La creación de modelos básicos (FM) requiere crear, mantener y optimizar grandes grupos para entrenar modelos con decenas a cientos de miles de millones de parámetros en grandes cantidades de datos. Crear un entorno resiliente que pueda manejar fallas y cambios ambientales sin perder días o semanas de progreso en la capacitación del modelo es un desafío operativo que requiere implementar escalamiento de clústeres, monitoreo proactivo del estado, puntos de control de trabajos y capacidades para reanudar automáticamente la capacitación en caso de que surjan fallas o problemas. .
Estamos emocionados de compartir eso HiperPod de Amazon SageMaker ahora está disponible de forma generalizada para permitir modelos básicos de capacitación con miles de aceleradores hasta un 40% más rápido al proporcionar un entorno de capacitación altamente resiliente y al mismo tiempo eliminar el trabajo pesado indiferenciado que implica operar grupos de capacitación a gran escala. Con SageMaker HyperPod, los profesionales del aprendizaje automático (ML) pueden entrenar FM durante semanas y meses sin interrupciones y sin tener que lidiar con problemas de fallas de hardware.
Clientes como Stability AI utilizan SageMaker HyperPod para entrenar sus modelos básicos, incluido Stable Diffusion.
“Como empresa líder en IA generativa de código abierto, nuestro objetivo es maximizar la accesibilidad de la IA moderna. Estamos construyendo modelos básicos con decenas de miles de millones de parámetros, que requieren la infraestructura para escalar el rendimiento del entrenamiento de manera óptima. Con la infraestructura administrada y las bibliotecas de optimización de SageMaker HyperPod, podemos reducir el tiempo y los costos de capacitación en más de un 50 %. Hace que nuestro entrenamiento de modelos sea más resistente y eficaz para construir modelos de última generación más rápido”.
– Emad Mostaque, fundador y director ejecutivo de Stability AI.
Para que el ciclo completo de desarrollo de FM sea resistente a fallas de hardware, SageMaker HyperPod lo ayuda a crear clústeres, monitorear el estado del clúster, reparar y reemplazar nodos defectuosos sobre la marcha, guardar puntos de control frecuentes y reanudar automáticamente el entrenamiento sin perder el progreso. Además, SageMaker HyperPod está preconfigurado con Amazon SageMaker bibliotecas de formación distribuidas, incluida la Biblioteca de paralelismo de datos de SageMaker (SMDDP) y Biblioteca de paralelismo de modelos de SageMaker (SMP), para mejorar el rendimiento del entrenamiento de FM al hacer que sea sencillo dividir los datos y modelos de entrenamiento en fragmentos más pequeños y procesarlos en paralelo en los nodos del clúster, mientras se utiliza al máximo la infraestructura informática y de red del clúster. SageMaker HyperPod integra Slurm Workload Manager para la orquestación de trabajos de capacitación y clústeres.
Descripción general del Administrador de carga de trabajo de Slurm
Slurm, anteriormente conocida como Utilidad simple de Linux para la gestión de recursos, es un programador de trabajos para ejecutar trabajos en un clúster informático distribuido. También proporciona un marco para ejecutar trabajos paralelos utilizando el Biblioteca de comunicaciones colectivas de NVIDIA (NCCL) or Interfaz de paso de mensajes (MPI) estándares. Slurm es un popular sistema de gestión de recursos de clúster de código abierto que se utiliza ampliamente en informática de alto rendimiento (HPC) y cargas de trabajo de capacitación de IA y FM generativas. SageMaker HyperPod proporciona una forma sencilla de poner en marcha un clúster Slurm en cuestión de minutos.
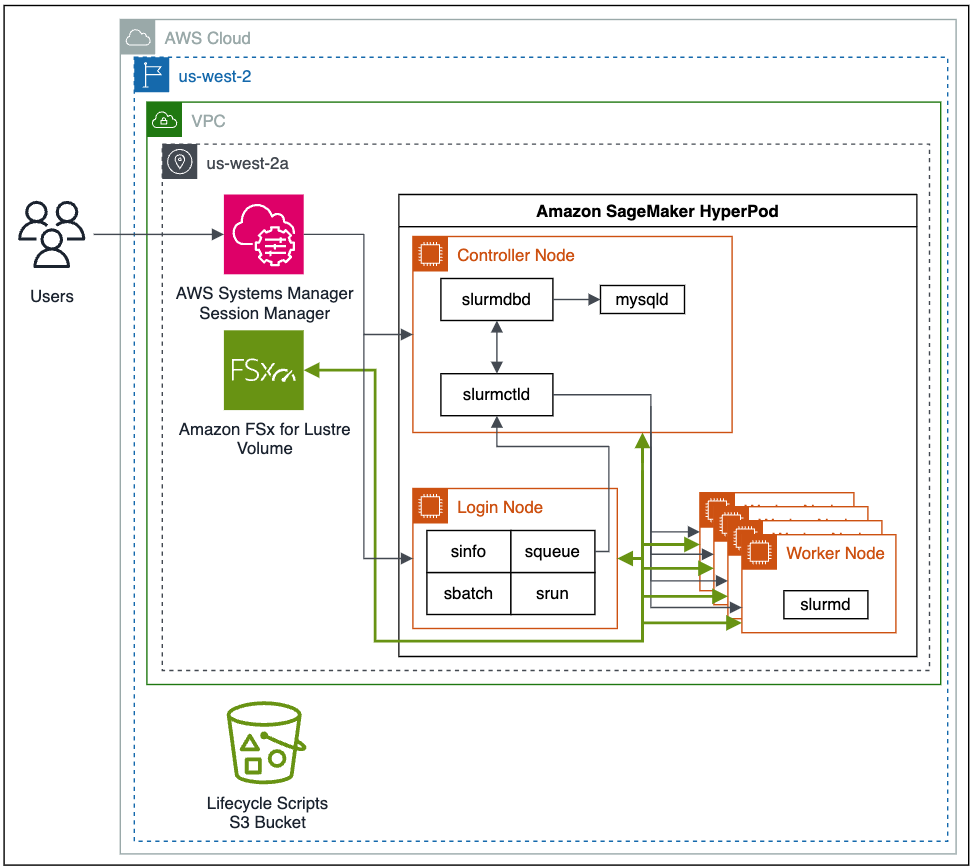
El siguiente es un diagrama arquitectónico de alto nivel de cómo los usuarios interactúan con SageMaker HyperPod y cómo los distintos componentes del clúster interactúan entre sí y con otros servicios de AWS, como Amazon FSx para Lustre y Servicio de almacenamiento simple de Amazon (Amazon S3).
Los trabajos de Slurm se envían mediante comandos en la línea de comandos. Los comandos para ejecutar trabajos de Slurm son srun y sbatch. srun El comando ejecuta el trabajo de entrenamiento en modo interactivo y de bloqueo, y sbatch se ejecuta en procesamiento por lotes y modo sin bloqueo. srun se utiliza principalmente para ejecutar trabajos inmediatos, mientras que sbatch se puede utilizar para posteriores ejecuciones de trabajos.
Para obtener información sobre la configuración y los comandos adicionales de Slurm, consulte la Documentación del administrador de carga de trabajo de Slurm.
Capacidades de recuperación y reanudación automática
Una de las nuevas características de SageMaker HyperPod es la capacidad de reanudar automáticamente sus trabajos. Anteriormente, cuando un nodo trabajador fallaba durante la ejecución de un trabajo de capacitación o ajuste, dependía del usuario verificar el estado del trabajo, reiniciar el trabajo desde el último punto de control y continuar monitoreando el trabajo durante toda la ejecución. Dado que los trabajos de capacitación o de ajuste deben ejecutarse durante días, semanas o incluso meses seguidos, esto se vuelve costoso debido a la sobrecarga administrativa adicional que supone para el usuario la necesidad de dedicar ciclos a monitorear y mantener el trabajo en caso de que un fallas de nodos, así como el costo del tiempo de inactividad de costosas instancias informáticas aceleradas.
SageMaker HyperPod aborda la resiliencia del trabajo mediante controles de estado automatizados, reemplazo de nodos y recuperación de trabajos. Los trabajos de Slurm en SageMaker HyperPod se monitorean usando un complemento Slurm personalizado de SageMaker usando el Marco SPANK. Cuando falla un trabajo de capacitación, SageMaker HyperPod inspeccionará el estado del clúster mediante un conjunto de comprobaciones de estado. Si se encuentra un nodo defectuoso en el clúster, SageMaker HyperPod eliminará automáticamente el nodo del clúster, lo reemplazará con un nodo en buen estado y reiniciará el trabajo de entrenamiento. Cuando se utilizan puntos de control en trabajos de capacitación, cualquier trabajo interrumpido o fallido puede reanudarse desde el último punto de control.
Resumen de la solución
Para implementar su SageMaker HyperPod, primero prepare su entorno configurando su Nube privada virtual de Amazon (Amazon VPC) y grupos de seguridad, implementando servicios de soporte como FSx for Lustre en su VPC y publicando sus scripts del ciclo de vida de Slurm en un depósito de S3. Luego, implementa y configura su SageMaker HyperPod y se conecta al nodo principal para comenzar sus trabajos de capacitación.
Requisitos previos
Antes de crear su SageMaker HyperPod, primero debe configurar su VPC, crear un sistema de archivos FSx para Lustre y establecer un depósito S3 con los scripts del ciclo de vida del clúster que desee. También necesita la última versión del Interfaz de línea de comandos de AWS (AWS CLI) y el complemento CLI instalado para Administrador de sesiones de AWS, una capacidad de Gerente de sistemas de AWS.
SageMaker HyperPod está completamente integrado con su VPC. Para obtener información sobre la creación de una nueva VPC, consulte Crear una VPC predeterminada or Crear una VPC. Para permitir una conexión perfecta con el mayor rendimiento entre recursos, debe crear todos sus recursos en la misma región y zona de disponibilidad, así como asegurarse de que las reglas del grupo de seguridad asociadas permitan la conexión entre los recursos del clúster.
Luego, tú crear un sistema de archivos FSx para Lustre. Esto servirá como sistema de archivos de alto rendimiento para usar durante nuestro entrenamiento de modelos. Asegúrese de que FSx for Lustre y los grupos de seguridad del clúster permitan la comunicación entrante y saliente entre los recursos del clúster y el sistema de archivos FSx for Lustre.
Para configurar los scripts del ciclo de vida del clúster, que se ejecutan cuando ocurren eventos como una nueva instancia del clúster, cree un depósito S3 y luego copie y, opcionalmente, personalice los scripts del ciclo de vida predeterminados. Para este ejemplo, almacenamos todos los scripts del ciclo de vida en un prefijo de depósito de lifecycle-scripts.
Primero, descargue los scripts de ciclo de vida de muestra del Repositorio GitHub. Debe personalizarlos para que se adapten a los comportamientos de clúster que desee.
A continuación, cree un depósito de S3 para almacenar los scripts del ciclo de vida personalizados.
A continuación, copie los scripts del ciclo de vida predeterminados de su directorio local al depósito que desee y prefije usando aws s3 sync:
Finalmente, para configurar el cliente para una conexión simplificada al nodo principal del clúster, debe instalar o actualizar la CLI de AWS E instalar el Complemento CLI de AWS Session Manager para permitir conexiones de terminales interactivas para administrar el clúster y ejecutar trabajos de capacitación.
Puede crear un clúster de SageMaker HyperPod con recursos bajo demanda disponibles o solicitando una reserva de capacidad con SageMaker. Para crear una reserva de capacidad, cree una solicitud de aumento de cuota para reservar tipos de instancias informáticas específicas y asignación de capacidad en el panel Cuotas de servicio.
Configura tu grupo de entrenamiento
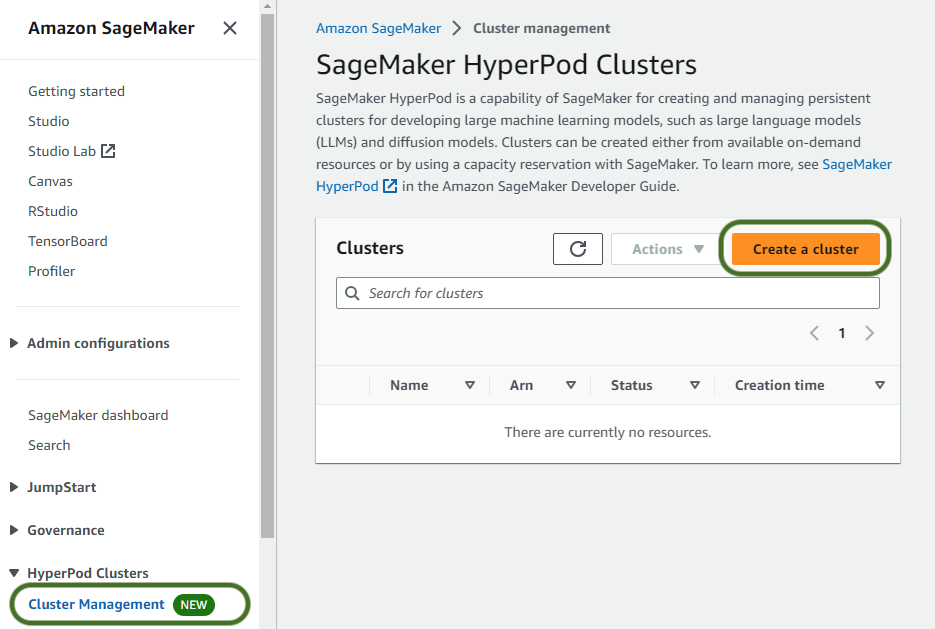
Para crear su clúster SageMaker HyperPod, complete los siguientes pasos:
- En la consola de SageMaker, elija Gestión de clústeres bajo Clústeres de HyperPod en el panel de navegación.
- Elige Crear un cluster.
- Proporcione un nombre de clúster y, opcionalmente, cualquier etiqueta para aplicar a los recursos del clúster, luego elija Siguiente.
- Seleccione Crear grupo de instancias y especifique el nombre del grupo de instancias, el tipo de instancia necesaria, la cantidad de instancias deseadas y el depósito de S3 y la ruta del prefijo donde copió los scripts del ciclo de vida del clúster anteriormente.
Se recomienda tener diferentes grupos de instancias para los nodos de controlador utilizados para administrar el clúster y enviar trabajos y los nodos trabajadores utilizados para ejecutar trabajos de entrenamiento mediante instancias informáticas aceleradas. Opcionalmente, puedes configurar un grupo de instancias adicional para los nodos de inicio de sesión.
- Primero crea el grupo de instancias del controlador, que incluirá el nodo principal del clúster.
- Para este grupo de instancias Gestión de identidades y accesos de AWS (IAM), elija Crear un nuevo rol y especifique los depósitos de S3 a los que desea que tengan acceso las instancias de clúster del grupo de instancias.
Al rol generado se le otorgará acceso de solo lectura a los depósitos especificados de forma predeterminada.
- Elige Crear rol.
- Ingrese el nombre del script que se ejecutará en cada creación de instancia en el mensaje de script al crear. En este ejemplo, el script de creación se llama
on_create.sh.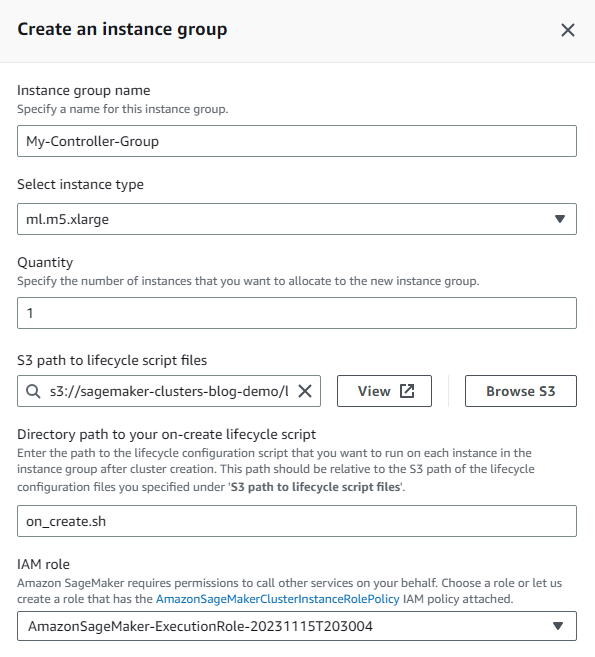
- Elige Guardar.
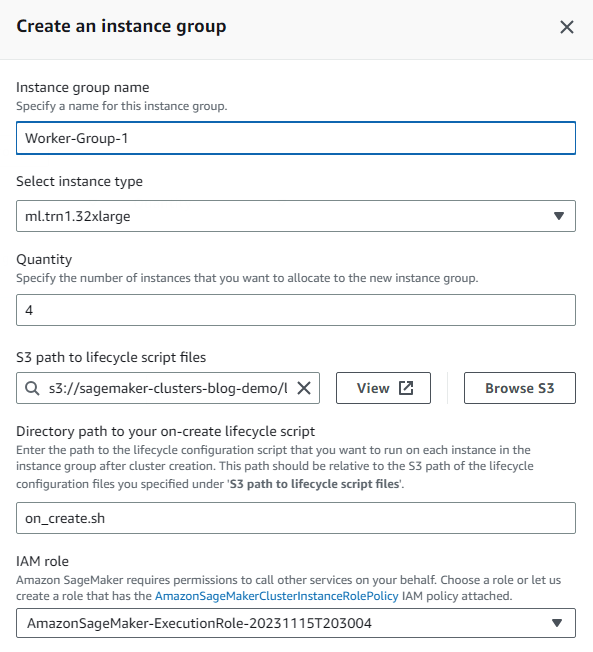
- Elige Crear grupo de instancias para crear su grupo de instancias de trabajador.
- Proporcione todos los detalles solicitados, incluido el tipo de instancia y la cantidad deseada.
Este ejemplo utiliza cuatro instancias aceleradas ml.trn1.32xl para realizar nuestro trabajo de capacitación. Puede utilizar la misma función de IAM que antes o personalizar la función para las instancias de trabajo. De manera similar, puede usar scripts de ciclo de vida de creación diferentes para este grupo de instancias de trabajador que para el grupo de instancias anterior.
- Elige Siguiente para proceder.
- Elija la VPC, la subred y los grupos de seguridad que desee para sus instancias de clúster.
Alojamos las instancias del clúster en una única zona de disponibilidad y subred para garantizar una baja latencia.
Tenga en cuenta que si accederá a datos de S3 con frecuencia, se recomienda crear un punto final de VPC asociado con la tabla de enrutamiento de la subred privada para reducir los costos potenciales de transferencia de datos.
- Elige Siguiente.

- Revise el resumen de detalles del clúster y luego elija Enviar.
Como alternativa, para crear su SageMaker HyperPod utilizando la CLI de AWS, primero personalice los parámetros JSON utilizados para crear el clúster:
Luego use el siguiente comando para crear el clúster usando las entradas proporcionadas:
Realiza tu primer trabajo de entrenamiento con Llama 2
Tenga en cuenta que el uso del modelo Llama 2 se rige por la licencia Meta. Para descargar los pesos del modelo y el tokenizador, visite el página web del NDN Collective y acepte la licencia antes de solicitar acceso en Sitio web de Meta's Hugging Face.
Después de que el clúster se esté ejecutando, inicie sesión en Session Manager utilizando la identificación del clúster, el nombre del grupo de instancias y la identificación de la instancia. Utilice el siguiente comando para ver los detalles de su clúster:
Tome nota del ID del clúster incluido en el ARN del clúster en la respuesta.
Utilice el siguiente comando para recuperar el nombre del grupo de instancias y el ID de instancia necesarios para iniciar sesión en el clúster.
Toma nota del InstanceGroupName y del InstanceId en la respuesta, ya que se utilizarán para conectarse a la instancia con el Administrador de sesión.
Ahora usa el Administrador de sesión para iniciar sesión en el nodo principal, o en uno de los nodos de inicio de sesión, y ejecutar su trabajo de entrenamiento:
A continuación, prepararemos el entorno y descargaremos Llama 2 y el conjunto de datos de RedPajama. Para obtener el código completo y un tutorial paso a paso, siga las instrucciones en el AWSome capacitación distribuida Repo de GitHub.
Siga los pasos detallados en el 2.test_cases/8.neuronx-nemo-megatron/README.md archivo. Después de seguir los pasos para preparar el entorno, preparar el modelo, descargar y tokenizar el conjunto de datos y precompilar el modelo, debe editar el 6.pretrain-model.sh guión y el sbatch comando de envío de trabajos para incluir un parámetro que le permitirá aprovechar la función de reanudación automática de SageMaker HyperPod.
Editar el sbatch línea para que se parezca a lo siguiente:
Después de enviar el trabajo, obtendrá un JobID que puede utilizar para comprobar el estado del trabajo utilizando el siguiente código:
Además, puede monitorear el trabajo siguiendo el registro de salida del trabajo usando el siguiente código:
Limpiar
Para eliminar su clúster de SageMaker HyperPod, utilice la consola de SageMaker o el siguiente comando de AWS CLI:
Conclusión
Esta publicación le mostró cómo preparar su entorno de AWS, implementar su primer clúster SageMaker HyperPod y entrenar un modelo Llama 7 de 2 mil millones de parámetros. SageMaker HyperPod está generalmente disponible hoy en las regiones de América (Virginia del Norte, Ohio y Oregón), Asia Pacífico (Singapur, Sídney y Tokio) y Europa (Frankfurt, Irlanda y Estocolmo). Se pueden implementar a través de la consola de SageMaker, AWS CLI y AWS SDK, y admiten las familias de instancias p4d, p4de, p5, trn1, inf2, g5, c5, c5n, m5 y t3.
Para obtener más información sobre SageMaker HyperPod, visite HiperPod de Amazon SageMaker.
Sobre los autores
 Brad Doran es gerente técnico senior de cuentas en Amazon Web Services, enfocado en IA generativa. Es responsable de resolver los desafíos de ingeniería para los clientes de IA generativa en el segmento del mercado empresarial nativo digital. Tiene experiencia en desarrollo de infraestructura y software y actualmente está realizando estudios de doctorado e investigación en inteligencia artificial y aprendizaje automático.
Brad Doran es gerente técnico senior de cuentas en Amazon Web Services, enfocado en IA generativa. Es responsable de resolver los desafíos de ingeniería para los clientes de IA generativa en el segmento del mercado empresarial nativo digital. Tiene experiencia en desarrollo de infraestructura y software y actualmente está realizando estudios de doctorado e investigación en inteligencia artificial y aprendizaje automático.
 Keita Watanabe es arquitecto senior de soluciones especializado en GenAI en Amazon Web Services, donde ayuda a desarrollar soluciones de aprendizaje automático utilizando proyectos OSS como Slurm y Kubernetes. Su experiencia se centra en la investigación y el desarrollo del aprendizaje automático. Antes de unirse a AWS, Keita trabajó en la industria del comercio electrónico como científica investigadora desarrollando sistemas de recuperación de imágenes para la búsqueda de productos. Keita tiene un doctorado en Ciencias de la Universidad de Tokio.
Keita Watanabe es arquitecto senior de soluciones especializado en GenAI en Amazon Web Services, donde ayuda a desarrollar soluciones de aprendizaje automático utilizando proyectos OSS como Slurm y Kubernetes. Su experiencia se centra en la investigación y el desarrollo del aprendizaje automático. Antes de unirse a AWS, Keita trabajó en la industria del comercio electrónico como científica investigadora desarrollando sistemas de recuperación de imágenes para la búsqueda de productos. Keita tiene un doctorado en Ciencias de la Universidad de Tokio.
 Justin Pirtle es arquitecto principal de soluciones en Amazon Web Services. Asesora periódicamente a clientes de IA generativa en el diseño, implementación y ampliación de su infraestructura. Es un orador habitual en las conferencias de AWS, incluido re:Invent, así como en otros eventos de AWS. Justin tiene una licenciatura en Sistemas de Información Gerencial de la Universidad de Texas en Austin y una maestría en Ingeniería de Software de la Universidad de Seattle.
Justin Pirtle es arquitecto principal de soluciones en Amazon Web Services. Asesora periódicamente a clientes de IA generativa en el diseño, implementación y ampliación de su infraestructura. Es un orador habitual en las conferencias de AWS, incluido re:Invent, así como en otros eventos de AWS. Justin tiene una licenciatura en Sistemas de Información Gerencial de la Universidad de Texas en Austin y una maestría en Ingeniería de Software de la Universidad de Seattle.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/introducing-amazon-sagemaker-hyperpod-to-train-foundation-models-at-scale/
- :es
- :dónde
- $ UP
- 1
- 100
- 12
- 14
- 24
- 7
- a
- capacidad
- Nuestra Empresa
- acelerado
- aceleradores
- Aceptar
- de la máquina
- accesibilidad
- el acceso
- Mi Cuenta
- a través de
- adición
- Adicionales
- direcciones
- administrar
- administrativo
- Ventaja
- Después
- AI
- Todos
- asignación
- permitir
- permite
- también
- Amazon
- Amazon SageMaker
- Amazon Web Services
- América
- cantidades
- an
- y
- cualquier
- Aplicá
- arquitectónico
- somos
- surgir
- artificial
- inteligencia artificial
- Inteligencia Artificial y Aprendizaje Automático
- AS
- Asia
- asia pacifico
- asociado
- At
- Austin
- Confirmación de Viaje
- automáticamente
- disponibilidad
- Hoy Disponibles
- AWS
- fondo
- BE
- se convierte en
- antes
- entre
- miles de millones
- bloqueo
- build
- Construir la
- by
- , que son
- PUEDEN
- capacidades
- capacidad
- Capacidad
- ceo
- Reto
- retos
- Cambios
- comprobar
- Cheques
- Elige
- cliente
- Médico
- código
- Colectivo
- proviene
- Comunicación
- Comunicaciónes
- compañía
- completar
- componentes
- Calcular
- informática
- conferencias
- Configuración
- Configurando
- Contacto
- conexión
- Conexiones
- Consola
- continue
- controlador
- Cost
- costoso
- Precio
- Para crear
- Creamos
- creación
- En la actualidad
- personalizado
- Clientes
- personalizan
- se adaptan
- Cycle
- de ciclos
- página de información de sus operaciones
- datos
- Días
- acuerdo
- Predeterminado
- Grado
- desplegar
- desplegado
- Desplegando
- diseño
- deseado
- detallado
- detalles
- desarrollar
- el desarrollo
- Desarrollo
- una experiencia diferente
- Difusión
- digital
- Interrupción
- distribuidos
- Computación distribuída
- entrenamiento distribuido
- descargar
- dos
- durante
- cada una
- comercio electrónico
- ya sea
- eliminando
- habilitar
- Punto final
- Ingeniería
- garantizar
- Todo
- Entorno
- ambientales
- establecer
- Éter (ETH)
- Europa
- Incluso
- Evento
- Eventos
- ejemplo
- excitado
- costoso
- extra
- Cara
- Fallidos
- falla
- Fracaso
- fallas
- familias
- más rápida
- defectuoso
- Feature
- Caracteristicas
- Archive
- Nombre
- centrado
- seguir
- siguiendo
- antes
- encontrado
- Fundación
- fundador
- Fundador y CEO
- Digital XNUMXk
- Marco conceptual
- Frankfurt
- frecuente
- frecuentemente
- Desde
- ser completados
- completamente
- en general
- generado
- generativo
- IA generativa
- obtener
- GitHub
- objetivo
- va
- gobernado
- concedido
- Grupo procesos
- Grupo
- encargarse de
- Materiales
- Tienen
- es
- he
- cabeza
- al proceso de curación
- Salud
- saludable
- pesado
- levantar objetos pesados
- ayuda
- Alta
- Computación de Alto Rendimiento
- de alto nivel
- Alto rendimiento
- más alto
- altamente
- su
- mantiene
- fortaleza
- Cómo
- Como Hacer
- HPC
- HTML
- http
- HTTPS
- Cientos
- AMI
- ID
- Identidad
- Idle
- if
- imagen
- inmediata
- implementar
- mejorar
- in
- incluir
- incluido
- Incluye
- aumente
- energético
- información
- Sistemas De Información
- EN LA MINA
- entradas
- instalar
- ejemplo
- instancias
- Instrucciones
- COMPLETAMENTE
- Integra
- Intelligence
- interactuar
- interactivo
- Interfaz
- interrumpido
- dentro
- Presentamos
- involucra
- Irlanda
- cuestiones
- IT
- Trabajos
- Empleo
- unión
- jpg
- json
- Justin
- conocido
- Kubernetes
- large
- Gran escala
- Estado latente
- luego
- más reciente
- líder
- APRENDE:
- aprendizaje
- bibliotecas
- Biblioteca
- Licencia
- ciclo de vida
- cirugía estética
- como
- línea
- Linux
- Llama
- local
- log
- Inicie sesión
- Mira
- parece
- no logras
- Baja
- máquina
- máquina de aprendizaje
- mantener
- el mantenimiento de
- para lograr
- HACE
- Realizar
- gestionado
- Management
- sistema de gestión
- gerente
- Mercado
- Máster
- Materia
- Maximizar
- Meta
- minutos
- ML
- Moda
- modelo
- modelos
- Moderno
- Monitorear
- monitoreado
- monitoreo
- meses
- más,
- cuales son las que reflejan
- nombre
- nativo
- Navegación
- ¿ Necesita ayuda
- necesidad
- del sistema,
- Nuevo
- Nuevas características
- nodo
- nodos
- nota
- ahora
- Nvidia
- ocurrir
- of
- Ohio
- on
- On-Demand
- ONE
- habiertos
- de código abierto
- funcionamiento
- operativos.
- optimización
- optimizando
- or
- orquestación
- Oregón
- Oss
- Otro
- nuestros
- salida
- Más de
- Costa
- cristal
- Paralelo
- parámetro
- parámetros
- Pasando (Paso)
- camino
- realizar
- actuación
- Doctor en Filosofía
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- plugin
- Popular
- Publicación
- posible
- Preparar
- anterior
- previamente
- Director de la escuela
- Anterior
- privada
- Proactiva
- proceder
- tratamiento
- Producto
- Progreso
- proyecta
- previsto
- proporciona un
- proporcionando
- DTP
- perseguir
- la cantidad
- RE
- recomendado
- recuperación
- reducir
- remitir
- región
- regiones
- regular
- regularmente
- remove
- reparación
- reemplazar
- reemplazo
- solicita
- pedido
- exigir
- requiere
- la investigación
- la investigación y el desarrollo
- reserva
- Reservar
- resistente
- Recurso
- Recursos
- respuesta
- responsable
- currículum
- Función
- enrutamiento
- reglas
- Ejecutar
- correr
- corre
- sabio
- mismo
- Guardar
- Escala
- la ampliación
- Ciencia:
- Científico
- guión
- guiones
- SDK
- sin costura
- Buscar
- Seattle
- EN LINEA
- ver
- segmento
- mayor
- ayudar
- de coches
- Servicios
- Sesión
- set
- Compartir
- tienes
- mostró
- Del mismo modo
- sencillos
- simplificado
- Singapur
- soltero
- menores
- Software
- Desarrollo de software ad-hoc
- Ingeniería de software
- Soluciones
- Resolver
- Fuente
- Speaker
- especialista
- soluciones y
- especificado
- pasar
- dividido
- Estabilidad
- estable
- estándares de salud
- comienzo
- el estado de la técnica
- Estado
- pasos
- STORAGE
- tienda
- sencillo
- estudios
- enviarlo a consideración
- enviar
- Subido
- subred
- tal
- siguiente
- suite
- RESUMEN
- SOPORTE
- Apoyar
- seguro
- Sydney
- sincronizar
- te
- Todas las funciones a su disposición
- mesa
- ¡Prepárate!
- Técnico
- tener
- terminal
- Texas
- que
- esa
- El
- su
- Les
- luego
- Estas
- ellos
- así
- miles
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- a lo largo de
- equipo
- a
- hoy
- tokenize
- Tokio
- Entrenar
- Formación
- transferir
- tipo
- tipos
- bajo
- universidad
- Universidad de Tokio
- Actualizar
- utilizan el
- usado
- Usuario
- usuarios
- usos
- usando
- utilidad
- Utilizando
- diversos
- Vasto
- versión
- vía
- Ver
- Virginia
- Virtual
- Visite
- tutorial
- fue
- Camino..
- we
- web
- servicios web
- Semanas
- WELL
- cuando
- que
- mientras
- extensamente
- Wikipedia
- seguirá
- dentro de
- sin
- trabajado
- obrero
- se
- Usted
- tú
- zephyrnet