Desplazamiento al rojo de Amazon es un almacén de datos en la nube rápido y totalmente administrado a escala de petabytes que hace que sea simple y rentable analizar todos sus datos utilizando SQL estándar y sus herramientas de inteligencia empresarial (BI) existentes. Hoy en día, decenas de miles de clientes utilizan Amazon Redshift para analizar exabytes de datos y ejecutar consultas analíticas, lo que lo convierte en el almacén de datos en la nube más utilizado. Amazon Redshift está disponible en configuraciones aprovisionadas y sin servidor.
Amazon Redshift le permite acceder directamente a los datos almacenados en Servicio de almacenamiento simple de Amazon (Amazon S3) utilizando consultas SQL y uniendo datos en su almacén de datos y lago de datos. Con Amazon Redshift, puede consultar los datos de su lago de datos S3 mediante una central Pegamento AWS metastore desde su almacén de datos de Redshift.
Amazon Redshift admite consultas de una amplia variedad de formatos de datos, como CSV, JSON, Parquet y ORC, y formatos de tablas como Apache Hudi y Delta. Amazon Redshift también admite consultas de datos anidados con tipos de datos complejos como estructura, matriz y mapa.
Con esta capacidad, Amazon Redshift extiende su almacén de datos a escala de petabytes a un lago de datos a escala de exabytes en Amazon S3 de manera rentable.
Apache Iceberg es el último formato de tabla admitido ahora en versión preliminar por Amazon Redshift. En esta publicación, le mostramos cómo consultar tablas de Iceberg mediante Amazon Redshift y explorar el soporte y las opciones de Iceberg.
Resumen de la solución
iceberg apache es un formato de tabla abierta para conjuntos de datos analíticos de gran tamaño a escala de petabytes. Iceberg gestiona grandes colecciones de archivos como tablas y admite operaciones analíticas modernas de lagos de datos, como consultas de inserción, actualización, eliminación y viajes en el tiempo a nivel de registro. La especificación Iceberg permite una evolución perfecta de tablas, como la evolución de esquemas y particiones, y su diseño está optimizado para su uso en Amazon S3.
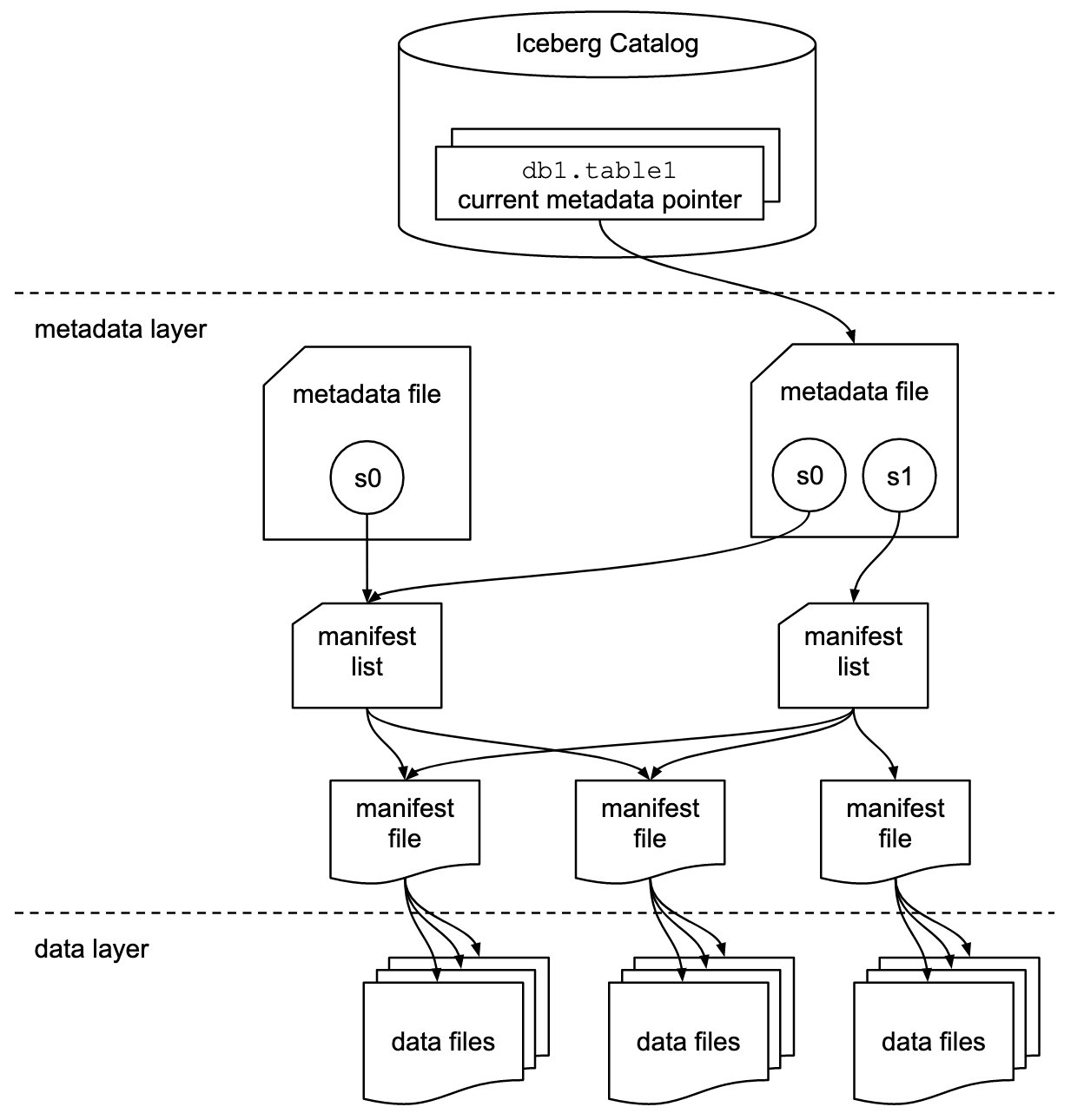
Iceberg almacena el puntero de metadatos de todos los archivos de metadatos. Cuando una consulta SELECT lee una tabla Iceberg, el motor de consultas primero va al catálogo de Iceberg y luego recupera la entrada de la ubicación del último archivo de metadatos, como se muestra en el siguiente diagrama.
Amazon Redshift ahora brinda soporte para tablas Apache Iceberg, lo que permite a los clientes del lago de datos ejecutar consultas de análisis de solo lectura de manera transaccionalmente consistente. Esto le permite administrar y mantener fácilmente sus tablas en lagos de datos transaccionales.
Amazon Redshift admite las capacidades de evolución de particiones y esquemas nativos de Apache Iceberg mediante el Catálogo de datos de AWS Glue, eliminando la necesidad de modificar las definiciones de las tablas para agregar nuevas particiones o mover y procesar grandes cantidades de datos para cambiar el esquema de una tabla de lago de datos existente. Amazon Redshift utiliza las estadísticas de columnas almacenadas en los metadatos de la tabla Apache Iceberg para optimizar sus planes de consultas y reducir los análisis de archivos necesarios para ejecutar consultas.
En esta publicación, usamos el Conjunto de datos públicos de taxis amarillos de la Comisión de Taxis y Limusinas de Nueva York como nuestra fuente de datos. El conjunto de datos contiene archivos de datos en Parquet Apache formato en Amazon S3. Usamos Atenea amazónica para convertir este conjunto de datos de Parquet y luego usar Espectro de Redshift de Amazon para consultar y unirse a una tabla local de Redshift, realizar eliminaciones y actualizaciones a nivel de fila y evolución de particiones, todo coordinado a través del catálogo de datos de AWS Glue en un lago de datos S3.
Requisitos previos
Debe tener los siguientes requisitos previos:
Convertir datos de Parquet en una tabla Iceberg
Para esta publicación necesitas el Conjunto de datos públicos de taxis amarillos de la Comisión de Taxis y Limusinas de Nueva York Disponible en formato Iceberg. Puede descargar los archivos y luego usar Athena para convertir el conjunto de datos de Parquet en una tabla Iceberg, o consultar Cree un lago de datos Apache Iceberg con Amazon Athena, Amazon EMR y AWS Glue publicación de blog para crear la tabla Iceberg.
En esta publicación, utilizamos Athena para convertir los datos. Complete los siguientes pasos:
- Descargue los archivos usando el enlace anterior o use el Interfaz de línea de comandos de AWS (AWS CLI) para copiar los archivos del depósito público de S3 para los años 2020 y 2021 a su depósito de S3 mediante el siguiente comando:
Para obtener más información, consulte Configuración de la CLI de Amazon Redshift.
- Crea una base de datos
Icebergdby cree una tabla usando Athena que apunte a los archivos en formato Parquet usando la siguiente declaración: - Valide los datos en la tabla Parquet usando el siguiente SQL:

- Cree una tabla Iceberg en Athena con el siguiente código. Puede ver las propiedades del tipo de tabla como una tabla Iceberg con formato Parquet y compresión rápida en lo siguiente
create tabledeclaración. Debe actualizar la ubicación de S3 antes de ejecutar SQL. También tenga en cuenta que la tabla Iceberg está dividida con elYearclave. - Después de crear la tabla, cargue los datos en la tabla Iceberg usando la tabla Parquet previamente cargada.
nyc_taxi_yellow_parquetcon el siguiente sql: - Cuando la declaración SQL esté completa, valide los datos en la tabla Iceberg
nyc_taxi_yellow_iceberg. Este paso es necesario antes de pasar al siguiente. - Puede validar que la tabla nyc_taxi_amarillo_iceberg esté en formato Iceberg y particionada en la columna Año usando el siguiente comando:



Cree un esquema externo en Amazon Redshift
En esta sección, demostramos cómo crear un esquema externo en Amazon Redshift que apunte a la base de datos de AWS Glue. icebergdb para consultar la tabla Iceberg nyc_taxi_yellow_iceberg que vimos en la sección anterior usando Athena.
Inicie sesión en Redshift a través de Editor de consultas v2 o un cliente SQL y ejecute el siguiente comando (tenga en cuenta que la base de datos de AWS Glue icebergdb y se está utilizando información de la región):

Para obtener información sobre la creación de esquemas externos en Amazon Redshift, consulte crear esquema externo
Después de crear el esquema externo spectrum_iceberg_schema, puede consultar la tabla Iceberg en Amazon Redshift.
Consultar la tabla Iceberg en Amazon Redshift
Ejecute la siguiente consulta en Query Editor v2. Tenga en cuenta que spectrum_iceberg_schema es el nombre del esquema externo creado en Amazon Redshift y nyc_taxi_yellow_iceberg es la tabla de la base de datos de AWS Glue utilizada en la consulta:
El resultado de los datos de la consulta en la siguiente captura de pantalla muestra que la tabla de AWS Glue con formato Iceberg se puede consultar mediante Redshift Spectrum.

Consulte el plan explicativo para consultar la tabla Iceberg.
Puede utilizar la siguiente consulta para obtener el resultado del plan de explicación, que muestra que el formato es ICEBERG:

Validar actualizaciones para la coherencia de los datos
Una vez completada la actualización en la tabla Iceberg, puede consultar Amazon Redshift para ver la vista transaccionalmente consistente de los datos. Ejecutemos una consulta eligiendo un vendorid y para una determinada recogida y devolución:

A continuación, actualice el valor de passenger_count a 4 y trip_distance a 9.4 para un vendorid y ciertas fechas de recogida y devolución en Athena:

Finalmente, ejecute la siguiente consulta en Query Editor v2 para ver el valor actualizado de passenger_count y trip_distance:
Como se muestra en la siguiente captura de pantalla, las operaciones de actualización en la tabla Iceberg están disponibles en Amazon Redshift.

Cree una vista unificada de la tabla local y los datos históricos en Amazon Redshift
Como estrategia de arquitectura de datos moderna, puede organizar datos históricos o datos a los que se accede con menos frecuencia en el lago de datos y mantener los datos a los que se accede con frecuencia en el almacén de datos de Redshift. Esto proporciona la flexibilidad para gestionar análisis a escala y encontrar la solución de arquitectura más rentable.
En este ejemplo, cargamos 2 años de datos en una tabla Redshift; el resto de los datos permanece en el lago de datos de S3 porque ese conjunto de datos se consulta con menos frecuencia.
- Utilice el siguiente código para cargar 2 años de datos en el
nyc_taxi_yellow_recenttabla en Amazon Redshift, procedente de la tabla Iceberg:
- A continuación, puede eliminar los datos de los últimos 2 años de la tabla Iceberg usando el siguiente comando en Athena porque cargó los datos en una tabla Redshift en el paso anterior:

Después de completar estos pasos, la tabla Redshift tiene 2 años de datos y el resto de los datos está en la tabla Iceberg en Amazon S3.
- Crea una vista usando el
nyc_taxi_yellow_icebergmesa iceberg ynyc_taxi_yellow_recenttabla en Amazon Redshift: - Ahora consulte la vista, dependiendo de las condiciones del filtro, Redshift Spectrum escaneará los datos de Iceberg, la tabla Redshift o ambos. La siguiente consulta de ejemplo devuelve una cantidad de registros de cada una de las tablas de origen al escanear ambas tablas:

Evolución de la partición
Usos del iceberg partición oculta, lo que significa que no necesita agregar particiones manualmente para sus tablas de Apache Iceberg. Amazon Redshift detecta automáticamente los nuevos valores de partición o las nuevas especificaciones de partición (agregar o eliminar columnas de partición) en las tablas de Apache Iceberg y no se necesita ninguna operación manual para actualizar las particiones en la definición de la tabla. El siguiente ejemplo demuestra esto.
En nuestro ejemplo, si la tabla Iceberg nyc_taxi_yellow_iceberg Originalmente se dividió por año y luego la columna vendorid se agregó como una columna de partición adicional, entonces Amazon Redshift puede consultar sin problemas la tabla Iceberg nyc_taxi_yellow_iceberg con dos esquemas de partición diferentes durante un período de tiempo.

Consideraciones al consultar tablas de Iceberg mediante Amazon Redshift
Durante el período de vista previa, tenga en cuenta lo siguiente al utilizar Amazon Redshift con tablas Iceberg:
- Solo se admiten las tablas Iceberg definidas en el catálogo de datos de AWS Glue.
- Los comandos CREATE o ALTER de tabla externa no son compatibles, lo que significa que la tabla Iceberg ya debería existir en una base de datos de AWS Glue.
- No se admiten consultas de viajes en el tiempo.
- Se admiten las versiones 1 y 2 de Iceberg. Para obtener más detalles sobre las versiones del formato Iceberg, consulte Versión de formato.
- Para obtener una lista de los tipos de datos admitidos con tablas Iceberg, consulte Tipos de datos admitidos con tablas Apache Iceberg (vista previa).
- El precio por consultar una tabla Iceberg es el mismo que el de acceder a cualquier otro formato de datos mediante Amazon Redshift.
Para obtener detalles adicionales sobre las consideraciones para la vista previa de tablas en formato Iceberg, consulte Uso de tablas de Apache Iceberg con Amazon Redshift (versión preliminar).
Valoración de los clientes
“Tinuiti, la firma independiente de marketing de resultados más grande, maneja grandes volúmenes de datos a diario y debe contar con una sólida estrategia de almacenamiento y lago de datos para que nuestros equipos de inteligencia de mercado almacenen y analicen todos los datos de nuestros clientes de una manera fácil, asequible y segura. , y robusta”, afirma Justin Manus, director de tecnología de Tinuiti. “El soporte de Amazon Redshift para las tablas Apache Iceberg en nuestro lago de datos, que es la única fuente de verdad, aborda un desafío crítico en la optimización del rendimiento y la accesibilidad y simplifica aún más nuestros procesos de integración de datos para acceder a todos los datos ingeridos de diferentes fuentes y potenciar nuestra el potencial de marca de los clientes”.
Conclusión
En esta publicación, le mostramos un ejemplo de consulta de una tabla Iceberg en Redshift utilizando archivos almacenados en Amazon S3, catalogados como una tabla en el catálogo de datos de AWS Glue, y demostramos algunas de las características clave, como actualización y eliminación eficientes a nivel de fila, y la experiencia de evolución de esquemas para que los usuarios desbloqueen el poder del big data utilizando Athena.
Puede utilizar Amazon Redshift para ejecutar consultas en tablas del lago de datos en varios archivos y formatos de tabla, como apache hudi y Delta Lakey ahora con Apache Iceberg (vista previa), que proporciona opciones adicionales para sus necesidades de arquitecturas de datos modernas.
Esperamos que esto le brinde un excelente punto de partida para consultar tablas Iceberg en Amazon Redshift.
Acerca de los autores
 rohit-bansal es un arquitecto de soluciones especialista en análisis en AWS. Se especializa en Amazon Redshift y trabaja con los clientes para crear soluciones de análisis de última generación utilizando otros servicios de análisis de AWS.
rohit-bansal es un arquitecto de soluciones especialista en análisis en AWS. Se especializa en Amazon Redshift y trabaja con los clientes para crear soluciones de análisis de última generación utilizando otros servicios de análisis de AWS.
 satish sathiya es ingeniero de productos sénior en Amazon Redshift. Es un ávido entusiasta de los macrodatos que colabora con clientes de todo el mundo para lograr el éxito y satisfacer sus necesidades de almacenamiento de datos y arquitectura de lago de datos.
satish sathiya es ingeniero de productos sénior en Amazon Redshift. Es un ávido entusiasta de los macrodatos que colabora con clientes de todo el mundo para lograr el éxito y satisfacer sus necesidades de almacenamiento de datos y arquitectura de lago de datos.
 Ranjan birmano es un arquitecto de soluciones especialista en análisis en AWS. Se especializa en Amazon Redshift y ayuda a los clientes a crear soluciones analíticas escalables. Tiene más de 16 años de experiencia en diferentes tecnologías de bases de datos y almacenamiento de datos. Le apasiona automatizar y resolver los problemas de los clientes con soluciones en la nube.
Ranjan birmano es un arquitecto de soluciones especialista en análisis en AWS. Se especializa en Amazon Redshift y ayuda a los clientes a crear soluciones analíticas escalables. Tiene más de 16 años de experiencia en diferentes tecnologías de bases de datos y almacenamiento de datos. Le apasiona automatizar y resolver los problemas de los clientes con soluciones en la nube.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :posee
- :es
- :no
- :dónde
- $ UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- Nuestra Empresa
- de la máquina
- visitada
- accesibilidad
- el acceso
- Lograr
- a través de
- add
- adicional
- Adicionales
- direcciones
- asequible
- Todos
- permite
- ya haya utilizado
- también
- Amazon
- Atenea amazónica
- EMR de Amazon
- Amazon Web Services
- cantidades
- an
- Analítico
- Pruebas analíticas
- Analytics
- analizar
- y
- cualquier
- APACHE
- arquitectura
- somos
- en torno a
- Formación
- AS
- At
- automáticamente
- automatizar
- Hoy Disponibles
- AWS
- Pegamento AWS
- base
- porque
- antes
- "Ser"
- Big
- Big Data
- uniéndose
- Blog
- ambas
- marca
- build
- inteligencia empresarial
- by
- PUEDEN
- capacidades
- capacidad
- catalogar
- central
- a ciertos
- Reto
- el cambio
- jefe
- Director de Tecnología
- cliente
- Soluciones
- código
- colecciones
- Columna
- Columnas
- completar
- integraciones
- condiciones
- Considerar
- consideraciones
- consistente
- contiene
- convertir
- coordinado
- rentable
- Para crear
- creado
- Creamos
- crítico
- cliente
- datos de los clientes
- Clientes
- todos los días
- datos
- integración de datos
- Lago de datos
- almacenamiento de datos
- Base de datos
- conjuntos de datos
- Fechas
- Predeterminado
- se define
- definición
- Definiciones
- Delta
- demostrar
- demostrado
- demuestra
- Dependiente
- Diseño
- detalles
- detectado
- Dev
- una experiencia diferente
- directamente
- No
- doble
- descargar
- cada una
- pasan fácilmente
- de forma sencilla
- editor
- eficiente
- ya sea
- eliminando
- permite
- Motor
- ingeniero
- entusiasta
- entrada
- Éter (ETH)
- evolución
- ejemplo
- existe
- existente
- experience
- Explicar
- explorar
- Se extiende
- externo
- extra
- RÁPIDO
- Caracteristicas
- Archive
- archivos
- filtrar
- Encuentre
- Firme
- Nombre
- Flexibilidad
- siguiendo
- formato
- frecuentemente
- Desde
- completamente
- promover
- obtener
- da
- globo
- Va
- maravillosa
- Grupo procesos
- Manijas
- Tienen
- he
- ayuda
- histórico
- esperanza
- Cómo
- Como Hacer
- HTML
- http
- HTTPS
- if
- in
- independientes
- información
- integración
- Intelligence
- dentro
- IT
- SUS
- únete
- jpg
- json
- Justin
- Guardar
- Clave
- lago
- large
- mayor
- Apellido
- luego
- más reciente
- APRENDE:
- menos
- como
- LIMITE LAS
- línea
- LINK
- Lista
- carga
- local
- Ubicación
- mantener
- HACE
- Realizar
- gestionan
- gestionado
- gestiona
- manera
- manual
- a mano
- mapa
- Mercado
- Marketing
- significa
- Conoce a
- metadatos
- Moderno
- más,
- MEJOR DE TU
- movimiento
- emocionante
- debe
- nombre
- nativo
- ¿ Necesita ayuda
- Nuevo
- Next
- próxima generación
- no
- nota
- ahora
- número
- Nueva York
- of
- Oficial
- on
- habiertos
- Inteligente
- Operaciones
- Optimización
- optimizado
- optimizando
- Opciones
- or
- originalmente
- Otro
- nuestros
- salida
- Más de
- página
- apasionado
- realizar
- actuación
- período
- plan
- jubilación
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- punto
- Publicación
- posible
- industria
- requisitos previos
- Vista previa
- anterior
- previamente
- problemas
- Producto
- propiedades
- proporciona un
- público
- consultas
- Reading
- archivos
- reducir
- región
- remove
- reemplazar
- Requisitos
- RESTO
- devoluciones
- robusto
- Ejecutar
- correr
- mismo
- Sierra
- dice
- escalable
- Escala
- escanear
- exploración
- escanea
- esquemas
- sin costura
- sin problemas
- Sección
- seguro
- ver
- mayor
- Sin servidor
- Servicios
- set
- tienes
- Mostrar
- mostró
- mostrado
- Shows
- sencillos
- soltero
- a medida
- Soluciones
- Resolver
- algo
- Fuente
- Fuentes
- Sourcing
- especialista
- se especializa
- especificación
- especificaciones
- Spectrum
- SQL
- estándar
- Comience a
- Posicionamiento
- statistics
- paso
- pasos
- STORAGE
- tienda
- almacenados
- tiendas
- Estrategia
- Cordón
- comercial
- tal
- SOPORTE
- Soportado
- soportes
- mesa
- equipos
- Tecnologías
- Tecnología
- tener
- que
- esa
- La
- La Fuente
- su
- luego
- Estas
- así
- miles
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- el tiempo de viaje
- fecha y hora
- a
- hoy
- transaccional
- viajes
- verdad
- dos
- tipo
- tipos
- unificado
- unión
- desbloquear
- Actualizar
- actualizado
- Actualizaciones
- Uso
- utilizan el
- usado
- usuarios
- usos
- usando
- VALIDAR
- propuesta de
- Valores
- variedad
- diversos
- muy
- vía
- Ver
- volúmenes
- Manejo de
- Almacenamiento
- fue
- Camino..
- we
- web
- servicios web
- cuando
- que
- QUIENES
- amplio
- extensamente
- seguirá
- funciona
- año
- años
- Usted
- tú
- zephyrnet