Κατά την ανάπτυξη ενός μεγάλου γλωσσικού μοντέλου (LLM), οι επαγγελματίες μηχανικής εκμάθησης (ML) συνήθως ενδιαφέρονται για δύο μετρήσεις για την απόδοση προβολής του μοντέλου: λανθάνουσα κατάσταση, που ορίζεται από το χρόνο που απαιτείται για τη δημιουργία ενός διακριτικού και απόδοση, που ορίζεται από τον αριθμό των κουπονιών που δημιουργούνται ανά δευτερόλεπτο. Αν και ένα μεμονωμένο αίτημα προς το αναπτυγμένο τελικό σημείο θα εμφάνιζε απόδοση περίπου ίση με το αντίστροφο της καθυστέρησης του μοντέλου, αυτό δεν ισχύει απαραίτητα όταν πολλαπλές ταυτόχρονες αιτήσεις αποστέλλονται ταυτόχρονα στο τελικό σημείο. Λόγω των τεχνικών εξυπηρέτησης μοντέλων, όπως η συνεχής ομαδοποίηση ταυτόχρονων αιτημάτων από την πλευρά του πελάτη, ο λανθάνοντας χρόνος και η απόδοση έχουν μια πολύπλοκη σχέση που ποικίλλει σημαντικά με βάση την αρχιτεκτονική του μοντέλου, τις διαμορφώσεις εξυπηρέτησης, το υλικό τύπου παρουσίας, τον αριθμό των ταυτόχρονων αιτημάτων και τις διακυμάνσεις στα ωφέλιμα φορτία εισόδου, όπως ως πλήθος διακριτικών εισόδου και διακριτικών εξόδου.
Αυτή η ανάρτηση διερευνά αυτές τις σχέσεις μέσω μιας ολοκληρωμένης συγκριτικής αξιολόγησης των LLM που είναι διαθέσιμα στο Amazon SageMaker JumpStart, συμπεριλαμβανομένων των παραλλαγών Llama 2, Falcon και Mistral. Με το SageMaker JumpStart, οι επαγγελματίες ML μπορούν να επιλέξουν από μια ευρεία επιλογή δημοσίως διαθέσιμων μοντέλων θεμελίωσης για να αναπτύξουν σε αποκλειστικές Amazon Sage Maker στιγμιότυπα σε περιβάλλον απομονωμένο σε δίκτυο. Παρέχουμε θεωρητικές αρχές σχετικά με τον τρόπο με τον οποίο οι προδιαγραφές του επιταχυντή επηρεάζουν τη συγκριτική αξιολόγηση LLM. Δείχνουμε επίσης τον αντίκτυπο της ανάπτυξης πολλαπλών παρουσιών πίσω από ένα μόνο τελικό σημείο. Τέλος, παρέχουμε πρακτικές συστάσεις για την προσαρμογή της διαδικασίας ανάπτυξης του SageMaker JumpStart ώστε να ευθυγραμμιστεί με τις απαιτήσεις σας σχετικά με την καθυστέρηση, την απόδοση, το κόστος και τους περιορισμούς στους διαθέσιμους τύπους παρουσιών. Όλα τα αποτελέσματα συγκριτικής αξιολόγησης καθώς και οι συστάσεις βασίζονται σε ένα ευέλικτο σημειωματάριο ώστε να μπορείτε να προσαρμόσετε στην περίπτωση χρήσης σας.
Εφαρμοσμένη συγκριτική αξιολόγηση τελικού σημείου
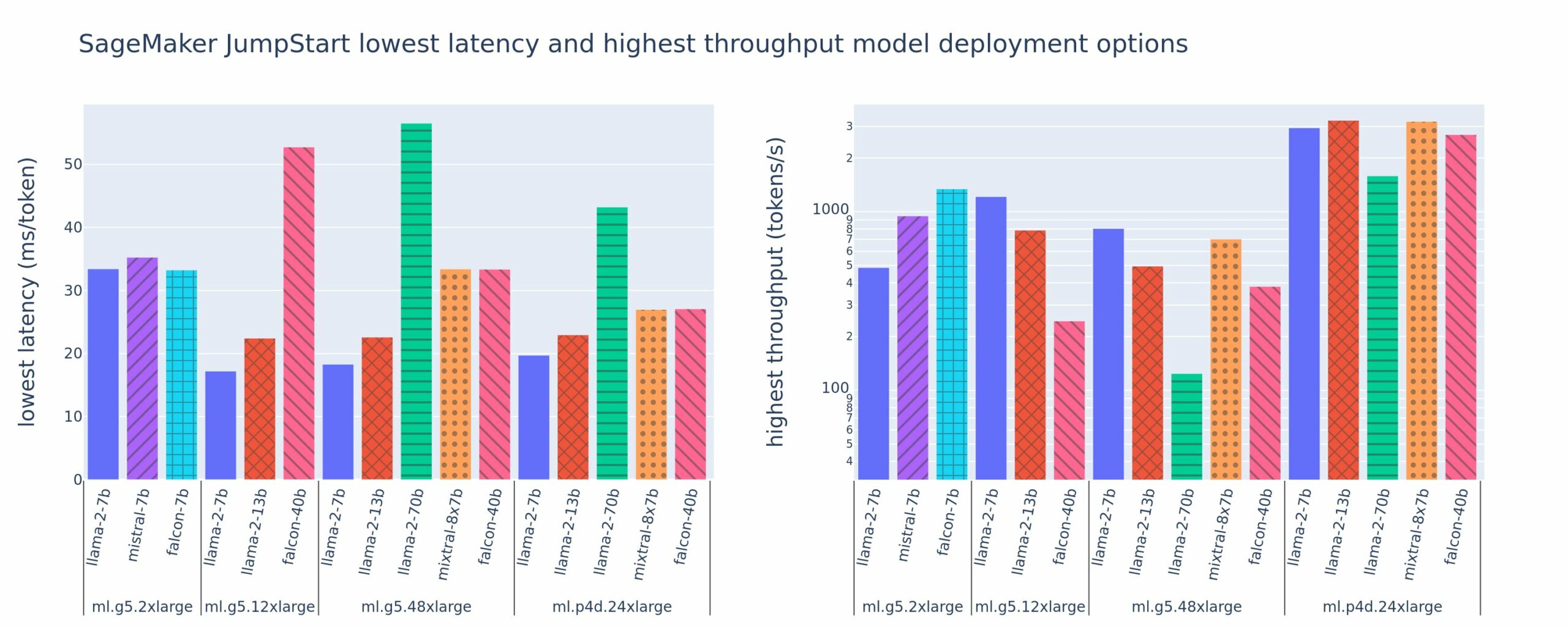
Το παρακάτω σχήμα δείχνει τις χαμηλότερες τιμές καθυστέρησης (αριστερά) και υψηλότερη απόδοση (δεξιά) για διαμορφώσεις ανάπτυξης σε διάφορους τύπους μοντέλων και τύπων παρουσιών. Είναι σημαντικό ότι καθεμία από αυτές τις αναπτύξεις μοντέλου χρησιμοποιεί προεπιλεγμένες διαμορφώσεις όπως παρέχονται από το SageMaker JumpStart, δεδομένου του επιθυμητού αναγνωριστικού μοντέλου και του τύπου παρουσίας για ανάπτυξη.
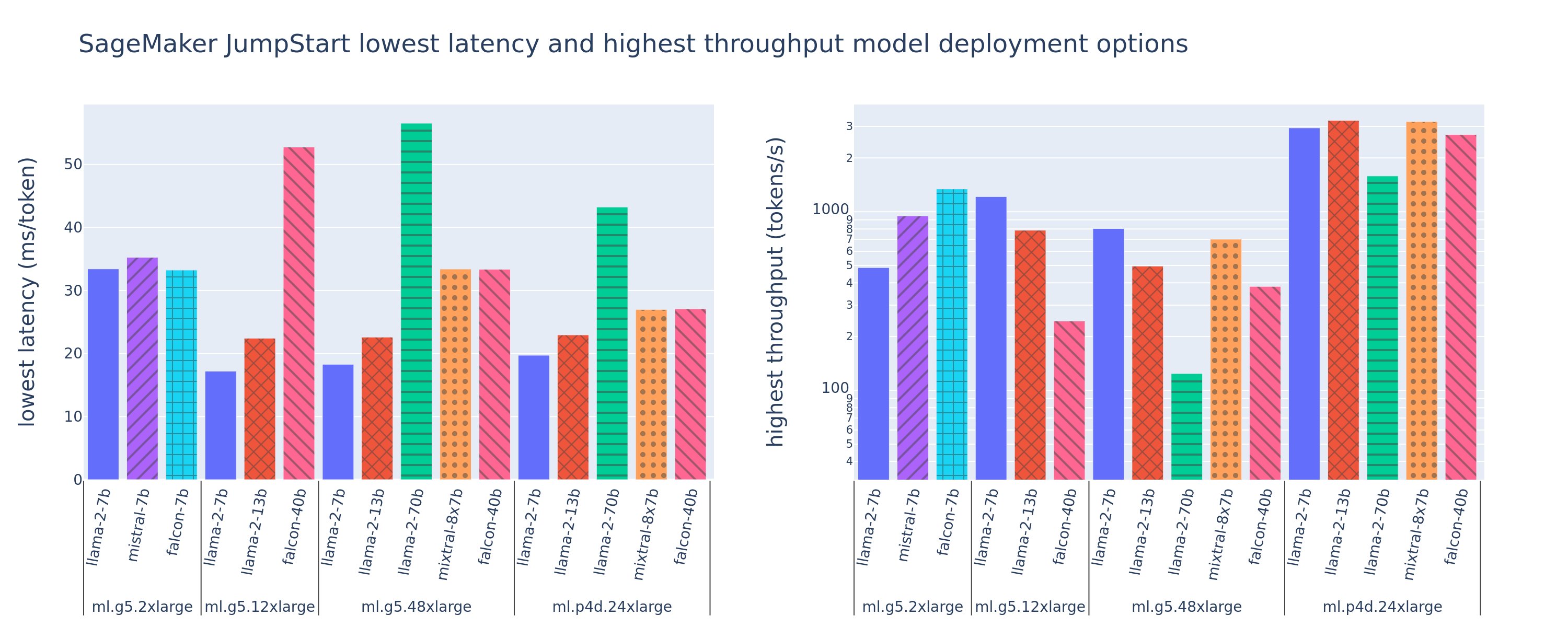
Αυτές οι τιμές καθυστέρησης και απόδοσης αντιστοιχούν σε ωφέλιμα φορτία με 256 διακριτικά εισόδου και 256 διακριτικά εξόδου. Η ρύθμιση παραμέτρων χαμηλότερης καθυστέρησης περιορίζει το μοντέλο που εξυπηρετεί ένα μόνο ταυτόχρονο αίτημα και η διαμόρφωση υψηλότερης απόδοσης μεγιστοποιεί τον πιθανό αριθμό ταυτόχρονων αιτημάτων. Όπως μπορούμε να δούμε στη συγκριτική αξιολόγηση, η αύξηση των ταυτόχρονων αιτημάτων αυξάνει μονότονα την απόδοση με φθίνουσα βελτίωση για μεγάλα ταυτόχρονα αιτήματα. Επιπλέον, τα μοντέλα διαχωρίζονται πλήρως στην υποστηριζόμενη παρουσία. Για παράδειγμα, επειδή η παρουσία ml.g5.48xlarge έχει 8 GPU, όλα τα μοντέλα SageMaker JumpStart που χρησιμοποιούν αυτήν την παρουσία μοιράζονται χρησιμοποιώντας παραλληλισμό τανυστών και στους οκτώ διαθέσιμους επιταχυντές.
Μπορούμε να σημειώσουμε μερικά στοιχεία από αυτό το σχήμα. Πρώτον, δεν υποστηρίζονται όλα τα μοντέλα σε όλες τις περιπτώσεις. Ορισμένα μικρότερα μοντέλα, όπως το Falcon 7B, δεν υποστηρίζουν την κοινή χρήση μοντέλων, ενώ τα μεγαλύτερα μοντέλα έχουν υψηλότερες απαιτήσεις υπολογιστικών πόρων. Δεύτερον, καθώς αυξάνεται η κοινή χρήση, η απόδοση συνήθως βελτιώνεται, αλλά μπορεί να μην βελτιώνεται απαραίτητα για μικρά μοντέλα. Αυτό συμβαίνει επειδή τα μικρά μοντέλα όπως τα 7B και 13B επιβαρύνουν σημαντικά την επικοινωνία όταν μοιράζονται σε πάρα πολλούς επιταχυντές. Θα το συζητήσουμε εκτενέστερα αργότερα. Τέλος, οι περιπτώσεις ml.p4d.24xlarge τείνουν να έχουν σημαντικά καλύτερη απόδοση λόγω βελτιώσεων στο εύρος ζώνης μνήμης του A100 έναντι των GPU A10G. Όπως θα συζητήσουμε αργότερα, η απόφαση να χρησιμοποιήσετε έναν συγκεκριμένο τύπο παρουσίας εξαρτάται από τις απαιτήσεις ανάπτυξης, συμπεριλαμβανομένων των περιορισμών καθυστέρησης, απόδοσης και κόστους.
Πώς μπορείτε να αποκτήσετε αυτές τις τιμές διαμόρφωσης της χαμηλότερης καθυστέρησης και της υψηλότερης απόδοσης; Ας ξεκινήσουμε σχεδιάζοντας την καθυστέρηση έναντι της απόδοσης για ένα τελικό σημείο Llama 2 7B σε μια περίπτωση ml.g5.12xlarge για ένα ωφέλιμο φορτίο με 256 διακριτικά εισόδου και 256 διακριτικά εξόδου, όπως φαίνεται στην ακόλουθη καμπύλη. Μια παρόμοια καμπύλη υπάρχει για κάθε αναπτυγμένο τελικό σημείο LLM.

Καθώς η ταυτόχρονη αύξηση αυξάνεται, η απόδοση και η καθυστέρηση αυξάνονται επίσης μονότονα. Επομένως, το χαμηλότερο σημείο καθυστέρησης εμφανίζεται σε μια τιμή ταυτόχρονης αίτησης 1 και μπορείτε να αυξήσετε οικονομικά την απόδοση του συστήματος αυξάνοντας τις ταυτόχρονες αιτήσεις. Υπάρχει ένα διακριτό «γόνατο» σε αυτή την καμπύλη, όπου είναι προφανές ότι τα κέρδη διεκπεραιώσεως που σχετίζονται με την πρόσθετη συγχρονικότητα δεν αντισταθμίζουν τη σχετική αύξηση της καθυστέρησης. Η ακριβής θέση αυτού του γονάτου εξαρτάται από τη χρήση. ορισμένοι επαγγελματίες μπορεί να ορίσουν το γόνατο στο σημείο όπου ξεπερνιέται μια προκαθορισμένη απαίτηση λανθάνοντος χρόνου (για παράδειγμα, 100 ms/token), ενώ άλλοι μπορεί να χρησιμοποιήσουν δείκτες αναφοράς δοκιμής φορτίου και μεθόδους θεωρίας ουρών όπως ο κανόνας μισού λανθάνοντος χρόνου και άλλοι μπορεί να χρησιμοποιήσουν θεωρητικές προδιαγραφές επιταχυντή.
Σημειώνουμε επίσης ότι ο μέγιστος αριθμός ταυτόχρονων αιτημάτων είναι περιορισμένος. Στο προηγούμενο σχήμα, το ίχνος γραμμής τελειώνει με 192 ταυτόχρονες αιτήσεις. Η πηγή αυτού του περιορισμού είναι το όριο χρονικού ορίου επίκλησης SageMaker, όπου το SageMaker ορίζει το χρονικό όριο λήξης μιας απόκρισης επίκλησης μετά από 60 δευτερόλεπτα. Αυτή η ρύθμιση είναι συγκεκριμένη για λογαριασμό και δεν μπορεί να διαμορφωθεί για ένα μεμονωμένο τελικό σημείο. Για τα LLM, η δημιουργία μεγάλου αριθμού διακριτικών εξόδου μπορεί να διαρκέσει δευτερόλεπτα ή και λεπτά. Επομένως, μεγάλα ωφέλιμα φορτία εισόδου ή εξόδου μπορεί να προκαλέσουν την αποτυχία των αιτημάτων επίκλησης. Επιπλέον, εάν ο αριθμός των ταυτόχρονων αιτημάτων είναι πολύ μεγάλος, τότε πολλά αιτήματα θα αντιμετωπίσουν μεγάλους χρόνους αναμονής, οδηγώντας αυτό το όριο χρονικού ορίου των 60 δευτερολέπτων. Για τους σκοπούς αυτής της μελέτης, χρησιμοποιούμε το όριο χρονικού ορίου για να ορίσουμε τη μέγιστη δυνατή απόδοση για μια ανάπτυξη μοντέλου. Είναι σημαντικό, αν και ένα τελικό σημείο του SageMaker μπορεί να χειριστεί μεγάλο αριθμό ταυτόχρονων αιτημάτων χωρίς να παρατηρήσει ένα χρονικό όριο απόκρισης επίκλησης, μπορεί να θέλετε να ορίσετε μέγιστες ταυτόχρονες αιτήσεις σε σχέση με το γόνατο στην καμπύλη λανθάνουσας απόδοσης. Αυτό είναι πιθανώς το σημείο στο οποίο αρχίζετε να εξετάζετε την οριζόντια κλιμάκωση, όπου ένα μεμονωμένο τελικό σημείο παρέχει πολλαπλές παρουσίες με αντίγραφα μοντέλων και εξισορροπεί τις εισερχόμενες αιτήσεις μεταξύ των αντιγράφων, για την υποστήριξη περισσότερων ταυτόχρονων αιτημάτων.
Πηγαίνοντας αυτό ένα βήμα παραπέρα, ο ακόλουθος πίνακας περιέχει αποτελέσματα συγκριτικής αξιολόγησης για διαφορετικές διαμορφώσεις για το μοντέλο Llama 2 7B, συμπεριλαμβανομένου διαφορετικού αριθμού διακριτικών εισόδου και εξόδου, τύπων παρουσιών και αριθμού ταυτόχρονων αιτημάτων. Σημειώστε ότι το προηγούμενο σχήμα απεικονίζει μόνο μία γραμμή αυτού του πίνακα.
| . | Διακίνηση (tokens/sec) | Καθυστέρηση (ms/token) | ||||||||||||||||||
| Ταυτόχρονα αιτήματα | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Αριθμός συνολικών κουπονιών: 512, Αριθμός κουπονιών εξόδου: 256 | ||||||||||||||||||||
| ml.g5.2xμεγάλο | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xμεγάλο | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xμεγάλο | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Αριθμός συνολικών κουπονιών: 4096, Αριθμός κουπονιών εξόδου: 256 | ||||||||||||||||||||
| ml.g5.2xμεγάλο | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xμεγάλο | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xμεγάλο | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
Παρατηρούμε ορισμένα πρόσθετα μοτίβα σε αυτά τα δεδομένα. Όταν αυξάνεται το μέγεθος του περιβάλλοντος, η καθυστέρηση αυξάνεται και η απόδοση μειώνεται. Για παράδειγμα, σε ml.g5.2xlarge με ταυτόχρονη 1, η απόδοση είναι 30 tokens/sec όταν ο αριθμός των συνολικών κουπονιών είναι 512, έναντι 20 tokens/sec εάν ο αριθμός των συνολικών κουπονιών είναι 4,096. Αυτό συμβαίνει επειδή χρειάζεται περισσότερος χρόνος για την επεξεργασία της μεγαλύτερης εισόδου. Μπορούμε επίσης να δούμε ότι η αύξηση της ικανότητας GPU και του διαμοιρασμού επηρεάζει τη μέγιστη απόδοση και τη μέγιστη υποστηριζόμενη ταυτόχρονη αιτήματα. Ο πίνακας δείχνει ότι το Llama 2 7B έχει σημαντικά διαφορετικές τιμές μέγιστης απόδοσης για διαφορετικούς τύπους παρουσιών και αυτές οι μέγιστες τιμές διεκπεραιότητας εμφανίζονται σε διαφορετικές τιμές ταυτόχρονων αιτημάτων. Αυτά τα χαρακτηριστικά θα οδηγούσαν έναν επαγγελματία ML να δικαιολογήσει το κόστος μιας παρουσίας έναντι μιας άλλης. Για παράδειγμα, δεδομένης της απαίτησης χαμηλής καθυστέρησης, ο επαγγελματίας μπορεί να επιλέξει μια παρουσία ml.g5.12xlarge (4 GPU A10G) έναντι μιας παρουσίας ml.g5.2xlarge (1 GPU A10G). Εάν δοθεί μια απαίτηση υψηλής απόδοσης, η χρήση μιας παρουσίας ml.p4d.24xlarge (8 GPU A100) με πλήρη διαμοιρασμό θα δικαιολογείται μόνο υπό υψηλή ταυτόχρονη χρήση. Σημειώστε, ωστόσο, ότι είναι συχνά ωφέλιμο να φορτώνετε πολλαπλά στοιχεία συμπερασμάτων ενός μοντέλου 7B σε μια μεμονωμένη περίπτωση ml.p4d.24xlarge. τέτοια υποστήριξη πολλαπλών μοντέλων συζητείται αργότερα σε αυτήν την ανάρτηση.
Οι προηγούμενες παρατηρήσεις έγιναν για το μοντέλο Llama 2 7B. Ωστόσο, παρόμοια μοτίβα εξακολουθούν να ισχύουν και για άλλα μοντέλα. Ένα βασικό στοιχείο είναι ότι οι αριθμοί απόδοσης καθυστέρησης και απόδοσης εξαρτώνται από το ωφέλιμο φορτίο, τον τύπο παρουσίας και τον αριθμό των ταυτόχρονων αιτημάτων, επομένως θα χρειαστεί να βρείτε την ιδανική διαμόρφωση για τη συγκεκριμένη εφαρμογή σας. Για να δημιουργήσετε τους προηγούμενους αριθμούς για την περίπτωση χρήσης σας, μπορείτε να εκτελέσετε το συνδεδεμένο σημειωματάριο, όπου μπορείτε να διαμορφώσετε αυτήν την ανάλυση δοκιμής φορτίου για το μοντέλο, τον τύπο παρουσίας και το ωφέλιμο φορτίο.
Κατανοώντας τις προδιαγραφές του επιταχυντή
Η επιλογή κατάλληλου υλικού για συμπέρασμα LLM βασίζεται σε μεγάλο βαθμό σε συγκεκριμένες περιπτώσεις χρήσης, στόχους εμπειρίας χρήστη και το επιλεγμένο LLM. Αυτή η ενότητα επιχειρεί να δημιουργήσει μια κατανόηση του γόνατος στην καμπύλη λανθάνουσας απόδοσης σε σχέση με αρχές υψηλού επιπέδου που βασίζονται στις προδιαγραφές του επιταχυντή. Αυτές οι αρχές από μόνες τους δεν αρκούν για τη λήψη μιας απόφασης: απαιτούνται πραγματικοί δείκτες αναφοράς. Ο όρος συσκευή χρησιμοποιείται εδώ για να συμπεριλάβει όλους τους επιταχυντές υλικού ML. Υποστηρίζουμε ότι το γόνατο στην καμπύλη λανθάνουσας απόδοσης καθοδηγείται από έναν από τους δύο παράγοντες:
- Ο επιταχυντής έχει εξαντλήσει τη μνήμη για την προσωρινή αποθήκευση πίνακες KV, επομένως τα επόμενα αιτήματα βρίσκονται στην ουρά
- Ο επιταχυντής εξακολουθεί να έχει εφεδρική μνήμη για την κρυφή μνήμη KV, αλλά χρησιμοποιεί ένα αρκετά μεγάλο μέγεθος παρτίδας που ο χρόνος επεξεργασίας καθορίζεται από τον υπολογιστικό λανθάνοντα χρόνο λειτουργίας και όχι από το εύρος ζώνης μνήμης
Συνήθως προτιμούμε να περιοριζόμαστε από τον δεύτερο παράγοντα γιατί αυτό σημαίνει ότι οι πόροι του επιταχυντή είναι κορεσμένοι. Βασικά, μεγιστοποιείτε τους πόρους που πληρώσατε. Ας εξερευνήσουμε αυτόν τον ισχυρισμό με περισσότερες λεπτομέρειες.
Προσωρινή αποθήκευση KV και μνήμη συσκευής
Οι τυπικοί μηχανισμοί προσοχής μετασχηματιστή υπολογίζουν την προσοχή για κάθε νέο διακριτικό σε σχέση με όλα τα προηγούμενα διακριτικά. Οι περισσότεροι σύγχρονοι διακομιστές ML αποθηκεύουν προσωρινά κλειδιά προσοχής και τιμές στη μνήμη της συσκευής (DRAM) για να αποφευχθεί ο επανυπολογισμός σε κάθε βήμα. Αυτό ονομάζεται αυτό το KV cache, και μεγαλώνει με το μέγεθος της παρτίδας και το μήκος της ακολουθίας. Καθορίζει πόσα αιτήματα χρηστών μπορούν να εξυπηρετηθούν παράλληλα και θα καθορίσει το γόνατο στην καμπύλη λανθάνουσας απόδοσης, εάν το καθεστώς δεσμευμένου υπολογισμού στο δεύτερο σενάριο που αναφέρθηκε προηγουμένως δεν πληρούται ακόμη, δεδομένης της διαθέσιμης DRAM. Ο ακόλουθος τύπος είναι μια κατά προσέγγιση προσέγγιση για το μέγιστο μέγεθος κρυφής μνήμης KV.

Σε αυτόν τον τύπο, το B είναι το μέγεθος παρτίδας και το N είναι ο αριθμός των επιταχυντών. Για παράδειγμα, το μοντέλο Llama 2 7B στο FP16 (2 byte/παράμετρος) που εξυπηρετείται σε μια GPU A10G (24 GB DRAM) καταναλώνει περίπου 14 GB, αφήνοντας 10 GB για την κρυφή μνήμη KV. Συνδέοντας το πλήρες μήκος περιβάλλοντος του μοντέλου (N = 4096) και τις υπόλοιπες παραμέτρους (n_layers=32, n_kv_attention_heads=32 και d_attention_head=128), αυτή η έκφραση δείχνει ότι περιοριζόμαστε στην παράλληλη εξυπηρέτηση ενός μεγέθους παρτίδας τεσσάρων χρηστών λόγω περιορισμών DRAM . Εάν παρατηρήσετε τα αντίστοιχα σημεία αναφοράς στον προηγούμενο πίνακα, αυτή είναι μια καλή προσέγγιση για το παρατηρούμενο γόνατο σε αυτήν την καμπύλη λανθάνουσας απόδοσης. Μέθοδοι όπως προσοχή ομαδοποιημένου ερωτήματος (GQA) μπορεί να μειώσει το μέγεθος της κρυφής μνήμης KV, στην περίπτωση του GQA με τον ίδιο παράγοντα μειώνει τον αριθμό των κεφαλών KV.
Αριθμητική ένταση και εύρος ζώνης μνήμης συσκευής
Η αύξηση της υπολογιστικής ισχύος των επιταχυντών ML έχει ξεπεράσει το εύρος ζώνης μνήμης τους, πράγμα που σημαίνει ότι μπορούν να εκτελούν πολλούς περισσότερους υπολογισμούς σε κάθε byte δεδομένων στον χρόνο που απαιτείται για την πρόσβαση σε αυτό το byte.
Η αριθμητική ένταση, ή ο λόγος των λειτουργιών υπολογισμού προς τις προσβάσεις στη μνήμη, για μια λειτουργία καθορίζει εάν περιορίζεται από το εύρος ζώνης μνήμης ή την υπολογιστική χωρητικότητα στο επιλεγμένο υλικό. Για παράδειγμα, μια GPU A10G (οικογένεια τύπου instance g5) με 70 TFLOPS FP16 και 600 GB/sec εύρος ζώνης μπορεί να υπολογίσει περίπου 116 ops/byte. Μια GPU A100 (οικογένεια τύπου p4d instance) μπορεί να υπολογίσει περίπου 208 ops/byte. Εάν η αριθμητική ένταση για ένα μοντέλο μετασχηματιστή είναι κάτω από αυτήν την τιμή, είναι δεσμευμένη στη μνήμη. αν είναι παραπάνω, είναι υπολογιστικό. Ο μηχανισμός προσοχής για το Llama 2 7B απαιτεί 62 ops/byte για το μέγεθος παρτίδας 1 (για εξήγηση, βλ. Ένας οδηγός για τα συμπεράσματα και τις επιδόσεις LLM), που σημαίνει ότι είναι δεσμευμένο στη μνήμη. Όταν ο μηχανισμός προσοχής είναι δεσμευμένος στη μνήμη, τα ακριβά FLOPS μένουν αχρησιμοποίητα.
Υπάρχουν δύο τρόποι για να χρησιμοποιήσετε καλύτερα το γκάζι και να αυξήσετε την αριθμητική ένταση: να μειώσετε τις απαιτούμενες προσβάσεις στη μνήμη για τη λειτουργία (αυτό είναι Flash Προσοχή εστιάζει σε) ή να αυξήσει το μέγεθος της παρτίδας. Ωστόσο, ενδέχεται να μην είμαστε σε θέση να αυξήσουμε το μέγεθος της παρτίδας μας αρκετά ώστε να φτάσουμε σε ένα καθεστώς δεσμευμένου υπολογισμού, εάν η μνήμη DRAM μας είναι πολύ μικρή για να κρατήσει την αντίστοιχη κρυφή μνήμη KV. Μια ακατέργαστη προσέγγιση του κρίσιμου μεγέθους παρτίδας B* που διαχωρίζει καθεστώτα υπολογιστικού δεσμού από δεσμευμένα στη μνήμη για τυπικό συμπέρασμα αποκωδικοποιητή GPT περιγράφεται από την ακόλουθη έκφραση, όπου A_mb είναι το εύρος ζώνης μνήμης επιταχυντή, A_f είναι FLOPS επιταχυντή και N είναι ο αριθμός των επιταχυντών. Αυτό το κρίσιμο μέγεθος παρτίδας μπορεί να εξαχθεί βρίσκοντας πού ο χρόνος πρόσβασης στη μνήμη ισούται με τον χρόνο υπολογισμού. Αναφέρομαι σε αυτό το post στο blog να κατανοήσουν λεπτομερέστερα την εξίσωση 2 και τις υποθέσεις της.

Αυτή είναι η ίδια αναλογία ops/byte που υπολογίσαμε προηγουμένως για το A10G, επομένως το κρίσιμο μέγεθος παρτίδας σε αυτήν την GPU είναι 116. Ένας τρόπος για να προσεγγίσετε αυτό το θεωρητικό, κρίσιμο μέγεθος παρτίδας είναι να αυξήσετε το κοινόχρηστο μοντέλο και να χωρίσετε την κρυφή μνήμη σε περισσότερους N επιταχυντές. Αυτό αυξάνει αποτελεσματικά τη χωρητικότητα της κρυφής μνήμης KV καθώς και το μέγεθος παρτίδας δεσμευμένης στη μνήμη.
Ένα άλλο πλεονέκτημα του διαμοιρασμού μοντέλων είναι ο διαχωρισμός των παραμέτρων μοντέλου και η εργασία φόρτωσης δεδομένων σε N επιταχυντές. Αυτός ο τύπος διαμοιρασμού είναι ένας τύπος παραλληλισμού μοντέλου που αναφέρεται επίσης ως παραλληλισμός τανυστών. Αφελώς, υπάρχει N φορές το εύρος ζώνης της μνήμης και η υπολογιστική ισχύς συνολικά. Υποθέτοντας ότι δεν υπάρχει καμία επιβάρυνση οποιουδήποτε είδους (επικοινωνία, λογισμικό κ.λπ.), αυτό θα μείωνε τον λανθάνοντα χρόνο αποκωδικοποίησης ανά διακριτικό κατά N εάν είμαστε δεσμευμένοι στη μνήμη, επειδή η καθυστέρηση αποκωδικοποίησης διακριτικού σε αυτό το καθεστώς δεσμεύεται από το χρόνο που χρειάζεται για τη φόρτωση του μοντέλου βάρη και κρυφή μνήμη. Στην πραγματική ζωή, ωστόσο, η αύξηση του βαθμού κοινής χρήσης έχει ως αποτέλεσμα την αυξημένη επικοινωνία μεταξύ των συσκευών για κοινή χρήση ενδιάμεσων ενεργοποιήσεων σε κάθε επίπεδο μοντέλου. Αυτή η ταχύτητα επικοινωνίας περιορίζεται από το εύρος ζώνης διασύνδεσης της συσκευής. Είναι δύσκολο να εκτιμηθεί επακριβώς ο αντίκτυπός του (για λεπτομέρειες, βλ Μοντέλο παραλληλισμού), αλλά αυτό μπορεί τελικά να σταματήσει να αποφέρει οφέλη ή να υποβαθμίσει την απόδοση — αυτό ισχύει ιδιαίτερα για μικρότερα μοντέλα, επειδή οι μικρότερες μεταφορές δεδομένων οδηγούν σε χαμηλότερους ρυθμούς μεταφοράς.
Για να συγκρίνετε τους επιταχυντές ML με βάση τις προδιαγραφές τους, προτείνουμε τα ακόλουθα. Αρχικά, υπολογίστε το κατά προσέγγιση κρίσιμο μέγεθος παρτίδας για κάθε τύπο επιταχυντή σύμφωνα με τη δεύτερη εξίσωση και το μέγεθος κρυφής μνήμης KV για το κρίσιμο μέγεθος παρτίδας σύμφωνα με την πρώτη εξίσωση. Στη συνέχεια, μπορείτε να χρησιμοποιήσετε τη διαθέσιμη μνήμη DRAM στον επιταχυντή για να υπολογίσετε τον ελάχιστο αριθμό επιταχυντών που απαιτούνται για την προσαρμογή της κρυφής μνήμης KV και των παραμέτρων μοντέλου. Εάν αποφασίζετε μεταξύ πολλών επιταχυντών, δώστε προτεραιότητα στους επιταχυντές με σειρά χαμηλότερου κόστους ανά GB/sec εύρους ζώνης μνήμης. Τέλος, συγκρίνετε αυτές τις διαμορφώσεις και επαληθεύστε ποιο είναι το καλύτερο κόστος/κουπόνι για το ανώτερο όριο της επιθυμητής καθυστέρησης.
Επιλέξτε μια διαμόρφωση ανάπτυξης τελικού σημείου
Πολλά LLM που διανέμονται από το SageMaker JumpStart χρησιμοποιούν το κείμενο-γενιά-συμπερασματικά (TGI) Δοχείο SageMaker για την εξυπηρέτηση μοντέλων. Ο παρακάτω πίνακας περιγράφει τον τρόπο προσαρμογής μιας ποικιλίας παραμέτρων εξυπηρέτησης μοντέλων είτε για να επηρεάσει την εξυπηρέτηση του μοντέλου που επηρεάζει την καμπύλη λανθάνουσας απόδοσης είτε να προστατεύσει το τελικό σημείο από αιτήματα που θα υπερφόρτωναν το τελικό σημείο. Αυτές είναι οι κύριες παράμετροι που μπορείτε να χρησιμοποιήσετε για να διαμορφώσετε την ανάπτυξη τελικού σημείου για την περίπτωση χρήσης σας. Εκτός εάν ορίζεται διαφορετικά, χρησιμοποιούμε προεπιλογή παραμέτρους ωφέλιμου φορτίου δημιουργίας κειμένου και Μεταβλητές περιβάλλοντος TGI.
| Μεταβλητή περιβάλλοντος | Περιγραφή | Προεπιλεγμένη τιμή SageMaker JumpStart |
| Διαμορφώσεις υπηρεσίας μοντέλου | . | . |
MAX_BATCH_PREFILL_TOKENS |
Περιορίζει τον αριθμό των διακριτικών στη λειτουργία προπλήρωσης. Αυτή η λειτουργία δημιουργεί την κρυφή μνήμη KV για μια νέα ακολουθία εντολών εισόδου. Είναι έντασης μνήμης και δεσμεύεται σε υπολογισμούς, επομένως αυτή η τιμή περιορίζει τον αριθμό των διακριτικών που επιτρέπονται σε μια μεμονωμένη λειτουργία προπλήρωσης. Τα βήματα αποκωδικοποίησης για άλλα ερωτήματα παύουν κατά τη διάρκεια της προπλήρωσης. | 4096 (προεπιλογή TGI) ή μέγιστο υποστηριζόμενο μήκος περιβάλλοντος για συγκεκριμένο μοντέλο (παρέχεται το SageMaker JumpStart), όποιο είναι μεγαλύτερο. |
MAX_BATCH_TOTAL_TOKENS |
Ελέγχει τον μέγιστο αριθμό κουπονιών που θα συμπεριληφθούν σε μια παρτίδα κατά την αποκωδικοποίηση ή ένα μεμονωμένο πέρασμα προς τα εμπρός μέσω του μοντέλου. Στην ιδανική περίπτωση, αυτό έχει ρυθμιστεί για να μεγιστοποιήσει τη χρήση όλου του διαθέσιμου υλικού. | Δεν καθορίζεται (προεπιλογή TGI). Το TGI θα ορίσει αυτήν την τιμή σε σχέση με την απομένουσα μνήμη CUDA κατά την προθέρμανση του μοντέλου. |
SM_NUM_GPUS |
Ο αριθμός των θραυσμάτων που θα χρησιμοποιηθούν. Δηλαδή, ο αριθμός των GPU που χρησιμοποιούνται για την εκτέλεση του μοντέλου χρησιμοποιώντας παραλληλισμό τανυστών. | Εξαρτάται από το παράδειγμα (παρέχεται το SageMaker JumpStart). Για κάθε υποστηριζόμενη παρουσία για ένα δεδομένο μοντέλο, το SageMaker JumpStart παρέχει την καλύτερη ρύθμιση για παραλληλισμό τανυστών. |
| Διαμορφώσεις για την προστασία του τελικού σας σημείου (ρυθμίστε τις για την περίπτωση χρήσης σας) | . | . |
MAX_TOTAL_TOKENS |
Αυτό περιορίζει τον προϋπολογισμό μνήμης ενός αιτήματος πελάτη περιορίζοντας τον αριθμό των διακριτικών στην ακολουθία εισόδου συν τον αριθμό των διακριτικών στην ακολουθία εξόδου (το max_new_tokens παράμετρος ωφέλιμου φορτίου). |
Μέγιστο υποστηριζόμενο μήκος περιβάλλοντος για συγκεκριμένο μοντέλο. Για παράδειγμα, 4096 για το Llama 2. |
MAX_INPUT_LENGTH |
Προσδιορίζει τον μέγιστο επιτρεπόμενο αριθμό διακριτικών στην ακολουθία εισόδου για ένα μόνο αίτημα πελάτη. Τα πράγματα που πρέπει να λάβετε υπόψη κατά την αύξηση αυτής της τιμής περιλαμβάνουν: οι μεγαλύτερες ακολουθίες εισόδου απαιτούν περισσότερη μνήμη, γεγονός που επηρεάζει τη συνεχή ομαδοποίηση και πολλά μοντέλα έχουν υποστηριζόμενο μήκος περιβάλλοντος που δεν πρέπει να ξεπεραστεί. | Μέγιστο υποστηριζόμενο μήκος περιβάλλοντος για συγκεκριμένο μοντέλο. Για παράδειγμα, 4095 για το Llama 2. |
MAX_CONCURRENT_REQUESTS |
Ο μέγιστος αριθμός ταυτόχρονων αιτημάτων που επιτρέπεται από το αναπτυγμένο τελικό σημείο. Τα νέα αιτήματα πέρα από αυτό το όριο θα προκαλέσουν αμέσως ένα σφάλμα υπερφόρτωσης του μοντέλου για να αποφευχθεί η κακή καθυστέρηση για τα τρέχοντα αιτήματα επεξεργασίας. | 128 (προεπιλογή TGI). Αυτή η ρύθμιση σάς επιτρέπει να λαμβάνετε υψηλή απόδοση για μια ποικιλία περιπτώσεων χρήσης, αλλά θα πρέπει να καρφιτσώσετε όπως αρμόζει για να μειώσετε τα σφάλματα χρονικού ορίου επίκλησης του SageMaker. |
Ο διακομιστής TGI χρησιμοποιεί συνεχή ομαδοποίηση, η οποία συγκεντρώνει δυναμικά ταυτόχρονες αιτήσεις μαζί για να μοιράζεται ένα ενιαίο εμπρός πάσο συμπερασμάτων μοντέλου. Υπάρχουν δύο τύποι διαβιβάσεων: προπλήρωση και αποκωδικοποίηση. Κάθε νέο αίτημα πρέπει να εκτελεί ένα μόνο προωθητικό πέρασμα προπλήρωσης για να συμπληρωθεί η κρυφή μνήμη KV για τα διακριτικά ακολουθίας εισόδου. Αφού συμπληρωθεί η κρυφή μνήμη KV, ένα προς τα εμπρός πέρασμα αποκωδικοποίησης εκτελεί μια πρόβλεψη μεμονωμένου επόμενου διακριτικού για όλες τις ομαδοποιημένες αιτήσεις, η οποία επαναλαμβάνεται επαναλαμβανόμενα για να παραχθεί η ακολουθία εξόδου. Καθώς αποστέλλονται νέα αιτήματα στον διακομιστή, το επόμενο βήμα αποκωδικοποίησης πρέπει να περιμένει, ώστε το βήμα προπλήρωσης να μπορεί να εκτελεστεί για τα νέα αιτήματα. Αυτό πρέπει να συμβεί πριν αυτά τα νέα αιτήματα συμπεριληφθούν στα επόμενα βήματα αποκωδικοποίησης συνεχούς ομαδοποίησης. Λόγω περιορισμών υλικού, η συνεχής παρτίδα που χρησιμοποιείται για την αποκωδικοποίηση ενδέχεται να μην περιλαμβάνει όλα τα αιτήματα. Σε αυτό το σημείο, τα αιτήματα εισέρχονται σε μια ουρά επεξεργασίας και η καθυστέρηση συμπερασμάτων αρχίζει να αυξάνεται σημαντικά με μικρό μόνο κέρδος απόδοσης.
Είναι δυνατός ο διαχωρισμός των αναλύσεων συγκριτικής αξιολόγησης λανθάνοντος χρόνου LLM σε καθυστέρηση προπλήρωσης, λανθάνουσα κατάσταση αποκωδικοποίησης και καθυστέρηση αναμονής. Ο χρόνος που καταναλώνεται από καθένα από αυτά τα στοιχεία είναι θεμελιωδώς διαφορετικός στη φύση: η προπλήρωση είναι ένας υπολογισμός μίας χρήσης, η αποκωδικοποίηση πραγματοποιείται μία φορά για κάθε διακριτικό στην ακολουθία εξόδου και η ουρά περιλαμβάνει διαδικασίες ομαδοποίησης διακομιστή. Όταν διεκπεραιώνονται πολλαπλά ταυτόχρονα αιτήματα, καθίσταται δύσκολο να διαχωριστούν οι καθυστερήσεις από κάθε ένα από αυτά τα στοιχεία, επειδή ο λανθάνοντας χρόνος που παρουσιάζεται από κάθε δεδομένο αίτημα πελάτη περιλαμβάνει καθυστερήσεις στην ουρά που οφείλονται στην ανάγκη εκ των προτέρων συμπλήρωσης νέων ταυτόχρονων αιτημάτων, καθώς και καθυστερήσεις ουράς που προκαλούνται από τη συμπερίληψη του αιτήματος σε διαδικασίες αποκωδικοποίησης παρτίδας. Για αυτόν τον λόγο, αυτή η ανάρτηση εστιάζει στον λανθάνοντα χρόνο επεξεργασίας από άκρο σε άκρο. Το γόνατο στην καμπύλη λανθάνουσας απόδοσης εμφανίζεται στο σημείο κορεσμού όπου οι καθυστερήσεις της ουράς αρχίζουν να αυξάνονται σημαντικά. Αυτό το φαινόμενο εμφανίζεται για οποιονδήποτε διακομιστή συμπερασμάτων μοντέλου και καθορίζεται από τις προδιαγραφές του επιταχυντή.
Οι κοινές απαιτήσεις κατά την ανάπτυξη περιλαμβάνουν την ικανοποίηση μιας ελάχιστης απαιτούμενης απόδοσης, της μέγιστης επιτρεπόμενης καθυστέρησης, του μέγιστου κόστους ανά ώρα και του μέγιστου κόστους για τη δημιουργία 1 εκατομμυρίου κουπονιών. Θα πρέπει να ρυθμίσετε αυτές τις απαιτήσεις σε ωφέλιμα φορτία που αντιπροσωπεύουν αιτήματα τελικού χρήστη. Ένας σχεδιασμός για να πληροί αυτές τις απαιτήσεις θα πρέπει να λαμβάνει υπόψη πολλούς παράγοντες, συμπεριλαμβανομένης της συγκεκριμένης αρχιτεκτονικής του μοντέλου, του μεγέθους του μοντέλου, των τύπων παρουσιών και του αριθμού παρουσιών (οριζόντια κλιμάκωση). Στις επόμενες ενότητες, εστιάζουμε στην ανάπτυξη τελικών σημείων για την ελαχιστοποίηση της καθυστέρησης, τη μεγιστοποίηση της απόδοσης και την ελαχιστοποίηση του κόστους. Αυτή η ανάλυση λαμβάνει υπόψη 512 συνολικά διακριτικά και 256 μάρκες εξόδου.
Ελαχιστοποιήστε την καθυστέρηση
Η καθυστέρηση είναι μια σημαντική απαίτηση σε πολλές περιπτώσεις χρήσης σε πραγματικό χρόνο. Στον παρακάτω πίνακα, εξετάζουμε την ελάχιστη καθυστέρηση για κάθε μοντέλο και κάθε τύπο παρουσίας. Μπορείτε να επιτύχετε ελάχιστο λανθάνοντα χρόνο με τη ρύθμιση MAX_CONCURRENT_REQUESTS = 1.
| Ελάχιστη καθυστέρηση (ms/token) | |||||
| Αναγνωριστικό μοντέλου | ml.g5.2xμεγάλο | ml.g5.12xμεγάλο | ml.g5.48xμεγάλο | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Λάμα 2 7Β | 33 | 17 | 18 | 20 | - |
| Συνομιλία Llama 2 7B | 33 | 17 | 18 | 20 | - |
| Λάμα 2 13Β | - | 22 | 23 | 23 | - |
| Συνομιλία Llama 2 13B | - | 23 | 23 | 23 | - |
| Λάμα 2 70Β | - | - | 57 | 43 | - |
| Συνομιλία Llama 2 70B | - | - | 57 | 45 | - |
| Mistral 7B | 35 | - | - | - | - |
| Mistral 7B Instruct | 35 | - | - | - | - |
| Mixtral 8x7B | - | - | 33 | 27 | - |
| Falcon 7B | 33 | - | - | - | - |
| Falcon 7B Instruct | 33 | - | - | - | - |
| Falcon 40B | - | 53 | 33 | 27 | - |
| Falcon 40B Instruct | - | 53 | 33 | 28 | - |
| Falcon 180B | - | - | - | - | 42 |
| Συνομιλία Falcon 180B | - | - | - | - | 42 |
Για να επιτύχετε ελάχιστο λανθάνοντα χρόνο για ένα μοντέλο, μπορείτε να χρησιμοποιήσετε τον ακόλουθο κώδικα αντικαθιστώντας το αναγνωριστικό μοντέλου και τον τύπο παρουσίας που επιθυμείτε:
Σημειώστε ότι οι αριθμοί καθυστέρησης αλλάζουν ανάλογα με τον αριθμό των διακριτικών εισόδου και εξόδου. Ωστόσο, η διαδικασία ανάπτυξης παραμένει η ίδια εκτός από τις μεταβλητές περιβάλλοντος MAX_INPUT_TOKENS και MAX_TOTAL_TOKENS. Εδώ, αυτές οι μεταβλητές περιβάλλοντος έχουν ρυθμιστεί για να συμβάλλουν στην εγγύηση των απαιτήσεων λανθάνοντος χρόνου τελικού σημείου, επειδή μεγαλύτερες ακολουθίες εισόδου ενδέχεται να παραβιάζουν την απαίτηση καθυστέρησης. Σημειώστε ότι το SageMaker JumpStart παρέχει ήδη τις άλλες βέλτιστες μεταβλητές περιβάλλοντος κατά την επιλογή του τύπου παρουσίας. Για παράδειγμα, με τη χρήση ml.g5.12xlarge θα ρυθμιστεί SM_NUM_GPUS έως 4 στο περιβάλλον μοντέλου.
Μεγιστοποιήστε την απόδοση
Σε αυτήν την ενότητα, μεγιστοποιούμε τον αριθμό των κουπονιών που δημιουργούνται ανά δευτερόλεπτο. Αυτό επιτυγχάνεται συνήθως στις μέγιστες έγκυρες ταυτόχρονες αιτήσεις για το μοντέλο και τον τύπο παρουσίας. Στον παρακάτω πίνακα, αναφέρουμε τη διεκπεραίωση που επιτεύχθηκε στη μεγαλύτερη τιμή ταυτόχρονης αίτησης που επιτεύχθηκε πριν συναντήσετε ένα χρονικό όριο επίκλησης SageMaker για οποιοδήποτε αίτημα.
| Μέγιστη απόδοση (tokens/sec), Ταυτόχρονα αιτήματα | |||||
| Αναγνωριστικό μοντέλου | ml.g5.2xμεγάλο | ml.g5.12xμεγάλο | ml.g5.48xμεγάλο | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Λάμα 2 7Β | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Συνομιλία Llama 2 7B | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Λάμα 2 13Β | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Συνομιλία Llama 2 13B | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Λάμα 2 70Β | - | - | 124 (16) | 1585 (256) | - |
| Συνομιλία Llama 2 70B | - | - | 114 (16) | 1546 (256) | - |
| Mistral 7B | 947 (64) | - | - | - | - |
| Mistral 7B Instruct | 986 (128) | - | - | - | - |
| Mixtral 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Falcon 7B | 1340 (128) | - | - | - | - |
| Falcon 7B Instruct | 1313 (128) | - | - | - | - |
| Falcon 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Falcon 40B Instruct | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Falcon 180B | - | - | - | - | 1100 (128) |
| Συνομιλία Falcon 180B | - | - | - | - | 1081 (128) |
Για να επιτύχετε τη μέγιστη απόδοση για ένα μοντέλο, μπορείτε να χρησιμοποιήσετε τον ακόλουθο κώδικα:
Λάβετε υπόψη ότι ο μέγιστος αριθμός ταυτόχρονων αιτημάτων εξαρτάται από τον τύπο του μοντέλου, τον τύπο του στιγμιότυπου, τον μέγιστο αριθμό των διακριτικών εισόδου και τον μέγιστο αριθμό των διακριτικών εξόδου. Επομένως, θα πρέπει να ορίσετε αυτές τις παραμέτρους πριν από τη ρύθμιση MAX_CONCURRENT_REQUESTS.
Σημειώστε επίσης ότι ένας χρήστης που ενδιαφέρεται να ελαχιστοποιήσει τον λανθάνοντα χρόνο βρίσκεται συχνά σε αντίθεση με έναν χρήστη που ενδιαφέρεται να μεγιστοποιήσει την απόδοση. Ο πρώτος ενδιαφέρεται για απαντήσεις σε πραγματικό χρόνο, ενώ ο δεύτερος ενδιαφέρεται για την επεξεργασία κατά παρτίδες έτσι ώστε η ουρά τελικού σημείου να είναι πάντα κορεσμένη, ελαχιστοποιώντας έτσι τον χρόνο διακοπής της επεξεργασίας. Οι χρήστες που θέλουν να μεγιστοποιήσουν την απόδοση με βάση τις απαιτήσεις καθυστέρησης συχνά ενδιαφέρονται να λειτουργήσουν στο γόνατο στην καμπύλη λανθάνουσας απόδοσης.
Ελαχιστοποιήστε το κόστος
Η πρώτη επιλογή για την ελαχιστοποίηση του κόστους περιλαμβάνει την ελαχιστοποίηση του κόστους ανά ώρα. Με αυτό, μπορείτε να αναπτύξετε ένα επιλεγμένο μοντέλο στην παρουσία του SageMaker με το χαμηλότερο κόστος ανά ώρα. Για την τιμολόγηση σε πραγματικό χρόνο των περιπτώσεων SageMaker, ανατρέξτε στο Τιμολόγηση Amazon SageMaker. Γενικά, ο προεπιλεγμένος τύπος παρουσίας για τα SageMaker JumpStart LLM είναι η επιλογή ανάπτυξης με το χαμηλότερο κόστος.
Η δεύτερη επιλογή για την ελαχιστοποίηση του κόστους περιλαμβάνει την ελαχιστοποίηση του κόστους δημιουργίας 1 εκατομμυρίου κουπονιών. Αυτός είναι ένας απλός μετασχηματισμός του πίνακα που συζητήσαμε νωρίτερα για τη μεγιστοποίηση της απόδοσης, όπου μπορείτε πρώτα να υπολογίσετε τον χρόνο που χρειάζεται σε ώρες για να δημιουργηθούν 1 εκατομμύριο μάρκες (1e6 / απόδοση / 3600). Στη συνέχεια, μπορείτε να πολλαπλασιάσετε αυτή τη φορά για να δημιουργήσετε 1 εκατομμύριο διακριτικά με την τιμή ανά ώρα της καθορισμένης παρουσίας του SageMaker.
Λάβετε υπόψη ότι οι περιπτώσεις με το χαμηλότερο κόστος ανά ώρα δεν είναι ίδιες με τις περιπτώσεις με το χαμηλότερο κόστος για τη δημιουργία 1 εκατομμυρίου διακριτικών. Για παράδειγμα, εάν τα αιτήματα επίκλησης είναι σποραδικά, μια περίπτωση με το χαμηλότερο κόστος ανά ώρα μπορεί να είναι η βέλτιστη, ενώ στα σενάρια στραγγαλισμού, το χαμηλότερο κόστος για τη δημιουργία ενός εκατομμυρίου διακριτικών μπορεί να είναι πιο κατάλληλο.
Αντιστάθμιση παράλληλου τανυστή έναντι πολλαπλών μοντέλων
Σε όλες τις προηγούμενες αναλύσεις, σκεφτήκαμε να αναπτύξουμε ένα μεμονωμένο αντίγραφο μοντέλου με παράλληλο βαθμό τανυστή ίσο με τον αριθμό των GPU στον τύπο της παρουσίας ανάπτυξης. Αυτή είναι η προεπιλεγμένη συμπεριφορά του SageMaker JumpStart. Ωστόσο, όπως σημειώθηκε προηγουμένως, η κοινή χρήση ενός μοντέλου μπορεί να βελτιώσει την καθυστέρηση και την απόδοση του μοντέλου μόνο μέχρι ένα ορισμένο όριο, πέρα από το οποίο οι απαιτήσεις επικοινωνίας μεταξύ συσκευών κυριαρχούν στον χρόνο υπολογισμού. Αυτό σημαίνει ότι είναι συχνά ωφέλιμο να αναπτύσσονται πολλά μοντέλα με χαμηλότερο παράλληλο βαθμό τανυστή σε μία μόνο παρουσία αντί για ένα μεμονωμένο μοντέλο με υψηλότερο βαθμό παράλληλου τανυστή.
Εδώ, αναπτύσσουμε τα τελικά σημεία Llama 2 7B και 13B σε στιγμιότυπα ml.p4d.24xμεγάλες με μοίρες παράλληλων τανυστών (TP) 1, 2, 4 και 8. Για λόγους σαφήνειας στη συμπεριφορά του μοντέλου, καθένα από αυτά τα τελικά σημεία φορτώνει μόνο ένα μοντέλο.
| . | Διακίνηση (tokens/sec) | Καθυστέρηση (ms/token) | ||||||||||||||||||
| Ταυτόχρονα αιτήματα | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Πτυχίο TP | Λάμα 2 13Β | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Λάμα 2 7Β | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Οι προηγούμενες αναλύσεις μας έδειξαν ήδη σημαντικά πλεονεκτήματα απόδοσης σε στιγμιότυπα ml.p4d.24xlarge, κάτι που συχνά μεταφράζεται σε καλύτερη απόδοση όσον αφορά το κόστος για τη δημιουργία 1 εκατομμυρίου διακριτικών στην οικογένεια παρουσιών g5 υπό συνθήκες υψηλών συνθηκών φόρτωσης ταυτόχρονων αιτημάτων. Αυτή η ανάλυση δείχνει ξεκάθαρα ότι θα πρέπει να λάβετε υπόψη την αντιστάθμιση μεταξύ του διαμοιρασμού μοντέλων και της αναπαραγωγής του μοντέλου σε μία μόνο περίπτωση. Δηλαδή, ένα πλήρως κατακερματισμένο μοντέλο δεν είναι συνήθως η καλύτερη χρήση των πόρων ml.p4d.24xlarge υπολογιστών για οικογένειες μοντέλων 7Β και 13Β. Στην πραγματικότητα, για την οικογένεια μοντέλων 7Β, αποκτάτε την καλύτερη απόδοση για ένα μόνο αντίγραφο μοντέλου με παράλληλο βαθμό τανυστή 4 αντί για 8.
Από εδώ, μπορείτε να υπολογίσετε ότι η διαμόρφωση υψηλότερης απόδοσης για το μοντέλο 7B περιλαμβάνει παράλληλο βαθμό τανυστή 1 με οκτώ αντίγραφα μοντέλων και η διαμόρφωση υψηλότερης απόδοσης για το μοντέλο 13Β είναι πιθανώς ένας παράλληλος βαθμός τανυστή 2 με τέσσερα αντίγραφα μοντέλων. Για να μάθετε περισσότερα σχετικά με το πώς να το επιτύχετε αυτό, ανατρέξτε στο Μειώστε το κόστος ανάπτυξης μοντέλων κατά 50% κατά μέσο όρο χρησιμοποιώντας τις πιο πρόσφατες δυνατότητες του Amazon SageMaker, το οποίο καταδεικνύει τη χρήση τελικών σημείων που βασίζονται σε στοιχεία συμπερασμάτων. Λόγω των τεχνικών εξισορρόπησης φορτίου, της δρομολόγησης διακομιστή και της κοινής χρήσης πόρων CPU, ενδέχεται να μην επιτύχετε πλήρως βελτιώσεις απόδοσης ακριβώς ίσες με τον αριθμό των αντιγράφων επί τη διεκπεραίωση για ένα μόνο αντίγραφο.
Οριζόντια κλιμάκωση
Όπως παρατηρήθηκε νωρίτερα, κάθε ανάπτυξη τελικού σημείου έχει έναν περιορισμό στον αριθμό των ταυτόχρονων αιτημάτων ανάλογα με τον αριθμό των διακριτικών εισόδου και εξόδου καθώς και τον τύπο παρουσίας. Εάν αυτό δεν ανταποκρίνεται στην απαίτηση διεκπεραίωσης ή ταυτόχρονης αίτησης, μπορείτε να αυξήσετε την κλίμακα για να χρησιμοποιήσετε περισσότερες από μία παρουσίες πίσω από το αναπτυγμένο τελικό σημείο. Το SageMaker εκτελεί αυτόματα εξισορρόπηση φορτίου των ερωτημάτων μεταξύ των παρουσιών. Για παράδειγμα, ο ακόλουθος κώδικας αναπτύσσει ένα τελικό σημείο που υποστηρίζεται από τρεις παρουσίες:
Ο παρακάτω πίνακας δείχνει το κέρδος απόδοσης ως συντελεστή του αριθμού των περιπτώσεων για το μοντέλο Llama 2 7B.
| . | . | Διακίνηση (tokens/sec) | Καθυστέρηση (ms/token) | ||||||||||||||
| . | Ταυτόχρονα αιτήματα | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Καταμέτρηση περιπτώσεων | Τύπος συμβολής | Αριθμός συνολικών κουπονιών: 512, Αριθμός κουπονιών εξόδου: 256 | |||||||||||||||
| 1 | ml.g5.2xμεγάλο | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xμεγάλο | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xμεγάλο | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Συγκεκριμένα, το γόνατο στην καμπύλη λανθάνουσας απόδοσης μετατοπίζεται προς τα δεξιά επειδή οι υψηλότερες μετρήσεις παρουσιών μπορούν να χειριστούν μεγαλύτερους αριθμούς ταυτόχρονων αιτημάτων εντός του τελικού σημείου πολλαπλών στιγμών. Για αυτόν τον πίνακα, η τιμή της ταυτόχρονης αίτησης είναι για ολόκληρο το τελικό σημείο, όχι για τον αριθμό των ταυτόχρονων αιτημάτων που λαμβάνει κάθε μεμονωμένη παρουσία.
Μπορείτε επίσης να χρησιμοποιήσετε την αυτόματη κλιμάκωση, μια λειτουργία για την παρακολούθηση του φόρτου εργασίας σας και τη δυναμική προσαρμογή της χωρητικότητας για να διατηρήσετε σταθερή και προβλέψιμη απόδοση με το δυνατό χαμηλότερο κόστος. Αυτό ξεφεύγει από το πεδίο εφαρμογής αυτής της ανάρτησης. Για να μάθετε περισσότερα σχετικά με την αυτόματη κλιμάκωση, ανατρέξτε στο Διαμόρφωση τελικών σημείων συμπερασμάτων αυτόματης κλιμάκωσης στο Amazon SageMaker.
Κλήση τελικού σημείου με ταυτόχρονες αιτήσεις
Ας υποθέσουμε ότι έχετε μια μεγάλη παρτίδα ερωτημάτων που θα θέλατε να χρησιμοποιήσετε για να δημιουργήσετε απαντήσεις από ένα αναπτυγμένο μοντέλο υπό συνθήκες υψηλής απόδοσης. Για παράδειγμα, στο ακόλουθο μπλοκ κώδικα, συντάσσουμε μια λίστα με 1,000 ωφέλιμα φορτία, με κάθε ωφέλιμο φορτίο να ζητά τη δημιουργία 100 διακριτικών. Συνολικά, ζητάμε τη δημιουργία 100,000 διακριτικών.
Κατά την αποστολή μεγάλου αριθμού αιτημάτων στο API χρόνου εκτέλεσης του SageMaker, ενδέχεται να αντιμετωπίσετε σφάλματα περιορισμού. Για να μετριαστεί αυτό, μπορείτε να δημιουργήσετε ένα προσαρμοσμένο πρόγραμμα-πελάτη χρόνου εκτέλεσης SageMaker που αυξάνει τον αριθμό των προσπαθειών επανάληψης. Μπορείτε να παρέχετε το αντικείμενο συνεδρίας SageMaker που προκύπτει σε οποιοδήποτε από τα JumpStartModel κατασκευαστής ή sagemaker.predictor.retrieve_default εάν θέλετε να επισυνάψετε έναν νέο προγνωστικό παράγοντα σε ένα ήδη αναπτυγμένο τελικό σημείο. Στον ακόλουθο κώδικα, χρησιμοποιούμε αυτό το αντικείμενο περιόδου λειτουργίας κατά την ανάπτυξη ενός μοντέλου Llama 2 με προεπιλεγμένες διαμορφώσεις SageMaker JumpStart:
Αυτό το αναπτυγμένο τελικό σημείο έχει MAX_CONCURRENT_REQUESTS = 128 από προεπιλογή. Στο επόμενο μπλοκ, χρησιμοποιούμε τη βιβλιοθήκη ταυτόχρονων συμβάσεων μελλοντικής εκπλήρωσης για να επαναλάβουμε την κλήση του τελικού σημείου για όλα τα ωφέλιμα φορτία με 128 νήματα εργαζομένων. Το πολύ, το τελικό σημείο θα επεξεργαστεί 128 ταυτόχρονες αιτήσεις και όποτε ένα αίτημα επιστρέφει μια απάντηση, ο εκτελεστής θα στείλει αμέσως ένα νέο αίτημα στο τελικό σημείο.
Αυτό έχει ως αποτέλεσμα τη δημιουργία 100,000 συνολικών κουπονιών με απόδοση 1255 μάρκες/δευτερόλεπτο σε μία μόνο περίπτωση ml.g5.2xlarge. Αυτό διαρκεί περίπου 80 δευτερόλεπτα για την επεξεργασία.
Λάβετε υπόψη ότι αυτή η τιμή διακίνησης είναι σημαντικά διαφορετική από τη μέγιστη απόδοση για το Llama 2 7B σε ml.g5.2xlarge στους προηγούμενους πίνακες αυτής της ανάρτησης (486 tokens/sec σε 64 ταυτόχρονα αιτήματα). Αυτό οφείλεται στο ότι το ωφέλιμο φορτίο εισόδου χρησιμοποιεί 8 διακριτικά αντί για 256, ο αριθμός των διακριτικών εξόδου είναι 100 αντί για 256 και οι μικρότεροι αριθμοί διακριτικών επιτρέπουν 128 ταυτόχρονες αιτήσεις. Αυτή είναι μια τελευταία υπενθύμιση ότι όλοι οι αριθμοί καθυστέρησης και απόδοσης εξαρτώνται από το ωφέλιμο φορτίο! Η αλλαγή του αριθμού των διακριτικών ωφέλιμου φορτίου θα επηρεάσει τις διαδικασίες παρτίδας κατά την προβολή του μοντέλου, κάτι που με τη σειρά του θα επηρεάσει τους χρόνους προπληρωμής, αποκωδικοποίησης και αναμονής για την εφαρμογή σας.
Συμπέρασμα
Σε αυτήν την ανάρτηση, παρουσιάσαμε τη συγκριτική αξιολόγηση των SageMaker JumpStart LLM, συμπεριλαμβανομένων των Llama 2, Mistral και Falcon. Παρουσιάσαμε επίσης έναν οδηγό για τη βελτιστοποίηση της καθυστέρησης, της απόδοσης και του κόστους για τη διαμόρφωση ανάπτυξης τελικού σημείου. Μπορείτε να ξεκινήσετε εκτελώντας το σχετικό σημειωματάριο για να αξιολογήσετε την περίπτωση χρήσης σας.
Σχετικά με τους Συγγραφείς
 Δόκτωρ Kyle Ulrich είναι Εφαρμοσμένος Επιστήμονας με την ομάδα Amazon SageMaker JumpStart. Τα ερευνητικά του ενδιαφέροντα περιλαμβάνουν κλιμακωτούς αλγόριθμους μηχανικής μάθησης, όραση υπολογιστή, χρονοσειρές, μη παραμετρικές Μπεϋζιανές και διεργασίες Gauss. Το διδακτορικό του είναι από το Πανεπιστήμιο Duke και έχει δημοσιεύσει εργασίες στα NeurIPS, Cell και Neuron.
Δόκτωρ Kyle Ulrich είναι Εφαρμοσμένος Επιστήμονας με την ομάδα Amazon SageMaker JumpStart. Τα ερευνητικά του ενδιαφέροντα περιλαμβάνουν κλιμακωτούς αλγόριθμους μηχανικής μάθησης, όραση υπολογιστή, χρονοσειρές, μη παραμετρικές Μπεϋζιανές και διεργασίες Gauss. Το διδακτορικό του είναι από το Πανεπιστήμιο Duke και έχει δημοσιεύσει εργασίες στα NeurIPS, Cell και Neuron.
 Dr. Vivek Madan είναι Εφαρμοσμένος Επιστήμονας με την ομάδα Amazon SageMaker JumpStart. Πήρε το διδακτορικό του από το Πανεπιστήμιο του Ιλινόις στο Urbana-Champaign και ήταν μεταδιδακτορικός ερευνητής στο Georgia Tech. Είναι ενεργός ερευνητής στη μηχανική μάθηση και στο σχεδιασμό αλγορίθμων και έχει δημοσιεύσει εργασίες σε συνέδρια EMNLP, ICLR, COLT, FOCS και SODA.
Dr. Vivek Madan είναι Εφαρμοσμένος Επιστήμονας με την ομάδα Amazon SageMaker JumpStart. Πήρε το διδακτορικό του από το Πανεπιστήμιο του Ιλινόις στο Urbana-Champaign και ήταν μεταδιδακτορικός ερευνητής στο Georgia Tech. Είναι ενεργός ερευνητής στη μηχανική μάθηση και στο σχεδιασμό αλγορίθμων και έχει δημοσιεύσει εργασίες σε συνέδρια EMNLP, ICLR, COLT, FOCS και SODA.
 Δρ Ashish Khetan είναι Senior Applied Scientist με το Amazon SageMaker JumpStart και βοηθά στην ανάπτυξη αλγορίθμων μηχανικής μάθησης. Πήρε το διδακτορικό του από το Πανεπιστήμιο του Illinois Urbana-Champaign. Είναι ενεργός ερευνητής στη μηχανική μάθηση και στα στατιστικά συμπεράσματα και έχει δημοσιεύσει πολλές εργασίες σε συνέδρια NeurIPS, ICML, ICLR, JMLR, ACL και EMNLP.
Δρ Ashish Khetan είναι Senior Applied Scientist με το Amazon SageMaker JumpStart και βοηθά στην ανάπτυξη αλγορίθμων μηχανικής μάθησης. Πήρε το διδακτορικό του από το Πανεπιστήμιο του Illinois Urbana-Champaign. Είναι ενεργός ερευνητής στη μηχανική μάθηση και στα στατιστικά συμπεράσματα και έχει δημοσιεύσει πολλές εργασίες σε συνέδρια NeurIPS, ICML, ICLR, JMLR, ACL και EMNLP.
 Τζοάο Μούρα είναι Senior AI/ML Specialist Solutions Architect στο AWS. Η João βοηθά τους πελάτες της AWS – από μικρές νεοφυείς επιχειρήσεις έως μεγάλες επιχειρήσεις – να εκπαιδεύουν και να αναπτύσσουν μεγάλα μοντέλα αποτελεσματικά και να δημιουργούν ευρύτερα πλατφόρμες ML στο AWS.
Τζοάο Μούρα είναι Senior AI/ML Specialist Solutions Architect στο AWS. Η João βοηθά τους πελάτες της AWS – από μικρές νεοφυείς επιχειρήσεις έως μεγάλες επιχειρήσεις – να εκπαιδεύουν και να αναπτύσσουν μεγάλα μοντέλα αποτελεσματικά και να δημιουργούν ευρύτερα πλατφόρμες ML στο AWS.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/
- :έχει
- :είναι
- :δεν
- :που
- $UP
- 000
- 1
- 10
- 100
- 11
- 116
- 12
- 14
- 150
- 16
- 17
- 20
- 24
- 28
- 30
- 32
- 60
- 600
- 70
- 8
- 80
- a
- A100
- Ικανός
- Σχετικα
- πάνω από
- επιταχυντής
- επιταχυντές
- αποδοχή
- πρόσβαση
- ολοκληρώσει
- Σύμφωνα με
- Κατορθώνω
- επιτευχθεί
- απέναντι
- ενεργοποιήσεις
- ενεργός
- προσαρμόσει
- Πρόσθετος
- Επιπλέον
- προσαρμόσει
- πλεονεκτήματα
- επηρεάζουν
- Μετά το
- κατά
- σύνολο
- AI / ML
- αλγόριθμος
- αλγόριθμοι
- ευθυγράμμιση
- Όλα
- επιτρέπουν
- επιτρέπεται
- επιτρέπει
- alone
- ήδη
- Επίσης
- Αν και
- πάντοτε
- Amazon
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon υπηρεσίες Web
- ποσό
- an
- αναλύσεις
- ανάλυση
- και
- Άλλος
- κάθε
- api
- Εφαρμογή
- εφαρμοσμένος
- πλησιάζω
- κατάλληλος
- κατά προσέγγιση
- περίπου
- αρχιτεκτονική
- ΕΙΝΑΙ
- AS
- συσχετισμένη
- παραδοχές
- At
- αποδίδουν
- Προσπάθειες
- προσοχή
- αυτομάτως
- διαθέσιμος
- μέσος
- αποφύγετε
- AWS
- b
- ισορροπίες
- εξισορρόπησης
- εύρος ζώνης
- βασίζονται
- Βασικα
- δοσοληψία
- Bayesian
- BE
- επειδή
- γίνεται
- πριν
- συμπεριφορά
- πίσω
- είναι
- Πιστεύω
- αναφοράς
- συγκριτικής αξιολόγησης
- αναφοράς
- ευεργετική
- όφελος
- οφέλη
- ΚΑΛΎΤΕΡΟΣ
- Καλύτερα
- μεταξύ
- Πέρα
- Αποκλεισμός
- Μπλοκ
- δεσμεύεται
- ευρύς
- γενικά
- προϋπολογισμός
- χτίζω
- αλλά
- by
- κρύπτη
- υπολογίσει
- υπολογίζεται
- που ονομάζεται
- CAN
- Μπορεί να πάρει
- ικανότητα
- Χωρητικότητα
- καλύμματα
- ο οποίος
- περίπτωση
- περιπτώσεις
- Αιτία
- κύτταρο
- ορισμένες
- αλλαγή
- αλλαγή
- χαρακτηριστικά
- Επιλέξτε
- επιλέγονται
- σαφήνεια
- σαφώς
- πελάτης
- κωδικός
- Επικοινωνία
- συγκρίνουν
- συγκρότημα
- εξαρτήματα
- περιεκτικός
- υπολογισμός
- υπολογιστική
- υπολογιστική δύναμη
- υπολογισμοί
- Υπολογίστε
- υπολογιστή
- Computer Vision
- ανταγωνιστής
- κατάσταση
- Συνθήκες
- συνέδρια
- διαμόρφωση
- Εξετάστε
- θεωρούνται
- θεωρεί
- περιορισμούς
- καταναλώνεται
- Περιέχει
- συμφραζόμενα
- συνεχής
- συνεχώς
- Αντίστοιχος
- Κόστος
- Δικαστικά έξοδα
- μετράνε
- CPU
- δημιουργία
- κρίσιμης
- ακατέργαστος
- Ρεύμα
- καμπύλη
- έθιμο
- Πελάτες
- ημερομηνία
- Αποφασίζοντας
- απόφαση
- Αποκρυπτογράφηση
- μείωση
- μειώνεται
- αφιερωμένο
- Προεπιλογή
- ορίζεται
- ορίζεται
- Ορίζει
- Πτυχίο
- αποδεικνύουν
- καταδεικνύει
- εξαρτώμενος
- Σε συνάρτηση
- εξαρτάται
- παρατάσσω
- αναπτυχθεί
- ανάπτυξη
- ανάπτυξη
- αναπτύξεις
- αναπτύσσεται
- βάθος
- Συμπληρωματικός
- περιγράφεται
- Υπηρεσίες
- επιθυμητή
- λεπτομέρεια
- καθέκαστα
- Προσδιορίστε
- καθορίζει
- ανάπτυξη
- συσκευή
- Συσκευές
- διαφορετικές
- δύσκολος
- μειώνοντας
- συζητήσουν
- συζήτηση
- διακριτή
- διανέμονται
- Όχι
- κυριαρχούν
- Μην
- downtime
- dr
- αυτοκίνητο
- οδηγείται
- οδήγηση
- δυο
- Δούκας
- πανεπιστήμιο του Δούκα
- κατά την διάρκεια
- δυναμικά
- κάθε
- Νωρίτερα
- αποτελεσματικά
- αποτελεσματικά
- οκτώ
- είτε
- περικυκλώ
- αντιμετωπίζω
- από άκρη σε άκρη
- Τελικό σημείο
- τελικά σημεία
- τελειώνει
- αρκετά
- εισάγετε
- επιχειρήσεις
- Ολόκληρος
- Περιβάλλον
- ίσος
- ισούται
- σφάλμα
- λάθη
- ειδικά
- εκτίμηση
- Αιθέρας (ΕΤΗ)
- Even
- τελικά
- Κάθε
- ακριβώς
- παράδειγμα
- υπέρβαση
- Εκτός
- έκθεμα
- υπάρχει
- ακριβά
- εμπειρία
- έμπειρος
- εξήγηση
- διερευνήσει
- διερευνά
- έκφραση
- γεγονός
- παράγοντας
- παράγοντες
- ΑΠΟΤΥΓΧΑΝΩ
- γεράκι
- οικογένειες
- οικογένεια
- εφικτός
- Χαρακτηριστικό
- Χαρακτηριστικά
- λίγοι
- Εικόνα
- τελικός
- Τελικά
- Εύρεση
- εύρεση
- Όνομα
- ταιριάζουν
- Συγκέντρωση
- εστιάζει
- Εξής
- Για
- Πρώην
- τύπος
- Προς τα εμπρός
- Θεμέλιο
- τέσσερα
- από
- πλήρη
- πλήρως
- θεμελιωδώς
- περαιτέρω
- Επί πλέον
- futures
- Κέρδος
- κέρδη
- General
- παράγουν
- παράγεται
- δημιουργεί
- παραγωγής
- γενεά
- Γεωργία
- παίρνω
- δεδομένου
- Στόχοι
- καλός
- πήρε
- GPU
- GPU
- μεγαλύτερη
- μεγαλώνει
- Ανάπτυξη
- εγγύηση
- φρουρά
- καθοδηγήσει
- λαβή
- υλικού
- Έχω
- he
- κεφαλές
- βαριά
- βοήθεια
- βοηθά
- εδώ
- Ψηλά
- υψηλού επιπέδου
- υψηλότερο
- υψηλότερο
- του
- κρατήστε
- Οριζόντιος
- ώρα
- ΩΡΕΣ
- Πως
- Πώς να
- Ωστόσο
- HTTPS
- i
- ICLR
- ID
- ιδανικό
- ιδανικά
- προσδιορίσει
- if
- Ιλλινόις
- αμέσως
- Επίπτωση
- Επιπτώσεις
- εισαγωγή
- σημαντικό
- το σημαντικότερο
- βελτίωση
- βελτίωση
- βελτιώσεις
- βελτιώνει
- in
- περιλαμβάνουν
- περιλαμβάνονται
- Συμπεριλαμβανομένου
- συμπερίληψη
- Εισερχόμενος
- Αυξάνουν
- αυξημένη
- Αυξήσεις
- αύξηση
- ατομικές
- εισαγωγή
- είσοδοι
- παράδειγμα
- περιπτώσεις
- αντί
- ενδιαφερόμενος
- συμφέροντα
- Ενδιάμεσος
- σε
- περιλαμβάνει
- IT
- ΤΟΥ
- jpg
- δικαιολογημένη
- πλήκτρα
- Είδος
- Kyle
- Γλώσσα
- large
- Μεγάλες επιχειρήσεις
- μεγαλύτερος
- μεγαλύτερη
- Αφάνεια
- αργότερα
- αργότερο
- στρώμα
- οδηγήσει
- ΜΑΘΑΊΝΩ
- μάθηση
- αφήνοντας
- αριστερά
- Μήκος
- Βιβλιοθήκη
- ζωή
- Μου αρέσει
- Πιθανός
- LIMIT
- περιορισμός
- Περιωρισμένος
- όρια
- γραμμή
- Λιστα
- Είδος μικρής καμήλας
- φορτίο
- φόρτωση
- τοποθεσία
- πλέον
- ματιά
- Χαμηλός
- χαμηλότερα
- χαμηλότερο
- μηχανή
- μάθηση μηχανής
- που
- διατηρήσουν
- κάνω
- πολοί
- Αυξάνω στον ανώτατο βαθμό
- μεγιστοποιεί
- μεγιστοποιώντας
- ανώτατο όριο
- Ενδέχεται..
- νόημα
- μέσα
- μετρήσεις
- μηχανισμός
- μηχανισμούς
- Γνωρίστε
- Μνήμη
- που αναφέρθηκαν
- πληρούνται
- μέθοδοι
- ενδέχεται να
- εκατομμύριο
- ελαχιστοποίηση
- ελαχιστοποιώντας
- ελάχιστο
- ανήλικος
- πρακτικά
- Μετριάζω
- ML
- Τρόπος
- μοντέλο
- μοντέλα
- ΜΟΝΤΕΡΝΑ
- Παρακολούθηση
- περισσότερο
- πλέον
- πολλαπλούς
- πρέπει
- Φύση
- αναγκαίως
- απαραίτητος
- Ανάγκη
- NeurIPS
- Νέα
- επόμενη
- Όχι.
- ιδιαίτερα
- σημείωση
- Σημειώνεται
- αριθμός
- αριθμοί
- αντικείμενο
- παρατηρήσεις
- παρατηρούμε
- παρατηρούμενη
- αποκτήσει
- Εμφανή
- συμβούν
- που συμβαίνουν
- Πιθανότητα
- of
- συχνά
- on
- ONE
- αποκλειστικά
- λειτουργίας
- λειτουργία
- λειτουργίες
- βέλτιστη
- Βελτιστοποίηση
- Επιλογή
- or
- τάξη
- ΑΛΛΑ
- Άλλα
- αλλιώς
- δικός μας
- παραγωγή
- επί
- χαρτιά
- Παράλληλο
- παράμετρος
- παράμετροι
- Ειδικότερα
- passieren
- περάσματα
- πρότυπα
- παύση
- για
- εκτελέσει
- επίδοση
- εκτελεί
- phd
- φαινόμενο
- Πλατφόρμες
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- συν
- Σημείο
- φτωχός
- κατοικημένη περιοχή
- δυνατός
- Θέση
- δύναμη
- Πρακτικός
- προηγείται
- ακριβώς
- προβλέψει
- Αναμενόμενος
- πρόβλεψη
- Predictor
- προτιμώ
- παρουσιάζονται
- πρόληψη
- προηγούμενος
- προηγουμένως
- τιμή
- τιμολόγηση
- πρωταρχικός
- αρχές
- Δώστε προτεραιότητα
- διαδικασια μας
- επεξεργασία
- Διεργασίες
- μεταποίηση
- παράγει
- προστασία
- παρέχουν
- παρέχεται
- παρέχει
- δημοσίως
- δημοσιεύθηκε
- σκοπός
- ερωτήματα
- αύξηση
- Τιμές
- μάλλον
- αναλογία
- φθάσουν
- πραγματικός
- πραγματική ζωή
- σε πραγματικό χρόνο
- λόγος
- λαμβάνει
- συνιστώ
- συστάσεις
- μείωση
- μειώνει
- παραπέμπω
- αναφέρεται
- καθεστώς
- δίαιτες
- σχέση
- Σχέσεις
- παραμένουν
- υπόλοιπα
- λείψανα
- υπενθύμιση
- επανειλημμένες
- απάντηση
- αναπαραγωγή
- αναφέρουν
- εκπροσωπώ
- ζητήσει
- ζητώντας
- αιτήματα
- απαιτούν
- απαιτείται
- απαίτηση
- απαιτήσεις
- Απαιτεί
- έρευνα
- ερευνητής
- πόρος
- Υποστηρικτικό υλικό
- σεβασμός
- απάντησης
- απαντήσεις
- με αποτέλεσμα
- Αποτελέσματα
- Επιστροφές
- δεξιά
- δρομολόγηση
- ΣΕΙΡΑ
- Άρθρο
- τρέξιμο
- τρέξιμο
- σοφός
- ίδιο
- επεκτάσιμη
- Κλίμακα
- απολέπιση
- σενάριο
- σενάρια
- Επιστήμονας
- έκταση
- Δεύτερος
- δευτερόλεπτα
- Τμήμα
- τμήματα
- δείτε
- δει
- επιλέξτε
- επιλέγονται
- επιλογή
- επιλογή
- στείλετε
- αποστολή
- αρχαιότερος
- αίσθηση
- αποστέλλονται
- ξεχωριστό
- Ακολουθία
- Σειρές
- σερβίρεται
- διακομιστής
- διακομιστές
- Υπηρεσίες
- εξυπηρετούν
- Συνεδρίαση
- σειρά
- τον καθορισμό
- θραύσμα
- κοπής
- Κοινοποίηση
- μοιράζονται
- Βάρδιες
- θα πρέπει να
- έδειξε
- Δείχνει
- σημαντικός
- σημαντικά
- παρόμοιες
- Απλούς
- ταυτοχρόνως
- ενιαίας
- Μέγεθος
- small
- μικρότερος
- So
- λογισμικό
- Λύσεις
- μερικοί
- Πηγή
- ειδικός
- συγκεκριμένες
- προδιαγραφές
- καθορίζεται
- specs
- ταχύτητα
- διαίρεση
- σποραδικός
- πρότυπο
- Εκκίνηση
- ξεκίνησε
- ξεκινά
- Startups
- στατιστικός
- σταθερός
- Βήμα
- Βήματα
- Ακόμη
- στάση
- Μελέτη
- μεταγενέστερος
- ουσιώδης
- τέτοιος
- κατάλληλος
- υποστήριξη
- υποστηριζόνται!
- σύστημα
- τραπέζι
- ραπτική
- Πάρτε
- Takeaways
- παίρνει
- tech
- τεχνικές
- Τείνουν
- όρος
- όροι
- δοκιμή
- από
- ότι
- Η
- Η Πηγη
- τους
- τότε
- θεωρητικός
- θεωρία
- Εκεί.
- εκ τούτου
- επομένως
- Αυτοί
- αυτοί
- πράγματα
- αυτό
- εκείνοι
- τρία
- Μέσω
- διακίνηση
- ώρα
- Χρονική σειρά
- φορές
- προς την
- μαζι
- ένδειξη
- κουπόνια
- πολύ
- Σύνολο
- tp
- ίχνος
- Τρένο
- μεταφορά
- μεταβιβάσεις
- Μεταμόρφωση
- μετασχηματιστής
- αληθής
- ΣΤΡΟΦΗ
- δύο
- τύπος
- τύποι
- συνήθως
- υπό
- καταλαβαίνω
- κατανόηση
- πανεπιστήμιο
- Χρήση
- χρήση
- περίπτωση χρήσης
- μεταχειρισμένος
- Χρήστες
- Η εμπειρία χρήστη
- Χρήστες
- χρησιμοποιεί
- χρησιμοποιώντας
- χρησιμοποιώ
- έγκυρος
- αξία
- Αξίες
- παραλλαγές
- ποικιλία
- επαληθεύει
- πολύπλευρος
- πολύ
- μέσω
- όραμα
- vs
- περιμένετε
- θέλω
- ζεστός
- ήταν
- Τρόπος..
- τρόπους
- we
- ιστός
- διαδικτυακές υπηρεσίες
- ΛΟΙΠΌΝ
- ήταν
- Τι
- Τι είναι
- πότε
- οποτεδήποτε
- ενώ
- Ποιό
- ενώ
- Ο ΟΠΟΊΟΣ
- θα
- με
- εντός
- χωρίς
- Εργασία
- εργάτης
- θα
- ακόμη
- αποδίδοντας
- εσείς
- Σας
- zephyrnet