Αυτή είναι μια δημοσίευση επισκέπτη που συνυπογράφουν οι Taylor Names, Staff Machine Learning Engineer, Dev Gupta, Machine Learning Manager και Argie Angeleas, Senior Product Manager στην Ibotta. Η Ibotta είναι μια αμερικανική εταιρεία τεχνολογίας που επιτρέπει στους χρήστες με τις εφαρμογές της για επιτραπέζιους υπολογιστές και για κινητά να κερδίζουν επιστροφή μετρητών σε αγορές εντός καταστήματος, εφαρμογών για κινητά και ηλεκτρονικές αγορές με υποβολή απόδειξης, συνδεδεμένους λογαριασμούς επιβράβευσης πωλητών λιανικής, πληρωμές και επαλήθευση αγορών.
Η Ibotta προσπαθεί να προτείνει εξατομικευμένες προσφορές για να διατηρεί και να προσελκύει καλύτερα τους χρήστες της. Ωστόσο, οι προσφορές και οι προτιμήσεις των χρηστών εξελίσσονται συνεχώς. Αυτό το συνεχώς μεταβαλλόμενο περιβάλλον με πολλούς νέους χρήστες και νέες προωθήσεις είναι ένα τυπικό πρόβλημα ψυχρής εκκίνησης—δεν υπάρχει επαρκής αλληλεπίδραση ιστορικού χρήστη και προώθησης για να εξαχθούν συμπεράσματα. Η ενισχυτική μάθηση (RL) είναι ένας τομέας μηχανικής μάθησης (ML) που ασχολείται με τον τρόπο με τον οποίο οι ευφυείς πράκτορες πρέπει να αναλαμβάνουν δράση σε ένα περιβάλλον προκειμένου να μεγιστοποιήσουν την έννοια των σωρευτικών ανταμοιβών. Το RL εστιάζει στην εξεύρεση ισορροπίας μεταξύ της εξερεύνησης αχαρτογράφητης περιοχής και της εκμετάλλευσης της τρέχουσας γνώσης. Το multi-armed bandit (MAB) είναι ένα κλασικό πρόβλημα μάθησης ενίσχυσης που αποτελεί παράδειγμα της ανταλλαγής εξερεύνησης/εκμετάλλευσης: μεγιστοποίηση της ανταμοιβής βραχυπρόθεσμα (εκμετάλλευση) ενώ θυσιάζεται η βραχυπρόθεσμη ανταμοιβή για γνώση που μπορεί να αυξήσει τις ανταμοιβές μακροπρόθεσμα (εξερεύνηση ). Ένας αλγόριθμος MAB εξερευνά και εκμεταλλεύεται τις βέλτιστες συστάσεις για τον χρήστη.
Ο Ibotta συνεργάστηκε με την Εργαστήριο Amazon Machine Learning Solutions να χρησιμοποιήσετε αλγόριθμους MAB για να αυξήσετε την αφοσίωση των χρηστών όταν οι πληροφορίες χρήστη και προώθησης είναι εξαιρετικά δυναμικές.
Επιλέξαμε έναν αλγόριθμο MAB με βάση τα συμφραζόμενα επειδή είναι αποτελεσματικός στις ακόλουθες περιπτώσεις χρήσης:
- Δημιουργία εξατομικευμένων προτάσεων ανάλογα με την κατάσταση των χρηστών (πλαίσιο)
- Αντιμετώπιση πτυχών ψυχρής εκκίνησης, όπως νέα μπόνους και νέοι πελάτες
- Συμβατές προτάσεις όπου οι προτιμήσεις των χρηστών αλλάζουν με την πάροδο του χρόνου
ημερομηνία
Για να αυξήσει τις εξαργυρώσεις μπόνους, η Ibotta επιθυμεί να στέλνει εξατομικευμένα μπόνους στους πελάτες. Τα μπόνους είναι τα αυτοχρηματοδοτούμενα κίνητρα μετρητών της Ibotta, τα οποία χρησιμεύουν ως οι ενέργειες του μοντέλου των ληστών πολλαπλών όπλων.
Το μοντέλο bandit χρησιμοποιεί δύο σετ χαρακτηριστικών:
- Χαρακτηριστικά δράσης – Αυτά περιγράφουν τις ενέργειες, όπως τον τύπο του μπόνους και το μέσο ποσό του μπόνους
- Χαρακτηριστικά πελατών – Αυτά περιγράφουν τις ιστορικές προτιμήσεις και τις αλληλεπιδράσεις των πελατών, όπως εξαργυρώσεις, κλικ και προβολές προηγούμενων εβδομάδων
Τα συμφραζόμενα χαρακτηριστικά προέρχονται από ιστορικά ταξίδια πελατών, τα οποία περιείχαν 26 εβδομαδιαίες μετρήσεις δραστηριότητας που δημιουργήθηκαν από τις αλληλεπιδράσεις των χρηστών με την εφαρμογή Ibotta.
Συμφραζόμενος πολύπλευρος ληστής
Το Bandit είναι ένα πλαίσιο διαδοχικής λήψης αποφάσεων στο οποίο ο υπεύθυνος λήψης αποφάσεων επιλέγει διαδοχικά μια ενέργεια, πιθανώς με βάση τις τρέχουσες πληροφορίες συμφραζομένων, και παρατηρεί ένα σήμα ανταμοιβής.
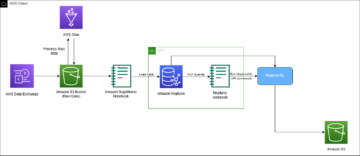
Ρυθμίσαμε τη ροή εργασίας πολλαπλών όπλων με βάση τα συμφραζόμενα Amazon Sage Maker χρησιμοποιώντας την ενσωματωμένη Vowpal Wabbit (VW) δοχείο. Το SageMaker βοηθά τους επιστήμονες δεδομένων και τους προγραμματιστές να προετοιμάσουν, να δημιουργήσουν, να εκπαιδεύσουν και να αναπτύξουν γρήγορα μοντέλα ML υψηλής ποιότητας, συγκεντρώνοντας ένα ευρύ σύνολο δυνατοτήτων που έχουν δημιουργηθεί ειδικά για την ML. Η εκπαίδευση και η δοκιμή του μοντέλου βασίζονται σε πειραματισμούς εκτός σύνδεσης. Ο ληστής μαθαίνει τις προτιμήσεις των χρηστών με βάση τα σχόλιά τους από προηγούμενες αλληλεπιδράσεις και όχι από ένα ζωντανό περιβάλλον. Ο αλγόριθμος μπορεί να μεταβεί σε λειτουργία παραγωγής, όπου το SageMaker παραμένει ως υποστηρικτική υποδομή.
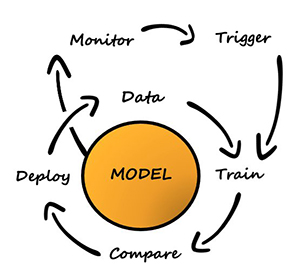
Για την εφαρμογή της στρατηγικής εξερεύνησης/εκμετάλλευσης, δημιουργήσαμε το επαναληπτικό σύστημα εκπαίδευσης και ανάπτυξης που εκτελεί τις ακόλουθες ενέργειες:
- Προτείνει μια ενέργεια χρησιμοποιώντας το μοντέλο bandit με βάση τα συμφραζόμενα με βάση το περιβάλλον χρήστη
- Καταγράφει την άρρητη ανατροφοδότηση με την πάροδο του χρόνου
- Εκπαιδεύει συνεχώς το μοντέλο με δεδομένα σταδιακής αλληλεπίδρασης
Η ροή εργασίας της εφαρμογής πελάτη είναι η εξής:
- Η εφαρμογή πελάτη επιλέγει ένα περιβάλλον, το οποίο αποστέλλεται στο τελικό σημείο του SageMaker για να ανακτήσει μια ενέργεια.
- Το τελικό σημείο του SageMaker επιστρέφει μια ενέργεια, σχετική πιθανότητα εξαργύρωσης μπόνους και
event_id. - Επειδή αυτός ο προσομοιωτής δημιουργήθηκε χρησιμοποιώντας ιστορικές αλληλεπιδράσεις, το μοντέλο γνωρίζει την πραγματική τάξη για αυτό το πλαίσιο. Εάν ο πράκτορας επιλέξει μια ενέργεια με εξαργύρωση, η ανταμοιβή είναι 1. Διαφορετικά, ο πράκτορας λαμβάνει ανταμοιβή 0.
Στην περίπτωση που υπάρχουν διαθέσιμα ιστορικά δεδομένα και είναι σε μορφή <state, action, action probability, reward>, η Ibotta μπορεί να ξεκινήσει ένα ζωντανό μοντέλο μαθαίνοντας την πολιτική εκτός σύνδεσης. Διαφορετικά, ο Ibotta μπορεί να ξεκινήσει μια τυχαία πολιτική για την 1η ημέρα και να αρχίσει να μαθαίνει μια πολιτική ληστών από εκεί.
Το παρακάτω είναι το απόσπασμα κώδικα για την εκπαίδευση του μοντέλου:
Μοντέλο απόδοσης
Διαχωρίσαμε τυχαία τις εξαργυρωμένες αλληλεπιδράσεις ως δεδομένα εκπαίδευσης (10,000 αλληλεπιδράσεις) και δεδομένα αξιολόγησης (5,300 αλληλεπιδράσεις κράτησης).
Οι μετρήσεις αξιολόγησης είναι η μέση ανταμοιβή, όπου το 1 υποδηλώνει ότι η προτεινόμενη ενέργεια εξαργυρώθηκε και το 0 σημαίνει ότι η προτεινόμενη ενέργεια δεν εξαργυρώθηκε.
Μπορούμε να προσδιορίσουμε τη μέση ανταμοιβή ως εξής:
Μέση ανταμοιβή (ποσοστό εξαργύρωσης) = (# από προτεινόμενες ενέργειες με εξαργύρωση)/(σύνολο # προτεινόμενες ενέργειες)
Ο παρακάτω πίνακας δείχνει το μέσο αποτέλεσμα ανταμοιβής:
| Μέση ανταμοιβή | Ομοιόμορφη τυχαία σύσταση | Σύσταση με βάση τα συμφραζόμενα MAB |
| Τρένο | 11.44% | 56.44% |
| Δοκιμή | 10.69% | 59.09% |
Το παρακάτω σχήμα απεικονίζει τη σταδιακή αξιολόγηση απόδοσης κατά τη διάρκεια της εκπαίδευσης, όπου ο άξονας x είναι ο αριθμός των εγγραφών που μαθαίνει το μοντέλο και ο άξονας y είναι η αυξητική μέση ανταμοιβή. Η μπλε γραμμή δείχνει τον ληστή με πολλά όπλα. η πορτοκαλί γραμμή υποδεικνύει τυχαίες συστάσεις.

Το γράφημα δείχνει ότι η προβλεπόμενη μέση ανταμοιβή αυξάνεται κατά τις επαναλήψεις και η προβλεπόμενη ανταμοιβή δράσης είναι σημαντικά μεγαλύτερη από την τυχαία ανάθεση ενεργειών.
Μπορούμε να χρησιμοποιήσουμε προηγουμένως εκπαιδευμένα μοντέλα ως θερμές εκκινήσεις και να επανεκπαιδεύσουμε κατά παρτίδες το μοντέλο με νέα δεδομένα. Σε αυτή την περίπτωση, η απόδοση του μοντέλου έχει ήδη συγκλίνει μέσω της αρχικής εκπαίδευσης. Δεν παρατηρήθηκε σημαντική πρόσθετη βελτίωση της απόδοσης σε νέα παρτίδα επανεκπαίδευσης, όπως φαίνεται στο παρακάτω σχήμα.
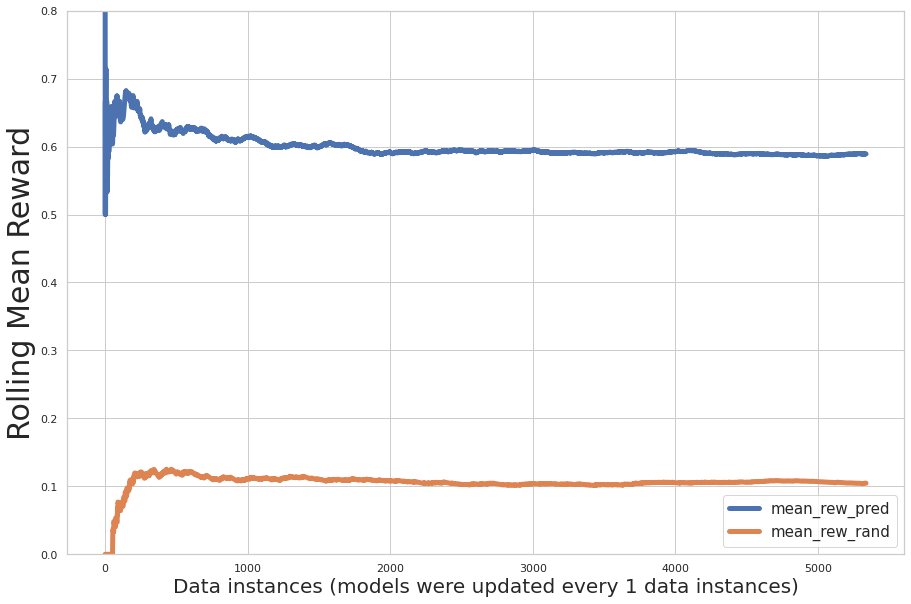
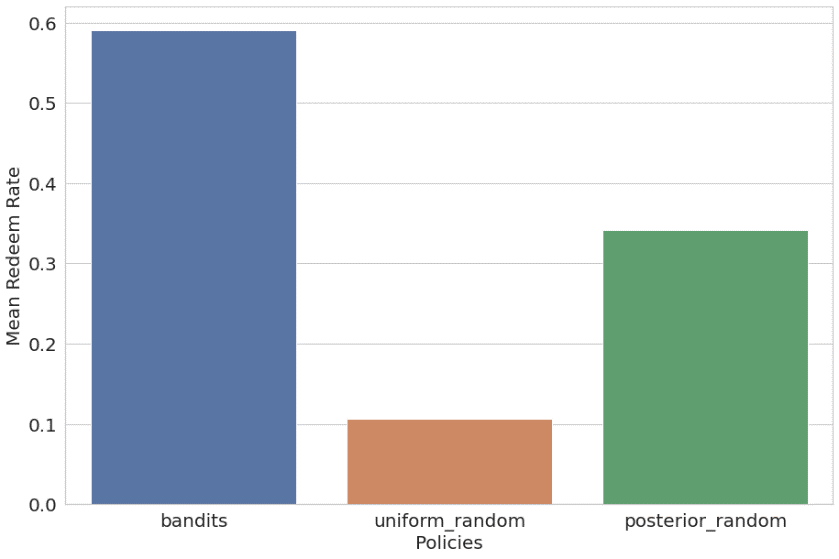
Συγκρίναμε επίσης το συμφραζόμενο bandit με ομοιόμορφα τυχαία και μεταγενέστερα τυχαία (τυχαία σύσταση χρησιμοποιώντας ιστορική κατανομή προτιμήσεων χρήστη ως θερμή εκκίνηση) πολιτικές. Τα αποτελέσματα παρατίθενται και απεικονίζονται ως εξής:
- Ληστής – 59.09% μέση ανταμοιβή (εκπαίδευση 56.44%)
- Ομοιόμορφο τυχαίο – 10.69% μέση ανταμοιβή (εκπαίδευση 11.44%)
- Πίσω πιθανότητα τυχαία – 34.21% μέση ανταμοιβή (εκπαίδευση 34.82%)
Ο αλγόριθμος ληστών πολλαπλών όπλων με βάση τα συμφραζόμενα ξεπέρασε σημαντικά τις άλλες δύο πολιτικές.
Χαρακτηριστικά
Το Amazon ML Solutions Lab συνεργάστηκε με την Ibotta για την ανάπτυξη μιας συμφραζόμενης λύσης προτάσεων εκμάθησης ενίσχυσης bandit χρησιμοποιώντας ένα κοντέινερ SageMaker RL.
Αυτή η λύση έδειξε μια σταθερή αυξητική αύξηση του ποσοστού εξαργύρωσης έναντι τυχαίων (πενταπλάσια αύξηση) και μη συμφραζομένων συστάσεων RL (δύο φορές αύξησης) βάσει μιας δοκιμής εκτός σύνδεσης. Με αυτή τη λύση, η Ibotta μπορεί να δημιουργήσει μια δυναμική μηχανή συστάσεων με επίκεντρο τον χρήστη για τη βελτιστοποίηση της αφοσίωσης των πελατών. Σε σύγκριση με την τυχαία σύσταση, η λύση βελτίωσε την ακρίβεια της σύστασης (μέση ανταμοιβή) από 11% σε 59%, σύμφωνα με τη δοκιμή εκτός σύνδεσης. Η Ibotta σχεδιάζει να ενσωματώσει αυτή τη λύση σε περισσότερες περιπτώσεις εξατομίκευσης.
"Το Amazon ML Solutions Lab συνεργάστηκε στενά με την ομάδα Machine Learning της Ibotta για τη δημιουργία μιας δυναμικής μηχανής συστάσεων μπόνους για την αύξηση των εξαργυρώσεων και τη βελτιστοποίηση της αφοσίωσης των πελατών. Δημιουργήσαμε έναν κινητήρα σύστασης που αξιοποιεί την ενίσχυση της εκμάθησης που μαθαίνει και προσαρμόζεται στη συνεχώς μεταβαλλόμενη κατάσταση των πελατών και τα νέα μπόνους εκκινούν αυτόματα. Μέσα σε 2 μήνες, οι επιστήμονες του ML Solutions Lab ανέπτυξαν μια συμφραζόμενη λύση εκμάθησης ενίσχυσης ληστών πολλαπλών όπλων χρησιμοποιώντας ένα δοχείο SageMaker RL. Η λύση RL με βάση τα συμφραζόμενα έδειξε μια σταθερή αύξηση στα ποσοστά εξαργύρωσης, επιτυγχάνοντας πενταπλάσια αύξηση στο ποσοστό εξαργύρωσης μπόνους σε σχέση με την τυχαία πρόταση και δύο φορές αύξηση σε σχέση με μια λύση RL χωρίς συμφραζόμενα. Η ακρίβεια της σύστασης βελτιώθηκε από 11% χρησιμοποιώντας τυχαία σύσταση σε 59% χρησιμοποιώντας τη λύση ML Solutions Lab. Δεδομένης της αποτελεσματικότητας και της ευελιξίας αυτής της λύσης, σχεδιάζουμε να ενσωματώσουμε αυτήν τη λύση σε περισσότερες περιπτώσεις χρήσης εξατομίκευσης Ibotta για να προωθήσουμε την αποστολή μας να κάνουμε κάθε αγορά ανταποδοτική για τους χρήστες μας."
– Heather Shannon, Senior Vice President of Engineering & Data στην Ibotta.
Σχετικά με τους Συγγραφείς
 Ονόματα Taylor είναι μηχανικός μηχανικής εκμάθησης προσωπικού στην Ibotta, με επίκεντρο την εξατομίκευση περιεχομένου και την πρόβλεψη ζήτησης σε πραγματικό χρόνο. Πριν από την ένταξή του στην Ibotta, ο Taylor ηγήθηκε ομάδων μηχανικής μάθησης στο IoT και στους χώρους καθαρής ενέργειας.
Ονόματα Taylor είναι μηχανικός μηχανικής εκμάθησης προσωπικού στην Ibotta, με επίκεντρο την εξατομίκευση περιεχομένου και την πρόβλεψη ζήτησης σε πραγματικό χρόνο. Πριν από την ένταξή του στην Ibotta, ο Taylor ηγήθηκε ομάδων μηχανικής μάθησης στο IoT και στους χώρους καθαρής ενέργειας.
 Dev Gupta είναι διευθυντής μηχανικής στην Ibotta Inc, όπου ηγείται της ομάδας μηχανικής εκμάθησης. Η ομάδα ML στο Ibotta είναι επιφορτισμένη με την παροχή λογισμικού ML υψηλής ποιότητας, όπως συστάτες, προγνωστικούς και εσωτερικά εργαλεία ML. Πριν ενταχθεί στην Ibotta, ο Dev εργαζόταν στην Predikto Inc, μια startup μηχανικής εκμάθησης και στο The Home Depot. Αποφοίτησε από το Πανεπιστήμιο της Φλόριντα.
Dev Gupta είναι διευθυντής μηχανικής στην Ibotta Inc, όπου ηγείται της ομάδας μηχανικής εκμάθησης. Η ομάδα ML στο Ibotta είναι επιφορτισμένη με την παροχή λογισμικού ML υψηλής ποιότητας, όπως συστάτες, προγνωστικούς και εσωτερικά εργαλεία ML. Πριν ενταχθεί στην Ibotta, ο Dev εργαζόταν στην Predikto Inc, μια startup μηχανικής εκμάθησης και στο The Home Depot. Αποφοίτησε από το Πανεπιστήμιο της Φλόριντα.
 Άργη Αγγελέας είναι Senior Product Manager στην Ibotta, όπου ηγείται των ομάδων Machine Learning και Browser Extension. Πριν ενταχθεί στην Ibotta, ο Argie εργαζόταν ως Διευθυντής Προϊόντος στο iReportsource. Ο Argie απέκτησε το διδακτορικό του στην Επιστήμη και τη Μηχανική Υπολογιστών από το Wright State University.
Άργη Αγγελέας είναι Senior Product Manager στην Ibotta, όπου ηγείται των ομάδων Machine Learning και Browser Extension. Πριν ενταχθεί στην Ibotta, ο Argie εργαζόταν ως Διευθυντής Προϊόντος στο iReportsource. Ο Argie απέκτησε το διδακτορικό του στην Επιστήμη και τη Μηχανική Υπολογιστών από το Wright State University.
 Φανγκ Γουάνγκ είναι Ανώτερος Επιστήμονας Έρευνας στο Εργαστήριο Amazon Machine Learning Solutions, όπου ηγείται της Retail Vertical, συνεργαζόμενη με πελάτες AWS σε διάφορες βιομηχανίες για την επίλυση των προβλημάτων ML τους. Πριν ενταχθεί στην AWS, ο Fang εργάστηκε ως Sr. Director of Data Science στην Anthem, επικεφαλής της πλατφόρμας AI για την επεξεργασία ιατρικών ισχυρισμών. Πήρε το μεταπτυχιακό της στη Στατιστική από το Πανεπιστήμιο του Σικάγο.
Φανγκ Γουάνγκ είναι Ανώτερος Επιστήμονας Έρευνας στο Εργαστήριο Amazon Machine Learning Solutions, όπου ηγείται της Retail Vertical, συνεργαζόμενη με πελάτες AWS σε διάφορες βιομηχανίες για την επίλυση των προβλημάτων ML τους. Πριν ενταχθεί στην AWS, ο Fang εργάστηκε ως Sr. Director of Data Science στην Anthem, επικεφαλής της πλατφόρμας AI για την επεξεργασία ιατρικών ισχυρισμών. Πήρε το μεταπτυχιακό της στη Στατιστική από το Πανεπιστήμιο του Σικάγο.
 Ξιν Τσεν είναι ανώτερος διευθυντής στο Εργαστήριο Amazon Machine Learning Solutions, όπου ηγείται των Κεντρικών ΗΠΑ, Περιφέρειας Ευρύτερης Κίνας, LATAM και Automotive Vertical. Βοηθά τους πελάτες της AWS σε διαφορετικούς κλάδους να εντοπίσουν και να δημιουργήσουν λύσεις μηχανικής εκμάθησης για να αντιμετωπίσουν τις ευκαιρίες μηχανικής εκμάθησης με την υψηλότερη απόδοση επένδυσης του οργανισμού τους. Ο Xin απέκτησε το διδακτορικό του στην Επιστήμη και τη Μηχανική Υπολογιστών από το Πανεπιστήμιο της Notre Dame.
Ξιν Τσεν είναι ανώτερος διευθυντής στο Εργαστήριο Amazon Machine Learning Solutions, όπου ηγείται των Κεντρικών ΗΠΑ, Περιφέρειας Ευρύτερης Κίνας, LATAM και Automotive Vertical. Βοηθά τους πελάτες της AWS σε διαφορετικούς κλάδους να εντοπίσουν και να δημιουργήσουν λύσεις μηχανικής εκμάθησης για να αντιμετωπίσουν τις ευκαιρίες μηχανικής εκμάθησης με την υψηλότερη απόδοση επένδυσης του οργανισμού τους. Ο Xin απέκτησε το διδακτορικό του στην Επιστήμη και τη Μηχανική Υπολογιστών από το Πανεπιστήμιο της Notre Dame.
 Ρατζ Μπίσβας είναι επιστήμονας δεδομένων στο Εργαστήριο Amazon Machine Learning Solutions. Βοηθά τους πελάτες της AWS να αναπτύξουν λύσεις που υποστηρίζονται από ML σε διάφορους κλάδους της βιομηχανίας για τις πιο πιεστικές επιχειρηματικές προκλήσεις τους. Πριν ενταχθεί στην AWS, ήταν μεταπτυχιακός φοιτητής στο Πανεπιστήμιο Κολούμπια στην Επιστήμη των Δεδομένων.
Ρατζ Μπίσβας είναι επιστήμονας δεδομένων στο Εργαστήριο Amazon Machine Learning Solutions. Βοηθά τους πελάτες της AWS να αναπτύξουν λύσεις που υποστηρίζονται από ML σε διάφορους κλάδους της βιομηχανίας για τις πιο πιεστικές επιχειρηματικές προκλήσεις τους. Πριν ενταχθεί στην AWS, ήταν μεταπτυχιακός φοιτητής στο Πανεπιστήμιο Κολούμπια στην Επιστήμη των Δεδομένων.
 Xinghua Liang είναι Εφαρμοσμένος Επιστήμονας στο Εργαστήριο Amazon Machine Learning Solutions, όπου συνεργάζεται με πελάτες σε διάφορους κλάδους, συμπεριλαμβανομένης της μεταποίησης και της αυτοκινητοβιομηχανίας, και τους βοηθά να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud. Ο Xinghua απέκτησε το διδακτορικό του στη Μηχανική από το Πανεπιστήμιο Carnegie Mellon.
Xinghua Liang είναι Εφαρμοσμένος Επιστήμονας στο Εργαστήριο Amazon Machine Learning Solutions, όπου συνεργάζεται με πελάτες σε διάφορους κλάδους, συμπεριλαμβανομένης της μεταποίησης και της αυτοκινητοβιομηχανίας, και τους βοηθά να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud. Ο Xinghua απέκτησε το διδακτορικό του στη Μηχανική από το Πανεπιστήμιο Carnegie Mellon.
 Γι Λιου είναι εφαρμοσμένος επιστήμονας στην Εξυπηρέτηση Πελατών της Amazon. Είναι παθιασμένη με τη χρήση της δύναμης του ML/AI για να βελτιστοποιήσει την εμπειρία χρήστη για τους πελάτες της Amazon και να βοηθήσει τους πελάτες της AWS να δημιουργήσουν επεκτάσιμες λύσεις cloud. Το επιστημονικό της έργο στο Amazon περιλαμβάνει τη δέσμευση μελών, το διαδικτυακό σύστημα συστάσεων και τον εντοπισμό και την επίλυση ελαττωμάτων εμπειρίας πελατών. Εκτός δουλειάς, η Yi απολαμβάνει τα ταξίδια και την εξερεύνηση της φύσης με τον σκύλο της.
Γι Λιου είναι εφαρμοσμένος επιστήμονας στην Εξυπηρέτηση Πελατών της Amazon. Είναι παθιασμένη με τη χρήση της δύναμης του ML/AI για να βελτιστοποιήσει την εμπειρία χρήστη για τους πελάτες της Amazon και να βοηθήσει τους πελάτες της AWS να δημιουργήσουν επεκτάσιμες λύσεις cloud. Το επιστημονικό της έργο στο Amazon περιλαμβάνει τη δέσμευση μελών, το διαδικτυακό σύστημα συστάσεων και τον εντοπισμό και την επίλυση ελαττωμάτων εμπειρίας πελατών. Εκτός δουλειάς, η Yi απολαμβάνει τα ταξίδια και την εξερεύνηση της φύσης με τον σκύλο της.
- Coinsmart. Το καλύτερο ανταλλακτήριο Bitcoin και Crypto στην Ευρώπη.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. ΕΛΕΥΘΕΡΗ ΠΡΟΣΒΑΣΗ.
- CryptoHawk. Ραντάρ Altcoin. Δωρεάν δοκιμή.
- Πηγή: https://aws.amazon.com/blogs/machine-learning/optimize-customer-engagement-with-reinforcement-learning/
- "
- &
- 000
- 10
- 100
- 11
- 7
- 9
- ΠΛΗΡΟΦΟΡΙΕΣ
- επιταχύνουν
- Σύμφωνα με
- απέναντι
- Ενέργειες
- ενεργειών
- δραστηριότητα
- Πρόσθετος
- διεύθυνση
- Υιοθεσία
- παράγοντες
- AI
- αλγόριθμος
- αλγόριθμοι
- ήδη
- Amazon
- Αμερικανικη
- ποσό
- app
- Εφαρμογή
- εφαρμογές
- ΠΕΡΙΟΧΗ
- αυτοκινήτων
- διαθέσιμος
- μέσος
- AWS
- Δώρο
- πρόγραμμα περιήγησης
- χτίζω
- ενσωματωμένο
- επιχείρηση
- δυνατότητες
- Carnegie Mellon
- περιπτώσεις
- Μετρητά
- προκλήσεις
- αλλαγή
- Σικάγο
- Κίνα
- κλασικό
- Backup
- κωδικός
- εταίρα
- σύγκριση
- Πληροφορική
- Δοχείο
- περιεχόμενο
- Ρεύμα
- εμπειρία του πελάτη
- Εξυπηρέτηση πελατών
- Πελάτες
- ημερομηνία
- επιστημονικά δεδομένα
- επιστήμονας δεδομένων
- ημέρα
- υπεύθυνος λήψης αποφάσεων
- Ζήτηση
- κατέδειξε
- παρατάσσω
- ανάπτυξη
- Dev
- ανάπτυξη
- αναπτύχθηκε
- προγραμματιστές
- διαφορετικές
- Διευθυντής
- διανομή
- δυναμικός
- Αποτελεσματικός
- Τελικό σημείο
- ενέργεια
- δέσμευση
- Κινητήρας
- μηχανικός
- Μηχανική
- Περιβάλλον
- εγκαθιδρύω
- εξελίσσεται
- εμπειρία
- εξερεύνηση
- Χαρακτηριστικά
- ανατροφοδότηση
- Εικόνα
- Ευελιξία
- Φλόριντα
- εστιάζει
- Εξής
- μορφή
- Πλαίσιο
- περαιτέρω
- αποφοιτήσουν
- Επισκέπτης
- Κείμενο
- ύψος
- βοήθεια
- βοηθά
- υψηλά
- ιστορικών
- Αρχική
- Πως
- HTTPS
- Αναγνώριση
- προσδιορίσει
- εφαρμογή
- Συμπεριλαμβανομένου
- Αυξάνουν
- βιομηχανίες
- βιομηχανία
- πληροφορίες
- Υποδομή
- ενσωματώσει
- Έξυπνος
- αλληλεπίδραση
- IoT
- γνώση
- εργαστήριο
- που οδηγεί
- Οδηγεί
- ΜΑΘΑΊΝΩ
- μάθει
- μάθηση
- Led
- μόχλευσης
- γραμμή
- Εισηγμένες
- Μακριά
- Loyalty
- μηχανή
- μάθηση μηχανής
- Κατασκευή
- διευθυντής
- κατασκευής
- κύριοι
- ιατρικών
- Metrics
- Αποστολή
- ML
- Κινητό
- εφαρμογή για κινητά
- μοντέλο
- μοντέλα
- μήνες
- περισσότερο
- πλέον
- ονόματα
- Φύση
- Εννοια
- αριθμός
- διαδικτυακά (online)
- ηλεκτρονικές αγορές
- Ευκαιρίες
- τάξη
- ΑΛΛΑ
- αλλιώς
- πληρωμές
- επίδοση
- εξατομίκευση
- πλατφόρμες
- Πολιτικές
- πολιτική
- δύναμη
- πρόεδρος
- Πρόβλημα
- προβλήματα
- Προϊόν
- παραγωγή
- προαγωγή
- χορήγηση
- αγορά
- ψώνια
- γρήγορα
- Τιμές
- σε πραγματικό χρόνο
- συνιστώ
- αρχεία
- έρευνα
- Αποτελέσματα
- λιανική πώληση
- έμπορος λιανικής
- Επιστροφές
- Ανταμοιβές
- επεκτάσιμη
- Επιστήμη
- Επιστήμονας
- επιστήμονες
- επιλέγονται
- υπηρεσία
- σειρά
- σημαντικός
- λογισμικό
- λύση
- Λύσεις
- SOLVE
- χώρων
- διαίρεση
- Εκκίνηση
- ξεκινά
- εκκίνηση
- Κατάσταση
- στατιστική
- Στρατηγική
- Φοιτητής
- Στήριξη
- Υποστηρίζει
- διακόπτης
- σύστημα
- Τεχνολογία
- δοκιμή
- Δοκιμές
- Μέσω
- μαζι
- εργαλεία
- Εκπαίδευση
- τρένα
- πανεπιστήμιο
- us
- χρήση
- Χρήστες
- διάφορα
- Επαλήθευση
- Vice President
- εβδομαδιαίος
- εντός
- Εργασία
- εργάστηκαν
- εργαζόμενος
- λειτουργεί