis, Reloj en la nube de Amazon, Amazon CloudTraily Amazon DynamoDB así como muchos otros
ADA proporciona una plataforma fundamental que pueden utilizar los analistas de datos en un conjunto diverso de casos de uso que incluyen TI, finanzas, marketing, ventas y seguridad. El conector de datos CloudWatch listo para usar de ADA permite la ingesta de datos de los registros de CloudWatch en la misma cuenta de AWS en la que se implementó ADA, o desde una cuenta de AWS diferente.
En esta publicación, demostramos cómo un desarrollador o probador de aplicaciones puede utilizar ADA para obtener información operativa de las aplicaciones que se ejecutan en AWS. También demostramos cómo puede utilizar la solución ADA para conectarse a diferentes fuentes de datos en AWS. Nosotros primero implementar la solución ADA en una cuenta de AWS y configurar la solución ADA por crear productos de datos utilizando conectores de datos. Luego utilizamos ADA Query Workbench para unir los conjuntos de datos separados y consultar los datos correlacionados, utilizando el familiar lenguaje de consulta estructurado (SQL), para obtener información. También demostramos cómo ADA se puede integrar con herramientas de inteligencia empresarial (BI) como Tableau para visualizar los datos y crear informes.
Resumen de la solución
En esta sección, presentamos la arquitectura de la solución para la demostración y explicamos el flujo de trabajo. Para fines de demostración, la aplicación personalizada se simula utilizando un AWS Lambda función que emite registros en Formato de registro de Apache a un intervalo preestablecido usando Puente de eventos de Amazon. Este formato estándar puede ser producido por muchos servidores web diferentes y leído por muchos programas de análisis de registros. Los registros de la aplicación (función Lambda) se envían a un grupo de registros de CloudWatch. Los registros históricos de la aplicación se almacenan en un depósito de S3 como referencia y con fines de consulta. Una tabla de búsqueda con una lista de Códigos de estado HTTP junto con las descripciones se almacena en una tabla de DynamoDB. Estos tres sirven como fuentes desde las cuales los datos se incorporan a ADA para su correlación, consulta y análisis. Nosotros implementar la solución ADA en una cuenta de AWS y configurar ADA. Luego creamos el productos de datos dentro de ADA para el Grupo de registros de CloudWatch, Cucharón S3y DynamoDB. A medida que se configuran los productos de datos, ADA proporciona canalizaciones de datos para ingerir los datos de las fuentes. Con ADA Query Workbench, puede consultar los datos ingeridos utilizando SQL simple para la resolución de problemas de la aplicación o el diagnóstico de problemas.
El siguiente diagrama proporciona una descripción general de la arquitectura y el flujo de trabajo del uso de ADA para obtener información sobre los registros de aplicaciones.
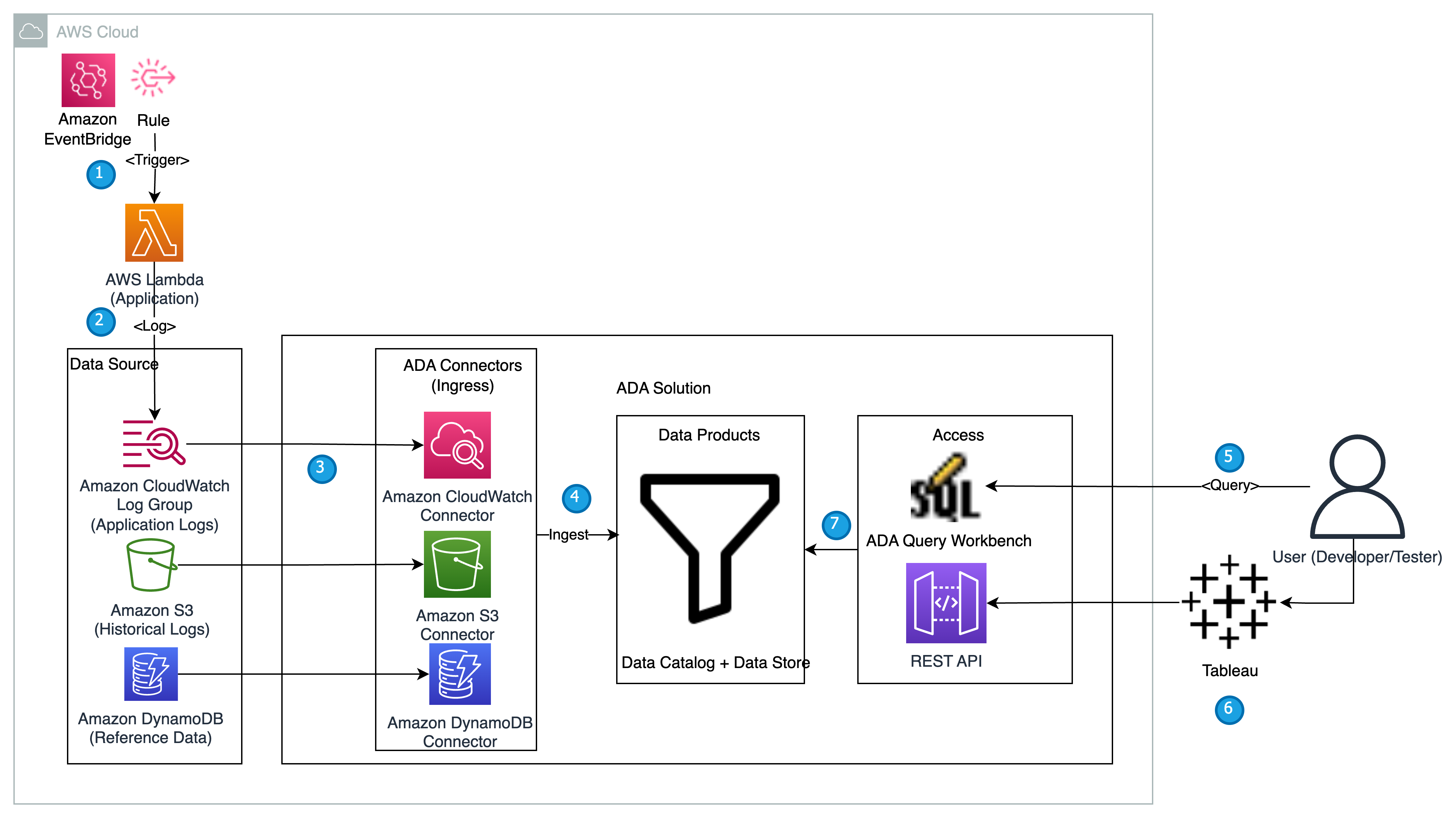
El flujo de trabajo incluye los siguientes pasos:
- Está programado que se active una función Lambda en intervalos de 2 minutos mediante EventBridge.
- La función Lambda emite registros que se almacenan en un grupo de registros de CloudWatch específico en
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. Los registros de la aplicación se generan utilizando el esquema de formato de registro de Apache, pero se almacenan en el grupo de registros de CloudWatch en formato JSON. - Los productos de datos para CloudWatch, Amazon S3 y DynamoDB se crean en ADA. El producto de datos de CloudWatch se conecta al grupo de registros de CloudWatch donde se almacenan los registros de la aplicación (función Lambda). El conector de Amazon S3 se conecta a una carpeta de depósito de S3 donde se almacenan los registros históricos. El conector de DynamoDB se conecta a una tabla de DynamoDB donde se almacenan los códigos de estado a los que hace referencia la aplicación y los registros históricos.
- Para cada uno de los productos de datos, ADA implementa la infraestructura de canalización de datos para ingerir datos de las fuentes. Cuando se completa la ingesta de datos, puede escribir consultas utilizando SQL a través de ADA Query Workbench.
- Puede iniciar sesión en el portal de ADA y redactar consultas SQL desde Query Workbench para obtener información sobre los registros de la aplicación. Opcionalmente, puede guardar la consulta y compartirla con otros usuarios de ADA en el mismo dominio. La función de consulta ADA funciona con Atenea amazónica, que es un servicio de análisis interactivo sin servidor que proporciona una forma simplificada y flexible de analizar petabytes de datos.
- Tableau está configurado para acceder a los productos de datos ADA a través de puntos finales de salida ADA. Luego crea un panel con dos gráficos. El primer gráfico es un mapa de calor que muestra la prevalencia de códigos de error HTTP correlacionados con los puntos finales de la API de la aplicación. El segundo gráfico es un gráfico de barras que muestra las 10 API de aplicaciones principales con un recuento total de códigos de error HTTP a partir de los datos históricos.
Requisitos previos
Para esta publicación, debe completar los siguientes requisitos previos:
- Instale la Interfaz de línea de comandos de AWS (CLI de AWS), Kit de desarrollo en la nube de AWS (CDK de AWS) requisitos previos, específico de TypeScript requisitos previosy git.
- Despliegue la solución ADA en su cuenta de AWS en el
us-east-1Región.- Proporcione un correo electrónico de administrador al iniciar ADA Formación en la nube de AWS pila. Esto es necesario para que ADA envíe la contraseña del usuario root. Se requiere un número de teléfono de administrador para recibir un mensaje de contraseña de un solo uso si la autenticación multifactor (MFA) está habilitada. Para esta demostración, MFA no está habilitado.
- Cree e implemente la aplicación de muestra (disponible en Repositorio GitHub) solución para que los siguientes recursos puedan ser aprovisionados en su cuenta en el
us-east-1Región:- Una función Lambda que simula la aplicación de registro y una regla EventBridge que invoca la función de la aplicación en intervalos de 2 minutos.
- Un depósito de S3 con las políticas de depósito relevantes y un archivo CSV que contiene los registros históricos de la aplicación.
- Una tabla de DynamoDB con los datos de búsqueda.
- Pertinente Gestión de identidades y accesos de AWS (IAM) roles y permisos necesarios para los servicios.
- Opcionalmente, instale Tableau Desktop, un proveedor de BI externo. Para esta publicación, utilizamos Tableau Desktop versión 2021.2. El uso de una versión con licencia de la aplicación Tableau Desktop conlleva un costo. Para obtener detalles adicionales, consulte la Licencias de Tableau información.
Implementar y configurar ADA
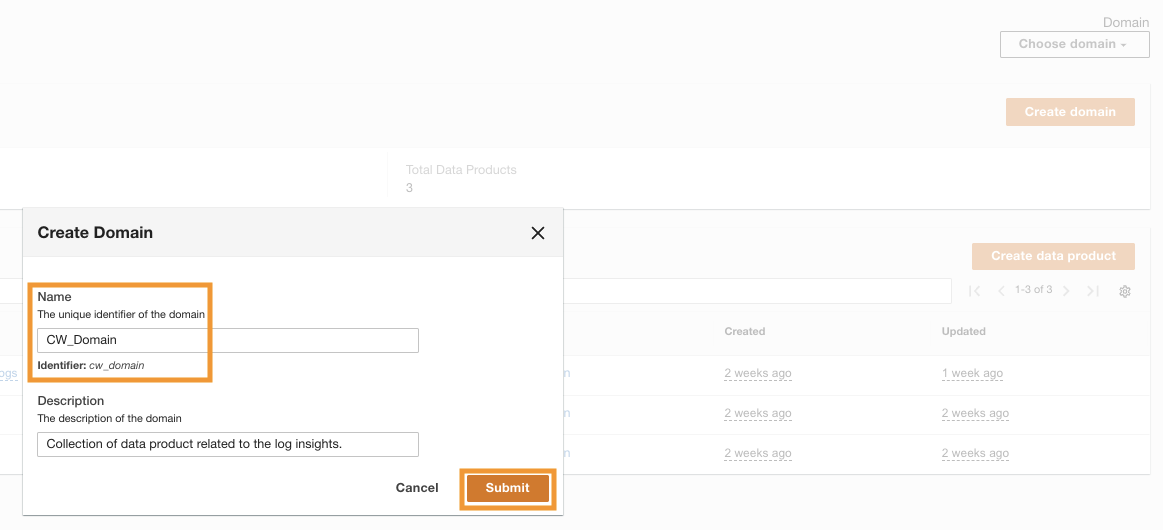
Una vez que ADA se haya implementado correctamente, podrá iniciar sesión utilizando el correo electrónico de administrador proporcionado durante la instalación. Luego creas un dominio llamado CW_Domain. Un dominio es una colección de productos de datos definida por el usuario. Por ejemplo, un dominio podría ser un equipo o un proyecto. Los dominios proporcionan una forma estructurada para que los usuarios organicen sus productos de datos y administren los permisos de acceso.
- En la consola ADA, elija dominios en el panel de navegación.
- Elige Crear dominio.
- Ingresa un nombre (
CW_Domain) y descripción, luego elija Enviar.
Configure la infraestructura de la aplicación de muestra mediante AWS CDK
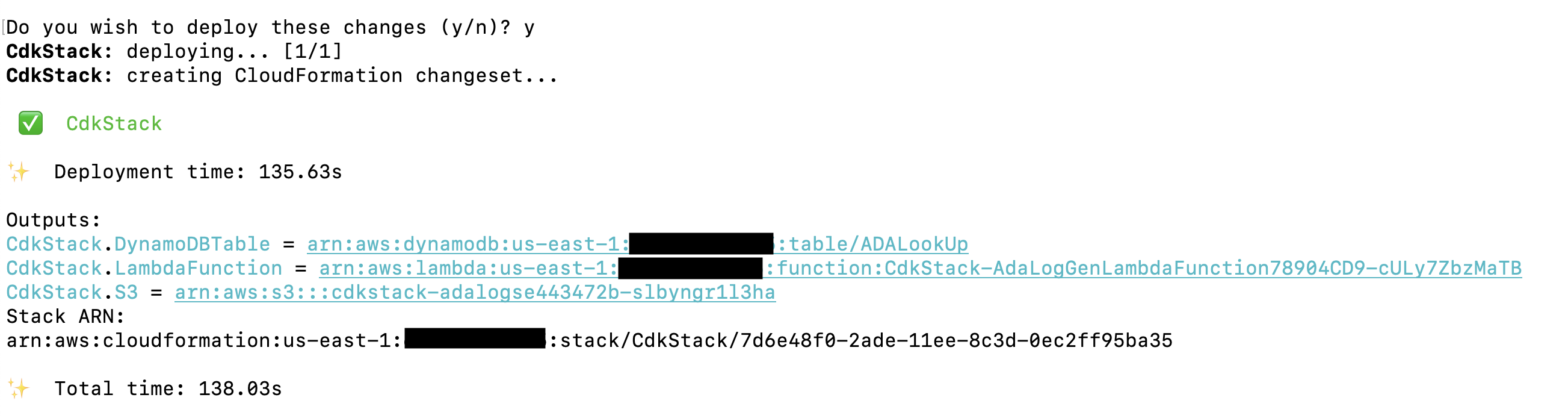
La solución AWS CDK que implementa la aplicación de demostración está alojada en GitHub. Los pasos para clonar el repositorio y configurar el proyecto AWS CDK se detallan en esta sección. Antes de ejecutar estos comandos, asegúrese de configurar sus credenciales de AWS. Cree una carpeta, abra la terminal y navegue hasta la carpeta donde debe instalarse la solución AWS CDK. Ejecute el siguiente código:
Estos pasos realizan las siguientes acciones:
- Instalar las dependencias de la biblioteca.
- Construye el proyecto
- Genere una plantilla de CloudFormation válida
- Implemente la pila utilizando AWS CloudFormation en su cuenta de AWS
La implementación demora entre 1 y 2 minutos y crea la tabla de búsqueda de DynamoDB, la función Lambda y el depósito S3 que contiene los archivos de registro históricos como resultados. Copie estos valores a una aplicación de edición de texto, como el Bloc de notas.
Crear productos de datos ADA
Creamos tres productos de datos diferentes para esta demostración, uno para cada fuente de datos que consultará para obtener información operativa. Un producto de datos es un conjunto de datos (una colección de datos como una tabla o un archivo CSV) que se ha importado correctamente a ADA y que se puede consultar.
Crear un producto de datos de CloudWatch
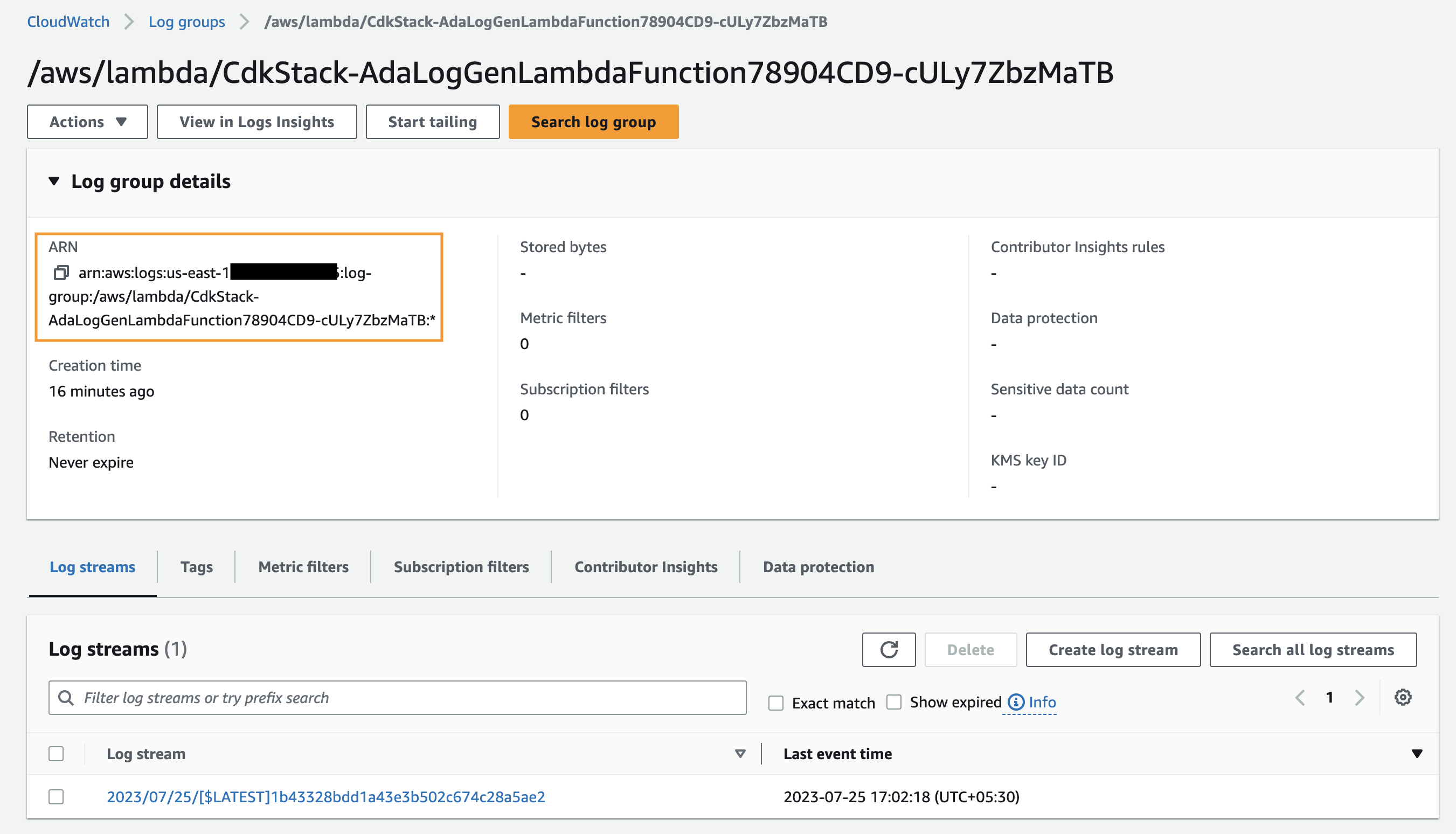
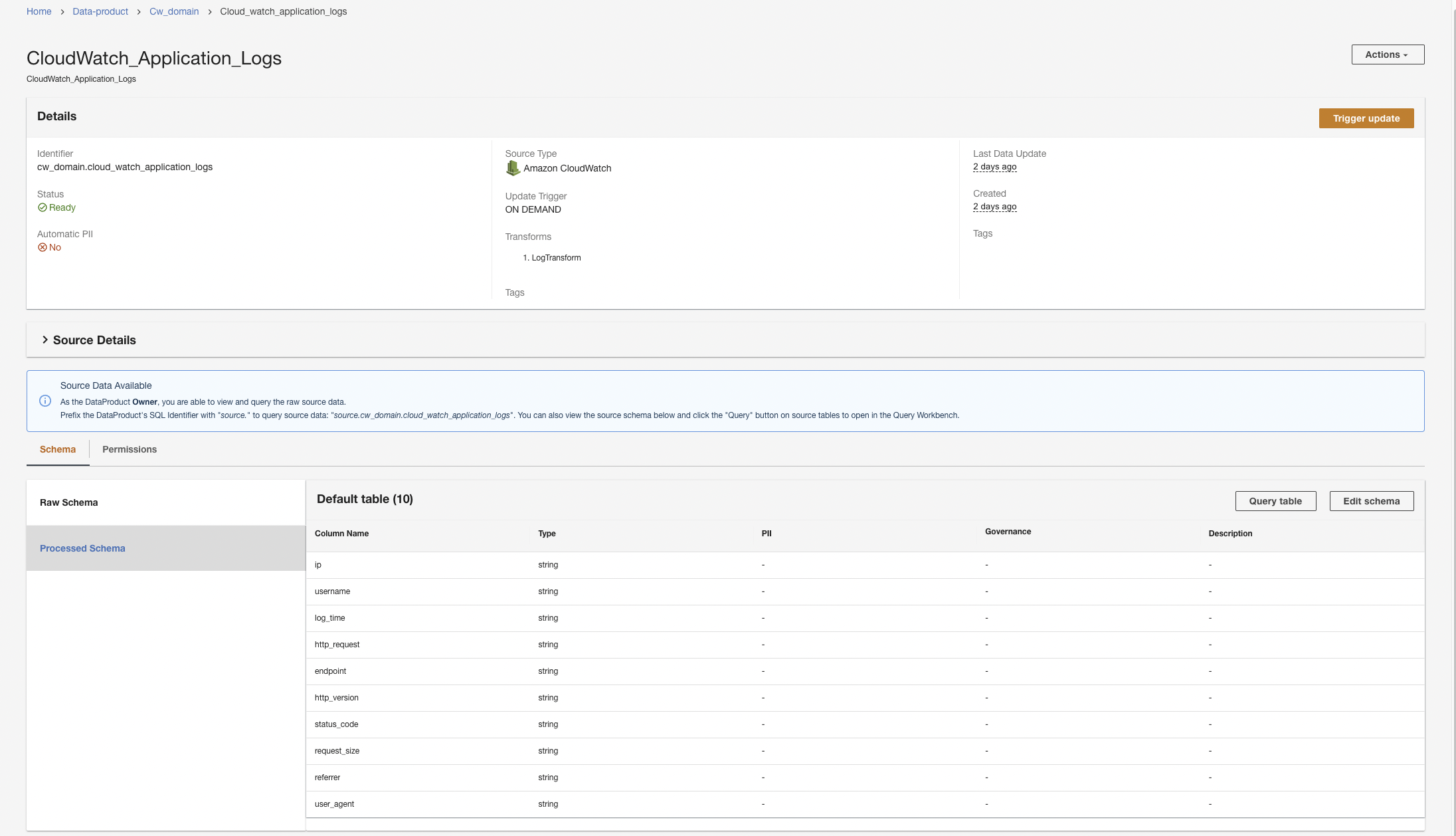
Primero, creamos un producto de datos para los registros de la aplicación configurando ADA para que ingiera el grupo de registros de CloudWatch para la aplicación de muestra (función Lambda). Utilizar el CdkStack.LambdaFunction salida para obtener el ARN de la función Lambda y ubicar el ARN del grupo de registros de CloudWatch correspondiente en la consola de CloudWatch.
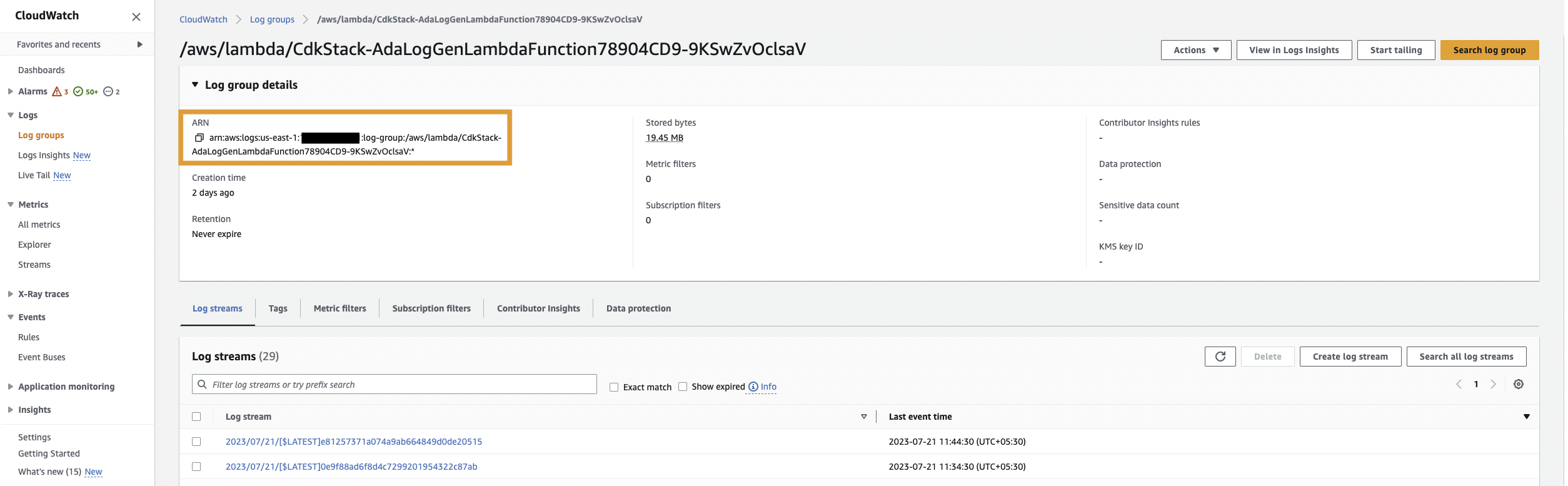
Luego complete los siguientes pasos:
- En la consola de ADA, navegue hasta el dominio de ADA y cree un producto de datos de CloudWatch.
- Nombreingresa un nombre.
- Tipo de fuente, escoger Reloj en la nube de Amazon.
- Deshabilitar IIP automática.
ADA tiene una función que detecta automáticamente datos de información de identificación personal (PII) durante la importación y que está habilitada de forma predeterminada. Para esta demostración, deshabilitamos esta opción para el producto de datos porque el descubrimiento de datos PII no está dentro del alcance de esta demostración.
- Elige Siguiente.
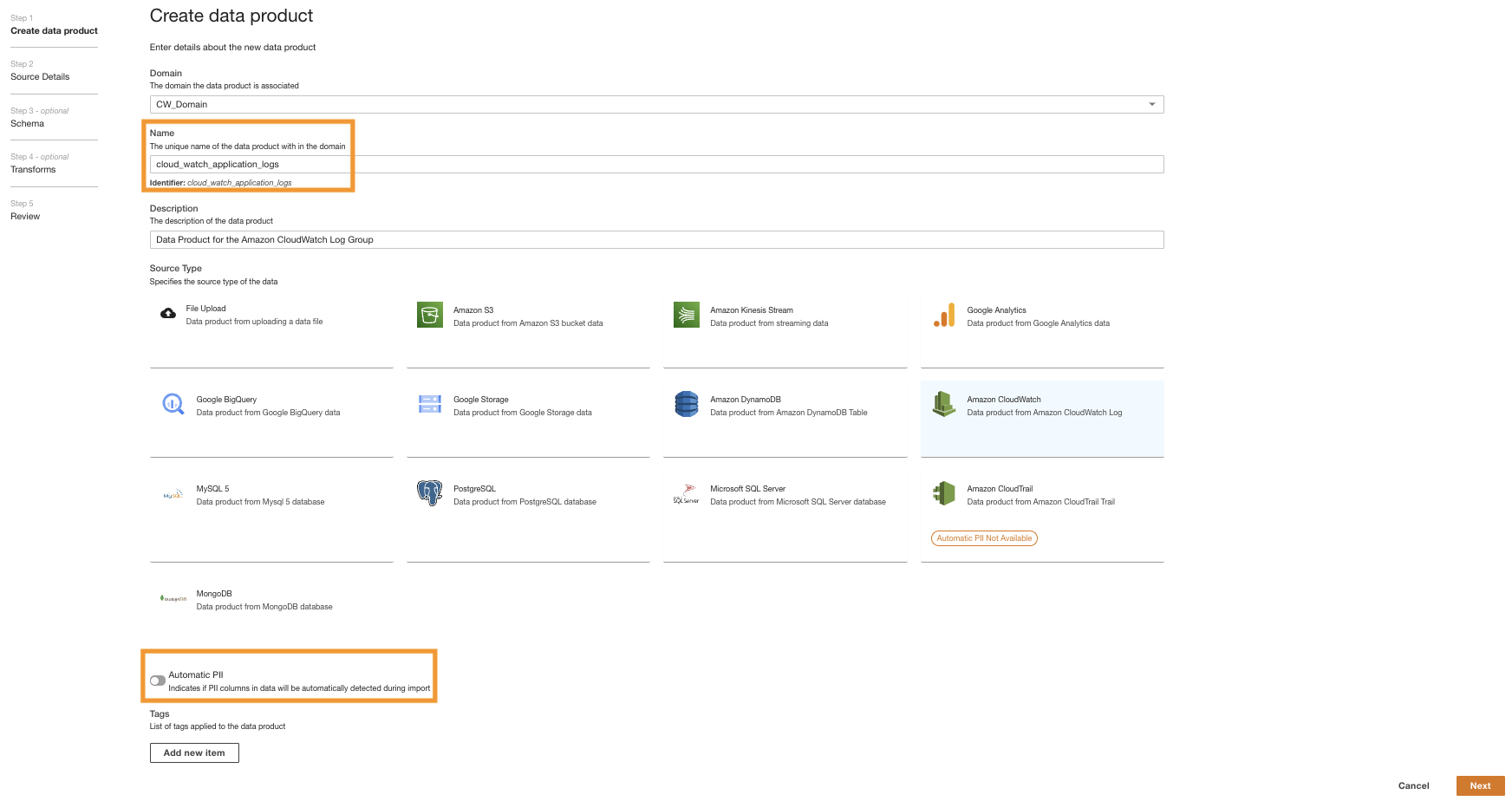
- Busque y elija el ARN del grupo de registros de CloudWatch copiado en el paso anterior.

- Copie el ARN del grupo de registros.
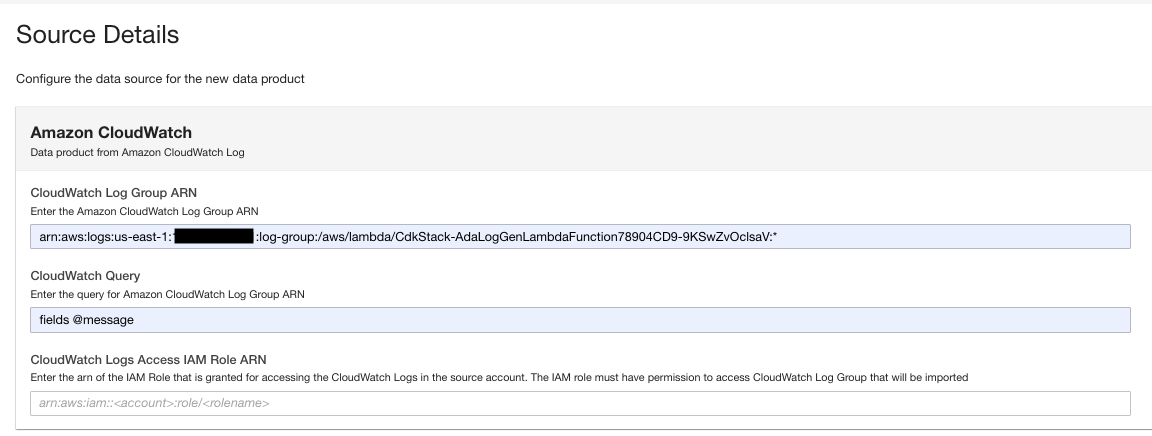
- En la página del producto de datos, ingrese el ARN del grupo de registros.
- Consulta de vigilancia en la nube, ingrese una consulta que desee que ADA obtenga del grupo de registros.
En esta demostración, consultamos el campo @message porque estamos interesados en obtener los registros de la aplicación del grupo de registros.
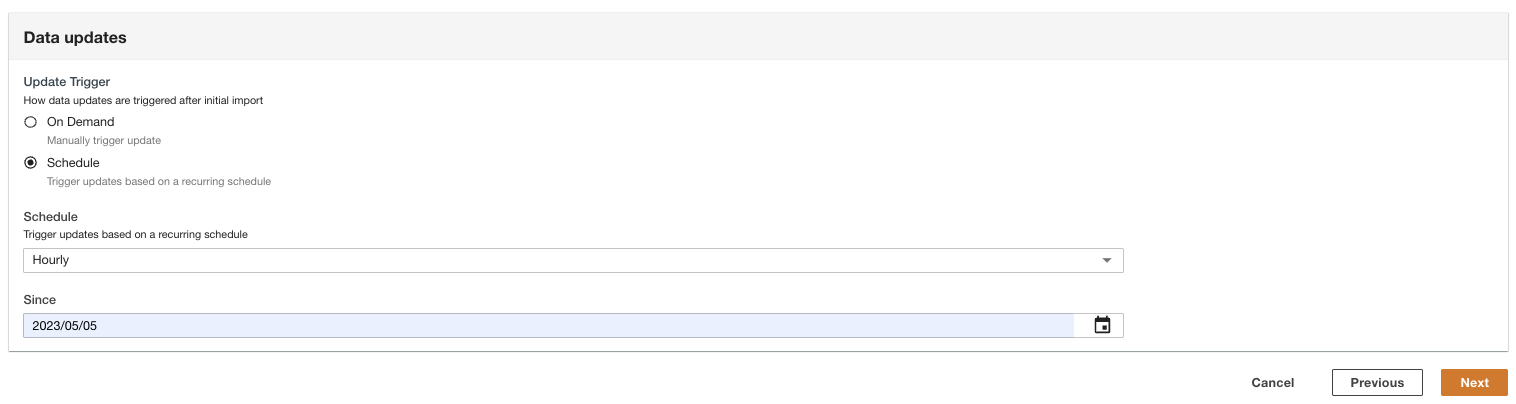
- Seleccione cómo se activan las actualizaciones de datos después de la importación inicial.
ADA se puede configurar para ingerir los datos de la fuente en intervalos flexibles (hasta 15 minutos o más) o bajo demanda. Para la demostración, configuramos las actualizaciones de datos para que se ejecuten cada hora.
- Elige Siguiente.
A continuación, ADA se conectará al grupo de registros y consultará el esquema. Debido a que los registros están en formato de registro Apache, los transformamos en campos separados para poder ejecutar consultas en los campos de registro específicos. ADA proporciona cuatro tu préstamo estudiantil transformaciones y admite transformaciones personalizadas a través de un script Python. En esta demostración, ejecutamos un script Python personalizado para transformar el campo de mensaje JSON en campos de formato de registro Apache.
- Elige Transformar esquema.
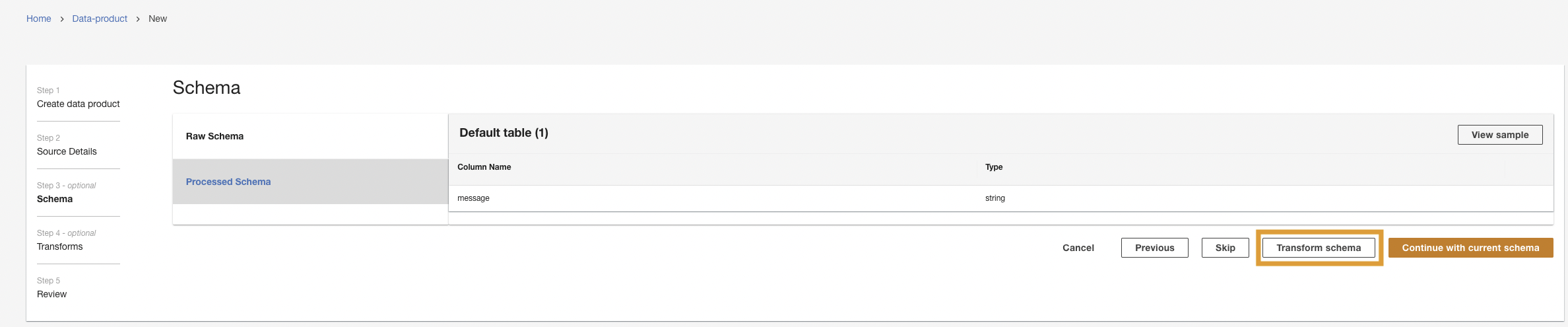
- Elige Crear nueva transformación.
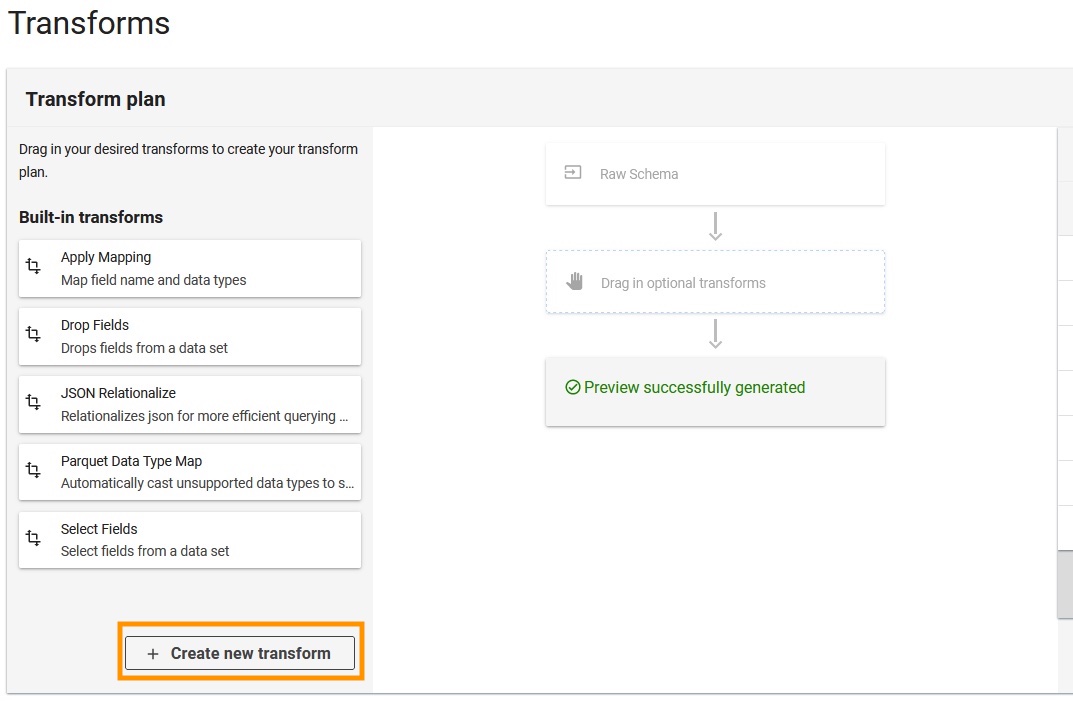
- Cargar la
apache-log-extractor-transform.pyguión del/asset/transform_logs/carpeta. - Elige Enviar.
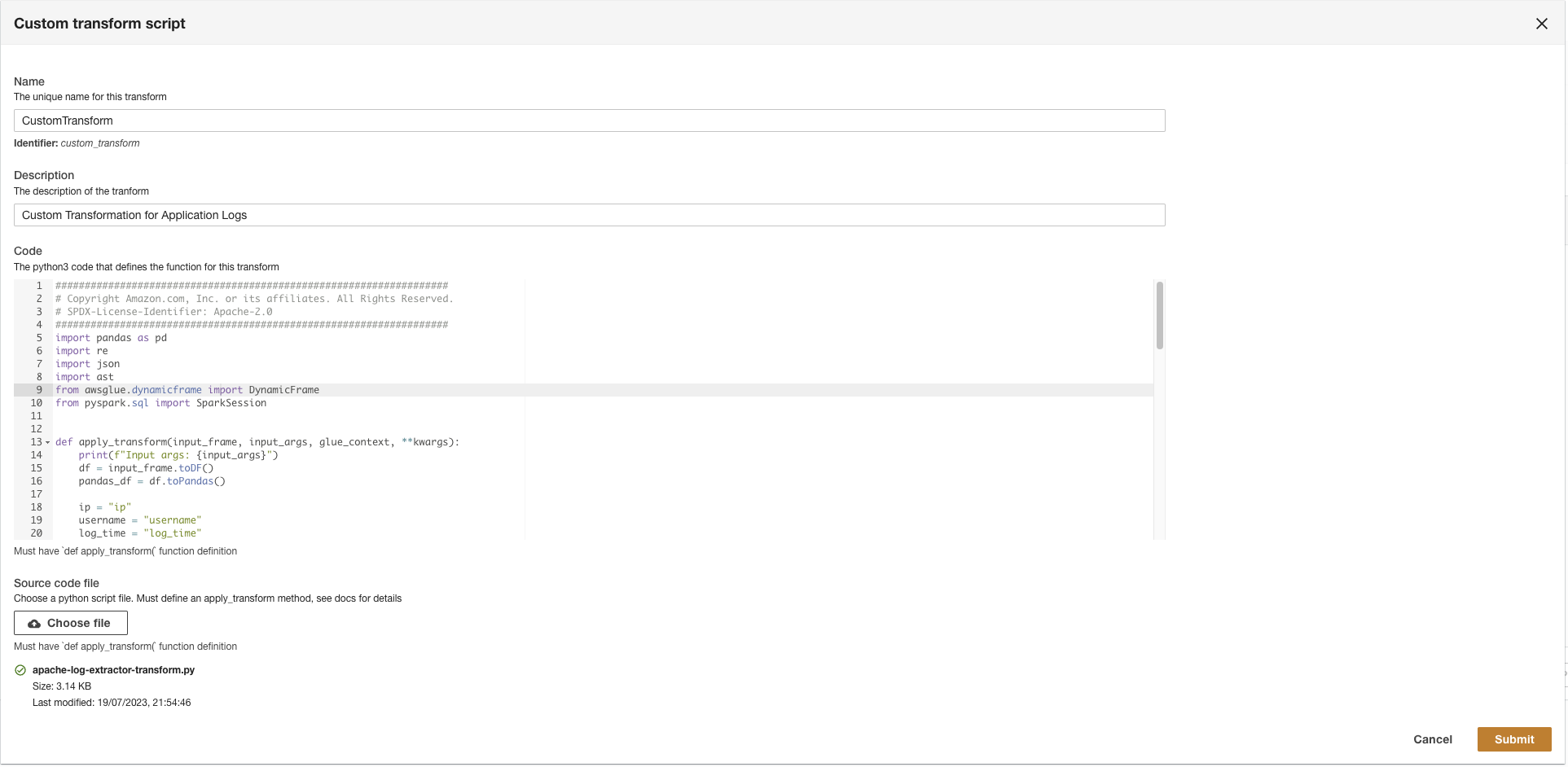
ADA transformará los registros de CloudWatch utilizando el script y presentará el esquema procesado.
- Elige Siguiente.
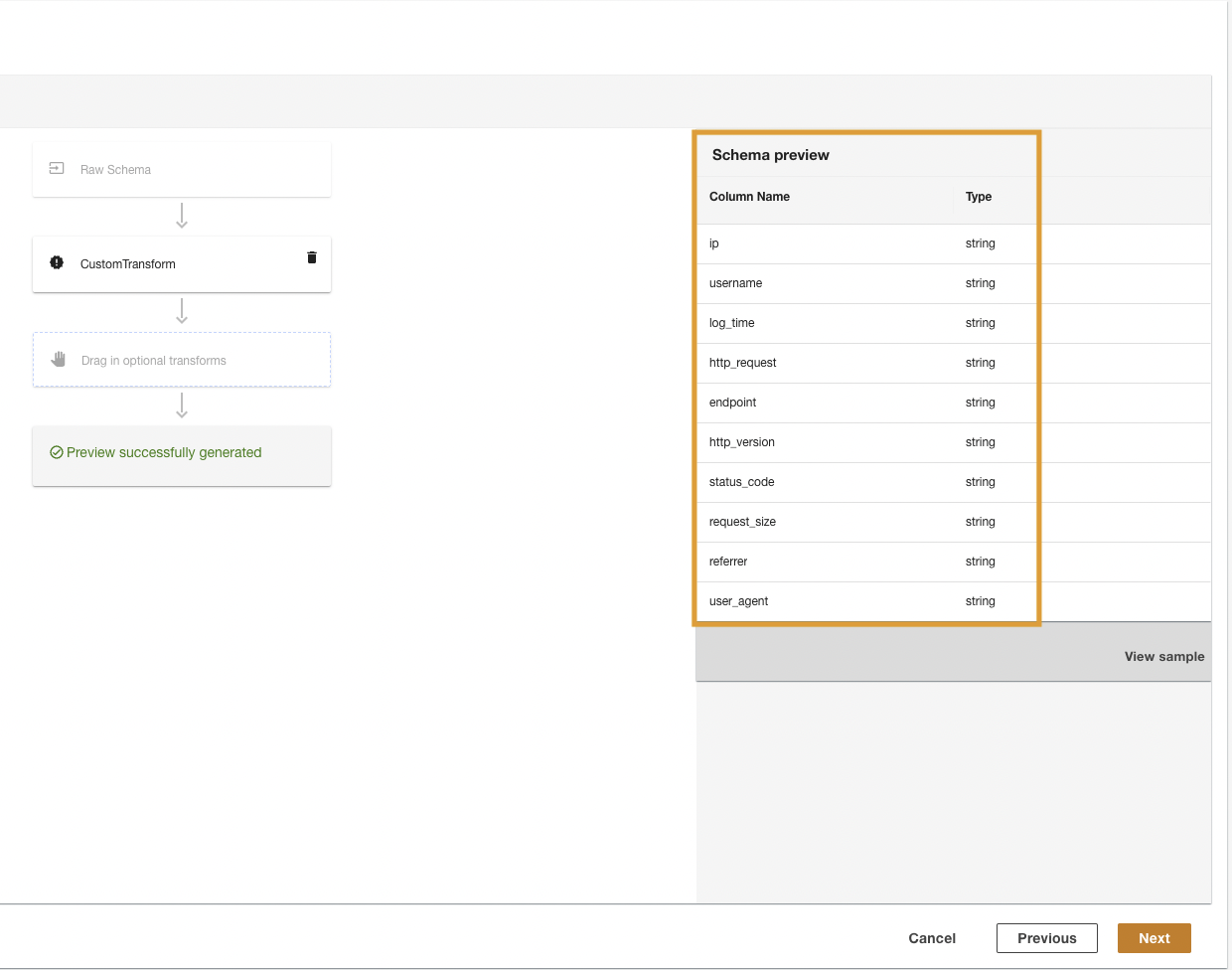
- En el último paso, revise los pasos y elija Enviar.
ADA iniciará el procesamiento de datos, creará las canalizaciones de datos y preparará los grupos de registros de CloudWatch para consultarlos desde Query Workbench. Este proceso tardará unos minutos en completarse y se mostrará en la consola ADA en Productos de datos.
Crear un producto de datos de Amazon S3
Repetimos los pasos para agregar los registros históricos de la fuente de datos de Amazon S3 y buscar datos de referencia en la tabla de DynamoDB. Para estas dos fuentes de datos, no creamos transformaciones personalizadas porque los formatos de datos están en CSV (para registros históricos) y atributos clave (para datos de búsqueda de referencia).
- En la consola ADA, cree un nuevo producto de datos.
- Ingresa un nombre (
hist_logs) y elige Amazon S3.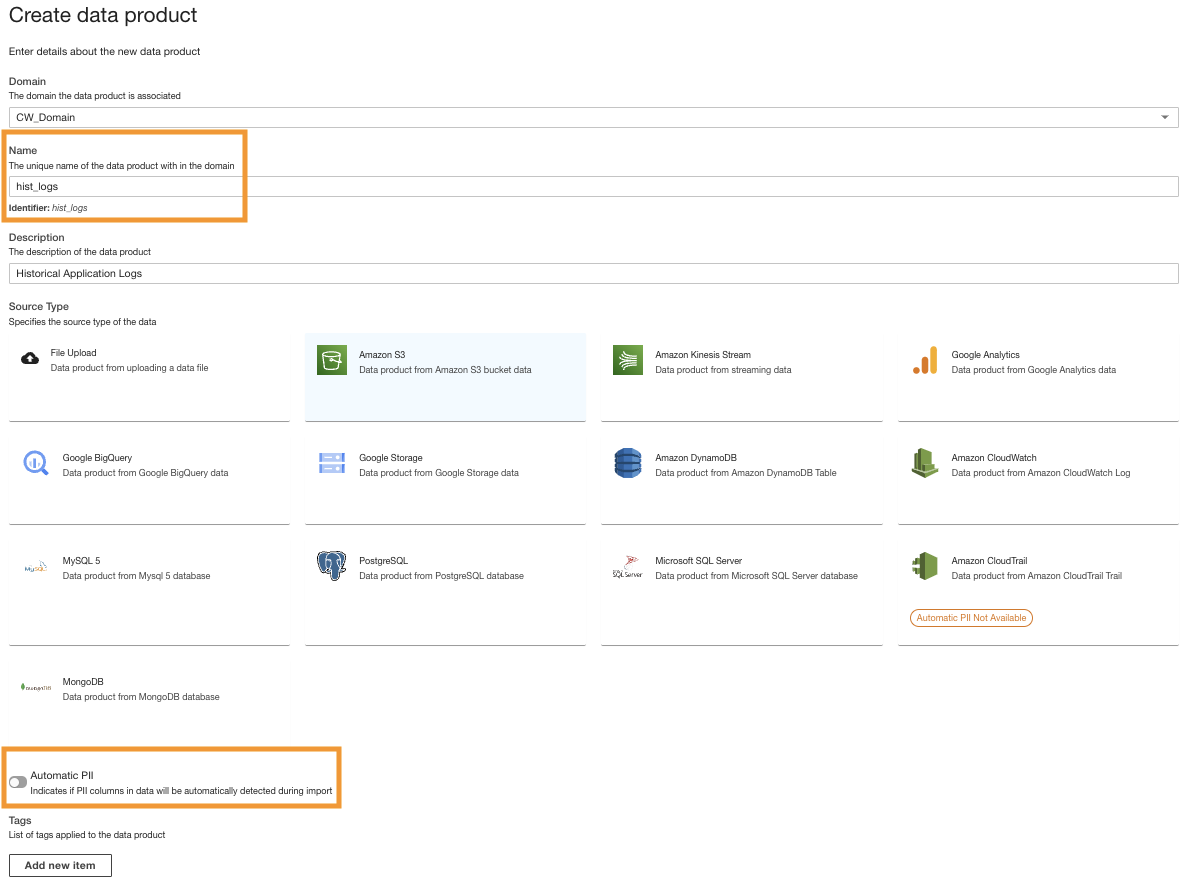
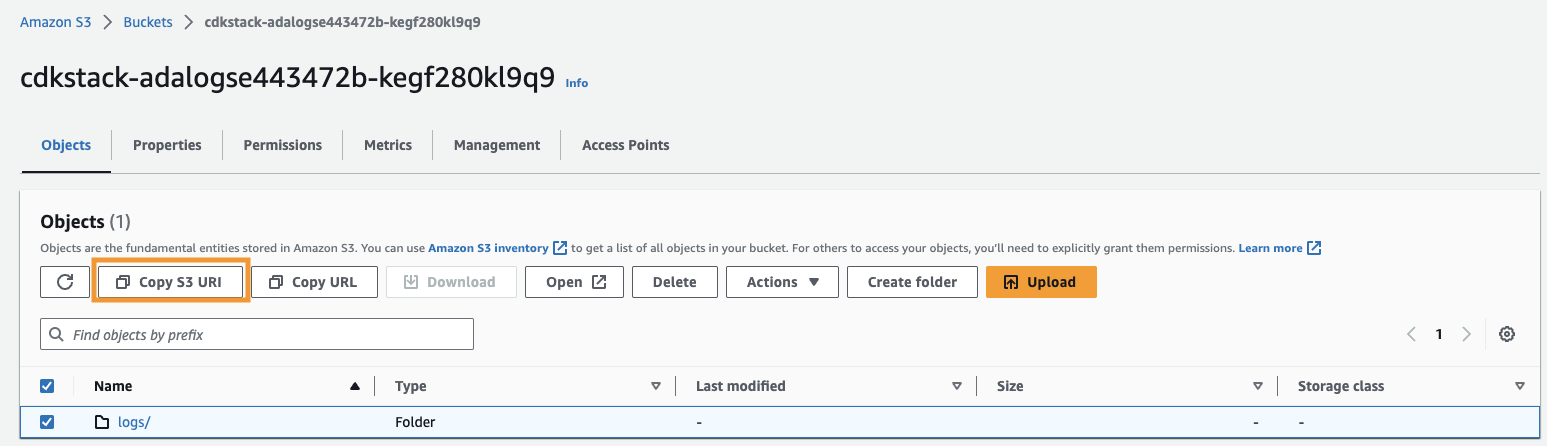
- Copie el URI de Amazon S3 (el texto después
arn:aws:s3:::) desde elCdkStack.S3variable de salida y navegue hasta la consola de Amazon S3. - En el cuadro de búsqueda, ingrese el texto copiado, abra el depósito S3, seleccione el
/logscarpeta y elija Copiar URI de S3.
Los registros históricos se almacenan en esta ruta.
- Vuelva a la consola ADA e ingrese el URI de S3 copiado para Ubicación S3.
- Activador de actualización, seleccione On Demand porque los registros históricos se actualizan con una frecuencia no especificada.
- Política de actualización, seleccione Adjuntar para agregar datos recién importados a los datos existentes.
- Elige Siguiente.
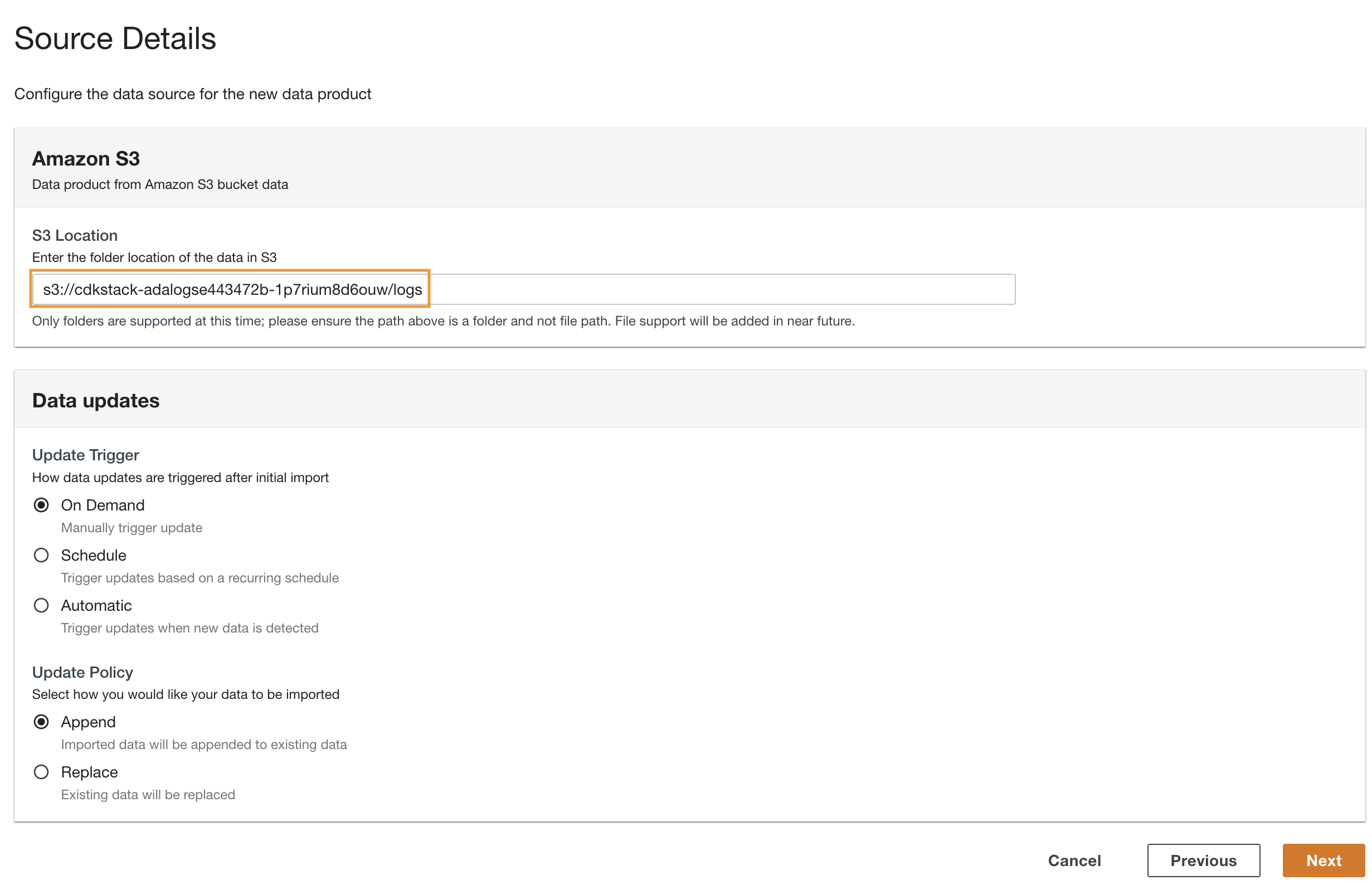
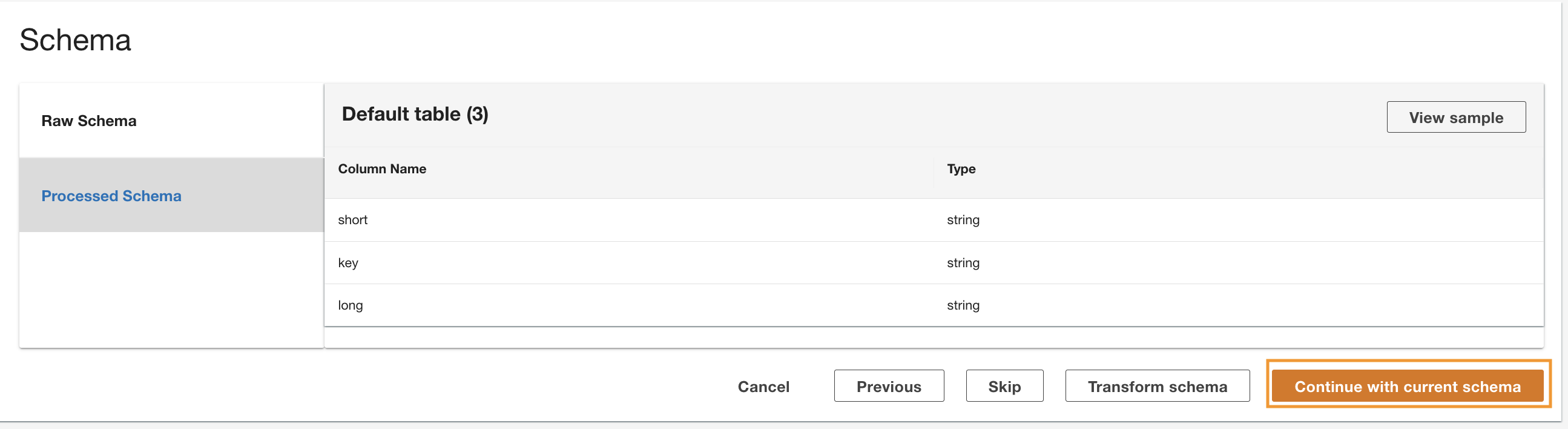
ADA procesa el esquema de los archivos en la ruta de la carpeta seleccionada. Debido a que los registros están en formato CSV, ADA puede leer los nombres de las columnas sin requerir transformaciones adicionales. Sin embargo, las columnas status_code y request_size ADA infiere que son de tipo largo. Queremos mantener los tipos de datos de las columnas consistentes entre los productos de datos para que podamos unir las tablas de datos y consultar los datos. La columna status_code se utilizará para crear uniones entre las tablas de datos.
- Elige Transformar esquema para cambiar los tipos de datos de las dos columnas al tipo de datos de cadena.
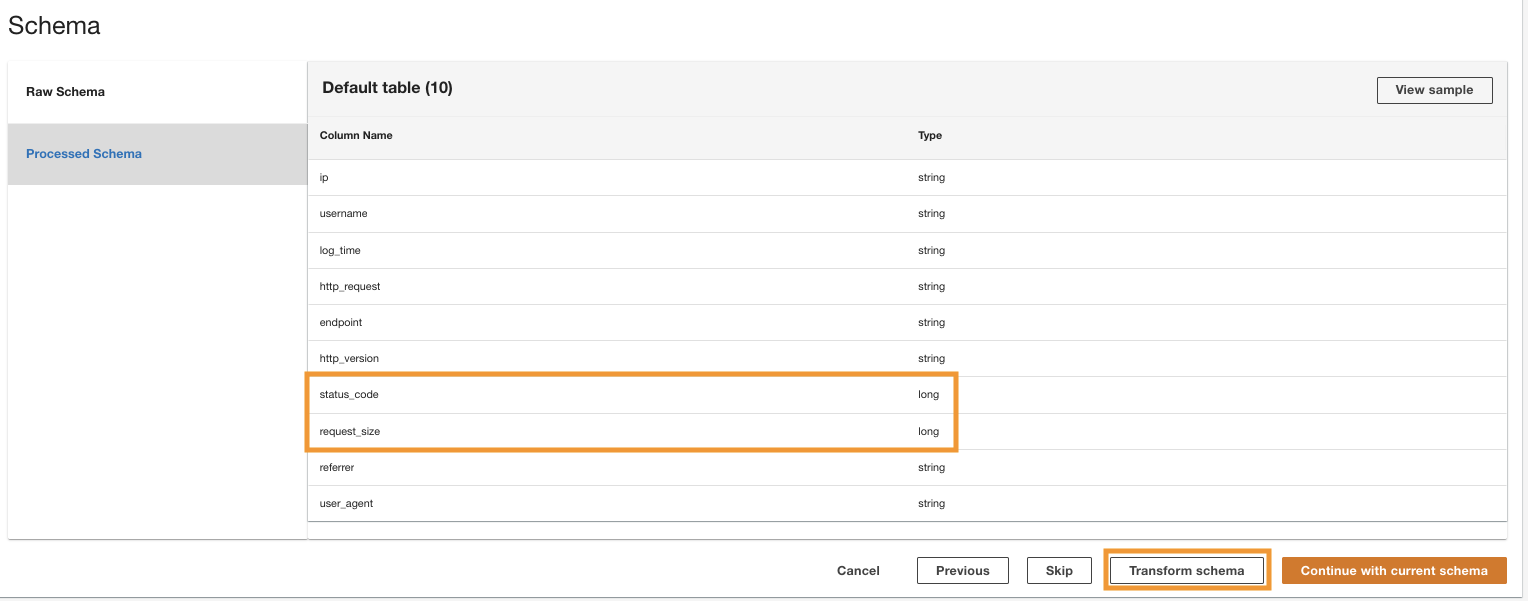
Tenga en cuenta los nombres de las columnas resaltadas en el Vista previa del esquema panel antes de aplicar las transformaciones del tipo de datos.
- En plan de transformación panel, debajo Transformaciones incorporadas, escoger Aplicar mapeo.
Esta opción le permite cambiar el tipo de datos de un tipo a otro.
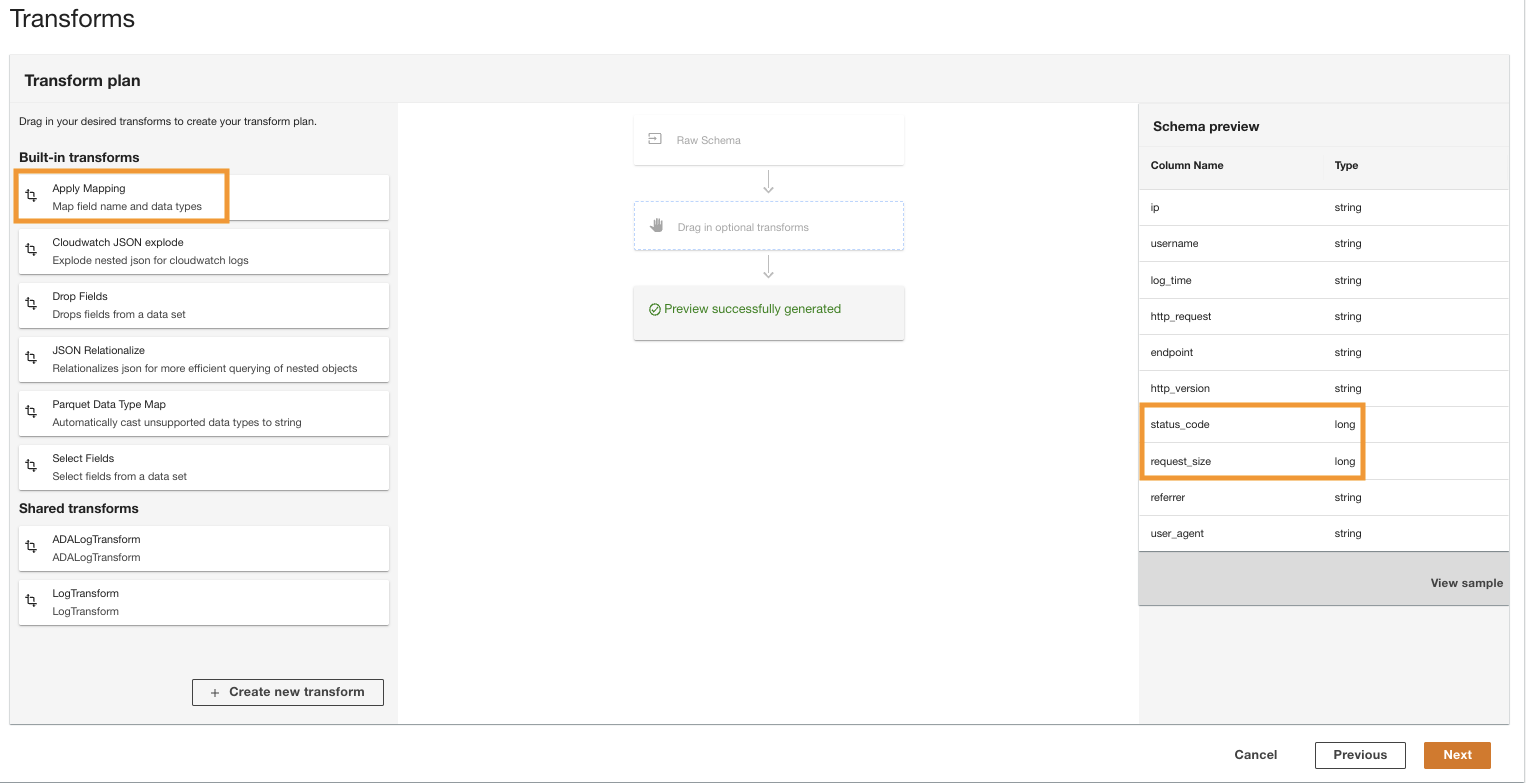
- En Aplicar mapeo sección, deseleccionar Eliminar otros campos.
Si esta opción no está deshabilitada, solo se conservarán las columnas transformadas y se eliminarán todas las demás columnas. Como queremos conservar todas las columnas, desactivamos esta opción.
- under Asignaciones de campopara Viejo nombre y Nuevo nombre, introduzca
status_codey para Nuevo tipo, introduzcastring.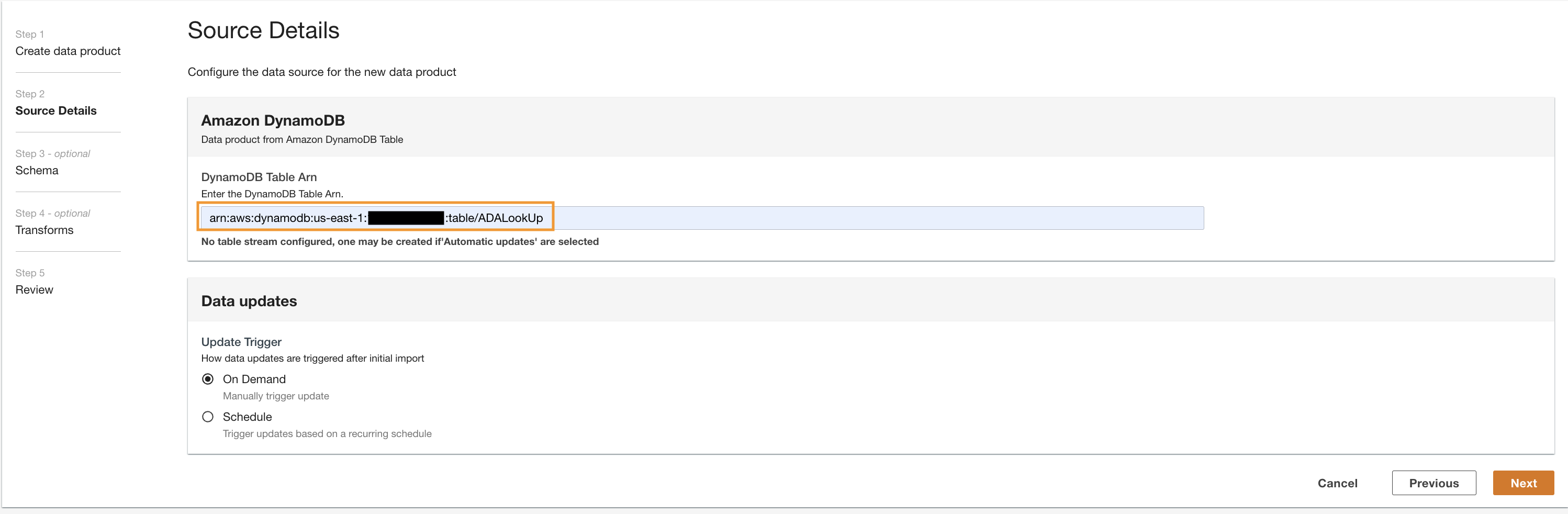
- Elige Añadir artículo.
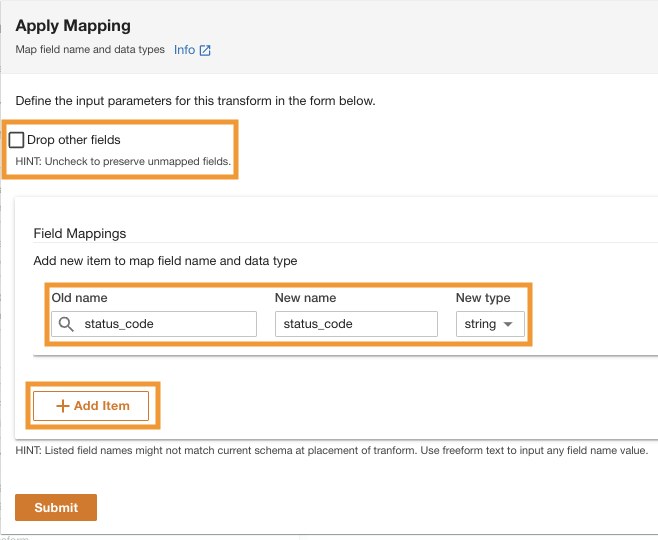
- Viejo nombre y Nuevo nombre¸ ingrese request_size y para Nuevo tipo de datos, ingrese la cadena.
- Elige Enviar.
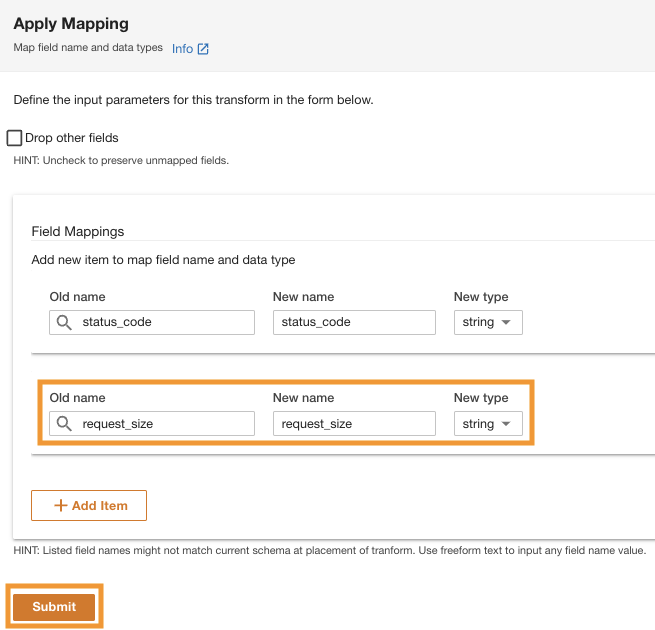
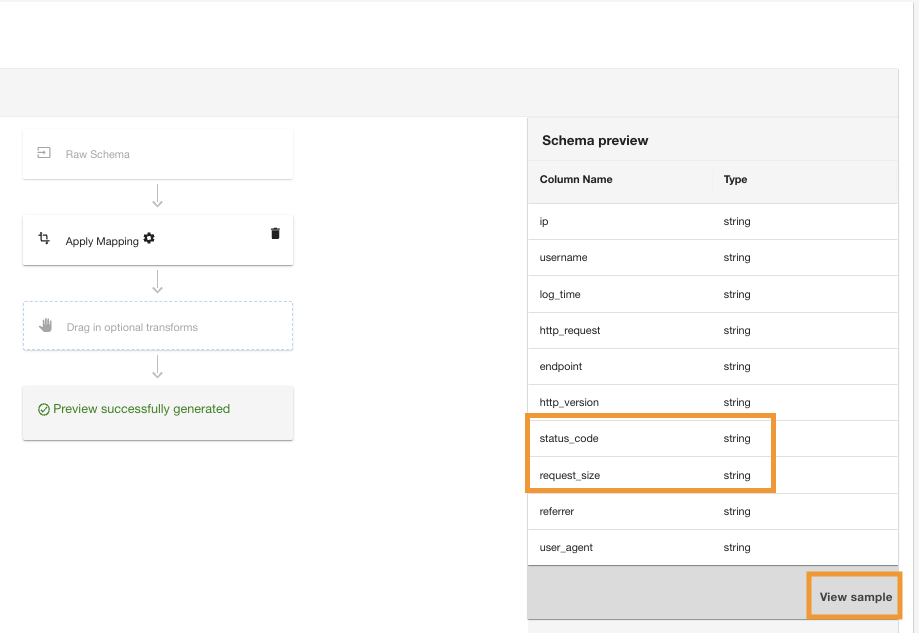
ADA aplicará la transformación de mapeo en la fuente de datos de Amazon S3. Tenga en cuenta los tipos de columnas en el Vista previa del esquema cristal.
- Elige Ver muestra para obtener una vista previa de los datos con la transformación aplicada.
ADA mostrará el reconocimiento de datos PII para garantizar que solo los usuarios autorizados puedan ver los datos o que el conjunto de datos no contenga ningún dato PII.
- Elige Muy de acuerdo para continuar viendo los datos de muestra.
Tenga en cuenta que el esquema es idéntico al esquema del grupo de registros de CloudWatch porque tanto los registros de la aplicación actual como los históricos de la aplicación están en formato de registro Apache.
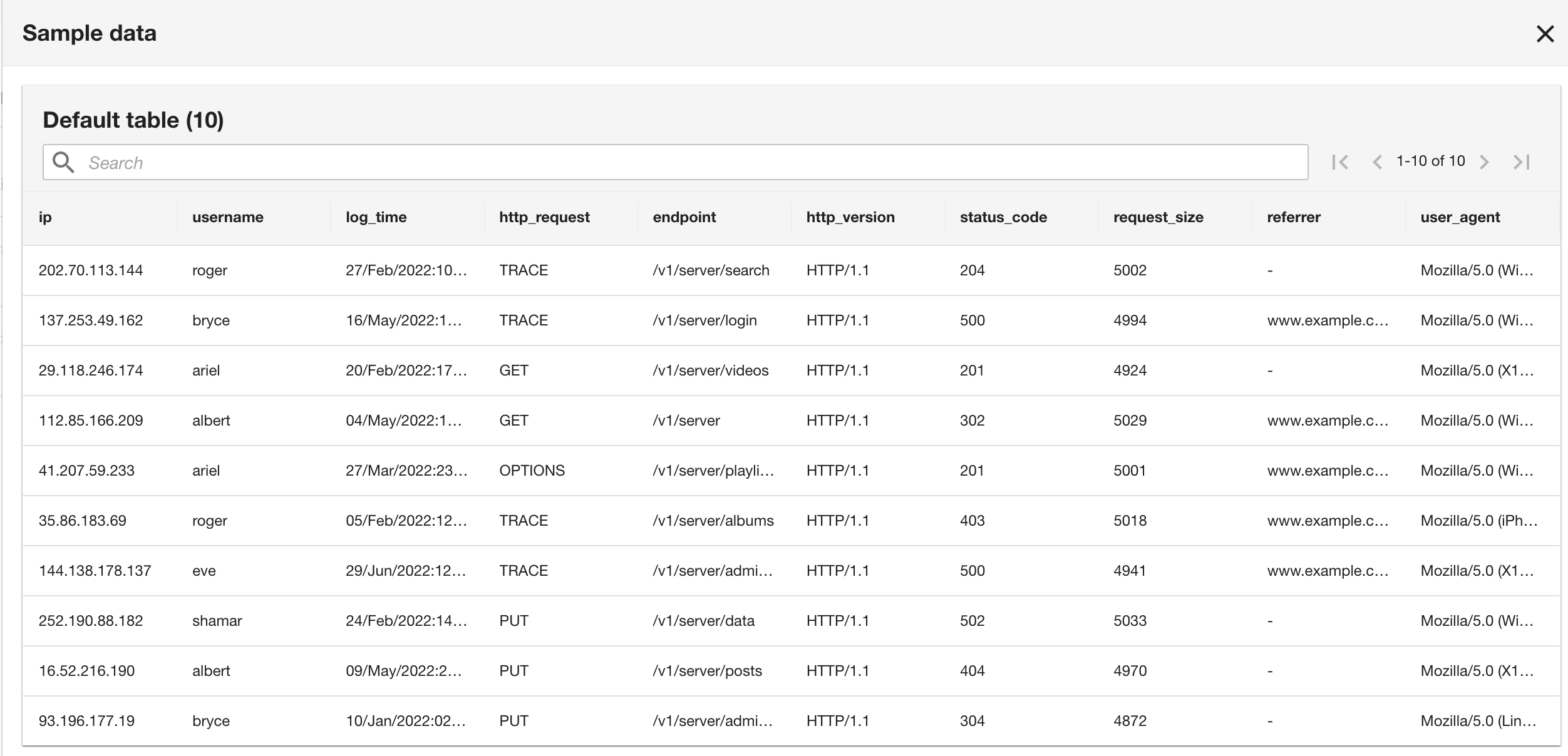
- En el paso final, revise la configuración y elija Enviar.
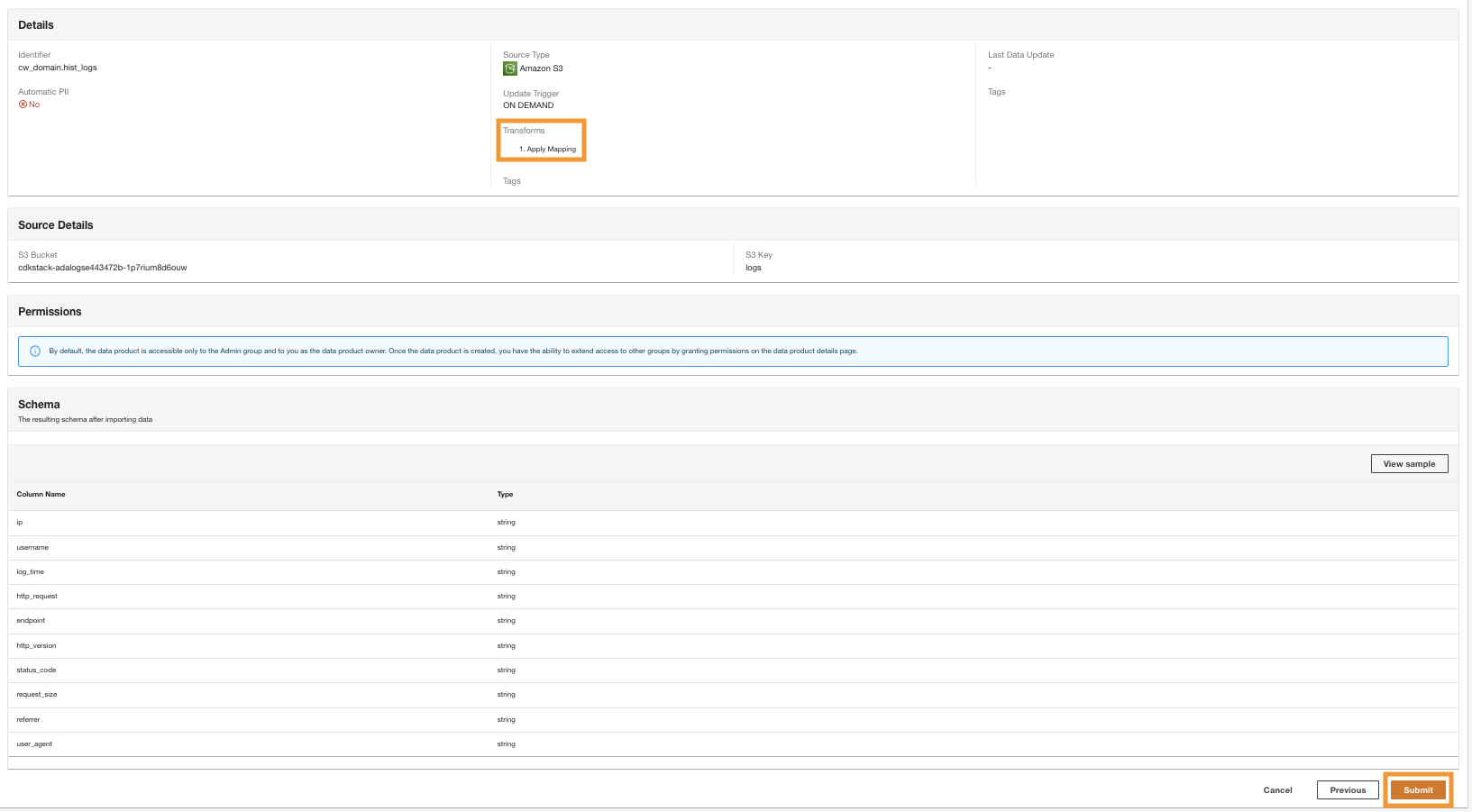
ADA comienza a procesar los datos desde la fuente de Amazon S3, crea la infraestructura de backend y prepara el producto de datos. Este proceso lleva unos minutos dependiendo del tamaño de los datos.
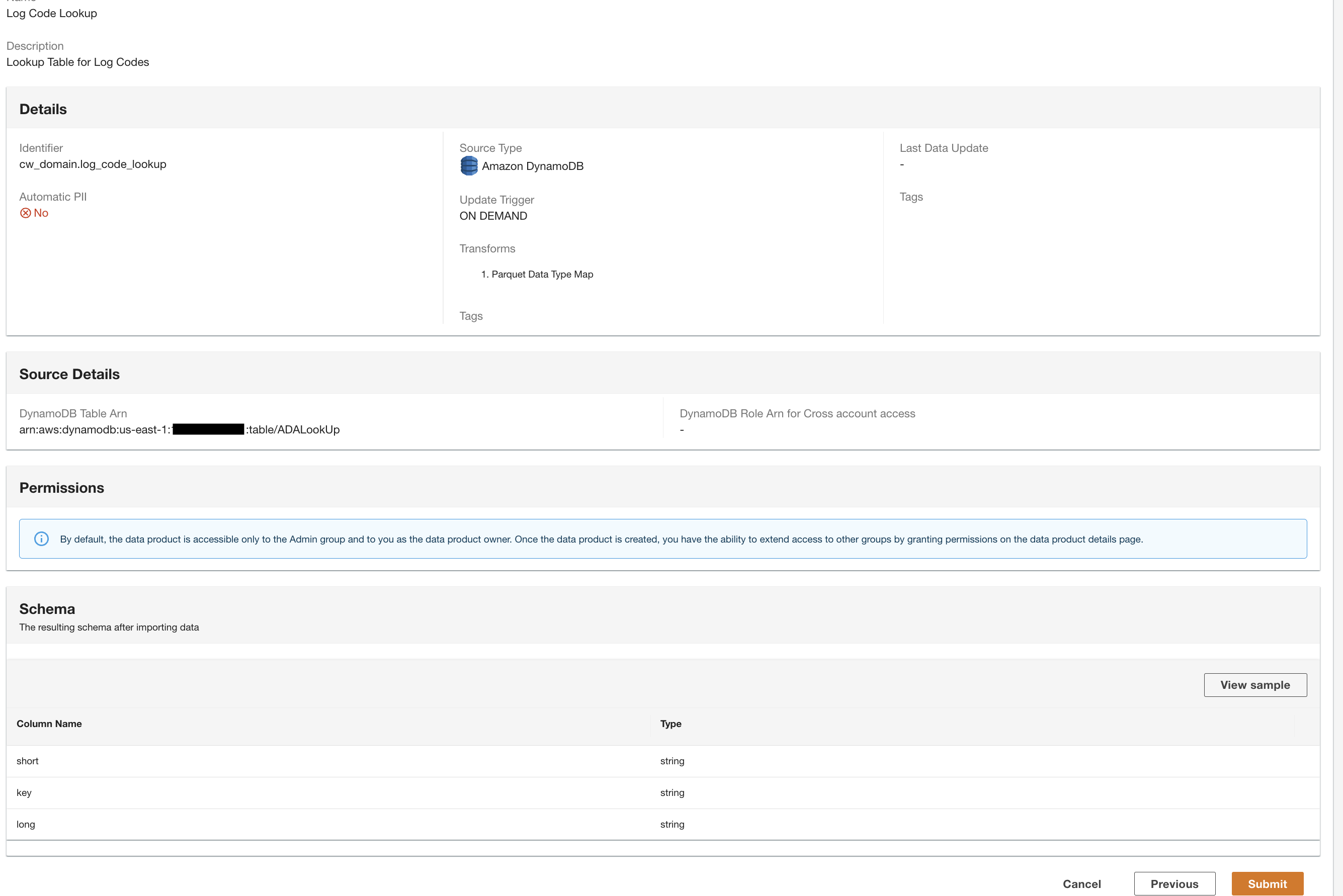
Crear un producto de datos de DynamoDB
Por último, creamos un producto de datos de DynamoDB. Complete los siguientes pasos:
- En la consola ADA, cree un nuevo producto de datos.
- Ingresa un nombre (
lookup) y elige Amazon DynamoDB.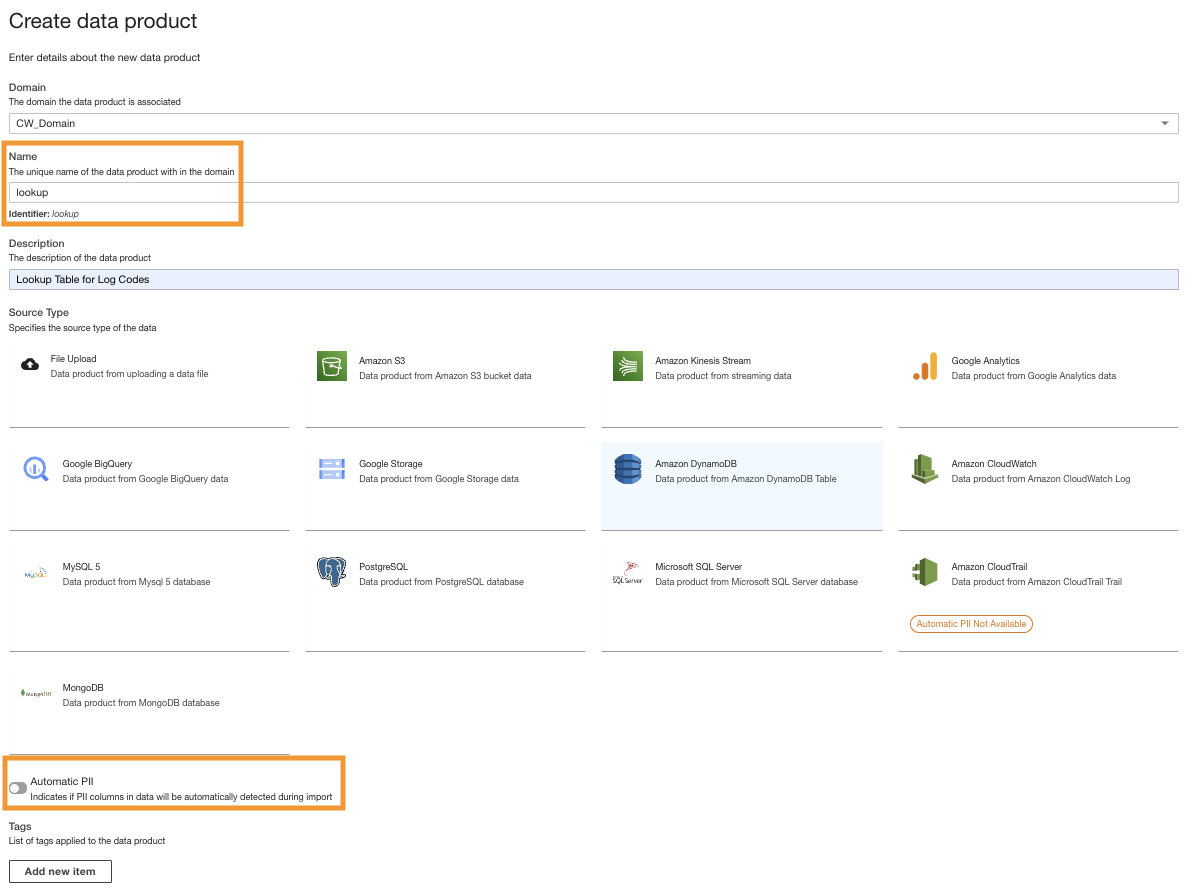
- Escriba la
Cdk.DynamoDBTablevariable de salida para ARN de la tabla de DynamoDB.
Esta tabla contiene atributos clave que se utilizarán como tabla de búsqueda en esta demostración. Para los datos de búsqueda, utilizamos códigos HTTP y descripciones largas y cortas de los códigos. También puede utilizar PostgreSQL, MySQL o un archivo fuente CSV como alternativa.
- Activador de actualización, seleccione On-Demand .
Las actualizaciones serán bajo demanda porque la búsqueda es principalmente para fines de referencia durante la consulta y cualquier actualización de los datos de búsqueda se puede actualizar en ADA mediante activadores bajo demanda.
- Elige Siguiente.
ADA lee el esquema del esquema subyacente de DynamoDB y presenta el nombre y el tipo de columna para una transformación opcional. Continuaremos con la selección del esquema predeterminado porque los tipos de columnas son consistentes con los tipos del grupo de registros de CloudWatch y la fuente de datos CSV de Amazon S3. Tener tipos de datos que sean consistentes en todas las fuentes de datos nos permite escribir consultas para recuperar registros uniendo las tablas usando los campos de columna. Por ejemplo, la columna key en el esquema de DynamoDB corresponde a la status_code en los productos de datos de Amazon S3 y CloudWatch. Podemos escribir consultas que puedan unir las tres tablas usando el nombre de la columna. key. En la siguiente sección se muestra un ejemplo.
- Elige Continuar con el esquema actual.
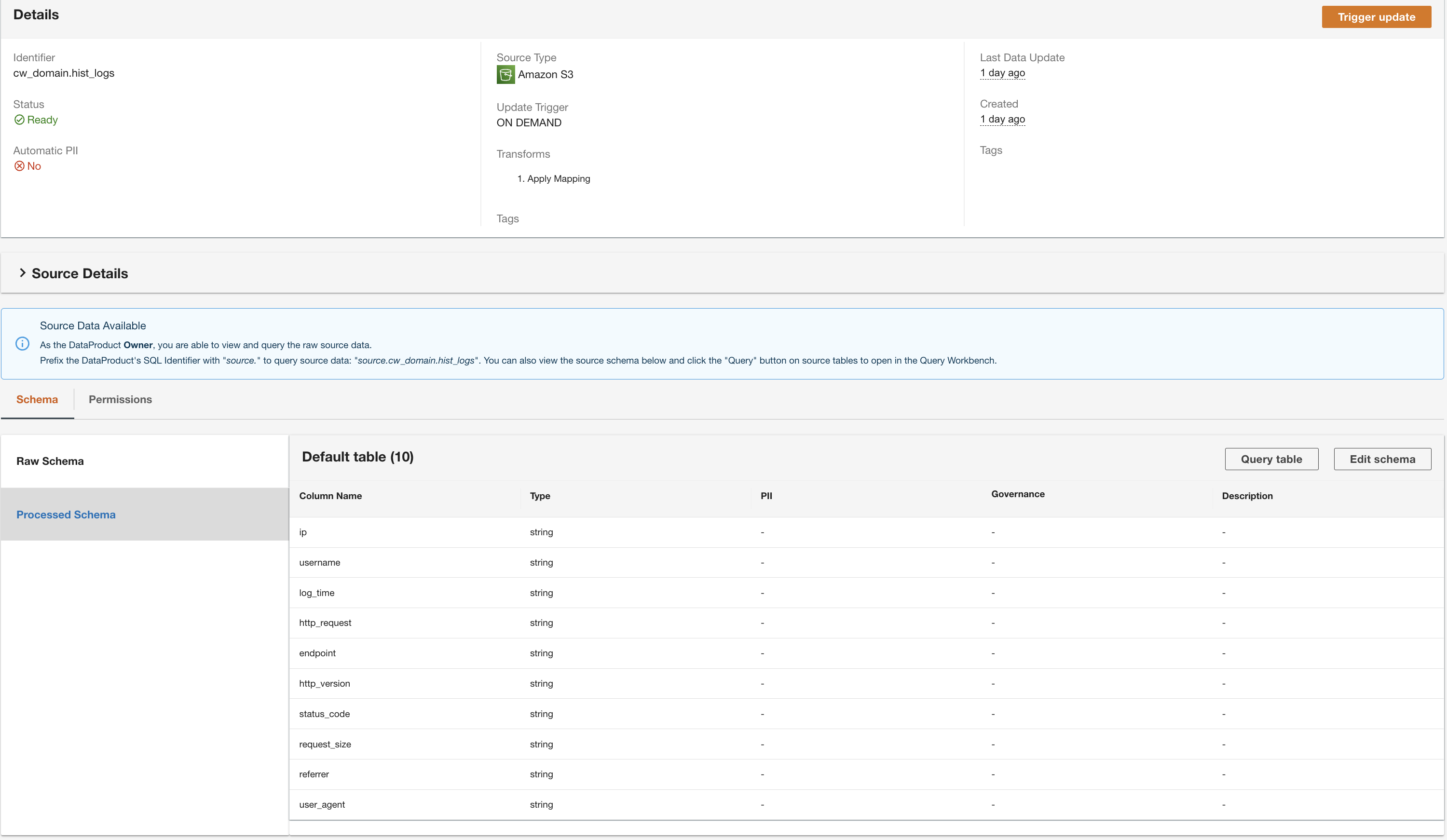
- Revisa la configuración y elige Enviar.
ADA procesará los datos de la fuente de datos de la tabla de DynamoDB y preparará el producto de datos. Dependiendo del tamaño de los datos, este proceso lleva unos minutos.
Ahora tenemos los tres productos de datos procesados por ADA y disponibles para que usted pueda realizar consultas.

Utilice Query Workbench para consultar los datos
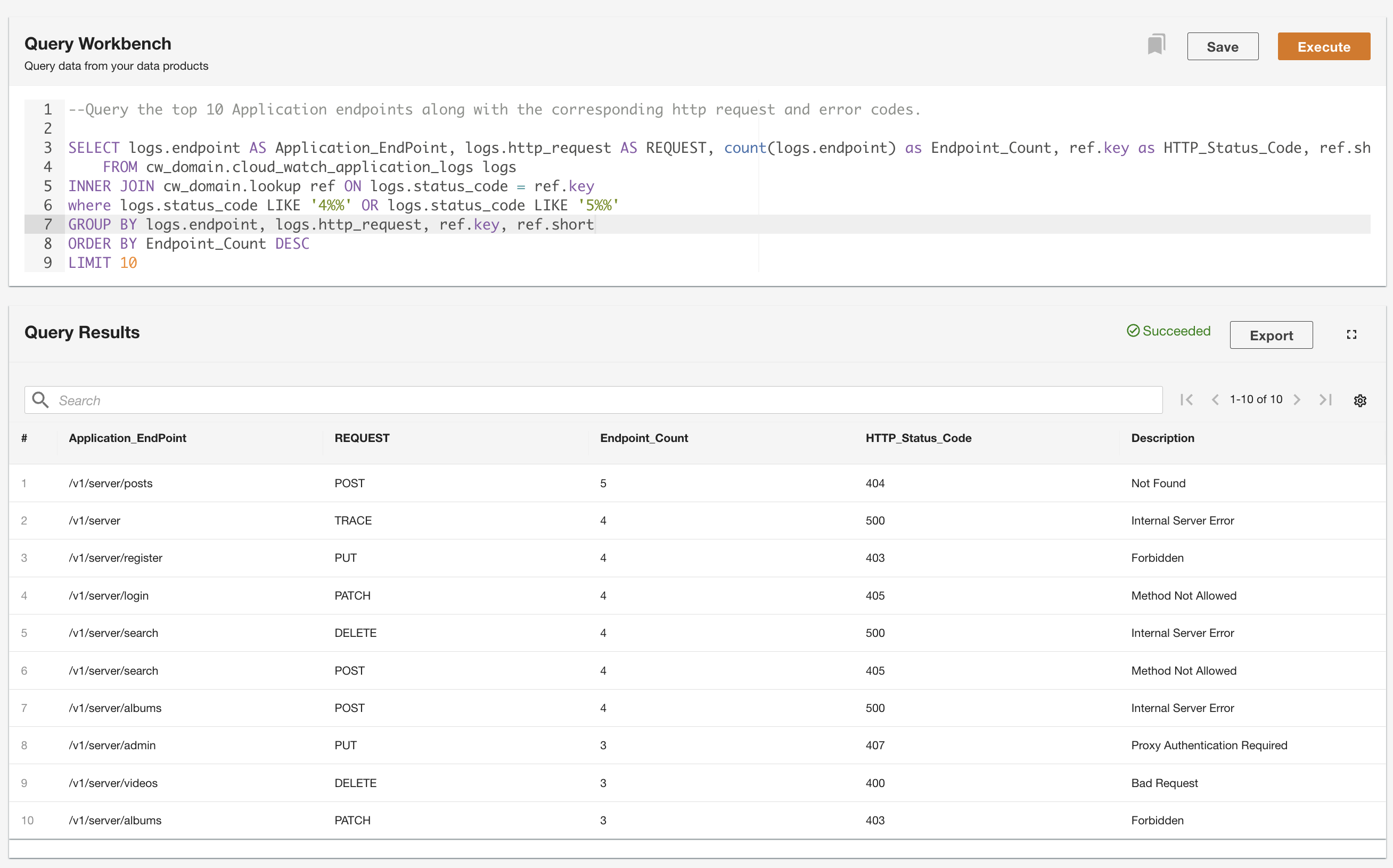
ADA le permite ejecutar consultas sobre los productos de datos mientras abstrae la fuente de datos y la hace accesible mediante SQL (lenguaje de consulta estructurado). Puede escribir consultas y unir las tablas tal como lo haría con tablas en una base de datos relacional. Demostramos la capacidad de consulta de ADA a través de dos escenarios de usuario. En ambos escenarios, unimos un conjunto de datos de registro de aplicación a la tabla de búsqueda de códigos de error. En el primer caso de uso, consultamos los registros de la aplicación actual para identificar los 10 puntos finales de la aplicación más accedidos junto con los códigos de estado HTTP correspondientes:
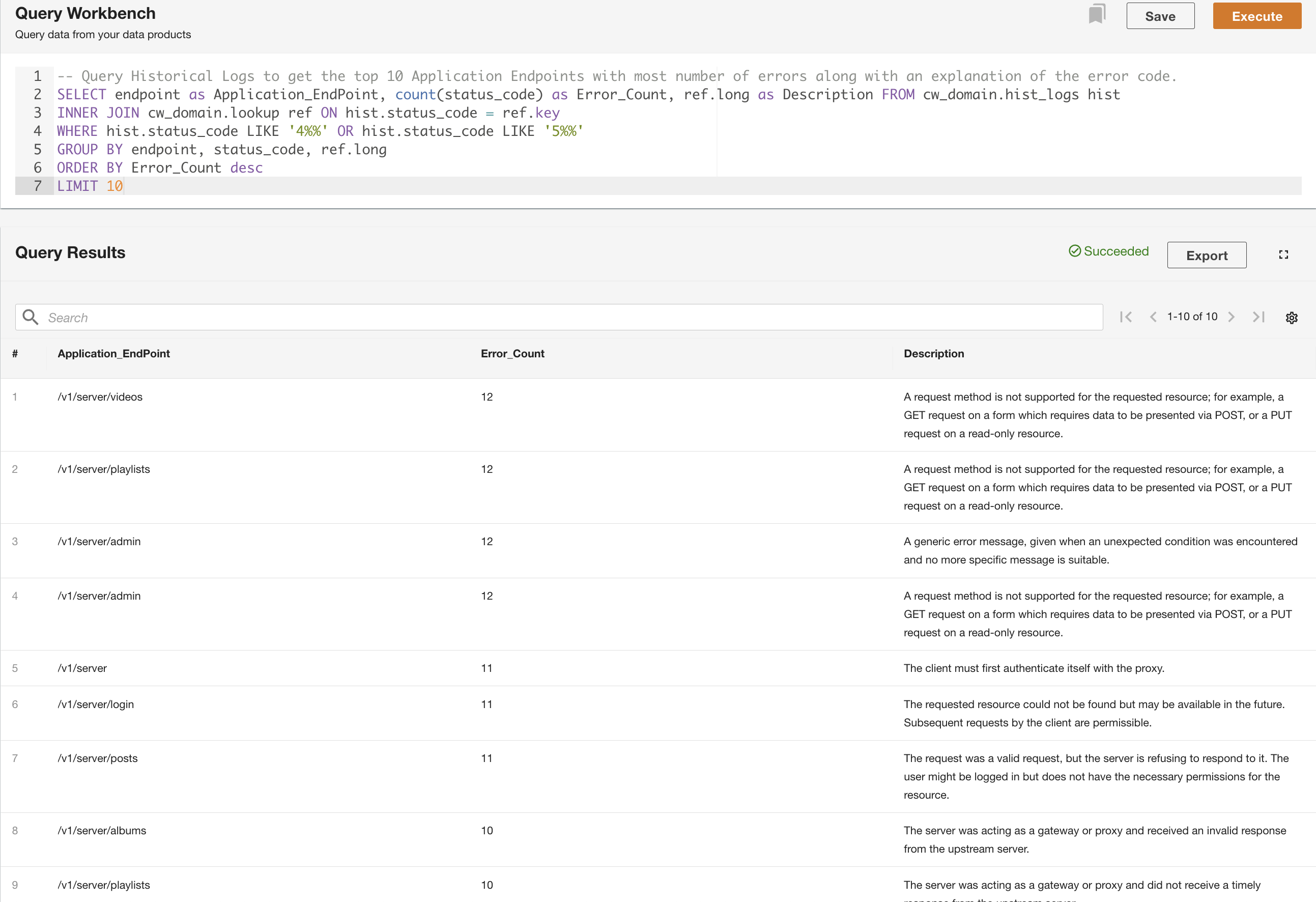
En el segundo ejemplo, consultamos la tabla de registros históricos para obtener los 10 puntos finales de aplicaciones principales con la mayor cantidad de errores para comprender el patrón de llamada del punto final:
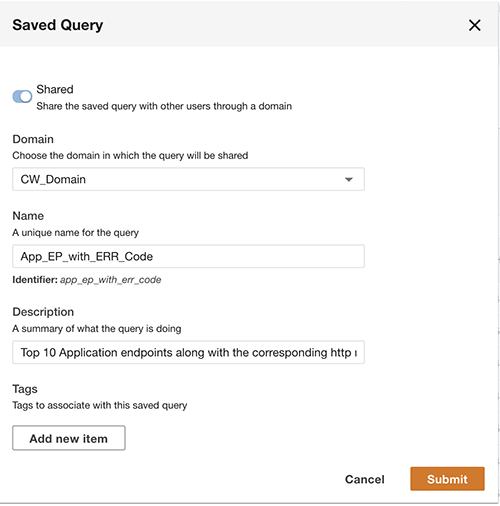
Además de realizar consultas, opcionalmente puede guardar la consulta y compartirla con otros usuarios del mismo dominio. Se puede acceder a las consultas compartidas directamente desde Query Workbench. Los resultados de la consulta también se pueden exportar a formato CSV.
Visualice productos de datos ADA en Tableau
ADA ofrece la posibilidad de conectamos a herramientas de BI de terceros para visualizar datos y crear informes a partir de los productos de datos de ADA. En esta demostración, utilizamos la integración nativa de ADA con Tableau para visualizar los datos de los tres productos de datos que configuramos anteriormente. Usando el conector Athena de Tableau y siguiendo los pasos en Configuración del cuadro, puede configurar ADA como fuente de datos en Tableau. Una vez que se haya establecido una conexión exitosa entre Tableau y ADA, Tableau completará los tres productos de datos en el catálogo de Tableau. cw_domain.
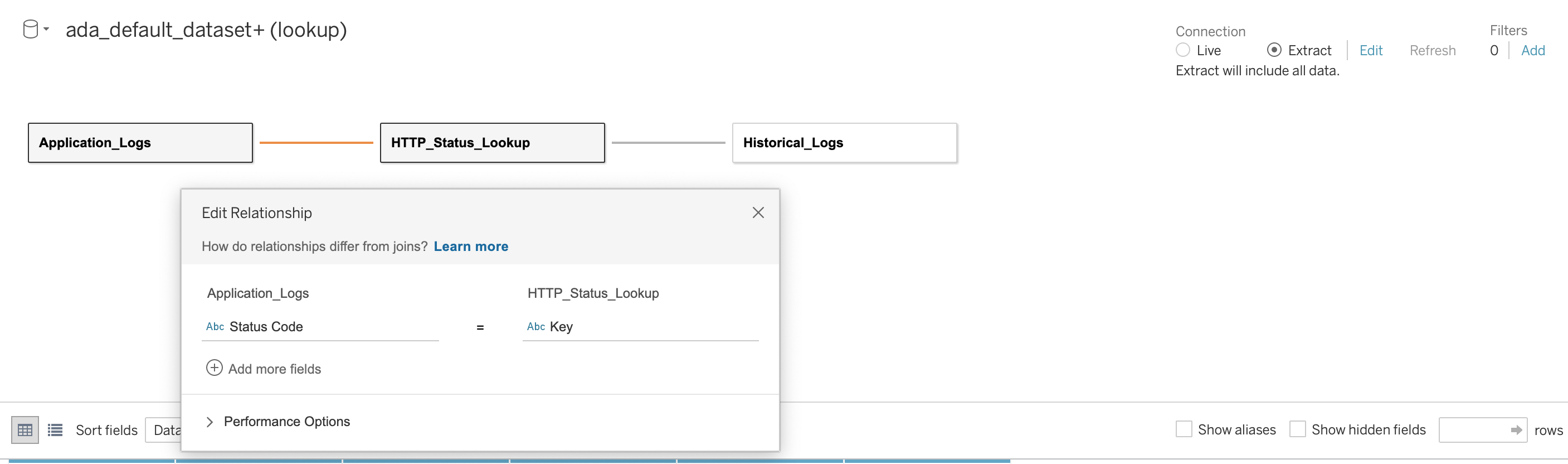
Luego establecemos una relación entre las tres bases de datos utilizando el código de estado HTTP como columna de unión, como se muestra en la siguiente captura de pantalla. Tableau nos permite trabajar en modo online y offline con las fuentes de datos. En el modo en línea, Tableau se conectará a ADA y consultará los productos de datos en vivo. En modo offline podemos utilizar el Extraer opción para extraer los datos de ADA e importarlos a Tableau. En esta demostración, importamos los datos a Tableau para que las consultas respondan mejor. Luego guardamos el libro de trabajo de Tableau. Podemos inspeccionar los datos de las fuentes de datos eligiendo la base de datos y Actualizar Ahora.
Con las configuraciones de fuente de datos implementadas en Tableau, podemos crear informes, gráficos y visualizaciones personalizados en los productos de datos de ADA. Consideremos dos casos de uso para visualizaciones.
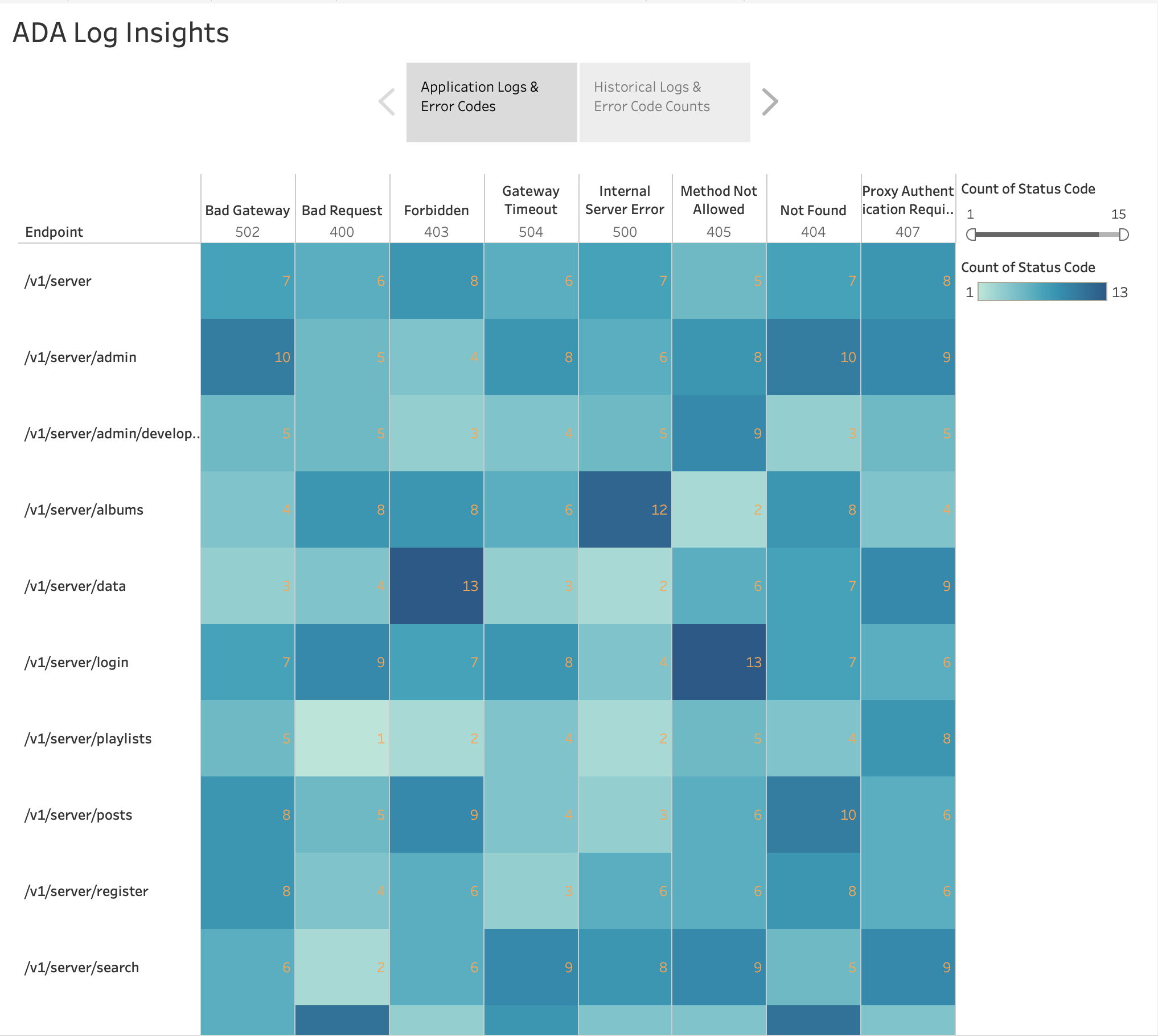
Como se muestra en la siguiente figura, visualizamos la frecuencia de los errores HTTP por puntos finales de la aplicación utilizando la herramienta integrada de Tableau. mapa de calor cuadro. Filtramos los códigos de estado HTTP para incluir solo códigos de error en el rango 4xx y 5xx.
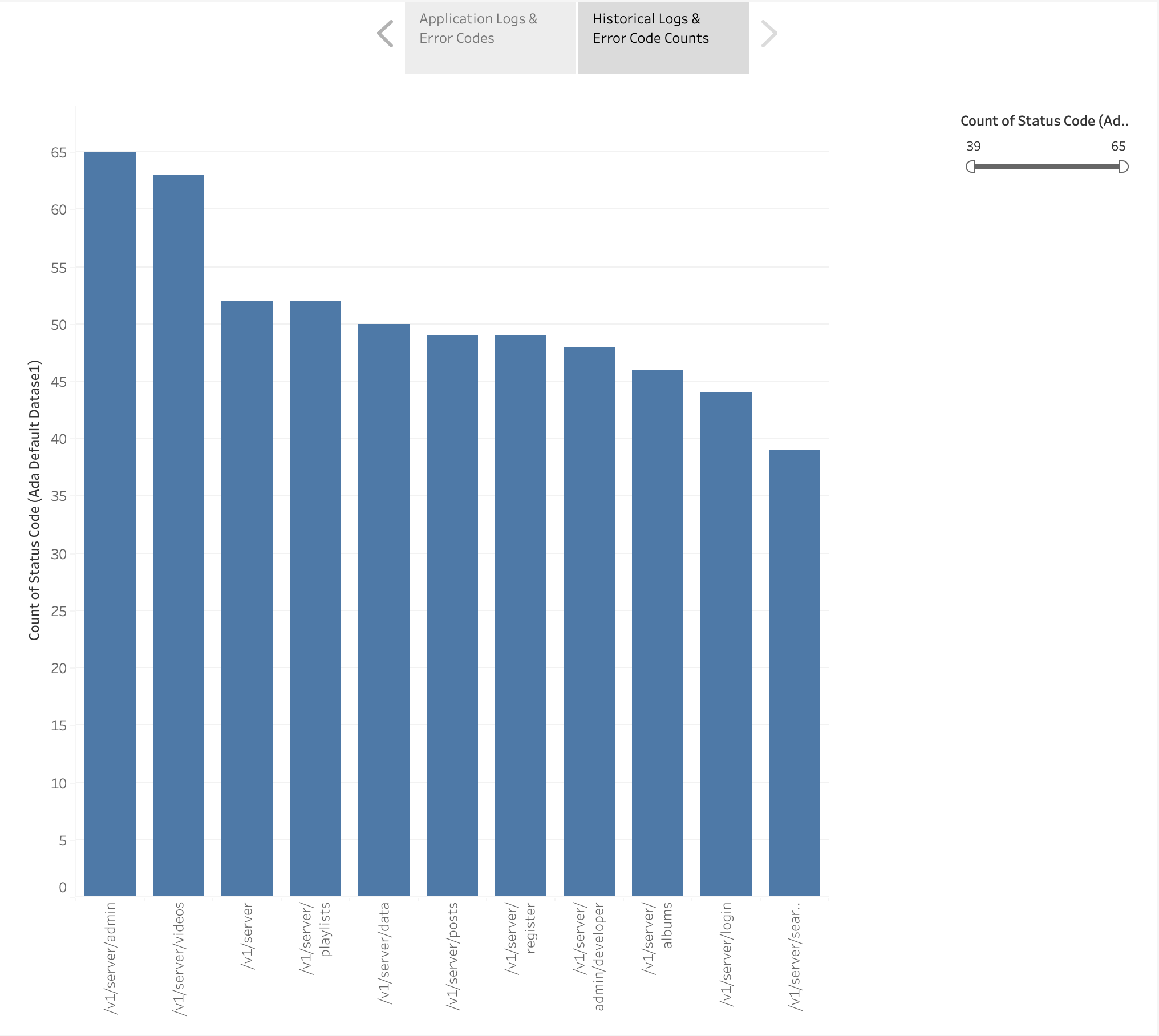
También creamos un gráfico de barras para representar los puntos finales de la aplicación a partir de los registros históricos ordenados por el recuento de códigos de error HTTP. En este gráfico podemos ver que el /v1/server/admin El punto final ha generado la mayor cantidad de códigos de estado de error HTTP.
Limpiar
La limpieza de la infraestructura de la aplicación de muestra es un proceso de dos pasos. Primero, para eliminar la infraestructura proporcionada para los fines de esta demostración, ejecute el siguiente comando en la terminal:
Para la siguiente pregunta, ingrese y y AWS CDK eliminará los recursos implementados para la demostración:
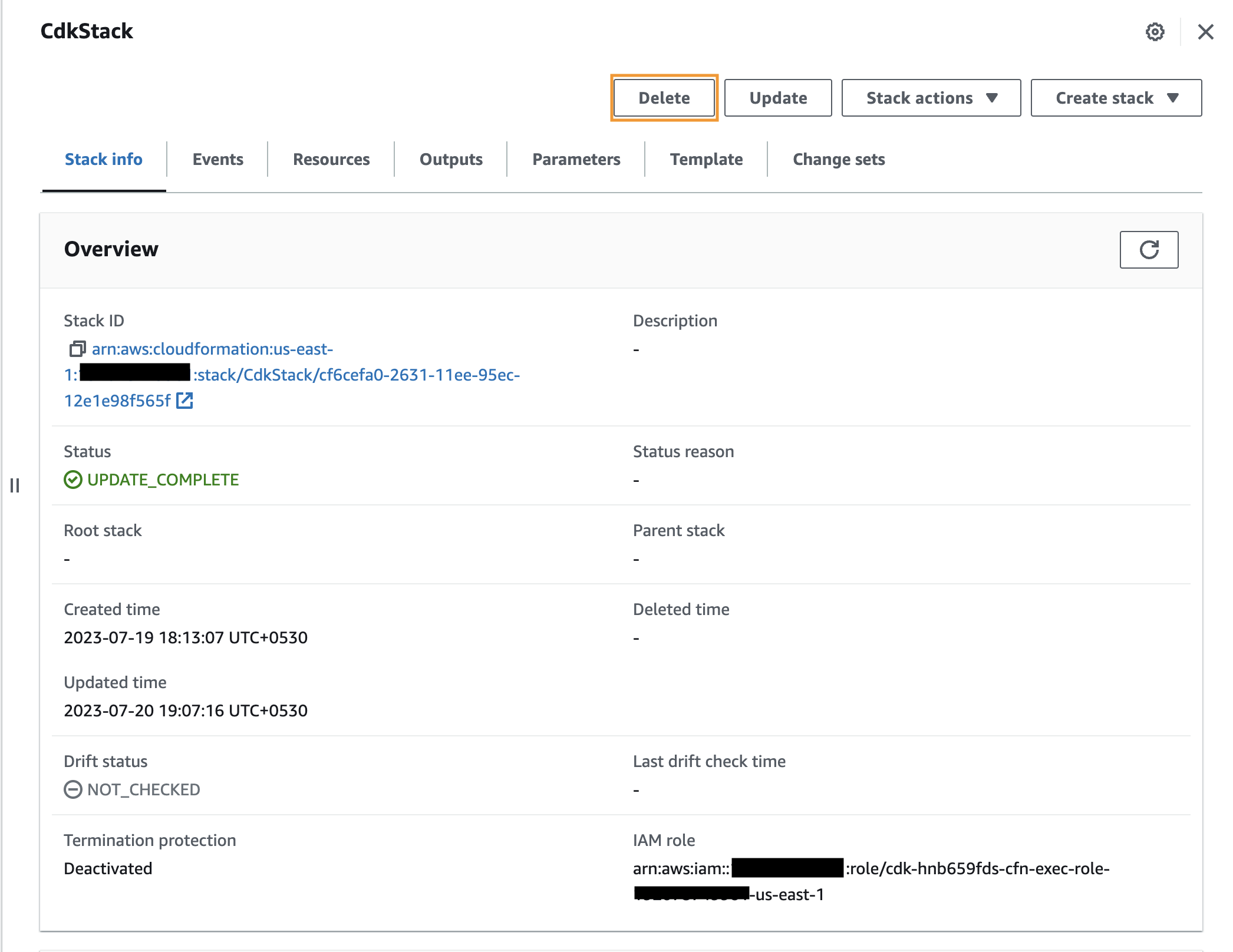
Alternativamente, puede eliminar los recursos a través de la consola de AWS CloudFormation navegando a la pila de CdkStack y eligiendo Borrar.
El segundo paso es desinstalar ADA. Para obtener instrucciones, consulte Desinstalar la solución.
Conclusión
En esta publicación, demostramos cómo utilizar la solución ADA para obtener información de los registros de aplicaciones almacenados en dos fuentes de datos diferentes. Demostramos cómo instalar ADA en una cuenta de AWS e implementar los componentes de demostración utilizando AWS CDK. Creamos productos de datos en ADA y configuramos los productos de datos con las respectivas fuentes de datos utilizando los conectores de datos integrados de ADA. Demostramos cómo consultar los productos de datos utilizando consultas SQL estándar y generar información sobre los datos de registro. También conectamos el cliente Tableau Desktop, un producto de BI de terceros, a ADA y demostramos cómo crear visualizaciones con los productos de datos.
ADA automatiza el proceso de ingesta, transformación, gobierno y consulta de diversos conjuntos de datos y simplifica la gestión del ciclo de vida de los datos. Los conectores prediseñados de ADA le permiten ingerir datos de diversas fuentes de datos. Los equipos de software con conocimientos básicos de los productos y servicios de AWS podrán configurar una plataforma operativa de análisis de datos en unas pocas horas y proporcionar acceso seguro a los datos. Luego, los datos se pueden consultar fácil y rápidamente mediante una interfaz de usuario web intuitiva e independiente.
Pruebe ADA hoy para administrar y obtener información valiosa a partir de los datos fácilmente.
Sobre los autores
 Aparajithan Vaidyanathan es Arquitecto Principal de Soluciones Empresariales en AWS. Ayuda a los clientes empresariales a migrar y modernizar sus cargas de trabajo en la nube de AWS. Es un arquitecto de la nube con más de 23 años de experiencia en el diseño y desarrollo de sistemas de software empresariales, a gran escala y distribuidos. Se especializa en aprendizaje automático y análisis de datos con enfoque en el dominio de ingeniería de características y datos. Es un aspirante a corredor de maratón y sus pasatiempos incluyen el senderismo, andar en bicicleta y pasar tiempo con su esposa y sus dos hijos.
Aparajithan Vaidyanathan es Arquitecto Principal de Soluciones Empresariales en AWS. Ayuda a los clientes empresariales a migrar y modernizar sus cargas de trabajo en la nube de AWS. Es un arquitecto de la nube con más de 23 años de experiencia en el diseño y desarrollo de sistemas de software empresariales, a gran escala y distribuidos. Se especializa en aprendizaje automático y análisis de datos con enfoque en el dominio de ingeniería de características y datos. Es un aspirante a corredor de maratón y sus pasatiempos incluyen el senderismo, andar en bicicleta y pasar tiempo con su esposa y sus dos hijos.
 Rahim Rahman es un desarrollador de software con sede en Sydney, Australia, con más de 10 años de experiencia en desarrollo y arquitectura de software. Trabaja principalmente en la creación de soluciones AWS de código abierto a gran escala para casos de uso y problemas comerciales comunes de los clientes. En su tiempo libre le gustan los deportes y pasar tiempo con amigos y familiares.
Rahim Rahman es un desarrollador de software con sede en Sydney, Australia, con más de 10 años de experiencia en desarrollo y arquitectura de software. Trabaja principalmente en la creación de soluciones AWS de código abierto a gran escala para casos de uso y problemas comerciales comunes de los clientes. En su tiempo libre le gustan los deportes y pasar tiempo con amigos y familiares.
 Hafiz Saadullah es director técnico principal de productos en Amazon Web Services. Hafiz se centra en las soluciones de AWS, diseñadas para ayudar a los clientes a abordar problemas comerciales y casos de uso comunes.
Hafiz Saadullah es director técnico principal de productos en Amazon Web Services. Hafiz se centra en las soluciones de AWS, diseñadas para ayudar a los clientes a abordar problemas comerciales y casos de uso comunes.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :posee
- :es
- :no
- :dónde
- $ UP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- capacidad
- Poder
- Nuestra Empresa
- de la máquina
- visitada
- accesible
- Mi Cuenta
- a través de
- acciones
- ADA
- add
- adición
- Adicionales
- direccionamiento
- Admin
- Después
- en contra
- Todos
- permitir
- permite
- a lo largo de
- también
- alternativa
- Amazon
- Amazon Web Services
- entre
- an
- análisis
- Analistas
- Analytics
- analizar
- y
- Otra
- cualquier
- APACHE
- abejas
- API
- Aplicación
- aplicaciones
- aplicada
- Aplicá
- La aplicación de
- arquitectura
- somos
- AS
- aspirantes
- At
- atributos
- Australia
- Autenticación
- autorizado
- Confirmación de Viaje
- automatiza
- automáticamente
- Hoy Disponibles
- AWS
- Formación en la nube de AWS
- Atrás
- Backend
- de caramelos
- basado
- básica
- BE
- porque
- esto
- antes
- a medida
- entre
- ambas
- Box
- build
- Construir la
- incorporado
- inteligencia empresarial
- pero
- by
- llamar al
- PUEDEN
- capacidad
- case
- cases
- catalogar
- CD
- el cambio
- Tabla
- Gráficas
- Elige
- la elección de
- cliente
- Soluciones
- código
- los códigos de
- --
- Columna
- Columnas
- Algunos
- completar
- componentes
- Configuración
- configurado
- Contacto
- conectado
- conexión
- conecta
- Considerar
- consistente
- Consola
- contiene
- continue
- correlacionado
- La correlación
- Correspondiente
- corresponde
- Cost
- Para crear
- creado
- crea
- Creamos
- Referencias
- Current
- personalizado
- cliente
- Clientes
- página de información de sus operaciones
- datos
- Data Analytics
- proceso de datos
- Base de datos
- bases de datos
- conjuntos de datos
- Predeterminado
- Demanda
- De demostración
- demostrar
- demostrado
- Dependiente
- desplegar
- desplegado
- despliegue
- despliega
- descripción
- diseñado
- diseño
- computadora de escritorio
- detallado
- detalles
- Developer
- el desarrollo
- Desarrollo
- diagnóstico
- una experiencia diferente
- directamente
- discapacitados
- descubrimiento
- Pantalla
- distribuidos
- diverso
- No
- dominio
- dominios
- No
- caído
- durante
- cada una
- Más temprano
- pasan fácilmente
- .
- ya sea
- facilita
- permite
- Punto final
- criterios de valoración
- Ingeniería
- garantizar
- Participar
- Empresa
- clientes empresariales
- Soluciones Empresariales
- error
- Errores
- establecer
- se establece
- Éter (ETH)
- ejemplo
- existente
- experience
- Explicar
- explicación
- extraerlos
- extraer los datos
- familiar
- familia
- Feature
- pocos
- campo
- Terrenos
- Figura
- Archive
- archivos
- final
- financiar
- Nombre
- flexible
- Focus
- se centra
- siguiendo
- formato
- Digital XNUMXk
- Frecuencia
- amigos
- Desde
- función
- Obtén
- generar
- generado
- obtener
- conseguir
- gobernante
- Grupo procesos
- Grupo
- Tienen
- es
- he
- ayuda
- Destacado
- excursionismo
- su
- histórico
- Pasatiempos
- organizado
- HORAS
- Cómo
- Como Hacer
- Sin embargo
- HTML
- http
- HTTPS
- AMI
- idéntico
- Identifique
- Identidad
- if
- importar
- in
- incluir
- incluye
- Incluye
- información
- EN LA MINA
- inicial
- Insights
- instalar
- instalación
- Instrucciones
- COMPLETAMENTE
- integración
- Intelligence
- interactivo
- interesado
- Interfaz
- dentro
- intuitivo
- invoca
- involucra
- IT
- únete
- unión
- Une
- jpg
- json
- solo
- Guardar
- Clave
- especialistas
- idioma
- large
- Gran escala
- Apellido
- luego
- lanzamiento
- aprendizaje
- Biblioteca
- Con licencia
- ciclo de vida
- como
- LIMITE LAS
- línea
- Lista
- para vivir
- log
- registro
- Largo
- Mira
- búsqueda
- máquina
- máquina de aprendizaje
- para lograr
- Realizar
- gestionan
- Management
- gerente
- muchos
- mapa
- cartografía
- Maratón
- Marketing
- Materia
- significativo
- mensaje
- MFA
- podría
- migrado
- minutos
- Moda
- modernizar
- más,
- MEJOR DE TU
- cuales son las que reflejan
- Mozilla
- autenticación de múltiples factores
- MySQL
- nombre
- Llamado
- nombres
- nativo
- Navegar
- navegando
- Navegación
- ¿ Necesita ayuda
- Nuevo
- recién
- Next
- número
- of
- Ofertas
- digital fuera de línea.
- Viejo
- on
- On-Demand
- ONE
- en línea
- , solamente
- habiertos
- de código abierto
- operativos.
- Optión
- or
- solicite
- Otro
- Otros
- salir
- salida
- visión de conjunto
- página
- cristal
- Contraseña
- camino
- Patrón de Costura
- realizar
- permisos
- Personalmente
- teléfono
- pii
- industrial
- Colocar
- Natural
- plan
- plataforma
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- políticas
- Portal
- Publicación
- Postgresql
- alimentado
- Preparar
- Prepara
- requisitos previos
- presente
- regalos
- Vista previa
- anterior
- las cuales
- Director de la escuela
- Anterior
- problemas
- proceder
- procesado
- en costes
- tratamiento
- producido
- Producto
- gerente de producto
- Productos
- Productos y Servicios
- Programas
- proyecto
- proporcionar
- previsto
- proveedor
- proporciona un
- propósito
- fines
- Python
- consultas
- pregunta
- con rapidez
- distancia
- Leer
- ready
- recepción
- archivos
- referido
- región
- relación
- remove
- repetir
- Informes
- solicita
- Requisitos
- Recursos
- aquellos
- sensible
- Resultados
- conservar
- una estrategia SEO para aparecer en las búsquedas de Google.
- equitación
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- raíz
- Regla
- Ejecutar
- corredor
- correr
- ventas
- mismo
- Guardar
- Escala
- escenarios
- programada
- alcance
- Buscar
- Segundo
- Sección
- seguro
- EN LINEA
- ver
- seleccionado
- selección
- envío
- expedido
- separado
- ayudar
- Sin servidor
- de coches
- Servicios
- set
- pólipo
- Compartir
- compartido
- En Corto
- mostrado
- Shows
- sencillos
- simplificado
- simplificando
- Tamaño
- habilidades
- So
- Software
- Desarrollo de software ad-hoc
- a medida
- Soluciones
- Fuente
- Fuentes
- especialista
- se especializa
- soluciones y
- especificado
- Gastos
- Deportes
- SQL
- montón
- independiente
- estándar
- comienzo
- comienza
- Estado
- paso
- pasos
- STORAGE
- almacenados
- Cordón
- estructurado
- exitosos
- Con éxito
- tal
- soportes
- seguro
- Sydney
- Todas las funciones a su disposición
- mesa
- Cuadro
- ¡Prepárate!
- toma
- equipo
- equipos
- Técnico
- habilidades técnicas
- terminal
- esa
- La
- La Fuente
- su
- luego
- Ahí.
- Estas
- terceros.
- así
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- a
- hoy
- parte superior
- Top 10
- Total
- Transformar
- transformaciones
- transformado
- transformadora
- transformadas
- desencadenados
- dos
- tipo
- tipos
- bajo
- subyacente
- entender
- actualizado
- Actualizaciones
- a
- URI
- us
- utilizan el
- caso de uso
- usado
- Usuario
- Interfaz de usuario
- usuarios
- usando
- Valores
- variable
- variedad
- versión
- vía
- Ver
- quieres
- Camino..
- we
- web
- servicios web
- WELL
- cuando
- que
- mientras
- amplio
- Amplia gama
- esposa
- seguirá
- dentro de
- sin
- Actividades:
- flujo de trabajo
- funciona
- se
- escribir
- años
- Usted
- tú
- zephyrnet