En el post Presentación de la herramienta de costo total de propiedad del kit de entrega de migración de Hadoop de AWS ProServe, presentamos la herramienta TCO de AWS ProServe Hadoop Migration Delivery Kit (HMDK) y los beneficios de migrar cargas de trabajo de Hadoop locales a EMR de Amazon. En esta publicación, profundizamos en la herramienta, recorriendo todos los pasos desde la ingesta de registros, la transformación, la visualización y el diseño de la arquitectura para calcular el TCO.
Resumen de la solución
Visitemos brevemente las funciones clave de la herramienta HMDK TCO. La herramienta proporciona un recopilador de registros de YARN para conectar Hadoop Resource Manager para recopilar registros de YARN. Un analizador de carga de trabajo de Hadoop basado en Python, denominado analizador de registros YARN, analiza las aplicaciones de Hadoop. Amazon QuickSight Los tableros muestran los resultados del analizador. Los mismos resultados también aceleran el diseño de futuras instancias de EMR. Además, una calculadora de TCO genera la estimación de TCO de un clúster de EMR optimizado para facilitar la migración.
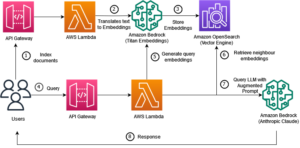
Ahora veamos cómo funciona la herramienta. El siguiente diagrama ilustra el flujo de trabajo de extremo a extremo.

En las siguientes secciones, repasamos los cinco pasos principales de la herramienta:
- Recopile registros del historial de trabajos de YARN.
- Transforme los registros del historial de trabajos de JSON a CSV.
- Analice los registros del historial de trabajos.
- Diseñe un clúster de EMR para la migración.
- Calcule el costo total de propiedad.
Requisitos previos
Antes de comenzar, asegúrese de completar los siguientes requisitos previos:
- Clona el repositorio hadoop-migration-assessment-tco.
- Instale Python 3 en su máquina local.
- Tener una cuenta de AWS con permiso en AWS Lambda, QuickSight (edición Enterprise) y Formación en la nube de AWS.
Recopilar registros del historial de trabajos de YARN
Primero, ejecuta un Colector de registros YARN, start-collector.sh, en su máquina local. Este paso recopila registros de Hadoop YARN y coloca los registros en su máquina local. El script conecta su máquina local con el nodo principal de Hadoop y se comunica con Resource Manager. Luego recupera la información del historial del trabajo (registros de YARN de los administradores de aplicaciones) llamando a la API de la aplicación ResourceManager de YARN.
Antes de ejecutar el recopilador de registros de YARN, debe configurar y establecer la conexión (HTTP: 8088 o HTTPS: 8090; se recomienda este último) para verificar la accesibilidad de YARN ResourceManager y el servidor de línea de tiempo de YARN habilitado (se admite el servidor de línea de tiempo v1 o posterior). ). Es posible que deba definir el intervalo de recopilación y la política de retención de los registros de YARN. Para asegurarse de recopilar registros de YARN consecutivos, puede usar un trabajo cron para programar el recopilador de registros en un intervalo de tiempo adecuado. Por ejemplo, para un clúster de Hadoop con 2,000 aplicaciones diarias y la configuración yarn.resourcemanager.max-completed-applications establecida en 1,000, en teoría, debe ejecutar el recopilador de registros al menos dos veces para obtener todos los registros de YARN. Además, recomendamos recopilar al menos 7 días de registros de YARN para analizar cargas de trabajo holísticas.
Para obtener más detalles sobre cómo configurar y programar el recopilador de registros, consulte el repositorio de GitHub de yarn-log-collector.
Transforme los registros del historial de trabajos de YARN de JSON a CSV
Después de obtener los registros de YARN, ejecute un organizador de registros de YARN, yarn-log-organizer.py, que es un analizador para transformar los registros basados en JSON en archivos CSV. Estos archivos CSV de salida son las entradas para el analizador de registros YARN. El analizador también tiene otras capacidades, incluida la clasificación de eventos por tiempo, la eliminación de dedicatorias y la fusión de varios registros.
Para obtener más información sobre cómo usar el organizador de registros YARN, consulte el repositorio de GitHub del organizador de registros de hilos.
Analizar los registros del historial de trabajos de YARN
A continuación, inicia el analizador de registros de YARN para analizar los registros de YARN en formato CSV.
Con QuickSight, puede visualizar los datos de registro de YARN y realizar análisis con los conjuntos de datos generados por las plantillas de panel preconstruidas y un widget. El widget crea automáticamente paneles de QuickSight en la cuenta de AWS de destino, que se configuró en una plantilla de CloudFormation.
El siguiente diagrama ilustra la arquitectura TCO de HMDK.

El analizador de registros YARN proporciona cuatro funcionalidades clave:
- Cargue los registros del historial de trabajos de YARN transformados en formato CSV (por ejemplo,
cluster_yarn_logs_*.csv) A Servicio de almacenamiento simple de Amazon (Amazon S3) baldes. Estos archivos CSV son los resultados del organizador de registros de YARN. - Cree un archivo JSON de manifiesto (por ejemplo,
yarn-log-manifest.json) para QuickSight y cárguelo en el depósito S3: - Implemente paneles de QuickSight con una plantilla de CloudFormation, que está en formato YAML. Después de la implementación, elija el icono de actualización hasta que vea el estado de la pila como
CREATE_COMPLETE. Este paso crea conjuntos de datos en paneles de QuickSight en su cuenta de destino de AWS.
- En el panel de QuickSight, puede encontrar información sobre las cargas de trabajo de Hadoop analizadas en varios gráficos. Esta información lo ayuda a diseñar futuras instancias de EMR para la aceleración de la migración, como se demuestra en el siguiente paso.

Diseñar un clúster de EMR para la migración
Los resultados del analizador de registros YARN lo ayudan a comprender las cargas de trabajo reales de Hadoop en el sistema existente. Este paso acelera el diseño de futuras instancias de EMR para la migración mediante el uso de un Plantilla de excel. La plantilla contiene una lista de verificación para realizar análisis de carga de trabajo y planificación de capacidad:
- ¿Las aplicaciones que se ejecutan en el clúster se utilizan adecuadamente con su capacidad actual?
- ¿El clúster está bajo carga en un momento determinado o no? Si es así, ¿cuándo es el momento?
- ¿Qué tipos de aplicaciones y motores (como MR, TEZ o Spark) se ejecutan en el clúster y cuál es el uso de recursos para cada tipo?
- ¿Se están ejecutando diferentes ciclos de ejecución de trabajos (en tiempo real, por lotes, ad hoc) en un clúster?
- ¿Hay trabajos que se ejecutan en lotes regulares y, de ser así, cuáles son estos intervalos de programación? (Por ejemplo, cada 10 minutos, 1 hora, 1 día). ¿Tiene trabajos que utilizan muchos recursos durante un período prolongado?
- ¿Algún trabajo necesita mejorar el rendimiento?
- ¿Existen organizaciones o individuos específicos que monopolizan el clúster?
- ¿Existen trabajos mixtos de desarrollo y operación en un clúster?
Después de completar la lista de verificación, comprenderá mejor cómo diseñar la arquitectura futura. Para optimizar la rentabilidad del clúster de EMR, la siguiente tabla proporciona pautas generales para elegir el tipo adecuado de clúster de EMR y Nube informática elástica de Amazon (Amazon EC2) familia.

Para elegir el tipo de clúster y la familia de instancias adecuados, debe realizar varias rondas de análisis en los registros de YARN en función de varios criterios. Veamos algunas métricas clave.
Cronograma
Puede encontrar patrones de carga de trabajo en función de la cantidad de aplicaciones de Hadoop que se ejecutan en una ventana de tiempo. Por ejemplo, los gráficos diarios o por hora "Recuento de registros por hora de inicio" brindan la siguiente información:
- En los gráficos de series temporales diarias, se compara el número de ejecuciones de aplicaciones entre días laborables y festivos, y entre días naturales. Si los números son similares, significa que las utilizaciones diarias del clúster son comparables. Por otro lado, si la desviación es grande, la proporción de trabajos ad hoc es significativa. También puede averiguar los posibles trabajos semanales o mensuales en días particulares. En la situación, puede ver fácilmente días específicos en una semana o un mes con alta concentración de carga de trabajo.
- En los gráficos de series temporales por hora, comprenderá mejor cómo se ejecutan las aplicaciones en ventanas por hora. Puede encontrar las horas pico y las horas valle en un día.
Usuarios
Los registros de YARN contienen el ID de usuario de cada aplicación. Esta información lo ayuda a comprender quién envía una solicitud a una cola. En función de las estadísticas de ejecuciones de aplicaciones individuales y agregadas por cola y por usuario, puede determinar la distribución de la carga de trabajo existente por usuario. Por lo general, los usuarios del mismo equipo tienen colas compartidas. En algún momento, varios equipos han compartido colas. Al diseñar colas para usuarios, ahora tiene información que le ayudará a diseñar y distribuir cargas de trabajo de aplicaciones que están más equilibradas entre colas que antes.
Tipos de aplicación
Puede segmentar las cargas de trabajo según varios tipos de aplicaciones (como Hive, Spark, Presto o HBase) y ejecutar motores (como MR, Spark o Tez). Para las cargas de trabajo de cómputo pesado, como trabajos de MapReduce o Hive-on-MR, use instancias optimizadas para CPU. Para cargas de trabajo con uso intensivo de memoria, como trabajos de Hive-on-TEZ, Presto y Spark, use instancias optimizadas para memoria.
Tiempo transcurrido
Puede clasificar las aplicaciones por tiempo de ejecución. La plantilla integrada de CloudFormation crea automáticamente un campo de grupo transcurrido en un tablero de QuickSight. Esto habilita una característica clave que le permite observar trabajos de ejecución prolongada en uno de los cuatro gráficos en los paneles de control de QuickSight. Por lo tanto, puede diseñar futuras arquitecturas personalizadas para estos grandes trabajos.
Los tableros QuickSight correspondientes incluyen cuatro gráficos. Puede desglosar cada gráfico, que está asociado a un grupo.
| Grupo procesos Número |
Tiempo de ejecución/tiempo transcurrido de un trabajo |
| 1 | Menos de 10 minutos |
| 2 | Entre 10 minutos y 30 minutos |
| 3 | entre 30 minutos y 1 hora |
| 4 | Más de 1 hora |
En el gráfico del Grupo 4, puede concentrarse en examinar trabajos grandes en función de varias métricas, incluido el usuario, la cola, el tipo de aplicación, la escala de tiempo, el uso de recursos, etc. Según esta consideración, puede tener colas dedicadas en un clúster o un clúster de EMR dedicado para trabajos grandes. Mientras tanto, puede enviar trabajos pequeños a colas compartidas.
Recursos
En función de los patrones de consumo de recursos (CPU, memoria), elige el tamaño y la familia de instancias EC2 adecuados para obtener rendimiento y rentabilidad. Para aplicaciones con uso intensivo de recursos informáticos, recomendamos instancias de familias optimizadas para CPU. Para las aplicaciones que hacen un uso intensivo de la memoria, se recomiendan las familias de instancias optimizadas para memoria.
Además, según la naturaleza de las cargas de trabajo de la aplicación y la utilización de los recursos a lo largo del tiempo, puede elegir un clúster de EMR persistente o transitorio, Amazon EMR en EKSo Amazon EMR sin servidor.
Después de analizar los registros de YARN según varias métricas, estará listo para diseñar futuras arquitecturas de EMR. La siguiente tabla enumera ejemplos de clústeres de EMR propuestos. Puedes encontrar más detalles en el repositorio optimizado de tco-calculator de GitHub.

Calcular costo total de propiedad
Finalmente, en su máquina local, ejecute tco-input-generator.py para agregar registros de historial de trabajos de YARN cada hora antes de usar una plantilla de Excel para calcular el TCO optimizado. Este paso es crucial porque los resultados simulan las cargas de trabajo de Hadoop en futuras instancias de EMR.
El requisito previo de la simulación TCO es ejecutar tco-input-generator.py, que genera registros agregados por hora. A continuación, abre un archivo de plantilla de Excel para habilitar macros y proporciona sus entradas en celdas verdes para calcular el TCO. Con respecto a los datos de entrada, ingresa el tamaño real de los datos sin replicación y las especificaciones de hardware (vCore, mem) del nodo principal y los nodos de datos de Hadoop. También debe seleccionar y cargar registros agregados por hora generados previamente. Después de configurar las variables de simulación de TCO, como Región, tipo de EC2, alta disponibilidad de Amazon EMR, efecto de motor, descuento de Amazon EC2 y Amazon EBS (EDP), descuento por volumen de Amazon S3, tasa de moneda local y relación de precios principal/tarea de EMR EC2 y precio/hora, el simulador TCO calcula automáticamente el costo óptimo de futuras instancias de EMR en Amazon EC2. Las siguientes capturas de pantalla muestran un ejemplo de resultados de TCO de HMDK.

Para obtener información adicional e instrucciones sobre los cálculos del TCO de HMDK, consulte el repositorio optimizado de tco-calculator de GitHub.
Limpiar
Después de completar todos los pasos y terminar la prueba, complete los siguientes pasos para eliminar recursos y evitar incurrir en costos:
- En la consola de AWS CloudFormation, elija la pila que creó.
- Elige Borrar.
- Elige Eliminar pila.
- Actualice la página hasta que vea el estado
DELETE_COMPLETE. - En la consola de Amazon S3, elimine el depósito de S3 que creó.
Conclusión
La herramienta TCO de AWS ProServe HMDK reduce significativamente los esfuerzos de planificación de la migración, que son las tareas desafiantes y que requieren mucho tiempo para evaluar sus cargas de trabajo de Hadoop. Con la herramienta HMDK TCO, la evaluación suele tardar de 2 a 3 semanas. También puede determinar el TCO calculado de futuras arquitecturas EMR. Con la herramienta HMDK TCO, puede comprender rápidamente sus cargas de trabajo y patrones de uso de recursos. Con los conocimientos generados por la herramienta, está equipado para diseñar futuras arquitecturas EMR óptimas. En muchos casos de uso, un TCO de 1 año de la arquitectura refactorizada optimizada proporciona ahorros de costos significativos (reducción del 64% al 80%) en cómputo y almacenamiento, en comparación con las migraciones de Hadoop de elevación y cambio.
Para obtener más información sobre cómo acelerar sus migraciones de Hadoop a Amazon EMR y la herramienta HMDK CTO, consulte la Repositorio GitHub del TCO del kit de entrega de migración de Hadoop, o comuníquese con AWS-HMDK@amazon.com.
Sobre los autores
 Parque Sungyoul es gerente sénior de prácticas en AWS ProServe. Ayuda a los clientes a innovar sus negocios con los servicios de AWS Analytics, IoT y AI/ML. Tiene una especialidad en servicios y tecnologías de big data y un interés en construir juntos los resultados comerciales de los clientes.
Parque Sungyoul es gerente sénior de prácticas en AWS ProServe. Ayuda a los clientes a innovar sus negocios con los servicios de AWS Analytics, IoT y AI/ML. Tiene una especialidad en servicios y tecnologías de big data y un interés en construir juntos los resultados comerciales de los clientes.
 kim jiseong es Arquitecto de datos sénior en AWS ProServe. Trabaja principalmente con clientes empresariales para ayudar en la migración y modernización del lago de datos, y brinda orientación y asistencia técnica en proyectos de big data como Hadoop, Spark, almacenamiento de datos, procesamiento de datos en tiempo real y aprendizaje automático a gran escala. También entiende cómo aplicar tecnologías para resolver problemas de big data y construir una arquitectura de datos bien diseñada.
kim jiseong es Arquitecto de datos sénior en AWS ProServe. Trabaja principalmente con clientes empresariales para ayudar en la migración y modernización del lago de datos, y brinda orientación y asistencia técnica en proyectos de big data como Hadoop, Spark, almacenamiento de datos, procesamiento de datos en tiempo real y aprendizaje automático a gran escala. También entiende cómo aplicar tecnologías para resolver problemas de big data y construir una arquitectura de datos bien diseñada.
 George Zhao es Arquitecto de datos sénior en AWS ProServe. Es un líder analítico experimentado que trabaja con clientes de AWS para ofrecer soluciones de datos modernas. También es un especialista en dominios de ProServe Amazon EMR que capacita a los consultores de ProServe sobre mejores prácticas y kits de entrega para migraciones de Hadoop a Amazon EMR. Su área de interés son los lagos de datos y la entrega de arquitectura de datos moderna en la nube.
George Zhao es Arquitecto de datos sénior en AWS ProServe. Es un líder analítico experimentado que trabaja con clientes de AWS para ofrecer soluciones de datos modernas. También es un especialista en dominios de ProServe Amazon EMR que capacita a los consultores de ProServe sobre mejores prácticas y kits de entrega para migraciones de Hadoop a Amazon EMR. Su área de interés son los lagos de datos y la entrega de arquitectura de datos moderna en la nube.
 kalen zhang fue el líder tecnológico del segmento global de datos y análisis de socios en AWS. Como asesora confiable de datos y análisis, seleccionó iniciativas estratégicas para la transformación de datos, lideró programas de modernización y migración de cargas de trabajo de datos y análisis, y aceleró los viajes de migración de clientes con socios a escala. Se especializa en sistemas distribuidos, gestión de datos empresariales, análisis avanzado e iniciativas estratégicas a gran escala.
kalen zhang fue el líder tecnológico del segmento global de datos y análisis de socios en AWS. Como asesora confiable de datos y análisis, seleccionó iniciativas estratégicas para la transformación de datos, lideró programas de modernización y migración de cargas de trabajo de datos y análisis, y aceleró los viajes de migración de clientes con socios a escala. Se especializa en sistemas distribuidos, gestión de datos empresariales, análisis avanzado e iniciativas estratégicas a gran escala.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- Poder
- Nuestra Empresa
- acelerar
- acelerado
- acelera
- acelerador
- aceleración
- accesibilidad
- Mi Cuenta
- a través de
- Ad
- adición
- Adicionales
- Información adicional
- Adicionalmente
- avanzado
- tutor
- Después
- en contra
- AI / ML
- Todos
- Amazon
- Amazon EC2
- EMR de Amazon
- entre
- análisis
- Analytics
- analizar
- el análisis de
- y
- abejas
- Aplicación
- aplicaciones
- Aplicá
- adecuadamente
- arquitectura
- Reservada
- evaluación
- Ayuda
- asociado
- automáticamente
- disponibilidad
- AWS
- Formación en la nube de AWS
- basado
- base
- porque
- "Ser"
- beneficios
- MEJOR
- y las mejores prácticas
- mejores
- entre
- Big
- Big Data
- brevemente
- build
- Construir la
- calcular
- calculado
- calcula
- el cálculo de
- Calendario
- , que son
- llamar
- capacidades
- Capacidad
- cases
- Células
- a ciertos
- desafiante
- Tabla
- Gráficas
- Elige
- la elección de
- Soluciones
- Médico
- recoger
- El cobro
- --
- coleccionista
- colecciona
- COM
- comparable
- comparar
- en comparación con
- completar
- Calcular
- concentrarse
- concentración
- Conducir
- conductible
- Contacto
- conexión
- conecta
- consecutivo
- consideración
- Consola
- consultores
- consumo
- contiene
- Correspondiente
- Cost
- ahorro de costes
- Precio
- CPU
- creado
- crea
- criterios
- crucial
- CTO
- comisariada
- Moneda
- Current
- cliente
- Clientes
- de ciclos
- todos los días
- página de información de sus operaciones
- datos
- Lago de datos
- datos de gestión
- proceso de datos
- conjuntos de datos
- día
- Días
- a dedicados
- profundo
- bucear profundo
- entregamos
- entrega
- demostrado
- Desplegando
- Diseño
- diseño
- detalles
- Determinar
- Desarrollo
- desviación
- una experiencia diferente
- El descuento
- distribuir
- distribuidos
- sistemas distribuidos
- dominio
- DE INSCRIPCIÓN
- durante
- cada una
- pasan fácilmente
- ebs
- edición
- efecto
- eficacia
- esfuerzos
- integrado
- habilitar
- facilita
- permite
- de extremo a extremo
- Motor
- motores
- garantizar
- Participar
- Empresa
- clientes empresariales
- equipado
- establecer
- Éter (ETH)
- Eventos
- Cada
- ejemplo
- ejemplos
- Excel
- existente
- experimentado
- facilitando
- familias
- familia
- Feature
- Caracteristicas
- campo
- Figura
- Archive
- archivos
- Encuentre
- acabado
- siguiendo
- formato
- Desde
- funcionalidades
- promover
- futuras
- General
- generado
- genera
- obtener
- conseguir
- GitHub
- Buscar
- Verde
- Grupo procesos
- orientaciones
- Hadoop
- Materiales
- ayuda
- ayuda
- Alta
- historia
- Colmena
- días festivos
- holístico
- HORAS
- Cómo
- Como Hacer
- HTML
- HTTPS
- ICON
- es la mejora continua
- in
- incluir
- Incluye
- INSTRUMENTO individual
- individuos
- información
- iniciativas
- innovar
- Las opciones de entrada
- Insights
- ejemplo
- Instrucciones
- intereses
- intereses
- Introducido
- IOT
- IT
- Trabajos
- Empleo
- Viajes
- json
- Clave
- kit
- lago
- large
- Gran escala
- lanzamiento
- Lead
- líder
- APRENDE:
- aprendizaje
- LED
- Datos LED
- Listas
- carga
- local
- Largo
- largo tiempo
- Mira
- Lote
- máquina
- máquina de aprendizaje
- macros
- Inicio
- para lograr
- Management
- gerente
- Managers
- muchos
- significa
- Mientras tanto
- Salud Cerebral
- la fusión de
- Métrica
- migración
- minutos
- mezclado
- Moderno
- modernización
- Mes
- mensual
- más,
- múltiples
- Naturaleza
- ¿ Necesita ayuda
- Next
- nodo
- nodos
- número
- números
- observar
- obtención
- ONE
- habiertos
- funcionamiento
- Inteligente
- óptimo
- optimizado
- optimizando
- óptimo
- para las fiestas.
- Otro
- particular
- Socio
- socios
- .
- En pleno
- realizar
- actuación
- período
- permiso
- Lugares
- planificar
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- política
- posible
- Publicación
- prácticas
- requisitos previos
- previamente
- cotización
- primario
- Anterior
- problemas
- tratamiento
- Programas
- proyecta
- apropiado
- propuesto
- proporcionar
- proporciona un
- Python
- con rapidez
- Rate
- proporción
- en comunicarse
- ready
- en tiempo real
- datos en tiempo real
- recomiendan
- recomendado
- archivos
- reduce
- con respecto a
- región
- regular
- la eliminación de
- replicación
- Recurso
- Recursos
- Resultados
- retención
- rondas
- Ejecutar
- correr
- mismo
- Ahorros
- Escala
- programa
- capturas de pantalla
- (secciones)
- segmento
- mayor
- Serie
- Servicios
- set
- pólipo
- Varios
- compartido
- Mostrar
- mostrar
- importante
- significativamente
- similares
- sencillos
- simulación
- simulador
- situación
- Tamaño
- chica
- So
- Soluciones
- RESOLVER
- algo
- Spark
- especialista
- se especializa
- CURSOS
- soluciones y
- Especificaciones
- montón
- fundó
- statistics
- Estado
- paso
- pasos
- STORAGE
- Estratégico
- enviar
- tal
- Soportado
- te
- Todas las funciones a su disposición
- mesa
- adaptado
- toma
- Target
- tareas
- equipo
- equipos
- tecnología
- Técnico
- Tecnologías
- plantilla
- plantillas
- Pruebas
- La
- El futuro de las
- su
- por lo tanto
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- Series de tiempo
- prolongado
- calendario
- a
- juntos
- del IRS
- Transformar
- transformado
- verdadero
- de confianza
- tipos
- bajo
- entender
- comprensión
- entiende
- Uso
- utilizan el
- Usuario
- usuarios
- generalmente
- diversos
- verificar
- visualización
- volumen
- a pie
- Almacenamiento
- semana
- una vez por semana
- Semanas
- ¿
- Que es
- que
- QUIENES
- ventanas
- sin
- flujo de trabajo
- trabajando
- funciona
- yaml
- tú
- zephyrnet