
20 de septiembre de 2023
Modelos fundamentales (FM) están marcando el comienzo de una nueva era en aprendizaje automático (ML) y inteligencia artificial (AI), lo que está conduciendo a un desarrollo más rápido de la IA que puede adaptarse a una amplia gama de tareas posteriores y ajustarse para una variedad de aplicaciones.
Con la creciente importancia del procesamiento de datos donde se realiza el trabajo, ofrecer modelos de IA en el borde empresarial permite predicciones casi en tiempo real, respetando al mismo tiempo los requisitos de privacidad y soberanía de los datos. Al combinar el IBM Watsonx capacidades de plataforma de datos e IA para FM con informática de punta, las empresas pueden ejecutar cargas de trabajo de IA para realizar inferencias y ajustes de FM en el borde operativo. Esto permite a las empresas escalar las implementaciones de IA en el borde, reduciendo el tiempo y el costo de implementación con tiempos de respuesta más rápidos.
Asegúrese de consultar todas las entregas de esta serie de publicaciones de blog sobre informática de punta:
¿Qué son los modelos fundacionales?
Los modelos fundamentales (FM), que se entrenan en un amplio conjunto de datos sin etiquetar a escala, están impulsando aplicaciones de inteligencia artificial (IA) de última generación. Se pueden adaptar a una amplia gama de tareas posteriores y ajustarse para una variedad de aplicaciones. Los modelos modernos de IA, que ejecutan tareas específicas en un solo dominio, están dando paso a los FM porque aprenden de manera más general y trabajan en todos los dominios y problemas. Como sugiere el nombre, un FM puede ser la base para muchas aplicaciones del modelo de IA.
Los FM abordan dos desafíos clave que han impedido que las empresas amplíen la adopción de la IA. En primer lugar, las empresas producen una gran cantidad de datos sin etiquetar, de los cuales sólo una fracción está etiquetada para el entrenamiento del modelo de IA. En segundo lugar, esta tarea de etiquetado y anotación requiere un uso extremadamente humano y a menudo requiere varios cientos de horas del tiempo de un experto en la materia (PYME). Esto hace que sea prohibitivo en términos de costos escalar entre casos de uso, ya que requeriría ejércitos de pymes y expertos en datos. Al ingerir grandes cantidades de datos sin etiquetar y utilizar técnicas de autosupervisión para el entrenamiento de modelos, los FM han eliminado estos cuellos de botella y han abierto la vía para la adopción a gran escala de la IA en toda la empresa. Estas enormes cantidades de datos que existen en todas las empresas están esperando a ser liberadas para generar conocimientos.
¿Qué son los grandes modelos de lenguaje?
Los modelos de lenguaje grande (LLM) son una clase de modelos fundamentales (FM) que constan de capas de redes neuronales que han sido entrenados con estas cantidades masivas de datos sin etiquetar. Utilizan algoritmos de aprendizaje autosupervisados para realizar una variedad de procesamiento del lenguaje natural (PNL) tareas de manera similar a cómo los humanos usan el lenguaje (ver Figura 1).
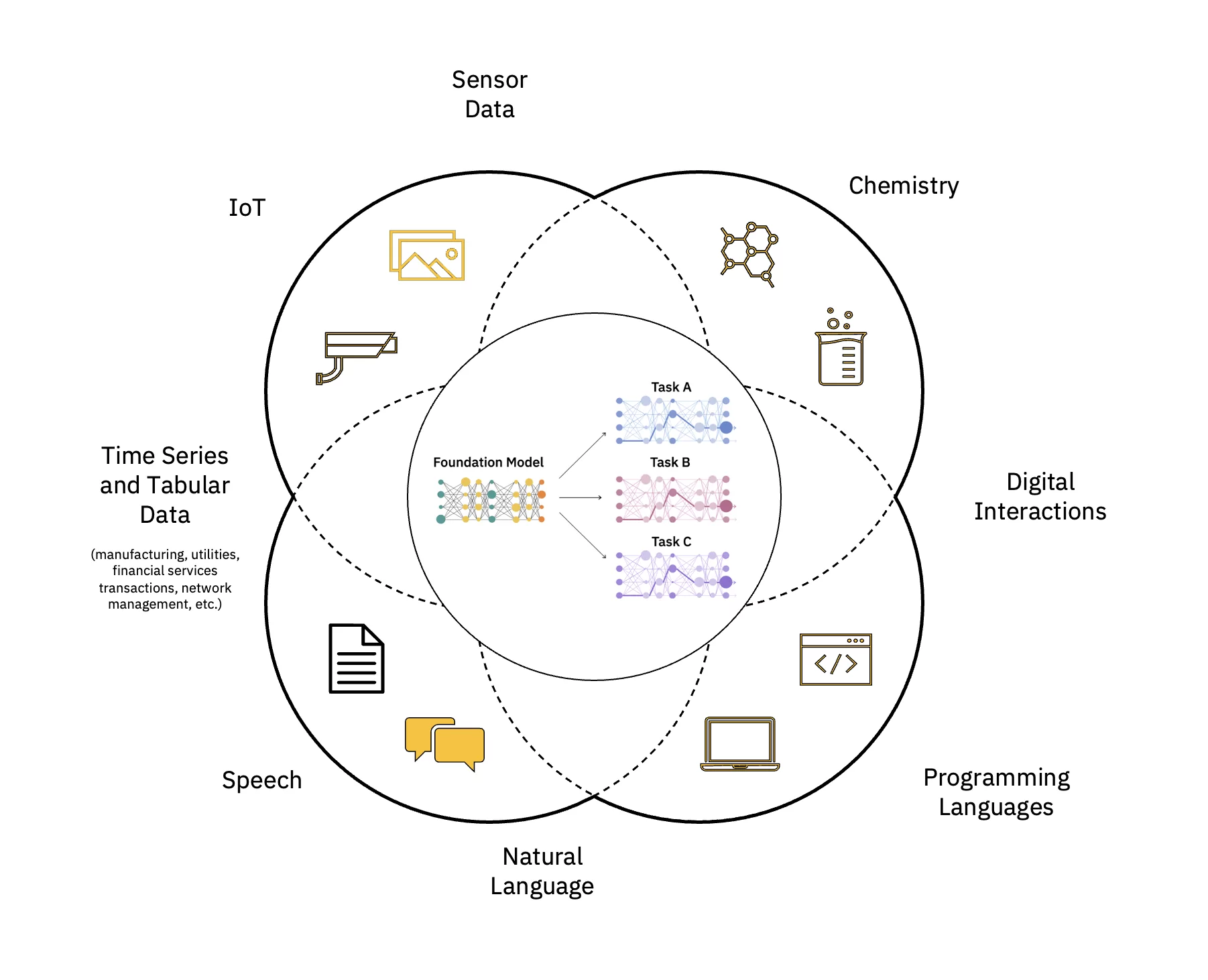
Escalar y acelerar el impacto de la IA
Hay varios pasos para construir e implementar un modelo fundamental (FM). Estos incluyen la ingesta de datos, la selección de datos, el preprocesamiento de datos, el entrenamiento previo de FM, el ajuste de modelos para una o más tareas posteriores, el servicio de inferencias y la gestión del ciclo de vida y la gobernanza de modelos de datos e IA, todos los cuales pueden describirse como FMOps.
Para ayudar con todo esto, IBM ofrece a las empresas las herramientas y capacidades necesarias para aprovechar el poder de estos FM a través de IBM Watsonx, una plataforma de datos e inteligencia artificial preparada para empresas y diseñada para multiplicar el impacto de la inteligencia artificial en toda la empresa. IBM Watsonx consta de lo siguiente:
- IBM watsonx.ai trae nuevo IA generativa capacidades, impulsadas por FM y aprendizaje automático (ML) tradicional, en un potente estudio que abarca el ciclo de vida de la IA.
- IBM watsonx.datos es un almacén de datos diseñado para su propósito construido sobre una arquitectura de lago abierto para escalar cargas de trabajo de IA para todos sus datos, en cualquier lugar.
- IBM watsonx.gobernanza es un conjunto de herramientas de gobernanza del ciclo de vida de la IA automatizado de extremo a extremo diseñado para permitir flujos de trabajo de IA responsables, transparentes y explicables.
Otro vector clave es la creciente importancia de la informática en el borde empresarial, como ubicaciones industriales, plantas de fabricación, tiendas minoristas, sitios de telecomunicaciones, etc. Más específicamente, la IA en el borde empresarial permite el procesamiento de datos donde se realiza el trabajo para Análisis casi en tiempo real. La ventaja empresarial es donde se generan grandes cantidades de datos empresariales y donde la IA puede proporcionar información empresarial valiosa, oportuna y procesable.
Ofrecer modelos de IA en el borde permite predicciones casi en tiempo real, respetando al mismo tiempo los requisitos de privacidad y soberanía de los datos. Esto reduce significativamente la latencia asociada a menudo con la adquisición, transmisión, transformación y procesamiento de datos de inspección. Trabajar en el borde nos permite salvaguardar los datos empresariales confidenciales y reducir los costos de transferencia de datos con tiempos de respuesta más rápidos.
Sin embargo, ampliar las implementaciones de IA en el borde no es una tarea fácil en medio de desafíos relacionados con datos (heterogeneidad, volumen y regulación) y recursos limitados (cómputo, conectividad de red, almacenamiento e incluso habilidades de TI). Estos se pueden describir en términos generales en dos categorías:
- Tiempo/coste de implementación: Cada implementación consta de varias capas de hardware y software que deben instalarse, configurarse y probarse antes de la implementación. Hoy en día, un profesional de servicio puede tardar hasta una o dos semanas en realizar la instalación. en cada lugar, lo que limita gravemente la rapidez y la rentabilidad con la que las empresas pueden ampliar las implementaciones en toda su organización.
- Gestión del día 2: La gran cantidad de bordes desplegados y la ubicación geográfica de cada implementación a menudo podrían hacer que sea prohibitivamente costoso proporcionar soporte de TI local en cada ubicación para monitorear, mantener y actualizar estas implementaciones.
Implementaciones de IA perimetral
IBM desarrolló una arquitectura perimetral que aborda estos desafíos incorporando un modelo de dispositivo integrado de hardware/software (HW/SW) a las implementaciones perimetrales de IA. Consta de varios paradigmas clave que ayudan a la escalabilidad de las implementaciones de IA:
- Aprovisionamiento sin intervención y basado en políticas de toda la pila de software.
- Monitoreo continuo del estado del sistema perimetral
- Capacidades para administrar e impulsar actualizaciones de software/seguridad/configuración a numerosas ubicaciones de borde, todo desde una ubicación central basada en la nube para la administración del día 2.
Se puede utilizar una arquitectura distribuida de centro y radio para escalar las implementaciones de IA empresarial en el borde, en la que una nube central o un centro de datos empresarial actúa como un centro y el dispositivo de borde en caja actúa como un radio en una ubicación de borde.. Este modelo de centro y radio, que se extiende a través de entornos de nube híbrida y de borde, ilustra mejor el equilibrio necesario para utilizar de manera óptima los recursos necesarios para las operaciones de FM (consulte la Figura 2).
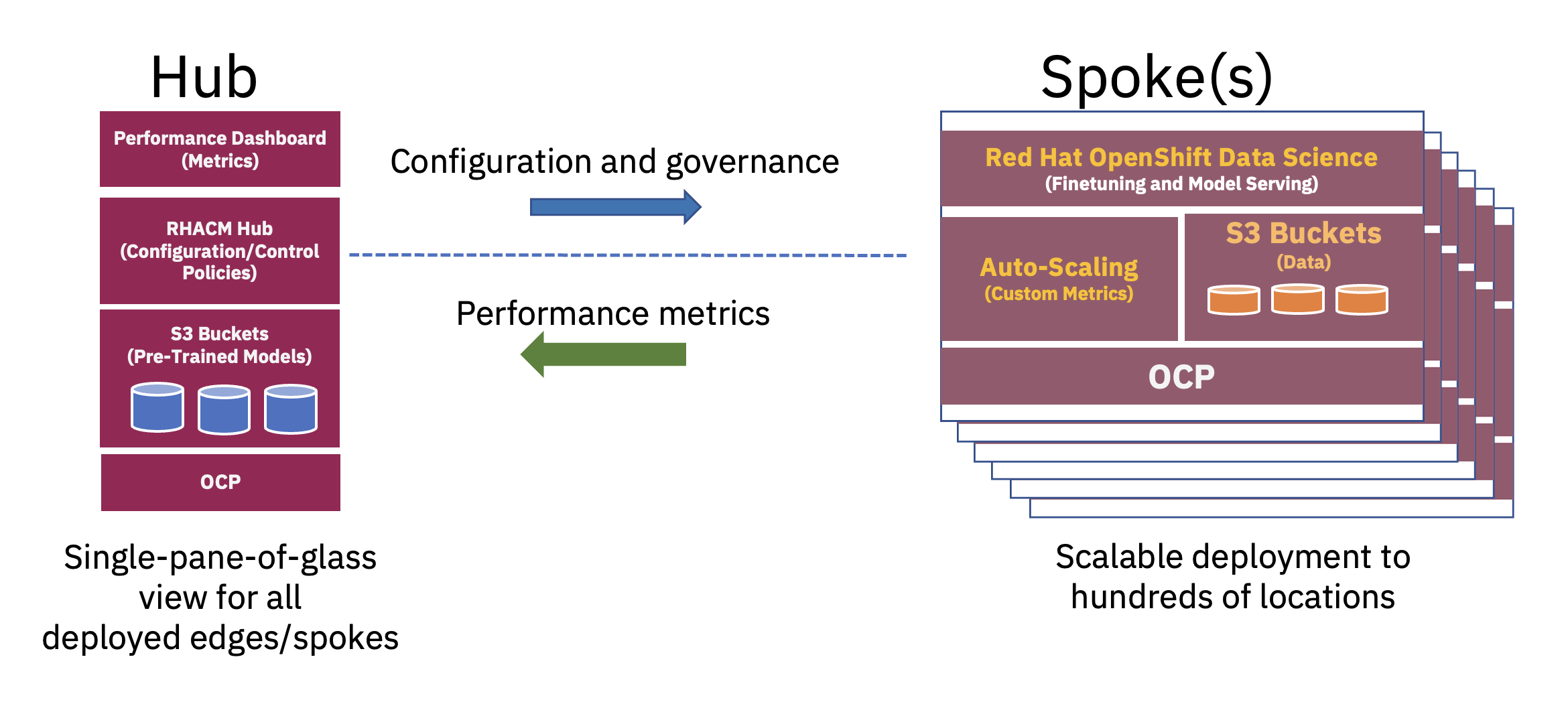
El entrenamiento previo de estos modelos básicos de lenguaje grande (LLM) y otros tipos de modelos básicos que utilizan técnicas autosupervisadas en vastos conjuntos de datos sin etiquetar a menudo necesita importantes recursos informáticos (GPU) y se realiza mejor en un centro. Los recursos informáticos prácticamente ilimitados y las grandes pilas de datos que a menudo se almacenan en la nube permiten el entrenamiento previo de modelos de parámetros grandes y la mejora continua de la precisión de estos modelos básicos.
Por otro lado, el ajuste de estos FM base para tareas posteriores (que solo requieren unas pocas decenas o cientos de muestras de datos etiquetados y servicios de inferencia) se puede lograr con solo unas pocas GPU en el borde empresarial. Esto permite que los datos etiquetados confidenciales (o los datos más importantes de la empresa) permanezcan de forma segura dentro del entorno operativo empresarial y, al mismo tiempo, reduce los costos de transferencia de datos.
Al utilizar un enfoque de pila completa para implementar aplicaciones en el perímetro, un científico de datos puede realizar ajustes, pruebas e implementación de los modelos. Esto se puede lograr en un único entorno y al mismo tiempo reducir el ciclo de vida de desarrollo para ofrecer nuevos modelos de IA a los usuarios finales. Plataformas como Red Hat OpenShift Data Science (RHODS) y Red Hat OpenShift AI recientemente anunciadas brindan herramientas para desarrollar e implementar rápidamente modelos de IA listos para producción en nube distribuida y entornos de borde.
Finalmente, ofrecer el modelo de IA perfeccionado en el perímetro empresarial reduce significativamente la latencia asociada a menudo con la adquisición, transmisión, transformación y procesamiento de datos. Desacoplar la capacitación previa en la nube del ajuste fino y la inferencia en el borde reduce el costo operativo general al reducir el tiempo requerido y los costos de movimiento de datos asociados con cualquier tarea de inferencia (consulte la Figura 3).
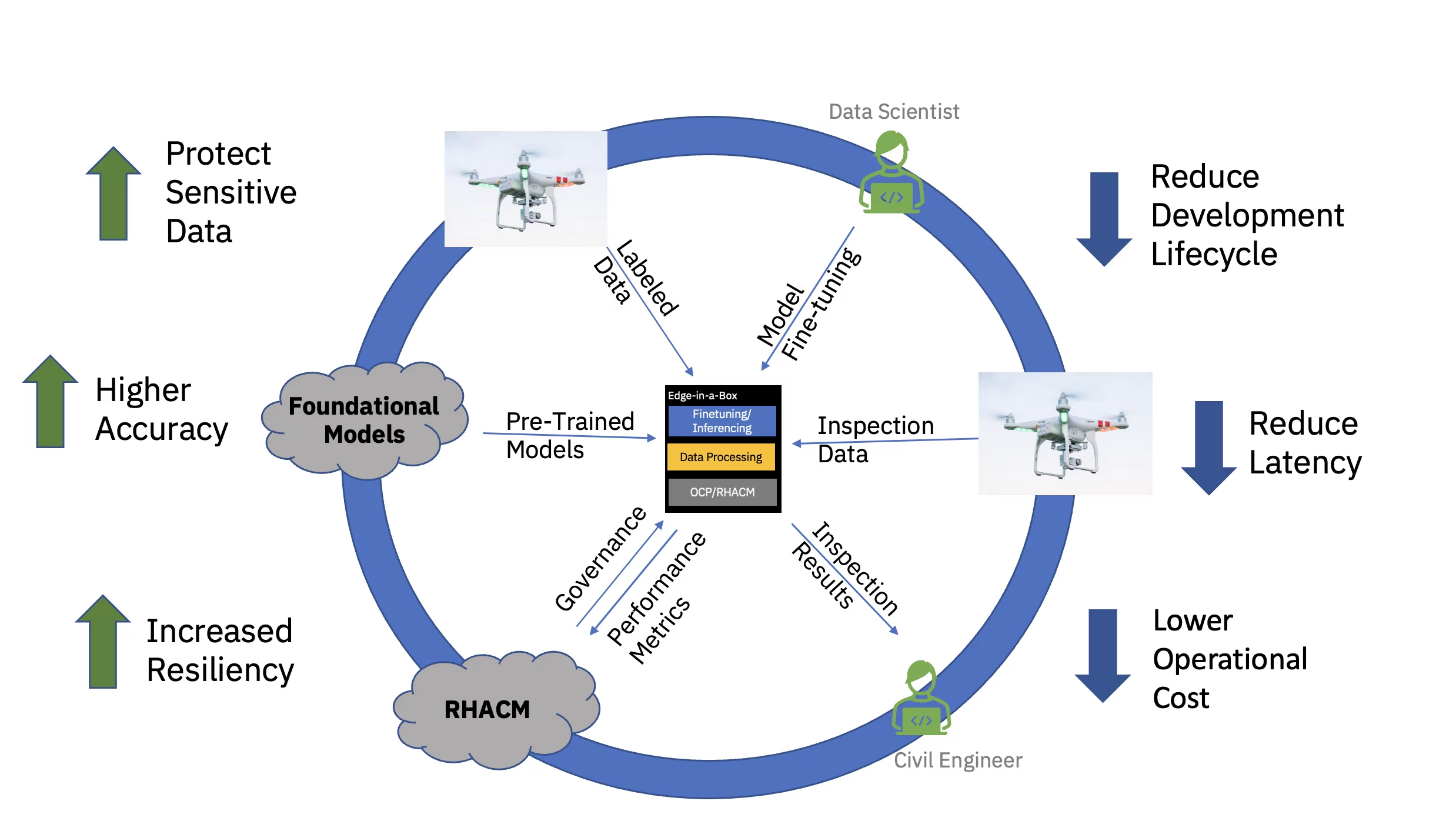
Para demostrar esta propuesta de valor de extremo a extremo, se ajustó e implementó un modelo de base ejemplar basado en transformadores de visión para infraestructura civil (preentrenado utilizando conjuntos de datos públicos y personalizados específicos de la industria) para realizar inferencias en un borde de tres nodos. (radio) grupo. La pila de software incluía Red Hat OpenShift Container Platform y Red Hat OpenShift Data Science. Este clúster perimetral también estaba conectado a una instancia del centro Red Hat Advanced Cluster Management for Kubernetes (RHACM) que se ejecuta en la nube.
Aprovisionamiento sin contacto
El aprovisionamiento sin intervención basado en políticas se realizó con Red Hat Advanced Cluster Management for Kubernetes (RHACM) a través de políticas y etiquetas de ubicación, que vinculan clústeres perimetrales específicos a un conjunto de componentes y configuraciones de software. Estos componentes de software, que se extienden a toda la pila y cubren la computación, el almacenamiento, la red y la carga de trabajo de IA, se instalaron utilizando varios operadores de OpenShift, aprovisionando los servicios de aplicaciones necesarios y S3 Bucket (almacenamiento).
El modelo fundamental (FM) previamente entrenado para infraestructura civil se ajustó mediante un Jupyter Notebook dentro de Red Hat OpenShift Data Science (RHODS) utilizando datos etiquetados para clasificar seis tipos de defectos encontrados en puentes de concreto. El servicio de inferencia de este FM optimizado también se demostró utilizando un servidor Triton. Además, el monitoreo del estado de este sistema de borde fue posible agregando métricas de observabilidad de los componentes de hardware y software a través de Prometheus al panel central de RHACM en la nube. Las empresas de infraestructura civil pueden implementar estos FM en sus ubicaciones periféricas y utilizar imágenes de drones para detectar defectos casi en tiempo real, lo que acelera el tiempo de obtención de información y reduce el costo de mover grandes volúmenes de datos de alta definición hacia y desde la nube.
Resumen
Combinando IBM Watsonx Las capacidades de la plataforma de datos e IA para modelos básicos (FM) con un dispositivo Edge-in-a-Box permiten a las empresas ejecutar cargas de trabajo de IA para realizar inferencias y ajustes de FM en el borde operativo. Este dispositivo puede manejar casos de uso complejos desde el primer momento y crea el marco centralizado para la administración centralizada, la automatización y el autoservicio. Las implementaciones de Edge FM se pueden reducir de semanas a horas con éxito repetible, mayor resiliencia y seguridad.
Obtenga más información sobre los modelos fundamentales
Asegúrese de consultar todas las entregas de esta serie de publicaciones de blog sobre informática de punta:
Más de la nube




- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :posee
- :es
- :no
- :dónde
- $ UP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- Nuestra Empresa
- acelerar
- de la máquina
- logrado
- la exactitud
- adquisición
- a través de
- hechos
- adaptado
- Adicionalmente
- dirección
- direcciones
- Adopción
- avanzado
- avances
- Publicidad
- AI
- Adopción de IA
- Modelos AI
- Plataforma de IA
- Ayudar
- algoritmos
- Todos
- permitir
- permite
- también
- En medio de
- cantidad
- cantidades
- amp
- an
- análisis
- Analytics
- y
- anunció
- cualquier
- dondequiera
- Aplicación
- aplicaciones
- enfoque
- arquitectura
- somos
- Formación
- artículo
- artificial
- inteligencia artificial
- Inteligencia Artificial (AI)
- AS
- asociado
- At
- autor
- Confirmación de Viaje
- Automatización
- Hoy Disponibles
- Avenida
- Atrás
- Balance
- Banca
- Bancos
- bases
- BE
- porque
- a las que has recomendado
- cada vez
- esto
- Comienzo
- "Ser"
- CREEMOS
- MEJOR
- se unen
- Blog
- Entradas De Blog
- Blogs
- ambas
- Box
- puentes
- Trayendo
- Trae
- general
- en general
- Construir la
- construye
- construido
- by
- PUEDEN
- capacidades
- capital
- Capturando
- carbono
- tarjeta
- Tarjetas
- cases
- CAT
- categoría
- Causa
- Reubicación
- central
- Banco Central
- monedas digitales del banco central
- centralizado
- cadena
- retos
- el cambio
- cambio
- comprobar
- opciones
- círculos
- CIS
- civil
- clase
- clasificar
- limpiar
- clientes
- de cerca
- Soluciones
- Médico
- Color
- vistoso
- combinar
- competitivos
- integraciones
- complejidad
- compliance
- componentes
- Calcular
- informática
- Configuración
- configurado
- conectado
- Conectividad
- consiste
- Envase
- continue
- control
- Cost
- Precio
- podría
- cubierta
- criptomoneda
- CO
- monedas
- personalizado
- cliente
- experiencia del cliente
- Clientes
- página de información de sus operaciones
- datos
- Data Center
- Plataforma de datos
- Ciencia de los datos
- científico de datos
- conjuntos de datos
- Fecha
- a dedicados
- Predeterminado
- Definiciones
- entregamos
- demostrar
- demostrado
- desplegar
- desplegado
- Desplegando
- despliegue
- Despliegues
- descrito
- descripción
- diseñado
- desarrollar
- desarrollado
- Desarrollo
- digital
- monedas digitales
- digitalización
- Interrupción
- disruptivo
- Disruptores
- distribuidos
- distrito
- dominio
- dominios
- hecho
- el lado de la transmisión
- conducción
- zángano
- cada una
- de forma sencilla
- ecosistema
- Southern Implants
- informática de punta
- ELEVATE
- elevado
- habilitar
- permite
- final
- de extremo a extremo
- ingeniero
- Ingeniería
- Participar
- Empresa
- empresas
- entrante
- Entorno
- ambientes
- Era
- especialmente
- etc.
- Éter (ETH)
- Incluso
- Eventos
- Cada
- evolucionado
- Examinar
- ejemplos
- ejecutar
- existe
- Exit
- costoso
- experience
- expertos
- IA explicable
- explicando
- extensión
- extremadamente
- factores importantes
- RÁPIDO
- más rápida
- pocos
- campo
- Figura
- financiero
- Instituciones financieras
- financiamiento
- Nombre
- pisos
- seguir
- siguiendo
- fuentes
- primer plano
- encontrado
- Fundación
- fracción
- Marco conceptual
- Desde
- ser completados
- Completa pila
- Además
- en general
- generado
- generador
- geográfico
- Geopolítica
- Diezmos y Ofrendas
- Buscar
- comercio global
- gobierno
- GPU
- GPU
- Cuadrícula
- mano
- encargarse de
- Materiales
- ¿Qué
- Tienen
- Salud
- altura
- ayuda
- ayudando
- ayuda
- alta definición
- más alto
- altamente
- historia
- fortaleza
- HORAS
- Cómo
- Como Hacer
- Sin embargo
- HTTPS
- Bujes
- Humanos
- Cientos
- Híbrido
- nube híbrida
- IBM
- Nube de IBM
- ICO
- ICON
- ilustra
- imagen
- Impacto
- importancia
- es la mejora continua
- in
- incluir
- incluido
- creciente
- cada vez más
- índice
- industrial
- industrias
- energético
- específico de la industria
- inflación
- Inflexión
- Punto de inflexión
- influenciado
- EN LA MINA
- Iniciativa
- Innovation
- originales
- entradas
- Insights
- ejemplo
- instituciones
- COMPLETAMENTE
- Intelligence
- intrínseco
- Presentamos
- IT
- Soporte de IT
- Viajes
- jpg
- saltar
- Cuaderno Jupyter
- solo
- tan siquiera solo una
- mantenido
- Clave
- Kubernetes
- etiquetado
- idioma
- large
- principalmente
- Estado latente
- más reciente
- ponedoras
- líder
- APRENDE:
- aprendizaje
- Apalancamiento
- ciclo de vida
- como
- sin límites
- Linux
- local
- local
- Ubicación
- Ubicaciones
- Largo
- Mira
- máquina
- máquina de aprendizaje
- hecho
- mantener
- para lograr
- HACE
- gestionan
- Management
- Fabricación
- muchos
- marcado
- masivo
- dominar
- Materia
- max-ancho
- los mecanismos de
- métodos
- Métrica
- min
- minimizando
- minutos
- ML
- Móvil
- modelo
- modelos
- Moderno
- modernización
- modernizar
- Monitorear
- monitoreo
- más,
- movimiento
- emocionante
- nombre
- Navegación
- Cerca
- necesario
- ¿ Necesita ayuda
- del sistema,
- Nuevo
- Next
- nlp
- cuaderno
- nada
- ahora
- número
- numeroso
- of
- que ofrece
- a menudo
- on
- ONE
- , solamente
- habiertos
- abierto
- operativos.
- Operaciones
- operadores
- optimizado
- or
- organización
- Otro
- "nuestr
- salir
- total
- paquetes
- página
- parámetro
- pago
- Métodos de pago
- pagos
- realizar
- realizado
- PHP
- colocación
- plataforma
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- plugin
- punto
- políticas
- política
- posición
- posible
- Publicación
- Artículos
- posible
- industria
- poderoso
- Predicciones
- Anterior
- política de privacidad
- privada
- problemas
- tratamiento
- producir
- Profesional
- valor.
- proporcionar
- público
- Push
- distancia
- rápidamente
- Reading
- en tiempo real
- recientemente
- grabar
- vea la grabación
- Rojo
- Red Hat
- reducir
- Reducción
- reduce
- la reducción de
- reglamentos
- Reguladores
- regulador
- relacionado
- Remoto
- repetible
- exigir
- Requisitos
- Requisitos
- requisito
- la investigación
- Recursos
- respuesta
- responsable
- sensible
- el comercio minorista
- Subir
- los robots
- Ejecutar
- correr
- de manera segura
- mismo
- Escalabilidad
- Escala
- escala ia
- la ampliación
- Ciencia:
- Científico
- Pantalla
- guiones
- Segundo
- segura
- EN LINEA
- ver
- ver
- selección
- Autoservicio
- sensible
- SEO
- Septiembre
- Serie
- servidor
- de coches
- Servicios
- servicio
- Sesión
- sesiones
- set
- Varios
- Compartir
- Mostrar
- importante
- significativamente
- similares
- desde
- Singapur
- soltero
- entorno único
- página web
- Sitios Web
- SEIS
- habilidades
- chica
- PYMI
- PYME
- Software
- componentes de software
- a medida
- soberanía
- Espacio
- abarcando
- soluciones y
- específicamente
- Patrocinado
- montón
- comienzo
- el estado de la técnica
- quedarse
- pasos
- STORAGE
- tienda
- almacenados
- tiendas
- Storm
- estudio
- sujeto
- comercial
- tal
- Sugiere
- suministro
- cadena de suministro
- SOPORTE
- seguro
- te
- ¡Prepárate!
- toma
- Tarea
- tareas
- técnicas
- Tecnología
- Las redes de
- Temenos
- tener
- Terraform
- probado
- Pruebas
- esa
- La
- su
- tema
- Ahí.
- Estas
- ellos
- así
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- oportuno
- veces
- Título
- a
- hoy
- juntos
- caja de herramientas
- parte superior
- comercio
- tradicional
- Entrenar
- entrenado
- Formación
- transferir
- Transformar
- transformaciones
- transparente
- Tritón
- dos
- tipo
- tipos
- soltado
- Actualizar
- Actualizaciones
- Enlance
- us
- utilizan el
- usado
- usuarios
- usando
- utilizar
- utilizado
- Valioso
- propuesta de
- propuesta de valor
- variedad
- diversos
- Vasto
- vía
- Ver
- virtualmente
- volumen
- volúmenes
- W
- Esperando
- Billetera
- fue
- Trenzado
- Camino..
- formas
- we
- semana
- Semanas
- ¿
- Que es
- cuando
- que
- mientras
- QUIENES
- porque
- amplio
- Amplia gama
- dentro de
- mujer
- WordPress
- Actividades:
- flujos de trabajo
- trabajando
- se
- escrito
- tú
- zephyrnet











