Σε αυτό το άρθρο θα μάθουμε πώς να αναπτύξετε και να χρησιμοποιήσετε το μοντέλο GPT4All στον υπολογιστή σας μόνο με CPU (Χρησιμοποιώ α Macbook Pro χωρίς GPU!)

Χρησιμοποιήστε το GPT4All στον υπολογιστή σας — Εικόνα από τον συγγραφέα
Σε αυτό το άρθρο πρόκειται να εγκαταστήσουμε στον τοπικό μας υπολογιστή το GPT4All (ένα ισχυρό LLM) και θα ανακαλύψουμε πώς να αλληλεπιδράσουμε με τα έγγραφά μας με την python. Μια συλλογή αρχείων PDF ή διαδικτυακών άρθρων θα είναι η βάση γνώσεων για τις ερωτήσεις/απαντήσεις μας.
Από το επίσημη ιστοσελίδα GPT4All περιγράφεται ως ένα δωρεάν στη χρήση, τοπικά εκτελούμενο, chatbot με επίγνωση του απορρήτου. Δεν απαιτείται GPU ή internet.
Το GTP4All είναι ένα οικοσύστημα για εκπαίδευση και ανάπτυξη ισχυρός και προσαρμοσμένη μεγάλα γλωσσικά μοντέλα που τρέχουν τοπικά σε CPU καταναλωτικού επιπέδου.
Το μοντέλο μας GPT4All είναι ένα αρχείο 4 GB που μπορείτε να κατεβάσετε και να το συνδέσετε στο λογισμικό ανοιχτού κώδικα οικοσυστήματος GPT4All. Nomic AI διευκολύνει υψηλής ποιότητας και ασφαλή οικοσυστήματα λογισμικού, καθοδηγώντας την προσπάθεια να επιτραπεί σε άτομα και οργανισμούς να εκπαιδεύσουν αβίαστα και να εφαρμόσουν τα δικά τους μεγάλα γλωσσικά μοντέλα τοπικά.
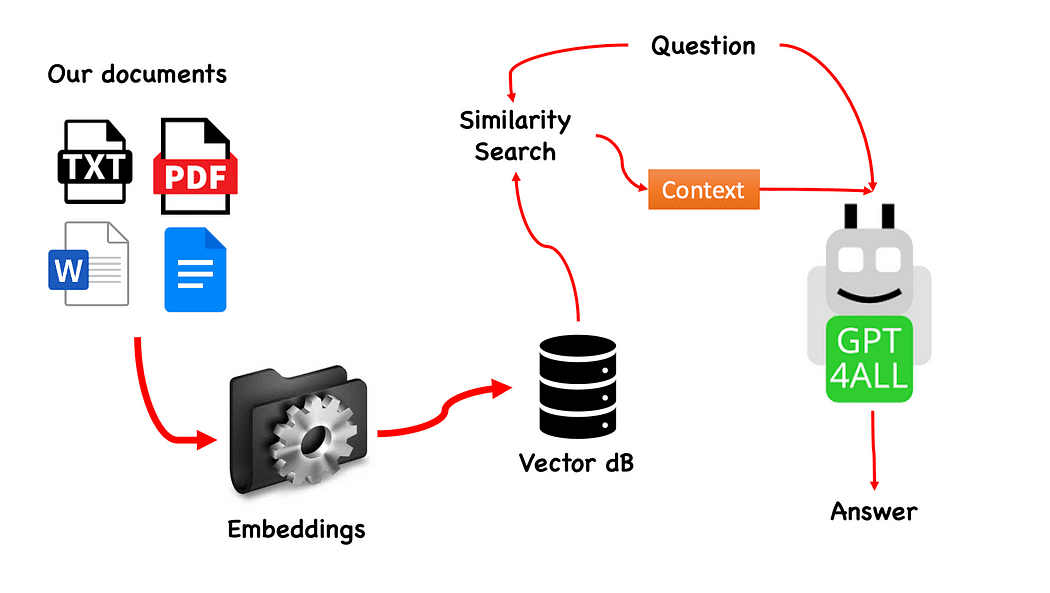
Ροή εργασίας του QnA με GPT4All — δημιουργήθηκε από τον συγγραφέα
Η διαδικασία είναι πραγματικά απλή (όταν το ξέρεις) και μπορεί να επαναληφθεί και με άλλα μοντέλα. Τα βήματα είναι τα εξής:
- φορτώστε το μοντέλο GPT4All
- χρήση Langchain για να ανακτήσουμε τα έγγραφά μας και να τα φορτώσουμε
- χωρίστε τα έγγραφα σε μικρά κομμάτια που μπορούν να χωνευτούν από το Embeddings
- Χρησιμοποιήστε το FAISS για να δημιουργήσετε τη διανυσματική μας βάση δεδομένων με τις ενσωματώσεις
- Εκτελέστε μια αναζήτηση ομοιότητας (σημασιολογική αναζήτηση) στη διανυσματική βάση δεδομένων μας με βάση την ερώτηση που θέλουμε να περάσουμε στο GPT4All: αυτό θα χρησιμοποιηθεί ως συμφραζόμενα για την ερώτησή μας
- Τροφοδοτήστε την ερώτηση και το πλαίσιο στο GPT4All με Langchain και περίμενε την απάντηση.
Αυτό που χρειαζόμαστε λοιπόν είναι Embeddings. Η ενσωμάτωση είναι μια αριθμητική αναπαράσταση μιας πληροφορίας, για παράδειγμα, κειμένου, εγγράφων, εικόνων, ήχου κ.λπ. Η αναπαράσταση αποτυπώνει το σημασιολογικό νόημα αυτού που ενσωματώνεται και αυτό ακριβώς χρειαζόμαστε. Για αυτό το έργο δεν μπορούμε να βασιστούμε σε βαριά μοντέλα GPU: επομένως θα κατεβάσουμε το εγγενές μοντέλο Alpaca και θα το χρησιμοποιήσουμε από Langchain ο LlamaCppEmbeddings. Μην ανησυχείς! Όλα εξηγούνται βήμα-βήμα
Δημιουργήστε ένα εικονικό περιβάλλον
Δημιουργήστε έναν νέο φάκελο για το νέο σας έργο Python, για παράδειγμα GPT4ALL_Fabio (βάλτε το όνομά σας…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioΣτη συνέχεια, δημιουργήστε ένα νέο εικονικό περιβάλλον Python. Εάν έχετε εγκαταστήσει περισσότερες από μία εκδόσεις python, καθορίστε την επιθυμητή έκδοση: σε αυτήν την περίπτωση θα χρησιμοποιήσω την κύρια εγκατάσταση μου, που σχετίζεται με την python 3.10.
python3 -m venv .venvΗ εντολή python3 -m venv .venv δημιουργεί ένα νέο εικονικό περιβάλλον με το όνομα .venv (η κουκκίδα θα δημιουργήσει έναν κρυφό κατάλογο που ονομάζεται venv).
Ένα εικονικό περιβάλλον παρέχει μια απομονωμένη εγκατάσταση Python, η οποία σας επιτρέπει να εγκαταστήσετε πακέτα και εξαρτήσεις μόνο για ένα συγκεκριμένο έργο χωρίς να επηρεάζετε την εγκατάσταση Python σε όλο το σύστημα ή άλλα έργα. Αυτή η απομόνωση βοηθά στη διατήρηση της συνέπειας και στην πρόληψη πιθανών συγκρούσεων μεταξύ των διαφορετικών απαιτήσεων του έργου.
Μόλις δημιουργηθεί το εικονικό περιβάλλον, μπορείτε να το ενεργοποιήσετε χρησιμοποιώντας την ακόλουθη εντολή:
source .venv/bin/activate 
Ενεργοποιημένο εικονικό περιβάλλον
Οι βιβλιοθήκες προς εγκατάσταση
Για το έργο που κατασκευάζουμε δεν χρειαζόμαστε πάρα πολλά πακέτα. Χρειαζόμαστε μόνο:
- συνδέσεις python για το GPT4All
- Langchain για αλληλεπίδραση με τα έγγραφά μας
Το LangChain είναι ένα πλαίσιο για την ανάπτυξη εφαρμογών που υποστηρίζονται από μοντέλα γλώσσας. Σας επιτρέπει όχι μόνο να καλείτε ένα μοντέλο γλώσσας μέσω ενός API, αλλά επίσης να συνδέσετε ένα μοντέλο γλώσσας με άλλες πηγές δεδομένων και να επιτρέψετε σε ένα μοντέλο γλώσσας να αλληλεπιδράσει με το περιβάλλον του.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4Για το LangChain βλέπετε ότι καθορίσαμε και την έκδοση. Αυτή η βιβλιοθήκη λαμβάνει πολλές ενημερώσεις πρόσφατα, επομένως για να είμαστε σίγουροι ότι η εγκατάσταση μας θα λειτουργήσει και αύριο, είναι καλύτερο να καθορίσετε μια έκδοση που γνωρίζουμε ότι λειτουργεί καλά. Το Unstructured είναι μια απαιτούμενη εξάρτηση για το πρόγραμμα φόρτωσης pdf και pytesseract και pdf2 εικόνα επίσης.
ΣΗΜΕΊΩΣΗ: στο αποθετήριο GitHub υπάρχει ένα αρχείο requires.txt (προτείνεται από jl adcr) με όλες τις εκδόσεις που σχετίζονται με αυτό το έργο. Μπορείτε να κάνετε την εγκατάσταση σε μία λήψη, αφού την κατεβάσετε στον κύριο κατάλογο αρχείων του έργου με την ακόλουθη εντολή:
pip install -r requirements.txtΣτο τέλος του άρθρου δημιούργησα ένα ενότητα για την αντιμετώπιση προβλημάτων. Το αποθετήριο GitHub διαθέτει επίσης ένα ενημερωμένο READ.ME με όλες αυτές τις πληροφορίες.
Λάβετε υπόψη ότι μερικά Οι βιβλιοθήκες έχουν διαθέσιμες εκδόσεις ανάλογα με την έκδοση python τρέχετε στο εικονικό σας περιβάλλον.
Κατεβάστε στον υπολογιστή σας τα μοντέλα
Αυτό είναι ένα πραγματικά σημαντικό βήμα.
Για το έργο χρειαζόμαστε σίγουρα το GPT4All. Η διαδικασία που περιγράφεται στο Nomic AI είναι πραγματικά πολύπλοκη και απαιτεί υλικό που δεν έχουμε όλοι μας (όπως εγώ). Έτσι εδώ είναι ο σύνδεσμος για το μοντέλο έχει ήδη μετατραπεί και είναι έτοιμο για χρήση. Απλώς κάντε κλικ στη λήψη.
Κατεβάστε το μοντέλο GPT4All
Όπως περιγράφεται εν συντομία στην εισαγωγή χρειαζόμαστε επίσης το μοντέλο για τις ενσωματώσεις, ένα μοντέλο που μπορούμε να τρέξουμε στην CPU μας χωρίς να συνθλίβουμε. Κάντε κλικ στο σύνδεσμος εδώ για λήψη του alpaca-native-7B-ggml έχει ήδη μετατραπεί σε 4-bit και έτοιμο για χρήση για να λειτουργήσει ως το μοντέλο μας για την ενσωμάτωση.

Κάντε κλικ στο βέλος λήψης δίπλα ggml-model-q4_0.bin
Γιατί χρειαζόμαστε ενσωματώσεις; Αν θυμάστε από το διάγραμμα ροής, το πρώτο βήμα που απαιτείται, αφού συλλέξουμε τα έγγραφα για τη γνωσιακή μας βάση, είναι να embed τους. Οι ενσωματώσεις LLamaCPP από αυτό το μοντέλο Alpaca ταιριάζουν απόλυτα στη δουλειά και αυτό το μοντέλο είναι επίσης αρκετά μικρό (4 Gb). Παρεμπιπτόντως, μπορείτε επίσης να χρησιμοποιήσετε το μοντέλο Alpaca για το QnA σας!
Ενημέρωση 2023.05.25: Οι χρήστες Mani Windows αντιμετωπίζουν προβλήματα στη χρήση των ενσωματώσεων llamaCPP. Αυτό συμβαίνει κυρίως επειδή κατά την εγκατάσταση του πακέτου python llama-cpp-python με:
pip install llama-cpp-pythonτο πακέτο pip πρόκειται να μεταγλωττίσει από την πηγή της βιβλιοθήκης. Τα Windows συνήθως δεν έχουν εγκατεστημένο το μεταγλωττιστή CMake ή C από προεπιλογή στο μηχάνημα. Αλλά μην ανησυχείτε, υπάρχει λύση
Η εκτέλεση της εγκατάστασης του llama-cpp-python, που απαιτείται από το LangChain με το llamaEmbeddings, στα Windows CMake C complier δεν είναι εγκατεστημένη από προεπιλογή, επομένως δεν μπορείτε να δημιουργήσετε από την πηγή.
Σε χρήστες Mac με Xtools και σε Linux, συνήθως το C complier είναι ήδη διαθέσιμο στο λειτουργικό σύστημα.
Για να αποφευχθεί το θέμα ΠΡΕΠΕΙ να χρησιμοποιήσετε προ-συμμορφωμένο τροχό.
Πήγαινε εδώ https://github.com/abetlen/llama-cpp-python/releases
και αναζητήστε τον συμμορφωμένο τροχό για την αρχιτεκτονική και την έκδοση python σας — ΠΡΕΠΕΙ να πάρετε το Weels Version 0.1.49 επειδή οι υψηλότερες εκδόσεις δεν είναι συμβατές.
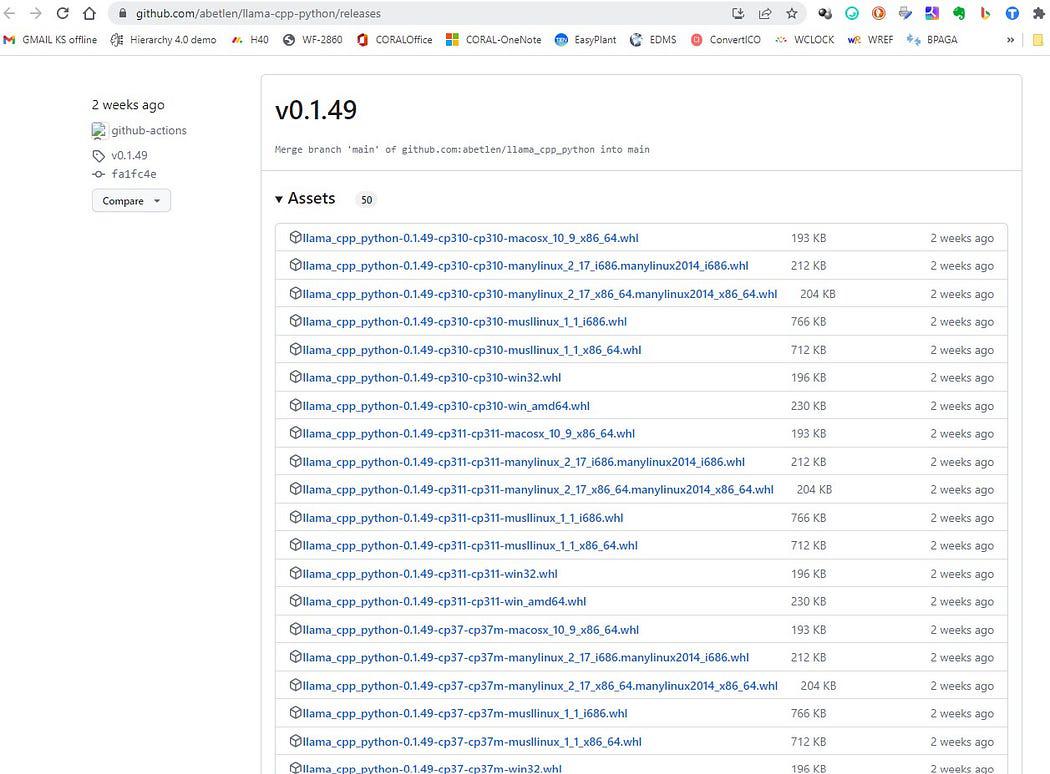
Screenshot από https://github.com/abetlen/llama-cpp-python/releases
Στην περίπτωσή μου έχω Windows 10, 64 bit, python 3.10
οπότε το αρχείο μου είναι llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
Αυτός ο διαλογισμός στα Το ζήτημα παρακολουθείται στο αποθετήριο GitHub
Μετά τη λήψη, πρέπει να βάλετε τα δύο μοντέλα στον κατάλογο μοντέλων, όπως φαίνεται παρακάτω.

Δομή καταλόγου και πού να τοποθετήσετε τα αρχεία του μοντέλου
Εφόσον θέλουμε να έχουμε τον έλεγχο της αλληλεπίδρασής μας στο μοντέλο GPT, πρέπει να δημιουργήσουμε ένα αρχείο python (ας το ονομάσουμε pygpt4all_test.py), εισάγετε τις εξαρτήσεις και δώστε τις οδηγίες στο μοντέλο. Θα δείτε ότι είναι πολύ εύκολο.
from pygpt4all.models.gpt4all import GPT4AllΑυτό είναι το δέσιμο python για το μοντέλο μας. Τώρα μπορούμε να το καλέσουμε και να αρχίσουμε να ρωτάμε. Ας δοκιμάσουμε ένα δημιουργικό.
Δημιουργούμε μια συνάρτηση που διαβάζει την επιστροφή κλήσης από το μοντέλο και ζητάμε από το GPT4All να ολοκληρώσει την πρόταση μας.
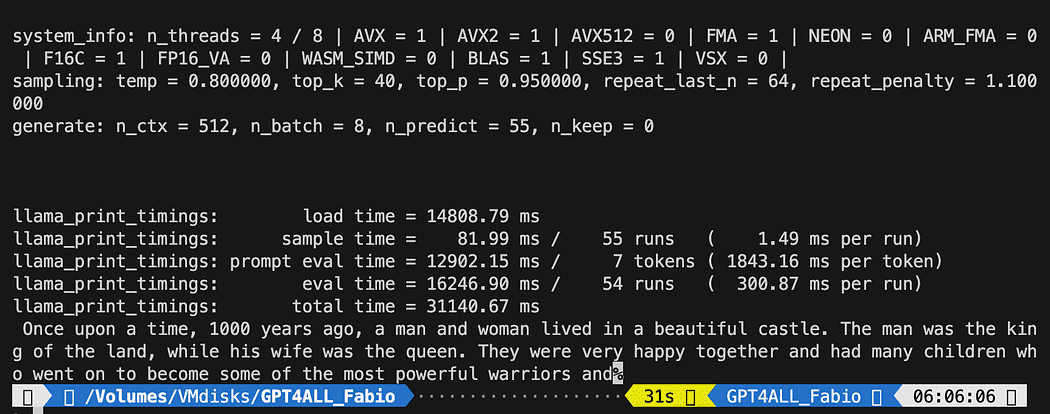
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)Η πρώτη δήλωση λέει στο πρόγραμμά μας πού να βρει το μοντέλο (θυμηθείτε τι κάναμε στην παραπάνω ενότητα)
Η δεύτερη δήλωση ζητά από το μοντέλο να δημιουργήσει μια απάντηση και να ολοκληρώσει την προτροπή μας "Μια φορά κι έναν καιρό".
Για να το εκτελέσετε, βεβαιωθείτε ότι το εικονικό περιβάλλον είναι ακόμα ενεργοποιημένο και απλώς εκτελέστε:
python3 pygpt4all_test.pyΘα πρέπει να δείτε ένα κείμενο φόρτωσης του μοντέλου και την ολοκλήρωση της πρότασης. Ανάλογα με τους πόρους του υλικού σας, μπορεί να χρειαστεί λίγος χρόνος.
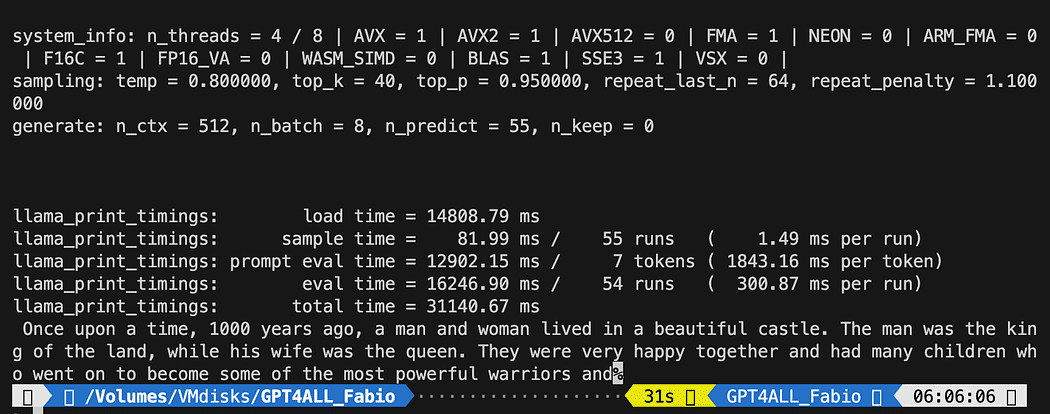
Το αποτέλεσμα μπορεί να είναι διαφορετικό από το δικό σας… Αλλά για εμάς το σημαντικό είναι ότι λειτουργεί και μπορούμε να προχωρήσουμε με το LangChain για να δημιουργήσουμε κάποια προηγμένα πράγματα.
ΣΗΜΕΙΩΣΗ (ενημερώθηκε 2023.05.23): εάν αντιμετωπίζετε ένα σφάλμα που σχετίζεται με το pygpt4all, ελέγξτε την ενότητα αντιμετώπισης προβλημάτων σε αυτό το θέμα με τη λύση που δίνεται από Rajneesh Aggarwal or από τον Oscar Jeong.
Το πλαίσιο LangChain είναι μια πραγματικά εκπληκτική βιβλιοθήκη. Παρέχει εξαρτήματα να εργάζεστε με μοντέλα γλώσσας με εύκολο στη χρήση τρόπο και παρέχει επίσης Αλυσίδες. Οι αλυσίδες μπορούν να θεωρηθούν ότι συναρμολογούν αυτά τα εξαρτήματα με συγκεκριμένους τρόπους προκειμένου να επιτευχθεί καλύτερα μια συγκεκριμένη περίπτωση χρήσης. Αυτές προορίζονται να είναι μια διεπαφή υψηλότερου επιπέδου μέσω της οποίας οι άνθρωποι μπορούν εύκολα να ξεκινήσουν με μια συγκεκριμένη περίπτωση χρήσης. Αυτές οι αλυσίδες έχουν επίσης σχεδιαστεί για να είναι προσαρμόσιμες.
Στην επόμενη δοκιμή μας για python θα χρησιμοποιήσουμε a Πρότυπο προτροπής. Τα μοντέλα γλώσσας λαμβάνουν κείμενο ως είσοδο — αυτό το κείμενο αναφέρεται συνήθως ως προτροπή. Συνήθως αυτό δεν είναι απλώς μια συμβολοσειρά με σκληρό κώδικα, αλλά ένας συνδυασμός ενός προτύπου, ορισμένων παραδειγμάτων και εισόδου χρήστη. Το LangChain παρέχει πολλές κλάσεις και λειτουργίες για να διευκολύνει την κατασκευή και την εργασία με προτροπές. Ας δούμε πώς μπορούμε να το κάνουμε κι εμείς.
Δημιουργήστε ένα νέο αρχείο python και καλέστε το my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])Εισαγάγαμε από το LangChain το Πρότυπο και την αλυσίδα προτροπής και την κλάση GPT4All llm για να μπορούμε να αλληλεπιδράσουμε απευθείας με το μοντέλο μας GPT.
Στη συνέχεια, αφού ορίσουμε τη διαδρομή llm μας (όπως κάναμε πριν) εγκαινιάζουμε τους διαχειριστές επανάκλησης έτσι ώστε να μπορούμε να συλλάβουμε τις απαντήσεις στο ερώτημά μας.
Η δημιουργία ενός προτύπου είναι πολύ εύκολη: ακολουθώντας το σεμινάριο τεκμηρίωσης μπορούμε να χρησιμοποιήσουμε κάτι τέτοιο…
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])Η πρότυπο η μεταβλητή είναι μια συμβολοσειρά πολλών γραμμών που περιέχει τη δομή αλληλεπίδρασής μας με το μοντέλο: σε σγουρά άγκιστρα εισάγουμε τις εξωτερικές μεταβλητές στο πρότυπο, στο σενάριο μας είναι ερώτηση.
Δεδομένου ότι είναι μια μεταβλητή, μπορείτε να αποφασίσετε εάν είναι μια ερώτηση με σκληρό κώδικα ή μια ερώτηση εισαγωγής χρήστη: εδώ τα δύο παραδείγματα.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")Για τη δοκιμαστική μας εκτέλεση θα σχολιάσουμε την εισαγωγή χρήστη. Τώρα χρειάζεται μόνο να συνδέσουμε το πρότυπό μας, την ερώτηση και το μοντέλο γλώσσας.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)Θυμηθείτε να επαληθεύσετε ότι το εικονικό σας περιβάλλον είναι ακόμα ενεργοποιημένο και εκτελέστε την εντολή:
python3 my_langchain.pyΜπορεί να έχετε διαφορετικά αποτελέσματα από τα δικά μου. Αυτό που είναι εκπληκτικό είναι ότι μπορείτε να δείτε ολόκληρο το σκεπτικό ακολουθούμενο από το GPT4All που προσπαθεί να πάρει μια απάντηση για εσάς. Η προσαρμογή της ερώτησης μπορεί επίσης να σας δώσει καλύτερα αποτελέσματα.
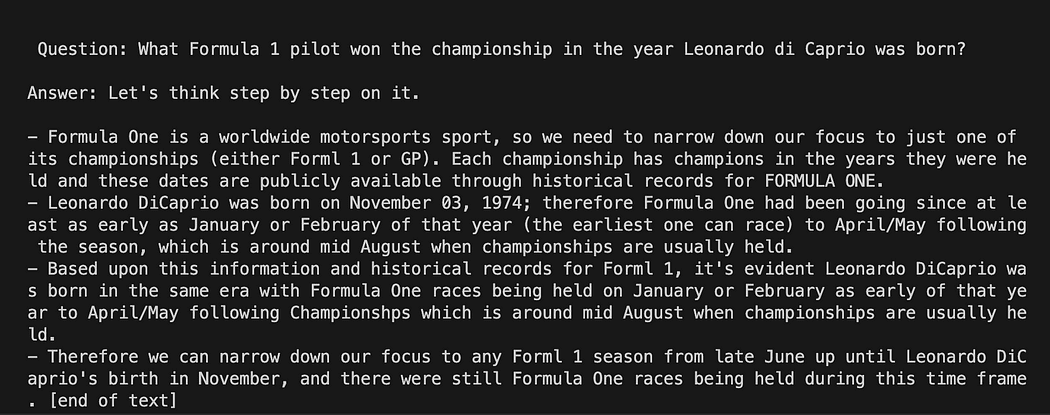
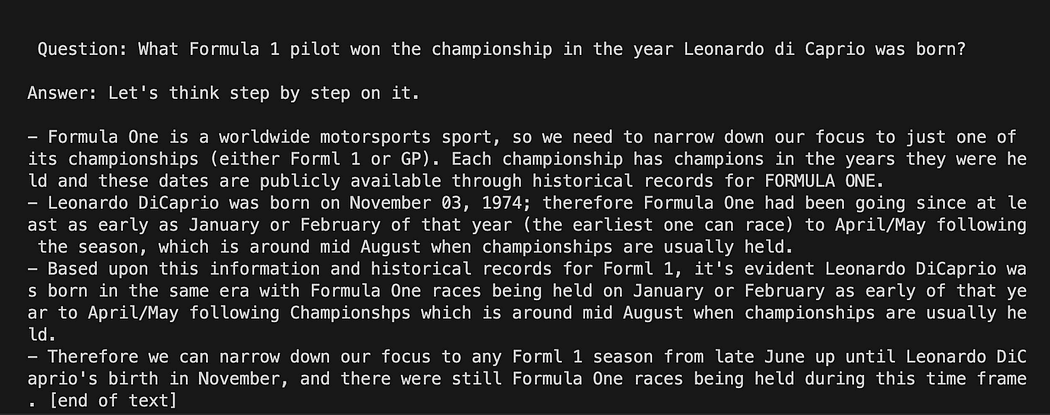
Langchain με πρότυπο προτροπής στο GPT4All
Εδώ ξεκινάμε το καταπληκτικό μέρος, γιατί πρόκειται να μιλήσουμε στα έγγραφά μας χρησιμοποιώντας το GPT4All ως chatbot που απαντά στις ερωτήσεις μας.
Η σειρά των βημάτων, που αναφέρεται σε Ροή εργασίας του QnA με GPT4All, είναι να φορτώσουμε τα αρχεία pdf μας, να τα κάνουμε κομμάτια. Μετά από αυτό θα χρειαστούμε ένα Vector Store για τις ενσωματώσεις μας. Πρέπει να τροφοδοτήσουμε τα τεμαχισμένα έγγραφά μας σε ένα διανυσματικό κατάστημα για ανάκτηση πληροφοριών και στη συνέχεια θα τα ενσωματώσουμε μαζί με την αναζήτηση ομοιότητας σε αυτήν τη βάση δεδομένων ως πλαίσιο για το ερώτημά μας LLM.
Για το σκοπό αυτό θα χρησιμοποιήσουμε το FAISS απευθείας από Langchain βιβλιοθήκη. Το FAISS είναι μια βιβλιοθήκη ανοιχτού κώδικα από το Facebook AI Research, σχεδιασμένη για να βρίσκει γρήγορα παρόμοια αντικείμενα σε μεγάλες συλλογές δεδομένων υψηλών διαστάσεων. Προσφέρει μεθόδους ευρετηρίασης και αναζήτησης για να διευκολύνει και πιο γρήγορα τον εντοπισμό των πιο όμοιων στοιχείων σε ένα σύνολο δεδομένων. Μας βολεύει ιδιαίτερα γιατί απλοποιεί ανάκτηση πληροφορίας και επιτρέψτε μας να αποθηκεύσουμε τοπικά τη βάση δεδομένων που δημιουργήθηκε: αυτό σημαίνει ότι μετά την πρώτη δημιουργία θα φορτωθεί πολύ γρήγορα για οποιαδήποτε περαιτέρω χρήση.
Δημιουργία του διανυσματικού δείκτη db
Δημιουργήστε ένα νέο αρχείο και καλέστε το my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeΟι πρώτες βιβλιοθήκες είναι οι ίδιες που χρησιμοποιούσαμε πριν: επιπλέον χρησιμοποιούμε Langchain για τη δημιουργία ευρετηρίου αποθήκευσης διανυσμάτων, το LlamaCppEmbeddings για αλληλεπίδραση με το μοντέλο μας Alpaca (κβαντισμένο σε 4-bit και μεταγλωττισμένο με τη βιβλιοθήκη cpp) και το πρόγραμμα φόρτωσης PDF.
Ας φορτώσουμε επίσης τα LLM μας με τις δικές τους διαδρομές: μία για τις ενσωματώσεις και μία για τη δημιουργία κειμένου.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Για δοκιμή, ας δούμε αν καταφέραμε να διαβάσουμε όλα τα αρχεία pfd: το πρώτο βήμα είναι να δηλώσουμε 3 συναρτήσεις που θα χρησιμοποιηθούν σε κάθε έγγραφο. Το πρώτο είναι να χωρίσετε το εξαγόμενο κείμενο σε κομμάτια, το δεύτερο είναι να δημιουργήσετε το διανυσματικό ευρετήριο με τα μεταδεδομένα (όπως αριθμούς σελίδων κ.λπ.…) και το τελευταίο είναι για τον έλεγχο της αναζήτησης ομοιότητας (θα εξηγήσω καλύτερα αργότερα).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesΤώρα μπορούμε να δοκιμάσουμε τη δημιουργία ευρετηρίου για τα έγγραφα στο docs κατάλογος: πρέπει να βάλουμε εκεί όλα τα pdf μας. Langchain έχει επίσης μια μέθοδο για τη φόρτωση ολόκληρου του φακέλου, ανεξάρτητα από τον τύπο αρχείου: καθώς είναι περίπλοκη η διαδικασία ανάρτησης, θα την καλύψω στο επόμενο άρθρο σχετικά με τα μοντέλα LaMini.

Ο κατάλογος των εγγράφων μου περιέχει 4 αρχεία pdf
Θα εφαρμόσουμε τις λειτουργίες μας στο πρώτο έγγραφο της λίστας
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)Στις πρώτες γραμμές χρησιμοποιούμε τη βιβλιοθήκη os για να λάβουμε το λίστα αρχείων pdf μέσα στον κατάλογο των εγγράφων. Στη συνέχεια, φορτώνουμε το πρώτο έγγραφο (doc_list[0]) από το φάκελο docs με Langchain, χωρίζουμε σε κομμάτια και στη συνέχεια δημιουργούμε τη διανυσματική βάση δεδομένων με το Είδος μικρής καμήλας ενσωματώσεις.
Όπως είδατε χρησιμοποιούμε το μέθοδος pyPDF. Αυτό είναι λίγο μεγαλύτερο στη χρήση, αφού πρέπει να φορτώσετε τα αρχεία ένα προς ένα, αλλά φορτώνοντας το PDF χρησιμοποιώντας pypdf σε μια σειρά εγγράφων σάς επιτρέπει να έχετε έναν πίνακα όπου κάθε έγγραφο περιέχει το περιεχόμενο της σελίδας και τα μεταδεδομένα με page αριθμός. Αυτό είναι πραγματικά βολικό όταν θέλετε να μάθετε τις πηγές του περιβάλλοντος που θα δώσουμε στο GPT4All με το ερώτημά μας. Εδώ το παράδειγμα από το readthedocs:
Screenshot από Τεκμηρίωση Langchain
Μπορούμε να εκτελέσουμε το αρχείο python με την εντολή από το τερματικό:
python3 my_knowledge_qna.pyΜετά τη φόρτωση του μοντέλου για ενσωματώσεις θα δείτε τα token να λειτουργούν για την ευρετηρίαση: μην φρικάρετε γιατί θα πάρει χρόνο, ειδικά αν τρέχετε μόνο σε CPU, όπως εγώ (χρειάστηκαν 8 λεπτά).
Συμπλήρωση του πρώτου διανύσματος db
Όπως εξήγησα, η μέθοδος pyPDF είναι πιο αργή αλλά μας δίνει πρόσθετα δεδομένα για την αναζήτηση ομοιότητας. Για να επαναλάβουμε όλα τα αρχεία μας, θα χρησιμοποιήσουμε μια βολική μέθοδο από το FAISS που μας επιτρέπει να ΣΥΓΧΩΝΕΥΟΥΜΕ διαφορετικές βάσεις δεδομένων μαζί. Αυτό που κάνουμε τώρα είναι ότι χρησιμοποιούμε τον παραπάνω κώδικα για να δημιουργήσουμε το πρώτο db (θα το ονομάσουμε db0) και το με ένα βρόχο for δημιουργούμε το ευρετήριο του επόμενου αρχείου στη λίστα και το συγχωνεύουμε αμέσως με db0.
Εδώ είναι ο κωδικός: σημειώστε ότι πρόσθεσα μερικά αρχεία καταγραφής για να σας δώσω την κατάσταση της προόδου που χρησιμοποιείτε datetime.datetime.now() και εκτύπωση του δέλτα του χρόνου λήξης και της ώρας έναρξης για να υπολογίσετε πόσο χρόνο κράτησε η λειτουργία (μπορείτε να το αφαιρέσετε αν δεν σας αρέσει).
Οι οδηγίες συγχώνευσης είναι κάπως έτσι
# merge dbi with the existing db0
db0.merge_from(dbi)Μία από τις τελευταίες οδηγίες είναι η αποθήκευση της βάσης δεδομένων μας τοπικά: ολόκληρη η γενιά μπορεί να πάρει ακόμη και ώρες (εξαρτάται από τον αριθμό των εγγράφων που έχετε) οπότε είναι πολύ καλό που πρέπει να το κάνουμε μόνο μία φορά!
# Save the databasae locally
db0.save_local("my_faiss_index")Εδώ ολόκληρος ο κώδικας. Θα σχολιάσουμε πολλά μέρη του όταν αλληλεπιδράσουμε με το GPT4All φορτώνοντας το ευρετήριο απευθείας από τον φάκελό μας.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  Η εκτέλεση του αρχείου python χρειάστηκε 22 λεπτά
Η εκτέλεση του αρχείου python χρειάστηκε 22 λεπτά
Κάντε ερωτήσεις στο GPT4All στα έγγραφά σας
Τώρα είμαστε εδώ. Έχουμε το ευρετήριό μας, μπορούμε να το φορτώσουμε και με ένα Πρότυπο Προτροπής μπορούμε να ζητήσουμε από το GPT4All να απαντήσει στις ερωτήσεις μας. Ξεκινάμε με μια σκληρά κωδικοποιημένη ερώτηση και, στη συνέχεια, θα περιηγηθούμε στις ερωτήσεις εισαγωγής μας.
Βάλτε τον παρακάτω κώδικα μέσα σε ένα αρχείο python db_loading.py και εκτελέστε το με την εντολή από το τερματικό python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])Το τυπωμένο κείμενο είναι η λίστα με τις 3 πηγές που ταιριάζει καλύτερα με το ερώτημα, δίνοντάς μας επίσης το όνομα του εγγράφου και τον αριθμό σελίδας.
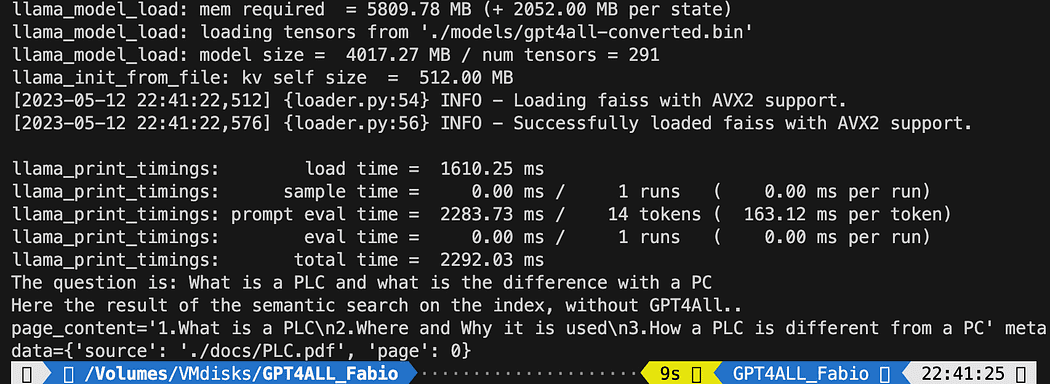
Αποτελέσματα της σημασιολογικής αναζήτησης που εκτελείται το αρχείο db_loading.py
Τώρα μπορούμε να χρησιμοποιήσουμε την αναζήτηση ομοιότητας ως πλαίσιο για το ερώτημά μας χρησιμοποιώντας το πρότυπο προτροπής. Μετά τις 3 λειτουργίες απλώς αντικαταστήστε όλο τον κώδικα με τον ακόλουθο:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))Μετά το τρέξιμο θα έχετε ένα αποτέλεσμα όπως αυτό (αλλά μπορεί να διαφέρει). Καταπληκτικό όχι!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Εάν θέλετε μια ερώτηση εισαγωγής χρήστη για να αντικαταστήσει τη γραμμή
question = "What is a PLC and what is the difference with a PC"με κάτι σαν αυτό:
question = input("Your question: ")Είναι καιρός να πειραματιστείτε. Κάντε διαφορετικές ερωτήσεις για όλα τα θέματα που σχετίζονται με τα έγγραφά σας και δείτε τα αποτελέσματα. Υπάρχει μεγάλο περιθώριο βελτίωσης, σίγουρα στην προτροπή και το πρότυπο: μπορείτε να ρίξετε μια ματιά εδώ για μερικές εμπνεύσεις. Αλλά Langchain Η τεκμηρίωση είναι πραγματικά καταπληκτική (θα μπορούσα να την ακολουθήσω!!).
Μπορείτε να ακολουθήσετε τον κώδικα από το άρθρο ή να τον ελέγξετε το αποθετήριο github μου.
Φάμπιο Ματρικάρντι εκπαιδευτικός, δάσκαλος, μηχανικός και λάτρης της μάθησης. Διδάσκει για 15 χρόνια σε νέους φοιτητές και τώρα εκπαιδεύει νέους υπαλλήλους στην Key Solution Srl. Ξεκίνησε την καριέρα μου ως Μηχανικός Βιομηχανικού Αυτοματισμού το 2010. Παθιασμένος με τον προγραμματισμό από τότε που ήταν έφηβος, ανακάλυψε την ομορφιά της κατασκευής λογισμικού και διασυνδέσεων ανθρώπινης μηχανής για να ζωντανέψει κάτι. Η διδασκαλία και η καθοδήγηση είναι μέρος της καθημερινής μου ρουτίνας, καθώς και η μελέτη και η εκμάθηση πώς να είμαι παθιασμένος ηγέτης με σύγχρονες δεξιότητες διαχείρισης. Ελάτε μαζί μου στο ταξίδι προς έναν καλύτερο σχεδιασμό, μια ενσωμάτωση προγνωστικού συστήματος που χρησιμοποιεί τη Μηχανική Μάθηση και την Τεχνητή Νοημοσύνη σε όλο τον κύκλο ζωής της μηχανικής.
Πρωτότυπο. Αναδημοσιεύτηκε με άδεια.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- EVM Finance. Ενιαία διεπαφή για αποκεντρωμένη χρηματοδότηση. Πρόσβαση εδώ.
- Quantum Media Group. Ενισχυμένο IR/PR. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Data Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :έχει
- :είναι
- :δεν
- :που
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 15 χρόνια
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- ικανότητα
- Ικανός
- Σχετικα
- πάνω από
- ολοκληρώσει
- Πράξη
- ενεργοποιείται
- προστιθέμενη
- Επιπλέον
- Πρόσθετος
- προηγμένες
- συγκινητικός
- Μετά το
- AI
- ai έρευνα
- Όλα
- επιτρέπουν
- επιτρέπει
- ήδη
- Επίσης
- am
- καταπληκτικό
- an
- ανάλυση
- και
- απάντηση
- κάθε
- api
- εφαρμογές
- Εφαρμογή
- αρχιτεκτονική
- ΕΙΝΑΙ
- Παράταξη
- άρθρο
- εμπορεύματα
- τεχνητός
- τεχνητή νοημοσύνη
- AS
- συσχετισμένη
- At
- ήχου
- Αυτοματοποιημένη
- αυτομάτως
- Αυτοματοποίηση
- διαθέσιμος
- αποφύγετε
- βάση
- βασίζονται
- BE
- Ομορφιά
- επειδή
- ήταν
- πριν
- είναι
- παρακάτω
- ΚΑΛΎΤΕΡΟΣ
- Καλύτερα
- μεταξύ
- Πέρα
- Μεγάλος
- BIN
- δεσμευτικός
- Κομμάτι
- γεννημένος
- εν συντομία
- φέρω
- χτίζω
- Κτίριο
- ενσωματωμένο
- Λεωφορεία
- αλλά
- by
- υπολογίσει
- κλήση
- που ονομάζεται
- κλήσεις
- CAN
- δεν μπορώ
- Χωρητικότητα
- συλλαμβάνει
- Σταδιοδρομία
- κουβαλάω
- περίπτωση
- πάλη
- CD
- ορισμένες
- σίγουρα
- αλυσίδα
- αλυσίδες
- πρωτάθλημα
- chatbot
- ChatGPT
- έλεγχος
- χημική ουσία
- τάξη
- τάξεις
- κλικ
- προπόνηση
- κωδικός
- κώδικες
- συλλέγουν
- συλλογή
- συλλογές
- συνδυασμός
- σχόλιο
- συνήθως
- επικοινωνούν
- Επικοινωνία
- σύμφωνος
- πλήρης
- Ολοκληρώθηκε το
- ολοκλήρωση
- συγκρότημα
- περίπλοκος
- εξαρτήματα
- υπολογιστή
- υπολογιστές
- Connect
- συνδεδεμένος
- κατασκευή
- καταναλωτής
- Περιέχει
- περιεχόμενο
- συμφραζόμενα
- έλεγχος
- ελεγκτής
- ελέγχους
- Βολικός
- μετατρέπονται
- θα μπορούσε να
- κάλυμμα
- CPU
- δημιουργία
- δημιουργήθηκε
- δημιουργεί
- δημιουργία
- δημιουργία
- Δημιουργικός
- κρίσιμης
- προσαρμόσιμη
- καθημερινά
- ημερομηνία
- βάση δεδομένων
- βάσεις δεδομένων
- Ημερομηνία
- ημερομηνία
- αποφασίζει
- Προεπιλογή
- ορίζεται
- Δέλτα
- Εξάρτηση
- Σε συνάρτηση
- εξαρτάται
- παρατάσσω
- περιγράφεται
- Υπηρεσίες
- σχεδιασμένα
- επιθυμητή
- ανάπτυξη
- συσκευή
- Συσκευές
- DID
- διαφορά
- διαφορετικές
- ευκολοχώνευτος
- ψηφιακό
- κατευθείαν
- ανακαλύπτουν
- ανακάλυψαν
- do
- έγγραφο
- τεκμηρίωση
- έγγραφα
- κάνει
- doesn
- γίνεται
- Μην
- DOT
- κατεβάσετε
- οδήγηση
- κατά την διάρκεια
- κάθε
- ευκολότερη
- εύκολα
- εύκολος
- οικοσύστημα
- οικοσυστήματα
- προσπάθεια
- embed
- ενσωματωμένο
- ενσωμάτωση
- υπαλλήλους
- ενεργοποιήσετε
- τέλος
- μηχανικός
- Μηχανική
- εισάγετε
- θιασώτης
- Ολόκληρος
- Περιβάλλον
- σφάλμα
- ειδικά
- κ.λπ.
- Αιθέρας (ΕΤΗ)
- Even
- πάντα
- ακριβώς
- παράδειγμα
- παραδείγματα
- εκτέλεση
- υφιστάμενα
- πείραμα
- Εξηγήστε
- εξήγησε
- εξηγώντας
- εξωτερικός
- Πρόσωπο
- διευκολύνει
- αντιμέτωπος
- FAST
- γρηγορότερα
- Αρχεία
- Αρχεία
- Εύρεση
- τέλος
- Όνομα
- ταιριάζουν
- ροή
- ακολουθήστε
- ακολουθείται
- Εξής
- εξής
- Για
- μορφή
- μορφή
- τύπος
- Φόρμουλα 1
- Πλαίσιο
- από
- λειτουργία
- λειτουργίες
- περαιτέρω
- παράγουν
- παραγωγής
- γενεά
- παίρνω
- GitHub
- Δώστε
- δεδομένου
- δίνει
- Δίνοντας
- μετάβαση
- καλός
- GPU
- βαθμός
- Χειρισμός
- συμβαίνει
- Σκληρά
- υλικού
- Έχω
- he
- βαριά
- βοηθά
- εδώ
- κρυμμένο
- Ψηλά
- υψηλότερο
- ΩΡΕΣ
- Πως
- Πώς να
- HTML
- http
- HTTPS
- ανθρώπινος
- i
- ICS
- if
- εικόνες
- αμέσως
- εφαρμογή
- εισαγωγή
- σημαντικό
- βελτίωση
- in
- περιλαμβάνουν
- ευρετήριο
- δείκτες
- άτομα
- βιομηχανικές
- βιομηχανικός αυτοματισμός
- βιομηχανίες
- πληροφορίες
- εισαγωγή
- εισόδου-εξόδου
- είσοδοι
- εγκαθιστώ
- εγκατάσταση
- παράδειγμα
- οδηγίες
- ολοκλήρωση
- Νοημοσύνη
- προορίζονται
- αλληλεπιδρούν
- αλληλεπίδραση
- περιβάλλον λειτουργίας
- διεπαφές
- Internet
- σε
- Εισαγωγή
- απομονωμένος
- απομόνωση
- IT
- αντικειμένων
- επανάληψη
- ΤΟΥ
- Δουλειά
- ενταχθούν
- ταξίδι
- μόλις
- KDnuggets
- Κλειδί
- Ξέρω
- γνώση
- Γλώσσα
- large
- Επίθετο
- αργότερα
- ηγέτης
- μάθηση
- Επίπεδο
- βιβλιοθήκες
- Βιβλιοθήκη
- ζωή
- κύκλος ζωής
- Μου αρέσει
- γραμμές
- LINK
- linux
- Λιστα
- λίγο
- φορτίο
- φορτωτής
- φόρτωση
- τοπικός
- τοπικά
- λογική
- Μακριά
- πλέον
- ματιά
- Παρτίδα
- mac
- μηχανή
- μάθηση μηχανής
- μηχανήματα
- Κυρίως
- κυρίως
- διατηρήσουν
- κάνω
- διαχειρίζεται
- διαχείριση
- διευθυντής
- Διευθυντές
- κατασκευής
- πολοί
- Ενδέχεται..
- νόημα
- μέσα
- Μνήμη
- πηγαίνω
- συγχώνευση
- Μεταδεδομένα
- μέθοδος
- μέθοδοι
- νου
- πρακτικά
- μοντέλο
- μοντέλα
- περισσότερο
- πλέον
- πολλαπλούς
- πρέπει
- my
- όνομα
- ντόπιος
- Ανάγκη
- δίκτυα
- Νέα
- επόμενη
- τώρα
- αριθμός
- αριθμοί
- αντικείμενο
- of
- προσφορές
- on
- μια φορά
- ONE
- διαδικτυακά (online)
- αποκλειστικά
- ανοικτού κώδικα
- λειτουργία
- λειτουργίες
- or
- τάξη
- οργανώσεις
- OS
- ΑΛΛΑ
- δικός μας
- έξω
- παραγωγή
- επί
- δική
- πακέτο
- Packages
- σελίδα
- Παράλληλο
- μέρος
- Ειδικότερα
- ιδιαίτερα
- passieren
- παθιασμένος
- μονοπάτι
- PC
- People
- εκτελέσει
- άδεια
- προσωπικός
- εικόνα
- κομμάτι
- πιλότος
- φυτά
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- PLC
- σας παρακαλούμε
- βύσμα
- λιμένες
- θέση
- Θέση
- δυναμικού
- δύναμη
- σταθμούς παραγωγής ηλεκτρικής ενέργειας
- τροφοδοτείται
- ισχυρός
- προ
- πρόληψη
- εκτύπωση
- προβλήματα
- διαδικασια μας
- επεξεργασία
- Διεργασίες
- Πρόγραμμα
- προγραμματισμένος
- Προγραμματισμός
- Πρόοδος
- σχέδιο
- έργα
- πρωτόκολλα
- παρέχει
- σκοποί
- βάζω
- Python
- ποιότητα
- ερώτηση
- Ερωτήσεις
- γρήγορα
- μάλλον
- Διάβασε
- έτοιμος
- πραγματικά
- λήψη
- πρόσφατα
- αναφέρεται
- αναφέρεται
- Ανεξάρτητα
- μητρώα
- σχετίζεται με
- αξιοπιστία
- βασίζονται
- θυμάμαι
- αφαιρέστε
- επανειλημμένες
- αντικαθιστώ
- αναφέρουν
- Αποθήκη
- αντιπροσώπευση
- απαιτείται
- απαιτήσεις
- Απαιτεί
- έρευνα
- Υποστηρικτικό υλικό
- απάντησης
- απαντήσεις
- αποτέλεσμα
- Αποτελέσματα
- απόδοση
- Δωμάτιο
- τρέξιμο
- τρέξιμο
- s
- Ασφάλεια
- ίδιο
- Αποθήκευση
- οικονομία
- σενάριο
- Αναζήτηση
- αναζήτηση
- Δεύτερος
- Τμήμα
- προστατευμένο περιβάλλον
- δείτε
- αισθητήρες
- ποινή
- Ακολουθία
- σειράς
- τον καθορισμό
- setup
- διάφοροι
- βολή
- θα πρέπει να
- παρουσιάζεται
- παρόμοιες
- Απλούς
- απλά
- αφού
- ενιαίας
- δεξιότητες
- small
- So
- λογισμικό
- λύση
- μερικοί
- κάτι
- Πηγή
- Πηγές
- ειδικευμένος
- ειδικώς
- συγκεκριμένες
- καθορίζεται
- διαίρεση
- Spot
- Εκκίνηση
- ξεκίνησε
- Ξεκινήστε
- Δήλωση
- Κατάσταση
- Βήμα
- Βήματα
- Ακόμη
- κατάστημα
- Σπάγγος
- δομή
- Φοιτητές
- μελετώντας
- τέτοιος
- σύστημα
- Πάρτε
- Συζήτηση
- εργασίες
- δάσκαλος
- Διδασκαλία
- έφηβος
- πρότυπο
- τερματικό
- δοκιμή
- Δοκιμαστικό τρέξιμο
- Δοκιμές
- δημιουργία κειμένου
- από
- ότι
- Η
- τους
- Τους
- τότε
- Εκεί.
- Αυτοί
- αυτοί
- νομίζω
- αυτό
- σκέψη
- Μέσω
- παντού
- ώρα
- προς την
- μαζι
- κουπόνια
- αύριο
- πολύ
- πήρε
- τοπικός
- Θέματα
- προς
- Τρένο
- προσπαθώ
- δύο
- τύπος
- τυπικός
- συνήθως
- ενημερώθηκε
- ενημερώσεις
- επάνω σε
- us
- Χρήση
- usb
- χρήση
- περίπτωση χρήσης
- μεταχειρισμένος
- Χρήστες
- Χρήστες
- χρησιμοποιώντας
- συνήθως
- χρησιμοποιούνται
- διάφορα
- επαληθεύει
- εκδοχή
- πολύ
- μέσω
- Πραγματικός
- W3
- περιμένετε
- θέλω
- ήταν
- Τρόπος..
- τρόπους
- we
- Ιστοσελίδα : www.example.gr
- ΛΟΙΠΌΝ
- Τι
- Τι είναι
- Τροχός
- πότε
- Ποιό
- Ο ΟΠΟΊΟΣ
- WHY
- ευρέως
- θα
- παράθυρα
- Χρήστες Windows
- με
- εντός
- χωρίς
- Κέρδισε
- Εργασία
- εργαζόμενος
- έτος
- χρόνια
- εσείς
- νέος
- Σας
- zephyrnet









