Εικόνα από Editor
Βασικές τακτικές
- Το t-test είναι μια στατιστική δοκιμή που μπορεί να χρησιμοποιηθεί για να προσδιοριστεί εάν υπάρχει σημαντική διαφορά μεταξύ των μέσων τιμών δύο ανεξάρτητων δειγμάτων δεδομένων.
- Επεξηγούμε πώς μπορεί να εφαρμοστεί ένα τεστ t χρησιμοποιώντας το σύνολο δεδομένων ίριδας και τη βιβλιοθήκη Scipy της Python.
Το t-test είναι μια στατιστική δοκιμή που μπορεί να χρησιμοποιηθεί για να προσδιοριστεί εάν υπάρχει σημαντική διαφορά μεταξύ των μέσων τιμών δύο ανεξάρτητων δειγμάτων δεδομένων. Σε αυτό το σεμινάριο, παρουσιάζουμε την πιο βασική έκδοση του τεστ t, για την οποία θα υποθέσουμε ότι τα δύο δείγματα έχουν ίσες διακυμάνσεις. Άλλες προηγμένες εκδόσεις του τεστ t περιλαμβάνουν το τεστ t Welch, το οποίο είναι μια προσαρμογή του τεστ t και είναι πιο αξιόπιστο όταν τα δύο δείγματα έχουν άνισες διακυμάνσεις και πιθανώς άνισα μεγέθη δειγμάτων.
Η στατιστική t ή η τιμή t υπολογίζεται ως εξής:
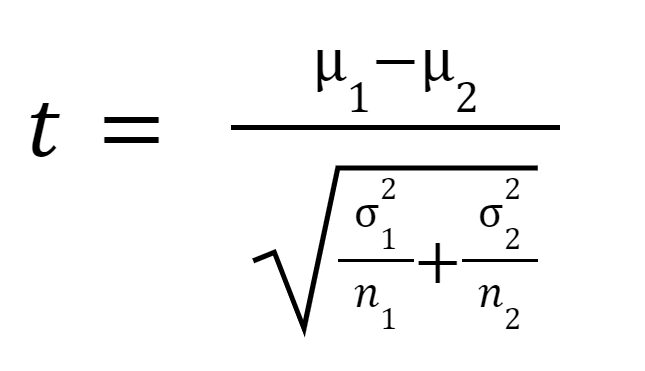
όπου
είναι ο μέσος όρος του δείγματος 1,
είναι ο μέσος όρος του δείγματος 2,
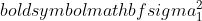 είναι η διακύμανση του δείγματος 1,
είναι η διακύμανση του δείγματος 1, 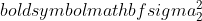 είναι η διακύμανση του δείγματος 2,
είναι η διακύμανση του δείγματος 2, 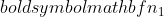 είναι το μέγεθος του δείγματος του δείγματος 1 και
είναι το μέγεθος του δείγματος του δείγματος 1 και 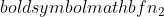 είναι το μέγεθος του δείγματος του δείγματος 2.
είναι το μέγεθος του δείγματος του δείγματος 2.
Για να επεξηγήσουμε τη χρήση του τεστ t, θα δείξουμε ένα απλό παράδειγμα χρησιμοποιώντας το σύνολο δεδομένων ίριδας. Ας υποθέσουμε ότι παρατηρούμε δύο ανεξάρτητα δείγματα, π.χ. μήκη σέπαλου λουλουδιών, και εξετάζουμε εάν τα δύο δείγματα προέρχονται από τον ίδιο πληθυσμό (π.χ. το ίδιο είδος λουλουδιών ή δύο είδη με παρόμοια χαρακτηριστικά σέπαλου) ή δύο διαφορετικούς πληθυσμούς.
Το τεστ t ποσοτικοποιεί τη διαφορά μεταξύ των αριθμητικών μέσων των δύο δειγμάτων. Η τιμή p ποσοτικοποιεί την πιθανότητα να ληφθούν τα παρατηρούμενα αποτελέσματα, υποθέτοντας ότι η μηδενική υπόθεση (ότι τα δείγματα προέρχονται από πληθυσμούς με τον ίδιο μέσο πληθυσμό) είναι αληθής. Μια τιμή p μεγαλύτερη από ένα επιλεγμένο όριο (π.χ. 5% ή 0.05) δείχνει ότι η παρατήρησή μας δεν είναι τόσο απίθανο να έχει συμβεί τυχαία. Επομένως, αποδεχόμαστε τη μηδενική υπόθεση των ίσων μέσων πληθυσμού. Εάν η τιμή p είναι μικρότερη από το όριο μας, τότε έχουμε στοιχεία ενάντια στη μηδενική υπόθεση των ίσων μέσων πληθυσμού.
Είσοδος T-Test
Οι είσοδοι ή οι παράμετροι που είναι απαραίτητες για την εκτέλεση ενός τεστ t είναι:
- Δύο συστοιχίες a και b που περιέχει τα δεδομένα για το δείγμα 1 και το δείγμα 2
Έξοδοι T-Test
Το t-test επιστρέφει τα ακόλουθα:
- Η υπολογισμένη t-statistics
- Η τιμή p
Εισαγάγετε τις απαραίτητες βιβλιοθήκες
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Φόρτωση συνόλου δεδομένων Iris
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Υπολογίστε τη μέση τιμή του δείγματος και τις διακυμάνσεις του δείγματος
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Εφαρμογή t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
Παραγωγή
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
Παραγωγή
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
Παραγωγή
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Παρατηρήσεις
Παρατηρούμε ότι η χρήση "true" ή "false" για την παράμετρο "equal-var" δεν αλλάζει τόσο πολύ τα αποτελέσματα του t-test. Παρατηρούμε επίσης ότι η εναλλαγή της σειράς των δειγματοληπτικών πινάκων a_1 και b_1 δίδει μια αρνητική τιμή t-test, αλλά δεν αλλάζει το μέγεθος της τιμής t-test, όπως αναμένεται. Δεδομένου ότι η υπολογισμένη τιμή p είναι πολύ μεγαλύτερη από την τιμή κατωφλίου του 0.05, μπορούμε να απορρίψουμε τη μηδενική υπόθεση ότι η διαφορά μεταξύ των μέσων τιμών του δείγματος 1 και του δείγματος 2 είναι σημαντική. Αυτό δείχνει ότι τα μήκη σέπαλ για το δείγμα 1 και το δείγμα 2 αντλήθηκαν από τα ίδια δεδομένα πληθυσμού.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Υπολογίστε τη μέση τιμή του δείγματος και τις διακυμάνσεις του δείγματος
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Εφαρμογή t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
Παραγωγή
stats.ttest_ind(a_1, b_1, equal_var = False)Παρατηρήσεις
Παρατηρούμε ότι η χρήση δειγμάτων με άνισο μέγεθος δεν αλλάζει σημαντικά τη στατιστική t και την τιμή p.
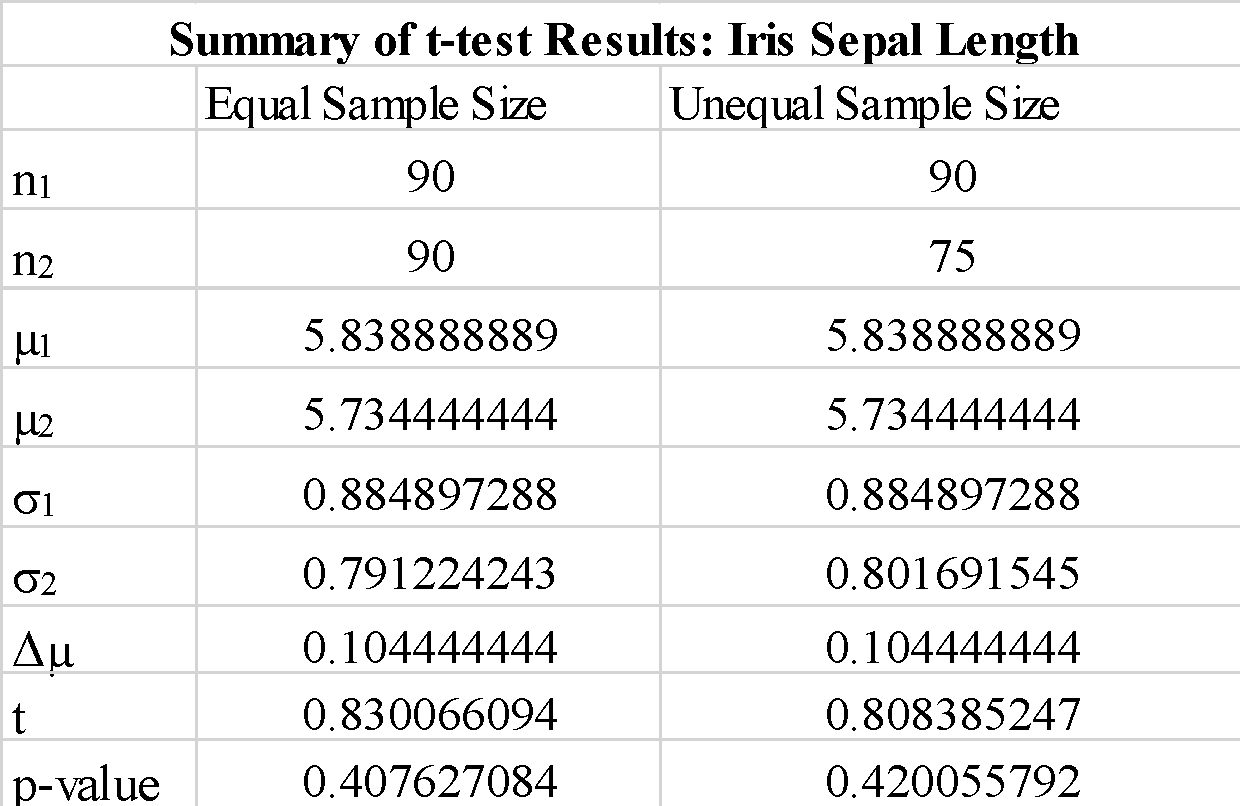
Συνοπτικά, δείξαμε πώς θα μπορούσε να εφαρμοστεί ένα απλό t-test χρησιμοποιώντας τη βιβλιοθήκη scipy στην python.
Benjamin O. Tayo είναι Φυσικός, Εκπαιδευτής Επιστήμης Δεδομένων και Συγγραφέας, καθώς και Ιδιοκτήτης του DataScienceHub. Προηγουμένως, ο Benjamin δίδασκε Μηχανική και Φυσική στο U. of Central Oklahoma, Grand Canyon U. και Pittsburgh State U.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Αποδέχομαι
- προηγμένες
- κατά
- και
- εφαρμοσμένος
- βασικός
- Βενιαμίν
- μεταξύ
- υπολογίζεται
- κεντρικός
- ευκαιρία
- αλλαγή
- χαρακτηριστικά
- επιλέγονται
- θεωρώντας
- θα μπορούσε να
- ημερομηνία
- επιστημονικά δεδομένα
- σύνολα δεδομένων
- Προσδιορίστε
- διαφορά
- διαφορετικές
- που
- Μηχανική
- απόδειξη
- παράδειγμα
- αναμένεται
- λουλούδι
- Εξής
- εξής
- από
- Πως
- HTTPS
- εφαρμοστεί
- εισαγωγή
- in
- περιλαμβάνουν
- ανεξάρτητος
- υποδηλώνει
- KDnuggets
- μεγαλύτερος
- Βιβλιοθήκη
- matplotlib
- μέσα
- περισσότερο
- πλέον
- απαραίτητος
- αρνητικός
- πολλοί
- παρατηρούμε
- την απόκτηση
- συνέβη
- Οκλαχόμα
- τάξη
- ΑΛΛΑ
- ιδιοκτήτης
- παράμετρος
- παράμετροι
- εκτέλεση
- Φυσική
- Πίτσμπουργκ
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- πληθυσμός
- πληθυσμών
- προηγουμένως
- πιθανότητα
- Python
- αξιόπιστος
- Αποτελέσματα
- Επιστροφές
- ίδιο
- Επιστήμη
- δείχνουν
- παρουσιάζεται
- Δείχνει
- σημαντικός
- σημαντικά
- παρόμοιες
- Απλούς
- αφού
- Μέγεθος
- μεγέθη
- μικρότερος
- So
- Κατάσταση
- στατιστικός
- stats
- ΠΕΡΙΛΗΨΗ
- Διδασκαλία
- δοκιμή
- Η
- επομένως
- κατώφλι
- προς την
- αληθής
- φροντιστήριο
- χρήση
- αξία
- εκδοχή
- αν
- Ποιό
- θα
- συγγραφέας
- αποδόσεις
- zephyrnet





