¿Con qué frecuencia los proyectos de aprendizaje automático logran una implementación exitosa? No con suficiente frecuencia. Hay mucho of energético la investigación demostración que los proyectos de aprendizaje automático comúnmente no logran generar retornos, pero muy pocos han medido la proporción entre fracaso y éxito desde la perspectiva de los científicos de datos: las personas que desarrollan los mismos modelos que estos proyectos deben implementar.
En seguimiento de una encuesta de científicos de datos que realicé con KDnuggets el año pasado, La encuesta sobre ciencia de datos líder en la industria de este año dirigido por la consultora de aprendizaje automático Rexer Analytics abordó la pregunta, en parte porque Karl Rexer, el fundador y presidente de la compañía, permitió que un servidor participara, impulsando la inclusión de preguntas sobre el éxito de la implementación (parte de mi trabajo durante una cátedra de análisis de un año que ocupé en UVA Darden).
La noticia no es buena. Sólo el 22% de los científicos de datos dicen que sus iniciativas “revolucionarias” (modelos desarrollados para permitir un nuevo proceso o capacidad) generalmente se implementan. El 43% dice que el 80% o más no logra implementar.
A través de todos tipos de proyectos de aprendizaje automático (incluidos modelos de actualización para implementaciones existentes), solo el 32 % dice que sus modelos se implementan habitualmente.
A continuación se muestran los resultados detallados de esa parte de la encuesta, presentados por Rexer Analytics, desglosando las tasas de implementación en tres tipos de iniciativas de ML:
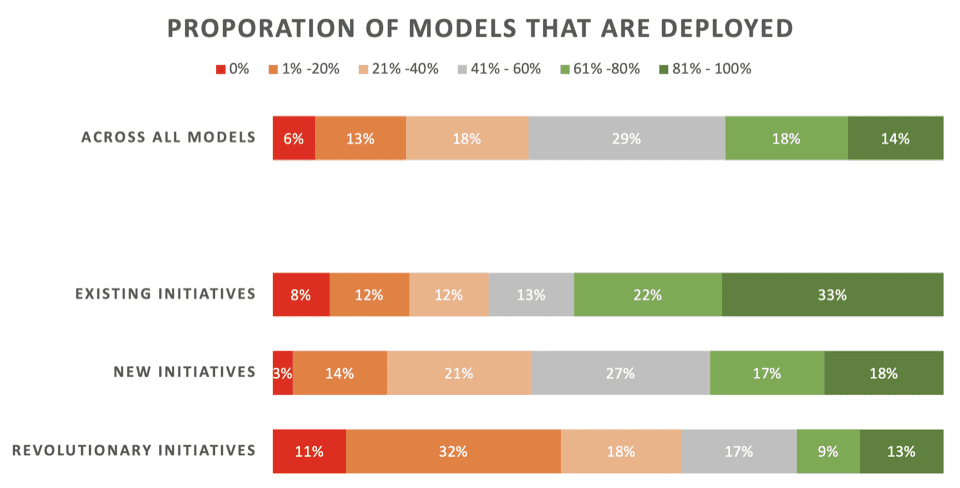
Llave:
- Iniciativas existentes: Modelos desarrollados para actualizar/actualizar un modelo existente que ya se ha implementado con éxito
- Nuevas iniciativas: Modelos desarrollados para mejorar un proceso existente para el cual aún no se había implementado ningún modelo.
- Iniciativas revolucionarias: Modelos desarrollados para habilitar un nuevo proceso o capacidad.
En mi opinión, esta lucha por el despliegue se debe a dos factores principales que contribuyen: la falta de planificación endémica y la falta de visibilidad concreta de las partes interesadas del sector empresarial. Muchos profesionales de datos y líderes empresariales no han llegado a reconocer que la puesta en funcionamiento prevista del ML debe planificarse con gran detalle y perseguirse agresivamente desde el inicio de cada proyecto de ML.
De hecho, he escrito un nuevo libro sobre eso: El libro de estrategias de la IA: dominar el raro arte de la implementación del aprendizaje automático. En este libro, presento una práctica de seis pasos centrada en la implementación para impulsar proyectos de aprendizaje automático desde la concepción hasta la implementación, a la que llamo bizML (reserva la tapa dura o el libro electrónico y reciba una copia avanzada gratuita de la versión del audiolibro de inmediato).
La parte interesada clave de un proyecto de ML (la persona a cargo de la eficacia operativa que se pretende mejorar, como un gerente de línea de negocio) necesita visibilidad sobre cómo ML mejorará sus operaciones y cuánto valor se espera que genere la mejora. Necesitan esto para, en última instancia, dar luz verde a la implementación de un modelo y, antes de eso, opinar sobre la ejecución del proyecto durante las etapas previas a la implementación.
¡Pero el rendimiento del ML a menudo no se mide! Cuando la encuesta de Rexer preguntó: "¿Con qué frecuencia su empresa/organización mide el desempeño de los proyectos analíticos?" Sólo el 48% de los científicos de datos dijeron "Siempre" o "La mayor parte del tiempo". Eso es bastante salvaje. Debería ser más bien del 99% o del 100%.
Y cuando se mide el desempeño, es en términos de métricas técnicas que son misteriosas y en su mayoría irrelevantes para las partes interesadas del negocio. Los científicos de datos lo saben mejor, pero generalmente no lo cumplen, en parte porque las herramientas de aprendizaje automático generalmente solo ofrecen métricas técnicas. Según la encuesta, los científicos de datos clasifican los KPI empresariales como el ROI y los ingresos como las métricas más importantes, pero enumeran métricas técnicas como el lift y el AUC como las que se miden con más frecuencia.
Las métricas de desempeño técnico son “fundamentalmente inútiles y desconectadas de las partes interesadas del negocio”, según Revisión de ciencia de datos de Harvard. He aquí por qué: solo te dicen el relativo rendimiento de un modelo, como cómo se compara con las conjeturas u otra línea de base. Las métricas comerciales le indican el fotometría absoluta) valor empresarial que se espera que proporcione el modelo o, al evaluarlo después de su implementación, que ha demostrado ofrecer. Estas métricas son esenciales para proyectos de aprendizaje automático centrados en la implementación.
Más allá del acceso a las métricas empresariales, las partes interesadas también deben intensificar sus esfuerzos. Cuando la encuesta de Rexer preguntó: "¿Los gerentes y tomadores de decisiones de su organización que deben aprobar la implementación del modelo tienen en general el conocimiento suficiente para tomar tales decisiones de manera bien informada?" Sólo el 49% de los encuestados respondió “La mayor parte del tiempo” o “Siempre”.
Esto es lo que creo que está sucediendo. El “cliente” del científico de datos, la parte interesada del negocio, a menudo se resiste cuando se trata de autorizar la implementación, ya que significaría realizar un cambio operativo significativo en el pan de cada día de la empresa, sus procesos de mayor escala. No tienen el marco contextual. Por ejemplo, se preguntan: “¿Cómo voy a entender en qué medida ayudará realmente este modelo, que tiene un rendimiento muy inferior a la perfección de una bola de cristal?” Así el proyecto muere. Luego, dar creativamente algún tipo de giro positivo a los “conocimientos adquiridos” sirve para barrer cuidadosamente el fracaso debajo de la alfombra. El entusiasmo por la IA permanece intacto incluso cuando se pierde el valor potencial, el propósito del proyecto.
Sobre este tema (aumentar las partes interesadas), publicaré mi nuevo libro, El manual de la IA, sólo una vez más. Si bien cubre la práctica de bizML, el libro también mejora las habilidades de los profesionales de negocios al brindarles una dosis vital pero amigable de conocimientos previos semitécnicos que todas las partes interesadas necesitan para liderar o participar en proyectos de aprendizaje automático, de principio a fin. Esto pone a los profesionales de negocios y de datos en la misma página para que puedan colaborar profundamente, estableciendo conjuntamente con precisión Qué debe predecir el aprendizaje automático, qué tan bien predice y cómo se aplican sus predicciones para mejorar las operaciones.. Estos elementos esenciales hacen o deshacen cada iniciativa; hacerlos bien allana el camino para la implementación impulsada por el valor del aprendizaje automático.
Es seguro decir que las cosas son difíciles, especialmente para las nuevas iniciativas de aprendizaje automático que son de primer intento. A medida que la fuerza pura del entusiasmo por la IA pierde su capacidad de compensar continuamente
menos valor obtenido del prometido, habrá cada vez más presión para demostrar el valor operativo del ML. Por eso les digo que se adelanten a esto ahora: ¡comience a inculcar una cultura más eficaz de colaboración entre empresas y liderazgo de proyectos orientado a la implementación!
Para obtener resultados más detallados de la Encuesta sobre ciencia de datos de Rexer Analytics 2023, haga clic esta página. Esta es la encuesta más grande de profesionales de análisis y ciencia de datos de la industria. Consta de aproximadamente 35 preguntas abiertas y de opción múltiple que cubren mucho más que solo las tasas de éxito de la implementación: siete áreas generales de la ciencia y la práctica de la minería de datos: (1) Campo y objetivos, (2) Algoritmos, (3) Modelos, ( 4) Herramientas (paquetes de software utilizados), (5) Tecnología, (6) Retos y (7) Futuro. Se lleva a cabo como un servicio (sin patrocinio corporativo) para la comunidad científica de datos y los resultados generalmente se anuncian en la conferencia de la Semana del Aprendizaje Automático y se comparte a través de informes resumidos disponibles gratuitamente.
Este artículo es producto del trabajo del autor mientras ocupó un puesto de un año como profesor de análisis del Bicentenario del Cuerpo en la Escuela de Negocios Darden de la UVA, que finalmente culminó con la publicación de El libro de estrategias de la IA: dominar el raro arte de la implementación del aprendizaje automático (oferta de audiolibro gratis).
eric siegel, Ph.D., es un consultor líder y ex profesor de la Universidad de Columbia que hace que el aprendizaje automático sea comprensible y cautivador. Es el fundador de la Mundo de análisis predictivo y del Mundo del aprendizaje profundo serie de conferencias, que han atendido a más de 17,000 asistentes desde 2009, el instructor del aclamado curso Liderazgo y práctica de aprendizaje automático: dominio de extremo a extremo, un orador popular que ha recibido el encargo de Más de 100 discursos de aperturay editor ejecutivo de Los tiempos del aprendizaje automático. Fue autor del bestseller Análisis predictivo: el poder de predecir quién hará clic, comprará, mentirá o morirá, que se ha utilizado en cursos en más de 35 universidades, y ganó premios de enseñanza cuando era profesor en la Universidad de Columbia, donde cantó canciones educativas a sus alumnos. Eric también publica artículos de opinión sobre análisis y justicia social. Síguelo en @predictanalytic.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- :posee
- :es
- :no
- :dónde
- $ UP
- 000
- 1
- 17
- 35%
- 7
- a
- capacidad
- Nuestra Empresa
- de la máquina
- aclamado
- Conforme
- a través de
- dirigido
- avanzado
- Después
- agresivamente
- adelante
- AI
- algoritmos
- Todos
- permitido
- ya haya utilizado
- también
- hacerlo
- am
- an
- Analítico
- Analytics
- y
- anunció
- Otra
- aprobar
- aproximadamente
- Arcane
- somos
- áreas
- Arte
- artículo
- AS
- At
- asistentes
- ninguna
- fue autor
- Hoy Disponibles
- premios
- lejos
- fondo
- Base
- BE
- porque
- esto
- antes
- CREEMOS
- más vendido
- mejores
- primer libro
- Pan
- Descanso
- Ruptura
- Líderes del negocio
- pero
- comprar
- by
- llamar al
- , que son
- PUEDEN
- capacidad
- cautivador
- retos
- el cambio
- CHARGE
- manera?
- clic
- cliente
- frío
- colaboran
- colaboración
- Columbia
- COM
- cómo
- proviene
- comúnmente
- vibrante e inclusiva
- compañía
- De la empresa
- concepción
- hormigón
- llevado a cabo
- Congreso
- consiste
- Consultancy
- consultor
- contextual
- continuamente
- contribuyendo
- Sector empresarial
- curso
- cursos
- Protectora
- cubierta
- Creativamente
- cs
- Cultura
- datos
- la minería de datos
- Ciencia de los datos
- científico de datos
- tomadores de decisiones
- decisiones
- profundamente
- entregamos
- entregar
- desplegar
- desplegado
- despliegue
- Despliegues
- detalle
- detallado
- desarrollar
- desarrollado
- desconectado
- do
- sí
- don
- No
- dosificar
- DE INSCRIPCIÓN
- conducción
- durante
- cada una
- editor
- Eficaz
- eficacia
- habilitar
- final
- de extremo a extremo
- endémico
- mejorar
- suficientes
- Eric
- especialmente
- esencial
- esenciales
- el establecimiento
- Éter (ETH)
- evaluación
- Incluso
- Cada
- ejemplo
- ejecución
- ejecutivos
- existente
- esperado
- hecho
- factores importantes
- FALLO
- Fracaso
- muchos
- Pies
- pocos
- campo
- seguir
- FORCE
- Ex
- fundador
- Marco conceptual
- Gratuito
- sin restricciones
- amigable
- Desde
- futuras
- ganado
- General
- en general
- obtener
- conseguir
- Goals
- maravillosa
- En Curso
- Tienen
- he
- Retenida
- ayuda
- su
- Cómo
- HTML
- http
- HTTPS
- Bombo
- i
- IBM
- importante
- mejorar
- es la mejora continua
- in
- comienzo
- Incluye
- inclusión
- energético
- líderes en la industria
- Iniciativa
- iniciativas
- Insights
- Destinado a
- dentro
- introducir
- ISN
- IT
- SUS
- solo
- tan siquiera solo una
- karl
- nuggets
- Clave
- Notas clave
- Tipo
- Saber
- especialistas
- carente
- mayor
- Apellido
- El año pasado
- Lead
- los líderes
- Liderazgo
- líder
- aprendizaje
- Mentir
- como
- Etiqueta LinkedIn
- Lista
- ll
- Pierde
- perdido
- máquina
- máquina de aprendizaje
- Inicio
- para lograr
- HACE
- Realizar
- gerente
- Managers
- manera
- muchos
- masterización
- personalizado
- significó
- medir
- mesurado
- Métrica
- Minería
- MIT
- ML
- modelo
- modelos
- más,
- MEJOR DE TU
- cuales son las que reflejan
- mucho más
- múltiples
- debe
- my
- ¿ Necesita ayuda
- Nuevo
- noticias
- no
- ahora
- of
- a menudo
- on
- ONE
- las
- , solamente
- operativos.
- Operaciones
- or
- solicite
- organización
- salir
- paquetes
- página
- parte
- participar
- naufragios
- (PDF)
- perfección
- actuación
- realiza
- persona
- la perspectiva
- planificado
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- enchufe
- Popular
- posición
- positivo
- posible
- industria
- Pedido Anticipado
- Joyas Preciosas
- precisamente
- predecir
- Predicciones
- Predice
- presentó
- presidente
- presión
- bastante
- en costes
- Producto
- profesionales
- Profesor
- proyecto
- proyecta
- prometido
- Demostrar.
- probado
- Publicación
- Publica
- propósito
- Pone
- Poniendo
- pregunta
- Preguntas
- Rampa
- rampa
- clasificar
- RARO
- Tarifas
- proporción
- en comunicarse
- realizado
- reconocer
- permanece
- Informes
- encuestados
- Resultados
- devoluciones
- ingresos
- revolucionario
- Derecho
- rocoso
- ROI
- rutinariamente
- Ejecutar
- s
- ambiente seguro
- Said
- mismo
- dices
- Escala
- Escuela
- Ciencia:
- Científico
- los científicos
- Serie
- ayudar
- servido
- sirve
- de coches
- siete
- compartido
- importante
- desde
- So
- Social
- Software
- algo
- Speaker
- Girar
- patrocinio
- etapas
- son afectados por la empresa
- las partes interesadas
- comienzo
- deriva
- Sin embargo
- Luchar
- Estudiantes
- comercial
- exitosos
- Con éxito
- tal
- RESUMEN
- Peritaje
- Sweep
- T
- afectados
- Educación
- Técnico
- Tecnología
- les digas
- términos
- que
- esa
- El proyecto
- su
- Les
- luego
- Ahí.
- Estas
- ellos
- así
- Tres
- a lo largo de
- Así
- equipo
- a
- tema
- verdaderamente
- dos
- Finalmente, a veces
- bajo
- entender
- comprensible
- Universidades
- universidad
- a
- usado
- introduciendo
- generalmente
- propuesta de
- Ve
- muy
- vía
- Ver
- la visibilidad
- vital
- fue
- Camino..
- semana
- pesar
- WELL
- ¿
- cuando
- que
- mientras
- QUIENES
- porque
- Wild
- seguirá
- sin
- Won
- la maravilla
- Actividades:
- se
- escrito
- año
- aún
- Usted
- tú
- zephyrnet








