Θέλετε να εξαγάγετε δεδομένα από μια ιστοσελίδα;
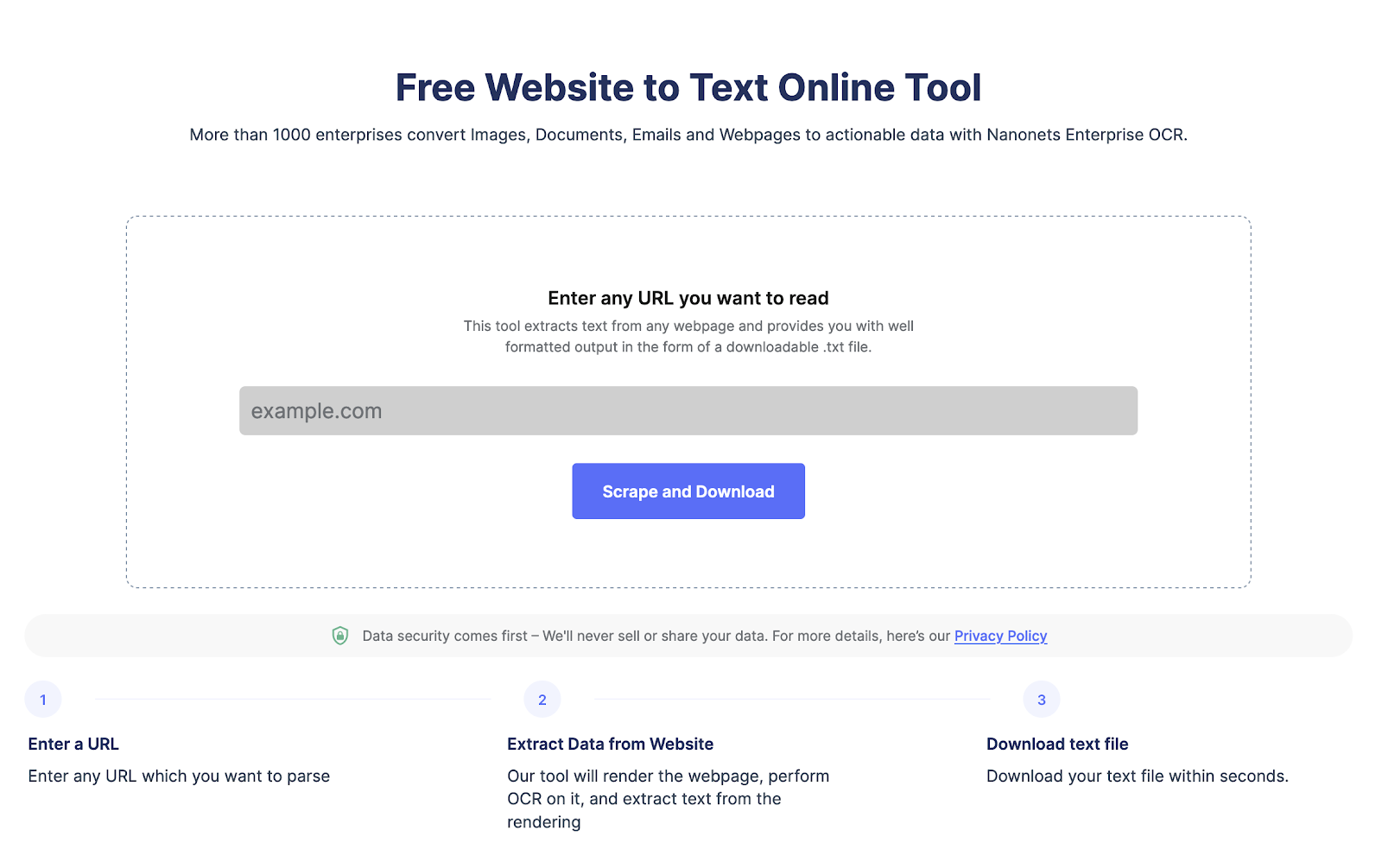
Πηγαίνετε στο Nanonets ξύστρα ιστότοπου, Προσθέστε τη διεύθυνση URL και κάντε κλικ στο "Scrape" και κατεβάστε το κείμενο της ιστοσελίδας ως αρχείο αμέσως. Δοκιμάστε το δωρεάν τώρα.
Τι είναι το Selenium Web Scraping;
Το web scraping είναι η διαδικασία εξαγωγής δεδομένων από ιστότοπους. Είναι μια ισχυρή τεχνική που φέρνει επανάσταση στη συλλογή και ανάλυση δεδομένων. Με τεράστια διαδικτυακά δεδομένα, το web scraping έχει γίνει ένα απαραίτητο εργαλείο για επιχειρήσεις και ιδιώτες.
Το Selenium είναι ένα εργαλείο ανάπτυξης ιστού ανοιχτού κώδικα που χρησιμοποιείται για την αυτοματοποίηση των λειτουργιών περιήγησης στο Web. Αναπτύχθηκε το 2004 και χρησιμοποιείται κυρίως για την αυτόματη δοκιμή ιστοτόπων και εφαρμογών σε διάφορα προγράμματα περιήγησης, αλλά πλέον έχει γίνει ένα δημοφιλές εργαλείο για την απόξεση ιστού. Το Selenium μπορεί να χρησιμοποιηθεί με πολλές γλώσσες προγραμματισμού, συμπεριλαμβανομένων των Python, Java και C#. Παρέχει ισχυρά API για αλληλεπίδραση ιστοσελίδων, συμπεριλαμβανομένης της πλοήγησης, του κλικ, της πληκτρολόγησης και της κύλισης.
Το Selenium web scraping αναφέρεται στη χρήση του εργαλείου αυτοματισμού του προγράμματος περιήγησης Selenium με την Python για την εξαγωγή δεδομένων από ιστότοπους. Το Selenium επιτρέπει στους προγραμματιστές να ελέγχουν μέσω προγραμματισμού ένα πρόγραμμα περιήγησης ιστού μέσω προγραμματισμού, που σημαίνει ότι μπορούν να αλληλεπιδρούν με ιστότοπους σαν να ήταν άνθρωποι χρήστες.
Γιατί να χρησιμοποιήσετε το Selenium και την Python για απόξεση ιστού;
Η Python είναι μια δημοφιλής γλώσσα προγραμματισμού για την απόξεση ιστού επειδή έχει πολλές βιβλιοθήκες και πλαίσια που διευκολύνουν την εξαγωγή δεδομένων από ιστότοπους.
Η χρήση Python και Selenium για απόξεση ιστού προσφέρει πολλά πλεονεκτήματα σε σχέση με άλλες τεχνικές απόξεσης ιστού:
- Δυναμικοί ιστότοποι: Οι δυναμικές ιστοσελίδες δημιουργούνται χρησιμοποιώντας JavaScript ή άλλες γλώσσες δέσμης ενεργειών. Αυτές οι σελίδες περιέχουν συχνά ορατά στοιχεία μόλις φορτωθεί πλήρως η σελίδα ή όταν ο χρήστης αλληλεπιδρά μαζί τους. Το σελήνιο μπορεί να αλληλεπιδράσει με αυτά τα στοιχεία, καθιστώντας το ένα ισχυρό εργαλείο για την απόξεση δεδομένων από δυναμικές ιστοσελίδες.
- Αλληλεπιδράσεις χρηστών: Το Selenium μπορεί να προσομοιώσει τις αλληλεπιδράσεις των χρηστών όπως τα κλικ, οι υποβολές φορμών και η κύλιση. Αυτό σας επιτρέπει να ξύνετε ιστότοπους που απαιτούν εισαγωγή χρήστη, όπως φόρμες σύνδεσης.
- Εντοπισμός σφαλμάτων: Το σελήνιο μπορεί να εκτελεστεί σε λειτουργία εντοπισμού σφαλμάτων, η οποία σας επιτρέπει να περάσετε στη διαδικασία απόξεσης και να δείτε τι κάνει η ξύστρα σε κάθε βήμα. Αυτό είναι χρήσιμο για την αντιμετώπιση προβλημάτων όταν τα πράγματα πάνε στραβά.
Προϋποθέσεις για απόξεση ιστού με σελήνιο:
Η Python 3 είναι εγκατεστημένη στο σύστημά σας.
Εγκαταστάθηκε η βιβλιοθήκη Selenium. Μπορείτε να το εγκαταστήσετε χρησιμοποιώντας pip με την ακόλουθη εντολή:
pip install SeleniumΕγκατεστημένο το WebDriver.
Το WebDriver είναι ένα ξεχωριστό εκτελέσιμο αρχείο που χρησιμοποιεί το Selenium για τον έλεγχο του προγράμματος περιήγησης. Ακολουθούν οι σύνδεσμοι που βρήκα για τη λήψη του WebDriver για τα πιο δημοφιλή προγράμματα περιήγησης:
Εναλλακτικά, και αυτός είναι ο ευκολότερος τρόπος, μπορείτε επίσης να εγκαταστήσετε το WebDriver χρησιμοποιώντας έναν διαχειριστή πακέτων όπως το πρόγραμμα οδήγησης-διαχειριστής ιστού. Αυτό θα πραγματοποιήσει αυτόματη λήψη και εγκατάσταση του κατάλληλου προγράμματος οδήγησης Web για εσάς. Για να εγκαταστήσετε το πρόγραμμα οδήγησης-διαχειριστής ιστού, μπορείτε να χρησιμοποιήσετε την ακόλουθη εντολή:
pip install webdriver-managerΕξαγωγή πλήρους κειμένου από την ιστοσελίδα σε δευτερόλεπτα!
Πηγαίνετε στο Nanonets ξύστρα ιστότοπου, Προσθέστε τη διεύθυνση URL και κάντε κλικ στο "Scrape" και κατεβάστε το κείμενο της ιστοσελίδας ως αρχείο αμέσως. Δοκιμάστε το δωρεάν τώρα.
Ένας βήμα προς βήμα οδηγός για την απόξεση ιστού σεληνίου
Βήμα 1: Εγκατάσταση και εισαγωγή
Πριν ξεκινήσουμε, έχουμε βεβαιωθεί ότι έχουμε εγκαταστήσει το Selenium και ένα κατάλληλο πρόγραμμα οδήγησης. Θα χρησιμοποιήσουμε το πρόγραμμα οδήγησης Edge σε αυτό το παράδειγμα.
from selenium import webdriver
from Selenium.webdriver.common.keys import Keys
from Selenium.webdriver.common.by import ByΒήμα 2: Εγκατάσταση και πρόσβαση στο WebDriver
Μπορούμε να δημιουργήσουμε μια νέα παρουσία του προγράμματος οδήγησης Edge εκτελώντας τον ακόλουθο κώδικα:
driver = webdriver.Edge()Βήμα 3: Πρόσβαση στον ιστότοπο μέσω Python
Στη συνέχεια, πρέπει να αποκτήσουμε πρόσβαση στον ιστότοπο της μηχανής αναζήτησης. Σε αυτήν την περίπτωση, θα χρησιμοποιήσουμε το Bing.
driver.get("https://www.bing.com")Βήμα 4: Εντοπίστε συγκεκριμένες πληροφορίες που ξύνετε
Θέλουμε να εξαγάγουμε τον αριθμό των αποτελεσμάτων αναζήτησης για ένα συγκεκριμένο όνομα. Μπορούμε να το κάνουμε αυτό εντοπίζοντας το στοιχείο HTML που περιέχει τον αριθμό των αποτελεσμάτων αναζήτησης
results = driver.find_elements(By.XPATH, "//*[@id='b_tween']/span")Βήμα 5: Κάντε το μαζί
Τώρα που έχουμε όλα τα κομμάτια, μπορούμε να τα συνδυάσουμε για να εξαγάγουμε τα αποτελέσματα αναζήτησης για ένα συγκεκριμένο όνομα.
try:
search_box = driver.find_element(By.NAME, "q")
search_box.clear()
search_box.send_keys("John Doe") # enter your name in the search box
search_box.submit() # submit the search
results = driver.find_elements(By.XPATH, "//*[@id='b_tween']/span")
for result in results:
text = result.text.split()[1] # extract the number of results
print(text)
# save it to a file
with open("results.txt", "w") as f:
f.write(text)
except Exception as e:
print(f"An error occurred: {e}")Βήμα 6: Αποθηκεύστε τα δεδομένα
Τέλος, μπορούμε να αποθηκεύσουμε τα εξαγόμενα δεδομένα σε ένα αρχείο κειμένου.
με open("results.txt", "w") ως f:
f.write(text)Χρήση διακομιστή μεσολάβησης με Selenium Wire
Το Selenium Wire είναι μια βιβλιοθήκη που επεκτείνει τη λειτουργικότητα του Selenium επιτρέποντάς σας να επιθεωρείτε και να τροποποιείτε αιτήματα και απαντήσεις HTTP. Για παράδειγμα, μπορεί επίσης να χρησιμοποιηθεί για να διαμορφώσετε εύκολα έναν διακομιστή μεσολάβησης για το Selenium WebDriver σας
Εγκαταστήστε το σύρμα σεληνίου
pip install selenium-wireΡύθμιση του διακομιστή μεσολάβησης
from selenium import webdriver
from Selenium.webdriver.chrome.options import Options
from seleniumwire import webdriver as wiredriver
PROXY_HOST = 'your.proxy.host'
PROXY_PORT = 'your_proxy_port'
chrome_options = Options()
chrome_options.add_argument('--proxy-server=http://{}:{}'.format(PROXY_HOST, PROXY_PORT))
driver = wiredriver.Chrome(options=chrome_options)Χρησιμοποιήστε το Selenium Wire για να επιθεωρήσετε και να τροποποιήσετε αιτήματα.
for request in driver.requests:
if request.response:
print(request.url, request.response.status_code, request.response.headers['Content-Type'])Στον παραπάνω κώδικα, επαναλαμβάνουμε όλα τα αιτήματα που γίνονται από το WebDriver κατά τη διάρκεια της περιόδου λειτουργίας απόξεσης ιστού. Για κάθε αίτημα, ελέγχουμε εάν ελήφθη απάντηση και εκτυπώνουμε τη διεύθυνση URL, τον κωδικό κατάστασης και τον τύπο περιεχομένου της απάντησης
Χρήση Selenium για εξαγωγή όλων των τίτλων από μια ιστοσελίδα
Ακολουθεί ένα παράδειγμα κώδικα Python που χρησιμοποιεί το Selenium για να ξύσει όλους τους τίτλους μιας ιστοσελίδας:
from selenium import webdriver
# Initialize the webdriver
driver = webdriver.Chrome()
# Navigate to the webpage
driver.get("https://www.example.com")
# Find all the title elements on the page
title_elements = driver.find_elements_by_tag_name("title")
# Extract the text from each title element
titles = [title.text for title in title_elements]
# Print the list of titles
print(titles)
# Close the webdriver
driver.quit()Σε αυτό το παράδειγμα, εισάγουμε πρώτα τη μονάδα προγράμματος οδήγησης ιστού από το Selenium και, στη συνέχεια, αρχικοποιούμε μια νέα παρουσία προγράμματος οδήγησης ιστού Chrome. Πλοηγούμαστε στην ιστοσελίδα που θέλουμε να ξύσουμε και, στη συνέχεια, χρησιμοποιούμε τη μέθοδο find_elements_by_tag_name για να βρούμε όλα τα στοιχεία τίτλου στη σελίδα.
Στη συνέχεια χρησιμοποιούμε μια κατανόηση λίστας για να εξαγάγουμε το κείμενο από κάθε στοιχείο τίτλου και να αποθηκεύουμε τη λίστα τίτλων που προκύπτει σε μια μεταβλητή που ονομάζεται τίτλοι. Τέλος, εκτυπώνουμε τη λίστα των τίτλων και κλείνουμε την παρουσία του προγράμματος οδήγησης web.
Σημειώστε ότι θα πρέπει να έχετε εγκατεστημένα τα πακέτα προγραμμάτων οδήγησης ιστού Selenium και Chrome στο περιβάλλον Python για να λειτουργήσει αυτός ο κώδικας. Μπορείτε να τα εγκαταστήσετε χρησιμοποιώντας pip, όπως:
pip install selenium chromedriver-binaryΕπίσης, φροντίστε να ενημερώσετε τη διεύθυνση URL στο πρόγραμμα οδήγησης. λάβετε μια μέθοδο για να δείξετε την ιστοσελίδα που θέλετε να ξύσετε.
Συμπέρασμα
Συμπερασματικά, το web scraping με Selenium είναι ένα ισχυρό εργαλείο για την εξαγωγή δεδομένων από ιστότοπους. Σας επιτρέπει να αυτοματοποιείτε τη διαδικασία συλλογής δεδομένων και μπορεί να σας εξοικονομήσει σημαντικό χρόνο και προσπάθεια. Χρησιμοποιώντας το Selenium, μπορείτε να αλληλεπιδράσετε με ιστότοπους όπως ένας άνθρωπος και να εξάγετε τα δεδομένα που χρειάζεστε πιο αποτελεσματικά.
Εναλλακτικά, μπορείτε να χρησιμοποιήσετε εργαλεία χωρίς κώδικα όπως τα Nanonets εργαλείο ξύστρας ιστότοπου για εύκολη εξαγωγή όλων των στοιχείων κειμένου από HTML. Είναι δωρεάν για χρήση εντελώς.
Εξαγωγή κειμένου από οποιαδήποτε ιστοσελίδα με ένα μόνο κλικ. Πηγαίνετε στο Nanonets ξύστρα ιστότοπου, Προσθέστε τη διεύθυνση URL και κάντε κλικ στο "Scrape" και κατεβάστε το κείμενο της ιστοσελίδας ως αρχείο αμέσως. Δοκιμάστε το δωρεάν τώρα.
Συχνές ερωτήσεις:
Είναι το σελήνιο καλύτερο από το BeautifulSoup;
Το Selenium και το BeautifulSoup είναι εργαλεία που εξυπηρετούν διαφορετικούς σκοπούς στην απόξεση ιστού. Ενώ το Selenium χρησιμοποιείται κυρίως για την αυτοματοποίηση προγραμμάτων περιήγησης ιστού, το BeautifulSoup είναι μια βιβλιοθήκη Python για την ανάλυση εγγράφων HTML και XML.
Το σελήνιο είναι καλύτερο από το BeautifulSoup όταν πρόκειται για την απόξεση δυναμικών ιστοσελίδων. Οι δυναμικές ιστοσελίδες δημιουργούνται χρησιμοποιώντας JavaScript ή άλλες γλώσσες δέσμης ενεργειών. Αυτές οι σελίδες περιέχουν συχνά στοιχεία που δεν είναι ορατά μέχρι να φορτωθεί πλήρως η σελίδα ή έως ότου ο χρήστης αλληλεπιδράσει μαζί τους. Το σελήνιο μπορεί να αλληλεπιδράσει με αυτά τα στοιχεία, καθιστώντας το ένα ισχυρό εργαλείο για την απόξεση δεδομένων από δυναμικές ιστοσελίδες.
Από την άλλη πλευρά, το BeautifulSoup είναι καλύτερο από το Selenium κατά την ανάλυση εγγράφων HTML και XML. Το BeautifulSoup παρέχει μια απλή και διαισθητική διεπαφή για την ανάλυση εγγράφων HTML και XML και την εξαγωγή των δεδομένων που χρειάζεστε. Είναι μια ελαφριά βιβλιοθήκη που δεν απαιτεί πρόγραμμα περιήγησης ιστού, καθιστώντας την ταχύτερη και πιο αποτελεσματική από το Selenium σε ορισμένες περιπτώσεις.
Συνοπτικά, το αν το σελήνιο είναι καλύτερο από το BeautifulSoup εξαρτάται από την εργασία. Εάν χρειάζεται να σκουπίσετε δεδομένα από δυναμικές ιστοσελίδες, τότε το Selenium είναι η καλύτερη επιλογή. Ωστόσο, εάν χρειάζεται να αναλύσετε έγγραφα HTML και XML, τότε το BeautifulSoup είναι η καλύτερη επιλογή.
Πρέπει να χρησιμοποιήσω σελήνιο ή Scrapy;
Το σελήνιο χρησιμοποιείται κυρίως για την αυτοματοποίηση προγραμμάτων περιήγησης ιστού και είναι το καταλληλότερο για τη συλλογή δεδομένων από δυναμικές ιστοσελίδες. Εάν χρειάζεται να αλληλεπιδράσετε με ιστοσελίδες που περιέχουν στοιχεία που δεν είναι ορατά μέχρι να φορτωθεί πλήρως η σελίδα ή έως ότου ο χρήστης αλληλεπιδράσει μαζί τους, τότε το Selenium είναι η καλύτερη επιλογή. Το Selenium μπορεί επίσης να αλληλεπιδράσει με ιστοσελίδες που απαιτούν έλεγχο ταυτότητας ή άλλες φόρμες εισαγωγής χρήστη.
Το Scrapy, από την άλλη πλευρά, είναι ένα πλαίσιο απόξεσης ιστού που βασίζεται σε Python και έχει σχεδιαστεί για τη διάσπαση δεδομένων από δομημένους ιστότοπους. Είναι ένα ισχυρό και ευέλικτο εργαλείο που παρέχει πολλές δυνατότητες για ανίχνευση και απόξεση ιστοσελίδων. Μπορεί να χρησιμοποιηθεί για την απόξεση δεδομένων από πολλές σελίδες ή ιστότοπους και τη διαχείριση σύνθετων εργασιών απόξεσης, όπως η παρακολούθηση συνδέσμων και η αντιμετώπιση της σελιδοποίησης. Το Scrapy είναι επίσης πιο αποτελεσματικό από το Selenium όσον αφορά τη μνήμη και τους πόρους επεξεργασίας, καθιστώντας το καλύτερη επιλογή για έργα απόξεσης ιστού μεγάλης κλίμακας.
Το αν θα πρέπει να χρησιμοποιήσετε το Selenium ή το Scrapy εξαρτάται από τις συγκεκριμένες απαιτήσεις του έργου σας απόξεσης ιστού. Εάν χρειάζεται να αφαιρέσετε δεδομένα από δυναμικές ιστοσελίδες ή να αλληλεπιδράσετε με ιστοσελίδες που απαιτούν έλεγχο ταυτότητας ή άλλα στοιχεία εισαγωγής χρήστη, τότε το Selenium είναι η καλύτερη επιλογή. Ωστόσο, εάν πρέπει να αποκόψετε δεδομένα από δομημένους ιστότοπους ή να εκτελέσετε πολύπλοκες εργασίες απόξεσης, τότε το Scrapy είναι η καλύτερη επιλογή.
Ποια γλώσσα είναι η καλύτερη για την απόξεση ιστού;
Η Python είναι μια από τις πιο δημοφιλείς γλώσσες για την απόξεση ιστού λόγω της ευκολίας χρήσης, της μεγάλης επιλογής βιβλιοθηκών και των ισχυρών πλαισίων απόξεσης όπως το Scrapy, τα αιτήματα, το beautifulSoup και το Selenium. Η Python είναι επίσης εύκολη στην εκμάθηση και στη χρήση, καθιστώντας την εξαιρετική επιλογή για αρχάριους
Πολλές γλώσσες προγραμματισμού μπορούν να χρησιμοποιηθούν για απόξεση ιστού, αλλά ορισμένες είναι πιο κατάλληλες για την εργασία από άλλες. Η καλύτερη γλώσσα για την απόξεση ιστού εξαρτάται από διάφορους παράγοντες, όπως η πολυπλοκότητα της εργασίας, ο ιστότοπος-στόχος και η προσωπική σας προτίμηση.
Άλλες γλώσσες όπως η R, η JavaScript και η PHP μπορούν επίσης να χρησιμοποιηθούν ανάλογα με τις συγκεκριμένες απαιτήσεις του έργου απόξεσης ιστού.
Γιατί είναι σημαντικό το σελήνιο στην απόξεση ιστού;
Το σελήνιο είναι ένα σημαντικό εργαλείο στην απόξεση ιστού για διάφορους λόγους:
Scraping Dynamic Web Pages: Πολλοί ιστότοποι σήμερα χρησιμοποιούν δυναμικό περιεχόμενο και αλληλεπιδράσεις χρηστών για την εμφάνιση δεδομένων. Αυτό σημαίνει ότι πολύ περιεχόμενο στον ιστότοπο φορτώνεται μέσω JavaScript ή AJAX. Το Selenium είναι πολύ αποτελεσματικό στην απόξεση αυτών των δυναμικών ιστότοπων, επειδή μπορεί να αλληλεπιδράσει με στοιχεία στη σελίδα και να προσομοιώσει τις αλληλεπιδράσεις των χρηστών, όπως η κύλιση και το κλικ. Αυτό διευκολύνει την απόξεση δεδομένων από ιστότοπους που εξαρτώνται σε μεγάλο βαθμό από δυναμικό περιεχόμενο. Είναι καταλληλότερο για χειρισμό cookie και περιόδων σύνδεσης, αυτοματοποιημένες δοκιμές, συμβατότητα μεταξύ προγραμμάτων περιήγησης και επεκτασιμότητα:
Μπορείτε να χρησιμοποιήσετε σελήνιο και BeautifulSoup μαζί;
Ναι, μπορείτε να τα χρησιμοποιήσετε μαζί. Το σελήνιο αλληλεπιδρά κυρίως με ιστοσελίδες και προσομοιώνει τις αλληλεπιδράσεις των χρηστών, όπως κλικ, κύλιση και συμπλήρωση φορμών. Από την άλλη πλευρά, το BeautifulSoup είναι μια βιβλιοθήκη Python που χρησιμοποιείται για την ανάλυση εγγράφων HTML και XML και την εξαγωγή δεδομένων από αυτά. Συνδυάζοντας το Selenium και το BeautifulSoup, μπορείτε να δημιουργήσετε ένα ισχυρό εργαλείο απόξεσης ιστού για αλληλεπίδραση με ιστοσελίδες και εξαγωγή δεδομένων από αυτές. Το Selenium μπορεί να χειριστεί δυναμικό περιεχόμενο και αλληλεπιδράσεις με τους χρήστες, ενώ το BeautifulSoup μπορεί να αναλύει HTML και να εξάγει δεδομένα από την πηγή της σελίδας.
Ωστόσο, αξίζει να σημειωθεί ότι η χρήση και των δύο εργαλείων μαζί μπορεί να είναι πιο εντατική σε πόρους και πιο αργή από ένα μόνο. Επομένως, είναι σημαντικό να αξιολογήσετε τις απαιτήσεις του έργου σας απόξεσης ιστού και να επιλέξετε τα σωστά εργαλεία για τη δουλειά.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://nanonets.com/blog/web-scraping-with-selenium/
- :είναι
- $UP
- 1
- 10
- 7
- a
- πάνω από
- πρόσβαση
- απέναντι
- πλεονεκτήματα
- Όλα
- Επιτρέποντας
- επιτρέπει
- ανάλυση
- και
- APIs
- κατάλληλος
- εφαρμογές
- ΕΙΝΑΙ
- AS
- At
- Πιστοποίηση
- αυτοματοποίηση
- Αυτοματοποιημένη
- αυτομάτως
- αυτοματοποίηση
- Αυτοματοποίηση
- BE
- επειδή
- γίνονται
- αρχίζουν
- ΚΑΛΎΤΕΡΟΣ
- Καλύτερα
- Bing
- Κουτί
- πρόγραμμα περιήγησης
- browsers
- Περιήγηση
- επιχειρήσεις
- by
- που ονομάζεται
- CAN
- περίπτωση
- περιπτώσεις
- έλεγχος
- επιλογή
- Επιλέξτε
- Chrome
- κλικ
- Κλεισιμο
- κωδικός
- Συλλέγοντας
- συλλογή
- COM
- συνδυασμός
- συνδυάζοντας
- Κοινός
- συμβατότητα
- πλήρης
- εντελώς
- συγκρότημα
- περίπλοκο
- συμπέρασμα
- Περιέχει
- περιεχόμενο
- έλεγχος
- μπισκότα
- δημιουργία
- δημιουργήθηκε
- cross-browser
- ημερομηνία
- μοιρασιά
- εξαρτώμενος
- Σε συνάρτηση
- εξαρτάται
- σχεδιασμένα
- αναπτύχθηκε
- προγραμματιστές
- Ανάπτυξη
- διαφορετικές
- Display
- έγγραφα
- DOE
- πράξη
- κατεβάσετε
- οδηγός
- κατά την διάρκεια
- δυναμικός
- e
- κάθε
- ευκολία στη χρήση
- ευκολότερη
- πιο εύκολη
- εύκολα
- άκρη
- Αποτελεσματικός
- αποτελεσματικός
- αποτελεσματικά
- προσπάθεια
- στοιχείο
- στοιχεία
- Κινητήρας
- εισάγετε
- Περιβάλλον
- σφάλμα
- ουσιώδης
- Αιθέρας (ΕΤΗ)
- αξιολογήσει
- παράδειγμα
- Εκτός
- εξαίρεση
- εκχύλισμα
- εξαγάγετε τα δεδομένα
- παράγοντες
- γρηγορότερα
- Χαρακτηριστικά
- Αρχεία
- Τελικά
- Εύρεση
- Όνομα
- εύκαμπτος
- Εξής
- Για
- μορφή
- μορφές
- Βρέθηκαν
- Πλαίσιο
- πλαισίων
- Δωρεάν
- από
- πλήρως
- λειτουργικότητα
- λειτουργίες
- παίρνω
- Go
- εξαιρετική
- καθοδηγήσει
- χέρι
- λαβή
- Χειρισμός
- Έχω
- κεφάλι
- βαριά
- εδώ
- οικοδεσπότης
- Ωστόσο
- HTML
- http
- HTTPS
- ανθρώπινος
- i
- εισαγωγή
- σημαντικό
- in
- Συμπεριλαμβανομένου
- άτομα
- πληροφορίες
- εισαγωγή
- εγκαθιστώ
- παράδειγμα
- αλληλεπιδρούν
- αλληλεπίδραση
- αλληλεπιδράσεις
- διαδραστικός
- περιβάλλον λειτουργίας
- διαισθητική
- IT
- ΤΟΥ
- Java
- το JavaScript
- Δουλειά
- Γιάννης
- JOHN DOE
- μόνο ένα
- πλήκτρα
- Γλώσσα
- Γλώσσες
- large
- μεγάλης κλίμακας
- ΜΑΘΑΊΝΩ
- βιβλιοθήκες
- Βιβλιοθήκη
- πυγμάχος ελαφρού βάρους
- Μου αρέσει
- ΣΥΝΔΕΣΜΟΙ
- Λιστα
- Παρτίδα
- που
- κάνω
- ΚΑΝΕΙ
- Κατασκευή
- διευθυντής
- πολοί
- νόημα
- μέσα
- Μνήμη
- μέθοδος
- Τρόπος
- τροποποιήσει
- ενότητα
- περισσότερο
- πιο αποτελεσματικό
- πλέον
- Δημοφιλέστερα
- πολλαπλούς
- όνομα
- Πλοηγηθείτε
- πλοήγηση
- Ανάγκη
- Νέα
- αριθμός
- συνέβη
- of
- προσφορές
- on
- ONE
- διαδικτυακά (online)
- ανοικτού κώδικα
- Επιλογές
- ΑΛΛΑ
- Άλλα
- πακέτο
- Packages
- σελίδα
- Σελιδοποίηση
- Ειδικότερα
- εκτελέσει
- προσωπικός
- PHP
- κομμάτια
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- Σημείο
- Δημοφιλής
- ισχυρός
- πρωτίστως
- διαδικασια μας
- μεταποίηση
- Προγραμματισμός
- γλώσσες προγραμματισμού
- σχέδιο
- έργα
- παρέχει
- πληρεξούσιο
- σκοποί
- Python
- λόγους
- έλαβε
- αναφέρεται
- σχετικά με
- τακτικός
- ζητήσει
- αιτήματα
- απαιτούν
- απαιτήσεις
- ένταση πόρων
- Υποστηρικτικό υλικό
- απάντησης
- αποτέλεσμα
- με αποτέλεσμα
- Αποτελέσματα
- επαναστατεί
- εύρωστος
- τρέξιμο
- τρέξιμο
- s
- Αποθήκευση
- Απεριόριστες δυνατότητες
- απόξεση
- κύλιση
- Αναζήτηση
- μηχανή αναζήτησης
- επιλογή
- ξεχωριστό
- εξυπηρετούν
- Συνεδρίαση
- συνεδρίες
- διάφοροι
- θα πρέπει να
- σημαντικός
- Απλούς
- So
- μερικοί
- Πηγή
- συγκεκριμένες
- Κατάσταση
- Βήμα
- κατάστημα
- δομημένος
- Υποβολές
- υποβάλουν
- τέτοιος
- ΠΕΡΙΛΗΨΗ
- σύστημα
- στόχος
- Έργο
- εργασίες
- τεχνικές
- δοκιμή
- Δοκιμές
- ότι
- Η
- Τους
- Αυτοί
- πράγματα
- Μέσω
- ώρα
- Τίτλος
- τίτλους
- προς την
- σήμερα
- μαζι
- εργαλείο
- εργαλεία
- Ενημέρωση
- URL
- χρήση
- Χρήστες
- Χρήστες
- διάφορα
- Σταθερή
- μέσω
- ορατός
- W
- Τρόπος..
- ιστός
- πρόγραμμα περιήγησης στο Web
- Περιηγητές ιστού
- Web ανάπτυξη
- ξύσιμο ιστού
- Ιστοσελίδα : www.example.gr
- ιστοσελίδες
- Τι
- αν
- Ποιό
- ενώ
- θα
- Σύρμα
- με
- Εργασία
- αξία
- Λανθασμένος
- XML
- Σας
- zephyrnet