Αυτή είναι μια guest post του AK Roy από την Qualcomm AI.
Amazon Elastic Compute Cloud (Amazon EC2) Οι παρουσίες DL2q, που υποστηρίζονται από επιταχυντές Qualcomm AI 100 Standard, μπορούν να χρησιμοποιηθούν για την οικονομική ανάπτυξη φόρτου εργασίας βαθιάς εκμάθησης (DL) στο cloud. Μπορούν επίσης να χρησιμοποιηθούν για την ανάπτυξη και την επικύρωση της απόδοσης και της ακρίβειας των φόρτων εργασίας DL που θα αναπτυχθούν σε συσκευές Qualcomm. Οι περιπτώσεις DL2q είναι οι πρώτες περιπτώσεις που έφεραν την τεχνολογία τεχνητής νοημοσύνης (AI) της Qualcomm στο cloud.
Με οκτώ επιταχυντές Qualcomm AI 100 Standard και 128 GiB συνολικής μνήμης επιταχυντή, οι πελάτες μπορούν επίσης να χρησιμοποιήσουν παρουσίες DL2q για να εκτελέσουν δημοφιλείς εφαρμογές τεχνητής νοημοσύνης, όπως δημιουργία περιεχομένου, σύνοψη κειμένου και εικονικούς βοηθούς, καθώς και κλασικές εφαρμογές τεχνητής νοημοσύνης για επεξεργασία φυσικής γλώσσας και όραση υπολογιστή. Επιπλέον, οι επιταχυντές Qualcomm AI 100 διαθέτουν την ίδια τεχνολογία AI που χρησιμοποιείται σε smartphone, αυτόνομη οδήγηση, προσωπικούς υπολογιστές και ακουστικά εκτεταμένης πραγματικότητας, επομένως οι περιπτώσεις DL2q μπορούν να χρησιμοποιηθούν για την ανάπτυξη και την επικύρωση αυτών των φόρτων εργασίας AI πριν από την ανάπτυξη.
Νέα στιγμιότυπα του DL2q
Κάθε παρουσία DL2q ενσωματώνει οκτώ επιταχυντές Qualcomm Cloud AI100, με συνολική απόδοση άνω των 2.8 PetaOps απόδοσης συμπερασμάτων Int8 και 1.4 PetaFlops απόδοσης συμπερασμάτων FP16. Το παράδειγμα έχει συνολικά 112 πυρήνες AI, χωρητικότητα μνήμης επιταχυντή 128 GB και εύρος ζώνης μνήμης 1.1 TB ανά δευτερόλεπτο.
Κάθε παρουσία DL2q έχει 96 vCPU, χωρητικότητα μνήμης συστήματος 768 GB και υποστηρίζει εύρος ζώνης δικτύου 100 Gbps καθώς και Amazon Elastic Block Store (Amazon EBS) αποθήκευση 19 Gbps.
| Όνομα παράδειγμα | vCPU | Επιταχυντές Cloud AI100 | Μνήμη επιταχυντή | Μνήμη γκαζιού BW (συγκεντρωτική) | Μνήμη για παράδειγμα | Ενδεικτική δικτύωση | Εύρος ζώνης αποθήκευσης (Amazon EBS). |
| DL2q.24xlarge | 96 | 8 | 128 GB | 1.088 TB / s | 768 GB | 100 Gbps | 19 Gbps |
Καινοτομία επιταχυντή Qualcomm Cloud AI100
Το σύστημα επιτάχυνσης Cloud AI100-on-chip (SoC) είναι μια ειδικά σχεδιασμένη, επεκτάσιμη αρχιτεκτονική πολλαπλών πυρήνων, που υποστηρίζει ένα ευρύ φάσμα περιπτώσεων χρήσης βαθιάς μάθησης που εκτείνονται από το κέντρο δεδομένων έως την άκρη. Το SoC χρησιμοποιεί βαθμωτούς, διανυσματικούς και τανυστικούς υπολογιστικούς πυρήνες με κορυφαία στον κλάδο on-die SRAM χωρητικότητα 126 MB. Οι πυρήνες διασυνδέονται με ένα πλέγμα υψηλού εύρους ζώνης χαμηλής καθυστέρησης δικτύου-σε-τσιπ (NoC).
Ο επιταχυντής AI100 υποστηρίζει μια ευρεία και ολοκληρωμένη γκάμα μοντέλων και περιπτώσεων χρήσης. Ο παρακάτω πίνακας υπογραμμίζει το εύρος της υποστήριξης του μοντέλου.
| Κατηγορία μοντέλου | Αριθμός μοντέλων | Παραδείγματα |
| NLP | 157 | BERT, BART, FasterTransformer, T5, Z-code MOE |
| Generative AI – NLP | 40 | LLaMA, CodeGen, GPT, OPT, BLOOM, Jais, Luminous, StarCoder, XGen |
| Generative AI – Εικόνα | 3 | Stable diffusion v1.5 and v2.1, OpenAI CLIP |
| Βιογραφικό – Ταξινόμηση εικόνων | 45 | ViT, ResNet, ResNext, MobileNet, EfficientNet |
| CV – Ανίχνευση αντικειμένου | 23 | YOLO v2, v3, v4, v5 και v7, SSD-ResNet, RetinaNet |
| βιογραφικό – Άλλο | 15 | LPRNet, Super-Resolution/SRGAN, ByteTrack |
| Δίκτυα αυτοκινήτων* | 53 | Ανίχνευση αντίληψης και LIDAR, πεζών, λωρίδων κυκλοφορίας και φαναριού |
| Σύνολο | > 300 | |
* Τα περισσότερα δίκτυα αυτοκινήτων είναι σύνθετα δίκτυα που αποτελούνται από μια συγχώνευση μεμονωμένων δικτύων.
Η μεγάλη on-die SRAM στον επιταχυντή DL2q επιτρέπει την αποτελεσματική εφαρμογή προηγμένων τεχνικών απόδοσης, όπως η ακρίβεια μικροεκθέτη MX6 για την αποθήκευση των βαρών και η ακρίβεια μικροεκθέτη MX9 για την επικοινωνία επιταχυντή με επιταχυντή. Η τεχνολογία μικροεκθέτη περιγράφεται στην ακόλουθη ανακοίνωση του κλάδου Open Compute Project (OCP): AMD, Arm, Intel, Meta, Microsoft, NVIDIA και Qualcomm τυποποιούν στενές μορφές δεδομένων ακριβείας επόμενης γενιάς για AI » Open Compute Project.
Ο χρήστης της παρουσίας μπορεί να χρησιμοποιήσει την ακόλουθη στρατηγική για να μεγιστοποιήσει την απόδοση ανά κόστος:
- Αποθηκεύστε τα βάρη χρησιμοποιώντας την ακρίβεια μικροεκθέτη MX6 στη μνήμη DDR του επιταχυντή. Η χρήση της ακρίβειας MX6 μεγιστοποιεί τη χρήση της διαθέσιμης χωρητικότητας μνήμης και του εύρους ζώνης μνήμης για να προσφέρει την καλύτερη απόδοση και καθυστέρηση στην κατηγορία του.
- Υπολογίστε στο FP16 για να προσφέρετε την απαιτούμενη ακρίβεια περίπτωσης χρήσης, ενώ χρησιμοποιείτε την ανώτερη on-chip SRAM και τα εφεδρικά TOP στην κάρτα, για να εφαρμόσετε πυρήνες υψηλής απόδοσης χαμηλής καθυστέρησης MX6 έως FP16.
- Χρησιμοποιήστε μια βελτιστοποιημένη στρατηγική παρτίδας και ένα μεγαλύτερο μέγεθος παρτίδας χρησιμοποιώντας τη μεγάλη διαθέσιμη SRAM στο τσιπ για να μεγιστοποιήσετε την επαναχρησιμοποίηση των βαρών, διατηρώντας παράλληλα τις ενεργοποιήσεις στο τσιπ στο μέγιστο δυνατό.
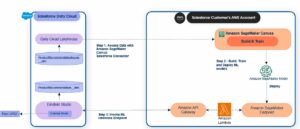
DL2q AI Στοίβα και αλυσίδα εργαλείων
Η παρουσία DL2q συνοδεύεται από το Qualcomm AI Stack που προσφέρει μια συνεπή εμπειρία προγραμματιστή σε όλη την Qualcomm AI στο cloud και σε άλλα προϊόντα της Qualcomm. Η ίδια Qualcomm AI stack και βασική τεχνολογία AI τρέχει στις παρουσίες DL2q και στις συσκευές Qualcomm edge, παρέχοντας στους πελάτες μια συνεπή εμπειρία προγραμματιστή, με ένα ενοποιημένο API σε περιβάλλοντα ανάπτυξης cloud, αυτοκινήτου, προσωπικού υπολογιστή, εκτεταμένης πραγματικότητας και smartphone.
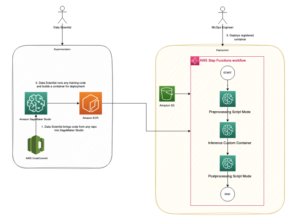
Η αλυσίδα εργαλείων δίνει τη δυνατότητα στον χρήστη του στιγμιότυπου να ενσωματώσει γρήγορα ένα μοντέλο που είχε εκπαιδευτεί προηγουμένως, να συντάξει και να βελτιστοποιήσει το μοντέλο για τις δυνατότητες του στιγμιότυπου και στη συνέχεια να αναπτύξει τα μεταγλωττισμένα μοντέλα για περιπτώσεις χρήσης συμπερασμάτων παραγωγής σε τρία βήματα που φαίνονται στο παρακάτω σχήμα.

Για να μάθετε περισσότερα σχετικά με τη ρύθμιση της απόδοσης ενός μοντέλου, ανατρέξτε στο Βασικές παράμετροι απόδοσης Cloud AI 100 Απόδειξη με έγγραφα.
Ξεκινήστε με παρουσίες DL2q
Σε αυτό το παράδειγμα, μεταγλωττίζετε και αναπτύσσετε ένα προεκπαιδευμένο μοντέλο BERT από Αγκαλιάζοντας το πρόσωπο σε μια παρουσία EC2 DL2q χρησιμοποιώντας ένα προ-ενσωματωμένο διαθέσιμο DL2q AMI, σε τέσσερα βήματα.
Μπορείτε να χρησιμοποιήσετε είτε προκατασκευασμένο Qualcomm DLAMI για παράδειγμα ή ξεκινήστε με ένα Amazon Linux2 AMI και δημιουργήστε το δικό σας DL2q AMI με το Cloud AI 100 Platform and Apps SDK που είναι διαθέσιμο σε αυτό Υπηρεσία απλής αποθήκευσης Amazon (Amazon S3) κάδος: s3://ec2-linux-qualcomm-ai100-sdks/latest/.
Τα βήματα που ακολουθούν χρησιμοποιούν το προκατασκευασμένο DL2q AMI, Qualcomm Base AL2 DLAMI.
Χρησιμοποιήστε το SSH για να αποκτήσετε πρόσβαση στο στιγμιότυπο DL2q με το Qualcomm Base AL2 DLAMI AMI και ακολουθήστε τα βήματα 1 έως 4.
Βήμα 1. Ρυθμίστε το περιβάλλον και εγκαταστήστε τα απαιτούμενα πακέτα
- Εγκαταστήστε την Python 3.8.
- Ρυθμίστε το εικονικό περιβάλλον Python 3.8.
- Ενεργοποιήστε το εικονικό περιβάλλον Python 3.8.
- Εγκαταστήστε τα απαιτούμενα πακέτα, που φαίνονται στο έγγραφα απαιτήσεων.txt διαθέσιμο στον δημόσιο ιστότοπο της Qualcomm Github.
- Εισαγάγετε τις απαραίτητες βιβλιοθήκες.
Βήμα 2. Εισαγάγετε το μοντέλο
- Εισαγάγετε και διαμορφώστε το μοντέλο.
- Ορίστε ένα δείγμα εισόδου και εξαγάγετε το
inputIdsκαιattentionMask. - Μετατρέψτε το μοντέλο σε ONNX, το οποίο στη συνέχεια μπορεί να περάσει στον μεταγλωττιστή.
- Θα εκτελέσετε το μοντέλο με ακρίβεια FP16. Επομένως, πρέπει να ελέγξετε εάν το μοντέλο περιέχει σταθερές πέρα από το εύρος FP16. Περάστε το μοντέλο στο
fix_onnx_fp16λειτουργία για τη δημιουργία του νέου αρχείου ONNX με τις απαιτούμενες διορθώσεις.
Βήμα 3. Μεταγλώττιση του μοντέλου
Η qaic-exec Το εργαλείο μεταγλώττισης της διεπαφής γραμμής εντολών (CLI) χρησιμοποιείται για τη μεταγλώττιση του μοντέλου. Η είσοδος σε αυτόν τον μεταγλωττιστή είναι το αρχείο ONNX που δημιουργήθηκε στο βήμα 2. Ο μεταγλωττιστής παράγει ένα δυαδικό αρχείο (που ονομάζεται QPC, Για Δοχείο προγράμματος Qualcomm) στη διαδρομή που ορίζεται από -aic-binary-dir διαφωνία.
Στην παρακάτω εντολή μεταγλώττισης, χρησιμοποιείτε τέσσερις υπολογιστικούς πυρήνες AI και μέγεθος παρτίδας ενός για τη μεταγλώττιση του μοντέλου.
Το QPC δημιουργείται στο bert-base-cased/generatedModels/bert-base-cased_fix_outofrange_fp16_qpc φάκελο.
Βήμα 4. Εκτελέστε το μοντέλο
Ρυθμίστε μια περίοδο λειτουργίας για να εκτελέσετε το συμπέρασμα σε έναν επιταχυντή Cloud AI100 Qualcomm στην παρουσία DL2q.
Η βιβλιοθήκη Qualcomm qaic Python είναι ένα σύνολο API που παρέχει υποστήριξη για την εκτέλεση συμπερασμάτων στον επιταχυντή Cloud AI100.
- Χρησιμοποιήστε την κλήση του Session API για να δημιουργήσετε μια παρουσία περιόδου σύνδεσης. Η κλήση του Session API είναι το σημείο εισόδου για τη χρήση της βιβλιοθήκης qaic Python.
- Αναδιάρθρωση των δεδομένων από την προσωρινή μνήμη εξόδου με
output_shapeκαιoutput_type. - Αποκωδικοποιήστε την παραγωγή που παράγεται.
Ακολουθούν τα αποτελέσματα για την πρόταση εισαγωγής "The dog [MASK] on the mat".
Αυτό είναι. Με λίγα μόλις βήματα, μεταγλωττίσατε και εκτελέσατε ένα μοντέλο PyTorch σε μια παρουσία Amazon EC2 DL2q. Για να μάθετε περισσότερα σχετικά με την ενσωμάτωση και τη μεταγλώττιση μοντέλων στην παρουσία DL2q, ανατρέξτε στο Τεκμηρίωση εκμάθησης Cloud AI100.
Για να μάθετε περισσότερα σχετικά με το ποιες αρχιτεκτονικές μοντέλων DL είναι κατάλληλες για παρουσίες AWS DL2q και τον τρέχοντα πίνακα υποστήριξης μοντέλων, ανατρέξτε στο Τεκμηρίωση Qualcomm Cloud AI100.
Άμεσα διαθέσιμο
Μπορείτε να εκκινήσετε παρουσίες DL2q σήμερα στις Περιφέρειες AWS των ΗΠΑ Δυτικής (Όρεγκον) και Ευρώπης (Φρανκφούρτη) ως Κατα παραγγελια, Κατοχυρωμένα, να Στιγμιαίες παρουσίες, ή ως μέρος του α Πρόγραμμα ταμιευτηρίου. Ως συνήθως με το Amazon EC2, πληρώνετε μόνο για ό,τι χρησιμοποιείτε. Για περισσότερες πληροφορίες, βλ Τιμές Amazon EC2.
Οι παρουσίες DL2q μπορούν να αναπτυχθούν χρησιμοποιώντας AWS Deep Learning AMI (DLAMI)και οι εικόνες κοντέινερ είναι διαθέσιμες μέσω διαχειριζόμενων υπηρεσιών, όπως π.χ Amazon Sage Maker, Amazon Elastic Kubernetes Service (Amazon EKS), Υπηρεσία Ελαστικού Κοντέινερ Amazon (Amazon ECS), να AWS ParallelCluster.
Για να μάθετε περισσότερα, επισκεφθείτε το Παράδειγμα Amazon EC2 DL2q σελίδα και στείλτε σχόλια σε AWS re: Δημοσίευση για EC2 ή μέσω των συνηθισμένων επαφών υποστήριξης AWS.
Σχετικά με τους συγγραφείς
 ΑΚ Ρόι είναι Διευθυντής Διαχείρισης Προϊόντων στην Qualcomm, για προϊόντα και λύσεις Cloud και Datacenter AI. Έχει πάνω από 20 χρόνια εμπειρίας στη στρατηγική και την ανάπτυξη προϊόντων, με την τρέχουσα εστίαση στις καλύτερες επιδόσεις και επιδόσεις στην κατηγορία του/$ end-to-end λύσεων για συμπέρασμα AI στο Cloud, για το ευρύ φάσμα περιπτώσεων χρήσης, συμπεριλαμβανομένων των GenAI, LLM, Auto και Hybrid AI.
ΑΚ Ρόι είναι Διευθυντής Διαχείρισης Προϊόντων στην Qualcomm, για προϊόντα και λύσεις Cloud και Datacenter AI. Έχει πάνω από 20 χρόνια εμπειρίας στη στρατηγική και την ανάπτυξη προϊόντων, με την τρέχουσα εστίαση στις καλύτερες επιδόσεις και επιδόσεις στην κατηγορία του/$ end-to-end λύσεων για συμπέρασμα AI στο Cloud, για το ευρύ φάσμα περιπτώσεων χρήσης, συμπεριλαμβανομένων των GenAI, LLM, Auto και Hybrid AI.
 Jianying Lang είναι Κύριος Αρχιτέκτονας Λύσεων στον Παγκόσμιο Ειδικό Οργανισμό AWS (WWSO). Έχει πάνω από 15 χρόνια εργασιακής εμπειρίας στον τομέα HPC και AI. Στην AWS, εστιάζει στο να βοηθά τους πελάτες να αναπτύξουν, να βελτιστοποιήσουν και να κλιμακώσουν τον φόρτο εργασίας τους AI/ML σε περιπτώσεις επιτάχυνσης υπολογιστών. Είναι παθιασμένη με το συνδυασμό των τεχνικών στους τομείς HPC και AI. Ο Jianying είναι κάτοχος διδακτορικού διπλώματος στην Υπολογιστική Φυσική από το Πανεπιστήμιο του Κολοράντο στο Boulder.
Jianying Lang είναι Κύριος Αρχιτέκτονας Λύσεων στον Παγκόσμιο Ειδικό Οργανισμό AWS (WWSO). Έχει πάνω από 15 χρόνια εργασιακής εμπειρίας στον τομέα HPC και AI. Στην AWS, εστιάζει στο να βοηθά τους πελάτες να αναπτύξουν, να βελτιστοποιήσουν και να κλιμακώσουν τον φόρτο εργασίας τους AI/ML σε περιπτώσεις επιτάχυνσης υπολογιστών. Είναι παθιασμένη με το συνδυασμό των τεχνικών στους τομείς HPC και AI. Ο Jianying είναι κάτοχος διδακτορικού διπλώματος στην Υπολογιστική Φυσική από το Πανεπιστήμιο του Κολοράντο στο Boulder.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/amazon-ec2-dl2q-instance-for-cost-efficient-high-performance-ai-inference-is-now-generally-available/
- :έχει
- :είναι
- $UP
- 1
- 1 TB
- 10
- 100
- 11
- 12
- 13
- 15 χρόνια
- 15%
- 17
- 19
- 20
- 20 χρόνια
- 22
- 23
- 46
- 7
- 75
- 8
- 84
- a
- Σχετικα
- πάνω από
- επιτάχυνση
- επιταχυντής
- επιταχυντές
- πρόσβαση
- συνοδεύεται
- ακρίβεια
- απέναντι
- ενεργοποιήσεις
- Επιπλέον
- προηγμένες
- σύνολο
- AI
- AI / ML
- Όλα
- Επίσης
- Amazon
- Amazon EC2
- Amazon υπηρεσίες Web
- an
- και
- Ανακοίνωσεις
- κάθε
- api
- APIs
- εφαρμογές
- εφαρμογές
- αρχιτεκτονική
- ΕΙΝΑΙ
- επιχείρημα
- ARM
- τεχνητός
- AS
- βοηθούς
- At
- αυτόματη
- αυτοκινήτων
- αυτονόμος
- διαθέσιμος
- AWS
- ΑΞΟΝΕΣ
- εύρος ζώνης
- βάση
- δοσοληψία
- BE
- πριν
- παρακάτω
- Πέρα
- BIN
- Αποκλεισμός
- άνθηση
- φέρω
- ευρύς
- ρυθμιστικό
- χτίζω
- by
- κλήση
- που ονομάζεται
- CAN
- δυνατότητες
- Χωρητικότητα
- κάρτα
- περίπτωση
- έλεγχος
- κλασικό
- Backup
- Κολοράντο
- συνδυάζοντας
- Επικοινωνία
- Συντάχθηκε
- περιεκτικός
- υπολογιστική
- Υπολογίστε
- υπολογιστή
- Computer Vision
- υπολογιστές
- χρήση υπολογιστή
- συνεπής
- Αποτελείται από
- Επαφές
- Δοχείο
- Περιέχει
- περιεχόμενο
- δημιουργία
- Ρεύμα
- Πελάτες
- ημερομηνία
- Datacenter
- βαθύς
- βαθιά μάθηση
- ορίζεται
- Πτυχίο
- παραδώσει
- παραδίδει
- παρατάσσω
- αναπτυχθεί
- ανάπτυξη
- περιγράφεται
- ανάπτυξη
- Εργολάβος
- Ανάπτυξη
- συσκευή
- Συσκευές
- Διάχυση
- Διευθυντής
- τεκμηρίωση
- Σκύλος
- οδήγηση
- δυναμικός
- εβς
- άκρη
- αποτελεσματικός
- είτε
- απασχολεί
- δίνει τη δυνατότητα
- από άκρη σε άκρη
- καταχώριση
- Περιβάλλον
- περιβάλλοντα
- Αιθέρας (ΕΤΗ)
- Ευρώπη
- παράδειγμα
- εμπειρία
- εκτεταμένη πραγματικότητα
- εκχύλισμα
- ψευδής
- Χαρακτηριστικό
- ανατροφοδότηση
- λίγοι
- πεδίο
- Πεδία
- Εικόνα
- Αρχεία
- Όνομα
- ταιριάζουν
- διορθώσεις
- Συγκέντρωση
- εστιάζει
- ακολουθήστε
- Εξής
- Για
- Βρέθηκαν
- τέσσερα
- Φρανκφούρτη
- από
- λειτουργία
- συγχώνευση
- γενικά
- παράγουν
- παράγεται
- γενεά
- γενετική
- Παραγωγική τεχνητή νοημοσύνη
- GitHub
- δεδομένου
- καλός
- Επισκέπτης
- Κείμενο
- he
- ακουστικά
- βοήθεια
- εδώ
- υψηλή απόδοση
- υψηλότερο
- ανταύγειες
- κατέχει
- hpc
- HTML
- HTTPS
- Υβριδικό
- i
- IDX
- if
- εικόνα
- εικόνες
- εφαρμογή
- εκτέλεση
- εισαγωγή
- in
- Συμπεριλαμβανομένου
- ενσωματώνει
- ατομικές
- βιομηχανία
- κορυφαία στον κλάδο
- πληροφορίες
- εισαγωγή
- εγκαθιστώ
- παράδειγμα
- περιπτώσεις
- Intel
- Έξυπνος
- διασυνδεδεμένα
- περιβάλλον λειτουργίας
- IT
- jpg
- μόλις
- Κλειδί
- Kubernetes
- Lane
- Γλώσσα
- large
- Αφάνεια
- ξεκινήσει
- ΜΑΘΑΊΝΩ
- μάθηση
- βιβλιοθήκες
- Βιβλιοθήκη
- αντιμετώπιση
- φως
- γραμμή
- φορτία
- διαχειρίζεται
- διαχείριση
- μάσκα
- Μήτρα
- max
- Αυξάνω στον ανώτατο βαθμό
- μεγιστοποιεί
- ανώτατο όριο
- Μνήμη
- ματιών
- Meta
- Microsoft
- πρακτικά
- μοντέλο
- μοντέλα
- τροποποιημένο
- περισσότερο
- πλέον
- όνομα
- Φυσικό
- Φυσική γλώσσα
- Επεξεργασία φυσικής γλώσσας
- απαραίτητος
- Ανάγκη
- δίκτυο
- δικτύωσης
- δίκτυα
- Νέα
- επόμενη γενιά
- τώρα
- πολλοί
- Nvidia
- αντικείμενο
- of
- on
- Onboard
- Επί του σκάφους
- ONE
- αποκλειστικά
- ανοίξτε
- OpenAI
- Βελτιστοποίηση
- βελτιστοποιημένη
- or
- Όρεγκον
- επιχειρήσεις
- OS
- ΑΛΛΑ
- έξω
- παραγωγή
- εξόδους
- επί
- δική
- Packages
- σελίδα
- μέρος
- passieren
- πέρασε
- παθιασμένος
- μονοπάτι
- Πληρωμή
- για
- επίδοση
- προσωπικός
- Προσωπικοί υπολογιστές
- phd
- Φυσική
- πλατφόρμες
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- Σημείο
- Δημοφιλής
- δυνατός
- Θέση
- τροφοδοτείται
- Ακρίβεια
- προηγουμένως
- Κύριος
- μεταποίηση
- Παράγεται
- παράγει
- Προϊόν
- διαχείριση προϊόντων
- παραγωγή
- Προϊόντα
- Πρόγραμμα
- σχέδιο
- παρέχει
- χορήγηση
- δημόσιο
- Python
- pytorch
- qualcomm
- γρήγορα
- σειρά
- RE
- Ανάγνωση
- Πραγματικότητα
- περιοχές
- απαιτείται
- απαιτήσεις
- συγκράτησης
- απόδοση
- επαναχρησιμοποίηση
- Roy
- τρέξιμο
- τρέξιμο
- τρέχει
- ίδιο
- Αποθήκευση
- οικονομία
- επεκτάσιμη
- Κλίμακα
- SDK
- Δεύτερος
- δείτε
- στείλετε
- ποινή
- Ακολουθία
- υπηρεσία
- Υπηρεσίες
- Συνεδρίαση
- σειρά
- αυτή
- παρουσιάζεται
- Απλούς
- απλοποίηση
- ιστοσελίδα
- Μέγεθος
- smartphone
- smartphones
- So
- Λύσεις
- ένταση
- ειδικός
- σωρός
- πρότυπο
- Εκκίνηση
- ξεκίνησε
- Βήμα
- Βήματα
- χώρος στο δίσκο
- κατάστημα
- Στρατηγική
- Ακολούθως
- τέτοιος
- ανώτερος
- υποστήριξη
- Στήριξη
- Υποστηρίζει
- σύστημα
- τραπέζι
- τεχνικές
- Τεχνολογία
- κείμενο
- ότι
- Η
- τους
- τότε
- Αυτοί
- αυτοί
- αυτό
- τρία
- Μέσω
- διακίνηση
- διά μέσου
- προς την
- σήμερα
- συμβολίζω
- εργαλείο
- Tops
- δάδα
- Σύνολο
- ΚΙΝΗΣΗ στους ΔΡΟΜΟΥΣ
- εκπαιδευμένο
- μετασχηματιστές
- αληθής
- φροντιστήριο
- ενιαία
- πανεπιστήμιο
- us
- χρήση
- περίπτωση χρήσης
- περιπτώσεις χρήσης
- μεταχειρισμένος
- Χρήστες
- χρησιμοποιώντας
- συνήθης
- v1
- VAL
- ΕΠΙΚΥΡΩΝΩ
- αξία
- Πραγματικός
- όραμα
- Επίσκεψη
- we
- ιστός
- διαδικτυακές υπηρεσίες
- ΛΟΙΠΌΝ
- δυτικά
- Τι
- Ποιό
- ενώ
- ευρύς
- Ευρύ φάσμα
- θα
- με
- λέξη
- εργαζόμενος
- παγκόσμιος
- χρόνια
- εσείς
- Σας
- zephyrnet