Imagen del autor
When you are getting started with machine learning, logistic regression is one of the first algorithms you’ll add to your toolbox. It’s a simple and robust algorithm, commonly used for binary classification tasks.
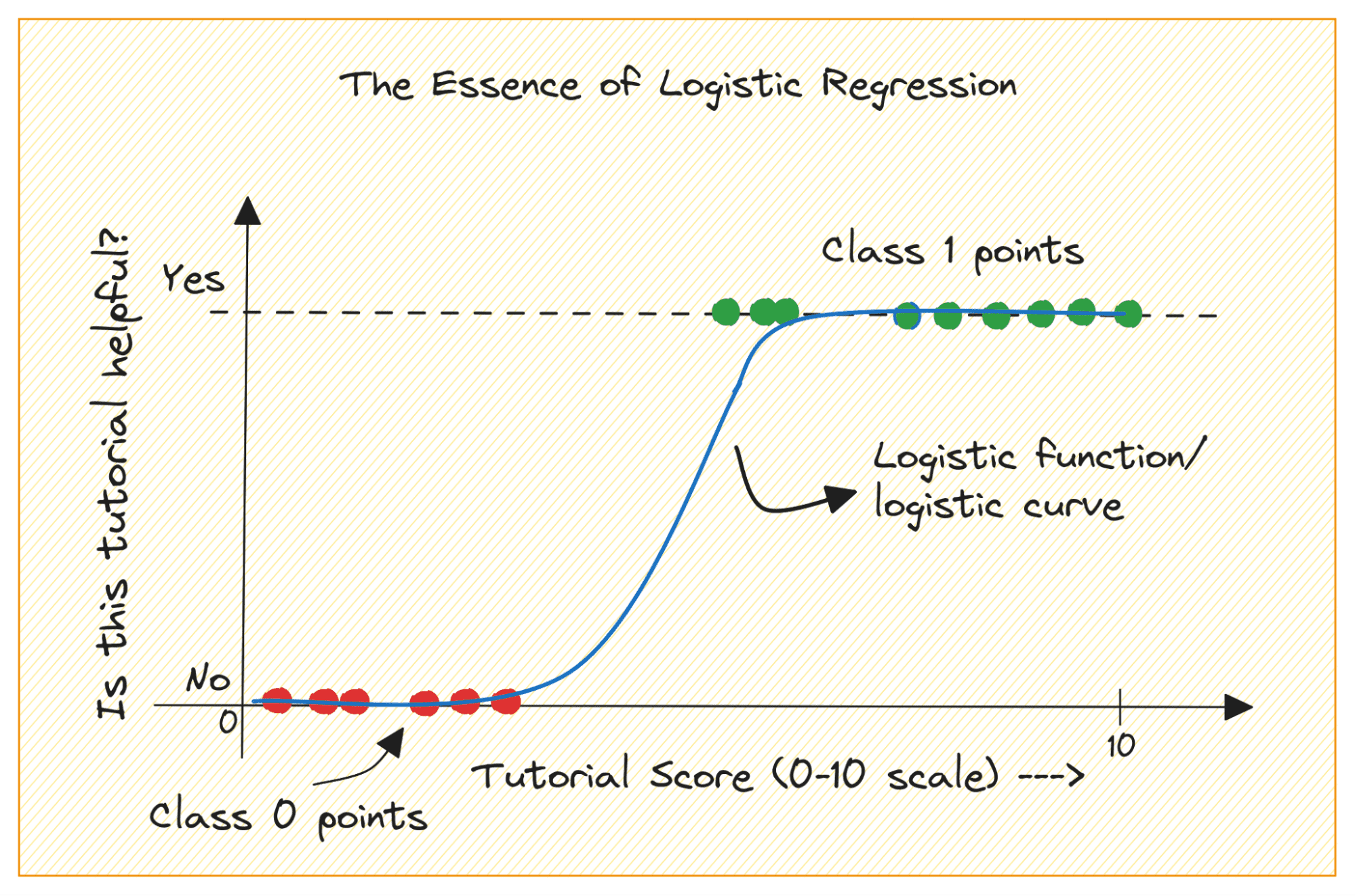
Considere un problema de clasificación binaria con las clases 0 y 1. La regresión logística ajusta una función logística o sigmoidea a los datos de entrada y predice la probabilidad de que un punto de datos de consulta pertenezca a la clase 1. Interesante, ¿no?
En este tutorial, aprenderemos sobre la regresión logística desde cero y cubriremos:
- La función logística (o sigmoidea)
- Cómo pasamos de la regresión lineal a la logística
- Cómo funciona la regresión logística
Finalmente, construiremos un modelo de regresión logística simple para clasificar los retornos de RADAR de la ionosfera.
Before we learn more about logistic regression, let’s review how the logistic function works. The logistic (or sigmoid function) is given by:

Cuando traces la función sigmoidea, se verá así:
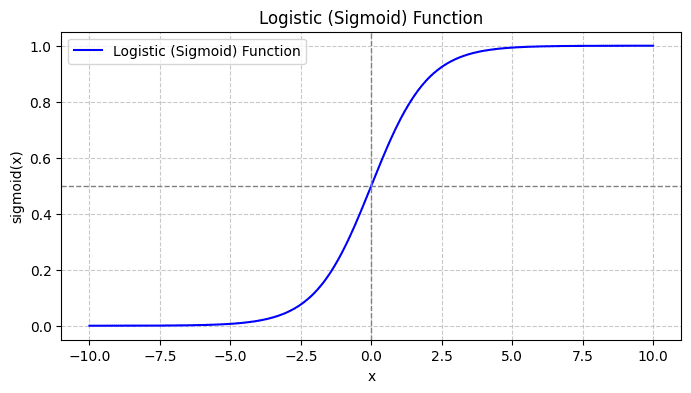
De la trama vemos que:
- Cuando x = 0, σ(x) toma un valor de 0.5.
- Cuando x se acerca a +∞, σ(x) se acerca a 1.
- Cuando x se acerca a -∞, σ(x) se acerca a 0.
Entonces, para todas las entradas reales, la función sigmoidea las aplasta para que tomen valores en el rango [0, 1].
Let’s first discuss why we cannot use linear regression for a binary classification problem.
En un problema de clasificación binaria, el resultado es una etiqueta categórica (0 o 1). Debido a que la regresión lineal predice resultados con valores continuos que pueden ser menores que 0 o mayores que 1, no tiene sentido para el problema que nos ocupa.
Además, una línea recta puede no ser la mejor opción cuando las etiquetas de salida pertenecen a una de las dos categorías.
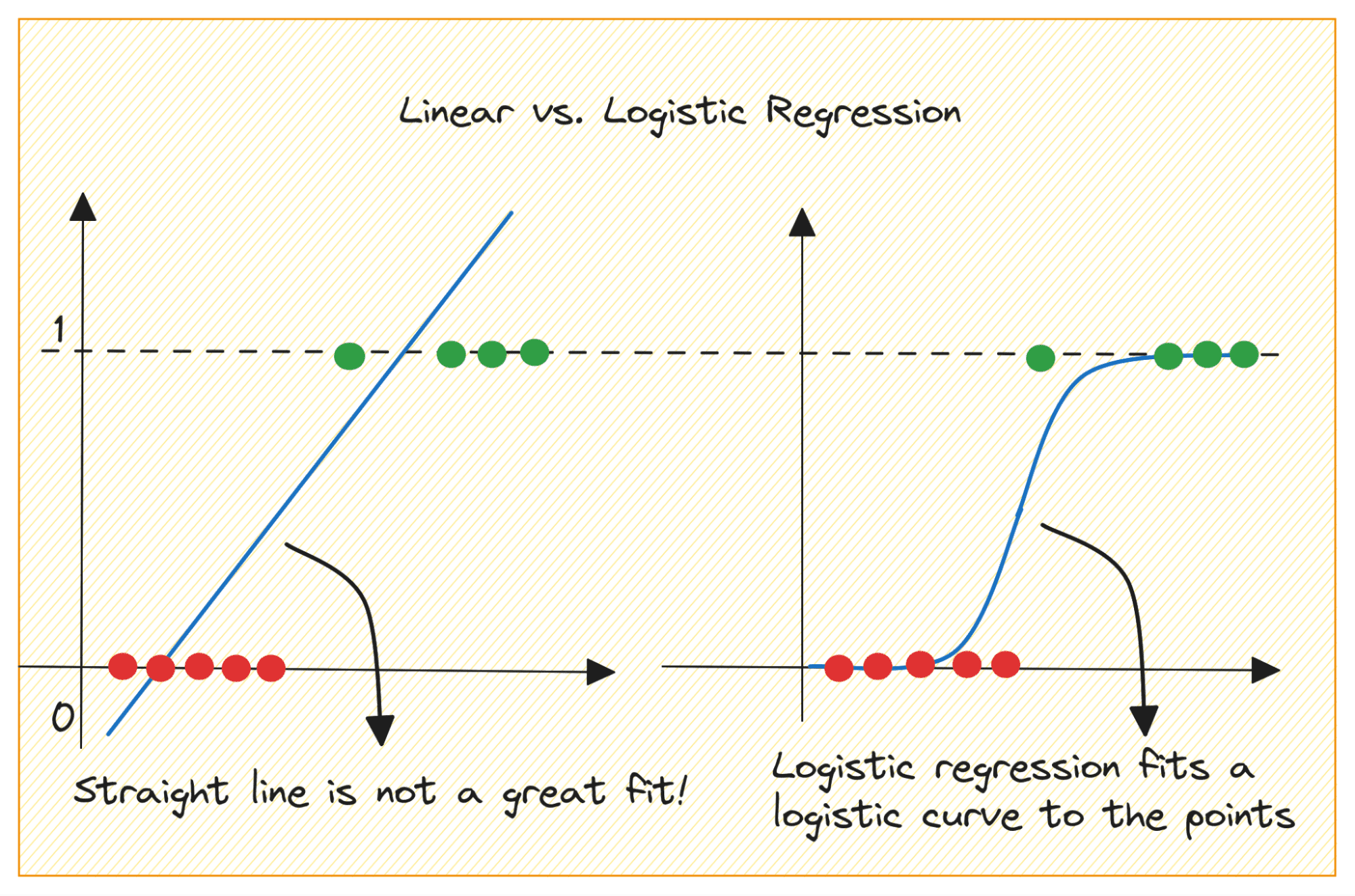
Imagen del autor
Entonces, ¿cómo pasamos de la regresión lineal a la logística? En regresión lineal, el resultado previsto viene dado por:
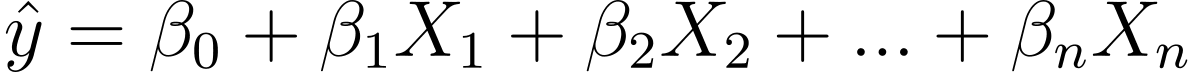
Donde los β son los coeficientes y X_is son los predictores (o características).
Sin pérdida de generalidad, supongamos X_0 = 1:

Entonces podemos tener una expresión más concisa:
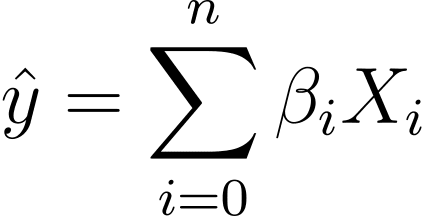
En regresión logística, necesitamos la probabilidad predicha p_i en el intervalo [0,1]. Sabemos que la función logística aplasta las entradas para que tomen valores en el intervalo [0,1].
Entonces, al conectar esta expresión a la función logística, tenemos la probabilidad predicha como:
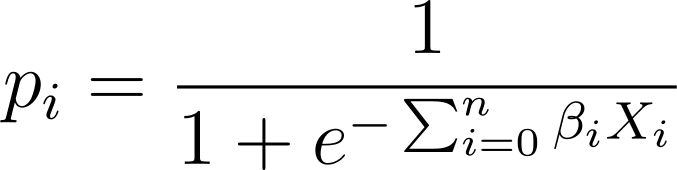
Entonces, ¿cómo encontramos la curva logística que mejor se ajusta al conjunto de datos dado? Para responder a esto, comprendamos la estimación de máxima verosimilitud.
Estimación de máxima verosimilitud (MLE) is used to estimate the parameters of the logistic regression model by maximizing the likelihood function. Let’s break down the process of MLE in logistic regression and how the cost function is formulated for optimization using gradient descent.
Desglose de la estimación de máxima verosimilitud
Como se analizó, modelamos la probabilidad de que ocurra un resultado binario en función de una o más variables predictoras (o características):
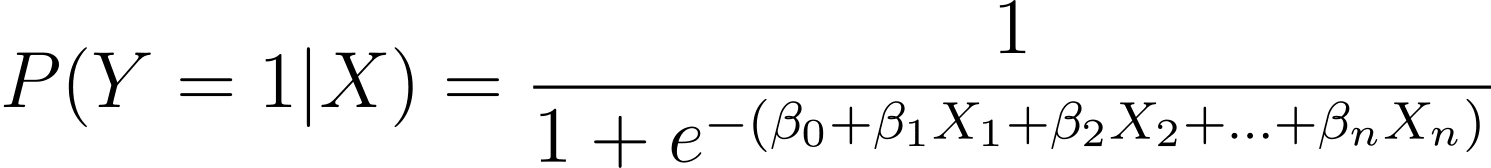
Here, the βs are the model parameters or coefficients. X_1, X_2,…, X_n are the predictor variables.
MLE tiene como objetivo encontrar los valores de β que maximicen la probabilidad de los datos observados. La función de verosimilitud, denotada como L(β), representa la probabilidad de observar los resultados dados para los valores predictivos dados bajo el modelo de regresión logística.
Formulación de la función logarítmica de verosimilitud
To simplify the optimization process, it’s common to work with the log-likelihood function. Because it transforms products of probabilities into sums of log probabilities.
La función de probabilidad logarítmica para la regresión logística viene dada por:
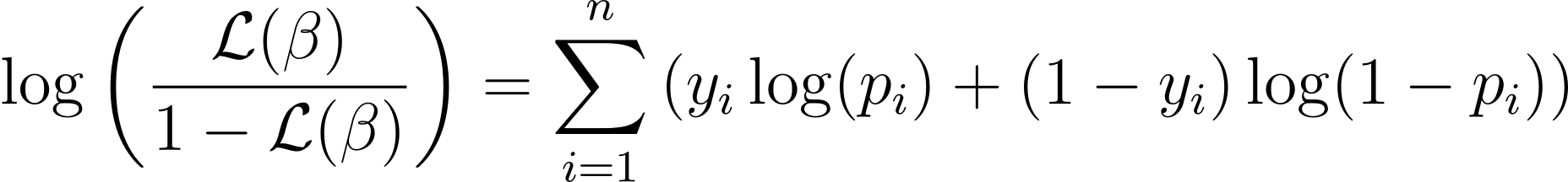
Now that we know the essence of log-likelihood, let’s proceed to formulate the cost function for logistic regression and subsequently gradient descent for finding the best model parameters
Función de costo para regresión logística
Para optimizar el modelo de regresión logística, debemos maximizar la probabilidad logarítmica. Por lo tanto, podemos utilizar la probabilidad logarítmica negativa como función de costo para minimizar durante el entrenamiento. La probabilidad logarítmica negativa, a menudo denominada pérdida logística, se define como:
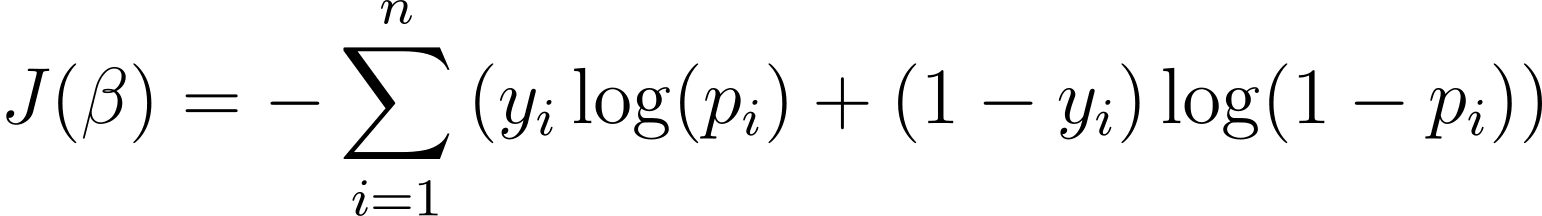
Por tanto, el objetivo del algoritmo de aprendizaje es encontrar los valores de ? que minimizan esta función de costos. El descenso de gradiente es un algoritmo de optimización comúnmente utilizado para encontrar el mínimo de esta función de costo.
Descenso de gradiente en regresión logística
Descenso de gradiente es un algoritmo de optimización iterativo que actualiza los parámetros del modelo β en la dirección opuesta al gradiente de la función de costo con respecto a β. La regla de actualización en el paso t+1 para la regresión logística mediante descenso de gradiente es la siguiente:
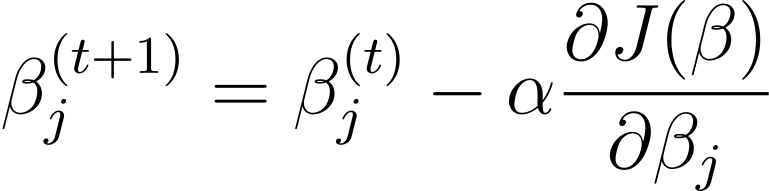
Donde α es la tasa de aprendizaje.
Las derivadas parciales se pueden calcular usando la regla de la cadena. El descenso de gradiente actualiza iterativamente los parámetros, hasta la convergencia, con el objetivo de minimizar la pérdida logística. A medida que converge, encuentra los valores óptimos de β que maximizan la probabilidad de los datos observados.
Ahora que sabe cómo funciona la regresión logística, creemos un modelo predictivo utilizando la biblioteca scikit-learn.
Usaremos el Conjunto de datos de la ionosfera del repositorio de aprendizaje automático de la UCI. para este tutorial. El conjunto de datos comprende 34 características numéricas. La salida es binaria, uno de "bueno" o "malo" (indicado por "g" o "b"). La etiqueta de salida "buena" se refiere a retornos de RADAR que han detectado alguna estructura en la ionosfera.
Paso 1: cargar el conjunto de datos
Primero, descargue el conjunto de datos y léalo en un marco de datos de pandas:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Paso 2: explorar el conjunto de datos
Let’s take a look at the first few rows of the dataframe:
# Display the first few rows of the DataFrame
df.head()
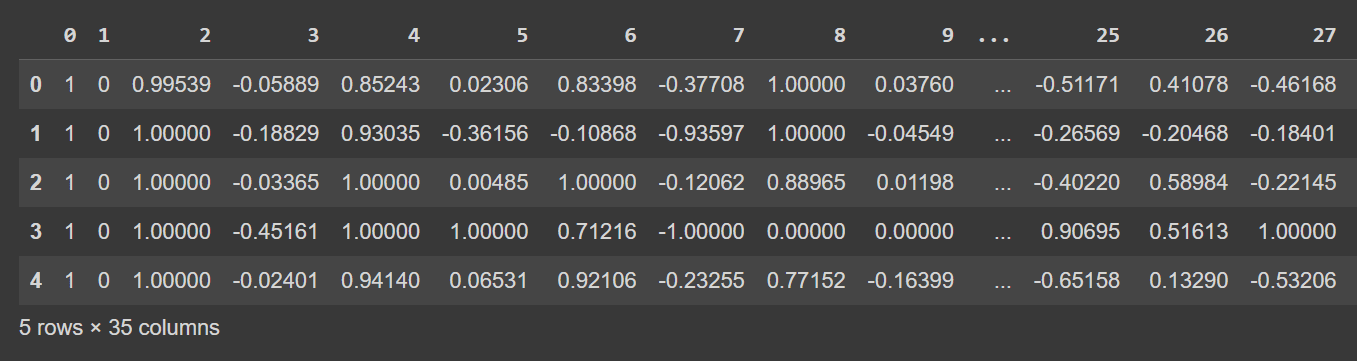
Salida truncada de df.head()
Let’s get some information about the dataset: the number of non-null values and the data types of each of the columns:
# Get information about the dataset
print(df.info())
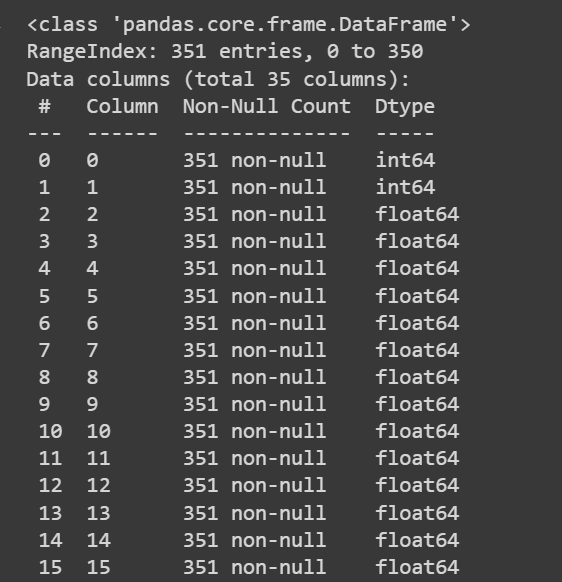 Salida truncada de df.info()
Salida truncada de df.info()
Debido a que tenemos todas las características numéricas, también podemos obtener algunas estadísticas descriptivas usando el describe() método en el marco de datos:
# Get descriptive statistics of the dataset
print(df.describe())
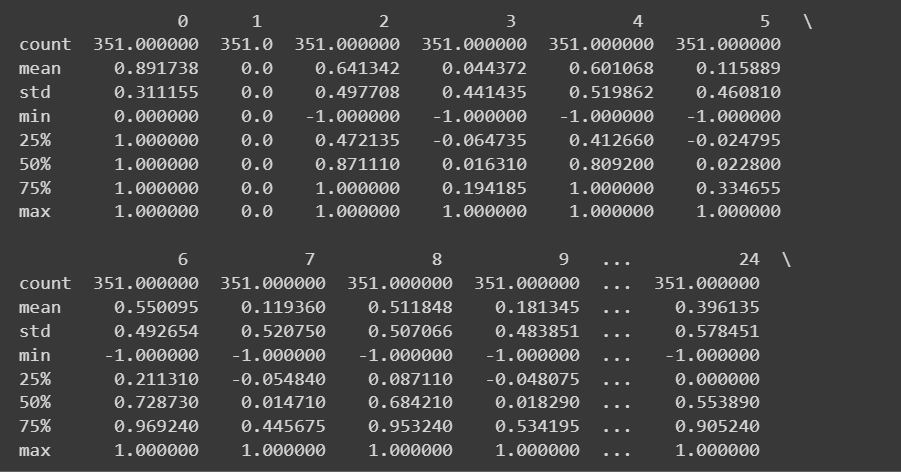
Salida truncada de df.describe()
Los nombres de las columnas actualmente van del 0 al 34, incluida la etiqueta. Debido a que el conjunto de datos no proporciona nombres descriptivos para las columnas, simplemente se refiere a ellas como atributo_1 a atributo_34. Si lo desea, puede cambiar el nombre de las columnas del marco de datos como se muestra:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Nota: Este paso es puramente opcional. Puede continuar con los nombres de columna predeterminados si lo prefiere.
# Display the first few rows of the DataFrame
df.head()
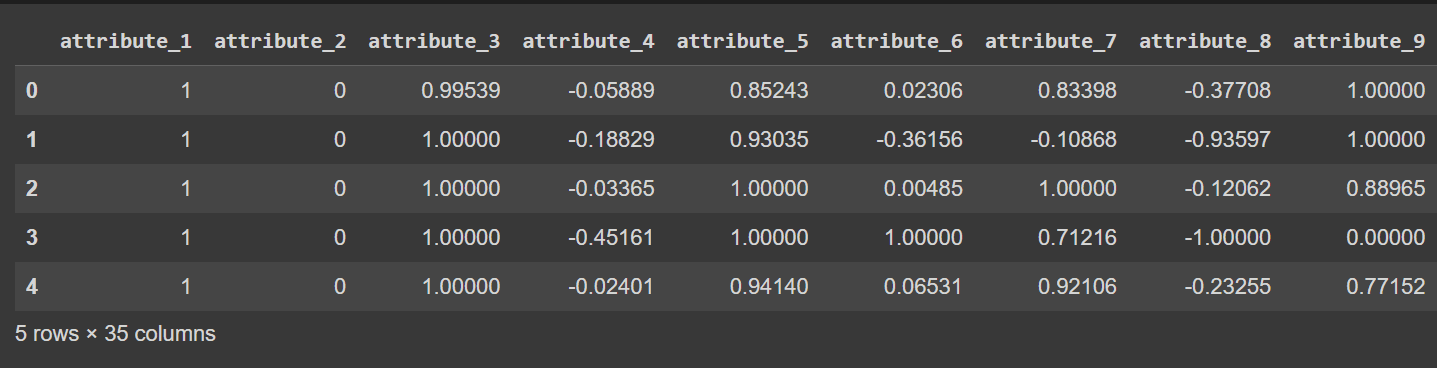
Salida truncada de df.head() [Después de cambiar el nombre de las columnas]
Paso 3: cambiar el nombre de las etiquetas de clase y visualizar la distribución de clases
Debido a que las etiquetas de clase de salida son "g" y "b", debemos asignarlas a 1 y 0, respectivamente. Puedes hacerlo usando map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Visualicemos también la distribución de las etiquetas de clase:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
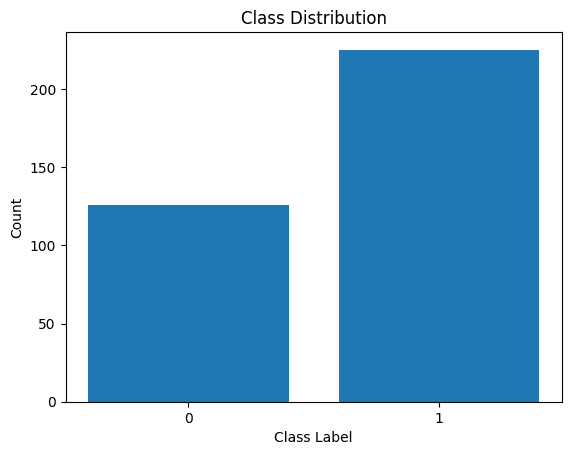
Distribución de etiquetas de clase
Vemos que hay un desequilibrio en la distribución. Hay más registros que pertenecen a la clase 1 que a la clase 0. Manejaremos este desequilibrio de clases al construir el modelo de regresión logística.
Paso 5: preprocesamiento del conjunto de datos
Recopilemos las características y las etiquetas de salida de esta manera:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Después de dividir el conjunto de datos en conjuntos de entrenamiento y de prueba, debemos preprocesar el conjunto de datos.
Cuando hay muchas características numéricas, cada una en una escala potencialmente diferente, necesitamos preprocesar las características numéricas. Un método común es transformarlos de modo que sigan una distribución con media cero y varianza unitaria.
El proyecto StandardScaler del módulo de preprocesamiento de scikit-learn nos ayuda a lograrlo.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Paso 6: construcción de un modelo de regresión logística
Ahora podemos crear una instancia de un clasificador de regresión logística. El LogisticRegression La clase es parte del módulo linear_model de scikit-learn.
Observe que hemos configurado el class_weight parámetro a "equilibrado". Esto nos ayudará a explicar el desequilibrio de clases. Asignando pesos a cada clase, inversamente proporcional al número de registros en las clases.
Después de crear una instancia de la clase, podemos ajustar el modelo al conjunto de datos de entrenamiento:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Paso 7: Evaluación del modelo de regresión logística
Puedes llamar al predict() método para obtener las predicciones del modelo.
Además de la puntuación de precisión, también podemos obtener un informe de clasificación con métricas como precisión, recuperación y puntuación F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
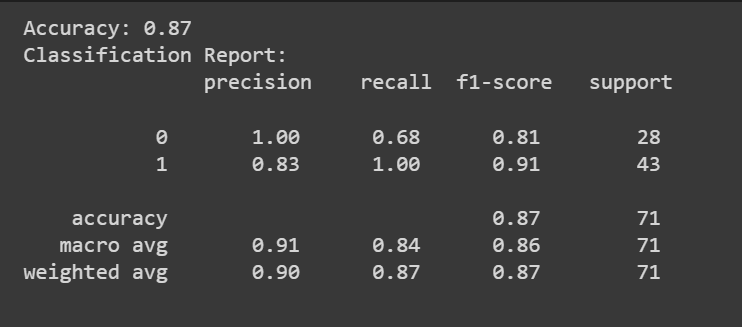
¡Felicitaciones, ha codificado su primer modelo de regresión logística!
En este tutorial, aprendimos en detalle sobre la regresión logística: desde la teoría y las matemáticas hasta la codificación de un clasificador de regresión logística.
Como siguiente paso, intente crear un modelo de regresión logística para un conjunto de datos adecuado de su elección.
El conjunto de datos Ionosphere tiene licencia bajo una Reconocimiento 4.0 internacional de Creative Commons Licencia (CC BY 4.0):
Sigillito, V., Wing, S., Hutton, L. y Baker, K. (1989). Ionosfera. Repositorio de aprendizaje automático de la UCI. https://doi.org/10.24432/C5W01B.
Bala Priya C. es un desarrollador y escritor técnico de la India. Le gusta trabajar en la intersección de matemáticas, programación, ciencia de datos y creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento de lenguaje natural. ¡Le gusta leer, escribir, codificar y tomar café! Actualmente, está trabajando para aprender y compartir su conocimiento con la comunidad de desarrolladores mediante la creación de tutoriales, guías prácticas, artículos de opinión y más.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :es
- :no
- $ UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- Nuestra Empresa
- Mi Cuenta
- la exactitud
- Lograr
- add
- adición
- Después
- paquete de capacitación DWoVH
- algoritmo
- algoritmos
- Todos
- también
- an
- y
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- enfoques
- somos
- áreas
- AS
- asumir
- At
- autoría
- b
- panadero
- Equilibrado
- de caramelos
- BE
- porque
- pertenencia
- MEJOR
- Descanso
- build
- Construir la
- by
- llamar al
- PUEDEN
- no puede
- categoría
- cadena
- manera?
- clase
- privadas
- clasificación
- codificado
- Codificación
- recoger
- Columna
- Columnas
- Algunos
- comúnmente
- Los comunes
- vibrante e inclusiva
- incluido
- conciso
- contenido
- creación de contenido
- convertir
- Cost
- cubierta
- Para crear
- creación
- En la actualidad
- curva
- datos
- puntos de datos
- Ciencia de los datos
- conjunto de datos
- Predeterminado
- se define
- Derivados
- detalle
- detectado
- Developer
- DevOps
- una experiencia diferente
- dirección
- discutir
- discutido
- Pantalla
- do
- sí
- DE INSCRIPCIÓN
- descargar
- durante
- cada una
- esencia
- estimación
- evaluación
- Experiencia
- Explorar
- expresión
- Caracteristicas
- pocos
- Encuentre
- la búsqueda de
- encuentra
- Nombre
- cómodo
- seguir
- siguiente
- FRAME
- Desde
- función
- obtener
- conseguir
- dado
- Go
- objetivo
- mayor
- Polo a Tierra
- Guías
- mano
- encargarse de
- Tienen
- ayuda
- ayuda
- aquí
- Cómo
- HTTPS
- ICS
- if
- desequilibrio
- importar
- in
- incluir
- índice
- India
- Indices
- información
- Las opciones de entrada
- entradas
- intereses
- interesante
- intersección
- dentro
- IT
- solo
- nuggets
- Saber
- especialistas
- Label
- Etiquetas
- idioma
- APRENDE:
- aprendido
- aprendizaje
- menos
- dejar
- Biblioteca
- Licencia
- Con licencia
- como
- probabilidad
- Me gusta
- línea
- carga
- log
- Mira
- parece
- de
- máquina
- máquina de aprendizaje
- para lograr
- muchos
- mapa
- las matemáticas
- matplotlib
- Maximizar
- maximizando
- máximas
- Puede..
- personalizado
- Método
- Métrica
- minimizar
- mínimo
- modelo
- modelos
- módulo
- más,
- movimiento
- nombres
- Natural
- Lenguaje natural
- Procesamiento natural del lenguaje
- ¿ Necesita ayuda
- negativas
- Next
- número
- observado
- of
- a menudo
- on
- ONE
- Opinión
- opuesto
- óptimo
- optimización
- Optimización
- or
- Resultado
- resultados
- salida
- salidas
- Los pandas
- parámetro
- parámetros
- parte
- piezas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- punto
- puntos
- la posibilidad
- Precisión
- previsto
- Predicciones
- profético
- Predictor
- Predice
- preferir
- probabilidades
- Problema
- proceder
- tratamiento
- Productos
- Programación
- proporcionar
- puramente
- Python
- radar
- distancia
- Rate
- Leer
- Reading
- real
- archivos
- referido
- se refiere
- regresión
- reporte
- repositorio
- representa
- solicita
- respeto
- respectivamente
- devoluciones
- una estrategia SEO para aparecer en las búsquedas de Google.
- robusto
- Regla
- s
- Ciencia:
- scikit-aprender
- Puntuación
- ver
- sentido
- set
- Sets
- compartir
- ella
- mostrado
- sencillos
- simplificar
- So
- algo
- dividido
- fundó
- statistics
- paso
- recto
- estructura
- Después
- tal
- adecuado
- sumas
- ¡Prepárate!
- toma
- Target
- tareas
- Técnico
- test
- Pruebas
- que
- esa
- El proyecto
- Les
- teoría
- Ahí.
- por lo tanto
- ellos
- así
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- a
- Herramientas
- Entrenar
- entrenado
- Formación
- Transformar
- transformadas
- try
- tutoriales
- Tutoriales
- dos
- tipos
- bajo
- entender
- unidad
- Actualizar
- Actualizaciones
- Enlance
- us
- cuenta de EE. UU.
- utilizan el
- usado
- usando
- propuesta de
- Valores
- visualizar
- we
- cuando
- que
- porque
- Wikipedia
- seguirá
- ala
- Actividades:
- trabajando
- funciona
- se
- escritor
- la escritura
- X
- si
- Usted
- tú
- zephyrnet
- cero







