Εικόνα από συγγραφέα
Βουτώντας στον κόσμο της επιστήμης δεδομένων και της μηχανικής μάθησης, μία από τις θεμελιώδεις δεξιότητες που θα συναντήσετε είναι η τέχνη της ανάγνωσης δεδομένων. Εάν έχετε ήδη κάποια εμπειρία με αυτό, πιθανότατα είστε εξοικειωμένοι με το JSON (JavaScript Object Notation) – μια δημοφιλής μορφή τόσο για την αποθήκευση όσο και για την ανταλλαγή δεδομένων.
Σκεφτείτε πώς οι βάσεις δεδομένων NoSQL όπως η MongoDB αγαπούν να αποθηκεύουν δεδομένα σε JSON ή πώς τα API REST συχνά αποκρίνονται με την ίδια μορφή.
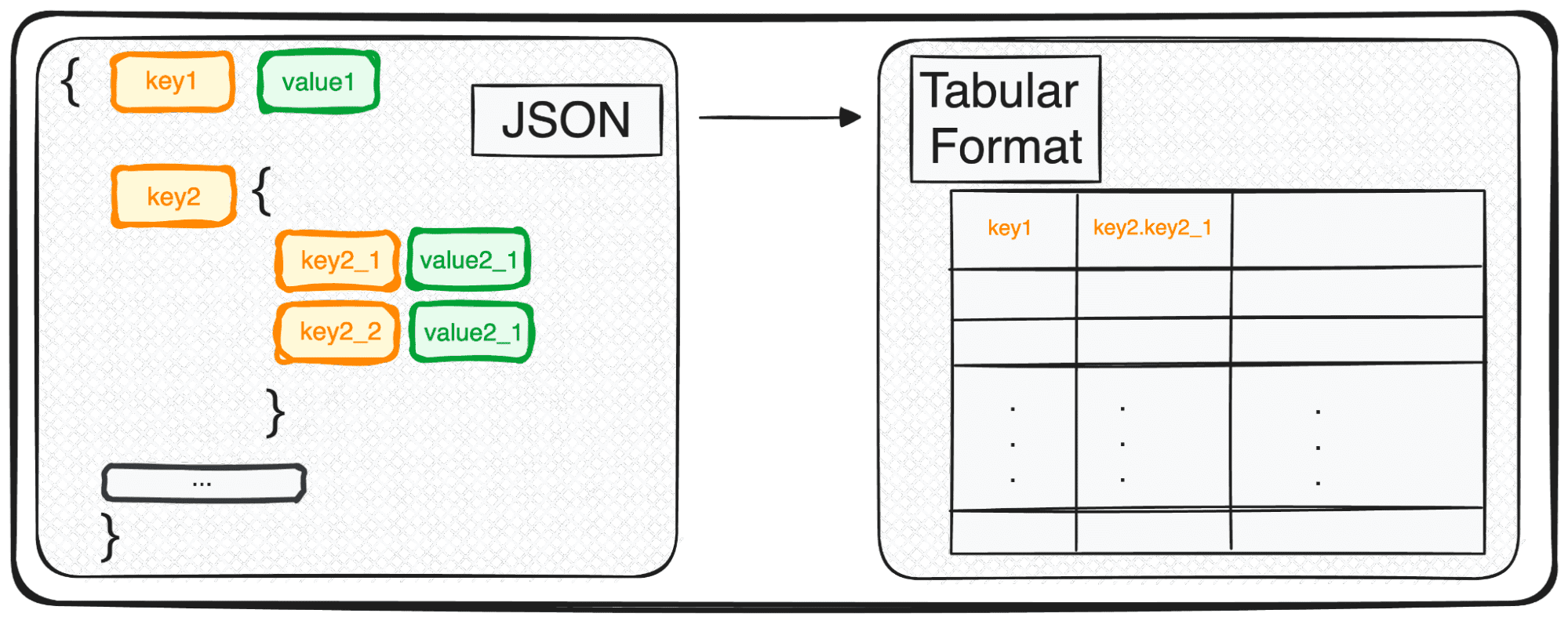
Ωστόσο, το JSON, αν και είναι ιδανικό για αποθήκευση και ανταλλαγή, δεν είναι αρκετά έτοιμο για εις βάθος ανάλυση στην ακατέργαστη μορφή του. Εδώ είναι που το μετατρέπουμε σε κάτι πιο φιλικό αναλυτικά – σε μορφή πίνακα.
Έτσι, είτε ασχολείστε με ένα μεμονωμένο αντικείμενο JSON είτε με μια ευχάριστη συστοιχία από αυτά, με τους όρους της Python, ουσιαστικά χειρίζεστε ένα dict ή μια λίστα εντολών.
Ας εξερευνήσουμε μαζί πώς εκτυλίσσεται αυτός ο μετασχηματισμός, καθιστώντας τα δεδομένα μας ώριμα για ανάλυση ????
Σήμερα θα εξηγήσω μια μαγική εντολή που μας επιτρέπει να αναλύουμε εύκολα οποιοδήποτε JSON σε μορφή πίνακα σε δευτερόλεπτα.
Και είναι… π.δ.json_normalize()
Ας δούμε λοιπόν πώς λειτουργεί με διαφορετικούς τύπους JSON.
Ο πρώτος τύπος JSON με τον οποίο μπορούμε να δουλέψουμε είναι JSON μονού επιπέδου με λίγα κλειδιά και τιμές. Ορίζουμε τα πρώτα μας απλά JSON ως εξής:
Κωδικός ανά συγγραφέα
Ας προσομοιώσουμε λοιπόν την ανάγκη εργασίας με αυτά τα JSON. Όλοι γνωρίζουμε ότι δεν υπάρχουν πολλά να κάνουμε στη μορφή JSON. Πρέπει να μετατρέψουμε αυτά τα JSON σε κάποια αναγνώσιμη και τροποποιήσιμη μορφή… που σημαίνει Pandas DataFrames!
1.1 Αντιμετώπιση απλών δομών JSON
Πρώτα, πρέπει να εισαγάγουμε τη βιβλιοθήκη pandas και στη συνέχεια μπορούμε να χρησιμοποιήσουμε την εντολή pd.json_normalize(), ως εξής:
import pandas as pd
pd.json_normalize(json_string)
Εφαρμόζοντας αυτήν την εντολή σε ένα JSON με μία μόνο εγγραφή, λαμβάνουμε τον πιο βασικό πίνακα. Ωστόσο, όταν τα δεδομένα μας είναι λίγο πιο περίπλοκα και παρουσιάζουν μια λίστα με JSON, μπορούμε να χρησιμοποιήσουμε την ίδια εντολή χωρίς περαιτέρω επιπλοκές και η έξοδος θα αντιστοιχεί σε έναν πίνακα με πολλές εγγραφές.

Εικόνα από συγγραφέα
Εύκολο… σωστά;
Το επόμενο φυσικό ερώτημα είναι τι συμβαίνει όταν λείπουν κάποιες από τις τιμές.
1.2 Αντιμετώπιση μηδενικών τιμών
Φανταστείτε ότι ορισμένες από τις αξίες δεν είναι ενημερωμένες, όπως για παράδειγμα, λείπει το αρχείο εισοδήματος για τον David. Όταν μετατρέπουμε το JSON μας σε ένα απλό πλαίσιο δεδομένων pandas, η αντίστοιχη τιμή θα εμφανίζεται ως NaN.
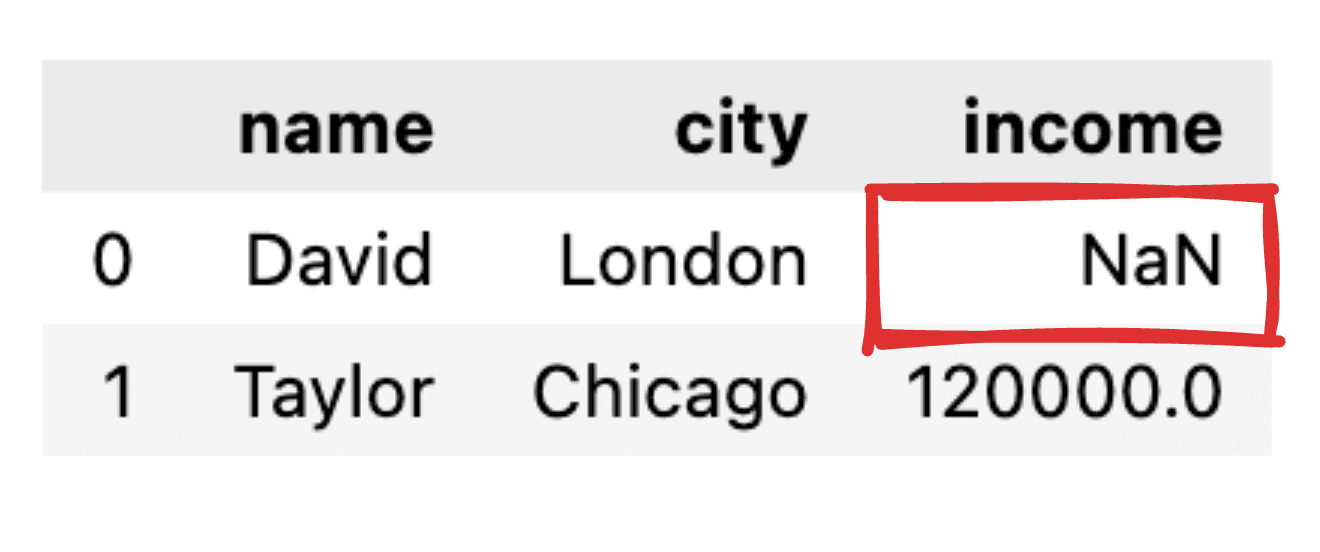
Εικόνα από συγγραφέα
Και τι γίνεται αν θέλω να πάρω μόνο μερικά από τα πεδία;
1.3 Επιλογή μόνο των στηλών που σας ενδιαφέρουν
Σε περίπτωση που θέλουμε απλώς να μετατρέψουμε ορισμένα συγκεκριμένα πεδία σε ένα πίνακα pandas DataFrame, η εντολή json_normalize() δεν μας επιτρέπει να επιλέξουμε ποια πεδία θα μετατρέψουμε.
Επομένως, θα πρέπει να πραγματοποιηθεί μια μικρή προεπεξεργασία του JSON όπου φιλτράρουμε μόνο αυτές τις στήλες που μας ενδιαφέρουν.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Λοιπόν, ας προχωρήσουμε σε κάποια πιο προηγμένη δομή JSON.
Όταν ασχολούμαστε με JSON πολλαπλών επιπέδων, βρισκόμαστε με ένθετα JSON σε διαφορετικά επίπεδα. Η διαδικασία είναι η ίδια όπως πριν, αλλά σε αυτήν την περίπτωση, μπορούμε να επιλέξουμε πόσα επίπεδα θέλουμε να μετατρέψουμε. Από προεπιλογή, η εντολή θα επεκτείνει πάντα όλα τα επίπεδα και θα δημιουργεί νέες στήλες που περιέχουν το συνενωμένο όνομα όλων των ένθετων επιπέδων.
Αν λοιπόν κανονικοποιήσουμε τα παρακάτω JSON.
Κωδικός ανά συγγραφέα
Θα λάβαμε τον παρακάτω πίνακα με 3 στήλες κάτω από τις δεξιότητες πεδίου:
- δεξιότητες.python
- δεξιότητες.SQL
- δεξιότητες.GCP
και 4 στήλες κάτω από τους ρόλους πεδίου
- ρόλοι.διαχειριστής έργου
- ρόλοι.μηχανικός δεδομένων
- ρόλους.data scientist
- ρόλοι.αναλυτής δεδομένων

Εικόνα από συγγραφέα
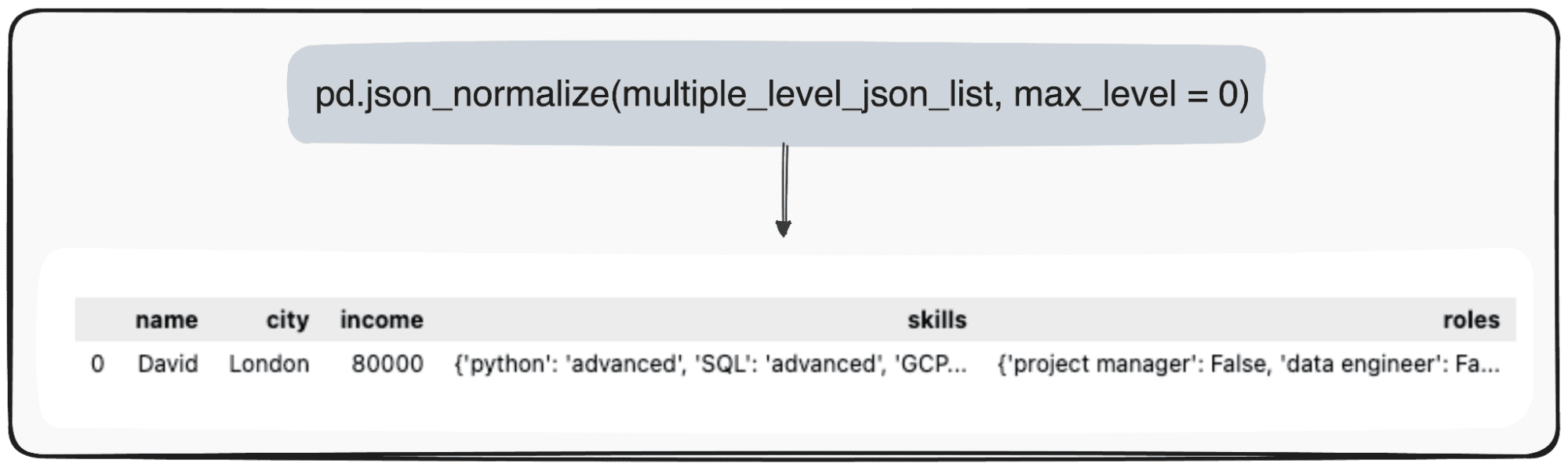
Ωστόσο, φανταστείτε ότι θέλουμε απλώς να μεταμορφώσουμε το κορυφαίο μας επίπεδο. Μπορούμε να το κάνουμε ορίζοντας συγκεκριμένα την παράμετρο max_level σε 0 (το max_level που θέλουμε να επεκτείνουμε).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Οι τιμές σε εκκρεμότητα θα διατηρηθούν στα JSON στο DataFrame των pandas μας.
Εικόνα από συγγραφέα
Η τελευταία περίπτωση που μπορούμε να βρούμε είναι να έχουμε μια ένθετη λίστα σε ένα πεδίο JSON. Οπότε πρώτα ορίζουμε τα JSON μας προς χρήση.
Κωδικός ανά συγγραφέα
Μπορούμε να διαχειριστούμε αποτελεσματικά αυτά τα δεδομένα χρησιμοποιώντας Pandas στην Python. Η συνάρτηση pd.json_normalize() είναι ιδιαίτερα χρήσιμη σε αυτό το πλαίσιο. Μπορεί να ισοπεδώσει τα δεδομένα JSON, συμπεριλαμβανομένης της ένθετης λίστας, σε μια δομημένη μορφή κατάλληλη για ανάλυση. Όταν αυτή η συνάρτηση εφαρμόζεται στα δεδομένα JSON μας, παράγει έναν κανονικοποιημένο πίνακα που ενσωματώνει την ένθετη λίστα ως μέρος των πεδίων της.
Επιπλέον, το Pandas προσφέρει τη δυνατότητα περαιτέρω βελτίωσης αυτής της διαδικασίας. Χρησιμοποιώντας την παράμετρο record_path στο pd.json_normalize(), μπορούμε να κατευθύνουμε τη συνάρτηση για να κανονικοποιήσει συγκεκριμένα την ένθετη λίστα.
Αυτή η ενέργεια οδηγεί σε έναν ειδικό πίνακα αποκλειστικά για τα περιεχόμενα της λίστας. Από προεπιλογή, αυτή η διαδικασία θα ξεδιπλώσει μόνο τα στοιχεία μέσα στη λίστα. Ωστόσο, για να εμπλουτίσουμε αυτόν τον πίνακα με πρόσθετο περιβάλλον, όπως η διατήρηση ενός συσχετισμένου αναγνωριστικού για κάθε εγγραφή, μπορούμε να χρησιμοποιήσουμε τη μετα-παράμετρο.

Εικόνα από συγγραφέα
Συνοπτικά, ο μετασχηματισμός των δεδομένων JSON σε αρχεία CSV χρησιμοποιώντας τη βιβλιοθήκη Pandas της Python είναι εύκολη και αποτελεσματική.
Το JSON εξακολουθεί να είναι η πιο κοινή μορφή στη σύγχρονη αποθήκευση και ανταλλαγή δεδομένων, ιδίως στις βάσεις δεδομένων NoSQL και στα API REST. Ωστόσο, παρουσιάζει ορισμένες σημαντικές αναλυτικές προκλήσεις κατά την επεξεργασία δεδομένων στην ακατέργαστη μορφή τους.
Ο κεντρικός ρόλος του pd.json_normalize() των Pandas αναδεικνύεται ως ένας εξαιρετικός τρόπος χειρισμού τέτοιων μορφών και μετατροπής των δεδομένων μας σε pandas DataFrame.
Ελπίζω ότι αυτός ο οδηγός ήταν χρήσιμος και την επόμενη φορά που θα ασχοληθείτε με το JSON, μπορείτε να το κάνετε με πιο αποτελεσματικό τρόπο.
Μπορείτε να πάτε να ελέγξετε το αντίστοιχο σημειωματάριο Jupyter στο ακολουθώντας το αποθετήριο GitHub.
Ζοζέπ Φερέρ είναι μηχανικός ανάλυσης από τη Βαρκελώνη. Αποφοίτησε από τη φυσική μηχανική και αυτή τη στιγμή εργάζεται στον τομέα της Επιστήμης Δεδομένων που εφαρμόζεται στην ανθρώπινη κινητικότητα. Είναι δημιουργός περιεχομένου μερικής απασχόλησης που επικεντρώνεται στην επιστήμη και την τεχνολογία δεδομένων. Μπορείτε να επικοινωνήσετε μαζί του στο LinkedIn, Twitter or Μέτριας Δυσκολίας.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :είναι
- :δεν
- :που
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- Σχετικα
- Ενέργειες
- Πρόσθετος
- προηγμένες
- Όλα
- επιτρέπουν
- επιτρέπει
- ήδη
- πάντοτε
- an
- ανάλυση
- αναλυτής
- Αναλυτικός
- analytics
- και
- κάθε
- APIs
- εμφανίζομαι
- εφαρμοσμένος
- εφαρμόζοντας
- ΕΙΝΑΙ
- Παράταξη
- Τέχνη
- AS
- συσχετισμένη
- Βαρκελώνη
- βασικός
- BE
- πριν
- Κομμάτι
- και οι δύο
- αλλά
- by
- CAN
- ικανότητα
- περίπτωση
- προκλήσεις
- έλεγχος
- Επιλέξτε
- Πόλη
- Στήλες
- Κοινός
- συγκρότημα
- επιπλοκές
- επικοινωνήστε μαζί μας
- περιεχόμενο
- περιεχόμενα
- συμφραζόμενα
- μετατρέψετε
- μετατροπή
- ανταποκρίνομαι
- Αντίστοιχος
- δημιουργός
- Τη στιγμή
- ημερομηνία
- αναλυτής δεδομένων
- μηχανικός δεδομένων
- επιστημονικά δεδομένα
- επιστήμονας δεδομένων
- αποθήκευση δεδομένων
- βάσεις δεδομένων
- Δαβίδ
- μοιρασιά
- αφιερωμένο
- Προεπιλογή
- ορίζεται
- καθορίζοντας
- γοητευτικός
- DICT
- διαφορετικές
- κατευθύνει
- do
- κάνει
- κάθε
- εύκολα
- εύκολος
- Αποτελεσματικός
- αποτελεσματικά
- στοιχεία
- αναδύεται
- συνάντηση
- μηχανικός
- Μηχανική
- εμπλουτίζω
- κατ 'ουσίαν,
- ανταλλαγή
- ανταλλαγή
- αποκλειστικά
- Ανάπτυξη
- εμπειρία
- εξηγώντας
- διερευνήσει
- οικείος
- λίγοι
- πεδίο
- Πεδία
- Αρχεία
- φιλτράρισμα
- Εύρεση
- Όνομα
- επικεντρώθηκε
- Εξής
- εξής
- Για
- μορφή
- μορφή
- φιλικό
- από
- λειτουργία
- θεμελιώδης
- περαιτέρω
- GCP
- παράγουν
- παίρνω
- GitHub
- Go
- εξαιρετική
- καθοδηγήσει
- λαβή
- Χειρισμός
- συμβαίνει
- Έχω
- που έχει
- he
- αυτόν
- ελπίζω
- Πως
- Ωστόσο
- HTTPS
- ανθρώπινος
- i
- ΕΓΩ ΘΑ
- ID
- if
- φαντάζομαι
- εισαγωγή
- σημαντικό
- in
- σε βάθος
- περιλαμβάνουν
- Συμπεριλαμβανομένου
- Εισόδημα
- ενσωματώνει
- ενημερώνεται
- παράδειγμα
- τόκος
- σε
- isn
- IT
- ΤΟΥ
- το JavaScript
- json
- Jupyter Notebook
- μόλις
- KDnuggets
- Κλειδί
- πλήκτρα
- Ξέρω
- Επίθετο
- μάθηση
- Επίπεδο
- επίπεδα
- Βιβλιοθήκη
- Μου αρέσει
- Λιστα
- λίγο
- ll
- αγάπη
- μηχανή
- μάθηση μηχανής
- μαγεία
- διατηρηθεί
- Κατασκευή
- διαχείριση
- διευθυντής
- πολοί
- μέσα
- Meta
- Λείπει
- κινητικότητα
- ΜΟΝΤΕΡΝΑ
- MongoDB
- περισσότερο
- πλέον
- μετακινήσετε
- πολύ
- πολλαπλούς
- όνομα
- Φυσικό
- Ανάγκη
- ένθετο
- Νέα
- επόμενη
- Όχι.
- ιδιαίτερα
- σημειωματάριο
- αντικείμενο
- αποκτήσει
- of
- προσφορές
- συχνά
- on
- ONE
- αποκλειστικά
- or
- δικός μας
- εμάς
- παραγωγή
- Πάντα
- παράμετρος
- μέρος
- ιδιαίτερα
- εκκρεμής
- τέλειος
- εκτελούνται
- Φυσική
- πιλοτικές
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- Δημοφιλής
- δώρα
- πιθανώς
- διαδικασία
- διαδικασια μας
- παράγει
- σχέδιο
- Python
- ερώτηση
- αρκετά
- Ακατέργαστος
- RE
- Ανάγνωση
- έτοιμος
- ρεκόρ
- αρχεία
- τελειοποίηση
- Απάντηση
- ΠΕΡΙΦΕΡΕΙΑ
- Αποτελέσματα
- συγκράτησης
- δεξιά
- Ρόλος
- s
- ίδιο
- Επιστήμη
- Επιστήμη και Τεχνολογία
- Επιστήμονας
- δευτερόλεπτα
- δείτε
- επιλογή
- θα πρέπει να
- Απλούς
- υποκρίνομαι
- ενιαίας
- δεξιότητες
- small
- So
- μερικοί
- κάτι
- συγκεκριμένες
- ειδικά
- SQL
- Ακόμη
- χώρος στο δίσκο
- κατάστημα
- δομή
- δομημένος
- τέτοιος
- κατάλληλος
- ΠΕΡΙΛΗΨΗ
- T
- τραπέζι
- Τεχνολογία
- όροι
- ότι
- Η
- ο κόσμος
- τους
- Τους
- τότε
- Αυτοί
- αυτό
- εκείνοι
- ώρα
- προς την
- μαζι
- κορυφή
- Μεταμορφώστε
- Μεταμόρφωση
- μετασχηματίζοντας
- τύπος
- τύποι
- υπό
- us
- χρήση
- χρήσιμος
- χρησιμοποιώντας
- αξιοποιώντας
- αξία
- Αξίες
- θέλω
- ήταν
- Τρόπος..
- we
- Τι
- πότε
- αν
- Ποιό
- ενώ
- θα
- με
- εντός
- Εργασία
- εργαζόμενος
- λειτουργεί
- κόσμος
- θα
- εσείς
- zephyrnet