Το web scraping μπορεί να είναι ένα ισχυρό εργαλείο για την εξαγωγή δεδομένων από ιστότοπους, αλλά μπορεί επίσης να είναι μια πολύπλοκη και χρονοβόρα διαδικασία. Ευτυχώς, τα Φύλλα Google προσφέρουν μια φιλική προς το χρήστη λύση για απόξεση δεδομένων από ιστότοπους χωρίς να χρειάζεται να γράψετε πολύπλοκο κώδικα. Αξιοποιώντας τη δύναμη των Φύλλων Google, μπορείτε εύκολα να εξαγάγετε δεδομένα από ιστοσελίδες και να τα αναλύσετε με διάφορους τρόπους. Σε αυτό το ιστολόγιο, θα σας καθοδηγήσω στη διαδικασία χρήσης των Φύλλων Google για την απόξεση ιστοσελίδων και θα σας βοηθήσω να ξεκλειδώσετε τις δυνατότητες της απόξεσης ιστού για τα δικά σας έργα. Λοιπόν, ας ξεκινήσουμε!
Το Web Scraping μπορεί να είναι χρονοβόρο, πολύπλοκο και να περιλαμβάνει πολλή κωδικοποίηση. Για μη κωδικοποιητές. Τα Φύλλα Google είναι μια εξαιρετική εναλλακτική λύση για την απόξεση ιστού. Η απόξεση ιστού φύλλων Google δεν περιλαμβάνει κωδικοποίηση και παρέχει πολλούς τρόπους ανάλυσης δεδομένων ιστότοπου.
Σε αυτό το ιστολόγιο θα δούμε πώς να χρησιμοποιείτε τα Φύλλα Google για να ξύνετε εύκολα ιστοσελίδες. Ας ξεκινήσουμε λοιπόν!
Γιατί να χρησιμοποιήσετε τα Φύλλα Google για απόξεση Ιστού;
Υπάρχουν διάφοροι λόγοι για τους οποίους τα Φύλλα Google είναι ένα εξαιρετικό εργαλείο για την απόξεση ιστού:
- Τα Φύλλα Google είναι φιλικά προς το χρήστη και έχουν μια οικεία διεπαφή.
- Δεν απαιτεί γνώση γλώσσας προγραμματισμού.
- Τα Φύλλα Google είναι προσβάσιμα από οπουδήποτε.
- Τα Φύλλα Google είναι δωρεάν, καθιστώντας τα οικονομικά προσιτά για ιδιώτες και μικρές επιχειρήσεις.
- Η Google ενσωματώνεται εύκολα με άλλα εργαλεία του Suite.
- Μπορείτε να χρησιμοποιήσετε μακροεντολές ή σενάρια για να αυτοματοποιήσετε εργασίες απόξεσης ιστού.
- Μπορείτε εύκολα να αναλύσετε τα αποξεσμένα δεδομένα χρησιμοποιώντας τύπους Φύλλων Google.
Εξαγωγή κειμένου από οποιαδήποτε ιστοσελίδα με ένα μόνο κλικ. Πηγαίνετε στο Nanonets ξύστρα ιστότοπου, Προσθέστε τη διεύθυνση URL και κάντε κλικ στο "Scrape" και κατεβάστε το κείμενο της ιστοσελίδας ως αρχείο αμέσως. Δοκιμάστε το δωρεάν τώρα.
Ποιες λειτουργίες να χρησιμοποιηθούν για την απόξεση Ιστού των Φύλλων Google;
Ακολουθούν ορισμένες λειτουργίες που μπορείτε να χρησιμοποιήσετε όταν χρειάζεται να ξύσετε ιστοσελίδες χρησιμοποιώντας τα Φύλλα Google.
IMPORTHTML:
Εξαγωγή πινάκων και λιστών από σελίδες HTML.
=IMPORTHTML(url, query, index)- url: Αυτός είναι ο σύνδεσμος της ιστοσελίδας που θέλετε να ξύσετε
- ερώτημα: Ο τύπος δεδομένων – Πίνακας, Λίστα
- ευρετήριο: Εάν θέλετε να εξαγάγετε έναν συγκεκριμένο πίνακα, μπορείτε να το χρησιμοποιήσετε
Παράδειγμα:
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)","table",1)IMPORTXML:
Εξαγωγή δεδομένων από σελίδες XML.
=IMPORTXML(url, xpath_query)- url: Αυτός είναι ο σύνδεσμος προς την ιστοσελίδα που θέλετε να ξύσετε
- xpath_query: η έκφραση XPath που προσδιορίζει τα δεδομένα που θέλετε να εξαγάγετε
Παράδειγμα:
=IMPORTXML("https://www.w3schools.com/xml/note.xml", "//note/to")ΕΙΣΑΓΩΓΙΚΑ ΣΤΟΙΧΕΙΑ:
Εξαγωγή δεδομένων από αρχεία CSV και TSV.
=IMPORTDATA(url)- url: η διεύθυνση URL του αρχείου CSV ή TSV από το οποίο θέλετε να εξαγάγετε δεδομένα
Παράδειγμα:
=IMPORTDATA("https://www.stats.govt.nz/assets/Uploads/Annual-enterprise-survey/Annual-enterprise-survey-2021-financial-year-provisional/Download-data/annual-enterprise-survey-2021-financial-year-provisional-size-bands.csv")REGEXTRACT:
Αυτή η συνάρτηση μπορεί να εξαγάγει δεδομένα που ταιριάζουν με ένα τυπικό μοτίβο έκφρασης.
=REGEXEXTRACT(text, regular_expression)- κείμενο: το κείμενο που θέλετε να αναζητήσετε το μοτίβο
- regular_expression: το μοτίβο που θέλετε να ταιριάξετε
Παράδειγμα:
=REGEXEXTRACT("1 pound = $1.40", "$d+.d+")Σημείωση: Αυτές οι λειτουργίες ενδέχεται να μην λειτουργούν για κάθε ιστότοπο. Εξαρτάται από τη διάταξη του ιστότοπου. Σε περίπτωση που χρειάζεστε περισσότερα δεδομένα, μπορείτε να καταφύγετε σε σεμινάρια απόξεσης ιστού χρησιμοποιώντας Python και Java ή να χρησιμοποιήσετε εργαλεία από ιστότοπο σε κείμενο όπως το Nanonets.
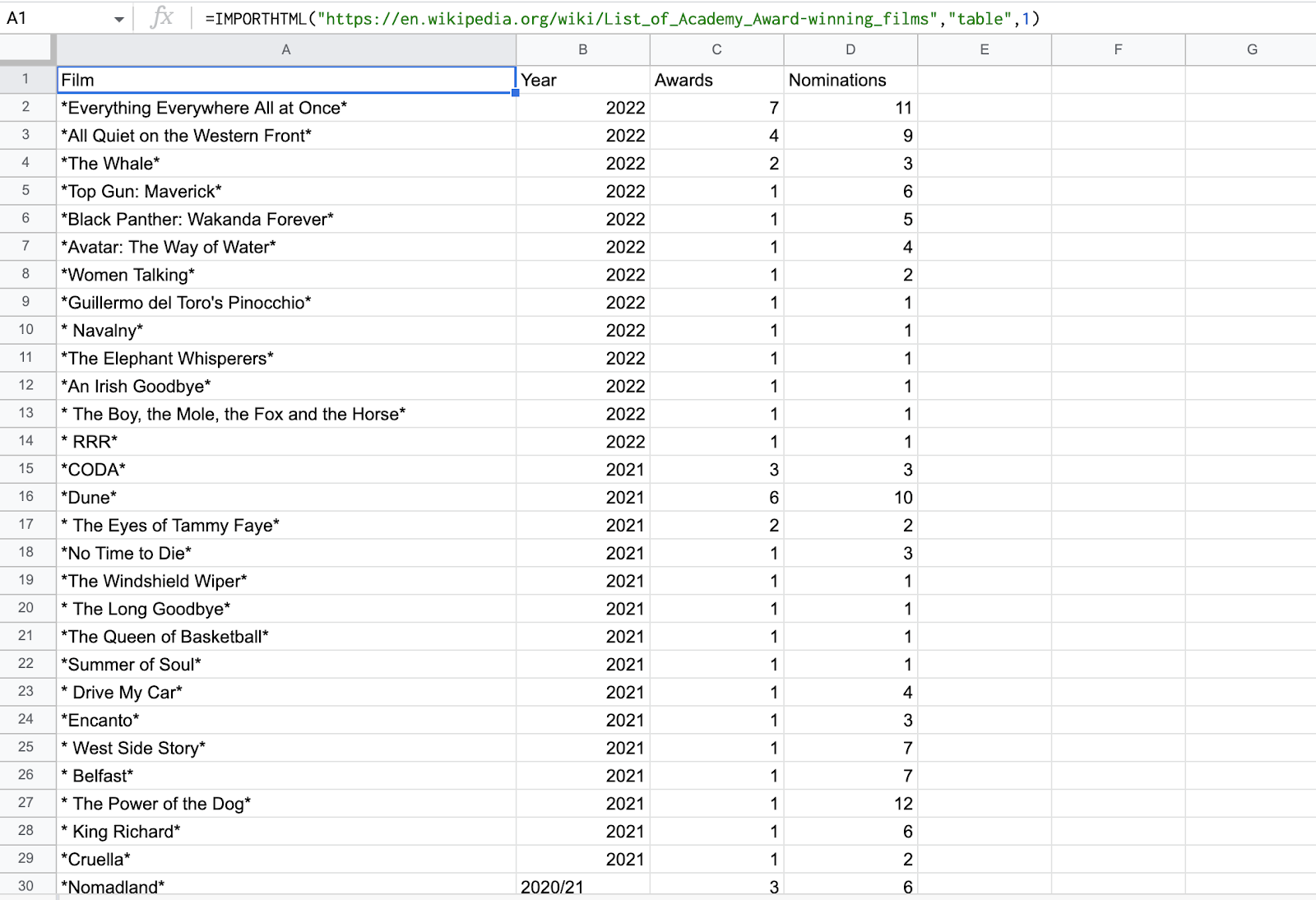
Ας προσπαθήσουμε να εξάγουμε έναν πίνακα HTML στα Φύλλα Google. Θα προσπαθήσουμε να ξύσουμε το τραπέζι από το Κατάλογος ταινιών που βραβεύτηκαν με Όσκαρ Σελίδα Wikipedia.
- Ανοίξτε τα Φύλλα Google.
- Σε ένα νέο κελί, πληκτρολογήστε =IMPORTHTML(url, ερώτημα, ευρετήριο)
1. Ο κωδικός μας γίνεται,
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","table",1) =IMPORTHTML(“https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films”,”πίνακας”,1)
θα ξύσει τον πρώτο πίνακα στη σελίδα της Wikipedia
3. Ελέγξτε τα αποτελέσματα
Πώς να ξύσετε δεδομένα χρησιμοποιώντας την απόξεση ιστού των Φύλλων Google;
Ας δούμε πώς να ξύνουμε τίτλους, περιγραφές, H1 και άλλα χρησιμοποιώντας τα Φύλλα Google. Για να ξεκινήσουμε με το ξύσιμο H1 με τα Φύλλα Google, θα χρησιμοποιήσουμε τη λειτουργία IMPORTXML για αυτό το συγκεκριμένο Σελίδα Nanonets. Εδώ είναι τα βήματα:
- Ανοίξτε ένα νέο ή υπάρχον Φύλλο Google.
- Σε ένα κελί, πληκτρολογήστε τον ακόλουθο τύπο:
=IMPORTXML(“https://nanonets.com/image-to-text”, “//h1/text()”)- Για να εξαγάγετε την ετικέτα H1, χρησιμοποιήστε την ακόλουθη έκφραση XPath: //h1/text()
- Για να εξαγάγετε την ετικέτα τίτλου, χρησιμοποιήστε την ακόλουθη έκφραση XPath: //title/text()
- Για να εξαγάγετε την ετικέτα περιγραφής meta, χρησιμοποιήστε την ακόλουθη έκφραση XPath: //meta[@name='description']/@content
- Για να εξαγάγετε όλους τους συνδέσμους σελίδων, χρησιμοποιήστε την ακόλουθη έκφραση XPath: //a/@href
Πατήστε Enter και τα Φύλλα Google θα ξύσουν αυτόματα τα δεδομένα και θα τα εμφανίσουν στο επιλεγμένο κελί.
Στη συνέχεια, μπορείτε να αντιγράψετε τον τύπο σε άλλα κελιά για να αφαιρέσετε πρόσθετα δεδομένα από τις ίδιες ή διαφορετικές ιστοσελίδες.
Εξαγωγή κειμένου από οποιαδήποτε ιστοσελίδα με ένα μόνο κλικ. Πηγαίνετε στο Nanonets ξύστρα ιστότοπου, Προσθέστε τη διεύθυνση URL και κάντε κλικ στο "Scrape" και κατεβάστε το κείμενο της ιστοσελίδας ως αρχείο αμέσως. Δοκιμάστε το δωρεάν τώρα.
Ποια είναι τα μειονεκτήματα της χρήσης του Google Sheets Web Scraper;
- Τα Φύλλα Google έχουν περιορισμένες δυνατότητες. Όταν πρόκειται για σύνθετες διατάξεις, δεν μπορεί να χειριστεί δυναμικό περιεχόμενο.
- Ενδέχεται να υπάρχουν ασυμφωνίες δεδομένων κατά την απόξεση δεδομένων χρησιμοποιώντας τύπους απόξεσης ιστού των Φύλλων Google.
- Κατά την απόξεση δεδομένων από ιστότοπους, ενδέχεται να αφαιρέσετε κατά λάθος ευαίσθητες ή εμπιστευτικές πληροφορίες. Αυτό μπορεί να εγείρει ανησυχίες σχετικά με το απόρρητο και την ασφάλεια, ειδικά εάν τα αποκομμένα δεδομένα κοινοποιούνται ή αποθηκεύονται σε μη ασφαλή τοποθεσία.
Συμβουλή: Το Google Sheets Web Scraping είναι μια εξαιρετική εναλλακτική λύση για μη σύνθετες εργασίες απόξεσης ιστού, όπως μετα-τίτλους, λίστες ή εξαγωγή πινάκων. Για πολύπλοκες εργασίες, θα πρέπει να χρησιμοποιείτε εργαλεία απόξεσης ιστού.
FAQs
Μπορώ να κάνω scrape στον ιστό με τα Φύλλα Google;
Ναι, τα Φύλλα Google έχουν ενσωματωμένες λειτουργίες όπως IMPORTHTML, IMPORTXML, IMPORTDATA,
και REGEXTRACT που σας επιτρέπουν να καταγράφετε δεδομένα από ιστότοπους απευθείας στα Φύλλα Google. Ωστόσο, η λειτουργικότητα μπορεί να είναι περιορισμένη και οι πιο περίπλοκες εργασίες απόξεσης ιστού ενδέχεται να απαιτούν τη χρήση ξεχωριστού ξύστρου ιστού ή τη σύνταξη προσαρμοσμένου κώδικα.
Πώς μπορώ να ξύσω δεδομένα σε ένα φύλλο Google;
Μπορείτε να εγγράψετε δεδομένα σε ένα Φύλλο Google χρησιμοποιώντας μία από τις ενσωματωμένες λειτουργίες όπως IMPORTHTML, IMPORTXML, IMPORTDATA ή REGEXTRACT. Αυτές οι λειτουργίες σάς επιτρέπουν να εξάγετε δεδομένα από ιστότοπους, αρχεία CSV ή TSV και να ταιριάζετε με μοτίβα κανονικών εκφράσεων. Απλώς καθορίστε τη διεύθυνση URL, το ερώτημα, το ευρετήριο ή το μοτίβο τυπικής έκφρασης και τα δεδομένα θα εγγραφούν και θα συμπληρωθούν στο Φύλλο Google σας.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://nanonets.com/blog/scrape-websites-using-google-sheets-formulas/
- :είναι
- 1
- 11
- 2023
- 7
- a
- Ακαδημία
- προσιτός
- Πρόσθετος
- προσιτές
- Όλα
- εναλλακτική λύση
- αναλύσει
- και
- οπουδήποτε
- ΕΙΝΑΙ
- AS
- αυτοματοποίηση
- αυτομάτως
- βραβευμένο
- BE
- γίνεται
- Μπλοκ
- ενσωματωμένο
- επιχειρήσεις
- by
- CAN
- δυνατότητες
- πιάνω
- περίπτωση
- Κύτταρα
- έλεγχος
- κλικ
- Κλεισιμο
- κωδικός
- Κωδικοποίηση
- συγκρότημα
- Πιθανά ερωτήματα
- περιεχόμενο
- έθιμο
- ημερομηνία
- εξαρτάται
- περιγραφή
- διαφορετικές
- κατευθείαν
- Display
- κατεβάσετε
- δυναμικός
- κάθε
- εύκολα
- εισάγετε
- ειδικά
- Αιθέρας (ΕΤΗ)
- Κάθε
- έξοχος
- υφιστάμενα
- εκχύλισμα
- εξαγωγή
- οικείος
- Χαρακτηριστικά
- Αρχεία
- Αρχεία
- ταινίες
- Όνομα
- Εξής
- Για
- τύπος
- Ευτυχώς
- Δωρεάν
- από
- λειτουργία
- λειτουργικότητα
- λειτουργίες
- παίρνω
- Κυβέρνηση
- εξαιρετική
- καθοδηγήσει
- λαβή
- κεφάλι
- βοήθεια
- εδώ
- Πως
- Πώς να
- Ωστόσο
- HTML
- HTTPS
- i
- αναγνωρίζει
- in
- ευρετήριο
- άτομα
- πληροφορίες
- Ενσωματώνει
- περιβάλλον λειτουργίας
- εμπλέκω
- IT
- Java
- μόνο ένα
- γνώση
- Γλώσσα
- σχέδιο
- μόχλευσης
- Μου αρέσει
- Περιωρισμένος
- LINK
- ΣΥΝΔΕΣΜΟΙ
- Λίστες
- τοποθεσία
- Παρτίδα
- μακροεντολές
- Κατασκευή
- πολοί
- Ταίριασμα
- Meta
- ενδέχεται να
- περισσότερο
- Ανάγκη
- χρειάζονται
- Νέα
- of
- προσφορές
- on
- ONE
- τάξη
- ΑΛΛΑ
- δική
- σελίδα
- Ειδικότερα
- πρότυπο
- πρότυπα
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- κατοικημένη περιοχή
- δυναμικού
- λίρα
- δύναμη
- ισχυρός
- μυστικότητα
- Απορρήτου και Ασφάλεια
- διαδικασια μας
- Προγραμματισμός
- έργα
- παρέχει
- Python
- αύξηση
- λόγους
- τακτικός
- απαιτούν
- Απαιτεί
- Resort
- s
- ίδιο
- απόξεση
- Εφαρμογές
- Αναζήτηση
- ασφάλεια
- επιλέγονται
- ευαίσθητος
- ξεχωριστό
- διάφοροι
- Shared
- θα πρέπει να
- Απλούς
- απλά
- small
- μικρές επιχειρήσεις
- So
- λύση
- μερικοί
- συγκεκριμένες
- ξεκίνησε
- stats
- Βήματα
- αποθηκεύονται
- τέτοιος
- σουίτα
- τραπέζι
- εξαγωγή τραπεζιού
- TAG
- εργασίες
- ότι
- Η
- Αυτοί
- Μέσω
- χρονοβόρος
- Τίτλος
- τίτλους
- προς την
- εργαλείο
- εργαλεία
- tutorials
- ξεκλειδώσετε
- χωρίς ασφάλεια
- URL
- χρήση
- φιλική προς το χρήστη
- ποικιλία
- τρόπους
- ιστός
- ξύσιμο ιστού
- Ιστοσελίδα : www.example.gr
- ιστοσελίδες
- Wikipedia
- θα
- με
- χωρίς
- Εργασία
- γράφω
- γραφή
- XML
- Σας
- zephyrnet