Esta es una publicación conjunta coescrita por AWS y Voxel51. Voxel51 es la empresa detrás de FiftyOne, el conjunto de herramientas de código abierto para crear conjuntos de datos y modelos de visión artificial de alta calidad.
Una empresa minorista está creando una aplicación móvil para ayudar a los clientes a comprar ropa. Para crear esta aplicación, necesitan un conjunto de datos de alta calidad que contenga imágenes de ropa, etiquetadas con diferentes categorías. En esta publicación, mostramos cómo reutilizar un conjunto de datos existente a través de la limpieza, el preprocesamiento y el preetiquetado de datos con un modelo de clasificación de disparo cero en Cincuenta y uno, y ajustando estas etiquetas con Verdad fundamental de Amazon SageMaker.
Puede usar Ground Truth y FiftyOne para acelerar su proyecto de etiquetado de datos. Ilustramos cómo utilizar sin problemas las dos aplicaciones juntas para crear conjuntos de datos etiquetados de alta calidad. Para nuestro caso de uso de ejemplo, trabajamos con el Conjunto de datos Fashion200K, lanzado en ICCV 2017.
Resumen de la solución
Ground Truth es un servicio de etiquetado de datos totalmente autónomo y administrado que permite a los científicos de datos, ingenieros de aprendizaje automático (ML) e investigadores crear conjuntos de datos de alta calidad. Cincuenta y uno by Voxel51 es un conjunto de herramientas de código abierto para seleccionar, visualizar y evaluar conjuntos de datos de visión artificial para que pueda entrenar y analizar mejores modelos al acelerar sus casos de uso.
En las siguientes secciones, demostramos cómo hacer lo siguiente:
- Visualice el conjunto de datos en FiftyOne
- Limpie el conjunto de datos con filtrado y deduplicación de imágenes en FiftyOne
- Etiquete previamente los datos limpios con clasificación de disparo cero en FiftyOne
- Etiquete el conjunto de datos seleccionado más pequeño con Ground Truth
- Inyecte resultados etiquetados de Ground Truth en FiftyOne y revise los resultados etiquetados en FiftyOne
Resumen del caso de uso
Suponga que es propietario de una empresa minorista y desea crear una aplicación móvil para brindar recomendaciones personalizadas para ayudar a los usuarios a decidir qué ponerse. Sus posibles usuarios están buscando una aplicación que les diga qué prendas de vestir en su armario combinan bien. Ves una oportunidad aquí: si puedes identificar buenos atuendos, puedes usarlo para recomendar nuevos artículos de ropa que complementen la ropa que un cliente ya posee.
Quiere hacer las cosas lo más fáciles posible para el usuario final. Idealmente, alguien que usa su aplicación solo necesita tomar fotografías de la ropa en su guardarropa, y sus modelos ML hacen su magia detrás de escena. Puede entrenar un modelo de propósito general o ajustar un modelo al estilo único de cada usuario con algún tipo de retroalimentación.
Sin embargo, primero debe identificar qué tipo de ropa está capturando el usuario. ¿Es una camisa? ¿Un par de pantalones? ¿O algo mas? Después de todo, probablemente no quieras recomendar un conjunto que tenga varios vestidos o varios sombreros.
Para abordar este desafío inicial, desea generar un conjunto de datos de entrenamiento que consta de imágenes de varias prendas de vestir con varios patrones y estilos. Para crear un prototipo con un presupuesto limitado, desea arrancar utilizando un conjunto de datos existente.
Para ilustrar y guiarlo a través del proceso en esta publicación, usamos el conjunto de datos Fashion200K publicado en ICCV 2017. Es un conjunto de datos establecido y bien citado, pero no es directamente adecuado para su caso de uso.
Aunque las prendas de vestir están etiquetadas con categorías (y subcategorías) y contienen una variedad de etiquetas útiles que se extraen de las descripciones originales del producto, los datos no están etiquetados sistemáticamente con información sobre patrones o estilos. Su objetivo es convertir este conjunto de datos existente en un conjunto de datos de entrenamiento sólido para sus modelos de clasificación de ropa. Debe limpiar los datos, aumentando el esquema de etiquetado con etiquetas de estilo. Y desea hacerlo rápidamente y con el menor gasto posible.
Descargar los datos localmente
Primero, descargue el archivo zip women.tar y la carpeta de etiquetas (con todas sus subcarpetas) siguiendo las instrucciones provistas en el Repositorio GitHub del conjunto de datos Fashion200K. Después de descomprimir ambos, cree un directorio principal fashion200k y mueva las carpetas de etiquetas y mujeres a este. Afortunadamente, estas imágenes ya se han recortado a los cuadros delimitadores de detección de objetos, por lo que podemos centrarnos en la clasificación, en lugar de preocuparnos por la detección de objetos.
A pesar del "200K" en su apodo, el directorio de mujeres que extrajimos contiene 338,339 imágenes. Para generar el conjunto de datos oficial de Fashion200K, los autores del conjunto de datos rastrearon más de 300,000 XNUMX productos en línea, y solo los productos con descripciones que contenían más de cuatro palabras pasaron el corte. Para nuestros propósitos, donde la descripción del producto no es esencial, podemos usar todas las imágenes rastreadas.
Veamos cómo se organizan estos datos: dentro de la carpeta de mujeres, las imágenes se organizan por tipo de artículo de nivel superior (faldas, tops, pantalones, chaquetas y vestidos) y subcategoría de tipo de artículo (blusas, camisetas, vestidos de manga larga). tapas).
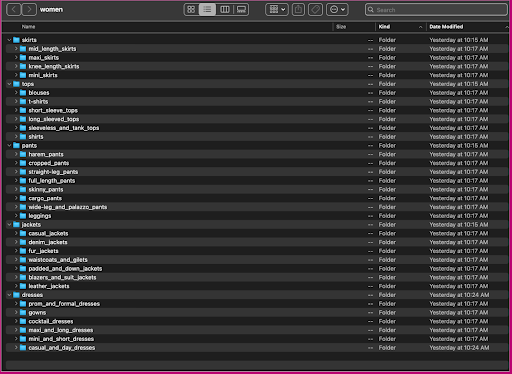
Dentro de los directorios de subcategorías, hay un subdirectorio para cada lista de productos. Cada uno de ellos contiene un número variable de imágenes. La subcategoría cropped_pants, por ejemplo, contiene las siguientes listas de productos e imágenes asociadas.
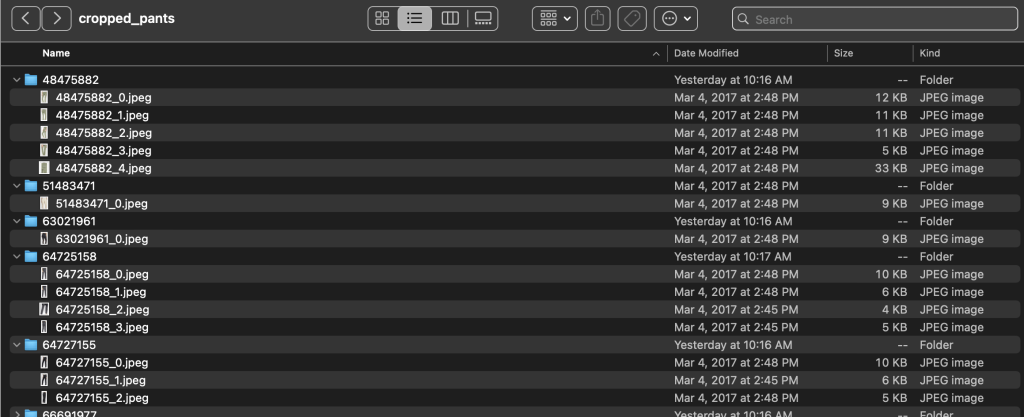
La carpeta de etiquetas contiene un archivo de texto para cada tipo de artículo de nivel superior, tanto para las divisiones de entrenamiento como para las de prueba. Dentro de cada uno de estos archivos de texto hay una línea separada para cada imagen, que especifica la ruta de archivo relativa, una puntuación y etiquetas de la descripción del producto.
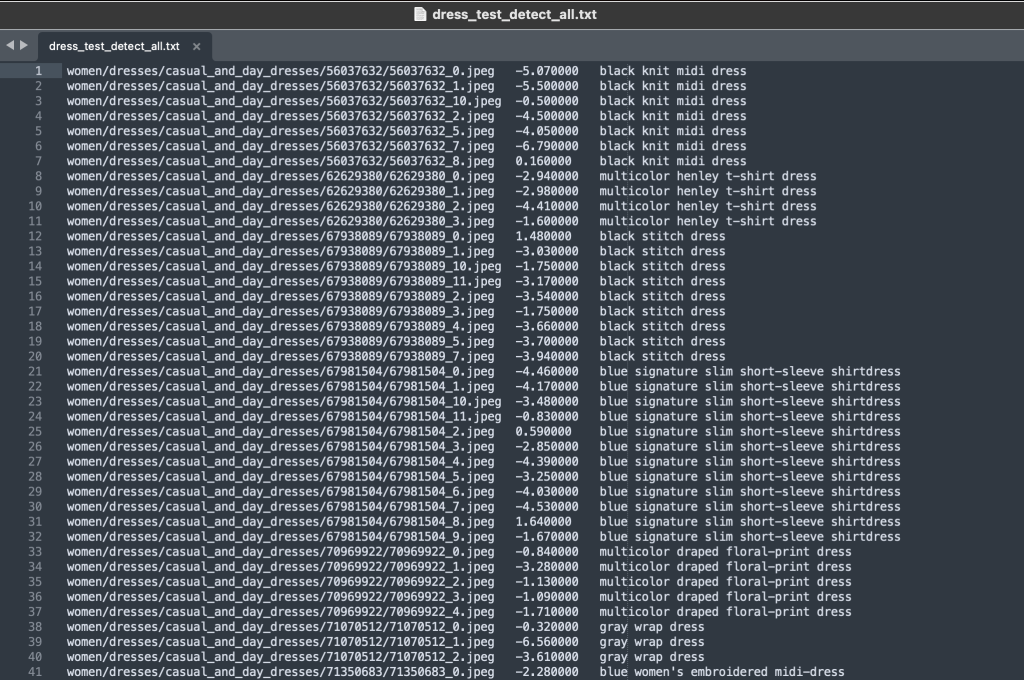
Debido a que estamos reutilizando el conjunto de datos, combinamos todas las imágenes del tren y de prueba. Los usamos para generar un conjunto de datos específico de la aplicación de alta calidad. Después de completar este proceso, podemos dividir aleatoriamente el conjunto de datos resultante en nuevas divisiones de tren y prueba.
Inyectar, ver y seleccionar un conjunto de datos en FiftyOne
Si aún no lo ha hecho, instale FiftyOne de código abierto usando pip:
Una mejor práctica es hacerlo dentro de un nuevo entorno virtual (venv o conda). Luego importe los módulos relevantes. Importe la biblioteca base, FiftyOne, FiftyOne Brain, que tiene métodos ML incorporados, FiftyOne Zoo, desde el cual cargaremos un modelo que generará etiquetas de disparo cero para nosotros, y ViewField, que nos permite filtrar de manera eficiente el datos en nuestro conjunto de datos:
También desea importar los módulos glob y os de Python, que nos ayudarán a trabajar con rutas y coincidencias de patrones sobre el contenido del directorio:
Ahora estamos listos para cargar el conjunto de datos en FiftyOne. Primero, creamos un conjunto de datos llamado fashion200k y lo hacemos persistente, lo que nos permite guardar los resultados de operaciones computacionalmente intensivas, por lo que solo necesitamos calcular dichas cantidades una vez.
Ahora podemos iterar a través de todos los directorios de subcategorías, agregando todas las imágenes dentro de los directorios de productos. Agregamos una etiqueta de clasificación FiftyOne a cada muestra con el nombre de campo tipo_de_artículo, completado por la categoría de artículo de nivel superior de la imagen. También agregamos información de categoría y subcategoría como etiquetas:
En este punto, podemos visualizar nuestro conjunto de datos en la aplicación FiftyOne iniciando una sesión:
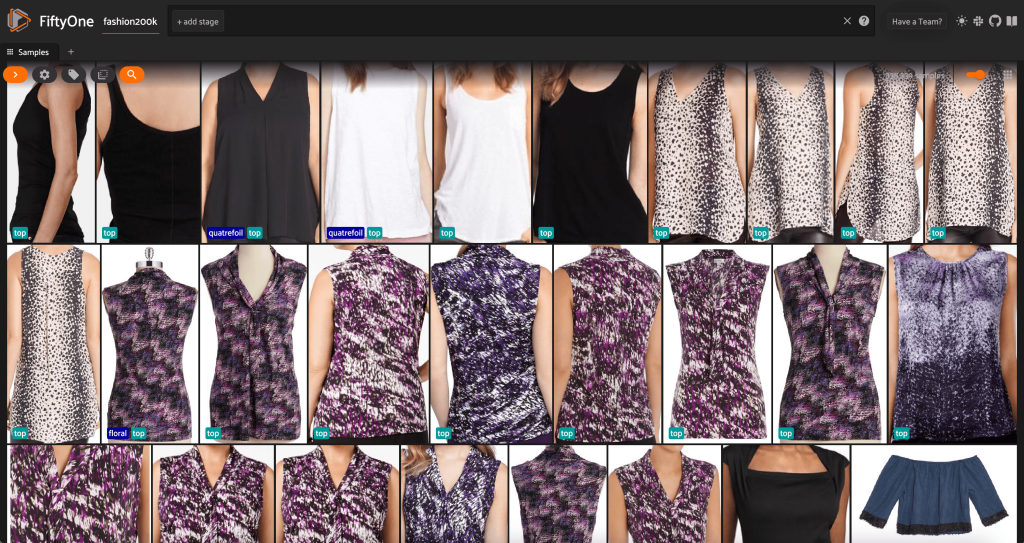
También podemos imprimir un resumen del conjunto de datos en Python ejecutando print(dataset):
También podemos añadir las etiquetas de la labels directorio a las muestras en nuestro conjunto de datos:
Mirando los datos, algunas cosas quedan claras:
- Algunas de las imágenes son bastante granulosas, con baja resolución. Es probable que esto se deba a que estas imágenes se generaron recortando imágenes iniciales en cuadros delimitadores de detección de objetos.
- Algunas prendas son usadas por una persona y otras son fotografiadas solas. Estos detalles están encapsulados por el
viewpointpropiedad. - Muchas de las imágenes del mismo producto son muy similares, por lo que al menos inicialmente, incluir más de una imagen por producto puede no agregar mucho poder predictivo. En su mayor parte, la primera imagen de cada producto (que termina en
_0.jpeg) es el más limpio.
Inicialmente, podríamos querer entrenar nuestro modelo de clasificación de estilo de ropa en un subconjunto controlado de estas imágenes. Con este fin, utilizamos imágenes de alta resolución de nuestros productos y limitamos nuestra visualización a una muestra representativa por producto.
Primero, filtramos las imágenes de baja resolución. usamos el compute_metadata() método para calcular y almacenar el ancho y alto de la imagen, en píxeles, para cada imagen en el conjunto de datos. Luego empleamos el FiftyOne ViewField para filtrar imágenes según los valores mínimos de ancho y alto permitidos. Ver el siguiente código:
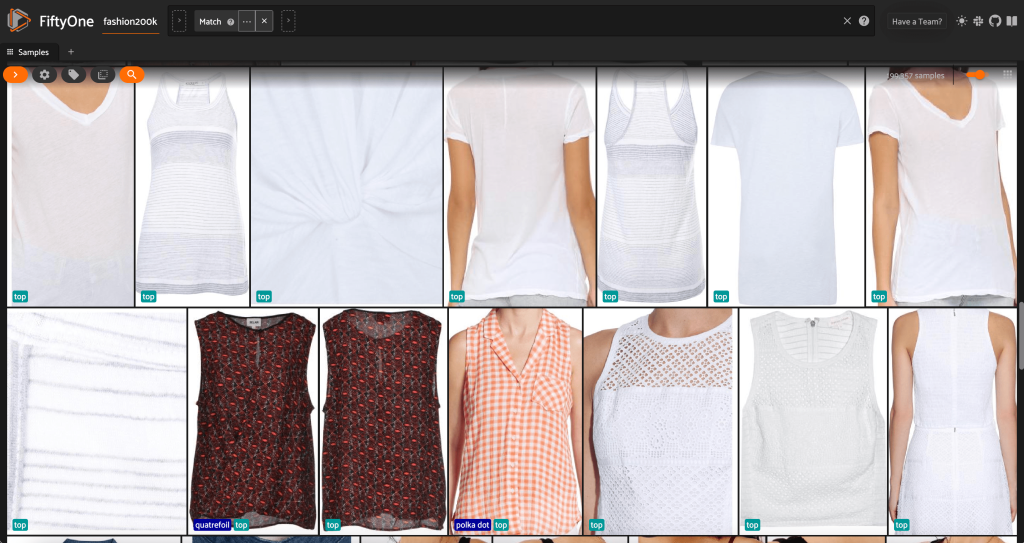
Este subconjunto de alta resolución tiene poco menos de 200,000 muestras.
Desde esta vista, podemos crear una nueva vista en nuestro conjunto de datos que contenga solo una muestra representativa (como máximo) para cada producto. usamos el ViewField una vez más, coincidencia de patrones para rutas de archivos que terminan con _0.jpeg:
Veamos un orden aleatorio de imágenes en este subconjunto:
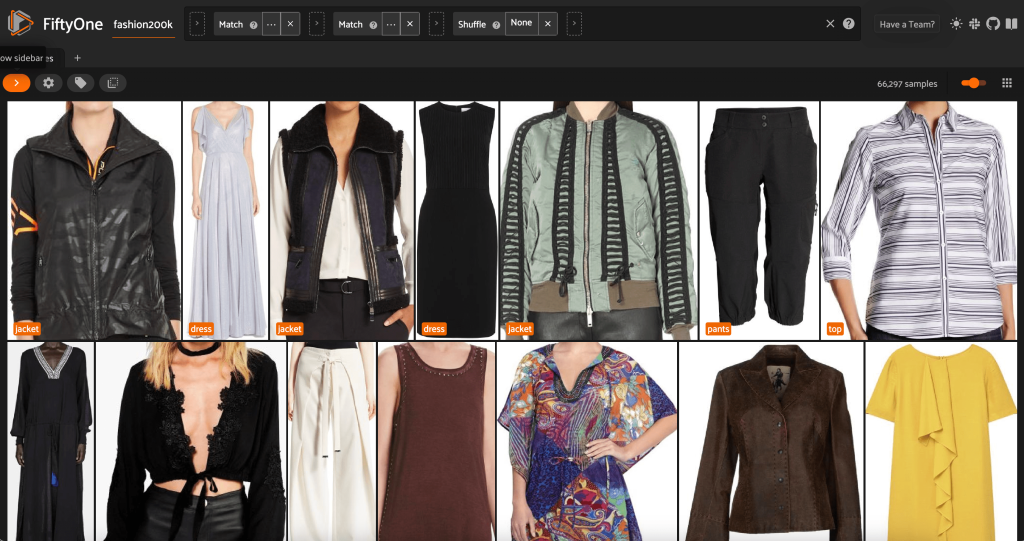
Eliminar imágenes redundantes en el conjunto de datos
Esta vista contiene 66,297 19 imágenes, o poco más del XNUMX % del conjunto de datos original. Sin embargo, cuando miramos la vista, vemos que hay muchos productos muy similares. Mantener todas estas copias probablemente solo agregará costos a nuestro etiquetado y capacitación de modelos, sin mejorar notablemente el rendimiento. En su lugar, deshagámonos de los casi duplicados para crear un conjunto de datos más pequeño que aún tenga el mismo impacto.
Debido a que estas imágenes no son duplicados exactos, no podemos verificar la igualdad de píxeles. Afortunadamente, podemos usar FiftyOne Brain para ayudarnos a limpiar nuestro conjunto de datos. En particular, calcularemos una incrustación para cada imagen (un vector de menor dimensión que representa la imagen) y luego buscaremos imágenes cuyos vectores de incrustación estén cerca uno del otro. Cuanto más cerca estén los vectores, más similares serán las imágenes.
Usamos un modelo CLIP para generar un vector de incrustación de 512 dimensiones para cada imagen y almacenamos estas incrustaciones en las incrustaciones de campo en las muestras de nuestro conjunto de datos:
Luego calculamos la cercanía entre incrustaciones, usando similitud de coseno, y afirme que es probable que dos vectores cuya similitud sea mayor que algún umbral estén casi duplicados. Las puntuaciones de similitud de coseno se encuentran en el rango [0, 1] y, al observar los datos, una puntuación de umbral de umbral = 0.5 parece ser correcta. Nuevamente, esto no necesita ser perfecto. No es probable que unas pocas imágenes casi duplicadas arruinen nuestro poder predictivo, y descartar algunas imágenes no duplicadas no afecta materialmente el rendimiento del modelo.
Podemos ver los supuestos duplicados para verificar que realmente son redundantes:
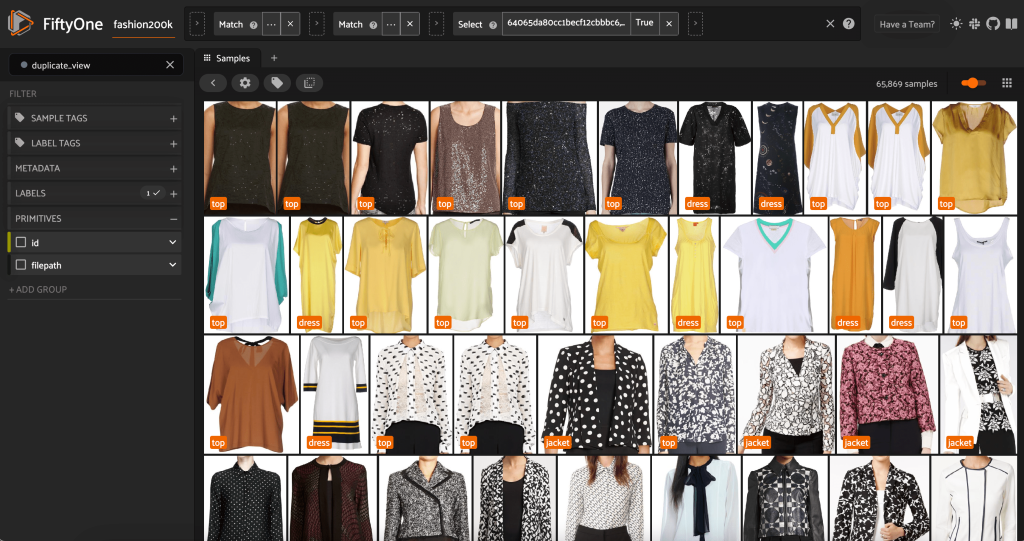
Cuando estemos satisfechos con el resultado y creamos que estas imágenes están casi duplicadas, podemos elegir una muestra de cada conjunto de muestras similares para conservar e ignorar las demás:
Ahora esta vista tiene 3,729 imágenes. Al limpiar los datos e identificar un subconjunto de alta calidad del conjunto de datos Fashion200K, FiftyOne nos permite restringir nuestro enfoque de más de 300,000 4,000 imágenes a poco menos de 98, lo que representa una reducción del 90 %. El uso de incrustaciones para eliminar imágenes casi duplicadas redujo nuestro número total de imágenes bajo consideración en más del XNUMX %, con poco o ningún efecto en los modelos que se entrenarán con estos datos.
Antes de etiquetar previamente este subconjunto, podemos comprender mejor los datos al visualizar las incrustaciones que ya hemos calculado. Podemos usar el sistema integrado de FiftyOne Brain compute_visualization(), que emplea la técnica de aproximación de variedad uniforme (UMAP) para proyectar los vectores de incrustación de 512 dimensiones en un espacio bidimensional para que podamos visualizarlos:
Abrimos un nuevo Panel de incrustaciones en la aplicación FiftyOne y colorear por tipo de artículo, y podemos ver que estas incrustaciones codifican aproximadamente una noción de tipo de artículo (¡entre otras cosas!).
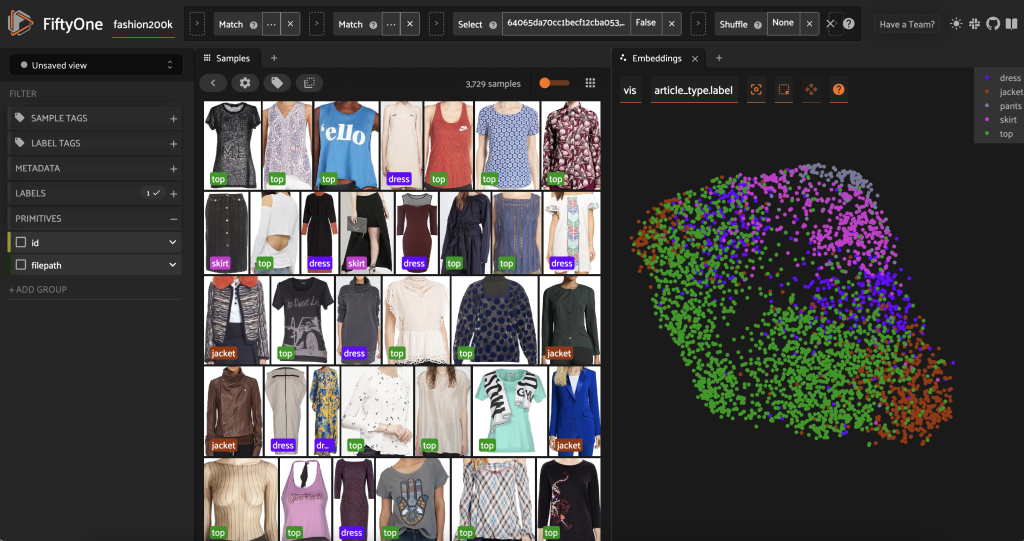
Ahora estamos listos para etiquetar previamente estos datos.
Al inspeccionar estas imágenes únicas y de alta resolución, podemos generar una lista inicial decente de estilos para usar como clases en nuestra clasificación de disparo cero de preetiquetado. Nuestro objetivo al etiquetar previamente estas imágenes no es necesariamente etiquetar cada imagen correctamente. Más bien, nuestro objetivo es proporcionar un buen punto de partida para los anotadores humanos para que podamos reducir el tiempo y el costo del etiquetado.
Entonces podemos instanciar un modelo de clasificación de tiro cero para esta aplicación. Usamos un modelo CLIP, que es un modelo de propósito general entrenado tanto en imágenes como en lenguaje natural. Creamos una instancia de un modelo CLIP con el mensaje de texto "Ropa con estilo", de modo que, dada una imagen, el modelo generará la clase para la que "Ropa con estilo [clase]" es la mejor opción. CLIP no está capacitado en datos específicos de venta minorista o moda, por lo que esto no será perfecto, pero puede ahorrarle costos de etiquetado y anotación.
Luego aplicamos este modelo a nuestro subconjunto reducido y almacenamos los resultados en un article_style campo:
Al iniciar la aplicación FiftyOne una vez más, podemos visualizar las imágenes con estas etiquetas de estilo previstas. Ordenamos por confianza de predicción para que veamos primero las predicciones de estilo más seguras:
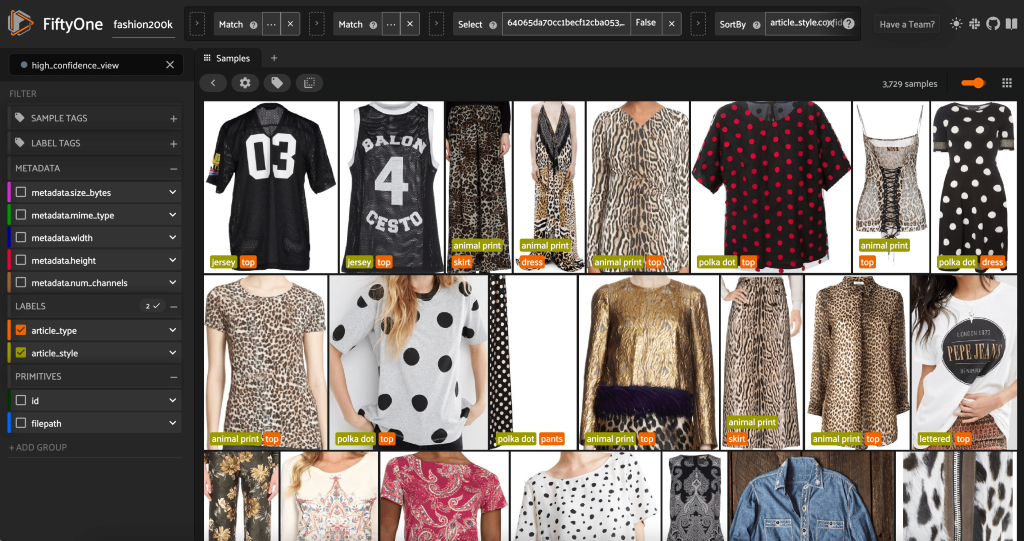
Podemos ver que las predicciones de mayor confianza parecen ser para los estilos "jersey", "animal print", "polka dot" y "lettered". Esto tiene sentido, porque estos estilos son relativamente distintos. También parece que, en su mayor parte, las etiquetas de estilo predichas son precisas.
También podemos ver las predicciones de estilo de menor confianza:
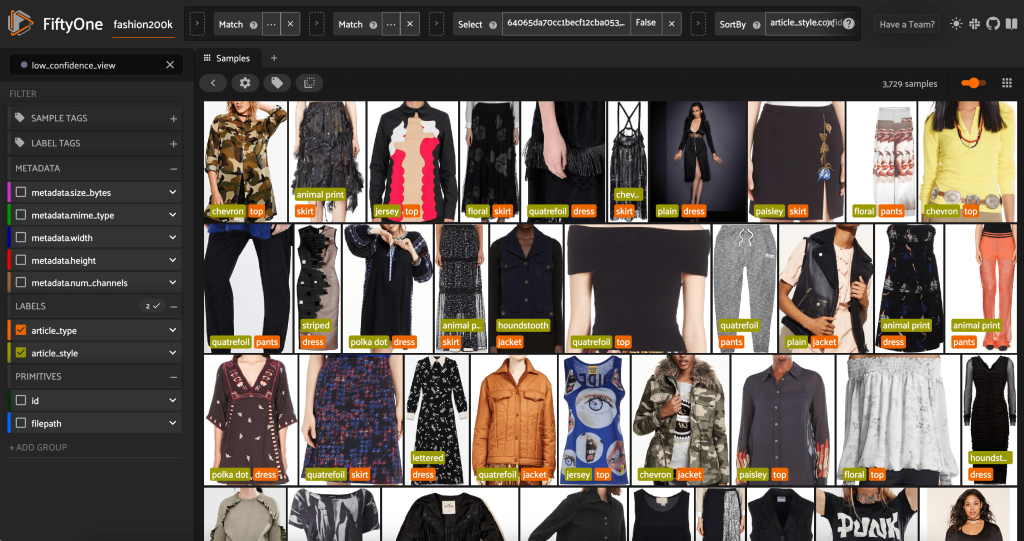
Para algunas de estas imágenes, la categoría de estilo adecuada se encuentra en la lista proporcionada y la prenda de vestir está etiquetada incorrectamente. La primera imagen en la cuadrícula, por ejemplo, debe ser claramente "camuflaje" y no "cheurón". En otros casos, sin embargo, los productos no encajan perfectamente en las categorías de estilo. El vestido de la segunda imagen de la segunda fila, por ejemplo, no tiene exactamente "rayas", pero dadas las mismas opciones de etiquetado, un anotador humano también podría haber estado en conflicto. A medida que construimos nuestro conjunto de datos, debemos decidir si eliminamos casos extremos como estos, agregamos nuevas categorías de estilo o aumentamos el conjunto de datos.
Exportar el conjunto de datos final de FiftyOne
Exporte el conjunto de datos final con el siguiente código:
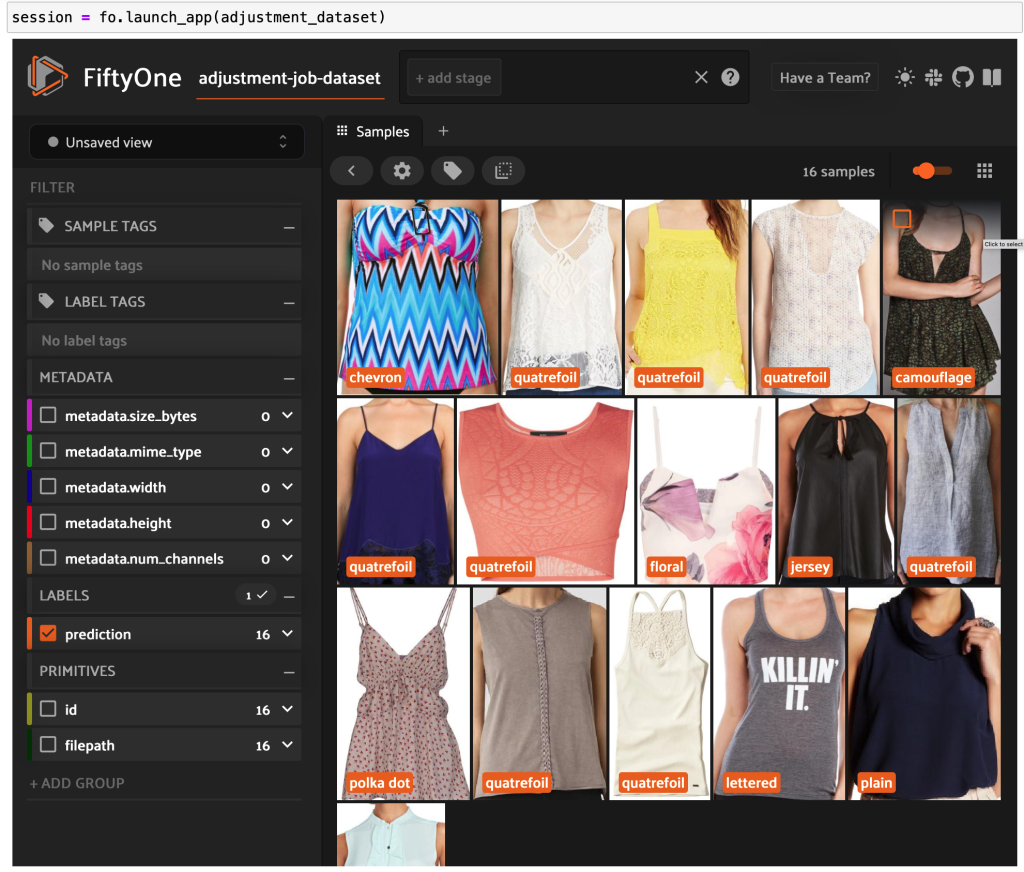
Podemos exportar un conjunto de datos más pequeño, por ejemplo, 16 imágenes, a la carpeta 200kFashionDatasetExportResult-16Images. Creamos un trabajo de ajuste de Ground Truth usándolo:
Cargue el conjunto de datos revisado, convierta el formato de la etiqueta a Ground Truth, cárguelo en Amazon S3 y cree un archivo de manifiesto para el trabajo de ajuste
Podemos convertir las etiquetas en el conjunto de datos para que coincidan con el esquema de manifiesto de salida de un trabajo de cuadro delimitador de Ground Truth y suba las imágenes a un Servicio de almacenamiento simple de Amazon (Amazon S3) cubo para lanzar un Trabajo de ajuste de Ground Truth:
Cargue el archivo de manifiesto en Amazon S3 con el siguiente código:
Cree etiquetas con estilo corregido con Ground Truth
Para anotar sus datos con etiquetas de estilo utilizando Ground Truth, complete los pasos necesarios para iniciar un trabajo de etiquetado de cuadro delimitador siguiendo el procedimiento descrito en el Primeros pasos con Ground Truth guía con el conjunto de datos en el mismo depósito S3.
- En la consola de SageMaker, cree un trabajo de etiquetado Ground Truth.
- Seleccione las Ubicación del conjunto de datos de entrada para ser el manifiesto que creamos en los pasos anteriores.
- Especifique una ruta S3 para Ubicación del conjunto de datos de salida.
- Rol de IAM, escoger Introduzca un rol de IAM personalizado ARNy, a continuación, introduzca el ARN del rol.
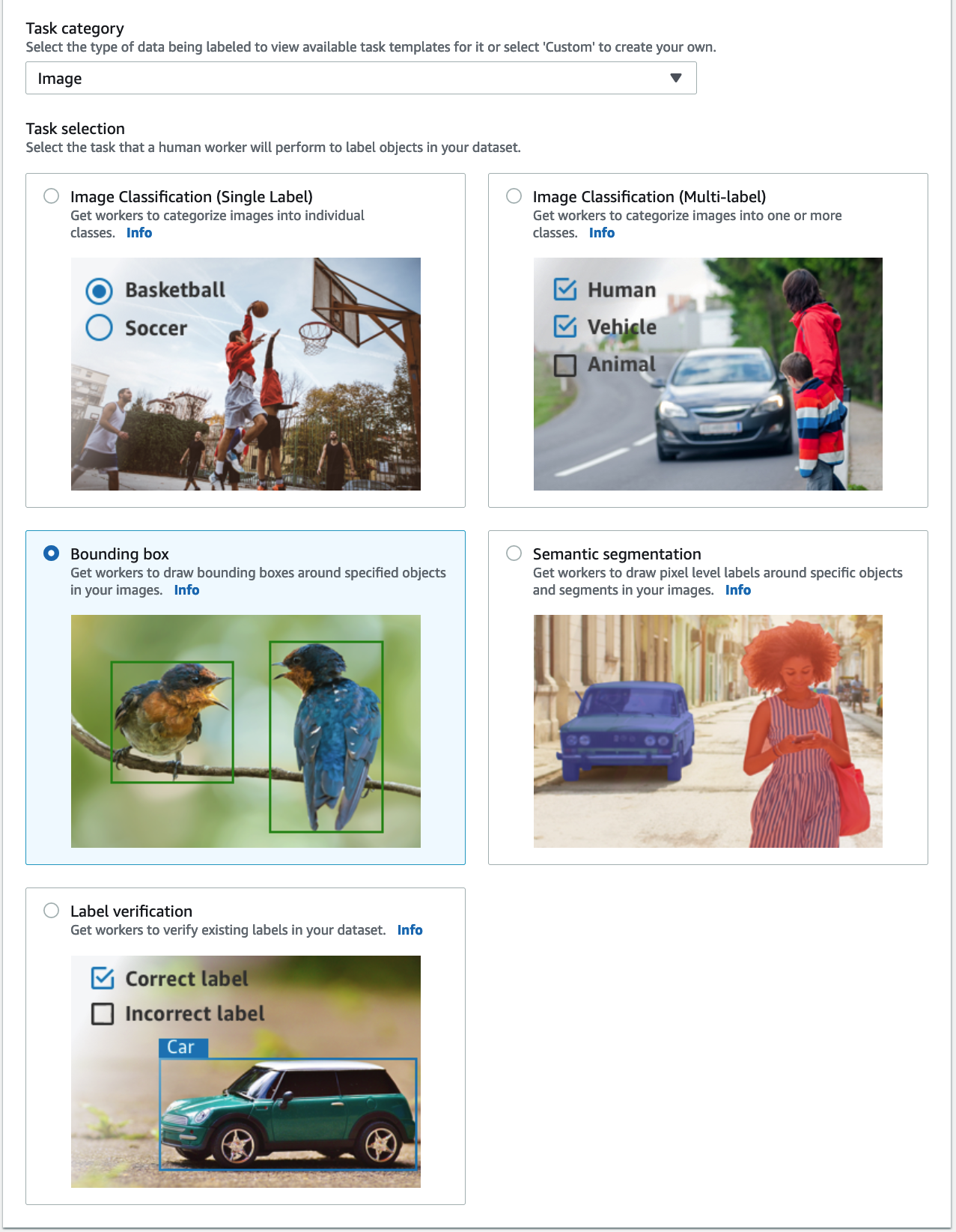
- Categoría de tarea, escoger Imagen y seleccionar Cuadro delimitador.
- Elige Siguiente.
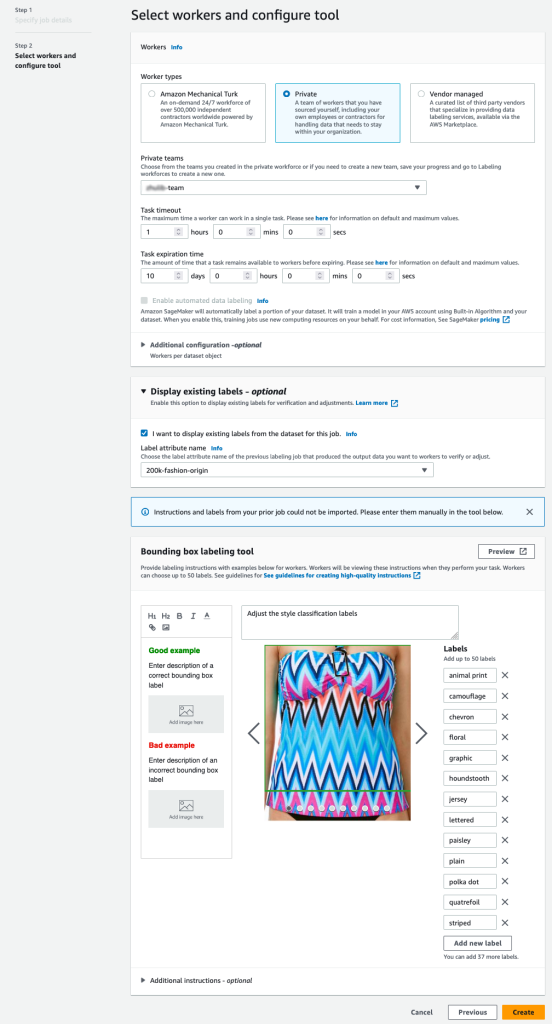
- En en domicilio sección, elija el tipo de mano de obra que le gustaría utilizar.
Puede seleccionar una fuerza de trabajo a través de Amazon Mechanical Turk, proveedores externos o su propia mano de obra privada. Para obtener más detalles sobre las opciones de su fuerza laboral, consulte Crear y administrar la fuerza laboral. - Expandir Opciones de visualización de etiquetas existentes y seleccionar Quiero mostrar las etiquetas existentes del conjunto de datos para este trabajo.
- Atributo de etiqueta nombre, elija el nombre de su manifiesto que corresponda a las etiquetas que desea mostrar para el ajuste.
Solo verá nombres de atributos de etiquetas para las etiquetas que coincidan con el tipo de tarea que seleccionó en los pasos anteriores. - Introduzca manualmente las etiquetas para Herramienta de etiquetado de cuadro delimitador.
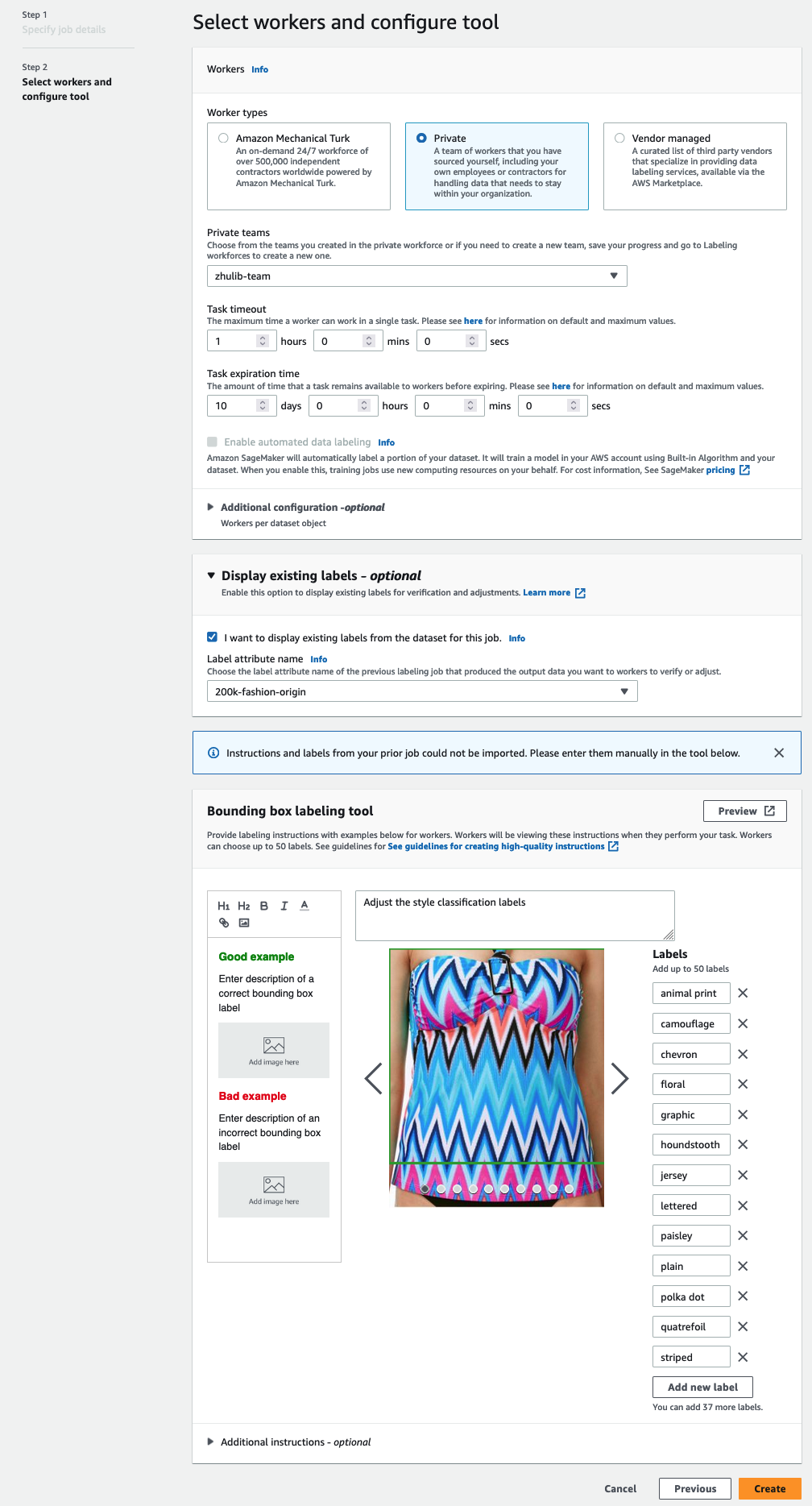 Las etiquetas deben contener las mismas etiquetas utilizadas en el conjunto de datos público. Puede agregar nuevas etiquetas. La siguiente captura de pantalla muestra cómo puede elegir los trabajadores y configurar la herramienta para su trabajo de etiquetado.
Las etiquetas deben contener las mismas etiquetas utilizadas en el conjunto de datos público. Puede agregar nuevas etiquetas. La siguiente captura de pantalla muestra cómo puede elegir los trabajadores y configurar la herramienta para su trabajo de etiquetado.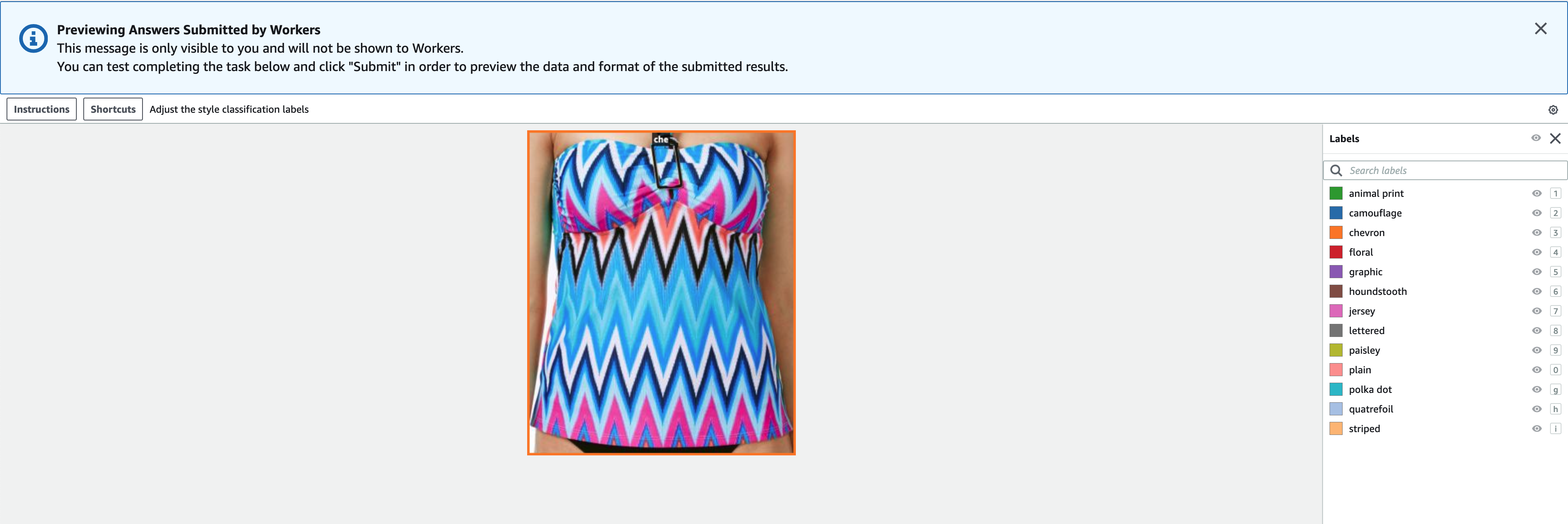
- Elige Vista previa para obtener una vista previa de la imagen y las anotaciones originales.
Ahora hemos creado un trabajo de etiquetado en Ground Truth. Después de completar nuestro trabajo, podemos cargar los datos etiquetados recién generados en FiftyOne. Ground Truth produce datos de salida en un manifiesto de salida de Ground Truth. Para obtener más detalles sobre el archivo de manifiesto de salida, consulte Salida de trabajo de cuadro delimitador. El siguiente código muestra un ejemplo de este formato de manifiesto de salida:
Revise los resultados etiquetados de Ground Truth en FiftyOne
Una vez completado el trabajo, descargue el manifiesto de salida del trabajo de etiquetado de Amazon S3.
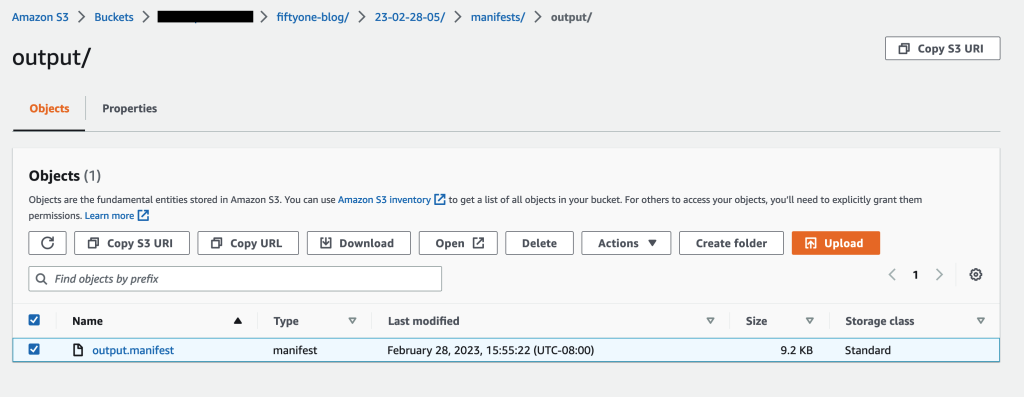
Lea el archivo de manifiesto de salida:
Cree un conjunto de datos FiftyOne y convierta las líneas del manifiesto en muestras en el conjunto de datos:
Ahora puede ver datos etiquetados de alta calidad de Ground Truth en FiftyOne.
Conclusión
En esta publicación, mostramos cómo crear conjuntos de datos de alta calidad combinando el poder de Cincuenta y uno by Voxel51, un conjunto de herramientas de código abierto que le permite administrar, rastrear, visualizar y seleccionar su conjunto de datos, y Ground Truth, un servicio de etiquetado de datos que le permite etiquetar de manera eficiente y precisa los conjuntos de datos necesarios para entrenar sistemas ML al proporcionar acceso a múltiples -en plantillas de tareas y acceso a una fuerza laboral diversa a través de Mechanical Turk, proveedores externos o su propia fuerza laboral privada.
Lo alentamos a que pruebe esta nueva funcionalidad instalando una instancia de FiftyOne y utilizando la consola Ground Truth para comenzar. Para obtener más información sobre Ground Truth, consulte Datos de etiqueta, Preguntas frecuentes sobre el etiquetado de datos de Amazon SageMaker, y la Blog de aprendizaje automático de AWS.
Conéctese con el Comunidad de inteligencia artificial y aprendizaje automático si tiene alguna pregunta o comentario!
¡Únete a la comunidad FiftyOne!
¡Únase a los miles de ingenieros y científicos de datos que ya utilizan FiftyOne para resolver algunos de los problemas más desafiantes de la visión por computadora en la actualidad!
Acerca de los autores
Shalendra Chabra Actualmente es jefe de gestión de productos de Amazon SageMaker Human-in-the-Loop (HIL) Services. Anteriormente, Shalendra incubó y lideró Language and Conversational Intelligence para Microsoft Teams Meetings, fue EIR en Amazon Alexa Techstars Startup Accelerator, VP of Product and Marketing en Discutir.io, Jefe de Producto y Marketing en Clipboard (adquirida por Salesforce) y Gerente Principal de Producto en Swype (adquirida por Nuance). En total, Shalendra ha ayudado a construir, enviar y comercializar productos que han afectado a más de mil millones de vidas.
jacob marcas es ingeniero de aprendizaje automático y evangelista desarrollador en Voxel51, donde ayuda a brindar transparencia y claridad a los datos del mundo. Antes de unirse a Voxel51, Jacob fundó una startup para ayudar a los músicos emergentes a conectarse y compartir contenido creativo con sus fans. Antes de eso, trabajó en Google X, Samsung Research y Wolfram Research. En una vida pasada, Jacob fue físico teórico y completó su doctorado en Stanford, donde investigó las fases cuánticas de la materia. En su tiempo libre, a Jacob le gusta escalar, correr y leer novelas de ciencia ficción.
jason corso es cofundador y director ejecutivo de Voxel51, donde dirige la estrategia para ayudar a brindar transparencia y claridad a los datos del mundo a través de un software flexible de última generación. También es profesor de Robótica, Ingeniería Eléctrica y Ciencias de la Computación en la Universidad de Michigan, donde se enfoca en problemas de vanguardia en la intersección de la visión por computadora, el lenguaje natural y las plataformas físicas. En su tiempo libre, Jason disfruta pasar tiempo con su familia, leer, estar en la naturaleza, jugar juegos de mesa y todo tipo de actividades creativas.
Brian Moore es co-fundador y CTO de Voxel51, donde lidera la estrategia técnica y la visión. Tiene un doctorado en Ingeniería Eléctrica de la Universidad de Michigan, donde su investigación se centró en algoritmos eficientes para problemas de aprendizaje automático a gran escala, con un énfasis particular en aplicaciones de visión artificial. En su tiempo libre, disfruta del bádminton, el golf, el senderismo y juega con sus gemelos Yorkshire Terriers.
Bai Zhuling es ingeniero de desarrollo de software en Amazon Web Services. Trabaja en el desarrollo de sistemas distribuidos a gran escala para resolver problemas de aprendizaje automático.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :posee
- :es
- :no
- :dónde
- $ UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Sobre nosotros
- acelerar
- acelerador
- acelerador
- de la máquina
- preciso
- precisamente
- adquirido
- actividades
- add
- la adición de
- dirección
- Equilibrado
- del Riesgo
- Después
- de nuevo
- AI
- Alexa
- algoritmos
- Todos
- permite
- solo
- ya haya utilizado
- también
- Amazon
- amazon alexa
- Amazon SageMaker
- Verdad fundamental de Amazon SageMaker
- Amazon Web Services
- entre
- an
- analizar
- y
- animal
- cualquier
- applicación
- Aplicación
- aplicaciones
- Aplicá
- adecuado
- somos
- arreglado
- artículo
- AS
- asociado
- At
- Autorzy
- lejos
- AWS
- bases
- basado
- BE
- porque
- a las que has recomendado
- esto
- antes
- detrás de
- entre bastidores
- "Ser"
- CREEMOS
- MEJOR
- mejores
- entre
- mil millones
- tablero
- Juegos de Mesa
- HUESO
- Bootstrap
- ambas
- Box
- cajas
- Cerebro
- Descanso
- llevar
- Traído
- presupuesto
- build
- Construir la
- incorporado
- pero
- comprar
- by
- PUEDEN
- Capturando
- case
- cases
- categoría
- Categoría
- ceo
- Reto
- desafiante
- comprobar
- Elige
- transparencia
- clase
- privadas
- clasificación
- Limpieza
- limpiar
- con claridad.
- cliente
- Alpinismo
- Cerrar
- más cerca
- ropa
- Ropa
- Co-founder
- código
- combinar
- combinar
- compañía
- Complemento
- completar
- completando
- Calcular
- computadora
- Ciencias de la Computación
- Visión por computador
- Aplicaciones de visión artificial
- confianza
- seguros
- Conectarse
- consideración
- Que consiste
- Consola
- contiene
- contenido
- contenido
- controlado
- conversacional
- convertir
- copias
- Core
- corregido
- corresponde
- Cost
- Precio
- Para crear
- creado
- Estudio
- Referencias
- CTO
- comisariada
- comisariado
- En la actualidad
- personalizado
- cliente
- Clientes
- Corte
- innovador
- datos
- conjuntos de datos
- decidir
- demostrar
- Denim
- profundidad
- descripción
- detalles
- Detección
- Developer
- el desarrollo
- Desarrollo
- una experiencia diferente
- directamente
- directorios
- Pantalla
- distinto
- distribuidos
- sistemas distribuidos
- diverso
- do
- No
- Perro
- "Hacer"
- hecho
- No
- DOT
- DE INSCRIPCIÓN
- descargar
- duplicados
- e
- cada una
- de forma sencilla
- Southern Implants
- efecto
- eficiente
- eficiente.
- Ingenieria Eléctrica
- incrustación
- emergentes
- énfasis
- emplea
- empodera
- encapsulado
- fomentar
- final
- ingeniero
- Ingeniería
- certificados
- Participar
- Entorno
- igualdad
- esencial
- se establece
- Éter (ETH)
- evaluación
- Evangelista
- exactamente
- ejemplo
- existente
- exportar
- bastante
- familia
- aficionados
- realimentación
- pocos
- Ficción
- campo
- Terrenos
- Archive
- archivos
- filtrar
- filtración
- final
- Nombre
- cómodo
- flexible
- Focus
- centrado
- se centra
- siguiendo
- formulario
- formato
- Afortunadamente
- Fundado
- Digital XNUMXk
- Gratuito
- en
- completamente
- a la fatiga
- Juegos
- propósito general
- generar
- generado
- obtener
- GitHub
- Donar
- dado
- objetivo
- golf
- candidato
- mayor
- Cuadrícula
- Polo a Tierra
- Grupo procesos
- guía
- Ahorrar
- Tienen
- he
- cabeza
- altura
- ayuda
- ayudado
- serviciales
- ayuda
- esta página
- alta calidad
- de alta resolución
- más alto
- altamente
- excursionismo
- su
- mantiene
- Cómo
- Como Hacer
- Sin embargo
- HTML
- http
- HTTPS
- humana
- i
- AMI
- ID
- Identifique
- identificar
- ids
- if
- imagen
- imágenes
- Impacto
- importar
- la mejora de
- in
- En otra
- Incluye
- incorrectamente
- incubado
- información
- inicial
- posiblemente
- instalar
- instalando
- ejemplo
- Instrucciones
- Intelligence
- intersección
- dentro
- IT
- SUS
- Jersey
- Trabajos
- unión
- articulación
- json
- solo
- Guardar
- acuerdo
- Label
- etiquetado
- Etiquetas
- idioma
- Gran escala
- lanzamiento
- lanzamiento
- Lead
- Prospectos
- APRENDE:
- aprendizaje
- menos
- LED
- izquierda
- Permíteme
- Biblioteca
- Vida
- como
- que otros
- LIMITE LAS
- Limitada
- línea
- líneas
- Lista
- listado
- Propiedades
- pequeño
- Vidas
- carga
- Mira
- mirando
- Lote
- Baja
- máquina
- máquina de aprendizaje
- hecho
- magic
- para lograr
- HACE
- gestionan
- gestionado
- Management
- gerente
- muchos
- mapa
- Mercado
- Marketing
- Match
- pareo
- materialmente
- Materia
- Puede..
- mecánico
- Medios
- reuniones
- Meta
- metadatos
- Método
- métodos
- Michigan
- Microsoft
- equipos de microsoft
- podría
- mínimo
- ML
- Móvil
- Aplicación movil
- modelo
- modelos
- Módulos
- más,
- MEJOR DE TU
- movimiento
- mucho más
- múltiples
- músicos
- debe
- nombre
- Llamado
- nombres
- Natural
- Lenguaje natural
- Naturaleza
- Cerca
- necesariamente
- necesario
- ¿ Necesita ayuda
- Nuevo
- notablemente
- Noción
- ahora
- Nuance
- número
- objeto
- Detección de objetos
- objetos
- of
- oficial
- on
- una vez
- ONE
- en línea
- , solamente
- habiertos
- de código abierto
- Operaciones
- Oportunidad
- Opciones
- or
- Organizado
- reconocida por
- OS
- Otro
- Otros
- nuestros
- salir
- esbozado
- salida
- Más de
- EL DESARROLLADOR
- Posee
- Packs
- emparejado
- parte
- particular
- pasado
- camino
- Patrón de Costura
- .
- perfecto
- actuación
- persona
- Personalizado
- Fases de la materia
- los libros físicos
- recoger
- Fotos
- TARTÁN
- Natural
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- jugando
- punto
- poblado
- posible
- Publicación
- industria
- previsto
- predicción
- Predicciones
- Vista previa
- anterior
- previamente
- Imprimir
- Anterior
- privada
- probablemente
- problemas
- Producto
- gestión de producto
- gerente de producto
- Productos
- Profesor
- proyecto
- perfecta
- futuro
- prototipo
- proporcionar
- previsto
- proporcionando
- público
- ponche
- fines
- Python
- Cuántico
- Preguntas
- con rapidez
- distancia
- más bien
- Reading
- ready
- recomiendan
- recomendaciones
- reducir
- Reducción
- reducción
- relativamente
- liberado
- remove
- representante
- que representa
- Requisitos
- la investigación
- investigadores
- Resolución
- restringir
- resultado
- resultante
- Resultados
- el comercio minorista
- volvemos
- una estrategia SEO para aparecer en las búsquedas de Google.
- Eliminar
- robótica
- robusto
- Función
- aproximadamente
- FILA
- ruina
- correr
- sabio
- Said
- fuerza de ventas
- mismo
- Samsung
- Guardar
- Escenas
- Ciencia:
- Ciencia ficción
- los científicos
- Puntuación
- sin problemas
- Segundo
- Sección
- (secciones)
- ver
- parecer
- parece
- seleccionado
- sentido
- separado
- de coches
- Servicios
- Sesión
- set
- Compartir
- ella
- tienes
- Mostrar
- Shows
- Tarjeta SIM
- similares
- sencillos
- menores
- So
- Software
- Desarrollo de software ad-hoc
- RESOLVER
- algo
- Alguien
- algo
- Espacio
- pasar
- Gastos
- dividido
- escisiones
- stanford
- comienzo
- fundó
- Comience a
- inicio
- acelerador de arranque
- el estado de la técnica
- pasos
- Sin embargo
- STORAGE
- tienda
- Estrategia
- papa
- estilos
- RESUMEN
- Soportado
- Todas las funciones a su disposición
- ¡Prepárate!
- Tarea
- equipos
- Técnico
- TechStars
- decirles
- plantillas
- test
- que
- esa
- El
- su
- Les
- luego
- teorético
- Ahí.
- Estas
- ellos
- cosas
- pensar
- terceros.
- así
- miles
- umbral
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- Lanzamiento
- equipo
- a
- juntos
- del IRS
- caja de herramientas
- parte superior
- nivel superior
- Tops
- Total
- tocado
- seguir
- Entrenar
- entrenado
- Formación
- Transformar
- Transparencia
- verdadero
- verdad
- GIRO
- dos
- tipo
- tipos
- bajo
- entender
- único
- universidad
- Universidad de Michigan
- Actualizar
- us
- utilizan el
- caso de uso
- usado
- Usuario
- usuarios
- usando
- Valores
- variedad
- diversos
- vendedores
- verificar
- muy
- vía
- Ver
- Virtual
- visión
- quieres
- fue
- we
- web
- servicios web
- WELL
- tuvieron
- ¿
- cuando
- sean
- que
- Wikipedia
- seguirá
- dentro de
- sin
- Mujeres
- palabras
- Actividades:
- trabajado
- los trabajadores.
- Empleados
- funciona
- mundo
- preocuparse
- se
- escribir
- X
- Usted
- tú
- zephyrnet
- Zip
- ZOO