Το Pandas είναι μια ισχυρή και ευρέως χρησιμοποιούμενη βιβλιοθήκη ανοιχτού κώδικα για χειρισμό και ανάλυση δεδομένων χρησιμοποιώντας Python. Ένα από τα βασικά χαρακτηριστικά του είναι η δυνατότητα ομαδοποίησης δεδομένων χρησιμοποιώντας τη συνάρτηση groupby, χωρίζοντας ένα DataFrame σε ομάδες που βασίζονται σε μία ή περισσότερες στήλες και στη συνέχεια εφαρμόζοντας διάφορες συναρτήσεις συγκέντρωσης σε κάθε μία από αυτές.

Εικόνα από Unsplash
Η groupby Η λειτουργία είναι απίστευτα ισχυρή, καθώς σας επιτρέπει να συνοψίζετε και να αναλύετε γρήγορα μεγάλα σύνολα δεδομένων. Για παράδειγμα, μπορείτε να ομαδοποιήσετε ένα σύνολο δεδομένων κατά μια συγκεκριμένη στήλη και να υπολογίσετε τον μέσο όρο, το άθροισμα ή τον αριθμό των υπολοίπων στηλών για κάθε ομάδα. Μπορείτε επίσης να ομαδοποιήσετε κατά πολλές στήλες για να κατανοήσετε καλύτερα τα δεδομένα σας. Επιπλέον, σας επιτρέπει να εφαρμόζετε προσαρμοσμένες συναρτήσεις συνάθροισης, οι οποίες μπορεί να είναι ένα πολύ ισχυρό εργαλείο για πολύπλοκες εργασίες ανάλυσης δεδομένων.
Σε αυτό το σεμινάριο, θα μάθετε πώς να χρησιμοποιείτε τη συνάρτηση groupby στα Panda για να ομαδοποιείτε διαφορετικούς τύπους δεδομένων και να εκτελείτε διαφορετικές λειτουργίες συγκέντρωσης. Μέχρι το τέλος αυτού του σεμιναρίου, θα πρέπει να μπορείτε να χρησιμοποιήσετε αυτήν τη συνάρτηση για να αναλύσετε και να συνοψίσετε δεδομένα με διάφορους τρόπους.
Οι έννοιες εσωτερικεύονται όταν εξασκούνται καλά και αυτό θα κάνουμε στη συνέχεια, δηλαδή να αποκτήσουμε τα χέρια μας με τη λειτουργία groupby Pandas. Συνιστάται η χρήση α Jupyter Notebook για αυτό το σεμινάριο καθώς μπορείτε να δείτε την έξοδο σε κάθε βήμα.
Δημιουργία Δειγμάτων Δεδομένων
Εισαγάγετε τις ακόλουθες βιβλιοθήκες:
- Pandas: Για να δημιουργήσετε ένα πλαίσιο δεδομένων και να εφαρμόσετε ομάδα κατά
- Τυχαία – Για τη δημιουργία τυχαίων δεδομένων
- Pprint – Για εκτύπωση λεξικών
import pandas as pd
import random
import pprint
Στη συνέχεια, θα αρχικοποιήσουμε ένα κενό πλαίσιο δεδομένων και θα συμπληρώσουμε τιμές για κάθε στήλη όπως φαίνεται παρακάτω:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Συμβουλή μπόνους – ένας πιο καθαρός τρόπος για να κάνετε την ίδια εργασία είναι να δημιουργήσετε ένα λεξικό με όλες τις μεταβλητές και τις τιμές και αργότερα να το μετατρέψετε σε πλαίσιο δεδομένων.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
Το πλαίσιο δεδομένων μοιάζει με αυτό που φαίνεται παρακάτω. Κατά την εκτέλεση αυτού του κώδικα, ορισμένες από τις τιμές δεν θα ταιριάζουν, καθώς χρησιμοποιούμε ένα τυχαίο δείγμα.
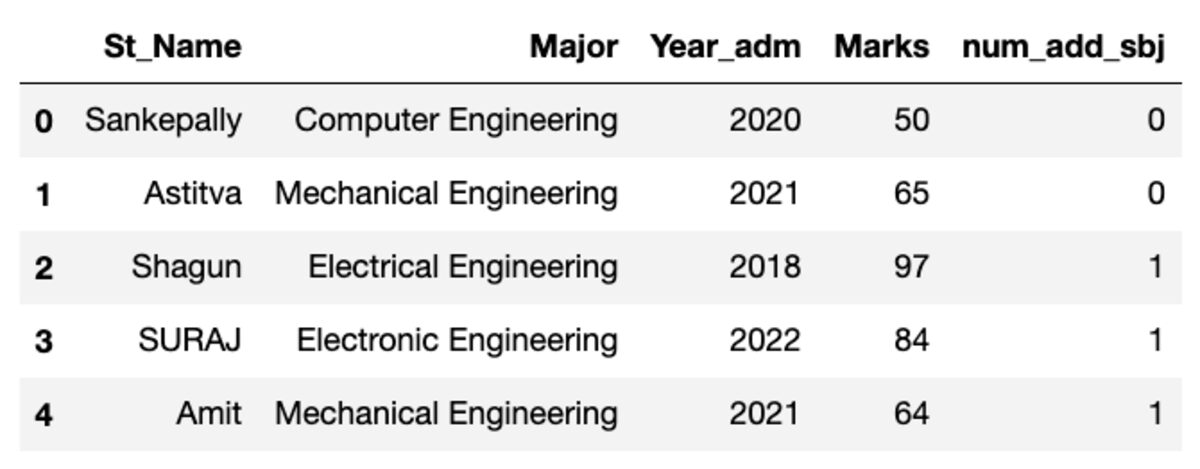
Δημιουργία Ομάδων
Ας ομαδοποιήσουμε τα δεδομένα κατά το θέμα "Κύρια" και ας εφαρμόσουμε το φίλτρο ομάδας για να δούμε πόσες εγγραφές ανήκουν σε αυτήν την ομάδα.
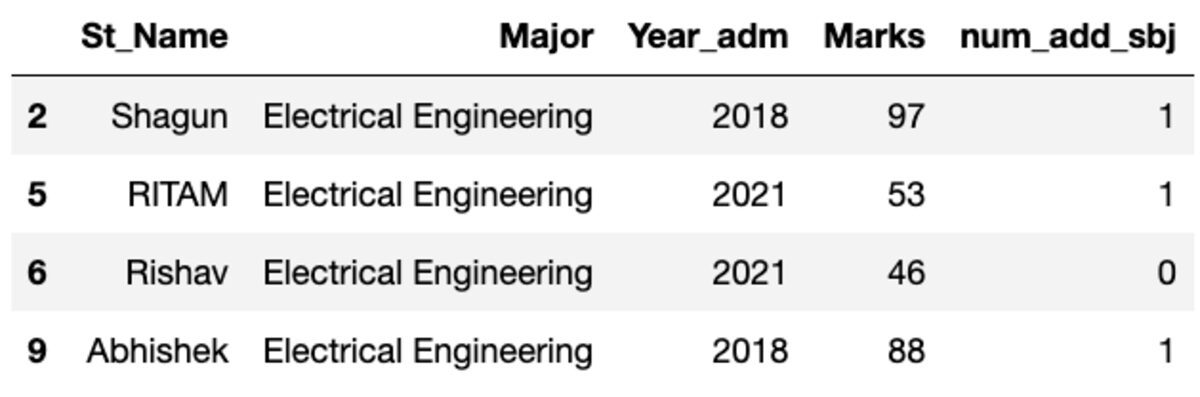
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Τέσσερις λοιπόν φοιτητές ανήκουν στην κατεύθυνση Ηλεκτρολόγων Μηχανικών.
Μπορείτε επίσης να ομαδοποιήσετε περισσότερες από μία στήλες (Major και num_add_sbj σε αυτήν την περίπτωση).
groups = df.groupby(['Major', 'num_add_sbj'])
Σημειώστε ότι όλες οι συγκεντρωτικές συναρτήσεις που μπορούν να εφαρμοστούν σε ομάδες με μία στήλη μπορούν να εφαρμοστούν σε ομάδες με πολλές στήλες. Για το υπόλοιπο του σεμιναρίου, ας εστιάσουμε στους διαφορετικούς τύπους συναθροίσεων χρησιμοποιώντας μια στήλη ως παράδειγμα.
Ας δημιουργήσουμε ομάδες χρησιμοποιώντας groupby στη στήλη "Major".
groups = df.groupby('Major')Εφαρμογή άμεσων συναρτήσεων
Ας υποθέσουμε ότι θέλετε να βρείτε τη μέση βαθμολογία σε κάθε Major. Τι θα έκανες?
- Επιλέξτε τη στήλη "Σήματα".
- Εφαρμογή μέσης συνάρτησης
- Εφαρμογή στρογγυλής συνάρτησης για στρογγυλοποίηση των σημείων σε δύο δεκαδικά ψηφία (προαιρετικό)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Σύνολο
Ένας άλλος τρόπος για να επιτύχετε το ίδιο αποτέλεσμα είναι χρησιμοποιώντας μια συνάρτηση συγκεντρωτικών στοιχείων όπως φαίνεται παρακάτω:
groups['Marks'].aggregate('mean').round(2)
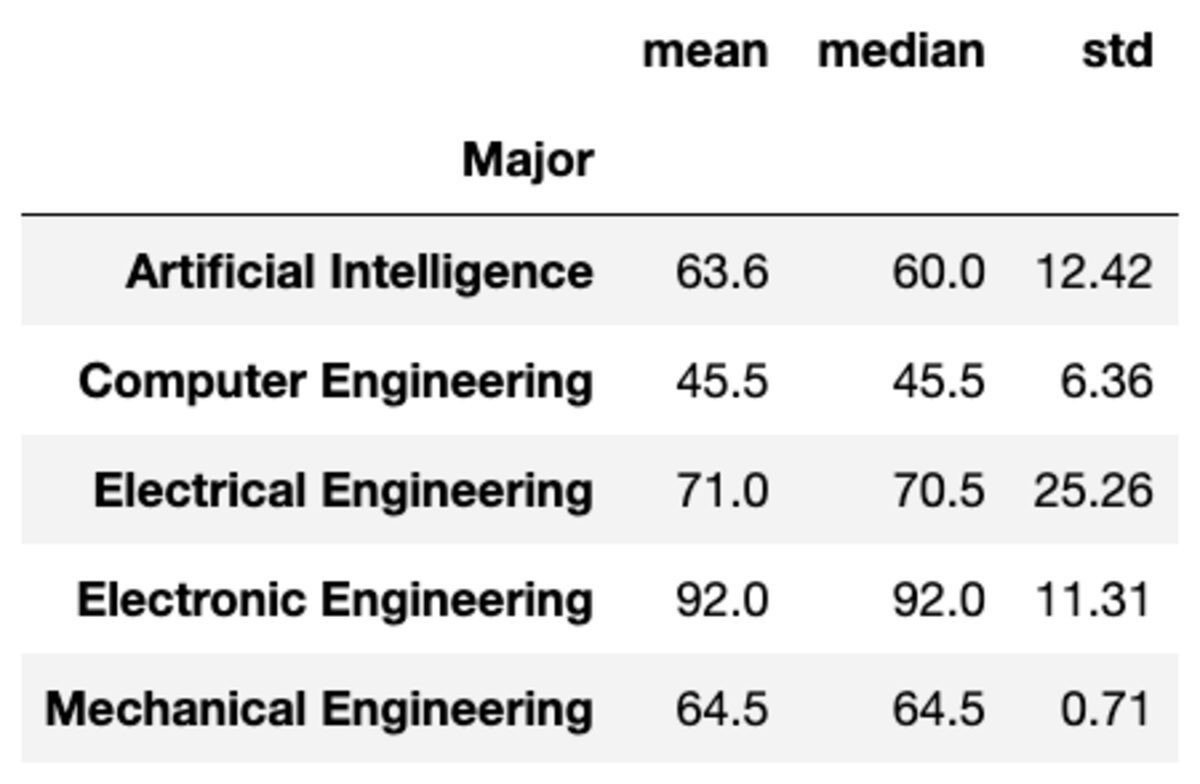
Μπορείτε επίσης να εφαρμόσετε πολλαπλές συναθροίσεις στις ομάδες περνώντας τις συναρτήσεις ως λίστα συμβολοσειρών.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
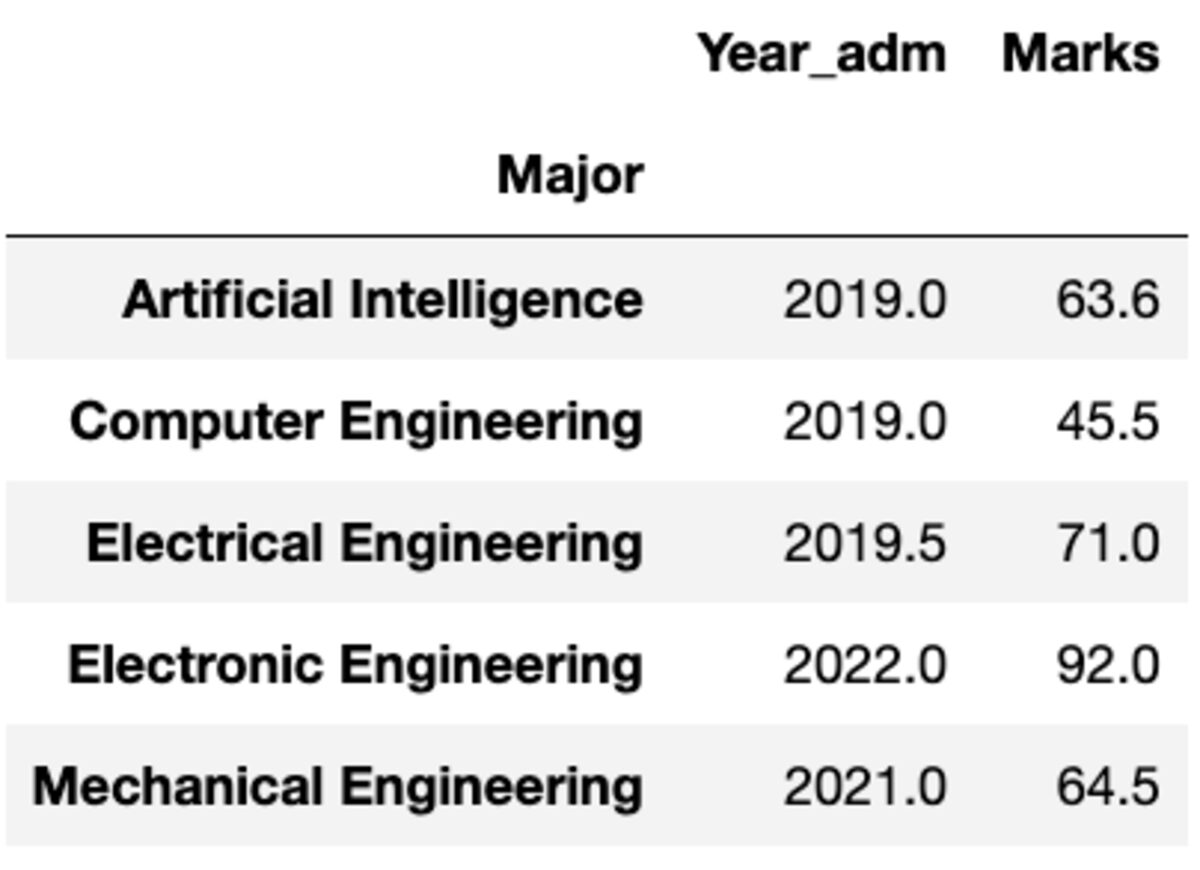
Τι γίνεται όμως αν χρειαστεί να εφαρμόσετε διαφορετική συνάρτηση σε διαφορετική στήλη. Μην ανησυχείς. Μπορείτε επίσης να το κάνετε αυτό περνώντας το ζεύγος {column: function}.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Μεταμορφώσεις
Ίσως χρειαστεί να εκτελέσετε προσαρμοσμένους μετασχηματισμούς σε μια συγκεκριμένη στήλη, οι οποίοι μπορούν εύκολα να επιτευχθούν χρησιμοποιώντας το groupby(). Ας ορίσουμε μια τυπική κλίμακα παρόμοια με αυτή που είναι διαθέσιμη στη μονάδα προεπεξεργασίας του sklearn. Μπορείτε να μετατρέψετε όλες τις στήλες καλώντας τη μέθοδο μετασχηματισμού και περνώντας την προσαρμοσμένη συνάρτηση.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
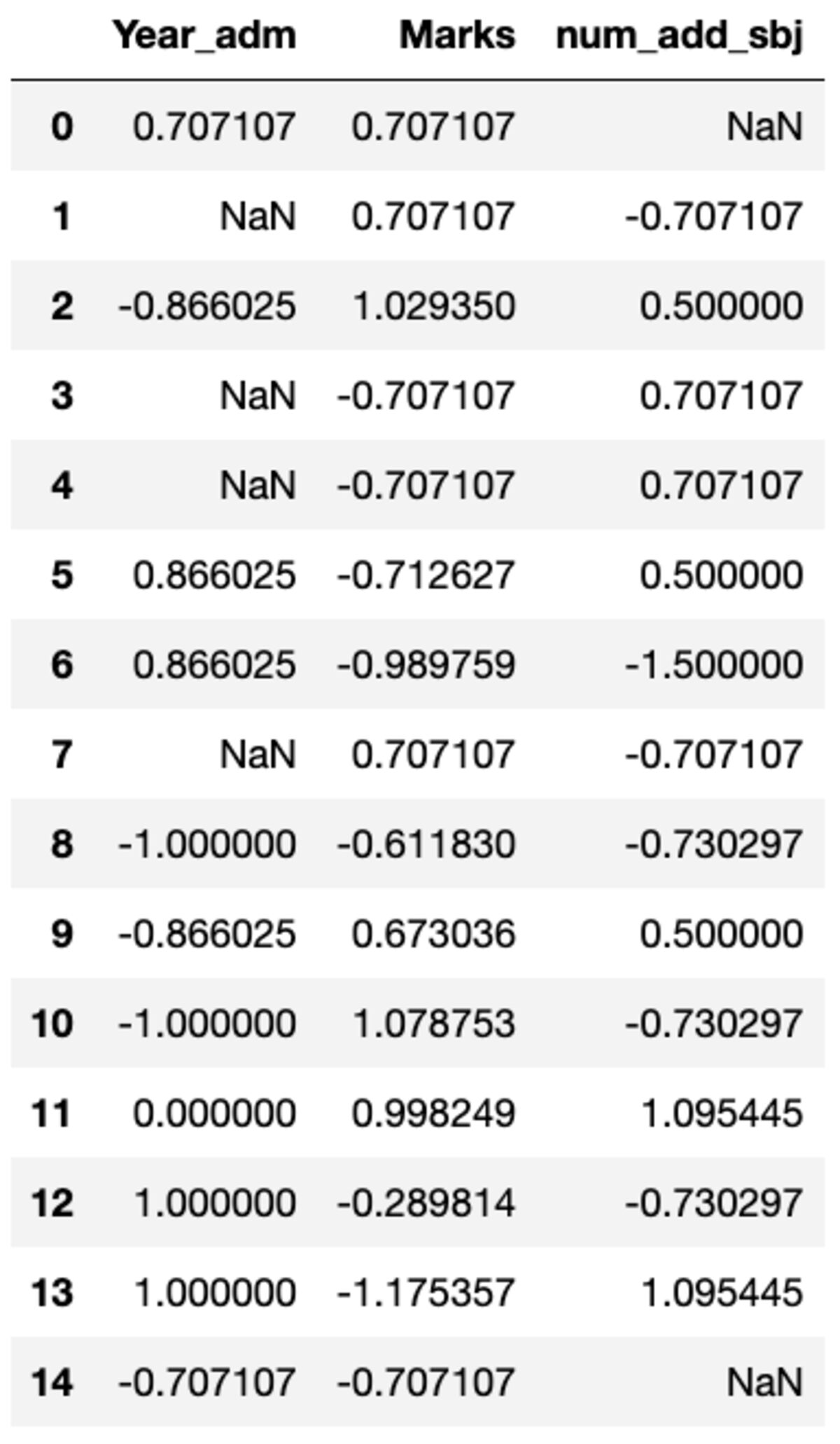
Σημειώστε ότι το "NaN" αντιπροσωπεύει ομάδες με μηδενική τυπική απόκλιση.
Φίλτρα
Ίσως θελήσετε να ελέγξετε ποια «Κύρια» έχει χαμηλότερη απόδοση, δηλαδή αυτή όπου οι μέσες «Βαθμοί» μαθητή είναι μικρότεροι από 60. Απαιτεί από εσάς να εφαρμόσετε μια μέθοδο φίλτρου σε ομάδες με μια συνάρτηση μέσα σε αυτήν. Ο παρακάτω κώδικας χρησιμοποιεί α συνάρτηση λάμδα για να επιτύχετε τα φιλτραρισμένα αποτελέσματα.
groups.filter(lambda x: x['Marks'].mean() 60)

Όνομα
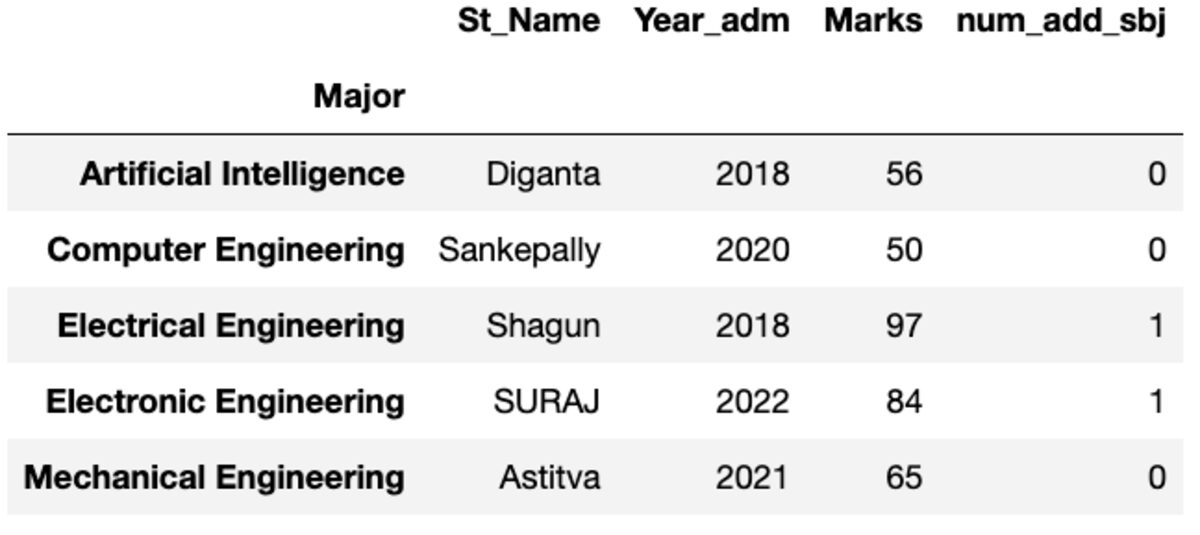
Σας δίνει την πρώτη του παρουσία ταξινομημένη κατά ευρετήριο.
groups.first()
Περιγράφω
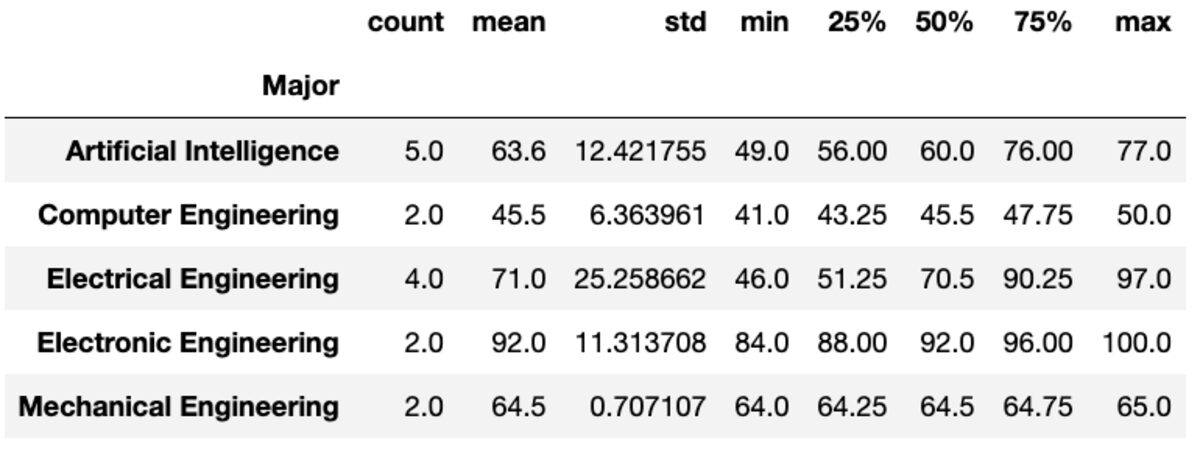
Η μέθοδος "describe" επιστρέφει βασικά στατιστικά στοιχεία όπως count, mean, std, min, max, κ.λπ. για τις δεδομένες στήλες.
groups['Marks'].describe()
Μέγεθος
Το μέγεθος, όπως υποδηλώνει το όνομα, επιστρέφει το μέγεθος κάθε ομάδας ως προς τον αριθμό των εγγραφών.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64Count και Nunique
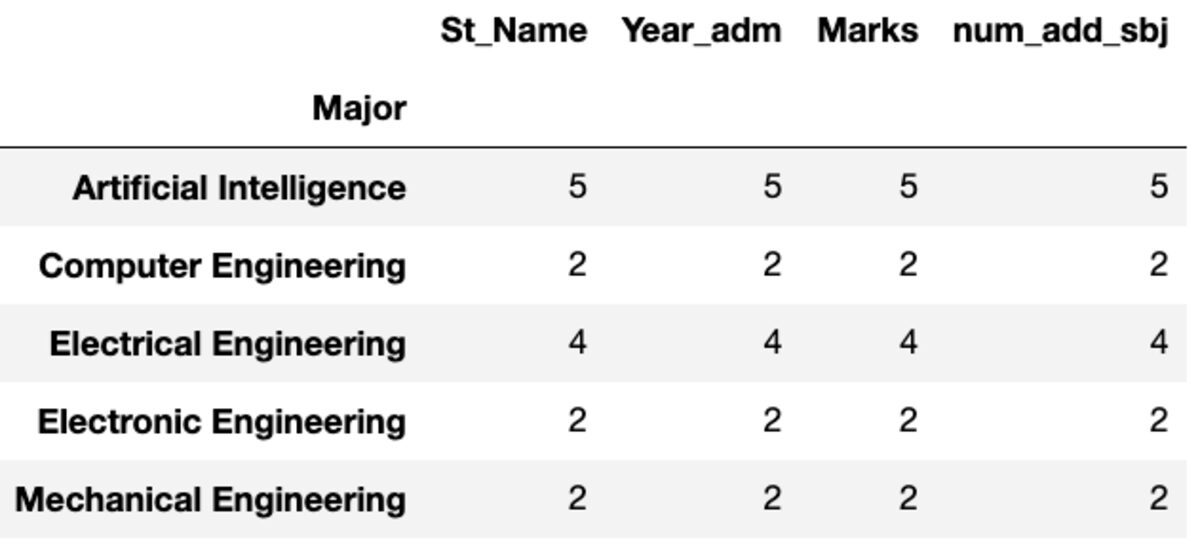
Το "Count" επιστρέφει όλες τις τιμές ενώ το "Nunique" επιστρέφει μόνο τις μοναδικές τιμές σε αυτήν την ομάδα.
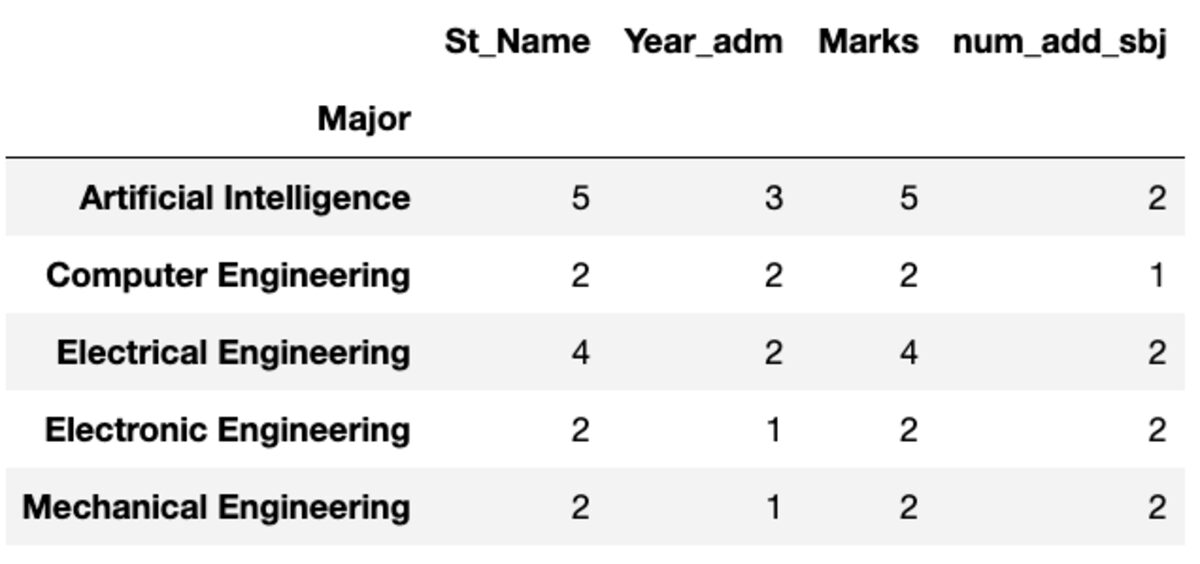
groups.count()
groups.nunique()
Μετονομασία
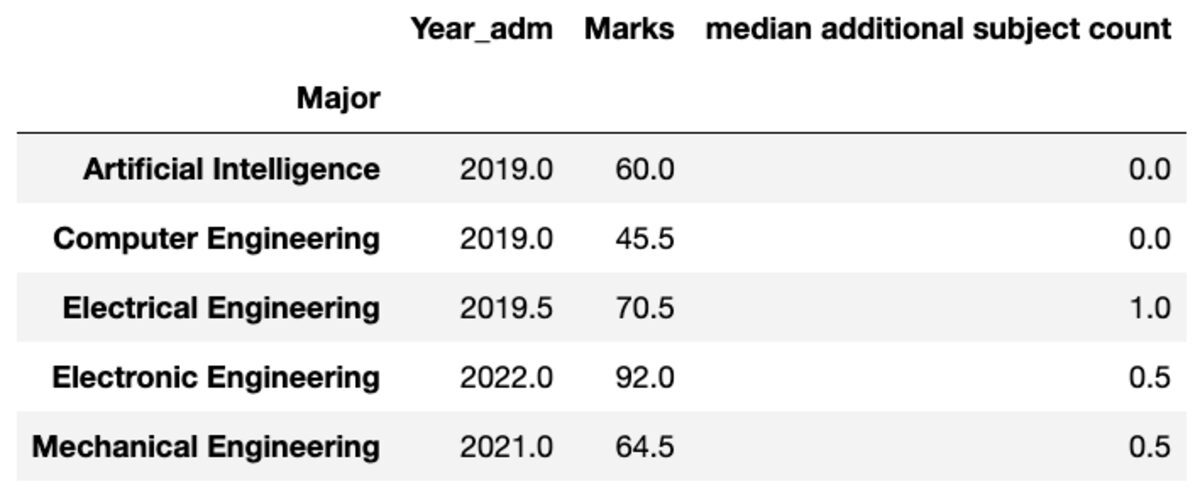
Μπορείτε επίσης να μετονομάσετε το όνομα των συγκεντρωτικών στηλών σύμφωνα με τις προτιμήσεις σας.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Να είστε σαφείς σχετικά με το σκοπό της ομάδας: Προσπαθείτε να ομαδοποιήσετε τα δεδομένα κατά μία στήλη για να λάβετε τον μέσο όρο μιας άλλης στήλης; Ή προσπαθείτε να ομαδοποιήσετε τα δεδομένα κατά πολλές στήλες για να λάβετε τον αριθμό των γραμμών σε κάθε ομάδα;
- Κατανοήστε την ευρετηρίαση του πλαισίου δεδομένων: Η συνάρτηση groupby χρησιμοποιεί το ευρετήριο για να ομαδοποιήσει τα δεδομένα. Εάν θέλετε να ομαδοποιήσετε τα δεδομένα ανά στήλη, βεβαιωθείτε ότι η στήλη έχει οριστεί ως ευρετήριο ή μπορείτε να χρησιμοποιήσετε το .set_index()
- Χρησιμοποιήστε την κατάλληλη συνάρτηση συγκεντρωτικών στοιχείων: Μπορεί να χρησιμοποιηθεί με διάφορες συναρτήσεις συγκέντρωσης όπως mean(), sum(), count(), min(), max()
- Χρησιμοποιήστε την παράμετρο as_index: Όταν οριστεί σε False, αυτή η παράμετρος λέει στα panda να χρησιμοποιούν τις ομαδοποιημένες στήλες ως κανονικές στήλες αντί για ευρετήριο.
Μπορείτε επίσης να χρησιμοποιήσετε το groupby() σε συνδυασμό με άλλες συναρτήσεις panda, όπως pivot_table(), crosstab() και cut() για να εξαγάγετε περισσότερες πληροφορίες από τα δεδομένα σας.
Μια συνάρτηση groupby είναι ένα ισχυρό εργαλείο για ανάλυση και χειρισμό δεδομένων, καθώς σας επιτρέπει να ομαδοποιήσετε σειρές δεδομένων με βάση μία ή περισσότερες στήλες και στη συνέχεια να εκτελέσετε συγκεντρωτικούς υπολογισμούς στις ομάδες. Το σεμινάριο παρουσίασε διάφορους τρόπους χρήσης της συνάρτησης groupby με τη βοήθεια παραδειγμάτων κώδικα. Ελπίζουμε ότι θα σας παρέχει μια κατανόηση των διαφορετικών επιλογών που το συνοδεύουν και επίσης πώς βοηθούν στην ανάλυση δεδομένων.
Vidhi Chugh είναι ένας στρατηγός τεχνητής νοημοσύνης και ένας ηγέτης ψηφιακού μετασχηματισμού που εργάζεται στη διασταύρωση προϊόντων, επιστημών και μηχανικής για την κατασκευή κλιμακούμενων συστημάτων μηχανικής μάθησης. Είναι βραβευμένη ηγέτης καινοτομίας, συγγραφέας και διεθνής ομιλήτρια. Είναι σε μια αποστολή να εκδημοκρατίσει τη μηχανική μάθηση και να σπάσει τη φρασεολογία για να είναι όλοι μέρος αυτού του μετασχηματισμού.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- ικανότητα
- Ικανός
- Κατορθώνω
- επιτευχθεί
- Πρόσθετος
- Επιπλέον
- συσσωμάτωση
- AI
- Όλα
- επιτρέπει
- ανάλυση
- αναλύσει
- και
- Άλλος
- εφαρμοσμένος
- Εφαρμογή
- εφαρμόζοντας
- κατάλληλος
- τεχνητός
- τεχνητή νοημοσύνη
- συγγραφέας
- διαθέσιμος
- μέσος
- βραβευμένο
- βασίζονται
- βασικός
- παρακάτω
- Βιοτεχνολογίας
- Διακοπή
- χτίζω
- υπολογίσει
- κλήση
- περίπτωση
- έλεγχος
- καθαρός
- κωδικός
- Στήλη
- Στήλες
- Ελάτε
- συγκρότημα
- υπολογιστή
- Μηχανικός ηλεκτρονικών υπολογιστών
- δημιουργία
- δημιουργία
- έθιμο
- ημερομηνία
- ανάλυση δεδομένων
- σύνολα δεδομένων
- εκδημοκρατίζω
- κατέδειξε
- απόκλιση
- διαφορετικές
- ψηφιακό
- ψηφιακή Μετασχηματισμού
- κατευθύνει
- Μην
- κάθε
- εύκολα
- αποτελεσματικά
- Ηλεκτρολόγων Μηχανικών
- Ηλεκτρονικός
- Μηχανική
- κ.λπ.
- όλοι
- παράδειγμα
- παραδείγματα
- εκχύλισμα
- Πτώση
- Χαρακτηριστικά
- συμπληρώστε
- φιλτράρισμα
- Εύρεση
- Όνομα
- Συγκέντρωση
- Εξής
- ΠΛΑΙΣΙΟ
- από
- λειτουργία
- λειτουργίες
- παράγουν
- παίρνω
- δεδομένου
- δίνει
- μετάβαση
- Group
- Ομάδα
- hands-on
- βοήθεια
- ελπίζω
- Πως
- Πώς να
- HTML
- HTTPS
- εισαγωγή
- in
- απίστευτα
- ευρετήριο
- Καινοτομία
- ιδέες
- παράδειγμα
- αντί
- Νοημοσύνη
- International
- διασταύρωση
- IT
- ορολογία
- KDnuggets
- Κλειδί
- large
- ηγέτης
- ΜΑΘΑΊΝΩ
- μάθηση
- βιβλιοθήκες
- Βιβλιοθήκη
- Λιστα
- ΦΑΊΝΕΤΑΙ
- μηχανή
- μάθηση μηχανής
- μεγάλες
- κάνω
- Χειρισμός
- πολοί
- Ταίριασμα
- max
- μηχανικός
- μηχανολογία
- medium
- μέθοδος
- Αποστολή
- ενότητα
- περισσότερο
- πολλαπλούς
- όνομα
- ονόματα
- Ανάγκη
- επόμενη
- αριθμός
- ONE
- ανοικτού κώδικα
- λειτουργίες
- Επιλογές
- ΑΛΛΑ
- Πάντα
- παράμετρος
- μέρος
- Ειδικότερα
- Πέρασμα
- εκτελέσει
- Μέρη
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- ισχυρός
- Προϊόν
- παρέχει
- σκοπός
- Python
- γρήγορα
- τυχαίος
- συνιστάται
- αρχεία
- τακτικός
- υπόλοιπα
- αντιπροσωπεύει
- Απαιτεί
- ΠΕΡΙΦΕΡΕΙΑ
- αποτέλεσμα
- Αποτελέσματα
- απόδοση
- Επιστροφές
- Richard
- γύρος
- τρέξιμο
- ίδιο
- επεκτάσιμη
- ΕΠΙΣΤΗΜΕΣ
- σειρά
- θα πρέπει να
- παρουσιάζεται
- παρόμοιες
- ενιαίας
- Μέγεθος
- μερικοί
- Ομιλητής
- συγκεκριμένες
- πρότυπο
- στατιστική
- Βήμα
- Στρατηγός
- Φοιτητής
- Φοιτητές
- θέμα
- Προτείνει
- συνοψίζω
- συστήματα
- Έργο
- εργασίες
- λέει
- όροι
- Η
- τύπος
- προς την
- εργαλείο
- Μεταμορφώστε
- Μεταμόρφωση
- μετασχηματισμούς
- φροντιστήριο
- τύποι
- κατανόηση
- μοναδικός
- χρήση
- Αξίες
- διάφορα
- τρόπους
- Τι
- Ποιό
- θα
- εργαζόμενος
- θα
- X
- έτος
- Σας
- zephyrnet
- μηδέν








