Amazon EMR-Studio ist eine integrierte Entwicklungsumgebung (IDE), die es Datenwissenschaftlern und Dateningenieuren erleichtert, Datentechnik und Datenwissenschaftsanwendungen, die in R, Python, Scala und PySpark geschrieben sind, zu entwickeln, zu visualisieren und zu debuggen. EMR Studio bietet vollständig verwaltete Jupyter-Notebooks und Tools wie Spark UI und YARN Timeline Server über EMR Studio Workspaces. Sie können einen EMR Studio-Arbeitsbereich an einen EMR-Cluster anhängen, die Rechenleistung des EMR-Clusters nutzen und Data-Science-Jobs auf dem Cluster ausführen. Daten werden oft in Data Lakes gespeichert, die von verwaltet werden AWS Lake-Formation, wodurch Sie eine differenzierte Zugriffskontrolle über einen einfachen Gewährungs- oder Widerrufsmechanismus anwenden können.
Wir stellen es Ihnen gerne vor Laufzeitrollen für EMR Studio-Arbeitsbereiche. Sie können jetzt eine Laufzeitrolle definieren und sie einem EMR-Cluster zuweisen, wenn Sie einen EMR Studio-Arbeitsbereich anhängen. Die Jobs im EMR-Cluster verwenden diese Laufzeitrolle, um auf AWS-Ressourcen zuzugreifen. Nach der Konfiguration einer Laufzeitrolle können Sie auch Lake Formation verwenden und eine differenzierte Datenzugriffskontrolle für die vom EMR Studio Workspace übermittelten Jobs anwenden.
Bisher mussten beim Anhängen von EMR Studio-Arbeitsbereichen an EMR-Cluster alle Arbeitsbereiche dasselbe verwenden AWS Identity and Access Management and (IAM)-Rolle – nämlich die des Clusters Amazon Elastic Compute-Cloud (Amazon EC2) Instanzprofil. Daher hatten alle Arbeitsbereiche, die an denselben EMR-Cluster angeschlossen waren, denselben Datenzugriff. Um den Zugriff auf Datenquellen zu steuern, musste jeder EMR Studio-Arbeitsbereich einen anderen EMR-Cluster verwenden und es waren mehrere EMR-Instanzprofile erforderlich.
Ab der Veröffentlichung von Amazon EMR 6.11 können Sie nun eine Laufzeitrolle auswählen, wenn Sie einen EMR Studio-Arbeitsbereich an einen EMR-Cluster anhängen. Diese Laufzeitrolle schränkt den Zugriff auf Arbeitsbereichsebene ein. Ihre Apache Livy- und Apache Spark-Jobs, die über die EMR Studio-Arbeitsbereiche ausgeführt werden, haben nur die Berechtigung, auf die Daten und Ressourcen zuzugreifen, die durch mit der Laufzeitrolle verknüpfte Richtlinien zulässig sind. Wenn auf Daten aus Data Lakes zugegriffen wird, die mit Lake Formation verwaltet werden, können Sie mithilfe von Lake Formation-Berechtigungen eine differenzierte Datenzugriffskontrolle erzwingen. Dies hilft Ihnen, den Betriebsaufwand zu reduzieren.
In diesem Beitrag zeigen wir, wie man Laufzeitrollen für EMR Studio-Arbeitsbereiche konfiguriert und einen Arbeitsbereich mit Laufzeitrollen an einen EMR-Cluster anfügt. Da große Unternehmen in der Regel mehrere AWS-Konten verwenden und viele dieser Konten möglicherweise Zugriff auf einen Data Lake benötigen, der von einem einzigen AWS-Konto verwaltet wird, werden in unserem Beispiel zwei AWS-Konten verwendet. Wir erklären, wie Sie den Zugriff auf EMR Studio-Laufzeitrollen steuern, den Datenzugriff über Konten in einem Data Lake über Lake Formation verwalten und Berechtigungen auf Tabellen- und Spaltenebene für die EMR-Laufzeitrollen erzwingen.
Lösungsüberblick
Um eine differenzierte Zugriffskontrolle zu demonstrieren, erstellen wir ein Beispiel AWS-Kleber Erstellen Sie eine Datenbank mit dem Namen „Unternehmen“ und verwalten Sie die Datenbankberechtigung in Lake Formation. Die Datenbank besteht aus zwei separaten Tabellen:
- Mitarbeiter – In dieser Tabelle werden Informationen über die Mitarbeiter des Unternehmens gespeichert, einschließlich Mitarbeiter-ID, Name, Abteilung und Gehalt
- unsere Produkte – In dieser Tabelle werden Informationen zu den vom Unternehmen verkauften Produkten gespeichert, einschließlich Produkt-ID, Name, Kategorie und Preis
Um die Datenzugriffskontrolle zu demonstrieren, berücksichtigen wir die folgenden Datennutzer:
- Alice, Datenwissenschaftlerin im Vertriebsteam – Sie sollte nur Lesezugriff auf alle Spalten im haben
productsTabelle und ausgewählte Spalten, einschließlich uID, Name und Abteilung in deremployeesTabelle - Bob, ein Datenwissenschaftler im Personalteam – Er sollte nur Lesezugriff auf alle Spalten haben
employeesTabelle und sollte keinen Zugriff darauf habenproductsTabelle
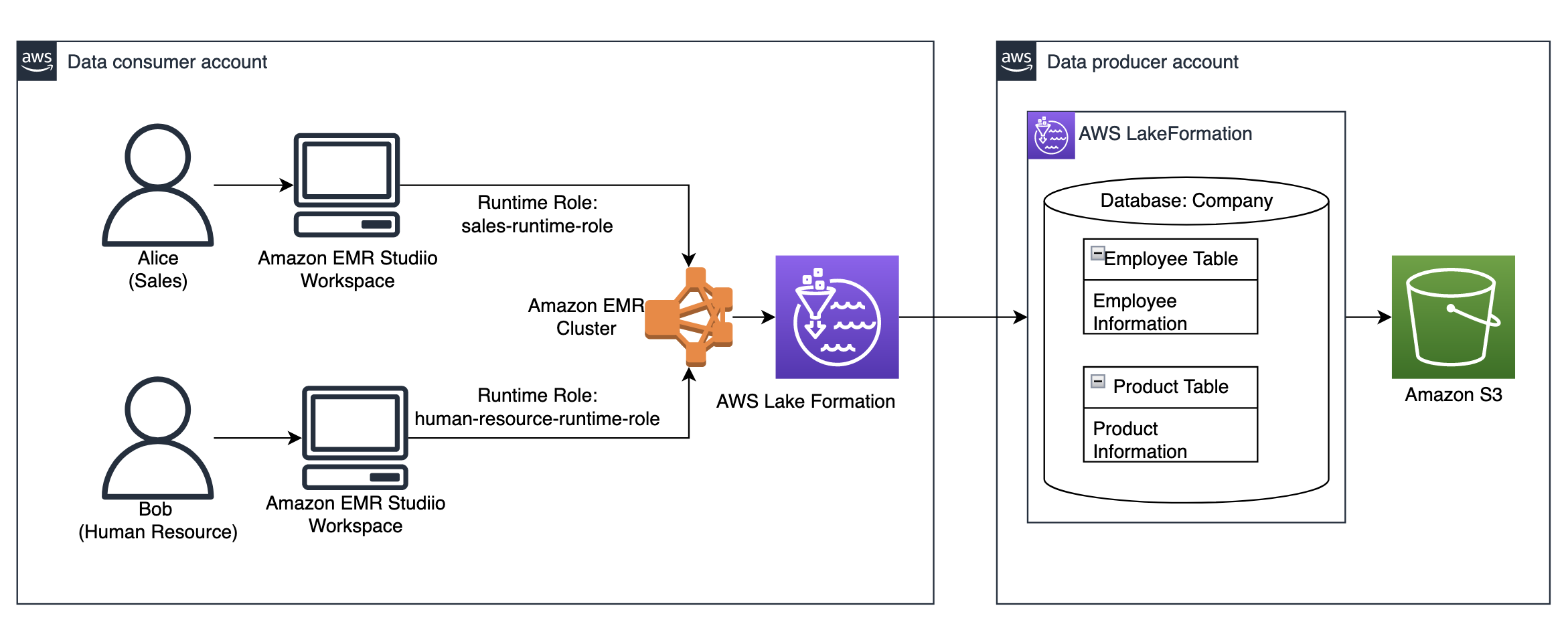
Um den kontoübergreifenden Datenaustausch zu demonstrieren, betrachten wir zwei Konten:
- Datenproduzentenkonto – Wir bezeichnen dieses Konto als
123456789012in diesem Beitrag. Dieses Konto verwaltet die Rohdaten in Amazon Simple Storage-Service (Amazon S3) und schreibt Daten in den Data Lake. DercompanyDatenbank und Tabellen sollten sich in diesem Konto befinden. - Datenverbraucherkonto – Wir bezeichnen dieses Konto als
111122223333in diesem Beitrag. Auf dieses Konto greifen die Benutzer direkt zur Datenanalyse zu und haben keinen Schreibzugriff auf die Daten. Dieses Konto sollte für Alice und Bob zugänglich sein.
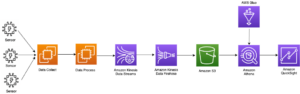
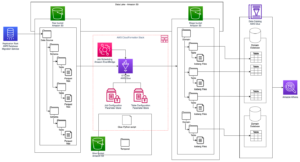
Die Architektur ist wie folgt implementiert:
- Das Datenproduzentenkonto verwaltet einen Data Lake. Rohdaten werden in S3-Buckets gespeichert und im AWS Glue Data Catalog katalogisiert.
- Lake Formation im Datenproduzentenkonto regelt den Datenzugriff über den Datenkatalog und ermöglicht die kontoübergreifende Datenfreigabe mit dem Datenkonsumentenkonto.
- Lake Formation im Datenkonsumentenkonto regelt den kontoübergreifenden Zugriff auf den Data Lake auf Tabellenebene und fein abgestufte Lake Formation-Berechtigungen. Weitere Informationen finden Sie unter Methoden für eine differenzierte Zugriffskontrolle.
- EMR Studio-Arbeitsbereiche im Datenkonsumentenkonto verwenden Laufzeitrollen, wenn Jobs auf einem EMR-Cluster ausgeführt werden.
- Der EMR-Cluster stellt eine Verbindung zum Glue Data Catalog im Datenkonsumentenkonto her und fragt die Daten aus dem Data Lake durch kontoübergreifende Datenfreigabe ab.
Das folgende Diagramm veranschaulicht diese Architektur.
In den folgenden Abschnitten gehen wir die Schritte zum kontoübergreifenden Teilen von Daten über Lake Formation durch, führen einen EMR Studio-Arbeitsbereich mit Laufzeitrollen aus und demonstrieren eine differenzierte Zugriffskontrolle.
Voraussetzungen:
Folgende Voraussetzungen sollten Sie mitbringen:
Erstellen Sie die Infrastruktur im Datenproduzentenkonto
Führen Sie die folgenden Schritte aus, um die Infrastrukturressourcen zu erstellen:
- Melden Sie sich beim AWS-Konto des Datenproduzenten an (
123456789012). - Auswählen
Stack starten um eine CloudFormation-Vorlage bereitzustellen, um die erforderlichen Ressourcen zu erstellen.

- Aussichten für DataLakeBucketSuffixGeben Sie das Suffix für den S3-Bucket ein, der vom Data Lake verwendet wird. Der gesamte zu erstellende S3-Bucket-Name lautet
{AwsAccoundId}-{AwsRegion}-{DataLakeBucketSuffix}. - Navigieren Sie nach dem Erstellen des CloudFormation-Stacks zur Ausgänge Registerkarte des Stapels und erfassen Sie den Wert von
DataLakeS3Bucketim nächsten Schritt zu verwenden.
Erstellen Sie Datendateien und laden Sie sie im Datenproduzentenkonto auf Amazon S3 hoch
Konfigurieren Sie Ihre AWS CLI so, dass sie die IAM-Identität mit der Berechtigung zum Hochladen auf DataLakeS3BucketName im AWS-Konto des Datenproduzenten verwendet (123456789012), oder Sie können sich mit dem bei CloudShell anmelden AWS-Managementkonsole. Führen Sie die folgenden Schritte aus:
- Wechseln Sie auf Ihrem lokalen Computer mit dem Befehl cd in ein Verzeichnis Ihrer Wahl, z. B.
cd ~. - Führen Sie die Skript mit
chmod 744 create_sample_data.sh && ./create_sample_data.sh <DataLakeS3BucketName>.
Das Skript erstellt ein Unterverzeichnis tmp Erstellen Sie in Ihrem aktuellen Arbeitsverzeichnis die Testdaten in CSV-Dateien und laden Sie die Dateien in das hoch DataLakeS3BucketName S3 Eimer.
Richten Sie Lake Formation im Datenproduzentenkonto ein
In diesem Abschnitt gehen wir die Schritte zum Einrichten von Lake Formation im Datenproduzentenkonto durch.
Richten Sie die Versionseinstellungen für die kontoübergreifende Datenfreigabe von Lake Formation ein
Lake Formation unterstützt mehrere Versionen zur Datenfreigabe. Für diesen Beitrag verwenden wir Version 3. Weitere Informationen zu den Unterschieden zwischen den Datenfreigabeversionen finden Sie unter Aktualisieren der Versionseinstellungen für die kontoübergreifende Datenfreigabe. Informationen zum Ändern der Datenfreigabeversion finden Sie unter Um die neue Version zu aktivieren.
Registrieren Sie den Amazon S3-Standort als Data Lake-Standort
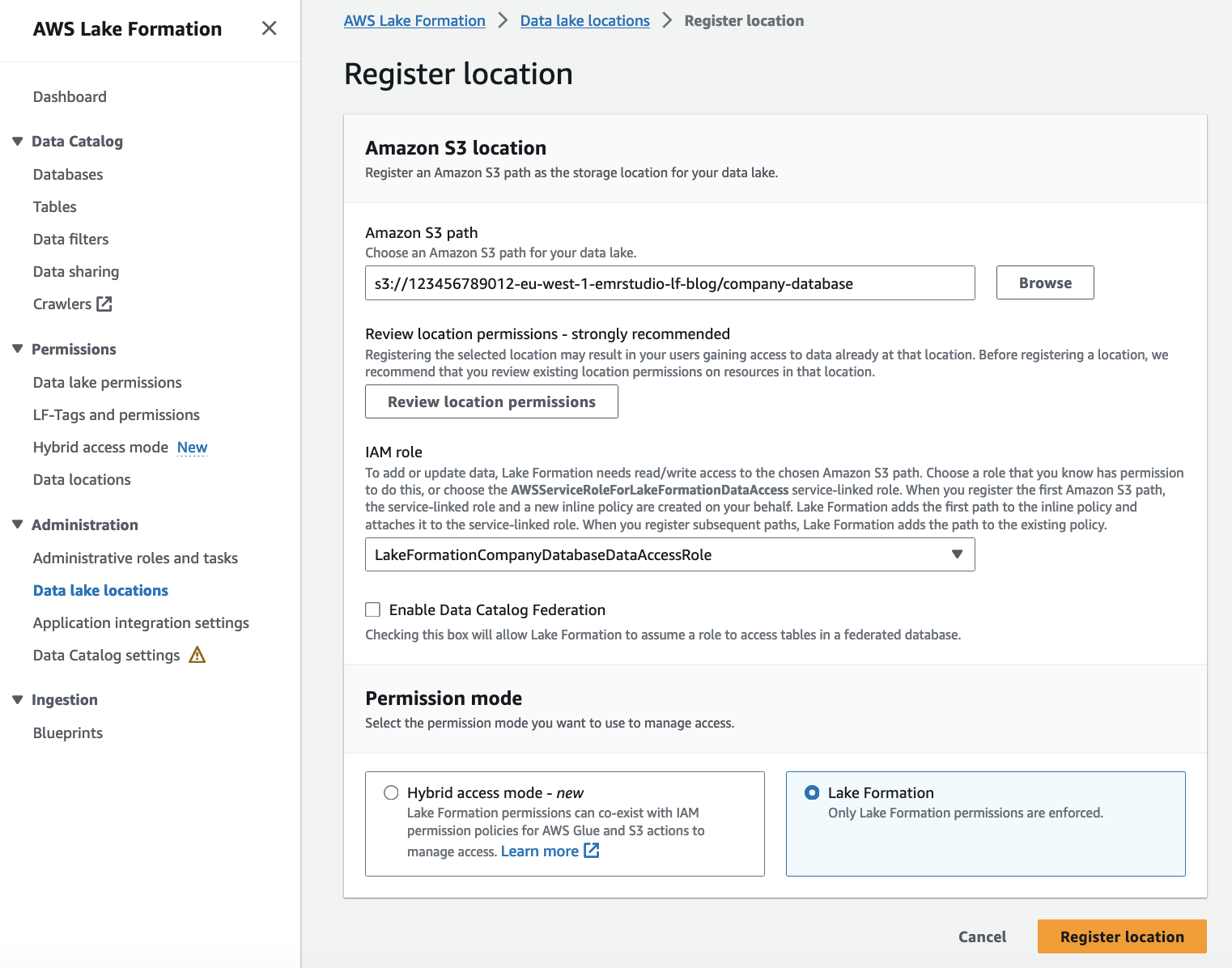
Wenn Sie Registrieren Sie einen Amazon S3-Standort Bei Lake Formation geben Sie eine IAM-Rolle mit Lese-/Schreibberechtigungen für diesen Standort an. Wenn EMR-Cluster nach der Registrierung Zugriff auf diesen Amazon S3-Standort anfordern, stellt Lake Formation temporäre Anmeldeinformationen der bereitgestellten Rolle für den Zugriff auf die Daten bereit. Wir haben die Rolle bereits erstellt LakeFormationCompanyDatabaseDataAccessRole zu diesem Zweck im vorherigen Schritt. Führen Sie die folgenden Schritte aus, um den Amazon S3-Standort als Data Lake-Standort zu registrieren:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenproduzentenkonto (
123456789012). - Wählen Sie im Navigationsbereich Datenseestandorte für Verwaltung.
- Auswählen Ort registrieren.
- Aussichten für Amazon S3-Pfad, eingeben
s3://<DataLakeS3BucketName>/company-database. - Aussichten für IAM-Rolle, eingeben
LakeFormationCompanyDatabaseDataAccessRole. - Aussichten für BerechtigungsmodusWählen Seebildung.
- Auswählen Ort registrieren.
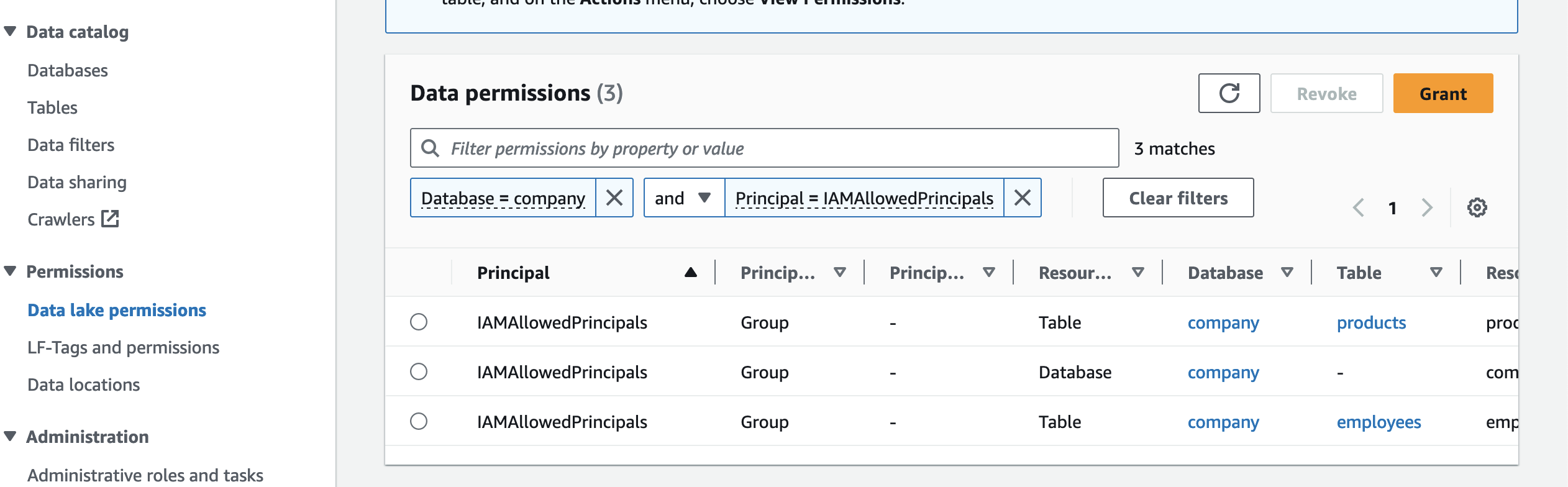
Widerrufen Sie die IAMAllowedPrincipals gewährten Berechtigungen
Das IAMAllowedPrincipals Die Gruppe umfasst alle IAM-Benutzer und -Rollen, denen gemäß Ihren IAM-Richtlinien Zugriff auf Ihre Data Catalog-Ressourcen gewährt wird. Zu Durchsetzung des Lake-Formation-Modells, wir müssen Widerrufen Sie die Berechtigung von IAMAllowedPrincipals mit den folgenden Schritten:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenproduzentenkonto.
- Wählen Sie im Navigationsbereich Data Lake-Berechtigungen unter Berechtigungen.
- Berechtigungen filtern nach
Database = companyundPrinciple=IAMAllowedPrinciples. - Wählen Sie alle dem Prinzipal erteilten Berechtigungen aus
IAMAllowedPrincipalsund wählen Sie Widerrufen.
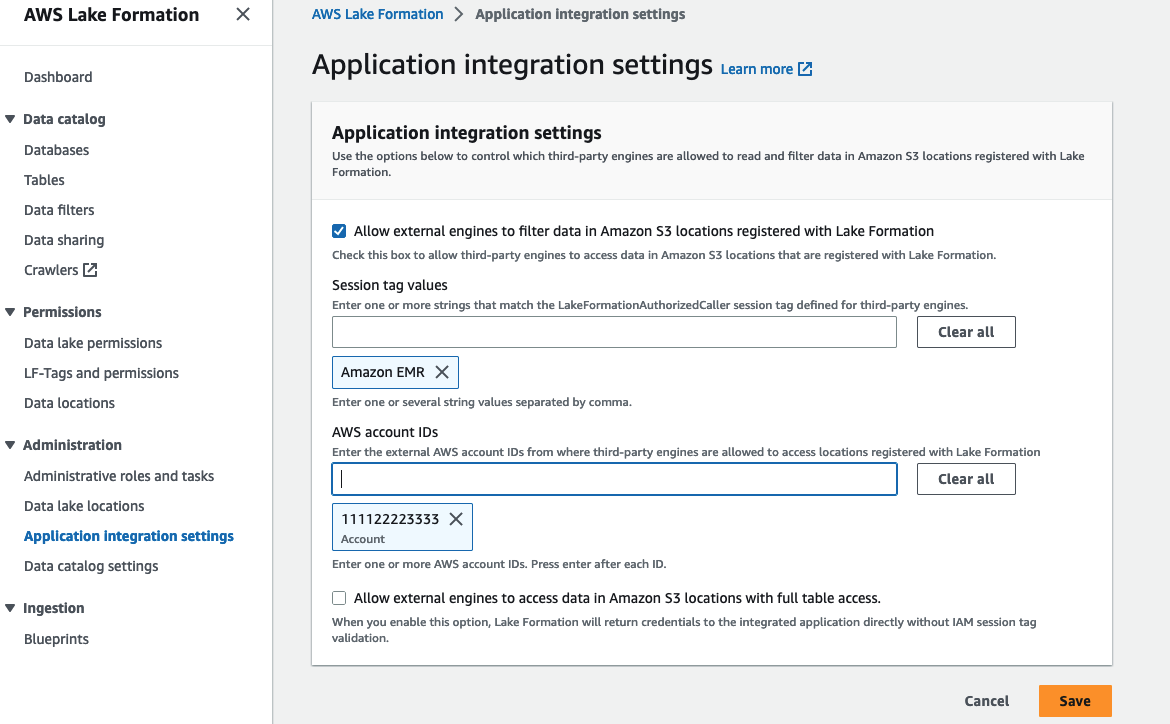
Richten Sie Einstellungen für die Anwendungsintegration ein
Um Berechtigungen für den EMR-Cluster zu erzwingen, müssen Sie einen Sitzungs-Tag-Wert bei Lake Formation registrieren. Lake Formation verwendet dieses Sitzungs-Tag, um Anrufer zu autorisieren und Zugriff auf den Data Lake bereitzustellen. Wir melden uns an Amazon EMR als Sitzungs-Tag-Wert. Auf diesen Wert wird im verwiesen Sicherheitskonfiguration beim Erstellen des EMR-Clusters.
Richten Sie das Sitzungs-Tag mit den folgenden Schritten ein:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenproduzentenkonto.
- Auswählen Einstellungen zur Anwendungsintegration für Verwaltung im Navigationsbereich.
- Auswählen Erlauben Sie externen Engines, Daten an Amazon S3-Standorten zu filtern, die bei Lake Formation registriert sind.
- Aussichten für Sitzungs-Tag-Werte, eingeben
Amazon EMR. - Aussichten für AWS-Konto-IDsGeben Sie die AWS-Konto-ID des Datenkonsumenten ein (
111122223333). - Auswählen Speichern.
Geben Sie die Datenbank und die Tabellen für das Datenkonsumentenkonto frei
Wir erteilen jetzt Berechtigungen für das AWS-Konto des Datenkonsumenten, einschließlich erteilbarer Berechtigungen. Dadurch kann der Lake Formation-Data-Lake-Administrator im Datenkonsumentenkonto den Zugriff auf die Daten innerhalb des Kontos steuern.
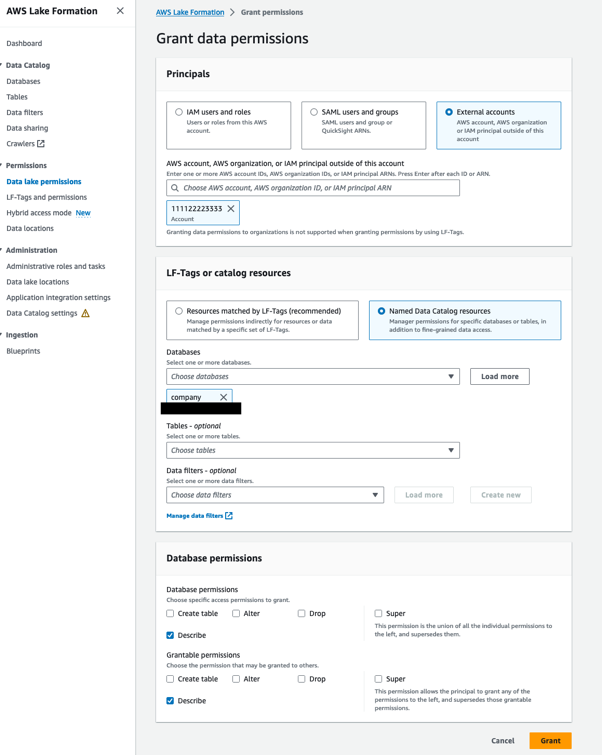
Gewähren Sie dem Datenkonsumentenkonto Datenbankberechtigungen
Führen Sie die folgenden Schritte aus:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenproduzentenkonto.
- Wählen Sie im Navigationsbereich Datenbanken.
- Wählen Sie die Datenbank aus
companyund auf dem Aktionen Menü unter Berechtigungen, wählen Gewähren. - Im Die Prinzipien Abschnitt auswählen Externe Konten und geben Sie das AWS-Konto des Datenkonsumenten ein (
111122223333). - Im LF-Tags oder Katalogressourcen Wählen Sie im Abschnitt
companyfür Datenbanken. - Im Datenbankberechtigungen Abschnitt auswählen Beschreiben sowohl Datenbankberechtigungen und Erteilbare Berechtigungen.
Dadurch kann der Data Lake-Administrator im Datenkonsumentenkonto die Datenbank beschreiben und anderen Prinzipalen im Datenkonsumentenkonto Beschreibungsberechtigungen erteilen.
- Auswählen Gewähren.
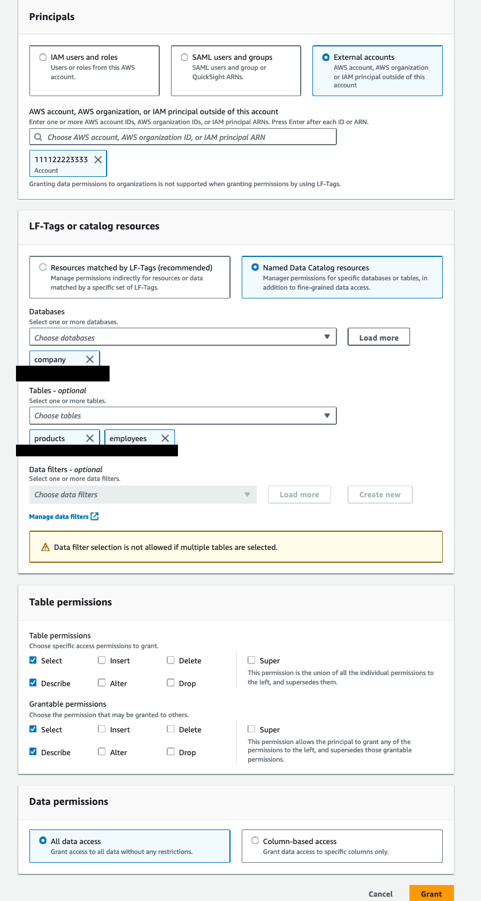
Gewähren Sie dem Datenkonsumentenkonto Tabellenberechtigungen
Führen Sie die folgenden Schritte aus:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenproduzentenkonto.
- Wählen Sie im Navigationsbereich Tische.
- Wähle aus
productsTabelle, die zum gehörtcompanyDatenbank und auf der Aktionen Menü unter Berechtigungen, wählen Gewähren. - Im Die Prinzipien Abschnitt auswählen Externe Konten und geben Sie im AWS-Konto des Datenkonsumenten ein (
111122223333). - Im LF-Tags oder Katalogressourcen Abschnitt auswählen Benannte Datenkatalogressourcen und geben Sie Folgendes an:
- Aussichten für Datenbanken, wählen
company. - Aussichten für Tische, wählen
productsundemployees.
- Aussichten für Datenbanken, wählen
- Im Tabellenberechtigungen Wählen Sie im Abschnitt Auswählen und Beschreiben sowohl Tabellenberechtigungen und Erteilbare Berechtigungen.
Dadurch kann der Data Lake-Administrator im Datenkonsumentenkonto die Tabellen auswählen und beschreiben und anderen Prinzipalen im Datenkonsumentenkonto Berechtigungen zum Auswählen und Beschreiben von Tabellen erteilen.
- Im Datenberechtigungen Abschnitt auswählen Alle Datenzugriff.
- Auswählen Gewähren.
Jetzt haben wir die Einrichtung des Datenproduzentenkontos abgeschlossen.
Richten Sie die Infrastruktur im Datenkonsumentenkonto ein
Führen Sie die folgenden Schritte aus, um die Infrastrukturressourcen zu erstellen:
- Melden Sie sich beim Datenverbraucherkonto an (
111122223333). - Auswählen
Stapel starten um eine CloudFormation-Vorlage bereitzustellen, um die erforderlichen Ressourcen zu erstellen.

- Aussichten für Etikett freigebenGeben Sie das zu verwendende Amazon EMR-Release-Label ein, das nur emr-6.11 oder höher lauten kann.
- Aussichten für InstanztypWählen Sie den Instanztyp für den EMR-Cluster aus, z. B. r4.4xlarge.
- Aussichten für EMRS3BucketNameSuffixGeben Sie das S3-Bucket-Suffix ein, um EMR-Clusterprotokolle und EMR-Notebookdateien zu speichern. Der vollständige S3-Bucket-Name, der erstellt werden soll, lautet
{AWSAccoundId}-{AWSRegion}-{EMRS3BucketNameSuffix}. - Aussichten für S3PathToInTransitCertificateGeben Sie den S3-Pfad für die ZIP-Datei ein, die die PEM-Dateien enthält, die für die Verschlüsselung während der Übertragung verwendet werden.
Anweisungen zum Erstellen der ZIP-Datei, die die PEM-Dateien enthält, und zum Hochladen dieser in Ihren S3-Bucket finden Sie unter Bereitstellung von Zertifikaten zur Verschlüsselung von Daten während der Übertragung mit Amazon EMR-Verschlüsselung.
- Navigieren Sie nach dem Erstellen des CloudFormation-Stacks zur Ausgänge Registerkarte des Stapels.
- Erfassen Sie den Wert von
EMRStudioLinkzur Anmeldung bei EMR Studio.
Akzeptieren Sie die Ressourcenfreigabe im Datenkonsumentenkonto
Um auf freigegebene Ressourcen zugreifen zu können, müssen Sie zunächst die Einladung annehmen.
- Öffnen Sie die AWS RAM-Konsole des Datenkonsumentenkontos mit der IAM-Identität, die über AWS RAM-Zugriff verfügt.
- Wählen Sie im Navigationsbereich Ressourcenfreigaben für Mit mir geteilt.
Sie sollten zwei ausstehende Ressourcenfreigaben vom Datenproduzentenkonto sehen.
- Akzeptieren Sie beide Ressourcenanteile.
Du solltest das sehen company Datenbank, employees Tisch und products Tabelle im Datenkatalog.
Richten Sie Lake Formation im Datenverbraucherkonto ein
In diesem Abschnitt gehen wir die Schritte zum Einrichten von Lake Formation im Datenverbraucherkonto durch.
Richten Sie Einstellungen für die Anwendungsintegration ein
Ähnlich wie bei der Einrichtung im Datenproduzentenkonto müssen Sie Amazon EMR als Sitzungs-Tag registrieren. Auf diesen Wert wird in verwiesen Sicherheitskonfiguration beim Erstellen des EMR-Clusters im CloudFormation-Stack.
Führen Sie dazu die folgenden Schritte aus:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenkonsumentenkonto (
111122223333). - Auswählen Einstellungen zur Anwendungsintegration für Verwaltung im Navigationsbereich.
- Auswählen Erlauben Sie externen Engines, Daten an Amazon S3-Standorten zu filtern, die bei Lake Formation registriert sind.
- Aussichten für Sitzungs-Tag-Werte, eingeben
Amazon EMR. - Aussichten für AWS-Konto-IDsGeben Sie die AWS-Konto-ID des Datenkonsumenten ein (
111122223333). - Auswählen Speichern.
Gewähren Sie Beschreibungsberechtigungen für Laufzeitrollen in der Standarddatenbank
Wenn Sie keine Standarddatenbank in Lake Formation haben oder Ihre Standarddatenbank bereits über Berechtigungen zum Erteilen verfügt IAMAllowedPrinciples, können Sie diesen Schritt überspringen.
Amazon EMR prüft standardmäßig die Standarddatenbank. Wenn Sie bereits über eine Standarddatenbank in Ihrer Lake Formation verfügen, erteilen Sie den Laufzeitrollen in der Standarddatenbank die Beschreibungsberechtigung, indem Sie die folgenden Schritte ausführen:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administratorbenutzer im Datenkonsumentenkonto.
- Wählen Sie im Navigationsbereich Datenbanken.
- Wählen Sie die Standarddatenbank aus und stellen Sie sicher, dass die Besitzerkonto-ID das Datenkonsumentenkonto ist (
111122223333) und auf der Aktionen Menü, wählen Sie Gewähren. - Im Abschnitt GrundsätzeWählen IAM-Benutzer und -Rollen.
- Aussichten für IAM-Benutzer und -Rollen, wählen
sales-runtime-roleundhuman-resource-runtime-role. - Aussichten für LF-Tags oder KatalogressourcenWählen Benannte Datenkatalogressourcen und wählen Sie Standard für Datenbanken.
- Im Datenbankberechtigungen Abschnitt, für Datenbankberechtigungen, wählen Beschreiben.
- Auswählen Gewähren.
Erstellen Sie einen Ressourcenlink für die freigegebene Datenbank
Um auf die Datenbank- und Tabellenressourcen zuzugreifen, die vom AWS-Konto des Datenproduzenten gemeinsam genutzt wurden, müssen Sie ein erstellen Ressourcenlink im AWS-Konto des Datenkonsumenten. Ein Ressourcenlink ist ein Datenkatalogobjekt, das einen Link zu einer lokalen oder gemeinsam genutzten Datenbank oder Tabelle darstellt. Nachdem Sie eine Ressourcenverknüpfung zu einer Datenbank oder Tabelle erstellt haben, können Sie den Ressourcenverknüpfungsnamen überall dort verwenden, wo Sie auch den Datenbank- oder Tabellennamen verwenden würden. In diesem Schritt erteilen Sie den Laufzeitrollenprinzipien Berechtigungen für die Ressourcenverknüpfungen. Die Laufzeitrollen greifen dann über den Ressourcenlink auf die Daten in gemeinsam genutzten Datenbanken und zugrunde liegenden Tabellen zu.
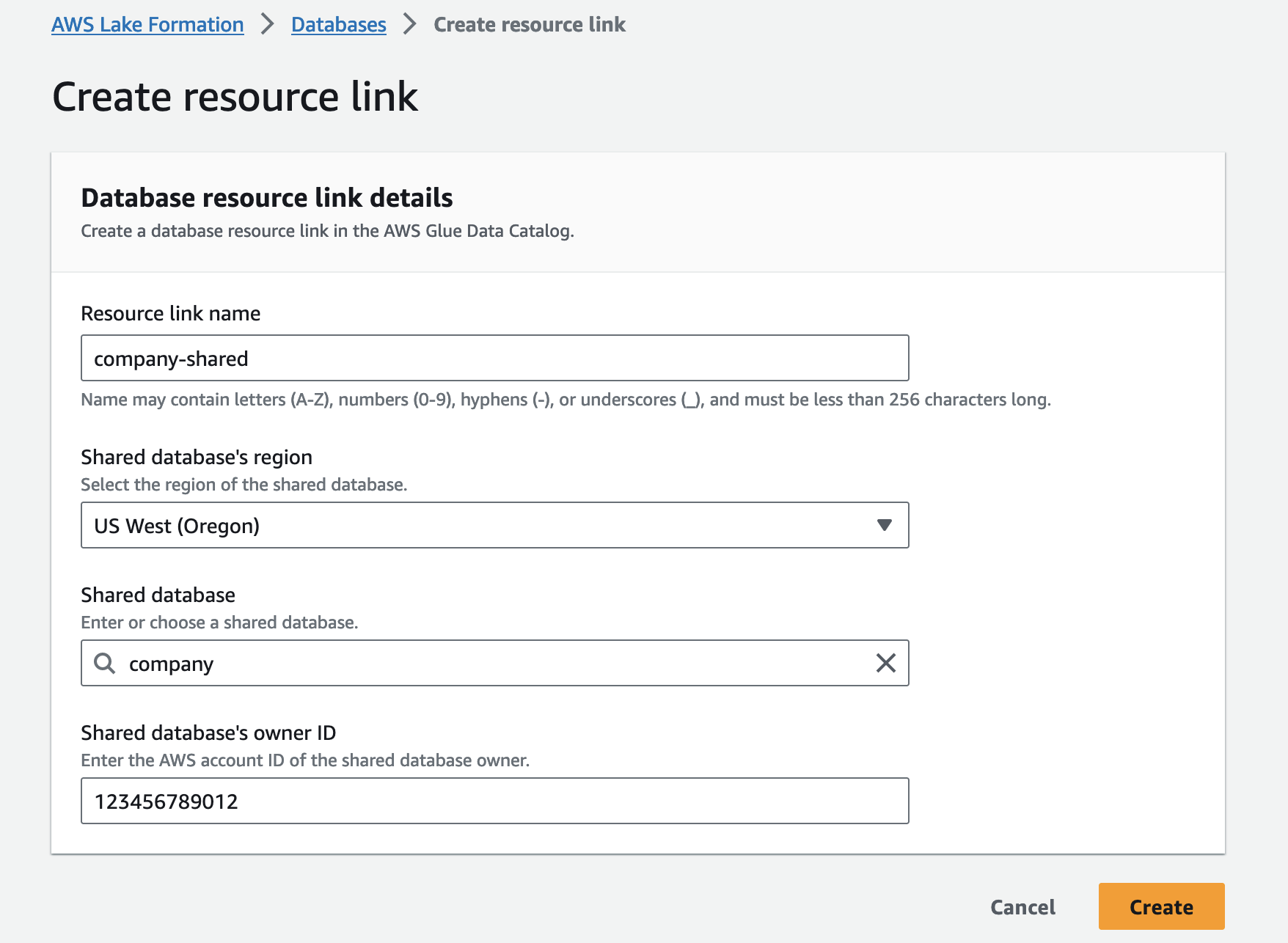
Führen Sie die folgenden Schritte aus, um einen Ressourcenlink zu erstellen:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenkonsumentenkonto.
- Wählen Sie im Navigationsbereich Datenbanken.
- Wähle aus
companyÜberprüfen Sie in der Datenbank, ob die Besitzerkonto-ID das Datenproduzentenkonto ist (123456789012) und auf der Aktionen Menü, wählen Sie Erstellen Sie Ressourcenlinks. - Aussichten für Name des Ressourcenlinks, geben Sie den Namen des Ressourcenlinks ein (z. B.
company-shared). - Aussichten für Region der freigegebenen Datenbank, wählen Sie die Region aus
companyDatenbank. - Aussichten für Freigegebene Datenbank, wählen Sie die Firmendatenbank.
- Aussichten für Die Besitzer-ID der freigegebenen DatenbankGeben Sie die Konto-ID des Datenproduzentenkontos ein (
123456789012). - Auswählen Erstellen.
Erteilen Sie Berechtigungen für den Ressourcenlink zum Laufzeitrollenprinzip
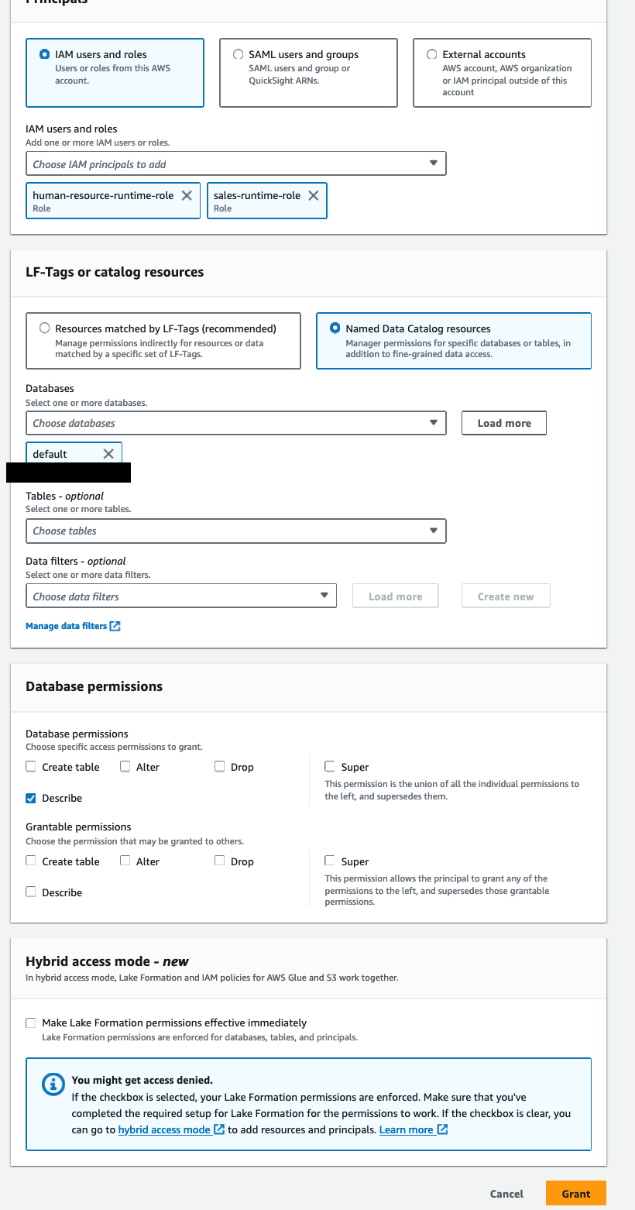
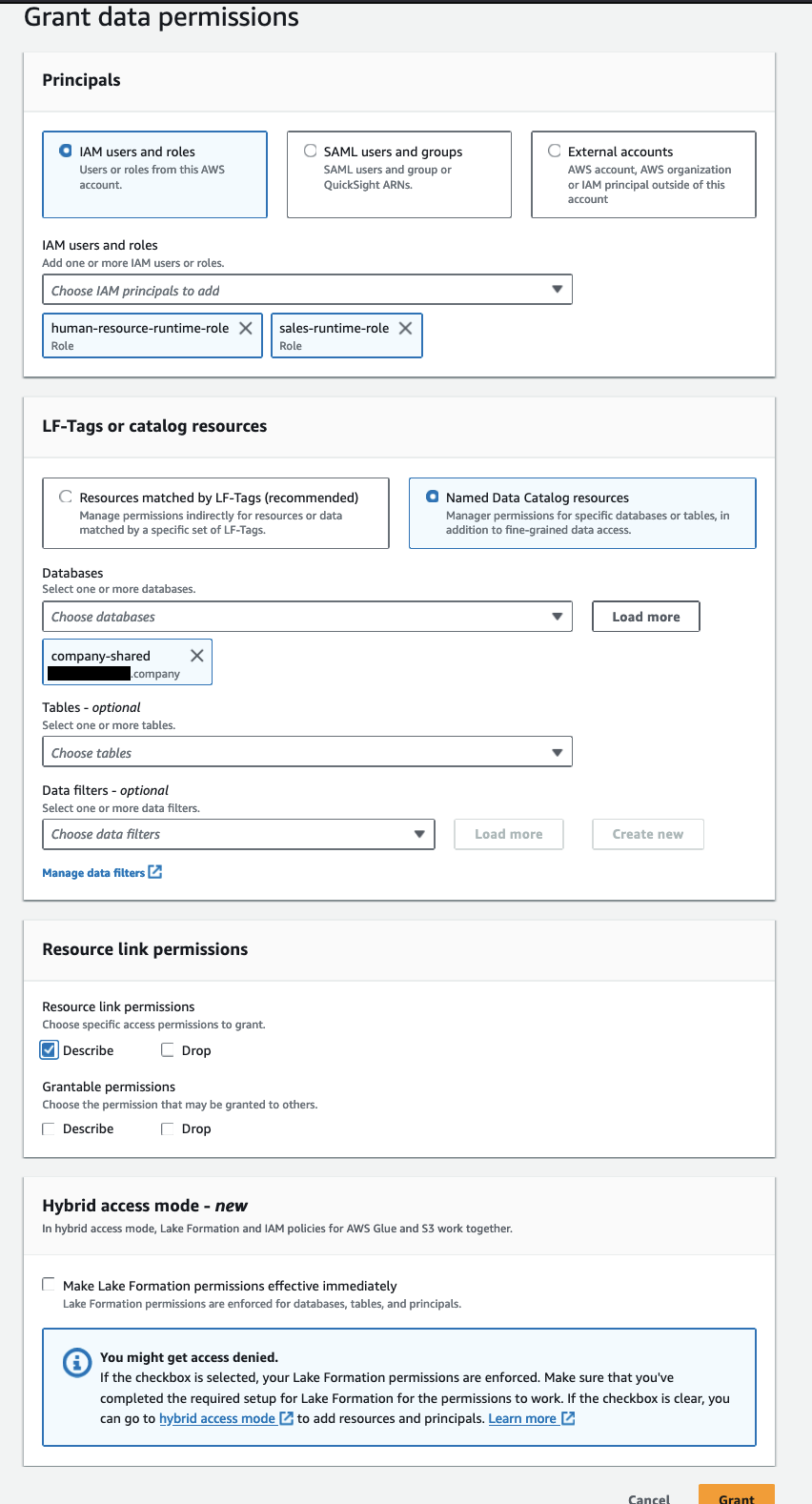
Erteilen Sie Berechtigungen für den Ressourcenlink zu „sales-runtime-role“ und „human-resource-runtime-role“, indem Sie die folgenden Schritte ausführen:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenkonsumentenkonto.
- Wählen Sie im Navigationsbereich Datenbanken.
- Wählen Sie den Ressourcenlink (
company-shared) und auf der Aktionen Menü, wählen Sie Gewähren. - Im Die Prinzipien Abschnitt auswählen IAM-Benutzer und -Rollen, und wähle
sales-runtime-roleundhuman-resource-runtime-role. - Im LF-Tags oder Katalogressourcen Abschnitt, für Datenbanken, wählen
company-shared. - Im Berechtigungen für Ressourcenlinks Abschnitt auswählen Beschreiben.
Dadurch können die Laufzeitrollen die Ressourcenverknüpfung beschreiben. Wir treffen keine Auswahl für erteilbare Berechtigungen, da Laufzeitrollen nicht in der Lage sein sollten, anderen Prinzipien Berechtigungen zu erteilen.
- Auswählen Gewähren.
Erteilen Sie dem Laufzeitrollenprinzip Berechtigungen für die Tabellen
Sie müssen Berechtigungen für die Tabellen erteilen sales-runtime-role und human-resource-runtime-role um den Datenzugriff zu erlauben:
Human-resource-runtime-rolesollte über Beschreibungs- und Auswahlberechtigungen für alle Spalten im verfügenemployeesTabelle und keine Berechtigungen für dieproductsTabelle.Sales-runtime-rolesollte über Auswahlberechtigungen für die Spalten verfügenuid,nameunddepartmentderemployeesTabelle und beschreiben und wählen Sie Berechtigungen für alle Spalten in der ausproductsTabelle.
Erteilen Sie der Human-Resource-Runtime-Rolle die Berechtigung für die Mitarbeitertabelle
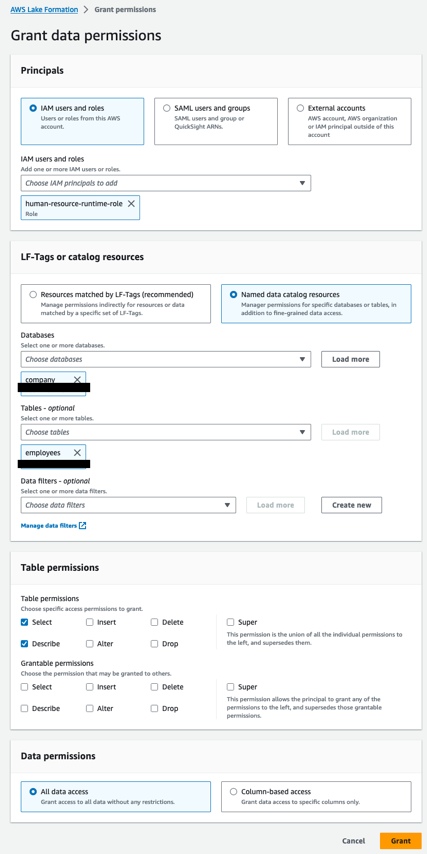
Führen Sie die folgenden Schritte aus:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenkonsumentenkonto.
- Wählen Sie im Navigationsbereich Datenbanken.
- Wählen Sie den Ressourcenlink (
company-shared) und auf der Aktionen Menü, wählen Sie Grant on Target. - Im Abschnitt GrundsätzeWählen IAM-Benutzer und -Rollen, Dann wählen
human-resource-runtime-role. - Im LF-Tags oder Katalogressourcen Abschnitt auswählen Benannte Datenkatalogressourcen und geben Sie Folgendes an:
- Aussichten für Datenbanken, wählen
company. - Aussichten für Tischewählen
employees.
- Aussichten für Datenbanken, wählen
- Im Tabellenberechtigungen Abschnitt, für TabellenberechtigungenWählen Beschreiben und Auswählen.
- Im Datenberechtigungen Abschnitt auswählen Alle Datenzugriff.
- Auswählen Gewähren.
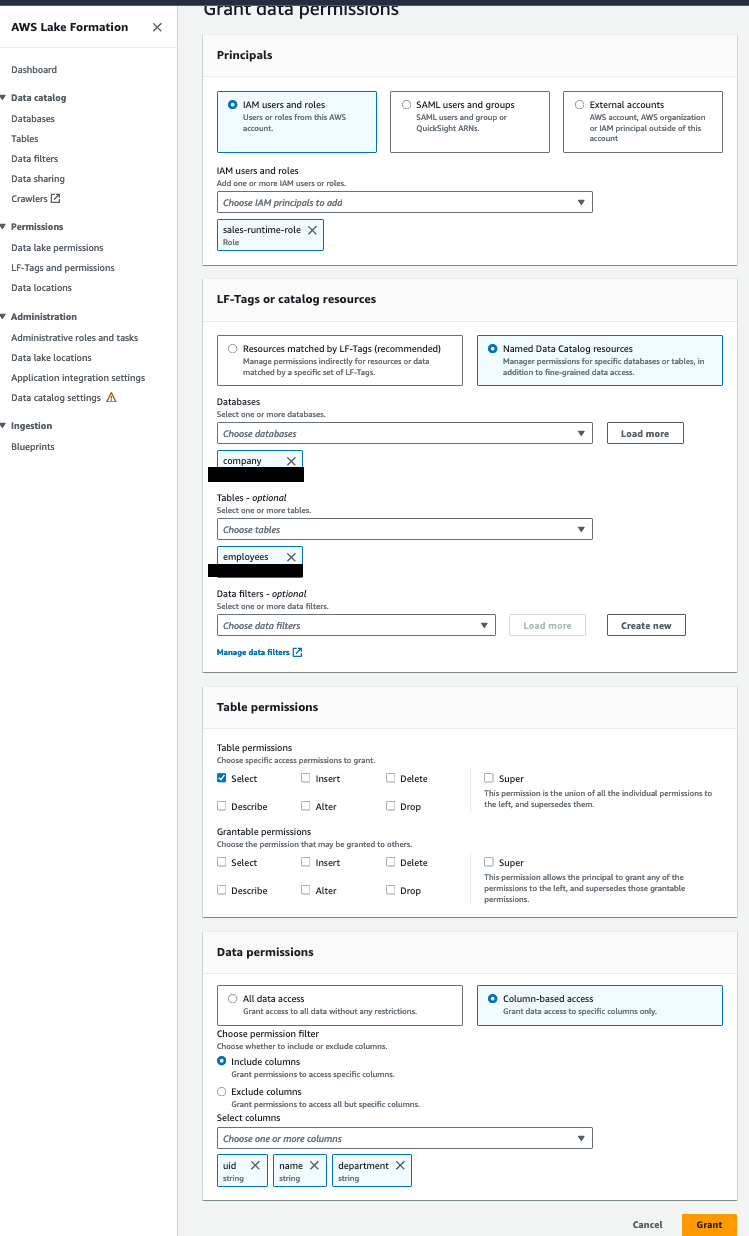
Erteilen Sie der sales-runtime-role die Berechtigung für die Mitarbeitertabelle
Führen Sie die folgenden Schritte aus:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenkonsumentenkonto.
- Wählen Sie im Navigationsbereich Datenbanken.
- Wählen Sie den Ressourcenlink (
company-shared) und auf der Aktionen Menü, wählen Sie Grant on Target. - Im Abschnitt GrundsätzeWählen IAM-Benutzer und -Rollen, Dann wählen
sales-runtime-role. - Im LF-Tags oder Katalogressourcen Abschnitt auswählen Benannte Datenkatalogressourcen und geben Sie Folgendes an:
- Aussichten für Datenbanken, wählen
company. - Aussichten für Tische, wählen
employees.
- Aussichten für Datenbanken, wählen
- Im Tabellenberechtigungen Abschnitt, für TabellenberechtigungenWählen Auswählen.
- Im Datenberechtigungen Abschnitt auswählen Spaltenbasierter Zugriff.
- Auswählen Spalten einschließen und wähle das
uid,nameunddepartmentSäulen. - Auswählen Gewähren.
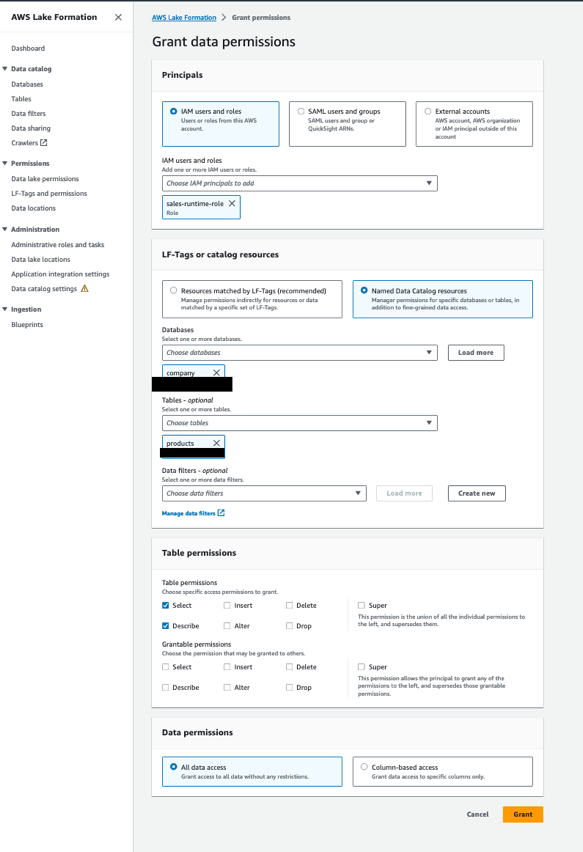
Erteilen Sie der Sales-Runtime-Rolle die Berechtigung für die Produkttabelle
Führen Sie die folgenden Schritte aus:
- Öffnen Sie die Lake Formation-Konsole mit dem Lake Formation Data Lake-Administrator im Datenkonsumentenkonto.
- Wählen Sie im Navigationsbereich Datenbanken.
- Wählen Sie den Ressourcenlink (
company-shared) und auf der Aktionen Menü, wählen Sie Grant on Target. - Im Abschnitt GrundsätzeWählen IAM-Benutzer und -Rollen, Dann wählen
sales-runtime-role. - Im LF-Tags oder Katalogressourcen Abschnitt auswählen Benannte Datenkatalogressourcen und geben Sie Folgendes an:
- Aussichten für Datenbanken, wählen
company. - Aussichten für Tische, wählen
products.
- Aussichten für Datenbanken, wählen
- Im Tabellenberechtigungen Abschnitt, für TabellenberechtigungenWählen Auswählen und Beschreiben.
- Im Datenberechtigungen Abschnitt auswählen Alle Datenzugriff.
- Auswählen Gewähren.
Melden Sie sich bei EMR Studio an und nutzen Sie den EMR Studio Workspace
Wechseln Sie Ihre Rolle zu alice-role or bob-role auf der Konsole mit verschiedenen Webbrowsern, um den Zugriff zu testen. Öffne das EMRStudioLink URL aus der CloudFormation-Stack-Ausgabe, um sich mit jeder Rolle beim EMR Studio anzumelden, und führen Sie dann die folgenden Schritte aus:
- Auswählen Workspaces im Navigationsbereich und wählen Sie Erstellen Sie Arbeitsbereich.
- Geben Sie einen Namen und eine Beschreibung für den Arbeitsbereich ein.
- Auswählen Erstellen Sie Arbeitsbereich.
Eine neue Registerkarte mit JupyterLab wird automatisch geöffnet, wenn der Arbeitsbereich bereit ist. Aktivieren Sie bei Bedarf Pop-ups in Ihrem Browser.
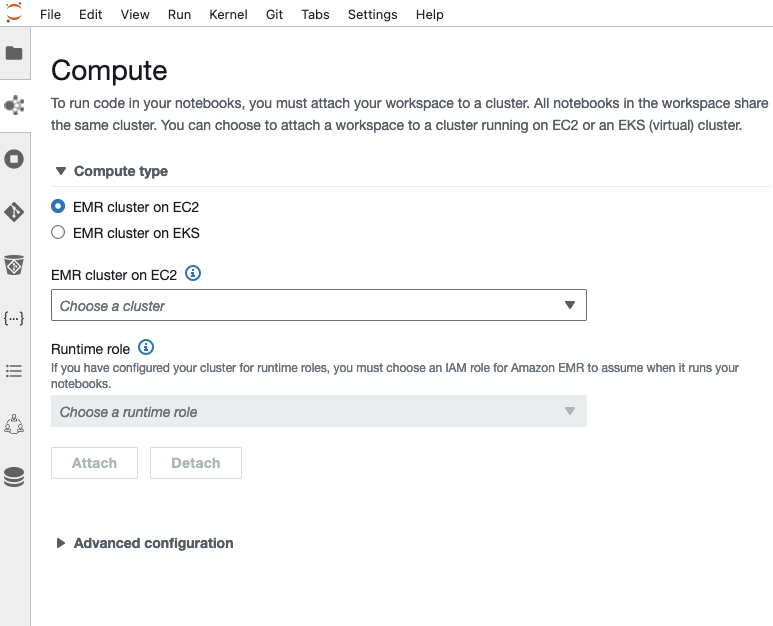
- Wählen Sie die Berechnen Symbol im Navigationsbereich, um den EMR Studio-Arbeitsbereich mit einer Rechen-Engine zu verbinden.
- Auswählen EMR-Cluster auf EC2 für Compute-Typ.
- Wählen Sie die EMR-Cluster-ID aus, die Sie mit AWS CloudFormation erstellt haben.
- Aussichten für Laufzeitrolle, wählen
sales-runtime-rolewenn angemeldet alsalice-role. Wählen Siehuman-resource-runtime-rolewenn angemeldet alsbob-role. - Auswählen Anfügen.
Führen Sie Code im EMR Studio Workspace aus und überprüfen Sie den Datenzugriff
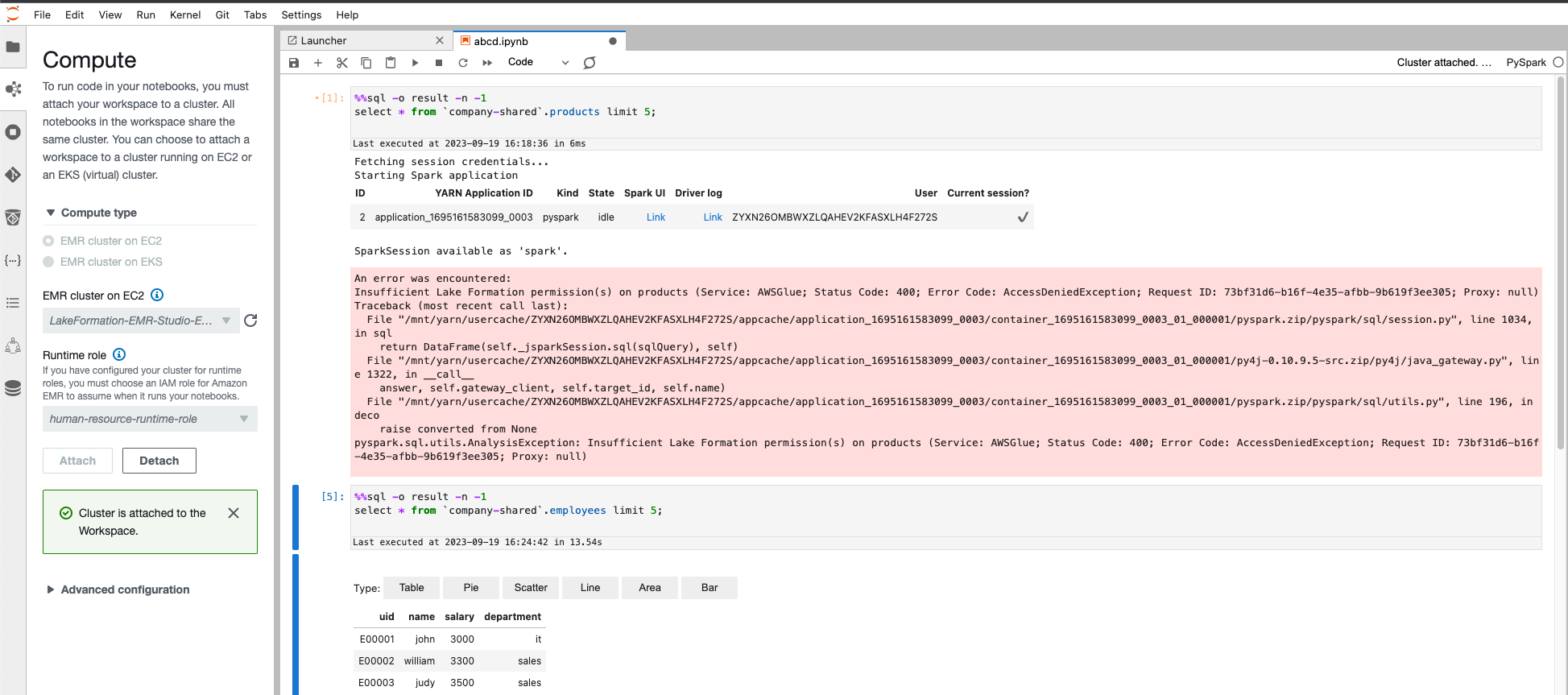
Führen Sie den folgenden Code im EMR Studio Workspace mit einem PySpark-Kernel aus, nachdem Sie sich mit alice-role oder bob-role angemeldet haben:
Bei der Verwendung verschiedener Rollen sollten unterschiedliche Ergebnisse angezeigt werden.
Gemäß unserer Datenzugriffskonfiguration in Lake Formation hat Alice vollen Datenzugriff für products Tisch. Sie kann alle Spalten außer dem Gehalt im sehen employees Tabelle.
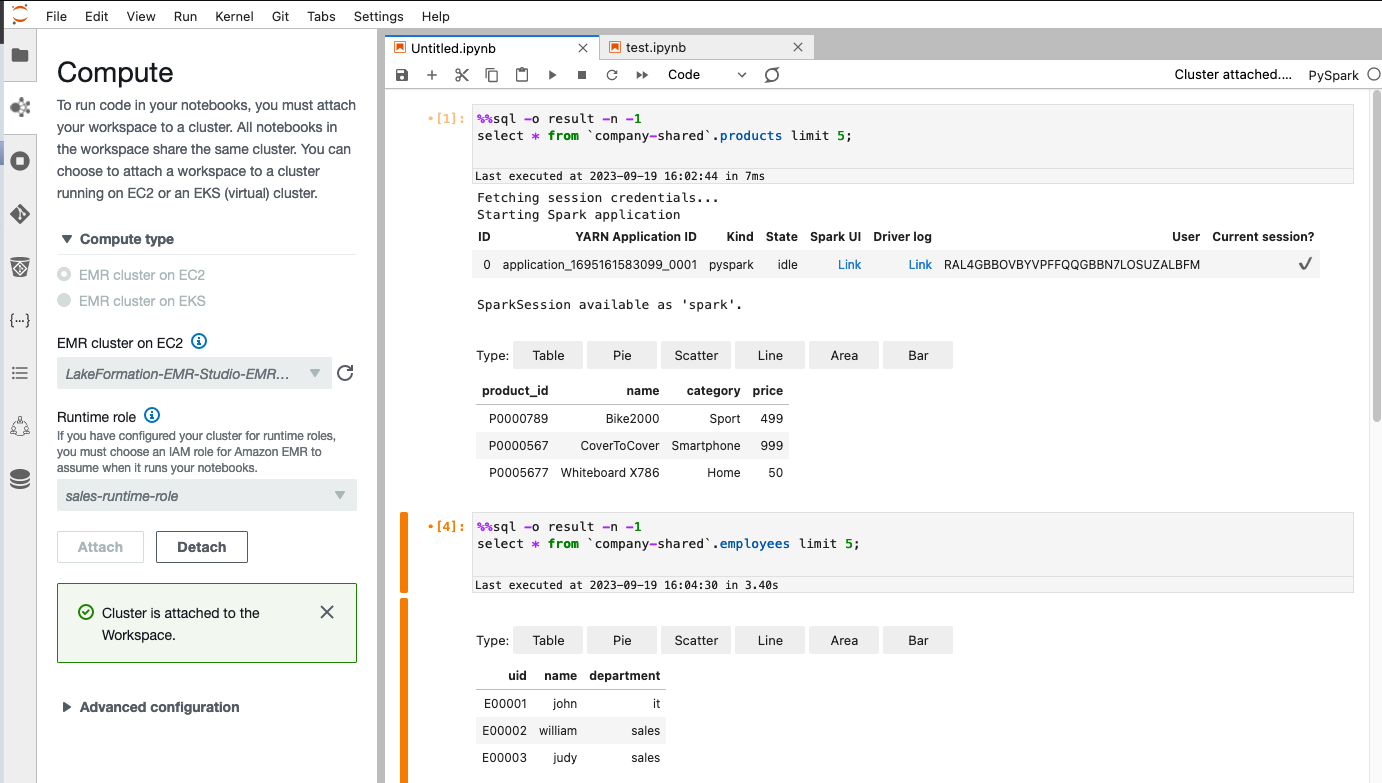
Für Bob wird er gemäß unserer Datenzugriffskonfiguration in Lake Formation vollen Datenzugriff auf die haben employees Tabelle, aber er hat keinen Zugriff auf die products Tabelle.
Aufräumen
Wenn Sie mit dem Experimentieren mit dieser Lösung fertig sind, bereinigen Sie Ihre Ressourcen:
- Stoppen und löschen Sie die EMR Studio-Arbeitsbereiche, die im AWS-Konto des Datenkonsumenten erstellt wurden.
- Löschen Sie den gesamten Inhalt im S3-Bucket
EMRS3Bucketim AWS-Konto des Datenkonsumenten. - Löschen Sie den CloudFormation-Stack im AWS-Konto des Datenkonsumenten.
- Löschen Sie den gesamten Inhalt im S3-Bucket
DataLakeS3Bucketim AWS-Konto des Datenproduzenten. - Löschen Sie den CloudFormation-Stack im AWS-Konto des Datenproduzenten.
Zusammenfassung
In diesem Beitrag wurde gezeigt, wie Sie mithilfe von Laufzeitrollen eine Verbindung zu einem EMR Studio-Arbeitsbereich mit Amazon EMR herstellen und eine kontoübergreifende, fein abgestimmte Datenzugriffskontrolle mit Lake Formation anwenden können. Wir haben auch gezeigt, wie sich mehrere EMR Studio-Benutzer mit demselben EMR-Cluster verbinden können, wobei jeder eine Laufzeitrolle mit Berechtigungen verwendet, die seiner individuellen Zugriffsebene auf Daten entsprechen.
Weitere Informationen zur Verwendung von EMR Studio Workspaces mit Lake Formation finden Sie unter Führen Sie einen EMR Studio-Arbeitsbereich mit einer Laufzeitrolle aus. Wir empfehlen Ihnen, diese neue Funktionalität auszuprobieren und uns zu kontaktieren, wenn Sie Fragen oder Feedback haben!
Über die Autoren
 Ashley Zhou ist Softwareentwicklungsingenieur bei AWS. Sie interessiert sich für Datenanalyse und verteilte Systeme.
Ashley Zhou ist Softwareentwicklungsingenieur bei AWS. Sie interessiert sich für Datenanalyse und verteilte Systeme.
 Srividya Parthasarathy ist Senior Big Data Architect im AWS Lake Formation Team. Sie entwickelt gerne Analyse- und Data-Mesh-Lösungen auf AWS und teilt sie mit der Community.
Srividya Parthasarathy ist Senior Big Data Architect im AWS Lake Formation Team. Sie entwickelt gerne Analyse- und Data-Mesh-Lösungen auf AWS und teilt sie mit der Community.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/use-iam-runtime-roles-with-amazon-emr-studio-workspaces-and-aws-lake-formation-for-cross-account-fine-grained-access-control/
- :hast
- :Ist
- :nicht
- $UP
- 100
- 107
- 11
- 20
- 7
- 8
- a
- Fähig
- LiveBuzz
- Akzeptieren
- Zugang
- Zugriff auf Daten
- Zugriff
- zugänglich
- Nach
- Konto
- Trading Konten
- über
- Nach der
- Alice
- Alle
- erlauben
- erlaubt
- erlaubt
- bereits
- ebenfalls
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- Analyse
- Analytik
- und
- jedem
- Apache
- Apache Funken
- Anwendung
- Anwendungen
- Bewerben
- Architektur
- SIND
- AS
- At
- anhängen
- autorisieren
- Im Prinzip so, wie Sie es von Google Maps kennen.
- AWS
- AWS CloudFormation
- AWS-Kleber
- AWS Lake-Formation
- BE
- weil
- gehört
- zwischen
- Big
- Big Data
- Getreide
- beide
- Browser
- Browsern
- Building
- aber
- by
- CAN
- Erfassung
- Katalog
- Kategorie
- CD
- Zertifikate
- Übernehmen
- aus der Ferne überprüfen
- Wahl
- Auswählen
- reinigen
- Cluster
- Code
- Spalten
- community
- Unternehmen
- Unternehmen
- abschließen
- Abschluss
- Berechnen
- Konfiguration
- Vernetz Dich
- Connects
- Geht davon
- besteht
- Konsul (Console)
- Verbraucher
- enthält
- Inhalt
- Smartgeräte App
- erstellen
- erstellt
- Erstellen
- Referenzen
- Strom
- technische Daten
- Datenzugriff
- Datenanalyse
- Datenanalyse
- Datensee
- Datenwissenschaft
- Datenwissenschaftler
- Datenübertragung
- Datenbase
- Datenbanken
- Standard
- definieren
- zeigen
- Synergie
- Abteilung
- einsetzen
- beschreiben
- Beschreibung
- entwickeln
- Entwicklung
- Unterschiede
- anders
- Direkt
- verteilt
- verteilte Systeme
- do
- Tut nicht
- Nicht
- nach unten
- jeder
- Mitarbeiter
- Mitarbeiter
- ermöglichen
- ermöglichen
- ermutigen
- Verschlüsselung
- erzwingen
- Motor
- Ingenieur
- Entwicklung
- Ingenieure
- Motor (en)
- Enter
- Unternehmen
- Arbeitsumfeld
- Äther (ETH)
- Beispiel
- Außer
- Erklären
- extern
- Reichen Sie das
- Mappen
- Filter
- Vorname
- Folgende
- folgt
- Aussichten für
- Ausbildung
- für
- voller
- voll
- Funktionalität
- gegeben
- Go
- regiert
- gewähren
- erteilt
- Gruppe an
- hätten
- glücklich
- Haben
- he
- hilft
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- human
- PERSONAL
- Human Resources
- IAM
- ID
- Identitätsschutz
- if
- zeigt
- umgesetzt
- in
- Dazu gehören
- Einschließlich
- Krankengymnastik
- Information
- Infrastruktur
- Instanz
- Anleitung
- integriert
- Integration
- interessiert
- einführen
- Einladung
- IT
- Jobs
- jpg
- Label
- See
- Seen
- grosse
- Große Unternehmen
- starten
- LERNEN
- Niveau
- LIMIT
- LINK
- Links
- aus einer regionalen
- Standorte
- Standorte
- Maschine
- um
- MACHT
- verwalten
- verwaltet
- Management
- Managed
- viele
- Abstimmung
- Mechanismus
- MENÜ
- ineinander greifen
- könnte
- mehr
- schlauer bewegen
- mehrere
- sollen
- Name
- Namens
- Navigieren
- Menü
- notwendig,
- Need
- erforderlich
- Neu
- weiter
- nicht
- Notizbuch
- Laptops
- jetzt an
- Objekt
- of
- vorgenommen,
- on
- einzige
- XNUMXh geöffnet
- Betriebs-
- or
- Andere
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- Eigentümer
- Brot
- Weg
- schwebend
- Erlaubnis
- Berechtigungen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Politik durchzulesen
- Post
- Werkzeuge
- Voraussetzungen
- früher
- Principal
- Auftraggeber
- Prinzip
- Grundsätze
- Hersteller
- Produkt
- Produkte
- Profil
- Profil
- die
- vorausgesetzt
- bietet
- Zweck
- Python
- Abfragen
- Fragen
- R
- RAM
- Roh
- Rohdaten
- bereit
- Veteran
- siehe
- Region
- Registrieren
- eingetragen
- Registrieren
- Release
- Anforderung
- Ressourcen
- Downloads
- Folge
- Die Ergebnisse
- Rollen
- Rollen
- Führen Sie
- Laufen
- Gehalt
- Vertrieb
- gleich
- Scala
- Wissenschaft
- Wissenschaftler
- Wissenschaftler
- Skript
- Abschnitt
- Abschnitte
- sehen
- ausgewählt
- Senior
- getrennte
- Server
- Lösungen
- Sitzung
- kompensieren
- Einstellung
- Einstellungen
- Setup
- Teilen
- von Locals geführtes
- Shares
- ,,teilen"
- sie
- sollte
- zeigte
- Schild
- unterzeichnet
- Unterzeichnung
- Einfacher
- Single
- Software
- Software-Entwicklung
- verkauft
- Lösung
- Lösungen
- Quellen
- Spark
- Stapel
- Schritt
- Shritte
- Lagerung
- speichern
- gelagert
- Läden
- einfach
- Studio Adressen
- eingereicht
- so
- liefern
- Unterstützt
- Systeme und Techniken
- Tabelle
- TAG
- Team
- Vorlage
- vorübergehend
- Test
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- deswegen
- fehlen uns die Worte.
- diejenigen
- Durch
- Timeline
- zu
- Werkzeuge
- Transit
- versuchen
- XNUMX
- tippe
- typisch
- ui
- für
- zugrunde liegen,
- Uploading
- URL
- us
- -
- benutzt
- Mitglied
- Nutzer
- verwendet
- Verwendung von
- Wert
- überprüfen
- Version
- Anzeigen
- visualisieren
- Spaziergang
- we
- Netz
- Internetbrowser
- Web-Services
- waren
- wann
- welche
- ganze
- werden wir
- mit
- .
- arbeiten,
- würde
- schreiben
- geschrieben
- YAML
- U
- Ihr
- Zephyrnet
- PLZ