Uno de los patrones de aplicación más útiles para cargas de trabajo de IA generativa es la generación aumentada de recuperación (RAG). En el patrón RAG, encontramos piezas de contenido de referencia relacionadas con un mensaje de entrada mediante la realización de búsquedas de similitud en incrustaciones. Las incrustaciones capturan el contenido de la información en cuerpos de texto, lo que permite que los modelos de procesamiento del lenguaje natural (NLP) trabajen con el lenguaje en forma numérica. Las incrustaciones son solo vectores de números de punto flotante, por lo que podemos analizarlos para ayudar a responder tres preguntas importantes: ¿nuestros datos de referencia cambian con el tiempo? ¿Las preguntas que hacen los usuarios están cambiando con el tiempo? Y, por último, ¿qué tan bien cubren nuestros datos de referencia las preguntas que se formulan?
En esta publicación, conocerá algunas de las consideraciones para el análisis de vectores de incrustación y la detección de señales de deriva de incrustación. Debido a que las incorporaciones son una fuente importante de datos para los modelos de PNL en general y las soluciones de IA generativa en particular, necesitamos una forma de medir si nuestras incorporaciones están cambiando con el tiempo (deriva). En esta publicación, verá un ejemplo de cómo realizar una detección de deriva en vectores integrados utilizando una técnica de agrupamiento con modelos de lenguaje grandes (LLMS) implementados desde JumpStart de Amazon SageMaker. También podrá explorar estos conceptos a través de dos ejemplos proporcionados, incluida una aplicación de muestra de un extremo a otro o, opcionalmente, un subconjunto de la aplicación.
Descripción general de RAG
El patrón de trapo le permite recuperar conocimientos de fuentes externas, como documentos PDF, artículos wiki o transcripciones de llamadas, y luego utilizar ese conocimiento para aumentar las instrucciones enviadas al LLM. Esto permite al LLM hacer referencia a información más relevante al generar una respuesta. Por ejemplo, si le pregunta a un LLM cómo hacer galletas con chispas de chocolate, puede incluir información de su propia biblioteca de recetas. En este patrón, el texto de la receta se convierte en vectores de incrustación utilizando un modelo de incrustación y se almacena en una base de datos de vectores. Las preguntas entrantes se convierten en incrustaciones y luego la base de datos vectorial ejecuta una búsqueda de similitudes para encontrar contenido relacionado. La pregunta y los datos de referencia luego se incluyen en el mensaje del LLM.
Echemos un vistazo más de cerca a los vectores de incrustación que se crean y cómo realizar un análisis de deriva en esos vectores.
Análisis de vectores de incrustación
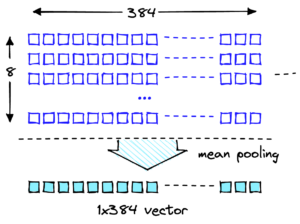
Los vectores de incrustación son representaciones numéricas de nuestros datos, por lo que el análisis de estos vectores puede proporcionar información sobre nuestros datos de referencia que luego pueden usarse para detectar posibles señales de deriva. Los vectores de incrustación representan un elemento en un espacio de n dimensiones, donde n suele ser grande. Por ejemplo, el modelo GPT-J 6B, utilizado en esta publicación, crea vectores de tamaño 4096. Para medir la deriva, supongamos que nuestra aplicación captura vectores de incrustación tanto para los datos de referencia como para las indicaciones entrantes.
Comenzamos realizando una reducción de dimensiones utilizando el Análisis de Componentes Principales (PCA). PCA intenta reducir el número de dimensiones preservando la mayor parte de la variación en los datos. En este caso, intentamos encontrar la cantidad de dimensiones que conservan el 95% de la varianza, lo que debería capturar cualquier cosa dentro de dos desviaciones estándar.
Luego usamos K-Means para identificar un conjunto de centros de conglomerados. K-Means intenta agrupar puntos en grupos de modo que cada grupo sea relativamente compacto y los grupos estén lo más distantes entre sí posible.
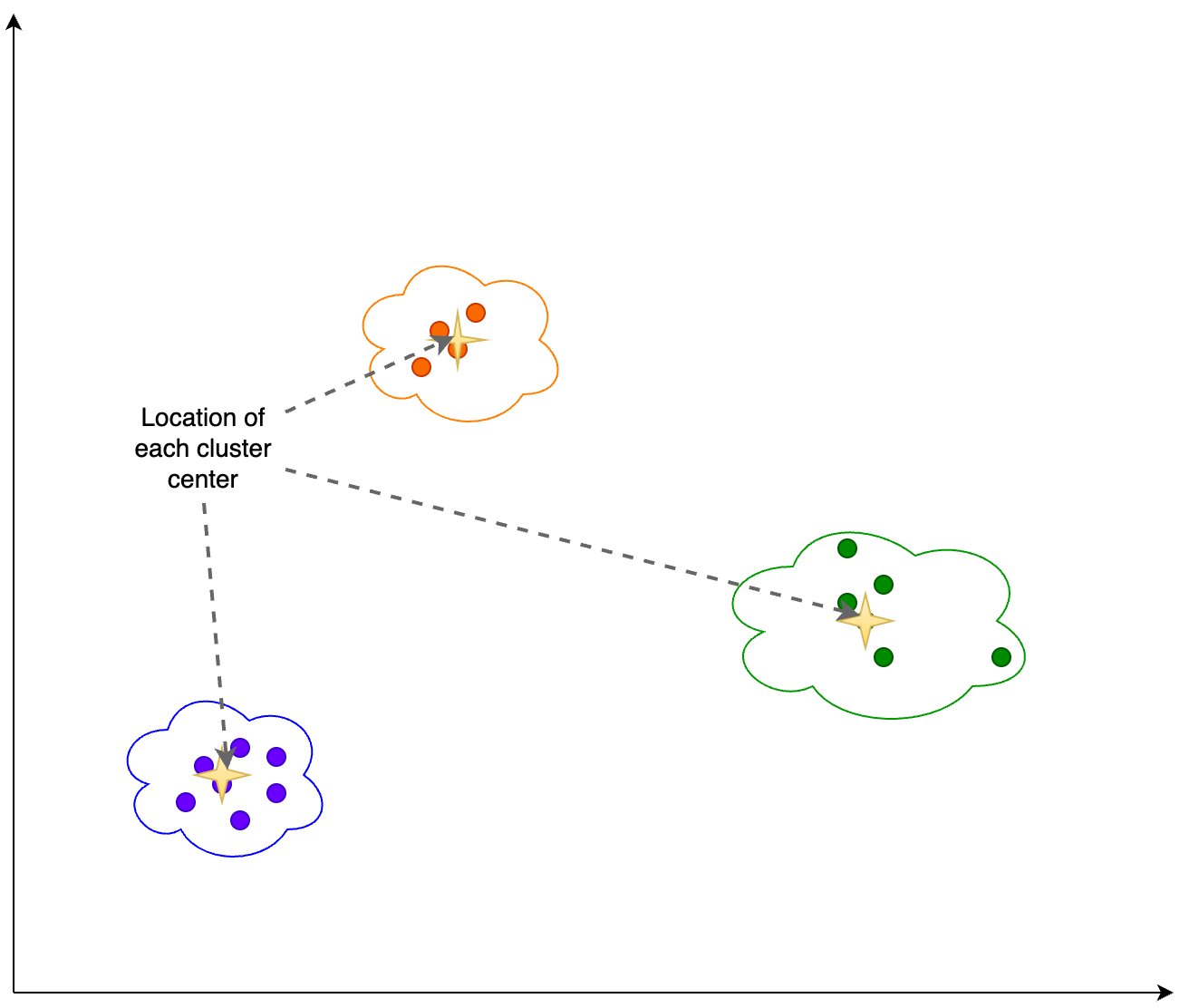
Calculamos la siguiente información en función del resultado de agrupación que se muestra en la siguiente figura:
- El número de dimensiones en PCA que explican el 95% de la varianza.
- La ubicación de cada centro del grupo o centroide.
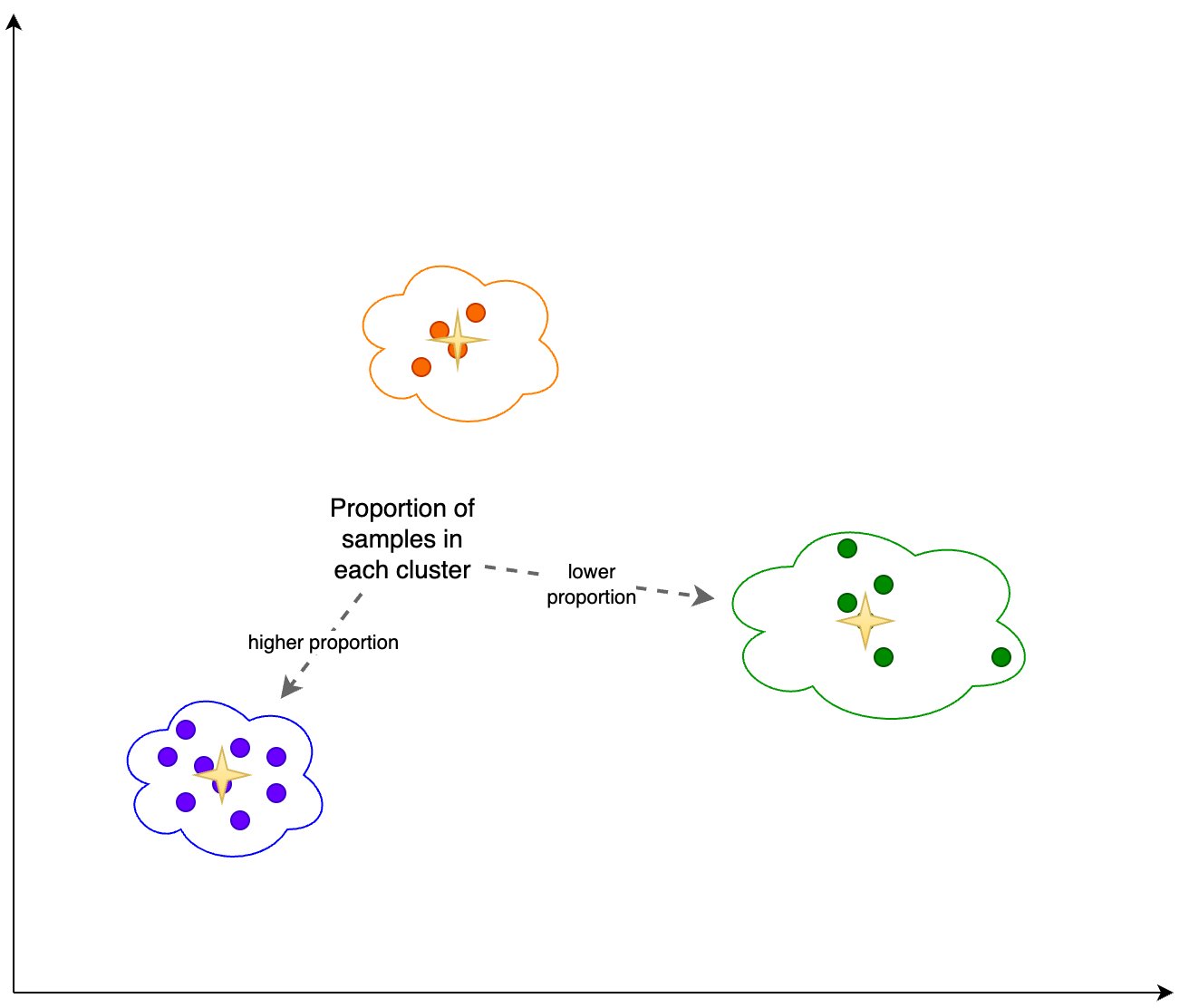
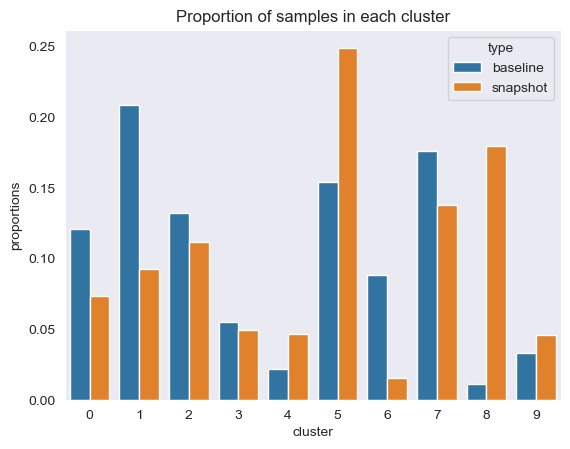
Además, observamos la proporción (mayor o menor) de muestras en cada grupo, como se muestra en la siguiente figura.
Finalmente, utilizamos este análisis para calcular lo siguiente:
- Inercia – La inercia es la suma de las distancias al cuadrado a los centroides del grupo, que mide qué tan bien se agruparon los datos utilizando K-Means.
- Puntuación de silueta – La puntuación de silueta es una medida para la validación de la coherencia dentro de los conglomerados y oscila entre -1 y 1. Un valor cercano a 1 significa que los puntos de un conglomerado están cerca de los demás puntos del mismo conglomerado y lejos del puntos de los otros clusters. En la siguiente figura se puede ver una representación visual de la puntuación de silueta.

Podemos capturar periódicamente esta información para obtener instantáneas de las incrustaciones tanto de los datos de referencia de origen como de las indicaciones. La captura de estos datos nos permite analizar señales potenciales de deriva de incrustación.
Detección de deriva de incrustación
Periódicamente, podemos comparar la información de agrupación a través de instantáneas de los datos, que incluyen las incrustaciones de datos de referencia y las incrustaciones de indicaciones. Primero, podemos comparar la cantidad de dimensiones necesarias para explicar el 95% de la variación en los datos de incrustación, la inercia y la puntuación de silueta del trabajo de agrupación. Como puede ver en la siguiente tabla, en comparación con una línea de base, la última instantánea de incorporaciones requiere 39 dimensiones más para explicar la variación, lo que indica que nuestros datos están más dispersos. La inercia ha aumentado, lo que indica que las muestras están en conjunto más lejos de los centros de sus grupos. Además, la puntuación de la silueta ha disminuido, lo que indica que los grupos no están tan bien definidos. Para datos rápidos, eso podría indicar que los tipos de preguntas que ingresan al sistema cubren más temas.
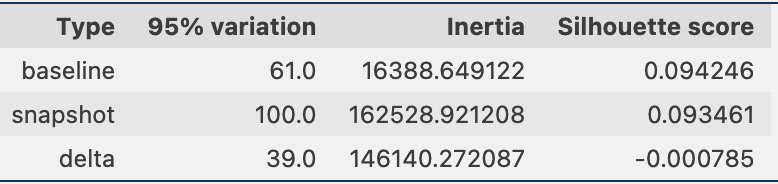
A continuación, en la siguiente figura, podemos ver cómo la proporción de muestras en cada grupo ha cambiado con el tiempo. Esto puede mostrarnos si nuestros datos de referencia más recientes son muy similares al conjunto anterior o cubren nuevas áreas.
Finalmente, podemos ver si los centros de los conglomerados se están moviendo, lo que mostraría una desviación en la información de los conglomerados, como se muestra en la siguiente tabla.

Cobertura de datos de referencia para preguntas entrantes
También podemos evaluar qué tan bien se alinean nuestros datos de referencia con las preguntas entrantes. Para hacer esto, asignamos cada inserción de mensajes a un grupo de datos de referencia. Calculamos la distancia desde cada mensaje hasta su centro correspondiente y observamos la media, la mediana y la desviación estándar de esas distancias. Podemos almacenar esa información y ver cómo cambia con el tiempo.
La siguiente figura muestra un ejemplo de análisis de la distancia entre los centros de datos de referencia y de inserción rápida a lo largo del tiempo.

Como puede ver, las estadísticas de distancia media, mediana y desviación estándar entre las incrustaciones de solicitudes y los centros de datos de referencia están disminuyendo entre la línea de base inicial y la última instantánea. Aunque el valor absoluto de la distancia es difícil de interpretar, podemos utilizar las tendencias para determinar si la superposición semántica entre los datos de referencia y las preguntas entrantes mejora o empeora con el tiempo.
Aplicación de muestra
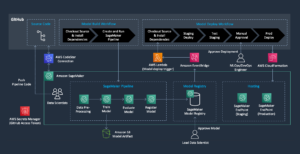
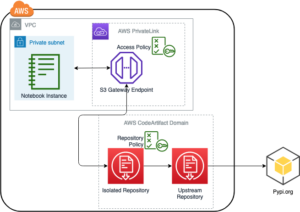
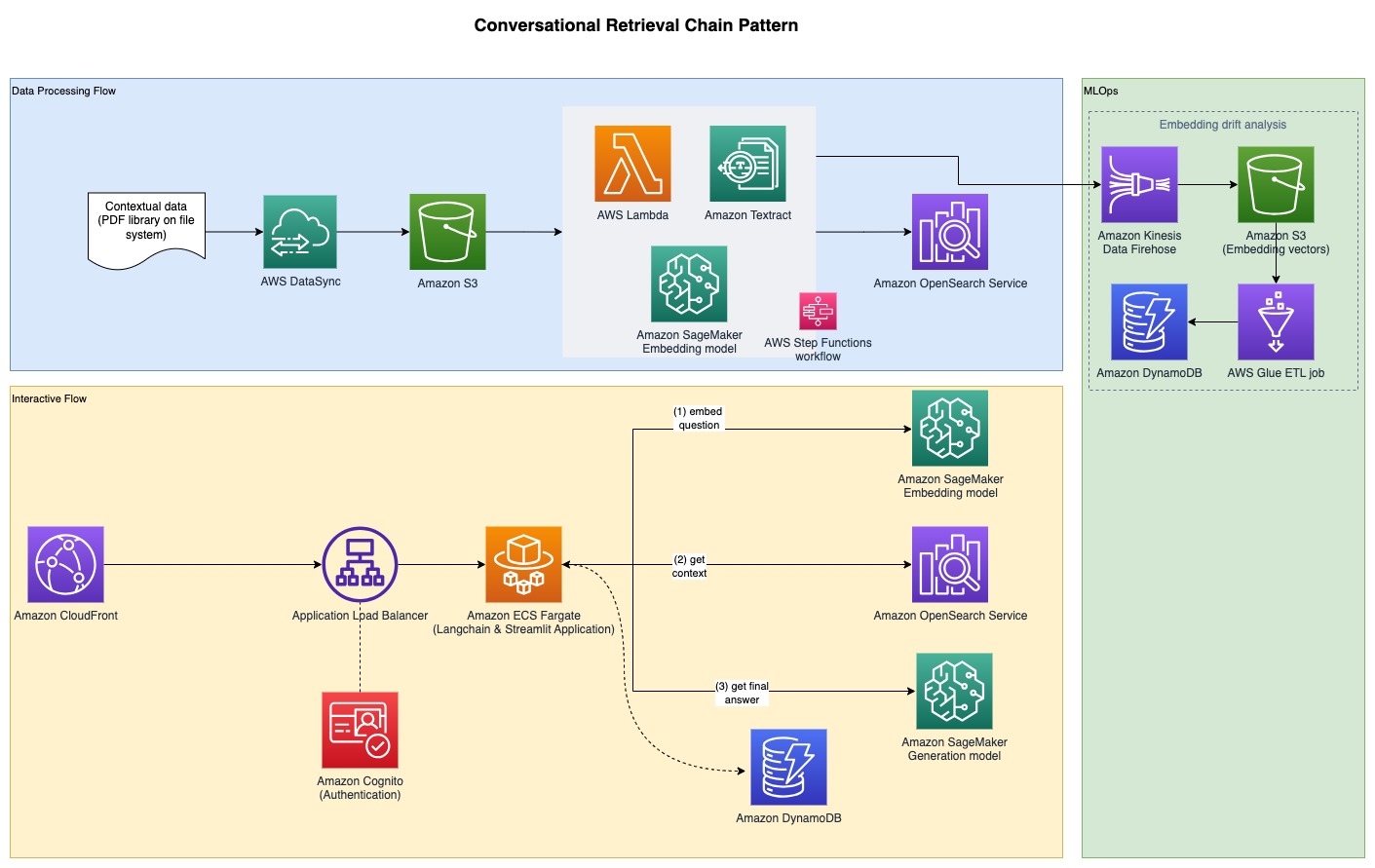
Para recopilar los resultados experimentales discutidos en la sección anterior, creamos una aplicación de muestra que implementa el patrón RAG utilizando modelos de incrustación y generación implementados a través de SageMaker JumpStart y alojados en Amazon SageMaker puntos finales en tiempo real.
La aplicación tiene tres componentes principales:
- Usamos un flujo interactivo, que incluye una interfaz de usuario para capturar indicaciones, combinado con una capa de orquestación RAG, usando LangChain.
- El flujo de procesamiento de datos extrae datos de documentos PDF y crea incrustaciones que se almacenan en Servicio Amazon OpenSearch. También los utilizamos en el componente final de análisis de deriva de incrustación de la aplicación.
- Las incrustaciones se capturan en Servicio de almacenamiento simple de Amazon (Amazon S3) vía Manguera de bomberos de datos de Amazon Kinesis, y ejecutamos una combinación de Pegamento AWS extraiga, transforme y cargue trabajos (ETL) y cuadernos de Jupyter para realizar el análisis de incrustación.
El siguiente diagrama ilustra la arquitectura de un extremo a otro.
El código de muestra completo está disponible en GitHub. El código proporcionado está disponible en dos patrones diferentes:
- Aplicación de muestra completa con una interfaz Streamlit – Esto proporciona una aplicación de un extremo a otro, que incluye una interfaz de usuario que utiliza Streamlit para capturar indicaciones, combinada con la capa de orquestación RAG, utilizando LangChain ejecutándose en Servicio de contenedor elástico de Amazon (Amazon ECS) con AWS Fargate
- Aplicación backend – Para aquellos que no desean implementar la pila de aplicaciones completa, pueden optar por implementar solo el backend. Kit de desarrollo en la nube de AWS (AWS CDK) y luego use el cuaderno Jupyter proporcionado para realizar la orquestación RAG usando LangChain
Para crear los patrones proporcionados, existen varios requisitos previos que se detallan en las siguientes secciones, comenzando con la implementación de los modelos generativo y de incrustación de texto y luego pasando a los requisitos previos adicionales.
Implementar modelos a través de SageMaker JumpStart
Ambos patrones suponen el despliegue de un modelo de integración y un modelo generativo. Para ello, implementará dos modelos de SageMaker JumpStart. El primer modelo, GPT-J 6B, se utiliza como modelo de incrustación y el segundo modelo, Falcon-40b, se utiliza para la generación de texto.
Puede implementar cada uno de estos modelos a través de SageMaker JumpStart desde la Consola de administración de AWS, Estudio Amazon SageMaker, o programáticamente. Para obtener más información, consulte Cómo utilizar los modelos de cimentación JumpStart. Para simplificar la implementación, puede utilizar el cuaderno proporcionado derivados de cuadernos creados automáticamente por SageMaker JumpStart. Este cuaderno extrae los modelos del centro JumpStart ML de SageMaker y los implementa en dos puntos finales separados en tiempo real de SageMaker.
El cuaderno de muestra también tiene una sección de limpieza. No ejecute esa sección todavía, porque eliminará los puntos finales que acaba de implementar. Completará la limpieza al final del tutorial.
Después de confirmar la implementación exitosa de los puntos finales, estará listo para implementar la aplicación de muestra completa. Sin embargo, si está más interesado en explorar solo los cuadernos de backend y análisis, opcionalmente puede implementar solo eso, lo cual se trata en la siguiente sección.
Opción 1: implementar solo la aplicación backend
Este patrón le permite implementar la solución backend únicamente e interactuar con la solución mediante un cuaderno Jupyter. Utilice este patrón si no desea crear la interfaz frontal completa.
Requisitos previos
Debe tener los siguientes requisitos previos:
- Implementación de un punto final del modelo SageMaker JumpStart – Implementar los modelos en puntos finales en tiempo real de SageMaker utilizando SageMaker JumpStart, como se describió anteriormente
- Parámetros de implementación – Registre lo siguiente:
- Nombre del punto final del modelo de texto – El nombre del punto final del modelo de generación de texto implementado con SageMaker JumpStart.
- Nombre del punto final del modelo de incrustaciones – El nombre del punto final del modelo de incorporación implementado con SageMaker JumpStart
Implemente los recursos utilizando AWS CDK
Utilice los parámetros de implementación indicados en la sección anterior para implementar la pila de AWS CDK. Para obtener más información sobre la instalación de AWS CDK, consulte Introducción a AWS CDK.
Asegúrese de que Docker esté instalado y ejecutándose en la estación de trabajo que se utilizará para la implementación de AWS CDK. Referirse a Obtener ventana acoplable para una guía adicional.
Alternativamente, puede ingresar los valores de contexto en un archivo llamado cdk.context.json existentes pattern1-rag/cdk directorio y ejecutar cdk deploy BackendStack --exclusively.
La implementación imprimirá resultados, algunos de los cuales serán necesarios para ejecutar el portátil. Antes de que pueda comenzar a hacer preguntas y respuestas, incruste los documentos de referencia, como se muestra en la siguiente sección.
Insertar documentos de referencia
Para este enfoque RAG, los documentos de referencia primero se incrustan con un modelo de incrustación de texto y se almacenan en una base de datos vectorial. En esta solución, se ha creado un canal de ingesta que incorpora documentos PDF.
An Nube informática elástica de Amazon (Amazon EC2) se ha creado para la ingesta de documentos PDF y se ha creado una Sistema de archivos elástico de Amazon El sistema de archivos (Amazon EFS) está montado en la instancia EC2 para guardar los documentos PDF. Un Sincronización de datos de AWS La tarea se ejecuta cada hora para recuperar los documentos PDF que se encuentran en la ruta del sistema de archivos EFS y cargarlos en un depósito S3 para iniciar el proceso de incrustación de texto. Este proceso incorpora los documentos de referencia y guarda las incorporaciones en OpenSearch Service. También guarda un archivo integrado en un depósito de S3 a través de Kinesis Data Firehose para su posterior análisis.
Para ingerir los documentos de referencia, complete los siguientes pasos:
- Recupere el ID de instancia EC2 de muestra que se creó (consulte la salida de AWS CDK
JumpHostId) y conéctese usando Gestor de sesiones, una capacidad de Gerente de sistemas de AWS. Para obtener instrucciones, consulte Conéctese a su instancia de Linux con AWS Systems Manager Session Manager. - Ir al directorio
/mnt/efs/fs1, que es donde está montado el sistema de archivos EFS, y cree una carpeta llamadaingest: - Agregue sus documentos PDF de referencia al
ingestdirectorio.
La tarea DataSync está configurada para cargar todos los archivos que se encuentran en este directorio en Amazon S3 para iniciar el proceso de incrustación.
La tarea DataSync se ejecuta según un cronograma por horas; Opcionalmente, puede iniciar la tarea manualmente para iniciar el proceso de incrustación inmediatamente para los documentos PDF que agregó.
- Para iniciar la tarea, busque el ID de la tarea en la salida de AWS CDK
DataSyncTaskIDy comenzar la tarea con valores predeterminados.
Una vez creadas las incrustaciones, puede iniciar la pregunta RAG y responder a través de un cuaderno Jupyter, como se muestra en la siguiente sección.
Preguntas y respuestas usando un cuaderno Jupyter
Complete los siguientes pasos:
- Recupere el nombre de la instancia del cuaderno de SageMaker de la salida de AWS CDK
NotebookInstanceNamey conéctese a JupyterLab desde la consola de SageMaker. - Ir al directorio
fmops/full-stack/pattern1-rag/notebooks/. - Abra y ejecute el cuaderno.
query-llm.ipynben la instancia del cuaderno para realizar preguntas y respuestas usando RAG.
Asegúrese de usar el conda_python3 núcleo para el cuaderno.
Este patrón es útil para explorar la solución backend sin necesidad de aprovisionar requisitos previos adicionales necesarios para la aplicación de pila completa. La siguiente sección cubre la implementación de una aplicación de pila completa, incluidos los componentes frontend y backend, para proporcionar una interfaz de usuario para interactuar con su aplicación de IA generativa.
Opción 2: implementar la aplicación de muestra de pila completa con una interfaz Streamlit
Este patrón le permite implementar la solución con una interfaz de usuario para preguntas y respuestas.
Requisitos previos
Para implementar la aplicación de ejemplo, debe tener los siguientes requisitos previos:
- Implementación del punto final del modelo SageMaker JumpStart – Implemente los modelos en sus terminales en tiempo real de SageMaker utilizando SageMaker JumpStart, como se describe en la sección anterior, utilizando los cuadernos proporcionados.
- Zona alojada de la Ruta 53 del Amazonas - Crear un Ruta del Amazonas 53 zona hospedada pública utilizar para esta solución. También puede utilizar una zona alojada pública de Route 53 existente, como
example.com. - Certificado de AWS Certificate Manager – Proporcionar un Administrador de certificados de AWS (ACM) Certificado TLS para el nombre de dominio de la zona alojada de Route 53 y sus subdominios aplicables, como
example.comy*.example.compara todos los subdominios. Para obtener instrucciones, consulte Solicitar un certificado público. Este certificado se utiliza para configurar HTTPS en Amazon CloudFront y el balanceador de carga de origen. - Parámetros de implementación – Registre lo siguiente:
- Nombre de dominio personalizado de la aplicación frontend – Un nombre de dominio personalizado utilizado para acceder a la aplicación de muestra de interfaz. El nombre de dominio proporcionado se utiliza para crear un registro DNS de Route 53 que apunta a la distribución frontend de CloudFront; Por ejemplo,
app.example.com. - Nombre de dominio personalizado de origen del balanceador de carga – Un nombre de dominio personalizado utilizado para el origen del balanceador de carga de distribución de CloudFront. El nombre de dominio proporcionado se utiliza para crear un registro DNS de Ruta 53 que apunta al equilibrador de carga de origen; Por ejemplo,
app-lb.example.com. - ID de zona alojada de Route 53 – El ID de la zona alojada de Route 53 para alojar los nombres de dominio personalizados proporcionados; Por ejemplo,
ZXXXXXXXXYYYYYYYYY. - Nombre de la zona alojada de Route 53 – El nombre de la zona alojada de Route 53 para alojar los nombres de dominio personalizados proporcionados; Por ejemplo,
example.com. - ARN del certificado ACM – El ARN del certificado ACM que se utilizará con el dominio personalizado proporcionado.
- Nombre del punto final del modelo de texto – El nombre del punto final del modelo de generación de texto implementado con SageMaker JumpStart.
- Nombre del punto final del modelo de incrustaciones – El nombre del punto final del modelo de incorporación implementado con SageMaker JumpStart.
- Nombre de dominio personalizado de la aplicación frontend – Un nombre de dominio personalizado utilizado para acceder a la aplicación de muestra de interfaz. El nombre de dominio proporcionado se utiliza para crear un registro DNS de Route 53 que apunta a la distribución frontend de CloudFront; Por ejemplo,
Implemente los recursos utilizando AWS CDK
Utilice los parámetros de implementación que anotó en los requisitos previos para implementar la pila de AWS CDK. Para obtener más información, consulte Introducción a AWS CDK.
Asegúrese de que Docker esté instalado y ejecutándose en la estación de trabajo que se utilizará para la implementación de AWS CDK.
En el código anterior, -c representa un valor de contexto, en forma de requisitos previos requeridos, proporcionado en la entrada. Alternativamente, puede ingresar los valores de contexto en un archivo llamado cdk.context.json existentes pattern1-rag/cdk directorio y ejecutar cdk deploy --all.
Tenga en cuenta que especificamos la Región en el archivo bin/cdk.ts. La configuración de los registros de acceso de ALB requiere una región específica. Puede cambiar esta región antes de la implementación.
La implementación imprimirá la URL para acceder a la aplicación Streamlit. Antes de poder comenzar a hacer preguntas y respuestas, debe incorporar los documentos de referencia, como se muestra en la siguiente sección.
Incrustar los documentos de referencia.
Para un enfoque RAG, los documentos de referencia primero se incrustan con un modelo de incrustación de texto y se almacenan en una base de datos vectorial. En esta solución, se ha creado un canal de ingesta que incorpora documentos PDF.
Como comentamos en la primera opción de implementación, se creó una instancia EC2 de ejemplo para la ingesta de documentos PDF y se montó un sistema de archivos EFS en la instancia EC2 para guardar los documentos PDF. Se ejecuta una tarea de DataSync cada hora para recuperar los documentos PDF que se encuentran en la ruta del sistema de archivos EFS y cargarlos en un depósito S3 para iniciar el proceso de incrustación de texto. Este proceso incorpora los documentos de referencia y guarda las incorporaciones en OpenSearch Service. También guarda un archivo integrado en un depósito de S3 a través de Kinesis Data Firehose para su posterior análisis.
Para ingerir los documentos de referencia, complete los siguientes pasos:
- Recupere el ID de instancia EC2 de muestra que se creó (consulte la salida de AWS CDK
JumpHostId) y conéctese usando el Administrador de sesión. - Ir al directorio
/mnt/efs/fs1, que es donde está montado el sistema de archivos EFS, y cree una carpeta llamadaingest: - Agregue sus documentos PDF de referencia al
ingestdirectorio.
La tarea DataSync está configurada para cargar todos los archivos que se encuentran en este directorio en Amazon S3 para iniciar el proceso de incrustación.
La tarea DataSync se ejecuta según un cronograma por horas. Opcionalmente, puede iniciar la tarea manualmente para iniciar el proceso de incrustación inmediatamente para los documentos PDF que agregó.
- Para iniciar la tarea, busque el ID de la tarea en la salida de AWS CDK
DataSyncTaskIDy comenzar la tarea con valores predeterminados.
Pregunta y respuesta
Una vez integrados los documentos de referencia, puede iniciar la pregunta y respuesta de RAG visitando la URL para acceder a la aplicación Streamlit. Un Cognito Amazonas Se utiliza la capa de autenticación, por lo que requiere la creación de una cuenta de usuario en el grupo de usuarios de Amazon Cognito implementado a través de AWS CDK (consulte la salida de AWS CDK para conocer el nombre del grupo de usuarios) para acceder por primera vez a la aplicación. Para obtener instrucciones sobre cómo crear un usuario de Amazon Cognito, consulte Creación de un nuevo usuario en la Consola de administración de AWS.
Incrustar análisis de deriva
En esta sección, le mostramos cómo realizar un análisis de deriva creando primero una línea base de las incorporaciones de datos de referencia y las incorporaciones de indicaciones, y luego creando una instantánea de las incorporaciones a lo largo del tiempo. Esto le permite comparar las incrustaciones de referencia con las incrustaciones de instantáneas.
Cree una línea base de incrustación para los datos de referencia y solicite
Para crear una línea base de incorporación de los datos de referencia, abra la consola de AWS Glue y seleccione el trabajo ETL. embedding-drift-analysis. Configure los parámetros para el trabajo ETL de la siguiente manera y ejecute el trabajo:
- Set
--job_typeaBASELINE. - Set
--out_tableEn el correo electrónico “Su Cuenta de Usuario en su Nuevo Sistema XNUMXCX”. Amazon DynamoDB tabla para datos de incrustación de referencia. (Consulte la salida de AWS CDKDriftTableReferencepara el nombre de la tabla.) - Set
--centroid_tablea la tabla de DynamoDB para obtener datos del centroide de referencia. (Consulte la salida de AWS CDKCentroidTableReferencepara el nombre de la tabla.) - Set
--data_pathal depósito S3 con el prefijo; Por ejemplo,s3:///embeddingarchive/. (Consulte la salida de AWS CDKBucketNamepara el nombre del depósito.)
De manera similar, usando el trabajo ETL embedding-drift-analysis, cree una línea base de incorporación de las indicaciones. Configure los parámetros para el trabajo ETL de la siguiente manera y ejecute el trabajo:
- Set
--job_typeaBASELINE - Set
--out_tablea la tabla de DynamoDB para incrustar datos rápidamente. (Consulte la salida de AWS CDKDriftTablePromptsNamepara el nombre de la tabla.) - Set
--centroid_tablea la tabla de DynamoDB para obtener datos del centroide rápidos. (Consulte la salida de AWS CDKCentroidTablePromptspara el nombre de la tabla.) - Set
--data_pathal depósito S3 con el prefijo; Por ejemplo,s3:///promptarchive/. (Consulte la salida de AWS CDKBucketNamepara el nombre del depósito.)
Cree una instantánea de incrustación para los datos de referencia y solicite
Después de ingerir información adicional en OpenSearch Service, ejecute el trabajo ETL embedding-drift-analysis nuevamente para tomar una instantánea de las incrustaciones de datos de referencia. Los parámetros serán los mismos que los del trabajo ETL que ejecutó para crear la línea base de incrustación de los datos de referencia como se muestra en la sección anterior, con la excepción de configurar el --job_type parámetro para SNAPSHOT.
De manera similar, para tomar una instantánea de las incrustaciones de mensajes, ejecute el trabajo ETL embedding-drift-analysis de nuevo. Los parámetros serán los mismos que los del trabajo ETL que ejecutó para crear la línea base de incorporación para las indicaciones como se muestra en la sección anterior, con la excepción de configurar el --job_type parámetro para SNAPSHOT.
Comparar la línea de base con la instantánea
Para comparar la línea base de incorporación y la instantánea para obtener datos de referencia e indicaciones, use el cuaderno proporcionado pattern1-rag/notebooks/drift-analysis.ipynb.
Para ver la comparación de inserción de datos de referencia o solicitudes, cambie las variables de nombre de la tabla de DynamoDB (tbl y c_tbl) en el cuaderno a la tabla de DynamoDB adecuada para cada ejecución del cuaderno.
La variable del cuaderno tbl debe cambiarse al nombre de tabla de deriva apropiado. El siguiente es un ejemplo de dónde configurar la variable en el cuaderno.

Los nombres de las tablas se pueden recuperar de la siguiente manera:
- Para los datos de inserción de referencia, recupere el nombre de la tabla de deriva de la salida de AWS CDK
DriftTableReference - Para el mensaje de incorporación de datos, recupere el nombre de la tabla de deriva de la salida de AWS CDK
DriftTablePromptsName
Además, la variable del cuaderno c_tbl debe cambiarse al nombre de la tabla de centroide apropiado. El siguiente es un ejemplo de dónde configurar la variable en el cuaderno.

Los nombres de las tablas se pueden recuperar de la siguiente manera:
- Para los datos de inserción de referencia, recupere el nombre de la tabla de centroides de la salida de AWS CDK
CentroidTableReference - Para el mensaje de incorporación de datos, recupere el nombre de la tabla de centroides de la salida de AWS CDK
CentroidTablePrompts
Analizar la distancia inmediata desde los datos de referencia.
Primero, ejecute el trabajo de AWS Glue embedding-distance-analysis. Este trabajo descubrirá a qué grupo, a partir de la evaluación K-Means de las incrustaciones de datos de referencia, pertenece cada mensaje. Luego calcula la media, la mediana y la desviación estándar de la distancia desde cada mensaje hasta el centro del grupo correspondiente.
Puedes ejecutar el cuaderno. pattern1-rag/notebooks/distance-analysis.ipynb para ver las tendencias en las métricas de distancia a lo largo del tiempo. Esto le dará una idea de la tendencia general en la distribución de las distancias de incrustación rápidas.
El cuaderno pattern1-rag/notebooks/prompt-distance-outliers.ipynb es un cuaderno de AWS Glue que busca valores atípicos, lo que puede ayudarle a identificar si recibe más mensajes que no están relacionados con los datos de referencia.
Monitorear puntuaciones de similitud
Todas las puntuaciones de similitud del servicio OpenSearch están registradas Reloj en la nube de Amazon bajo el rag espacio de nombres. El tablero RAG_Scores muestra la puntuación media y el número total de puntuaciones ingeridas.
Limpiar
Para evitar incurrir en cargos futuros, elimine todos los recursos que creó.
Eliminar los modelos de SageMaker implementados
Consulte la sección de limpieza del cuaderno de ejemplo proporcionado para eliminar los modelos SageMaker JumpStart implementados, o puede eliminar los modelos en la consola de SageMaker.
Eliminar los recursos de AWS CDK
Si ingresó sus parámetros en un cdk.context.json archivo, limpie de la siguiente manera:
Si ingresó sus parámetros en la línea de comando y solo implementó la aplicación de backend (la pila de AWS CDK de backend), limpie de la siguiente manera:
Si ingresó sus parámetros en la línea de comando e implementó la solución completa (las pilas de AWS CDK de frontend y backend), limpie de la siguiente manera:
Conclusión
En esta publicación, proporcionamos un ejemplo funcional de una aplicación que captura vectores de incrustación tanto para datos de referencia como para indicaciones en el patrón RAG para IA generativa. Mostramos cómo realizar un análisis de agrupamiento para determinar si los datos de referencia o de indicaciones varían con el tiempo y qué tan bien los datos de referencia cubren los tipos de preguntas que hacen los usuarios. Si detecta una desviación, puede proporcionar una señal de que el entorno ha cambiado y su modelo está recibiendo nuevas entradas que tal vez no esté optimizado para manejar. Esto permite una evaluación proactiva del modelo actual frente a entradas cambiantes.
Acerca de los autores
 Abdullahi Olaoye es arquitecto senior de soluciones en Amazon Web Services (AWS). Abdullahi tiene una maestría en redes informáticas de la Universidad Estatal de Wichita y es un autor publicado que ha desempeñado funciones en diversos dominios tecnológicos, como DevOps, modernización de infraestructura e inteligencia artificial. Actualmente se centra en la IA generativa y desempeña un papel clave en ayudar a las empresas a diseñar y crear soluciones de vanguardia impulsadas por la IA generativa. Más allá del ámbito de la tecnología, encuentra alegría en el arte de la exploración. Cuando no está creando soluciones de inteligencia artificial, le gusta viajar con su familia para explorar nuevos lugares.
Abdullahi Olaoye es arquitecto senior de soluciones en Amazon Web Services (AWS). Abdullahi tiene una maestría en redes informáticas de la Universidad Estatal de Wichita y es un autor publicado que ha desempeñado funciones en diversos dominios tecnológicos, como DevOps, modernización de infraestructura e inteligencia artificial. Actualmente se centra en la IA generativa y desempeña un papel clave en ayudar a las empresas a diseñar y crear soluciones de vanguardia impulsadas por la IA generativa. Más allá del ámbito de la tecnología, encuentra alegría en el arte de la exploración. Cuando no está creando soluciones de inteligencia artificial, le gusta viajar con su familia para explorar nuevos lugares.
 Randy DeFauw es un Arquitecto Principal Principal de Soluciones en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión artificial para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el espacio tecnológico, desde ingeniería de software hasta gestión de productos. En ingresó al espacio Big Data en 2013 y continúa explorando esa área. Está trabajando activamente en proyectos en el espacio ML y se ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
Randy DeFauw es un Arquitecto Principal Principal de Soluciones en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión artificial para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el espacio tecnológico, desde ingeniería de software hasta gestión de productos. En ingresó al espacio Big Data en 2013 y continúa explorando esa área. Está trabajando activamente en proyectos en el espacio ML y se ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
 Shelbee Eigen Brode es Arquitecto Principal de Soluciones Especializado en Inteligencia Artificial y Aprendizaje Automático en Amazon Web Services (AWS). Ha estado en tecnología durante 24 años, abarcando múltiples industrias, tecnologías y funciones. Actualmente se está enfocando en combinar su experiencia en DevOps y ML en el dominio de MLOps para ayudar a los clientes a entregar y administrar cargas de trabajo de ML a escala. Con más de 35 patentes otorgadas en varios dominios tecnológicos, le apasiona la innovación continua y el uso de datos para impulsar los resultados comerciales. Shelbee es cocreadora e instructora de la especialización en Ciencias prácticas de datos en Coursera. También es codirectora de Women In Big Data (WiBD), capítulo de Denver. En su tiempo libre, le gusta pasar tiempo con su familia, amigos y perros hiperactivos.
Shelbee Eigen Brode es Arquitecto Principal de Soluciones Especializado en Inteligencia Artificial y Aprendizaje Automático en Amazon Web Services (AWS). Ha estado en tecnología durante 24 años, abarcando múltiples industrias, tecnologías y funciones. Actualmente se está enfocando en combinar su experiencia en DevOps y ML en el dominio de MLOps para ayudar a los clientes a entregar y administrar cargas de trabajo de ML a escala. Con más de 35 patentes otorgadas en varios dominios tecnológicos, le apasiona la innovación continua y el uso de datos para impulsar los resultados comerciales. Shelbee es cocreadora e instructora de la especialización en Ciencias prácticas de datos en Coursera. También es codirectora de Women In Big Data (WiBD), capítulo de Denver. En su tiempo libre, le gusta pasar tiempo con su familia, amigos y perros hiperactivos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/monitor-embedding-drift-for-llms-deployed-from-amazon-sagemaker-jumpstart/
- :posee
- :es
- :no
- :dónde
- $ UP
- 1
- 10
- 100
- 2%
- 2013
- 24
- 35%
- 39
- 4
- 53
- 62
- 7
- 9
- 90
- 95%
- a
- Poder
- Nuestra Empresa
- Absoluto
- de la máquina
- Mi Cuenta
- ACM
- a través de
- activamente
- adicional
- adición
- Adicionales
- Información adicional
- Adicionalmente
- de nuevo
- en contra
- agregar
- AI
- Alinea
- Todos
- Permitir
- permite
- también
- Aunque
- Amazon
- Cognito Amazonas
- Amazon EC2
- Amazon SageMaker
- JumpStart de Amazon SageMaker
- Amazon Web Services
- Servicios Web de Amazon (AWS)
- an
- análisis
- analizar
- el análisis de
- y
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- responder
- cualquier cosa
- aplicable
- Aplicación
- enfoque
- adecuado
- arquitectura
- Archive
- somos
- Reservada
- áreas
- Arte
- AS
- contacta
- pidiendo
- ayudando
- asumir
- At
- aumentar
- aumentado
- Autenticación
- autor
- automáticamente
- autónomo
- vehículos autónomos
- Hoy Disponibles
- promedio
- evitar
- lejos
- AWS
- Pegamento AWS
- Backend
- fondo
- equilibrador
- basado
- Base
- BE
- porque
- esto
- antes
- "Ser"
- pertenece
- mejores
- entre
- Más allá de
- Big
- Big Data
- cuerpos
- ambas
- en general
- build
- construido
- by
- calcular
- calcula
- llamar al
- , que son
- PUEDEN
- capacidad
- capturar
- capturado
- capturas
- Capturando
- case
- CD
- Reubicación
- Centros
- certificado
- el cambio
- cambiado
- Cambios
- cambio
- Capítulo
- cargos
- chip
- Chocolate
- Elige
- limpia
- Cerrar
- más cerca
- Soluciones
- Médico
- clustering
- código
- Colorado
- combinación
- combinado
- combinar
- viniendo
- compacto
- comparar
- en comparación con
- comparación
- completar
- componente
- componentes
- Calcular
- computadora
- Visión por computador
- conceptos
- conferencias
- configurado
- Configurando
- Contacto
- consideraciones
- consistencia
- Consola
- Envase
- contenido
- contexto
- continúa
- continuo
- convertido
- galletas
- Core
- Correspondiente
- Coursera
- cobertura
- cubierto
- cubierta
- cubre suministros para
- Para crear
- creado
- crea
- Creamos
- Current
- En la actualidad
- personalizado
- Clientes
- innovador
- página de información de sus operaciones
- datos
- los centros de datos
- proceso de datos
- Ciencia de los datos
- Base de datos
- decreciente
- por defecto
- se define
- borrar
- entregamos
- Denver
- desplegar
- desplegado
- Desplegando
- despliegue
- despliega
- Derivado
- destruir
- detallado
- detectar
- Detección
- Determinar
- Desarrollo
- desviación
- DevOps
- diagrama
- una experiencia diferente
- difícil
- Dimensiones
- dimensiones
- discutido
- disperso
- distancia
- Distante
- dns
- do
- Docker
- documento
- documentos
- Perros
- dominio
- Nombre de dominio
- NOMBRES DE DOMINIO
- dominios
- No
- DE INSCRIPCIÓN
- el lado de la transmisión
- cada una
- incrustar
- integrado
- incrustación
- final
- de extremo a extremo
- Punto final
- criterios de valoración
- Ingeniería
- Participar
- entrado
- empresas
- Entorno
- Éter (ETH)
- evaluar
- evaluación
- Cada
- ejemplo
- ejemplos
- excepción
- existente
- experimental
- Explicar
- exploración
- explorar
- Explorar
- externo
- extraerlos
- Extractos
- familia
- muchos
- Figura
- Archive
- archivos
- final
- Finalmente
- Encuentre
- encuentra
- Nombre
- flotante
- de tus señales
- centrado
- enfoque
- siguiendo
- siguiente
- formulario
- encontrado
- Fundación
- amigos
- Desde
- Frontend
- ser completados
- futuras
- reunir
- General
- la generación de
- generación de AHSS
- generativo
- IA generativa
- modelo generativo
- obtener
- conseguir
- Donar
- Go
- pasado
- concedido
- Grupo procesos
- guía
- encargarse de
- Tienen
- he
- Retenida
- ayuda
- aquí
- más alto
- su
- mantiene
- fortaleza
- organizado
- horas.
- Cómo
- Como Hacer
- Sin embargo
- HTML
- http
- HTTPS
- Bujes
- ID
- Identifique
- if
- ilustra
- inmediatamente
- implementación
- implementos
- importante
- in
- incluir
- incluye
- Incluye
- Entrante
- indicar
- indicando
- industrias
- inercia
- información
- EN LA MINA
- inicial
- Innovation
- Las opciones de entrada
- entradas
- penetración
- instalación
- ejemplo
- Instrucciones
- interactuar
- interactuando
- interactivo
- interesado
- Interfaz
- dentro
- IT
- SUS
- Trabajos
- Empleo
- alegría
- jpg
- Cuaderno Jupyter
- solo
- Clave
- Manguera de incendios de datos de Kinesis
- especialistas
- idioma
- large
- luego
- más reciente
- .
- APRENDE:
- aprendizaje
- Permíteme
- Biblioteca
- Me gusta
- línea
- Linux
- llm
- carga
- Ubicación
- conectado
- Mira
- MIRADAS
- inferior
- máquina
- máquina de aprendizaje
- para lograr
- gestionan
- Management
- gerente
- a mano
- Puede..
- MBA
- personalizado
- significa
- medir
- medidas
- Métrica
- Michigan
- podría
- ML
- MLOps
- modelo
- modelos
- modernización
- Monitorear
- más,
- MEJOR DE TU
- emocionante
- múltiples
- debe
- nombre
- nombres
- Natural
- Lenguaje natural
- Procesamiento natural del lenguaje
- ¿ Necesita ayuda
- necesidad
- red
- Nuevo
- más nuevo
- Next
- nlp
- cuaderno
- ordenadores portátiles
- señaló
- número
- números
- numeroso
- of
- a menudo
- on
- , solamente
- habiertos
- optimizado
- Optión
- or
- orquestación
- solicite
- Natural
- Otro
- nuestros
- salir
- resultados
- esbozado
- salida
- salidas
- Más de
- total
- superposición
- EL DESARROLLADOR
- parámetro
- parámetros
- particular
- pasión
- Okeanos
- camino
- Patrón de Costura
- .
- (PDF)
- realizar
- realizar
- piezas
- industrial
- Lugares
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- juega
- punto
- puntos
- alberca
- abiertas
- posible
- Publicación
- posible
- alimentado
- Metodología
- anterior
- requisitos previos
- presentó
- conservas
- conservación
- anterior
- previamente
- Director de la escuela
- Imprimir
- Proactiva
- tratamiento
- Producto
- gestión de producto
- proyecta
- ideas
- proporción
- proporcionar
- previsto
- proporciona un
- provisión
- público
- publicado
- Tira
- pregunta
- Preguntas
- trapo
- rangos
- que van
- ready
- en tiempo real
- reino
- recetas
- grabar
- reducir
- reducción
- remitir
- referencia
- región
- relacionado
- relativamente
- representar
- representación
- representa
- Requisitos
- requiere
- Recursos
- respuesta
- Resultados
- recuperación
- Función
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- Ruta
- Ejecutar
- correr
- corre
- sabio
- mismo
- Guardar
- Escala
- programa
- Ciencia:
- Puntuación
- puntuaciones
- Buscar
- Búsquedas
- Segundo
- Sección
- (secciones)
- ver
- visto
- selecciona
- semántico
- mayor
- sentido
- expedido
- separado
- de coches
- Servicios
- Sesión
- set
- pólipo
- Varios
- ella
- tienes
- Mostrar
- mostró
- mostrado
- Shows
- Signal
- señales
- similares
- sencillos
- simplificar
- Tamaño
- Instantánea
- So
- Software
- Ingeniería de software
- a medida
- Soluciones
- algo
- Fuente
- Fuentes
- Espacio
- abarcando
- especialista
- especificado
- pasar
- Squared
- montón
- Stacks
- estándar
- comienzo
- fundó
- Comience a
- Estado
- statistics
- pasos
- STORAGE
- tienda
- almacenados
- exitosos
- tal
- suma
- seguro
- te
- Todas las funciones a su disposición
- mesa
- ¡Prepárate!
- Tarea
- la técnica
- Tecnologías
- Tecnología
- texto
- generación de texto
- esa
- El
- la información
- La Fuente
- su
- Les
- luego
- Ahí.
- Estas
- así
- aquellos
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- TLS
- a
- juntos
- Temas
- Total
- Transformar
- Viajar
- Tendencia
- Tendencias
- intentos
- try
- dos
- tipos
- bajo
- universidad
- Universidad de Michigan
- Enlance
- us
- utilizan el
- usado
- eficiente
- Usuario
- Interfaz de usuario
- usuarios
- usando
- validación
- propuesta de
- Valores
- variable
- las variables
- variedad
- diversos
- vector
- vectores
- Vehículos
- vía
- visión
- visual
- tutorial
- quieres
- fue
- Camino..
- we
- web
- servicios web
- WELL
- cuando
- sean
- que
- mientras
- seguirá
- dentro de
- sin
- Mujeres
- Actividades:
- trabajado
- trabajando
- puesto de trabajo
- peor
- se
- años
- aún
- Usted
- tú
- zephyrnet
- zona