Σήμερα είμαστε ενθουσιασμένοι που ανακοινώνουμε ότι το Φρουρός Λάμα Το μοντέλο είναι πλέον διαθέσιμο για πελάτες που χρησιμοποιούν Amazon SageMaker JumpStart. Το Llama Guard παρέχει διασφαλίσεις εισόδου και εξόδου στην ανάπτυξη μοντέλου μεγάλων γλωσσών (LLM). Είναι ένα από τα στοιχεία στο πλαίσιο της Purple Llama, της πρωτοβουλίας της Meta που περιλαμβάνει ανοιχτά εργαλεία εμπιστοσύνης και ασφάλειας και αξιολογήσεις για να βοηθήσει τους προγραμματιστές να χτίσουν υπεύθυνα με μοντέλα AI. Το Purple Llama συγκεντρώνει εργαλεία και αξιολογήσεις για να βοηθήσει την κοινότητα να οικοδομήσει υπεύθυνα με γενετικά μοντέλα AI. Η αρχική έκδοση περιλαμβάνει εστίαση στην ασφάλεια στον κυβερνοχώρο και στις διασφαλίσεις εισόδου και εξόδου LLM. Τα εξαρτήματα του έργου Purple Llama, συμπεριλαμβανομένου του μοντέλου Llama Guard, αδειοδοτούνται επιτρεπτά, επιτρέποντας τόσο την έρευνα όσο και την εμπορική χρήση.
Τώρα μπορείτε να χρησιμοποιήσετε το μοντέλο Llama Guard στο SageMaker JumpStart. Το SageMaker JumpStart είναι ο κόμβος μηχανικής εκμάθησης (ML) του Amazon Sage Maker που παρέχει πρόσβαση σε μοντέλα θεμελίωσης εκτός από ενσωματωμένους αλγόριθμους και πρότυπα λύσεων από άκρο σε άκρο για να σας βοηθήσει να ξεκινήσετε γρήγορα με την ML.
Σε αυτήν την ανάρτηση, περιγράφουμε τον τρόπο ανάπτυξης του μοντέλου Llama Guard και τη δημιουργία υπεύθυνων λύσεων τεχνητής νοημοσύνης.
Μοντέλο Llama Guard
Το Llama Guard είναι ένα νέο μοντέλο από τη Meta που παρέχει προστατευτικά κιγκλιδώματα εισόδου και εξόδου για αναπτύξεις LLM. Το Llama Guard είναι ένα ανοιχτά διαθέσιμο μοντέλο που αποδίδει ανταγωνιστικά σε κοινά ανοιχτά σημεία αναφοράς και παρέχει στους προγραμματιστές ένα προεκπαιδευμένο μοντέλο για να βοηθήσει στην άμυνα έναντι της δημιουργίας δυνητικά επικίνδυνων αποτελεσμάτων. Αυτό το μοντέλο έχει εκπαιδευτεί σε έναν συνδυασμό δημοσίως διαθέσιμων συνόλων δεδομένων για να επιτρέψει τον εντοπισμό κοινών τύπων δυνητικά επικίνδυνου ή παραβατικού περιεχομένου που μπορεί να σχετίζεται με ορισμένες περιπτώσεις χρήσης προγραμματιστών. Τελικά, το όραμα του μοντέλου είναι να επιτρέψει στους προγραμματιστές να προσαρμόσουν αυτό το μοντέλο για να υποστηρίξουν σχετικές περιπτώσεις χρήσης και να κάνουν αβίαστη την υιοθέτηση βέλτιστων πρακτικών και τη βελτίωση του ανοιχτού οικοσυστήματος.
Το Llama Guard μπορεί να χρησιμοποιηθεί ως συμπληρωματικό εργαλείο για τους προγραμματιστές ώστε να ενσωματωθούν στις δικές τους στρατηγικές μετριασμού, όπως για chatbots, εποπτεία περιεχομένου, εξυπηρέτηση πελατών, παρακολούθηση μέσων κοινωνικής δικτύωσης και εκπαίδευση. Διαβιβάζοντας περιεχόμενο που δημιουργείται από χρήστες μέσω του Llama Guard πριν το δημοσιεύσετε ή απαντήσετε σε αυτό, οι προγραμματιστές μπορούν να επισημάνουν την μη ασφαλή ή ακατάλληλη γλώσσα και να αναλάβουν δράση για να διατηρήσουν ένα ασφαλές περιβάλλον με σεβασμό.
Ας εξερευνήσουμε πώς μπορούμε να χρησιμοποιήσουμε το μοντέλο Llama Guard στο SageMaker JumpStart.
Μοντέλα θεμελίωσης στο SageMaker
Το SageMaker JumpStart παρέχει πρόσβαση σε μια σειρά μοντέλων από δημοφιλείς κόμβους μοντέλων, συμπεριλαμβανομένων των Hugging Face, PyTorch Hub και TensorFlow Hub, τα οποία μπορείτε να χρησιμοποιήσετε στη ροή εργασιών ανάπτυξης ML στο SageMaker. Οι πρόσφατες εξελίξεις στην ML οδήγησαν σε μια νέα κατηγορία μοντέλων που είναι γνωστά ως μοντέλα θεμελίωσης, τα οποία συνήθως εκπαιδεύονται σε δισεκατομμύρια παραμέτρους και είναι προσαρμόσιμα σε μια ευρεία κατηγορία περιπτώσεων χρήσης, όπως η σύνοψη κειμένων, η δημιουργία ψηφιακής τέχνης και η μετάφραση γλώσσας. Επειδή αυτά τα μοντέλα είναι ακριβά στην εκπαίδευση, οι πελάτες θέλουν να χρησιμοποιήσουν τα υπάρχοντα προεκπαιδευμένα μοντέλα θεμελίωσης και να τα προσαρμόσουν όπως απαιτείται, αντί να εκπαιδεύσουν οι ίδιοι αυτά τα μοντέλα. Το SageMaker παρέχει μια επιμελημένη λίστα μοντέλων από τα οποία μπορείτε να επιλέξετε στην κονσόλα SageMaker.
Μπορείτε πλέον να βρείτε μοντέλα θεμελίωσης από διαφορετικούς παρόχους μοντέλων στο SageMaker JumpStart, επιτρέποντάς σας να ξεκινήσετε γρήγορα με τα μοντέλα θεμελίωσης. Μπορείτε να βρείτε μοντέλα θεμελίωσης που βασίζονται σε διαφορετικές εργασίες ή παρόχους μοντέλων και να ελέγξετε εύκολα τα χαρακτηριστικά του μοντέλου και τους όρους χρήσης. Μπορείτε επίσης να δοκιμάσετε αυτά τα μοντέλα χρησιμοποιώντας ένα δοκιμαστικό γραφικό στοιχείο διεπαφής χρήστη. Όταν θέλετε να χρησιμοποιήσετε ένα μοντέλο βάσης σε κλίμακα, μπορείτε να το κάνετε εύκολα χωρίς να φύγετε από το SageMaker, χρησιμοποιώντας προκατασκευασμένα σημειωματάρια από παρόχους μοντέλων. Επειδή τα μοντέλα φιλοξενούνται και αναπτύσσονται σε AWS, μπορείτε να είστε βέβαιοι ότι τα δεδομένα σας, είτε χρησιμοποιούνται για αξιολόγηση είτε για χρήση του μοντέλου σε κλίμακα, δεν κοινοποιούνται ποτέ σε τρίτους.
Ας εξερευνήσουμε πώς μπορούμε να χρησιμοποιήσουμε το μοντέλο Llama Guard στο SageMaker JumpStart.
Ανακαλύψτε το μοντέλο Llama Guard στο SageMaker JumpStart
Μπορείτε να αποκτήσετε πρόσβαση σε μοντέλα βάσης Code Llama μέσω του SageMaker JumpStart στο SageMaker Studio UI και στο SageMaker Python SDK. Σε αυτήν την ενότητα, θα δούμε πώς να ανακαλύψετε τα μοντέλα Στούντιο Amazon SageMaker.
Το SageMaker Studio είναι ένα ολοκληρωμένο περιβάλλον ανάπτυξης (IDE) που παρέχει μια ενιαία οπτική διεπαφή βασισμένη στον ιστό, όπου μπορείτε να έχετε πρόσβαση σε ειδικά σχεδιασμένα εργαλεία για να εκτελέσετε όλα τα βήματα ανάπτυξης ML, από την προετοιμασία δεδομένων έως τη δημιουργία, την εκπαίδευση και την ανάπτυξη των μοντέλων σας ML. Για περισσότερες λεπτομέρειες σχετικά με το πώς να ξεκινήσετε και να ρυθμίσετε το SageMaker Studio, ανατρέξτε στο Στούντιο Amazon SageMaker.
Στο SageMaker Studio, μπορείτε να αποκτήσετε πρόσβαση στο SageMaker JumpStart, το οποίο περιέχει προεκπαιδευμένα μοντέλα, σημειωματάρια και προκατασκευασμένες λύσεις, κάτω από Προκατασκευασμένες και αυτοματοποιημένες λύσεις.
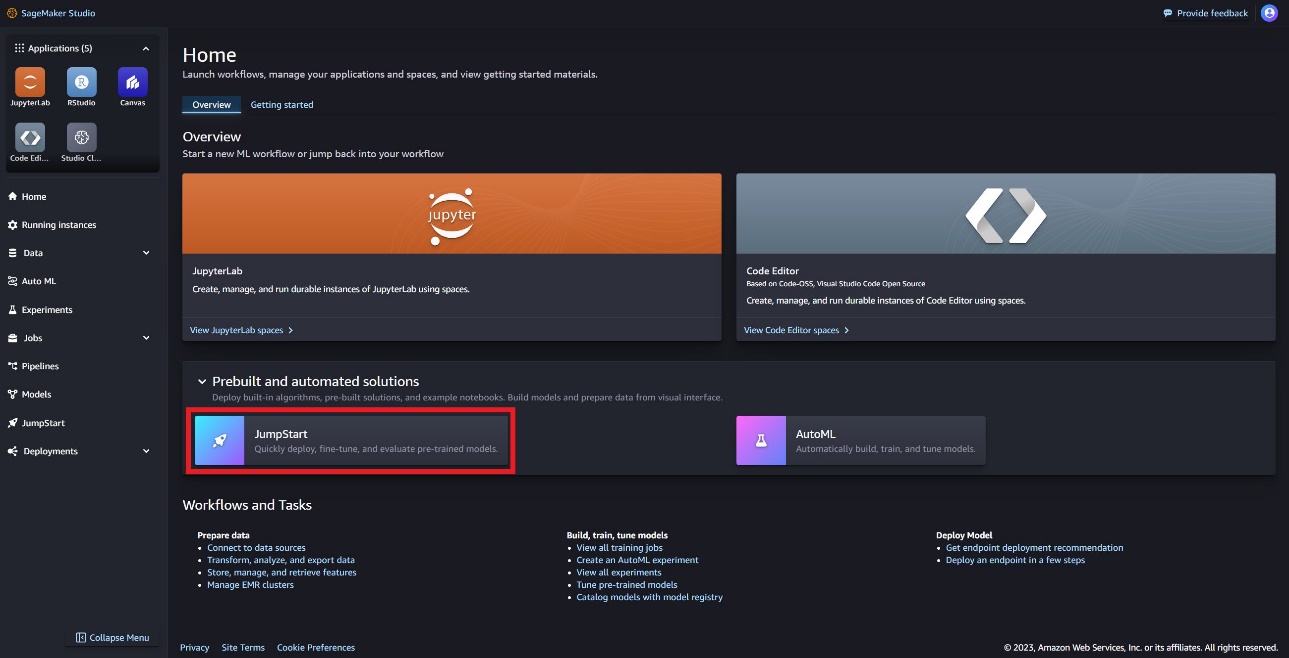
Στη σελίδα προορισμού του SageMaker JumpStart, μπορείτε να βρείτε το μοντέλο Llama Guard επιλέγοντας το κέντρο Meta ή αναζητώντας το Llama Guard.

Μπορείτε να επιλέξετε από μια ποικιλία παραλλαγών μοντέλων Llama, συμπεριλαμβανομένων των Llama Guard, Llama-2 και Code Llama.

Μπορείτε να επιλέξετε την κάρτα μοντέλου για να προβάλετε λεπτομέρειες σχετικά με το μοντέλο, όπως άδεια χρήσης, δεδομένα που χρησιμοποιούνται για την εκπαίδευση και τον τρόπο χρήσης. Θα βρείτε επίσης ένα Ανάπτυξη επιλογή, η οποία θα σας μεταφέρει σε μια σελίδα προορισμού όπου μπορείτε να δοκιμάσετε το συμπέρασμα με ένα παράδειγμα ωφέλιμου φορτίου.

Αναπτύξτε το μοντέλο με το SageMaker Python SDK
Μπορείτε να βρείτε τον κώδικα που δείχνει την ανάπτυξη του Llama Guard στο Amazon JumpStart και ένα παράδειγμα του τρόπου χρήσης του αναπτυγμένου μοντέλου στο αυτό Σημειωματάριο GitHub.
Στον ακόλουθο κώδικα, καθορίζουμε το αναγνωριστικό μοντέλου του διανομέα μοντέλου SageMaker και την έκδοση μοντέλου που θα χρησιμοποιηθούν κατά την ανάπτυξη του Llama Guard:
Τώρα μπορείτε να αναπτύξετε το μοντέλο χρησιμοποιώντας το SageMaker JumpStart. Ο παρακάτω κώδικας χρησιμοποιεί την προεπιλεγμένη παρουσία ml.g5.2xlarge για το τελικό σημείο συμπερασμάτων. Μπορείτε να αναπτύξετε το μοντέλο σε άλλους τύπους παρουσιών περνώντας instance_type στο JumpStartModel τάξη. Η ανάπτυξη μπορεί να διαρκέσει μερικά λεπτά. Για επιτυχή ανάπτυξη, πρέπει να αλλάξετε μη αυτόματα το accept_eula όρισμα στη μέθοδο ανάπτυξης του μοντέλου σε True.
Αυτό το μοντέλο αναπτύσσεται χρησιμοποιώντας το κοντέινερ βαθιάς εκμάθησης της δημιουργίας κειμένου (TGI). Τα αιτήματα συμπερασμάτων υποστηρίζουν πολλές παραμέτρους, συμπεριλαμβανομένων των εξής:
- μέγιστο μήκος – Το μοντέλο δημιουργεί κείμενο μέχρι να φτάσει το μήκος εξόδου (το οποίο περιλαμβάνει το μήκος του περιβάλλοντος εισαγωγής).
max_length. Εάν ορίζεται, πρέπει να είναι θετικός ακέραιος. - max_new_tokens – Το μοντέλο δημιουργεί κείμενο μέχρι να φτάσει το μήκος εξόδου (εξαιρουμένου του μήκους περιβάλλοντος εισαγωγής).
max_new_tokens. Εάν ορίζεται, πρέπει να είναι θετικός ακέραιος. - num_beams – Αυτό υποδεικνύει τον αριθμό των ακτίνων που χρησιμοποιούνται στην άπληστη αναζήτηση. Εάν ορίζεται, πρέπει να είναι ακέραιος αριθμός μεγαλύτερος ή ίσος με
num_return_sequences. - no_repeat_ngram_size – Το μοντέλο διασφαλίζει ότι μια ακολουθία λέξεων του
no_repeat_ngram_sizeδεν επαναλαμβάνεται στην ακολουθία εξόδου. Εάν ορίζεται, πρέπει να είναι θετικός ακέραιος μεγαλύτερος από 1. - θερμοκρασία – Αυτή η παράμετρος ελέγχει την τυχαιότητα στην έξοδο. Ένα υψηλότερο
temperatureκαταλήγει σε μια ακολουθία εξόδου με λέξεις χαμηλής πιθανότητας και μια χαμηλότερηtemperatureκαταλήγει σε μια ακολουθία εξόδου με λέξεις υψηλής πιθανότητας. Ανtemperatureείναι 0, καταλήγει σε άπληστη αποκωδικοποίηση. Εάν καθορίζεται, πρέπει να είναι θετικός float. - νωρίς_διακοπή - Αν
True, η δημιουργία κειμένου ολοκληρώνεται όταν όλες οι υποθέσεις δέσμης φτάσουν στο τέλος της πρότασης. Εάν ορίζεται, πρέπει να είναι Boolean. - do_sample - Αν
True, το μοντέλο λαμβάνει δείγματα της επόμενης λέξης σύμφωνα με την πιθανότητα. Εάν ορίζεται, πρέπει να είναι Boolean. - top_k – Σε κάθε βήμα δημιουργίας κειμένου, το μοντέλο λαμβάνει δείγματα μόνο από το
top_kπιθανότατα λόγια. Εάν ορίζεται, πρέπει να είναι θετικός ακέραιος. - top_p – Σε κάθε βήμα δημιουργίας κειμένου, το μοντέλο λαμβάνει δείγματα από το μικρότερο δυνατό σύνολο λέξεων με αθροιστική πιθανότητα
top_p. Εάν καθορίζεται, πρέπει να είναι float μεταξύ 0–1. - επιστροφή_πλήρους_κειμένου - Αν
True, το κείμενο εισαγωγής θα είναι μέρος του παραγόμενου κειμένου εξόδου. Εάν ορίζεται, πρέπει να είναι Boolean. Η προεπιλεγμένη τιμή είναιFalse. - στάση – Εάν ορίζεται, πρέπει να είναι μια λίστα συμβολοσειρών. Η δημιουργία κειμένου σταματά αν δημιουργηθεί οποιαδήποτε από τις καθορισμένες συμβολοσειρές.
Επικαλέστε ένα τελικό σημείο του SageMaker
Μπορείτε να ανακτήσετε μέσω προγραμματισμού παραδείγματα ωφέλιμων φορτίων από το JumpStartModel αντικείμενο. Αυτό θα σας βοηθήσει να ξεκινήσετε γρήγορα παρατηρώντας προδιαμορφωμένες προτροπές οδηγιών που μπορεί να απορροφήσει το Llama Guard. Δείτε τον παρακάτω κώδικα:
Αφού εκτελέσετε το προηγούμενο παράδειγμα, μπορείτε να δείτε πώς θα μορφοποιηθεί η είσοδος και η έξοδος σας από το Llama Guard:
Παρόμοια με το Llama-2, το Llama Guard χρησιμοποιεί ειδικά κουπόνια για να υποδείξει οδηγίες ασφαλείας στο μοντέλο. Γενικά, το ωφέλιμο φορτίο πρέπει να ακολουθεί την παρακάτω μορφή:
Η προτροπή χρήστη εμφανίζεται ως {user_prompt} παραπάνω, μπορεί να περιλαμβάνει περαιτέρω ενότητες για ορισμούς κατηγοριών περιεχομένου και συνομιλίες, οι οποίες έχουν την εξής μορφή:
Στην επόμενη ενότητα, συζητάμε τις προτεινόμενες προεπιλεγμένες τιμές για τους ορισμούς της εργασίας, της κατηγορίας περιεχομένου και των εντολών. Η συζήτηση πρέπει να εναλλάσσεται μεταξύ τους User και Agent κείμενο ως εξής:
Συντονίστε μια συνομιλία με το Llama-2 Chat
Μπορείτε τώρα να αναπτύξετε ένα τελικό σημείο του μοντέλου συνομιλίας Llama-2 7B για συνομιλία και, στη συνέχεια, να χρησιμοποιήσετε το Llama Guard για να ελέγξετε την εισαγωγή και την έξοδο κειμένου που προέρχεται από το Llama-2 7B Chat.
Σας δείχνουμε το παράδειγμα της εισόδου και της εξόδου του μοντέλου συνομιλίας Llama-2 7B που εποπτεύεται μέσω του Llama Guard, αλλά μπορείτε να χρησιμοποιήσετε το Llama Guard για εποπτεία με οποιοδήποτε LLM της επιλογής σας.
Αναπτύξτε το μοντέλο με τον ακόλουθο κώδικα:
Τώρα μπορείτε να ορίσετε το πρότυπο εργασιών Llama Guard. Οι κατηγορίες μη ασφαλούς περιεχομένου μπορούν να προσαρμοστούν όπως επιθυμείτε για τη συγκεκριμένη περίπτωση χρήσης σας. Μπορείτε να ορίσετε σε απλό κείμενο τη σημασία κάθε κατηγορίας περιεχομένου, συμπεριλαμβανομένου του περιεχομένου που πρέπει να επισημανθεί ως μη ασφαλές και ποιο περιεχόμενο θα πρέπει να επιτρέπεται ως ασφαλές. Δείτε τον παρακάτω κώδικα:
Στη συνέχεια, ορίζουμε βοηθητικές συναρτήσεις format_chat_messages και format_guard_messages για να μορφοποιήσετε την προτροπή για το μοντέλο συνομιλίας και για το μοντέλο Llama Guard που απαιτούσε ειδικά διακριτικά:
Στη συνέχεια, μπορείτε να χρησιμοποιήσετε αυτές τις βοηθητικές λειτουργίες σε ένα παράδειγμα προτροπής εισαγωγής μηνύματος για να εκτελέσετε την εισαγωγή παραδείγματος μέσω του Llama Guard για να προσδιορίσετε εάν το περιεχόμενο του μηνύματος είναι ασφαλές:
Η ακόλουθη έξοδος υποδεικνύει ότι το μήνυμα είναι ασφαλές. Μπορεί να παρατηρήσετε ότι η προτροπή περιλαμβάνει λέξεις που μπορεί να σχετίζονται με βία, αλλά, σε αυτήν την περίπτωση, ο Llama Guard είναι σε θέση να κατανοήσει το πλαίσιο σε σχέση με τις οδηγίες και τους ορισμούς μη ασφαλών κατηγοριών που δώσαμε προηγουμένως και να προσδιορίσει ότι είναι ένα ασφαλές μήνυμα και όχι που σχετίζονται με τη βία.
Τώρα που έχετε επιβεβαιώσει ότι το κείμενο εισαγωγής είναι ασφαλές σε σχέση με τις κατηγορίες περιεχομένου Llama Guard, μπορείτε να μεταβιβάσετε αυτό το ωφέλιμο φορτίο στο αναπτυσσόμενο μοντέλο Llama-2 7B για να δημιουργήσετε κείμενο:
Ακολουθεί η απάντηση του μοντέλου:
Τέλος, μπορεί να θέλετε να επιβεβαιώσετε ότι το κείμενο απάντησης από το μοντέλο έχει καθοριστεί ότι περιέχει ασφαλές περιεχόμενο. Εδώ, επεκτείνετε την απόκριση εξόδου LLM στα μηνύματα εισόδου και εκτελείτε ολόκληρη αυτήν τη συνομιλία μέσω του Llama Guard για να διασφαλίσετε ότι η συνομιλία είναι ασφαλής για την εφαρμογή σας:
Ενδέχεται να δείτε την ακόλουθη έξοδο, υποδεικνύοντας ότι η απάντηση από το μοντέλο συνομιλίας είναι ασφαλής:
εκκαθάριση
Αφού δοκιμάσετε τα τελικά σημεία, βεβαιωθείτε ότι έχετε διαγράψει τα τελικά σημεία συμπερασμάτων του SageMaker και το μοντέλο για να αποφύγετε χρεώσεις.
Συμπέρασμα
Σε αυτήν την ανάρτηση, σας δείξαμε πώς μπορείτε να εποπτεύσετε τις εισόδους και τις εξόδους χρησιμοποιώντας το Llama Guard και να τοποθετήσετε προστατευτικά κιγκλιδώματα για εισόδους και εξόδους από LLM στο SageMaker JumpStart.
Καθώς η τεχνητή νοημοσύνη συνεχίζει να προοδεύει, είναι σημαντικό να δοθεί προτεραιότητα στην υπεύθυνη ανάπτυξη και ανάπτυξη. Εργαλεία όπως το CyberSecEval του Purple Llama και το Llama Guard είναι καθοριστικής σημασίας για την προώθηση της ασφαλούς καινοτομίας, προσφέροντας έγκαιρη αναγνώριση κινδύνου και καθοδήγηση μετριασμού για γλωσσικά μοντέλα. Αυτά θα πρέπει να ενσωματωθούν στη διαδικασία σχεδιασμού της τεχνητής νοημοσύνης για να αξιοποιήσει πλήρως τις δυνατότητές του για LLM ηθικά από την Ημέρα 1.
Δοκιμάστε το Llama Guard και άλλα μοντέλα βάσης στο SageMaker JumpStart σήμερα και πείτε μας τα σχόλιά σας!
Αυτή η καθοδήγηση είναι μόνο για ενημερωτικούς σκοπούς. Θα πρέπει ακόμα να πραγματοποιήσετε τη δική σας ανεξάρτητη αξιολόγηση και να λάβετε μέτρα για να διασφαλίσετε ότι συμμορφώνεστε με τις δικές σας συγκεκριμένες πρακτικές και πρότυπα ποιοτικού ελέγχου, καθώς και με τους τοπικούς κανόνες, νόμους, κανονισμούς, άδειες και όρους χρήσης που ισχύουν για εσάς, το περιεχόμενό σας, και το μοντέλο τρίτου κατασκευαστή που αναφέρεται σε αυτήν την καθοδήγηση. Η AWS δεν έχει κανέναν έλεγχο ή εξουσία επί του μοντέλου τρίτου κατασκευαστή που αναφέρεται σε αυτήν την καθοδήγηση και δεν παρέχει καμία δήλωση ή εγγύηση ότι το μοντέλο τρίτου κατασκευαστή είναι ασφαλές, απαλλαγμένο από ιούς, λειτουργικό ή συμβατό με το περιβάλλον παραγωγής και τα πρότυπά σας. Η AWS δεν προβαίνει σε δηλώσεις, εγγυήσεις ή εγγυήσεις ότι οποιαδήποτε πληροφορία σε αυτήν την καθοδήγηση θα έχει ως αποτέλεσμα ένα συγκεκριμένο αποτέλεσμα ή αποτέλεσμα.
Σχετικά με τους συγγραφείς
 Δόκτωρ Kyle Ulrich είναι Εφαρμοσμένος Επιστήμονας με το Ενσωματωμένοι αλγόριθμοι Amazon SageMaker ομάδα. Τα ερευνητικά του ενδιαφέροντα περιλαμβάνουν κλιμακωτούς αλγόριθμους μηχανικής μάθησης, όραση υπολογιστή, χρονοσειρές, μη παραμετρικές Μπεϋζιανές και διεργασίες Gauss. Το διδακτορικό του είναι από το Πανεπιστήμιο Duke και έχει δημοσιεύσει εργασίες στα NeurIPS, Cell και Neuron.
Δόκτωρ Kyle Ulrich είναι Εφαρμοσμένος Επιστήμονας με το Ενσωματωμένοι αλγόριθμοι Amazon SageMaker ομάδα. Τα ερευνητικά του ενδιαφέροντα περιλαμβάνουν κλιμακωτούς αλγόριθμους μηχανικής μάθησης, όραση υπολογιστή, χρονοσειρές, μη παραμετρικές Μπεϋζιανές και διεργασίες Gauss. Το διδακτορικό του είναι από το Πανεπιστήμιο Duke και έχει δημοσιεύσει εργασίες στα NeurIPS, Cell και Neuron.
 Έβαν Κράβιτς είναι μηχανικός λογισμικού στο Amazon Web Services, που εργάζεται στο SageMaker JumpStart. Ενδιαφέρεται για τη συσχέτιση της μηχανικής μάθησης με το cloud computing. Ο Έβαν έλαβε το προπτυχιακό του πτυχίο από το Πανεπιστήμιο Κορνέλ και το μεταπτυχιακό του από το Πανεπιστήμιο της Καλιφόρνια στο Μπέρκλεϋ. Το 2021, παρουσίασε μια εργασία για τα αντίθετα νευρωνικά δίκτυα στο συνέδριο ICLR. Στον ελεύθερο χρόνο του, ο Έβαν απολαμβάνει να μαγειρεύει, να ταξιδεύει και να τρέχει στη Νέα Υόρκη.
Έβαν Κράβιτς είναι μηχανικός λογισμικού στο Amazon Web Services, που εργάζεται στο SageMaker JumpStart. Ενδιαφέρεται για τη συσχέτιση της μηχανικής μάθησης με το cloud computing. Ο Έβαν έλαβε το προπτυχιακό του πτυχίο από το Πανεπιστήμιο Κορνέλ και το μεταπτυχιακό του από το Πανεπιστήμιο της Καλιφόρνια στο Μπέρκλεϋ. Το 2021, παρουσίασε μια εργασία για τα αντίθετα νευρωνικά δίκτυα στο συνέδριο ICLR. Στον ελεύθερο χρόνο του, ο Έβαν απολαμβάνει να μαγειρεύει, να ταξιδεύει και να τρέχει στη Νέα Υόρκη.
 Rachna Chadha είναι ένας κύριος αρχιτέκτονας λύσεων AI/ML σε στρατηγικούς λογαριασμούς στο AWS. Η Rachna είναι αισιόδοξη που πιστεύει ότι η ηθική και υπεύθυνη χρήση της τεχνητής νοημοσύνης μπορεί να βελτιώσει την κοινωνία στο μέλλον και να φέρει οικονομική και κοινωνική ευημερία. Στον ελεύθερο χρόνο της, στη Ράχνα αρέσει να περνά χρόνο με την οικογένειά της, να κάνει πεζοπορία και να ακούει μουσική.
Rachna Chadha είναι ένας κύριος αρχιτέκτονας λύσεων AI/ML σε στρατηγικούς λογαριασμούς στο AWS. Η Rachna είναι αισιόδοξη που πιστεύει ότι η ηθική και υπεύθυνη χρήση της τεχνητής νοημοσύνης μπορεί να βελτιώσει την κοινωνία στο μέλλον και να φέρει οικονομική και κοινωνική ευημερία. Στον ελεύθερο χρόνο της, στη Ράχνα αρέσει να περνά χρόνο με την οικογένειά της, να κάνει πεζοπορία και να ακούει μουσική.
 Δρ Ashish Khetan είναι Ανώτερος Εφαρμοσμένος Επιστήμονας με ενσωματωμένους αλγόριθμους του Amazon SageMaker και βοηθά στην ανάπτυξη αλγορίθμων μηχανικής μάθησης. Πήρε το διδακτορικό του από το Πανεπιστήμιο του Illinois Urbana-Champaign. Είναι ενεργός ερευνητής στη μηχανική μάθηση και στα στατιστικά συμπεράσματα και έχει δημοσιεύσει πολλές εργασίες σε συνέδρια NeurIPS, ICML, ICLR, JMLR, ACL και EMNLP.
Δρ Ashish Khetan είναι Ανώτερος Εφαρμοσμένος Επιστήμονας με ενσωματωμένους αλγόριθμους του Amazon SageMaker και βοηθά στην ανάπτυξη αλγορίθμων μηχανικής μάθησης. Πήρε το διδακτορικό του από το Πανεπιστήμιο του Illinois Urbana-Champaign. Είναι ενεργός ερευνητής στη μηχανική μάθηση και στα στατιστικά συμπεράσματα και έχει δημοσιεύσει πολλές εργασίες σε συνέδρια NeurIPS, ICML, ICLR, JMLR, ACL και EMNLP.
 Καρλ Άλμπερτσεν ηγείται προϊόντων, μηχανικής και επιστήμης για τους αλγόριθμους Amazon SageMaker και το JumpStart, τον κόμβο μηχανικής μάθησης του SageMaker. Είναι παθιασμένος με την εφαρμογή μηχανικής μάθησης για να ξεκλειδώσει την επιχειρηματική αξία.
Καρλ Άλμπερτσεν ηγείται προϊόντων, μηχανικής και επιστήμης για τους αλγόριθμους Amazon SageMaker και το JumpStart, τον κόμβο μηχανικής μάθησης του SageMaker. Είναι παθιασμένος με την εφαρμογή μηχανικής μάθησης για να ξεκλειδώσει την επιχειρηματική αξία.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/
- :έχει
- :είναι
- :δεν
- :που
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 2021
- 39
- 7
- 8
- 9
- a
- Ικανός
- Σχετικά με εμάς
- πάνω από
- Αποδέχομαι
- πρόσβαση
- Σύμφωνα με
- Λογαριασμοί
- Πράξη
- Ενέργειες
- ενεργειών
- ενεργός
- δραστηριοτήτων
- πραγματικός
- Επιπλέον
- ρυθμίζεται
- ενστερνίζομαι
- εκ των προτέρων
- προκαταβολές
- αντιφατική
- συμβουλές
- κατά
- Πράκτορας
- AI
- Μοντέλα AI
- AI / ML
- Αλκοόλ
- αλγόριθμοι
- Όλα
- Επίσης
- Amazon
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon υπηρεσίες Web
- an
- και
- Ανακοινώστε
- απάντηση
- κάθε
- Εφαρμογή
- εφαρμοσμένος
- Εφαρμογή
- εφαρμόζοντας
- κατάλληλος
- ΕΙΝΑΙ
- επιχείρημα
- επιχειρήματα
- Τέχνη
- AS
- εκτίμηση
- βοηθήσει
- Βοηθός
- συσχετισμένη
- βέβαιος
- At
- εξουσία
- Αυτοματοποιημένη
- διαθέσιμος
- αποφύγετε
- AWS
- βασίζονται
- βασικός
- Bayesian
- BE
- Πλάτος
- επειδή
- ήταν
- πριν
- αρχίζουν
- συμπεριφορά
- πιστεύει
- παρακάτω
- αναφοράς
- Berkeley
- ΚΑΛΎΤΕΡΟΣ
- βέλτιστες πρακτικές
- μεταξύ
- δισεκατομμύρια
- σώμα
- και οι δύο
- φέρω
- Φέρνει
- χτίζω
- Κτίριο
- ενσωματωμένο
- επιχείρηση
- αλλά
- by
- Καλιφόρνια
- CAN
- κάνναβης
- κάρτα
- περίπτωση
- περιπτώσεις
- κατηγορίες
- κατηγορία
- κύτταρο
- προκλήσεις
- ευκαιρία
- αλλαγή
- χαρακτηριστικά
- φορτία
- chat
- chatbots
- έλεγχος
- χημική ουσία
- επιλογή
- Επιλέξτε
- επιλέγοντας
- Πόλη
- τάξη
- καθαρός
- Backup
- cloud computing
- κωδικός
- χρώμα
- ερχομός
- εμπορικός
- δεσμεύεται
- Κοινός
- κοινότητα
- σύμφωνος
- συμμορφώνονται
- εξαρτήματα
- σύνθεση
- υπολογιστή
- Computer Vision
- χρήση υπολογιστή
- Διάσκεψη
- συνέδρια
- Επιβεβαιώνω
- ΕΠΙΒΕΒΑΙΩΜΕΝΟΣ
- συμβολή
- πρόξενος
- κατανάλωση
- περιέχουν
- Δοχείο
- Περιέχει
- περιεχόμενο
- μετριοπάθεια περιεχομένου
- συμφραζόμενα
- συνεχίζεται
- έλεγχος
- ελέγχεται
- ελέγχους
- Συνομιλία
- ομιλητικός
- συνομιλίες
- μαγείρεμα
- cornell
- θα μπορούσε να
- δημιουργία
- δημιουργία
- Εγκλήματα
- εγκληματίας
- κρίσιμης
- επιμέλεια
- πελάτης
- Εξυπηρέτηση πελατών
- Πελάτες
- προσαρμόσετε
- στον κυβερνοχώρο
- κυβερνασφάλεια
- κύκλος
- ημερομηνία
- σύνολα δεδομένων
- ημέρα
- Αποκρυπτογράφηση
- βαθύς
- βαθιά μάθηση
- Προεπιλογή
- ορίζεται
- ορισμοί
- Πτυχίο
- παρατάσσω
- αναπτυχθεί
- ανάπτυξη
- ανάπτυξη
- αναπτύξεις
- Υπηρεσίες
- διαδικασία σχεδιασμού
- επιθυμία
- επιθυμητή
- λεπτομερής
- καθέκαστα
- Ανίχνευση
- Προσδιορίστε
- αποφασισμένος
- ανάπτυξη
- Εργολάβος
- προγραμματιστές
- Ανάπτυξη
- DICT
- διαφορετικές
- ψηφιακό
- ψηφιακής τέχνης
- Αναπηρία
- ανακαλύπτουν
- Διάκριση
- συζητήσουν
- do
- κάνει
- Ναρκωτικά
- Δούκας
- πανεπιστήμιο του Δούκα
- e
- κάθε
- Νωρίτερα
- Νωρίς
- εύκολα
- Οικονομικός
- οικοσύστημα
- Εκπαίδευση
- αποτελέσματα
- ΧΩΡΙΣ κοπο
- ενεργοποιήσετε
- ενεργοποίηση
- ενθαρρύνει
- τέλος
- από άκρη σε άκρη
- Τελικό σημείο
- τελικά σημεία
- ασκούν
- μηχανικός
- Μηχανική
- εξασφαλίζω
- εξασφαλίζει
- Περιβάλλον
- ίσος
- ειδικά
- Αιθέρας (ΕΤΗ)
- ηθικά
- αξιολογώντας
- αξιολογήσεις
- εκδηλώσεις
- παράδειγμα
- Εκτός
- εξαίρεση
- ενθουσιασμένοι
- Με εξαίρεση
- εκτέλεση
- υφιστάμενα
- ακριβά
- διερευνήσει
- ρητή
- επεκτείνουν
- Πρόσωπο
- αντιμετωπίζουν
- ψευδής
- οικογένεια
- Χαρακτηρίζοντας
- λίγοι
- οικονομικός
- οικονομικά εγκλήματα
- Εύρεση
- πυροβόλων όπλων
- Όνομα
- σημαία
- φλοτέρ
- Συγκέντρωση
- ακολουθήστε
- ακολουθείται
- Εξής
- εξής
- Για
- μορφή
- προώθηση
- Θεμέλιο
- Δωρεάν
- από
- πλήρη
- λειτουργίες
- περαιτέρω
- μελλοντικός
- Φύλο
- General
- παράγουν
- παράγεται
- δημιουργεί
- παραγωγής
- γενεά
- γενετική
- Παραγωγική τεχνητή νοημοσύνη
- παίρνω
- GitHub
- δεδομένου
- Δίνοντας
- Go
- μετάβαση
- πήρε
- μεγαλύτερη
- Άπληστος
- εγγυήσεις
- φρουρά
- καθοδήγηση
- ΟΠΛΑ
- βλάψει
- ιπποσκευή
- μισώ
- Έχω
- he
- Υγεία
- βοήθεια
- βοηθά
- αυτήν
- εδώ
- υψηλότερο
- πεζοπορία
- του
- ιστορικών
- φιλοξενείται
- Πως
- Πώς να
- HTML
- HTTPS
- Hub
- Hubs
- i
- ICLR
- ID
- Αναγνώριση
- Ταυτότητα
- if
- παράνομος
- Ιλλινόις
- αμέσως
- εισαγωγή
- βελτίωση
- in
- περιλαμβάνουν
- περιλαμβάνει
- Συμπεριλαμβανομένου
- ανεξάρτητος
- υποδεικνύω
- υποδηλώνει
- υποδεικνύοντας
- πληροφορίες
- Ενημερωτικό
- βαθιά ριζωμένος
- αρχικός
- Πρωτοβουλία
- Καινοτομία
- εισαγωγή
- είσοδοι
- παράδειγμα
- οδηγίες
- ενόργανος
- ενσωματώσει
- ενσωματωθεί
- ενδιαφερόμενος
- συμφέροντα
- περιβάλλον λειτουργίας
- σε
- συμμετοχή
- IT
- ΤΟΥ
- jpg
- Σκοτώστε
- Ξέρω
- γνωστός
- Kyle
- προσγείωση
- σελίδα προορισμού
- Γλώσσα
- large
- Επίθετο
- Του νόμου
- Οδηγεί
- μάθηση
- αφήνοντας
- Μήκος
- ας
- Άδεια
- Άδεια
- άδειες
- Μου αρέσει
- πιθανότητα
- Πιθανός
- συμπαθεί
- Περιωρισμένος
- γραμμή
- linux
- Λιστα
- Ακούγοντας
- Είδος μικρής καμήλας
- τοπικός
- ΦΑΊΝΕΤΑΙ
- χαμηλότερα
- μηχανή
- μάθηση μηχανής
- διατηρήσουν
- κάνω
- χειροκίνητα
- κατασκευάζονται
- πολοί
- κύριοι
- Ενδέχεται..
- νόημα
- μέτρα
- Εικόνες / Βίντεο
- ψυχική
- Ψυχική υγεία
- μήνυμα
- μηνύματα
- Meta
- μέθοδος
- μέθοδοι
- ενδέχεται να
- πρακτικά
- μείωση
- μείγμα
- ML
- μοντέλο
- μοντέλα
- μέτριος
- μετριοπάθεια
- παρακολούθηση
- περισσότερο
- πλέον
- Μουσική
- πρέπει
- πρέπει να διαβάσετε
- εθνικός
- που απαιτούνται
- δίκτυα
- Νευρικός
- νευρωνικά δίκτυα
- NeurIPS
- ποτέ
- Νέα
- Νέα Υόρκη
- Νέα Υόρκη
- επόμενη
- Όχι.
- σημειωματάριο
- φορητούς υπολογιστές
- Ειδοποίηση..
- τώρα
- αριθμός
- αντικείμενο
- of
- προσφορά
- on
- ONE
- αποκλειστικά
- ανοίξτε
- φανερά
- επιχειρήσεων
- Επιλογή
- Επιλογές
- or
- Προέλευση
- ΑΛΛΑ
- δικός μας
- έξω
- Αποτέλεσμα
- παραγωγή
- εξόδους
- επί
- δική
- ιδιοκτησία
- σελίδα
- Χαρτί
- χαρτιά
- παράμετρος
- παράμετροι
- μέρος
- Ειδικότερα
- μέρη
- passieren
- Πέρασμα
- παθιασμένος
- People
- για
- εκτελέσει
- εκτελεί
- person
- προσωπικός
- phd
- Σκέτη
- σχέδιο
- σχεδιασμό
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- πολιτική
- Δημοφιλής
- θετικός
- δυνατός
- Θέση
- δυναμικού
- ενδεχομένως
- πρακτικές
- προηγείται
- Predictor
- προετοιμασία
- παρουσιάζονται
- πρόληψη
- Κύριος
- Δώστε προτεραιότητα
- πιθανότητα
- διαδικασια μας
- Διεργασίες
- Προϊόν
- παραγωγή
- σχέδιο
- προτρέπει
- ευημερία
- παρέχουν
- παρέχεται
- Παρόχους υπηρεσιών
- παρέχει
- δημοσίως
- δημοσιεύθηκε
- Δημοσιεύσεις
- σκοποί
- βάζω
- Python
- pytorch
- ποιότητα
- γρήγορα
- Αγώνας
- τυχαία
- σειρά
- μάλλον
- φθάσουν
- Φτάνει
- Διάβασε
- έλαβε
- πρόσφατος
- συνιστάται
- παραπέμπω
- σχετικά με
- ρυθμίζονται
- κανονισμοί
- σχετίζεται με
- απελευθερώνουν
- θρησκεία
- επανειλημμένες
- αντικαθιστώ
- αιτήματα
- απαιτείται
- έρευνα
- ερευνητής
- Υποστηρικτικό υλικό
- σεβασμός
- απαντώντας
- απάντησης
- υπεύθυνος
- αξιοπίστως
- ΠΕΡΙΦΕΡΕΙΑ
- αποτέλεσμα
- Αποτελέσματα
- απόδοση
- ανασκόπηση
- Αύξηση
- Κίνδυνος
- Επικίνδυνος
- οδικός χάρτης
- Ρόλος
- ρόλους
- κανόνες
- τρέξιμο
- τρέχει
- ένα ασφαλές
- διασφαλίσεις
- Ασφάλεια
- σοφός
- Συμπεράσματα SageMaker
- επεκτάσιμη
- Κλίμακα
- Επιστήμη
- Επιστήμονας
- SDK
- Αναζήτηση
- αναζήτηση
- Δεύτερος
- Τμήμα
- τμήματα
- προστατευμένο περιβάλλον
- ασφάλεια
- δείτε
- επιλέξτε
- αρχαιότερος
- ευαίσθητος
- ποινή
- συναισθήματα
- Ακολουθία
- Σειρές
- υπηρεσία
- Υπηρεσίες
- σειρά
- Σεξουαλικός
- Shared
- θα πρέπει να
- δείχνουν
- έδειξε
- επίδειξη
- παρουσιάζεται
- ενιαίας
- So
- Μ.Κ.Δ
- social media
- Κοινωνία
- λογισμικό
- Μηχανικός Λογισμικού
- λύση
- Λύσεις
- ειδική
- συγκεκριμένες
- καθορίζεται
- Δαπάνες
- πρότυπα
- ξεκίνησε
- Ξεκινήστε
- στατιστικός
- στατιστική
- Βήμα
- Βήματα
- Ακόμη
- Διακόπτει
- Στρατηγική
- στρατηγικές
- στούντιο
- επιτυχής
- τέτοιος
- Αυτοκτονία
- υποστήριξη
- Υποστηρίζει
- βέβαιος
- σύνταξη
- σύστημα
- συστήματα
- Πάρτε
- Έργο
- εργασίες
- πρότυπο
- πρότυπα
- tensorflow
- όροι
- δοκιμή
- δοκιμαστεί
- κείμενο
- δημιουργία κειμένου
- από
- ότι
- Η
- Το μέλλον
- οι πληροφορίες
- κλοπή
- τους
- Τους
- τους
- τότε
- Εκεί.
- Αυτοί
- αυτοί
- Τρίτος
- τρίτους
- τρίτους
- αυτό
- εκείνοι
- Μέσω
- ώρα
- Χρονική σειρά
- προς την
- καπνός
- σήμερα
- μαζι
- ένδειξη
- κουπόνια
- εργαλείο
- εργαλεία
- Θέματα
- διακίνησης
- Τρένο
- εκπαιδευμένο
- Εκπαίδευση
- Μετάφραση
- Ταξίδια
- αληθής
- Εμπιστευθείτε
- προσπαθώ
- ΣΤΡΟΦΗ
- τύποι
- συνήθως
- ui
- τελικά
- υπό
- καταλαβαίνω
- πανεπιστήμιο
- Πανεπιστήμιο της Καλιφόρνια
- ξεκλειδώσετε
- μέχρι
- us
- Χρήση
- χρήση
- περίπτωση χρήσης
- μεταχειρισμένος
- Χρήστες
- χρησιμοποιεί
- χρησιμοποιώντας
- αξία
- Αξίες
- ποικιλία
- εκδοχή
- Δες
- παραβιαστεί
- Παραβίαση
- όραμα
- οπτικές
- walk
- θέλω
- Τρόπος..
- we
- Όπλα
- ιστός
- διαδικτυακές υπηρεσίες
- Web-based
- Τι
- πότε
- αν
- Ποιό
- Ο ΟΠΟΊΟΣ
- ολόκληρο
- ευρύς
- θα
- με
- εντός
- χωρίς
- λέξη
- λόγια
- Εργασία
- ροής εργασίας
- εργαζόμενος
- θα
- Υόρκη
- εσείς
- Σας
- zephyrnet