Εικόνα από συγγραφέα
When you are getting started with machine learning, logistic regression is one of the first algorithms you’ll add to your toolbox. It’s a simple and robust algorithm, commonly used for binary classification tasks.
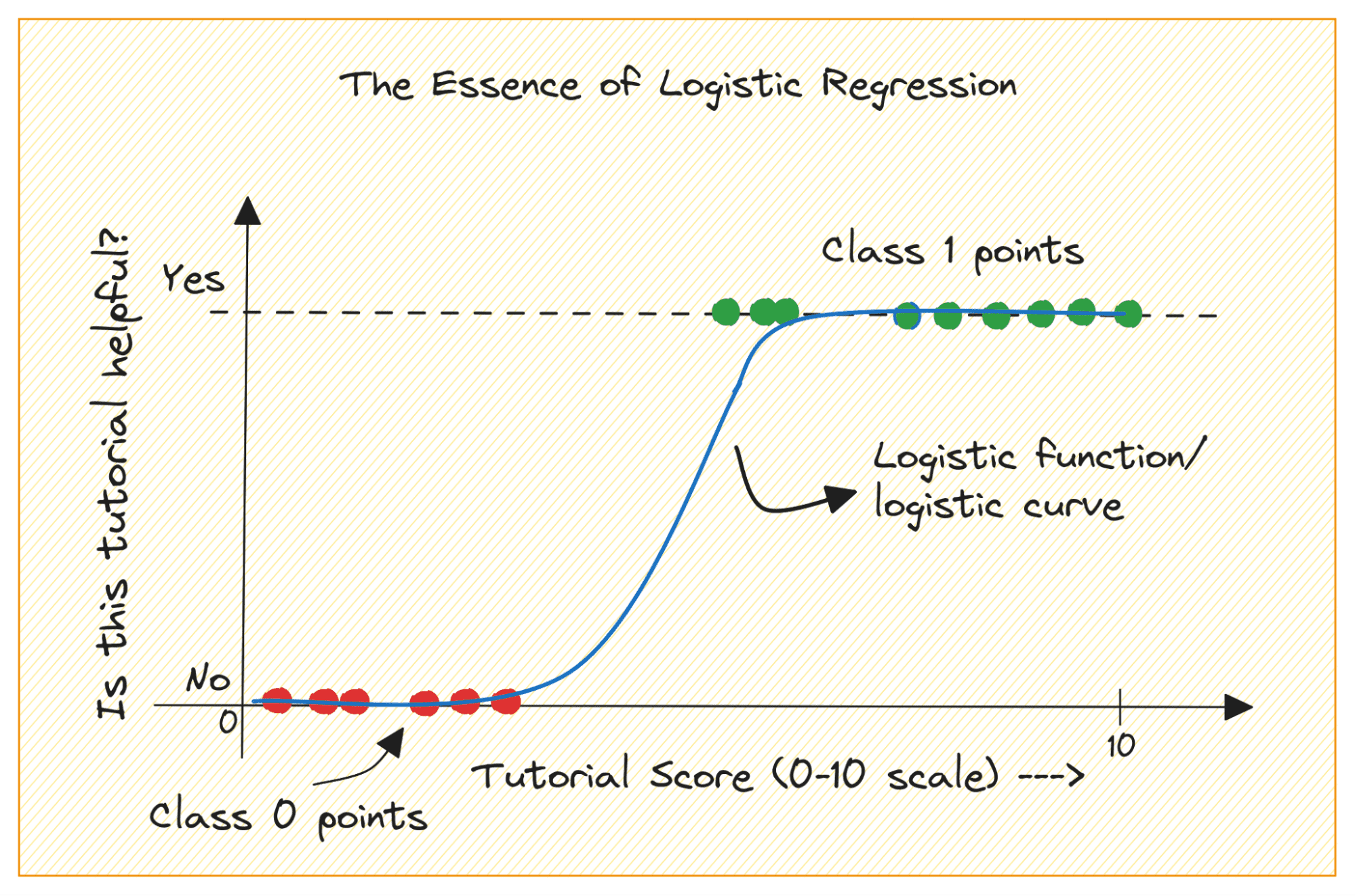
Εξετάστε ένα πρόβλημα δυαδικής ταξινόμησης με τις κλάσεις 0 και 1. Η λογιστική παλινδρόμηση ταιριάζει με μια λογιστική ή σιγμοειδή συνάρτηση στα δεδομένα εισόδου και προβλέπει την πιθανότητα ενός σημείου δεδομένων ερωτήματος που ανήκει στην κλάση 1. Ενδιαφέρον, ναι;
Σε αυτό το σεμινάριο, θα μάθουμε για την λογιστική παλινδρόμηση από την αρχή, καλύπτοντας:
- Η λογιστική (ή σιγμοειδής) συνάρτηση
- Πώς κινούμαστε από τη γραμμική στην λογιστική παλινδρόμηση
- Πώς λειτουργεί η λογιστική παλινδρόμηση
Τέλος, θα δημιουργήσουμε ένα απλό μοντέλο λογιστικής παλινδρόμησης ταξινομούν τις επιστροφές RADAR από την ιονόσφαιρα.
Before we learn more about logistic regression, let’s review how the logistic function works. The logistic (or sigmoid function) is given by:

Όταν σχεδιάζετε τη συνάρτηση σιγμοειδούς, θα μοιάζει με αυτό:
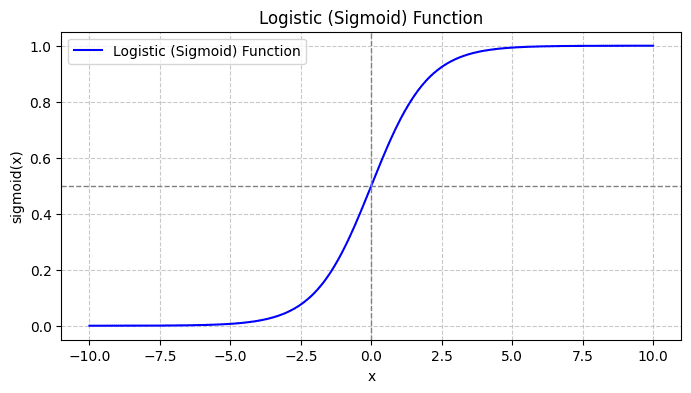
Από την πλοκή βλέπουμε ότι:
- Όταν x = 0, το σ(x) παίρνει μια τιμή 0.5.
- Όταν το x πλησιάζει το +∞, το σ(x) πλησιάζει το 1.
- Όταν το x πλησιάζει το -∞, το σ(x) πλησιάζει το 0.
Έτσι, για όλες τις πραγματικές εισόδους, η σιγμοειδής συνάρτηση τις συμπιέζει για να λάβουν τιμές στην περιοχή [0, 1].
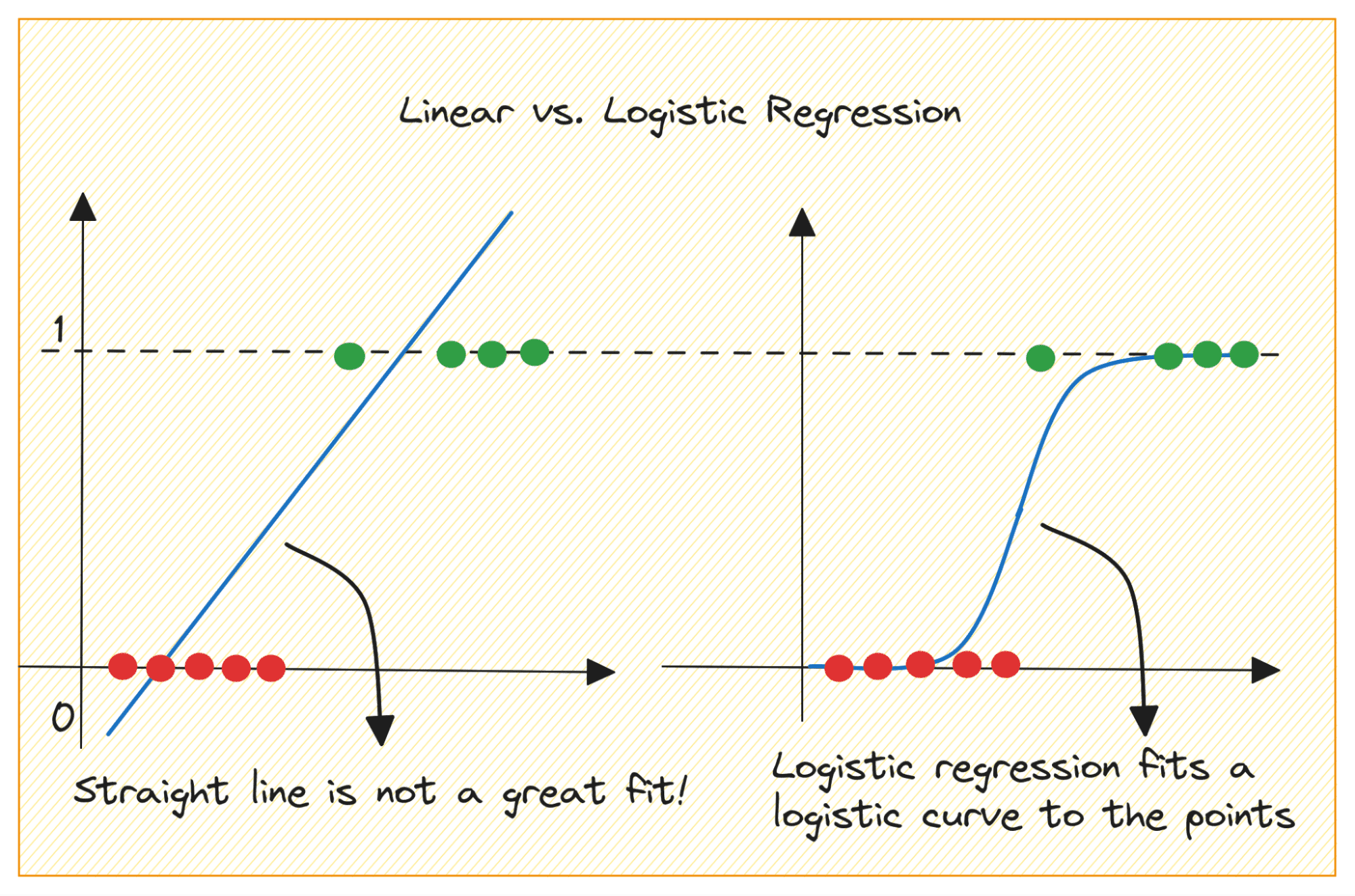
Let’s first discuss why we cannot use linear regression for a binary classification problem.
Σε ένα πρόβλημα δυαδικής ταξινόμησης, η έξοδος είναι κατηγορική ετικέτα (0 ή 1). Επειδή η γραμμική παλινδρόμηση προβλέπει εξόδους συνεχούς αξίας που μπορεί να είναι μικρότερες από 0 ή μεγαλύτερες από 1, δεν έχει νόημα για το πρόβλημα.
Επίσης, μια ευθεία γραμμή μπορεί να μην ταιριάζει καλύτερα όταν οι ετικέτες εξόδου ανήκουν σε μία από τις δύο κατηγορίες.
Εικόνα από συγγραφέα
Πώς λοιπόν περνάμε από τη γραμμική στην λογιστική παλινδρόμηση; Στη γραμμική παλινδρόμηση η προβλεπόμενη έξοδος δίνεται από:
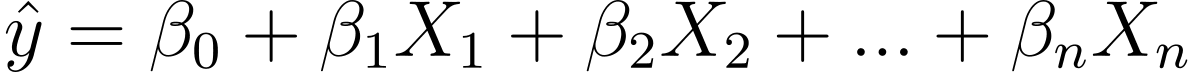
Όπου τα β είναι οι συντελεστές και X_is οι προβλέψεις (ή χαρακτηριστικά).
Χωρίς απώλεια γενικότητας, ας υποθέσουμε X_0 = 1:

Μπορούμε λοιπόν να έχουμε μια πιο συνοπτική έκφραση:
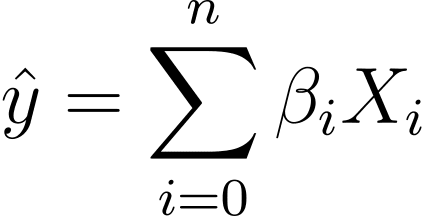
Στην λογιστική παλινδρόμηση, χρειαζόμαστε την προβλεπόμενη πιθανότητα p_i στο διάστημα [0,1]. Γνωρίζουμε ότι η λογιστική συνάρτηση συμπιέζει τις εισόδους έτσι ώστε να λαμβάνουν τιμές στο διάστημα [0,1].
Συνδέοντας λοιπόν αυτήν την έκφραση στην λογιστική συνάρτηση, έχουμε την προβλεπόμενη πιθανότητα ως:
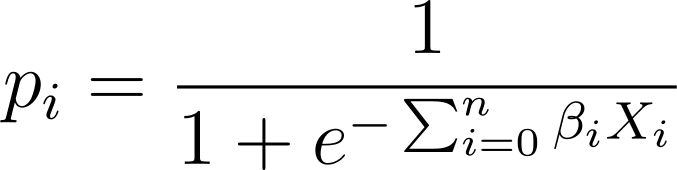
Πώς λοιπόν βρίσκουμε την καλύτερη προσαρμογή λογιστικής καμπύλης για το δεδομένο σύνολο δεδομένων; Για να απαντήσουμε σε αυτό, ας κατανοήσουμε την εκτίμηση μέγιστης πιθανότητας.
Εκτίμηση μέγιστης πιθανότητας (MLE) is used to estimate the parameters of the logistic regression model by maximizing the likelihood function. Let’s break down the process of MLE in logistic regression and how the cost function is formulated for optimization using gradient descent.
Ανάλυση της εκτίμησης μέγιστης πιθανότητας
Όπως συζητήθηκε, μοντελοποιούμε την πιθανότητα να συμβεί ένα δυαδικό αποτέλεσμα ως συνάρτηση μιας ή περισσότερων μεταβλητών (ή χαρακτηριστικών) πρόβλεψης:
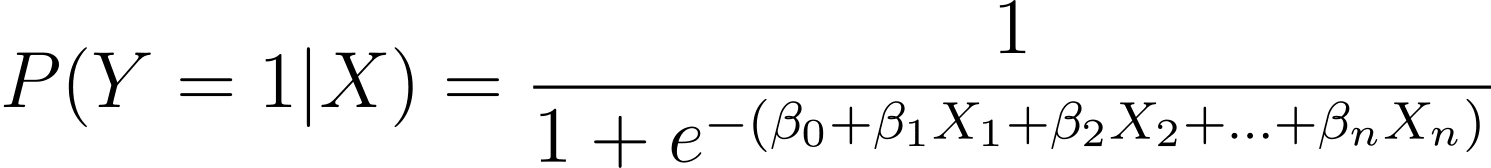
Here, the βs are the model parameters or coefficients. X_1, X_2,…, X_n are the predictor variables.
Το MLE στοχεύει να βρει τις τιμές του β που μεγιστοποιούν την πιθανότητα των παρατηρούμενων δεδομένων. Η συνάρτηση πιθανότητας, που συμβολίζεται ως L(β), αντιπροσωπεύει την πιθανότητα παρατήρησης των δεδομένων αποτελεσμάτων για τις δεδομένες τιμές πρόβλεψης στο μοντέλο λογιστικής παλινδρόμησης.
Διατύπωση της συνάρτησης Log-Likelihood
To simplify the optimization process, it’s common to work with the log-likelihood function. Because it transforms products of probabilities into sums of log probabilities.
Η συνάρτηση log-likelihood για λογιστική παλινδρόμηση δίνεται από:
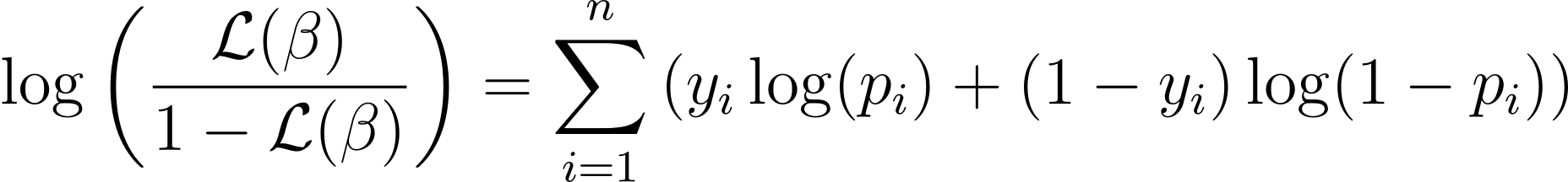
Now that we know the essence of log-likelihood, let’s proceed to formulate the cost function for logistic regression and subsequently gradient descent for finding the best model parameters
Συνάρτηση κόστους για λογιστική παλινδρόμηση
Για να βελτιστοποιήσουμε το μοντέλο λογιστικής παλινδρόμησης, πρέπει να μεγιστοποιήσουμε την πιθανότητα καταγραφής. Έτσι, μπορούμε να χρησιμοποιήσουμε την αρνητική πιθανότητα καταγραφής ως συνάρτηση κόστους για την ελαχιστοποίηση κατά τη διάρκεια της προπόνησης. Η αρνητική πιθανότητα καταγραφής, που συχνά αναφέρεται ως απώλεια υλικοτεχνικής υποστήριξης, ορίζεται ως:
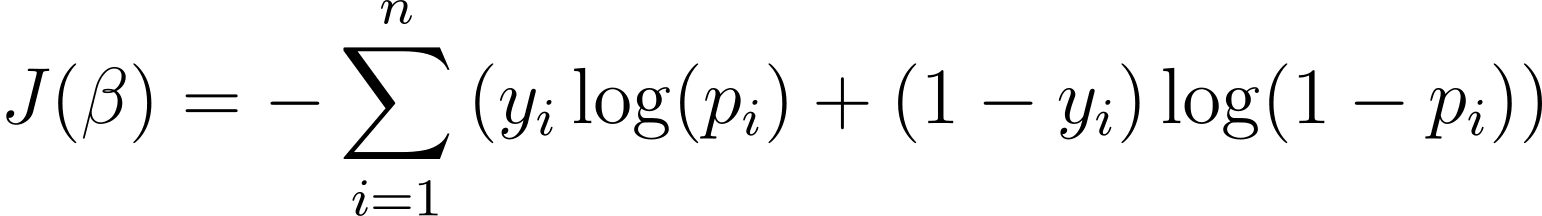
Ο στόχος του αλγορίθμου μάθησης, λοιπόν, είναι να βρει τις τιμές του ? που ελαχιστοποιούν αυτή τη συνάρτηση κόστους. Το Gradient Descent είναι ένας ευρέως χρησιμοποιούμενος αλγόριθμος βελτιστοποίησης για την εύρεση του ελάχιστου αυτής της συνάρτησης κόστους.
Gradient Descent σε Logistic Regression
Διαβάθμιση κλίσης είναι ένας επαναληπτικός αλγόριθμος βελτιστοποίησης που ενημερώνει τις παραμέτρους του μοντέλου β στην αντίθετη κατεύθυνση της κλίσης της συνάρτησης κόστους σε σχέση με το β. Ο κανόνας ενημέρωσης στο βήμα t+1 για λογιστική παλινδρόμηση με χρήση gradient descent είναι ο εξής:
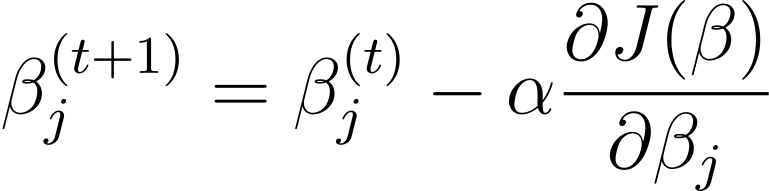
Όπου α είναι ο ρυθμός μάθησης.
Οι μερικές παράγωγοι μπορούν να υπολογιστούν χρησιμοποιώντας τον κανόνα της αλυσίδας. Το Gradient descent ενημερώνει επαναληπτικά τις παραμέτρους —μέχρι τη σύγκλιση— με στόχο την ελαχιστοποίηση της λογιστικής απώλειας. Καθώς συγκλίνει, βρίσκει τις βέλτιστες τιμές του β που μεγιστοποιούν την πιθανότητα των παρατηρούμενων δεδομένων.
Τώρα που ξέρετε πώς λειτουργεί η λογιστική παλινδρόμηση, ας δημιουργήσουμε ένα μοντέλο πρόβλεψης χρησιμοποιώντας τη βιβλιοθήκη scikit-learn.
Θα χρησιμοποιήσουμε το σύνολο δεδομένων ιονόσφαιρας από το αποθετήριο μηχανικής μάθησης UCI για αυτό το σεμινάριο. Το σύνολο δεδομένων περιλαμβάνει 34 αριθμητικά χαρακτηριστικά. Η έξοδος είναι δυαδική, μία από τις «καλές» ή τις «κακές» (σημειώνεται με «g» ή «b»). Η ετικέτα εξόδου «καλή» αναφέρεται σε επιστροφές RADAR που έχουν ανιχνεύσει κάποια δομή στην ιονόσφαιρα.
Βήμα 1 – Φόρτωση του συνόλου δεδομένων
Πρώτα, κατεβάστε το σύνολο δεδομένων και διαβάστε το σε ένα πλαίσιο δεδομένων pandas:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Βήμα 2 – Εξερεύνηση του συνόλου δεδομένων
Let’s take a look at the first few rows of the dataframe:
# Display the first few rows of the DataFrame
df.head()
Περικομμένη έξοδος df.head()
Let’s get some information about the dataset: the number of non-null values and the data types of each of the columns:
# Get information about the dataset
print(df.info())
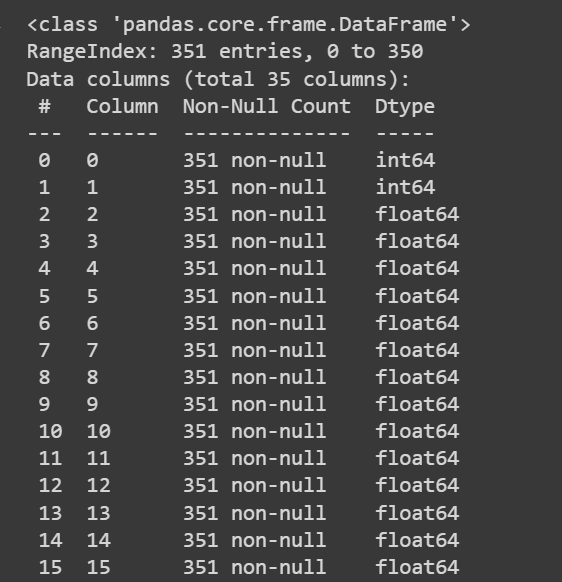 Περικομμένη έξοδος του df.info()
Περικομμένη έξοδος του df.info()
Επειδή έχουμε όλα τα αριθμητικά χαρακτηριστικά, μπορούμε επίσης να λάβουμε ορισμένα περιγραφικά στατιστικά στοιχεία χρησιμοποιώντας το describe() μέθοδος στο πλαίσιο δεδομένων:
# Get descriptive statistics of the dataset
print(df.describe())
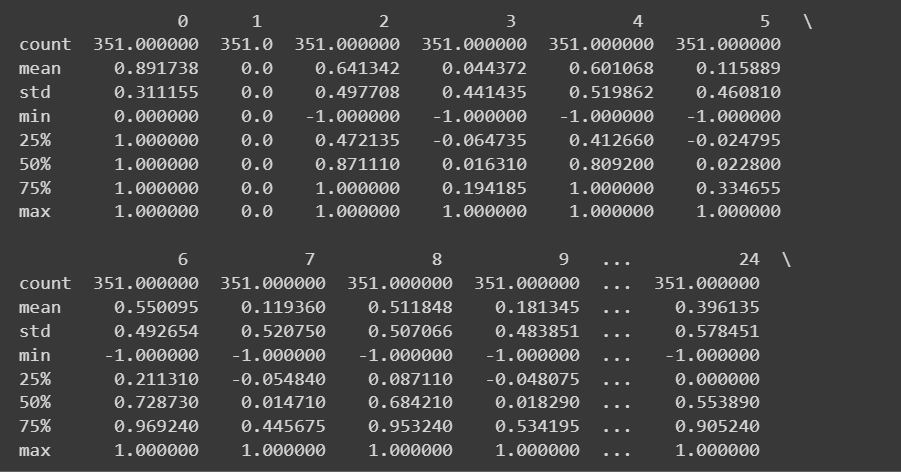
Περικομμένη έξοδος της df.describe()
Τα ονόματα στηλών είναι προς το παρόν από 0 έως 34—συμπεριλαμβανομένης της ετικέτας. Επειδή το σύνολο δεδομένων δεν παρέχει περιγραφικά ονόματα για τις στήλες, απλώς τις αναφέρει ως χαρακτηριστικό_1 στο χαρακτηριστικό_34, εάν θέλετε να μετονομάσετε τις στήλες του πλαισίου δεδομένων όπως φαίνεται:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Σημείωση: Αυτό το βήμα είναι καθαρά προαιρετικό. Μπορείτε να προχωρήσετε με τα προεπιλεγμένα ονόματα στηλών εάν προτιμάτε.
# Display the first few rows of the DataFrame
df.head()
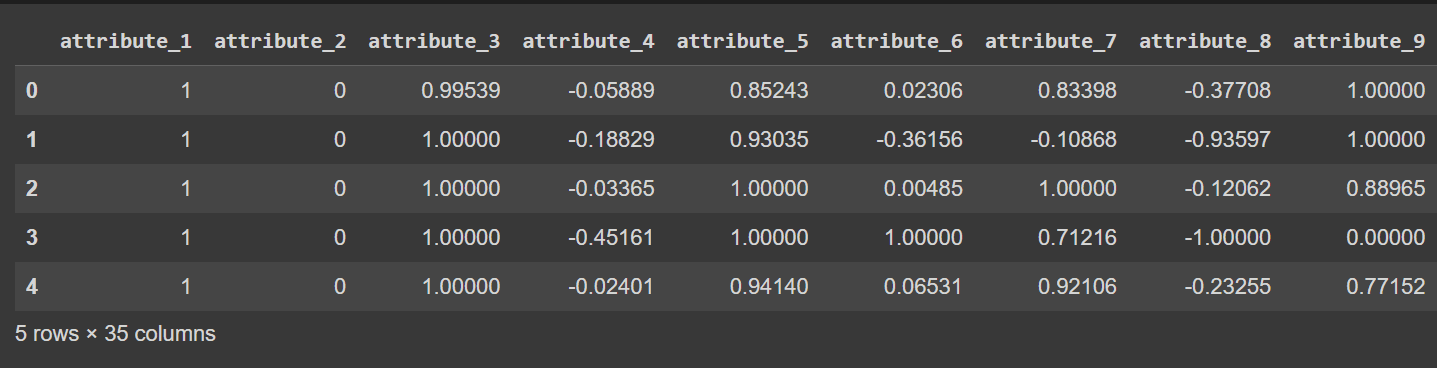
Περικομμένη έξοδος df.head() [Μετά τη μετονομασία στηλών]
Βήμα 3 – Μετονομασία ετικετών τάξης και οπτικοποίηση της διανομής κλάσεων
Επειδή οι ετικέτες κλάσης εξόδου είναι 'g' και 'b', πρέπει να τις αντιστοιχίσουμε στο 1 και 0, αντίστοιχα. Μπορείτε να το κάνετε χρησιμοποιώντας map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Ας δούμε επίσης την κατανομή των ετικετών κλάσεων:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
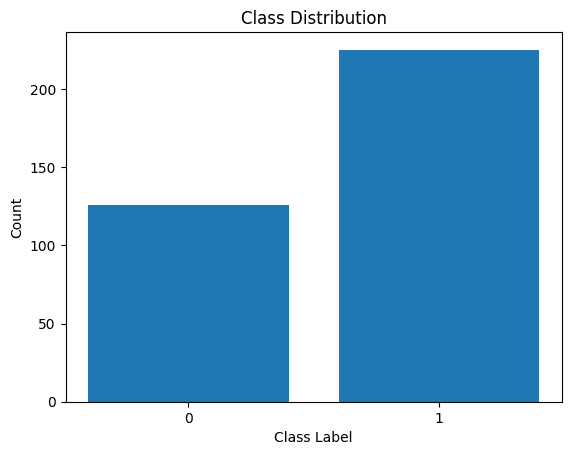
Διανομή Ετικετών Τάξης
Βλέπουμε ότι υπάρχει ανισορροπία στην κατανομή. Υπάρχουν περισσότερες εγγραφές που ανήκουν στην κλάση 1 παρά στην κλάση 0. Θα χειριστούμε αυτήν την ανισορροπία κλάσης κατά τη δημιουργία του μοντέλου λογιστικής παλινδρόμησης.
Βήμα 5 – Προεπεξεργασία του συνόλου δεδομένων
Ας συλλέξουμε τα χαρακτηριστικά και τις ετικέτες εξόδου ως εξής:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Αφού διαιρέσουμε το σύνολο δεδομένων στα σύνολα αμαξοστοιχίας και δοκιμών, πρέπει να επεξεργαστούμε εκ των προτέρων το σύνολο δεδομένων.
Όταν υπάρχουν πολλά αριθμητικά χαρακτηριστικά - το καθένα σε δυνητικά διαφορετική κλίμακα - πρέπει να προεπεξεργαζόμαστε τα αριθμητικά χαρακτηριστικά. Μια κοινή μέθοδος είναι ο μετασχηματισμός τους έτσι ώστε να ακολουθούν μια κατανομή με μηδενικό μέσο όρο και μοναδιαία διακύμανση.
Η StandardScaler από τη μονάδα προεπεξεργασίας του scikit-learn μας βοηθά να το πετύχουμε αυτό.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Βήμα 6 – Δημιουργία μοντέλου λογιστικής παλινδρόμησης
Τώρα μπορούμε να δημιουργήσουμε έναν ταξινομητή λογιστικής παλινδρόμησης. ο LogisticRegression Η τάξη είναι μέρος της ενότητας linear_model του scikit-learn.
Παρατηρήστε ότι έχουμε ορίσει το class_weight παράμετρος σε «ισορροπημένο». Αυτό θα μας βοηθήσει να υπολογίσουμε την ανισορροπία της τάξης. Με την ανάθεση βαρών σε κάθε τάξη—αντίστροφα ανάλογη με τον αριθμό των εγγραφών στις κλάσεις.
Αφού δημιουργήσουμε την κλάση, μπορούμε να προσαρμόσουμε το μοντέλο στο σύνολο δεδομένων εκπαίδευσης:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Βήμα 7 – Αξιολόγηση του Μοντέλου Logistic Regression
Μπορείτε να καλέσετε το predict() μέθοδος λήψης των προβλέψεων του μοντέλου.
Εκτός από τη βαθμολογία ακρίβειας, μπορούμε επίσης να λάβουμε μια αναφορά ταξινόμησης με μετρήσεις όπως η ακρίβεια, η ανάκληση και η βαθμολογία F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
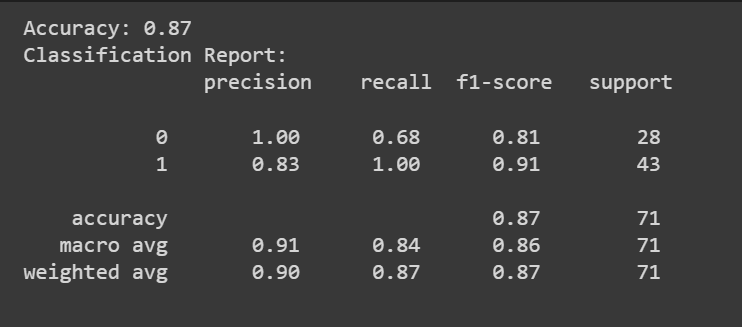
Συγχαρητήρια, έχετε κωδικοποιήσει το πρώτο σας μοντέλο λογιστικής παλινδρόμησης!
Σε αυτό το σεμινάριο, μάθαμε λεπτομερώς για την λογιστική παλινδρόμηση: από τη θεωρία και τα μαθηματικά μέχρι την κωδικοποίηση ενός ταξινομητή λογιστικής παλινδρόμησης.
Ως επόμενο βήμα, δοκιμάστε να δημιουργήσετε ένα μοντέλο λογιστικής παλινδρόμησης για ένα κατάλληλο σύνολο δεδομένων της επιλογής σας.
Το σύνολο δεδομένων Ionosphere αδειοδοτείται βάσει α Creative Commons Attribution 4.0 International (CC BY 4.0) άδεια:
Sigillito, V., Wing, S., Hutton, L., and Baker, Κ.. (1989). Ιονόσφαιρα. UCI Machine Learning Repository. https://doi.org/10.24432/C5W01B.
Bala Priya C είναι προγραμματιστής και τεχνικός συγγραφέας από την Ινδία. Της αρέσει να εργάζεται στη διασταύρωση των μαθηματικών, του προγραμματισμού, της επιστήμης δεδομένων και της δημιουργίας περιεχομένου. Οι τομείς ενδιαφέροντος και εξειδίκευσής της περιλαμβάνουν τα DevOps, την επιστήμη δεδομένων και την επεξεργασία φυσικής γλώσσας. Της αρέσει να διαβάζει, να γράφει, να κωδικοποιεί και τον καφέ! Επί του παρόντος, εργάζεται για να μάθει και να μοιράζεται τις γνώσεις της με την κοινότητα προγραμματιστών, γράφοντας σεμινάρια, οδηγούς με οδηγίες, απόψεις και πολλά άλλα.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :είναι
- :δεν
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- Σχετικα
- Λογαριασμός
- ακρίβεια
- Κατορθώνω
- προσθέτω
- Επιπλέον
- Μετά το
- στόχοι
- αλγόριθμος
- αλγόριθμοι
- Όλα
- Επίσης
- an
- και
- απάντηση
- προσεγγίσεις
- ΕΙΝΑΙ
- περιοχές
- AS
- υποθέτω
- At
- συγγραφικός
- b
- αρτοποιός
- ισορροπημένη
- μπαρ
- BE
- επειδή
- ανήκουν
- ΚΑΛΎΤΕΡΟΣ
- Διακοπή
- χτίζω
- Κτίριο
- by
- κλήση
- CAN
- δεν μπορώ
- κατηγορίες
- αλυσίδα
- επιλογή
- τάξη
- τάξεις
- ταξινόμηση
- κωδικοποιημένο
- Κωδικοποίηση
- συλλέγουν
- Στήλη
- Στήλες
- Κοινός
- συνήθως
- Κοινά
- κοινότητα
- περιλαμβάνει
- συνοπτικός
- περιεχόμενο
- δημιουργία περιεχομένου
- μετατρέψετε
- Κόστος
- κάλυμμα
- δημιουργία
- δημιουργία
- Τη στιγμή
- καμπύλη
- ημερομηνία
- σημεία δεδομένων
- επιστημονικά δεδομένα
- σύνολο δεδομένων
- Προεπιλογή
- ορίζεται
- Παράγωγα
- λεπτομέρεια
- εντοπιστεί
- Εργολάβος
- DevOps
- διαφορετικές
- κατεύθυνση
- συζητήσουν
- συζήτηση
- Display
- διανομή
- do
- κάνει
- κάτω
- κατεβάσετε
- κατά την διάρκεια
- κάθε
- ουσία
- εκτίμηση
- αξιολογώντας
- εξειδίκευση
- Εξερευνώντας
- έκφραση
- Χαρακτηριστικά
- λίγοι
- Εύρεση
- εύρεση
- ευρήματα
- Όνομα
- ταιριάζουν
- ακολουθήστε
- εξής
- Για
- ΠΛΑΙΣΙΟ
- από
- λειτουργία
- παίρνω
- να πάρει
- δεδομένου
- Go
- γκολ
- μεγαλύτερη
- Έδαφος
- Οδηγοί
- χέρι
- λαβή
- Έχω
- βοήθεια
- βοηθά
- αυτήν
- Πως
- HTTPS
- ICS
- if
- ανισορροπία
- εισαγωγή
- in
- περιλαμβάνουν
- ευρετήριο
- Ινδία
- Δείκτες
- πληροφορίες
- εισαγωγή
- είσοδοι
- τόκος
- ενδιαφέρον
- διασταύρωση
- σε
- IT
- μόλις
- KDnuggets
- Ξέρω
- γνώση
- επιγραφή
- Ετικέτες
- Γλώσσα
- ΜΑΘΑΊΝΩ
- μάθει
- μάθηση
- μείον
- ας
- Βιβλιοθήκη
- Άδεια
- Άδεια
- Μου αρέσει
- πιθανότητα
- συμπαθεί
- γραμμή
- φόρτωση
- κούτσουρο
- ματιά
- μοιάζει
- off
- μηχανή
- μάθηση μηχανής
- κάνω
- πολοί
- χάρτη
- μαθηματικά
- matplotlib
- Αυξάνω στον ανώτατο βαθμό
- μεγιστοποιώντας
- ανώτατο όριο
- Ενδέχεται..
- εννοώ
- μέθοδος
- Metrics
- ελαχιστοποίηση
- ελάχιστο
- μοντέλο
- μοντέλα
- ενότητα
- περισσότερο
- μετακινήσετε
- ονόματα
- Φυσικό
- Φυσική γλώσσα
- Επεξεργασία φυσικής γλώσσας
- Ανάγκη
- αρνητικός
- επόμενη
- αριθμός
- παρατηρούμενη
- of
- συχνά
- on
- ONE
- Γνώμη
- απέναντι
- βέλτιστη
- βελτιστοποίηση
- Βελτιστοποίηση
- or
- Αποτέλεσμα
- αποτελέσματα
- παραγωγή
- εξόδους
- Πάντα
- παράμετρος
- παράμετροι
- μέρος
- κομμάτια
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- Σημείο
- σημεία
- ενδεχομένως
- Ακρίβεια
- προβλεπόμενη
- Προβλέψεις
- προφητικός
- Predictor
- Προβλέπει
- προτιμώ
- πιθανότητα
- Πρόβλημα
- προχωρήσει
- διαδικασια μας
- μεταποίηση
- Προϊόντα
- Προγραμματισμός
- παρέχουν
- καθαρώς
- Python
- ραντάρ
- σειρά
- Τιμή
- Διάβασε
- Ανάγνωση
- πραγματικός
- αρχεία
- αναφέρεται
- αναφέρεται
- οπισθοδρόμηση
- αναφέρουν
- Αποθήκη
- αντιπροσωπεύει
- ζητήσει
- σεβασμός
- αντίστοιχα
- Επιστροφές
- ανασκόπηση
- εύρωστος
- Άρθρο
- s
- Επιστήμη
- scikit-μάθετε
- σκορ
- δείτε
- αίσθηση
- σειρά
- Σέτς
- μοιράζονται
- αυτή
- παρουσιάζεται
- Απλούς
- απλοποίηση
- So
- μερικοί
- διαίρεση
- ξεκίνησε
- στατιστική
- Βήμα
- ευθεία
- δομή
- Ακολούθως
- τέτοιος
- κατάλληλος
- ποσά
- Πάρτε
- παίρνει
- στόχος
- εργασίες
- Τεχνικός
- δοκιμή
- Δοκιμές
- από
- ότι
- Η
- Τους
- θεωρία
- Εκεί.
- επομένως
- αυτοί
- αυτό
- Μέσω
- προς την
- Εργαλειοθήκη
- Τρένο
- εκπαιδευμένο
- Εκπαίδευση
- Μεταμορφώστε
- μετασχηματισμών
- προσπαθώ
- φροντιστήριο
- tutorials
- δύο
- τύποι
- υπό
- καταλαβαίνω
- μονάδα
- Ενημέρωση
- ενημερώσεις
- URL
- us
- λογαριασμός ΗΠΑ
- χρήση
- μεταχειρισμένος
- χρησιμοποιώντας
- αξία
- Αξίες
- φαντάζομαι
- we
- πότε
- Ποιό
- WHY
- Wikipedia
- θα
- Πτέρυγα
- με
- Εργασία
- εργαζόμενος
- λειτουργεί
- θα
- συγγραφέας
- γραφή
- X
- Ναί
- εσείς
- Σας
- zephyrnet
- μηδέν