En el mundo actual impulsado por los datos, la capacidad de mover y analizar datos sin esfuerzo a través de diversas plataformas es esencial. Flujo de aplicaciones de Amazon, un servicio de integración de datos totalmente administrado, ha estado a la vanguardia de la optimización de la transferencia de datos entre los servicios de AWS, las aplicaciones de software como servicio (SaaS) y ahora Google BigQuery. En esta publicación de blog, exploras lo nuevo Conector de Google BigQuery en Amazon AppFlow y descubra cómo simplifica el proceso de transferencia de datos desde el almacén de datos de Google a Servicio de almacenamiento simple de Amazon (Amazon S3), proporcionando importantes beneficios para las organizaciones y profesionales de datos, incluida la democratización del acceso a datos en múltiples nubes.
Descripción general de Amazon AppFlow
Flujo de aplicaciones de Amazon es un servicio de integración totalmente administrado que puede utilizar para transferir datos de forma segura entre aplicaciones SaaS como Google BigQuery, Salesforce, SAP, Hubspot y ServiceNow, y servicios de AWS como Amazon S3 y Desplazamiento al rojo de Amazon, en tan sólo unos pocos clics. Con Amazon AppFlow, puede ejecutar flujos de datos en casi cualquier escala con la frecuencia que elija: según un cronograma, en respuesta a un evento comercial o según demanda. Puede configurar capacidades de transformación de datos, como filtrado y validación, para generar datos enriquecidos y listos para usar como parte del propio flujo, sin pasos adicionales. Amazon AppFlow cifra automáticamente los datos en movimiento y le permite restringir el flujo de datos a través de la Internet pública para aplicaciones SaaS que están integradas con Enlace privado de AWS, reduciendo la exposición a amenazas a la seguridad.
Presentamos el conector de Google BigQuery
El nuevo Conector de Google BigQuery en Amazon AppFlow revela posibilidades para las organizaciones que buscan utilizar la capacidad analítica del almacén de datos de Google e integrar, analizar, almacenar o procesar datos de BigQuery sin esfuerzo, transformándolos en información procesable.
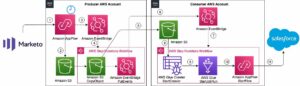
Arquitectura
Repasemos la arquitectura para transferir datos de Google BigQuery a Amazon S3 usando Amazon AppFlow.

- Seleccione una fuente de datos: En Flujo de aplicaciones de Amazon, seleccione Google BigQuery como fuente de datos. Especifique las tablas o conjuntos de datos de los que desea extraer datos.
- Mapeo y transformación de campos: configure la transferencia de datos utilizando la interfaz visual intuitiva de Amazon AppFlow. Puede asignar campos de datos y aplicar transformaciones según sea necesario para alinear los datos con sus requisitos.
- Frecuencia de transferencia: decida con qué frecuencia desea transferir datos (por ejemplo, diaria, semanal o mensual), lo que respalda la flexibilidad y la automatización.
- Destino: especifique un depósito de S3 como destino de sus datos. Amazon AppFlow moverá los datos de manera eficiente, haciéndolos accesibles en su almacenamiento de Amazon S3.
- Consumo: Uso Atenea amazónica para analizar los datos en Amazon S3.
Requisitos previos
El conjunto de datos utilizado en esta solución es generado por Sintea, un simulador sintético de población de pacientes y un proyecto de código abierto bajo el Licencia Apache 2.0. Cargue estos datos en Google BigQuery o utilice su conjunto de datos existente.
Conecte Amazon AppFlow a su cuenta de Google BigQuery
Para esta publicación, utiliza una cuenta de Google, un cliente OAuth con los permisos adecuados y datos de Google BigQuery. Para habilitar el acceso a Google BigQuery desde Amazon AppFlow, debe configurar un nuevo cliente OAuth con anticipación. Para obtener instrucciones, consulte Conector de Google BigQuery para Amazon AppFlow.
Configurar Amazon S3
Cada objeto de Amazon S3 se almacena en un depósito. Antes de poder almacenar datos en Amazon S3, debe crear un cubo S3 para almacenar los resultados.
Cree un nuevo depósito de S3 para los resultados de Amazon AppFlow
Para crear un depósito de S3, complete los siguientes pasos:
- En la consola de administración de AWS para Amazon S3, escoger Crear cubeta.
- Ingrese un globalmente único nombre para tu cubo; por ejemplo,
appflow-bq-sample. - Elige Crea un cubo.
Cree un nuevo depósito de S3 para los resultados de Amazon Athena
Para crear un depósito de S3, complete los siguientes pasos:
- En la consola de administración de AWS para Amazon S3, escoger Crear cubeta.
- Ingrese un globalmente único nombre para tu cubo; por ejemplo,
athena-results. - Elige Crea un cubo.
Rol de usuario (rol de IAM) para AWS Glue Data Catalog
Para catalogar los datos que transfiere con su flujo, debe tener el rol de usuario adecuado en Administración de acceso e identidad de AWS (IAM). Usted proporciona este rol a Amazon AppFlow para otorgar los permisos que necesita para crear un Catálogo de datos de AWS Glue, tablas, bases de datos y particiones.
Para ver un ejemplo de política de IAM que tiene los permisos necesarios, consulte Ejemplos de políticas basadas en identidad para Amazon AppFlow.
Tutorial del diseño.
Ahora, veamos un caso de uso práctico para ver cómo funciona el conector Amazon AppFlow Google BigQuery a Amazon S3. Para el caso de uso, utilizará Amazon AppFlow para archivar datos históricos de Google BigQuery en Amazon S3 para su almacenamiento y análisis a largo plazo.
Configurar Amazon AppFlow
Cree un nuevo flujo de Amazon AppFlow para transferir datos de Google Analytics a Amazon S3.
- En Consola de Amazon AppFlow, escoger Crear flujo.
- Ingrese un nombre para su flujo; Por ejemplo,
my-bq-flow. - Agregar necesario Etiquetas; por ejemplo, para Clave entrar
envy para Valor entrardev.

- Elige Siguiente.
- Nombre de la fuente, escoger Google BigQuery.
- Elige Crear nueva conexión.
- Ingrese su OAuth ID de cliente y Secreto del cliente, luego nombra tu conexión; Por ejemplo,
bq-connection.

- En la ventana emergente, elija permitir el acceso de amazon.com a la API de Google BigQuery.

- Elija el objeto Google BigQuery, escoger Mesa.
- Elija el subobjeto de Google BigQuery, escoger Nombre del proyecto de BigQuery.
- Elija el subobjeto de Google BigQuery, escoger DatabaseName.
- Elija el subobjeto de Google BigQuery, escoger Nombre de tabla.
- Nombre del destino, escoger Amazon S3.
- Detalles del cubo, elija el depósito de Amazon S3 que creó para almacenar los resultados de Amazon AppFlow en los requisitos previos.
- Participar
rawcomo herramienta de edición del prefijo.
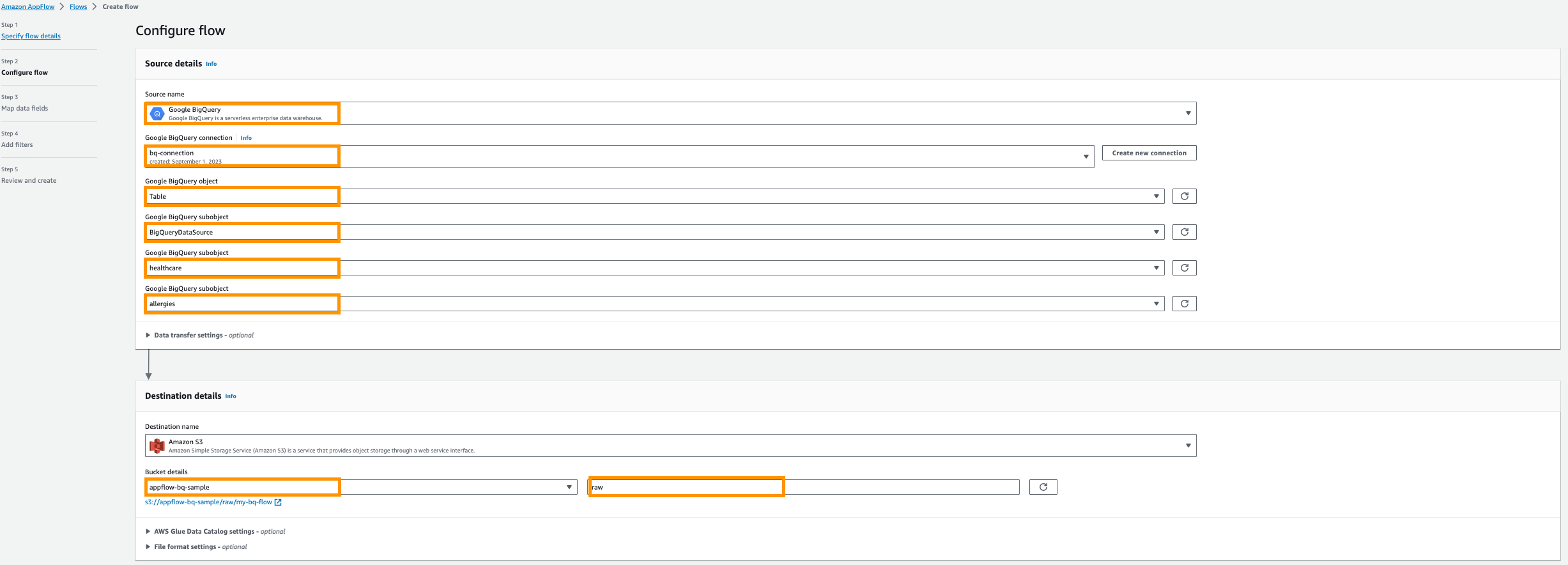
- A continuación, proporcione Catálogo de datos de AWS Glue configuración para crear una tabla para análisis posteriores.
- Seleccione Rol de usuario (rol de IAM) creado en los requisitos previos.
- Crear nuevo base de datos por ejemplo,
healthcare. - Proporcionar una Tabla de prefijos configurando por ejemplo,
bq.
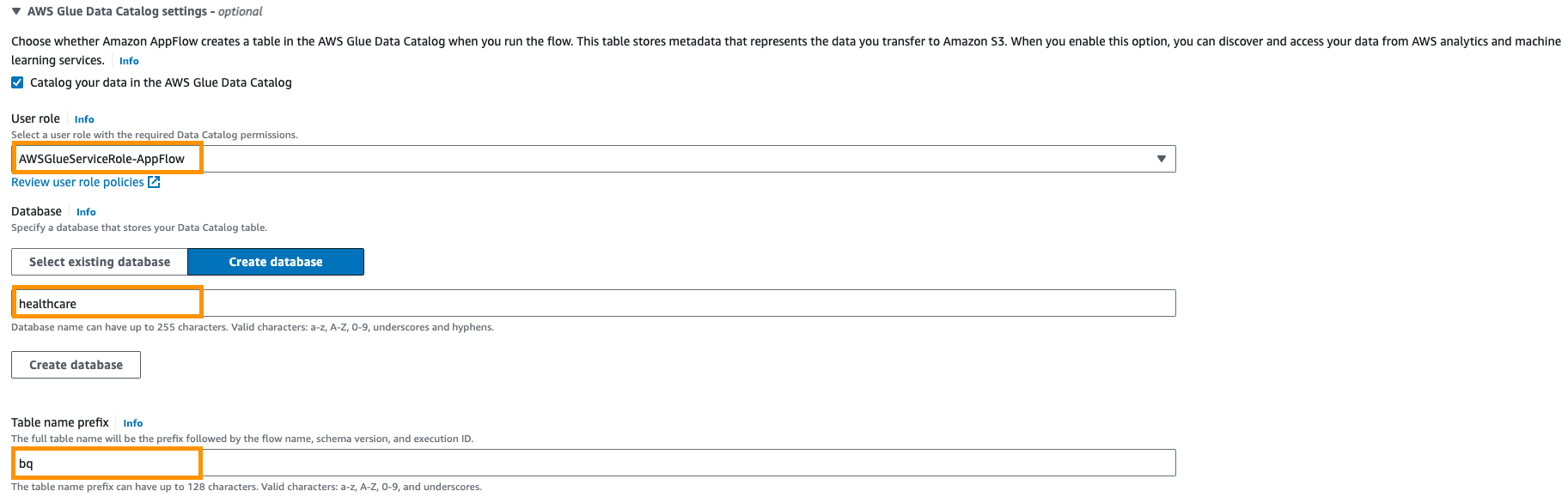
- Seleccione Ejecutar bajo demanda.
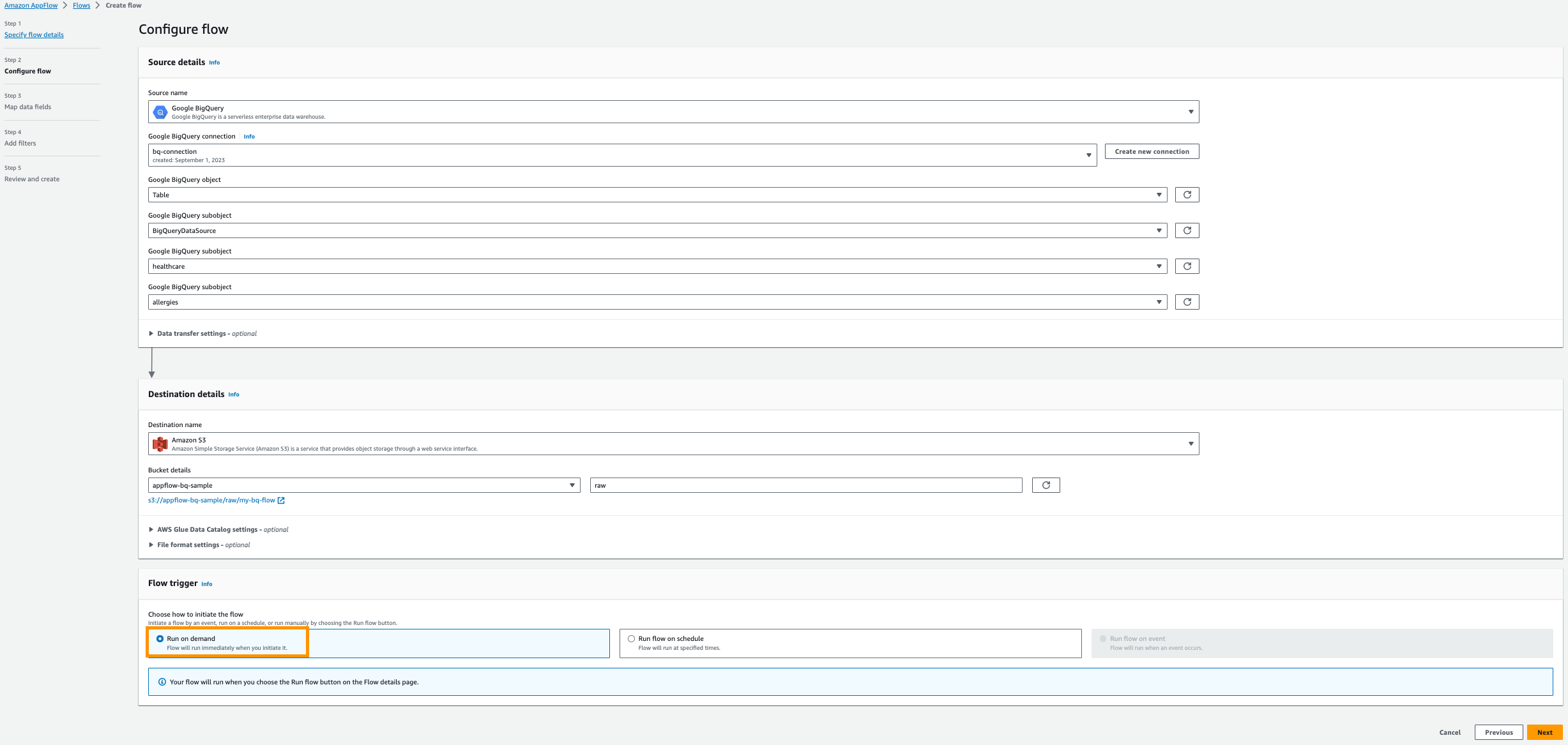
- Elige Siguiente.
- Seleccione Asignar campos manualmente.
- Seleccione los siguientes seis campos para Nombre del campo de origen de la mesa Alergias:
- Inicio
- Pacientes
- Código
- Descripción
- Tipo de Propiedad
- Categoría
- Elige Asignar campos directamente.

- Elige Siguiente.
- In Agregar filtros sección, elija Siguiente.
- Elige Crear flujo.
Ejecuta el flujo
Después de crear su nuevo flujo, puede ejecutarlo según demanda.
- En Consola de Amazon AppFlow, escoger
my-bq-flow. - Elige Ejecutar flujo.

Para este tutorial, elija ejecutar el trabajo bajo demanda para facilitar su comprensión. En la práctica, puede elegir un trabajo programado y extraer periódicamente sólo los datos recién agregados.
Consulta a través de Amazon Athena
Cuando selecciona la configuración opcional de AWS Glue Data Catalog, Data Catalog crea el catálogo de datos, lo que permite a Amazon Athena realizar consultas.
Si se le solicita que configure una ubicación de resultados de consulta, navegue hasta la Ajustes pestaña y elegir Gestiona. Debajo Administrar configuración, elija el depósito de resultados de Athena creado en los requisitos previos y elija Guardar.
- En Consola Amazon Atenea, seleccione la fuente de datos como
AWSDataCatalog. - Luego, selecciona Base de datos as
healthcare. - Ahora puede seleccionar la tabla creada por el rastreador de AWS Glue y obtener una vista previa de ella.

- También puede ejecutar una consulta personalizada para encontrar las 10 alergias principales, como se muestra en la siguiente consulta.
Note: En la siguiente consulta, reemplace el nombre de la tabla, en este caso bq_appflow_mybqflow_1693588670_latest, con el nombre de la tabla generada en su cuenta de AWS.
- Elige Ejecutar consulta.

Este resultado muestra las 10 principales alergias por número de casos.
Limpiar
Para evitar incurrir en cargos, limpie los recursos de su cuenta de AWS completando los siguientes pasos:
- En la consola de Amazon AppFlow, elija Flujos en el panel de navegación.
- De la lista de flujos, seleccione el flujo
my-bq-flowy eliminarlo. - Ingrese eliminar para eliminar el flujo.
- Elige Conexiones en el panel de navegación.
- Elige Google BigQuery de la lista de conectores, seleccione
bq-connectory eliminarlo. - Ingrese eliminar para eliminar el conector.
- En la consola de IAM, elija Roles en la página de navegación, luego seleccione el rol que creó para el rastreador de AWS Glue y elimínelo.
- En la consola de Amazon Athena:
- Eliminar las tablas creadas en la base de datos.
healthcareutilizando el rastreador de AWS Glue. - Suelta la base de datos
healthcare
- Eliminar las tablas creadas en la base de datos.
- En la consola de Amazon S3, busque el depósito de resultados de Amazon AppFlow que creó, elija Vacío para eliminar los objetos, luego elimine el cubo.
- En la consola de Amazon S3, busque el depósito de resultados de Amazon Athena que creó, elija Vacío para eliminar los objetos, luego elimine el cubo.
- Limpie los recursos de su cuenta de Google eliminando el proyecto que contiene los recursos de Google BigQuery. Siga la documentación para limpiar los recursos de Google.
Conclusión
El conector Google BigQuery en Amazon AppFlow agiliza el proceso de transferencia de datos desde el almacén de datos de Google a Amazon S3. Esta integración simplifica el análisis y el aprendizaje automático, el archivado y el almacenamiento a largo plazo, lo que brinda importantes beneficios para los profesionales de datos y las organizaciones que buscan aprovechar las capacidades analíticas de ambas plataformas.
Con Amazon AppFlow, se eliminan las complejidades de la integración de datos, lo que le permite concentrarse en obtener información útil a partir de sus datos. Ya sea que esté archivando datos históricos, realizando análisis complejos o preparando datos para el aprendizaje automático, este conector simplifica el proceso y lo hace accesible a una gama más amplia de profesionales de datos.
Si está interesado en ver cómo se transfieren los datos de Google BigQuery a Amazon S3 usando Amazon AppFlow, consulte el paso a paso. tutorial de vídeo. En este tutorial, recorremos todo el proceso, desde configurar la conexión hasta ejecutar el flujo de transferencia de datos. Para obtener más información sobre Amazon AppFlow, visite Flujo de aplicaciones de Amazon.
Sobre los autores
![]() Kartikay Khator es arquitecto de soluciones para ciencias biológicas globales en Amazon Web Services. Le apasiona ayudar a los clientes en su viaje a la nube centrándose en los servicios de análisis de AWS. Es un ávido corredor y le gusta el senderismo.
Kartikay Khator es arquitecto de soluciones para ciencias biológicas globales en Amazon Web Services. Le apasiona ayudar a los clientes en su viaje a la nube centrándose en los servicios de análisis de AWS. Es un ávido corredor y le gusta el senderismo.
 Kamen Sharlandjiev es un arquitecto senior de soluciones ETL y Big Data y experto en Amazon AppFlow. Su misión es hacer la vida más fácil a los clientes que enfrentan desafíos complejos de integración de datos. ¿Su arma secreta? Servicios de AWS totalmente administrados y de bajo código que pueden realizar el trabajo con el mínimo esfuerzo y sin codificación.
Kamen Sharlandjiev es un arquitecto senior de soluciones ETL y Big Data y experto en Amazon AppFlow. Su misión es hacer la vida más fácil a los clientes que enfrentan desafíos complejos de integración de datos. ¿Su arma secreta? Servicios de AWS totalmente administrados y de bajo código que pueden realizar el trabajo con el mínimo esfuerzo y sin codificación.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/simplify-data-transfer-google-bigquery-to-amazon-s3-using-amazon-appflow/
- :posee
- :es
- $ UP
- 10
- 100
- 14
- 16
- 17
- 22
- 321
- 8
- 9
- a
- capacidad
- Nuestra Empresa
- de la máquina
- Gestión de Acceso
- accesible
- Mi Cuenta
- a través de
- add
- adicional
- Adicionales
- avanzar
- alinear
- Alergias
- permitir
- Permitir
- permite
- también
- Amazon
- Atenea amazónica
- Amazon Web Services
- Amazon.com
- an
- análisis
- Pruebas analíticas
- Analytics
- analizar
- y
- cualquier
- abejas
- aplicaciones
- Aplicá
- adecuado
- arquitectura
- Archive
- somos
- AS
- At
- automáticamente
- Automatización
- evitar
- AWS
- Pegamento AWS
- Consola de administración de AWS
- esto
- antes
- a continuación
- beneficios
- entre
- Big
- Big Data
- bigquery
- Blog
- ambas
- más amplio
- by
- PUEDEN
- Puede conseguir
- capacidades
- capacidad
- case
- cases
- catalogar
- Categoría
- retos
- cargos
- Elige
- cliente
- Soluciones
- Codificación
- COM
- completar
- completando
- integraciones
- complejidades
- conexión
- Consola
- contiene
- rastreador
- Para crear
- creado
- crea
- Creamos
- personalizado
- Clientes
- todos los días
- datos
- acceso a los datos
- integración de datos
- almacenamiento de datos
- basada en datos
- Base de datos
- bases de datos
- conjuntos de datos
- decidir
- Demanda
- democratización
- descripción
- destino
- descrubrir
- diverso
- documentación
- hecho
- facilidad
- más fácil
- eficiente.
- esfuerzo
- sin esfuerzo
- eliminado
- habilitar
- permitiendo
- Todo
- esencial
- Éter (ETH)
- Evento
- ejemplo
- ejemplos
- existente
- experto
- explorar
- Exposición
- extraerlos
- tener problemas con
- pocos
- campo
- Terrenos
- filtración
- Encuentre
- Flexibilidad
- de tus señales
- Fluido
- Flujos
- Focus
- seguir
- siguiendo
- primer plano
- Frecuencia
- frecuentemente
- Desde
- completamente
- promover
- generar
- generado
- obtener
- Buscar
- En todo el mundo
- Google Analytics
- De Google
- conceder
- Grupo procesos
- aprovechar
- Tienen
- he
- la salud
- ayudando
- excursionismo
- su
- histórico
- Cómo
- HTML
- http
- HTTPS
- HubSpot
- AMI
- Identidad
- Gestión de identidad y acceso.
- in
- Incluye
- información
- Insights
- Instrucciones
- integrar
- COMPLETAMENTE
- integración
- interesado
- Interfaz
- Internet
- dentro
- intuitivo
- IT
- sí mismo
- Trabajos
- solo
- aprendizaje
- Licencia
- Vida
- Ciencias de la vida
- LIMITE LAS
- Lista
- carga
- Ubicación
- compromiso a largo plazo
- Mira
- máquina
- máquina de aprendizaje
- para lograr
- Realizar
- gestionado
- Management
- mapa
- cartografía
- mínimo
- misión
- más,
- movimiento
- movimiento
- debe
- nombre
- Navegar
- Navegación
- hace casi
- necesario
- Nuevo
- recién
- no
- ahora
- número
- juramento
- objeto
- objetos
- of
- on
- On-Demand
- , solamente
- opensource
- or
- solicite
- para las fiestas.
- Más de
- página
- cristal
- parte
- apasionado
- paciente
- realizar
- realizar
- permisos
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- política
- ventanas emergentes
- población
- POSIBILIDADES
- Publicación
- Metodología
- preparación
- requisitos previos
- Vista previa
- profesionales
- proyecto
- proporcionar
- proporcionando
- público
- consultas
- distancia
- la reducción de
- reemplazar
- Requisitos
- Requisitos
- Recursos
- respuesta
- restringir
- resultado
- Resultados
- una estrategia SEO para aparecer en las búsquedas de Google.
- Rico
- Función
- Ejecutar
- corredor
- correr
- SaaS
- fuerza de ventas
- savia
- Escala
- programa
- programada
- Ciencia:
- Buscar
- Secreto
- Sección
- segura
- EN LINEA
- Las amenazas de seguridad
- ver
- la búsqueda de
- de coches
- Servicios
- set
- pólipo
- ajustes
- mostrado
- Shows
- importante
- sencillos
- simplificar
- simulador
- SEIS
- Software
- software como servicio
- a medida
- Soluciones
- Fuente
- pasos
- STORAGE
- tienda
- almacenados
- racionalización
- tal
- sintético
- mesa
- ¡Prepárate!
- esa
- La
- su
- luego
- así
- amenazas
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- a
- de hoy
- parte superior
- Top 10
- transferir
- Transferencia
- transformaciones
- transformadora
- tutoriales
- tipo
- bajo
- comprensión
- único
- Revela
- utilizan el
- caso de uso
- usado
- Usuario
- usando
- validación
- propuesta de
- Visite
- caminar
- tutorial
- quieres
- Manejo de
- we
- web
- servicios web
- una vez por semana
- sean
- QUIENES
- seguirá
- ventana
- sin
- funciona
- mundo
- Usted
- tú
- Youtube
- zephyrnet