Bild vom Autor
Zeiten ändern sich. Wenn Sie im Jahr 2023 Datenwissenschaftler werden möchten, sollten Sie Ihrer Liste mehrere neue Fähigkeiten hinzufügen sowie eine Reihe vorhandener Fähigkeiten, die Sie bereits beherrschen sollten.
Warum so viele Fähigkeiten? Ein Teil des Problems ist das Kriechen des Auftragsumfangs. Niemand weiß, was ein Data Scientist ist oder was er tun sollte, am allerwenigsten Ihr zukünftiger Arbeitgeber. Alles, was Daten enthält, bleibt also in der Kategorie Data Science hängen, mit der Sie sich befassen müssen.
Von Ihnen wird erwartet, dass Sie wissen, wie man Daten bereinigt, transformiert, statistisch analysiert, visualisiert, kommuniziert und vorhersagt. Nicht nur das, sondern auch neue Technologien (oder Technologien, die kürzlich den Mainstream erreicht haben) könnten zu Ihren beruflichen Verantwortlichkeiten hinzugefügt werden.
In diesem Artikel werde ich die 19 wichtigsten Fähigkeiten aufschlüsseln, die Sie im Jahr 2023 kennen müssen, um ein Data Scientist zu sein.
Hier ein Überblick über die zehn wichtigsten.
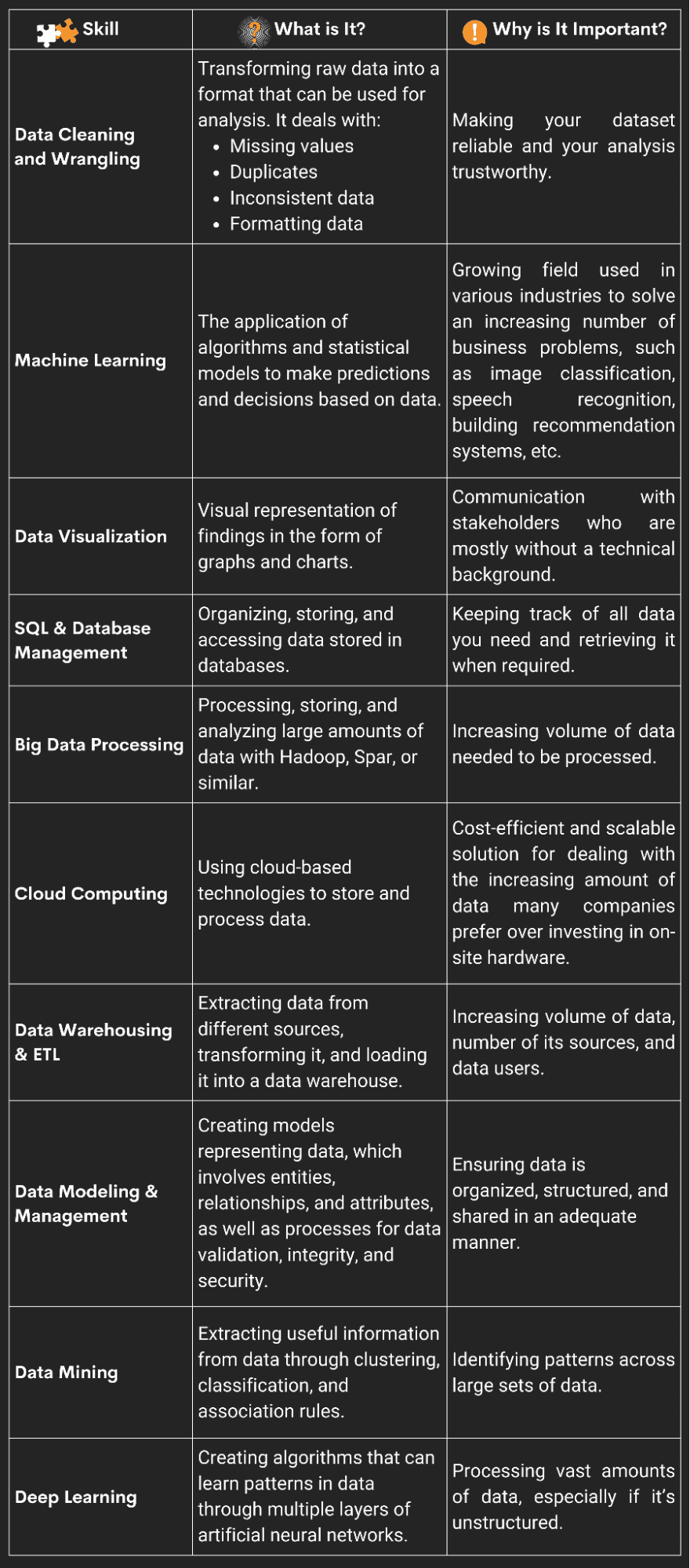
Bild vom Autor
Diese Fähigkeiten werden Ihnen helfen, einen Job zu bekommen, ein Vorstellungsgespräch zu meistern, der Kurve voraus zu bleiben und für diese Beförderung zu verhandeln. In jedem Abschnitt fasse ich kurz zusammen, was jede Fähigkeit ist, warum sie wichtig ist, und biete einige Orte an, an denen diese Fähigkeiten erlernt werden können.
Während es ist nicht 80 % des Jobs eines Datenwissenschaftlers, Datenbereinigung und -gerangel sind immer noch eine der wichtigsten Fähigkeiten, die ein Datenwissenschaftler im Jahr 2023 beherrschen kann.
Was ist Datenbereinigung und Wrangling?
Datenbereinigung und Wrangling sind die Prozesse zur Umwandlung von Rohdaten in ein Format, das für die Analyse verwendet werden kann. Dazu gehören der Umgang mit fehlenden Werten, das Entfernen von Duplikaten, der Umgang mit inkonsistenten Daten und das Formatieren der Daten in einer Weise, die sie für die Analyse bereit macht.
Das Bereinigen der Daten bezieht sich normalerweise darauf, schlechte/ungenaue Werte zu beseitigen, Lücken auszufüllen, Duplikate zu finden und auf andere Weise sicherzustellen, dass Ihr Datensatz so makellos und zuverlässig genau ist, wie es erwartet werden kann. Ihn zu zerren (oder ihn zu mungen, ihn zu massieren oder irgendein anderes seltsames Verb wie dieses) bedeutet, ihn in eine analysierbare Form zu bringen. Sie konvertieren es oder mappen es in ein anderes, einfacher zu betrachtendes Format.
Warum ist es wichtig, 2023 Data Scientist zu werden?
Fragen Sie einen beliebigen Datenwissenschaftler, was er tut, und eines der ersten Dinge, die er erwähnt, ist Datenbereinigung und -gerangel. Daten kommen nie in einer schönen, sauberen, analysierbaren Form in Ihre Hände, daher ist es äußerst wichtig zu wissen, wie man sie aufräumt.
Die Möglichkeit, Daten zu bereinigen und zu verfälschen, stellt sicher, dass Ihre Analyseergebnisse vertrauenswürdig sind, und hilft, falsche Schlussfolgerungen zu vermeiden.
Wo kann man diese Schlüsselkompetenz lernen?
Es gibt viele großartige Optionen, um Datenbereinigung und Wrangling zu lernen. Harvard bietet a Kurs auf EdX. Sie können auch selbst üben, indem Sie kostenlose Rohdatensätze wie den Common Crawl, Web-Crawling-Daten, die aus über 50 Milliarden Webseiten bestehen, bereinigen und durcheinander bringen (hier) oder Brasiliens Wetterdaten (hier).
Nein, es ist nicht nur ein Schlagwort! Maschinelles Lernen ist eine sehr wichtige Fähigkeit für jeden zukünftigen Datenwissenschaftler.
Was ist maschinelles Lernen?
Maschinelles Lernen ist die Anwendung von Algorithmen und statistischen Modellen, um Vorhersagen und Entscheidungen auf der Grundlage von Daten zu treffen.
Es ist ein Teilbereich der künstlichen Intelligenz, der es Computern ermöglicht, ihre Leistung bei einer bestimmten Aufgabe zu verbessern, indem sie aus Daten lernen, ohne explizit programmiert zu werden. Es hilft bei der Automatisierung. Sie finden es in jeder Branche.
Warum ist es wichtig, 2023 Data Scientist zu werden?
Sie müssen über maschinelles Lernen im Jahr 2023 Bescheid wissen, da es sich um ein schnell wachsendes Gebiet handelt, das zu einem entscheidenden Werkzeug für die Lösung komplexer Probleme und die Erstellung von Vorhersagen in verschiedenen Branchen geworden ist.
Algorithmen für maschinelles Lernen können verwendet werden, um Bilder zu klassifizieren, Sprache zu erkennen, natürliche Sprache zu verarbeiten und Empfehlungssysteme zu erstellen. Es wird Ihnen schwerfallen, eine Branche zu finden, die diese ML-unterstützten Aufgaben nicht erledigt (oder nicht tun will).
Die Beherrschung des maschinellen Lernens ermöglicht es einem Datenwissenschaftler, wertvolle Erkenntnisse aus großen und komplexen Datensätzen zu extrahieren und Vorhersagemodelle zu entwickeln, die bessere Geschäftsentscheidungen ermöglichen.
Wo kann man diese Schlüsselkompetenz lernen?
Wir haben ein Repository von über dreißig Machine-Learning-Projekte auf ScrataScratch, um diese Fähigkeit in Ihrem Lebenslauf hervorzuheben. TensorFlow hat auch eine Reihe großartiger kostenloser Ressourcen zum Erlernen des maschinellen Lernens.

Bild vom Autor
Diese Fähigkeit ist ziemlich selbsterklärend. Wenn Sie Zahlen analysieren, werden wichtige Interessengruppen Ihre Ergebnisse mit hübschen Grafiken und Diagrammen verstehen wollen.
Was ist Datenvisualisierung?
Datenvisualisierung ist die Erstellung von Diagrammen, Grafiken und anderen Grafiken, um Daten leichter verständlich zu machen. Sie nehmen die Zahlen, die Sie gerade bereinigt, gerendert oder vorhergesagt haben, und bringen sie in ein visuelles Format, entweder um Trends mit anderen zu kommunizieren oder um Trends leichter erkennbar zu machen.
Warum ist es wichtig, 2023 Data Scientist zu werden?
Im Jahr 2023 ist es für einen Data Scientist entscheidend, Daten visualisieren zu können. Es ist, als hätte man eine geheime Superkraft, um verborgene Muster und Trends in den Daten aufzudecken, die auf den ersten Blick vielleicht nicht offensichtlich sind. Und das Beste? Sie können Ihre Ergebnisse auf ansprechende und einprägsame Weise mit anderen teilen. Als Data Scientist arbeiten Sie mit Gruppen aller Erfahrungsstufen, aber ein Bild ist viel leichter zu verstehen als eine Reihe von Zahlen.
Wenn Sie also ein Datenwissenschaftler sein möchten, der Ihre Erkenntnisse und Entdeckungen effektiv kommunizieren kann, ist es wichtig, die Kunst der Datenvisualisierung zu beherrschen.
Wo kann man diese Schlüsselkompetenz lernen?
Hier ist eine Liste von freien Orten, um Daten zu lernen, nämlich.
SQL ist eine strukturierte Abfragesprache. Data Scientists verwenden SQL, um mit SQL-Datenbanken zu arbeiten, Datenbanken zu verwalten und Datenspeicherungsaufgaben durchzuführen.
Was ist SQL und Datenbankmanagement?
SQL ist eine sehr beliebte Sprache, mit der Sie auf strukturierte Daten zugreifen und diese bearbeiten können. Es geht Hand in Hand mit der Datenbankverwaltung, die üblicherweise in SQL erfolgt. Bei der Datenbankverwaltung können Sie im Grunde Daten organisieren, speichern und von einem Ort abrufen. SQL-Datenbanken sind eine davon Top-Backend-Technologien 2023 zu lernen, also nicht nur für Data Science.
Warum ist es wichtig, 2023 Data Scientist zu werden?
Als Data Scientist müssen Sie den Überblick über alle Daten behalten, sicherstellen, dass sie organisiert sind, und sie abrufen, wenn jemand sie benötigt. Das ist es, was Sie mit SQL und der Datenbankverwaltung tun können.
Wo kann man diese Schlüsselkompetenz lernen?
Coursera hat eine Tonne von großartigen, preisgünstigen Datenbankverwaltungs-/Administrationskursen, die Sie ausprobieren können. Sie können auch eine Vorschau auf einige erhalten SQL-Interviewfragen hier, die nützlich sein können, um Ihr Wissen zu testen.
Big Data ist ein Schlagwort, ja, aber es ist auch ein echtes Konzept – Oracle definiert es als „Daten, die eine größere Vielfalt enthalten, in zunehmendem Umfang und mit größerer Geschwindigkeit ankommen“ oder Daten mit den drei Vs.
Was ist Big-Data-Verarbeitung?
Big-Data-Verarbeitung ist die Fähigkeit, große Datenmengen mit Technologien wie Hadoop und Spark zu verarbeiten, zu speichern und zu analysieren.
Warum ist es wichtig, 2023 Data Scientist zu werden?
Im Jahr 2023 ist die Fähigkeit, Big Data zu verarbeiten, für Data Scientists von entscheidender Bedeutung. Das Volumen der generierten Daten wächst weiterhin exponentiell, und die Fähigkeit, diese Daten effektiv zu handhaben und zu analysieren, ist unerlässlich, um fundierte Entscheidungen zu treffen und wertvolle Erkenntnisse zu gewinnen. Data Scientists, die über ein tiefes Verständnis von Big-Data-Verarbeitungstechniken verfügen, können problemlos mit großen Datensätzen arbeiten und das Beste aus den darin enthaltenen Informationen machen.
Dank seiner Schlagwortigkeit schadet es auch nie, „Big Data“ in Ihren Lebenslauf zu packen.
Wo kann man es lernen?
Ich liebe Simplilearns YouTube-Tutorial-Reihe auf diesem Konzept.

Bild vom Autor
Es ist lustig – da immer mehr Produkte und Dienste in die Cloud verlagert werden, wird Cloud Computing zu einer Jobvoraussetzung für so ziemlich jeden technisch anspruchsvollen Job, egal ob es sich um einen Job handelt oder nicht DevOps oder ein Datenwissenschaftler.
Was ist Cloud Computing?
Cloud Computing ist die Nutzung von Cloud-basierten Technologien und Plattformen wie AWS, Azure oder Google Cloud zum Speichern und Verarbeiten von Daten. Es ist wie ein virtueller Lagerraum, auf den Sie jederzeit und überall zugreifen können. Anstatt Daten und Rechenressourcen auf lokalen Maschinen oder Servern zu speichern, ermöglicht Cloud Computing Organisationen – und Datenwissenschaftlern – den Zugriff auf diese Ressourcen über das Internet.
Warum ist es wichtig, 2023 Data Scientist zu werden?
Wie ich immer wieder hervorhebe, wächst die Datenmenge, mit der Sie als Data Scientist arbeiten müssen. Immer mehr Unternehmen werden es in die Cloud stecken, anstatt sich vor Ort damit zu befassen. Es wird immer wichtiger, diese Daten skalierbar und effizient speichern und verarbeiten zu können.
Cloud Computing bietet hierfür eine effektive Lösung, die es Data Scientists ermöglicht, auf riesige Mengen an Rechenressourcen und Datenspeicher zuzugreifen, ohne teure Hardware und Infrastruktur zu benötigen.
Wo kann man es lernen?
Die gute Nachricht ist, dass Unternehmen verschiedene Clouds besitzen und viele von ihnen ein begründetes Interesse daran haben, Sie kostenlos darüber zu unterrichten, damit Sie lernen, ihre zu nutzen. Google, Microsoft und Amazon alle haben großartige Cloud-Computing-Ressourcen.
„Warte, haben wir nicht gerade Datenbanken behandelt? Was ist ein Data Warehouse?“ Ich höre dich fragen.
Ich krieg dich. Manchmal scheint es, als ob die wichtigste Data-Science-Fähigkeit darin besteht, alle Akronyme und den Jargon klar zu halten.
Was sind Data Warehousing und ETL?
Lassen Sie uns zunächst Data Warehouses von Datenbanken unterscheiden.
Warehouses speichern aktuelle und historische Daten für mehrere Systeme, während Datenbanken aktuelle Daten speichern, die für ein Projekt benötigt werden. Eine Datenbank speichert die aktuellen Daten, die zum Betreiben einer Anwendung erforderlich sind, während ein Data Warehouse aktuelle und historische Daten für ein oder mehrere Systeme in einem vordefinierten und festen Schema speichert, um die Daten zu analysieren.
Kurz gesagt, Sie würden ein Data Warehouse für Daten für viele verschiedene Projekte zusammen verwenden, während eine Datenbank meistens die Daten eines einzigen Projekts speichert.
ETL ist ein Prozess, der Data Warehousing beinhaltet, kurz für Extract, Transform und Load. Ein ETL-Tool extrahiert Daten aus beliebigen Datenquellensystemen, wandelt sie im Staging-Bereich um (normalerweise bereinigt, manipuliert oder „munget“ sie) und lädt sie dann in ein Data Warehouse.
Warum ist es wichtig, 2023 Data Scientist zu werden?
Ich habe das Gefühl, dass ich diesen Punkt in jedem Skill wiederholt habe, aber die Daten wachsen. Unternehmen sind hungrig danach und erwarten von Ihnen, dass Sie damit umgehen. Zu wissen, wie Daten in erstellbaren Pipelines verwaltet werden, ist von entscheidender Bedeutung.
Wo kann man es lernen?
Ich empfehle zu lernen, wie man eine richtige ETL mit einer bestimmten Sprache wie SQL oder Python durchführt. Datacamp hat eine ein guter mit Python. Microsoft betreibt eine weitere Tutorium für Mittelstufe um eine SQL-Option zu durchlaufen.
Jeder Data Scientist ist ein Modellspezialist. Ich rede nicht von Giselle Bündchen. Ich meine, ein Modell zu erstellen, wie Daten in einem System gespeichert und organisiert werden.
Was ist Datenmodellierung und -verwaltung?
Datenmodellierung und -verwaltung ist der Prozess der Erstellung mathematischer Modelle zur Darstellung von Daten sowie die Verwaltung von Daten zur Aufrechterhaltung ihrer Qualität, Genauigkeit und Nützlichkeit.
Dies umfasst die Definition von Datenentitäten, Beziehungen und Attributen sowie die Implementierung von Prozessen zur Datenvalidierung, -integrität und -sicherheit.
Einfacher ausgedrückt bedeutet Datenmodellierung im Grunde, dass Sie einen Entwurf dafür erstellen, wie Daten in den Systemen Ihres Arbeitgebers organisiert und verbunden werden. Man kann sich das so vorstellen, als würde man einen Bauplan für ein Haus entwerfen. So wie ein Bauplan die verschiedenen Räume und ihre Verbindungen zeigt, zeigt die Datenmodellierung, wie verschiedene Informationen miteinander in Beziehung stehen und miteinander verbunden sind.
Dadurch wird sichergestellt, dass Daten konsistent und effektiv gespeichert und verwendet werden.
Warum ist es wichtig, 2023 Data Scientist zu werden?
Als Data Scientist sind Sie dafür verantwortlich, dass Daten auf zugängliche Weise organisiert und strukturiert sind. Datenmodellierung und -management helfen Ihnen, mit Daten zu arbeiten, sie zu teilen, sicherzustellen, dass sie korrekt sind, und darauf basierende Entscheidungen zu treffen.
Wo kann man es lernen?
Microsoft hat eine gute Intro auf ihrem Blog, nur eine halbe Stunde lang und hoch bewertet. Es ist ein guter Anfang.

Bild von Autor
Viele Data-Science-Begriffe wurden gerade aus anderen Berufen wie Modellierung und Mining geraubt. Lassen Sie uns darauf eingehen, was es bedeutet und warum es wichtig ist.
Was ist Data Mining?
Data Mining ist der Prozess des Extrahierens nützlicher Informationen aus Daten durch Techniken wie Clustering, Klassifizierung und Assoziationsregeln. Sie sichten die wahre Datenflut nach nützlichen Goldnuggets. (Vielleicht wäre Data Panning ein besserer Name für diese Fähigkeit gewesen!)
Warum ist es wichtig, 2023 Data Scientist zu werden?
Stellen Sie sich vor: Sie sind ein Datenwissenschaftler im Jahr 2023. Sie haben Daten aus zehntausend verschiedenen Quellen. Welche Fähigkeiten nutzen Sie, um Muster in all diesen Datenquellen zu erkennen?
Es ist Data-Mining.
Wo kann man es lernen?
Data Mining wird normalerweise in Kursen behandelt, die sich mit Big Data oder Datenanalyse befassen, da es eine ziemlich wichtige Komponente dieser beiden Fähigkeiten ist. EdX bietet ein Paar an Möglichkeiten, Data Mining zu lernen.
Deep Learning unterscheidet sich subtil von maschinellem Lernen! Deep Learning ist ein Teilgebiet des maschinellen Lernens.
Was ist Deep Learning?
Deep Learning ist eine Facette des maschinellen Lernens, die sich auf die Erstellung von Algorithmen konzentriert, die Muster in Daten durch mehrere Schichten künstlicher neuronaler Netze lernen können. (Künstliche neuronale Netze sind übrigens eine Art maschineller Lernalgorithmus, der so modelliert ist, dass er der Struktur und Funktion des menschlichen Gehirns ähnelt.)
Warum ist es wichtig, 2023 Data Scientist zu werden?
Künstliche Intelligenz wird im Jahr 2023 immer ausgefeilter. Es reicht nicht aus, die Grundlagen von KI und ML zu kennen – Sie sollten auch mit dem neuesten Stand vertraut sein, denn das wird morgen nicht mehr der neueste Stand sein. Deep Learning war vor ein paar Jahren neu, und jetzt ist es eine Notwendigkeit.
Von Datenwissenschaftlern wird erwartet, dass sie Deep Learning einsetzen, wenn Unternehmen Zugriff auf eine wirklich große Datenmenge haben. Es wird für Bild- und Videoverarbeitung oder Computer-Vision-Anwendungen verwendet.
Wo kann man es lernen?
antworte ich gerne, Tutorial von Simplilearn als Ausgangspunkt.
Es gibt viele aufstrebende Technologien und Techniken, die Sie kennen sollten. Diese sind entweder noch weiter fortgeschritten, wie Generative Adversarial Networks, oder stärker auf Soft Skills basierend, wie Data Storytelling, oder auf ein Gebiet wie Zeitreihenvorhersage spezialisiert. Diese fasse ich hier kurz zusammen:
- Natürliche Sprachverarbeitung (NLP): Ein Teilgebiet der KI, das sich mit der Verarbeitung und dem Verständnis menschlicher Sprache befasst. Chatbots nutzen dies.
- Zeitreihenanalyse & Prognose: Das Studium von Daten im Laufe der Zeit und die Verwendung statistischer Modelle, um Vorhersagen über zukünftige Ereignisse zu treffen. Sie können diese Fähigkeit verwenden, um Verkaufs- oder Umsatzanalysen durchzuführen.
- Experimentelles Design & A/B-Tests: Der Prozess des Entwerfens und Durchführens kontrollierter Experimente, um Hypothesen zu testen und Entscheidungen auf der Grundlage von Daten zu treffen.
- Storytelling von Daten: Die Fähigkeit, Datenerkenntnisse und -ergebnisse effektiv an nicht-technische Stakeholder zu kommunizieren. Immer mehr Interessenten interessieren sich für die warum hinter datenbasierten Entscheidungen, daher ist dies von entscheidender Bedeutung.
- Generative Adversarial Networks (GANs): Eine Art Deep-Learning-Architektur, bei der zwei neuronale Netze darauf trainiert werden, zusammenzuarbeiten, um neue Daten zu generieren, die einem bestimmten Datensatz ähneln.
- Transferlernen: Eine maschinelle Lerntechnik, bei der ein Modell für eine Aufgabe vortrainiert und für eine verwandte Aufgabe feinabgestimmt wird, wodurch die Leistung verbessert und die Menge der benötigten Trainingsdaten reduziert wird. Kleinere Unternehmen mit begrenzteren Ressourcen werden dies nützlich finden.
- Automatisiertes maschinelles Lernen (AutoML): Eine Methode zur Automatisierung des Auswahl-, Trainings- und Bereitstellungsprozesses von Modellen für maschinelles Lernen.
- Hyperparameter-Tuning: Eine weitere ML-Unterkategorie. Dies ist der Prozess der Optimierung der Leistung eines maschinellen Lernmodells durch Anpassung der Parameter, die nicht aus den Daten gelernt werden, wie z. B. die Lernrate oder die Anzahl der verborgenen Schichten.
- Erklärbare KI (XAI): Ein Zweig der KI, der sich auf die Erstellung von Algorithmen und Modellen konzentriert, die transparent und interpretierbar sind, damit ihre Entscheidungsprozesse von Menschen verstanden werden können. Auch hier hilft es den Beteiligten zu verstehen, was passiert.
Wenn Sie 2023 Data Scientist sein wollen, sind diese 19 Fähigkeiten absolut entscheidend. Die wirklich gute Nachricht ist, dass viele dieser Fähigkeiten autodidaktisch erlernt werden können, während Sie andere erwerben können, während Sie in einer eher untergeordneten Rolle wie einem arbeiten Daten- oder Business-Analyst.
Ein paar Möglichkeiten zu lernen:
- Überprüfen Sie immer YouTube. Es gibt so viele kostenlose, umfassende Ressourcen. Ich habe hier ein paar aufgelistet, aber es gibt praktisch unendlich viele Videos da draußen.
- Plattformen wie Coursera und EdX haben oft Vortragsreihen
- Wir haben über tausend echte Interviewfragen zum Üben, beides codierungsbasiert machen nicht kodierend. Wir bieten auch Beispiele für Datenprojekte.
Genießen Sie die Reise zum Erlernen dieser Fähigkeiten, um im Jahr 2023 Datenwissenschaftler zu werden.
Nate Rosidi ist Data Scientist und in der Produktstrategie. Er ist auch außerplanmäßiger Professor für Analytik und Gründer von StrataScratch, eine Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Top-Unternehmen auf ihre Interviews vorzubereiten. Verbinde dich mit ihm auf Twitter: StrataScratch or LinkedIn.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/04/top-19-skills-need-know-2023-data-scientist.html?utm_source=rss&utm_medium=rss&utm_campaign=top-19-skills-you-need-to-know-in-2023-to-be-a-data-scientist
- :Ist
- $UP
- 2023
- a
- Fähigkeit
- Fähig
- Über uns
- darüber
- absolut
- Zugang
- zugänglich
- Genauigkeit
- genau
- Akronyme
- über
- hinzugefügt
- advanced
- widersprüchlich
- voraus
- AI
- Algorithmus
- Algorithmen
- Alle
- Zulassen
- erlaubt
- bereits
- Amazon
- Betrag
- Beträge
- Analyse
- Analytik
- analysieren
- machen
- und Infrastruktur
- Ein anderer
- von jedem Standort
- Anwendung
- Anwendungen
- Architektur
- SIND
- Bereich
- ankommen
- Kunst
- Artikel
- künstlich
- künstliche Intelligenz
- künstliche neurale Netzwerke
- AS
- Verein
- At
- Attribute
- automatisieren
- Automation
- AutoML
- AWS
- Azure
- Backend
- basierend
- Grundsätzlich gilt
- Grundlagen
- BE
- weil
- werden
- wird
- Werden
- hinter
- Sein
- BESTE
- Besser
- Big
- Big Data
- Milliarde
- Blog
- Gehirn
- Filiale
- Break
- kurz
- Geschäft
- by
- CAN
- Kategorie
- Ändern
- Charts
- Chatbots
- aus der Ferne überprüfen
- Einstufung
- klassifizieren
- Reinigung
- Cloud
- Cloud Computing
- Clustering
- COM
- Kommen
- gemeinsam
- häufig
- mit uns kommunizieren,
- Unternehmen
- Komplex
- Komponente
- zusammengesetzt
- umfassend
- Computer
- Computer Vision
- Computer Vision-Anwendungen
- Computer
- Computing
- konzept
- Leitung
- Vernetz Dich
- Sie
- konsistent
- enthält
- weiter
- gesteuert
- verkaufen
- könnte
- Coursera
- Kurse
- Abdeckung
- bedeckt
- erstellen
- Erstellen
- Schaffung
- kritischem
- wichtig
- Strom
- Kurve
- Schneiden
- technische Daten
- Datenanalyse
- Data Mining
- Datenverarbeitung
- Datenwissenschaft
- Datenwissenschaftler
- Datensatz
- Datensätze
- Datenspeichervorrichtung
- Datenvisualisierung
- Data Warehouse
- Data Warehouse
- Datenbase
- Datenbanken
- Datensätze
- Deal
- Behandlung
- Decision Making
- Entscheidungen
- tief
- tiefe Lernen
- Definition
- Bereitstellen
- Design
- Entwerfen
- entwickeln
- anders
- unterscheiden
- Tut nicht
- nach unten
- gezogen
- Antrieb
- Duplikate
- jeder
- einfacher
- leicht
- Edge
- edx
- Effektiv
- effektiv
- effizient
- entweder
- ermöglicht
- Eingriff
- genug
- gewährleisten
- sorgt
- Entitäten
- essential
- Äther (ETH)
- Sogar
- Veranstaltungen
- Jedes
- vorhandenen
- erwarten
- erwartet
- ERFAHRUNGEN
- exponentiell
- umfangreiche
- Extrakt
- vertraut
- wenige
- Feld
- Finden Sie
- Suche nach
- Vorname
- fixiert
- Flut
- konzentriert
- konzentriert
- Aussichten für
- Format
- Gründer
- Frei
- für
- Funktion
- komisch
- Zukunft
- gewinnen
- GANs
- erzeugen
- erzeugt
- generativ
- generative kontradiktorische Netzwerke
- bekommen
- bekommen
- gegeben
- Blick
- Go
- Goes
- Golden
- gut
- Cumolocity
- Grafik
- Graphen
- groß
- mehr
- Gruppen
- Wachsen Sie über sich hinaus
- persönlichem Wachstum
- Hadoop
- Hälfte
- Pflege
- Griff
- Griffe
- Handling
- Hände
- Los
- Hardware
- Harvard
- Haben
- mit
- hören
- Hilfe
- Unternehmen
- hilft
- hier
- versteckt
- Hervorheben
- hoch
- historisch
- Häuser
- Ultraschall
- Hilfe
- HTTPS
- human
- Humans
- Hungrig
- i
- KRANK
- identifizieren
- Image
- Bilder
- Umsetzung
- wichtig
- zu unterstützen,
- Verbesserung
- in
- zunehmend
- zunehmend
- Branchen
- Energiegewinnung
- Information
- informiert
- Infrastruktur
- Einblicke
- beantragen müssen
- Integrität
- Intelligenz
- Interesse
- Internet
- Interview
- Interview Fragen
- Interviews
- IT
- SEINE
- Jargon
- Job
- Reise
- KDnuggets
- Behalten
- Aufbewahrung
- Wesentliche
- Art
- Wissen
- Wissend
- Wissen
- Land
- Sprache
- grosse
- Lagen
- LERNEN
- gelernt
- lernen
- Lesen
- Lasst uns
- Cholesterinspiegel
- Gefällt mir
- Gelistet
- Belastung
- aus einer regionalen
- Lang
- ich liebe
- Maschine
- Maschinelles Lernen
- Maschinen
- Mainstream
- halten
- um
- MACHT
- Making
- verwalten
- Management
- manipulieren
- Weise
- viele
- Karte
- Master
- mathematisch
- Materie
- Angelegenheiten
- Mittel
- Methode
- Microsoft
- könnte
- Bergbau
- Kommt demnächst...
- ML
- Modell
- Modellieren
- für
- mehr
- vor allem warme
- schlauer bewegen
- mehrere
- Name
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Need
- erforderlich
- benötigen
- Bedürfnisse
- Netzwerke
- Neural
- Neuronale Netze
- Neu
- News
- Nlp
- Nicht-technisch
- Roman
- Anzahl
- Zahlen
- offensichtlich
- of
- bieten
- Angebote
- on
- EINEM
- Optimierung
- Option
- Optionen
- Orakel
- Organisationen
- Organisiert
- Andere
- Anders
- Andernfalls
- Überblick
- besitzen
- Parameter
- Teil
- Muster
- ausführen
- Leistung
- wählen
- ein Bild
- Stücke
- Ort
- Länder/Regionen
- Plattform
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Reichlich
- Points
- Beliebt
- Werkzeuge
- praktisch
- Praxis
- vorhersagen
- vorhergesagt
- Prognosen
- Danach
- ziemlich
- Vorspann
- Aufgabenstellung:
- Probleme
- Prozessdefinierung
- anpassen
- Verarbeitung
- Produkt
- Produkte
- Produkte und Dienstleistungen
- Professor
- programmierten
- Projekt
- Projekte
- Förderung
- ordnungsgemäße
- bietet
- setzen
- Python
- Qualität
- Fragen
- schnell
- Bewerten
- lieber
- Roh
- Rohdaten
- RE
- erreicht
- bereit
- echt
- kürzlich
- erkennen
- empfehlen
- Software Empfehlungen
- Reduzierung
- bezieht sich
- bezogene
- Beziehungen
- Entfernen
- wiederholt
- Quelle
- vertreten
- falls angefordert
- Anforderung
- ähnelt
- Downloads
- Verantwortlichkeiten
- für ihren Verlust verantwortlich.
- Die Ergebnisse
- fortsetzen
- Einnahmen
- Loswerden
- Rollen
- Zimmer
- Schlafzimmer
- Dienstplan
- REIHE
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- s
- Vertrieb
- skalierbaren
- Wissenschaft
- Wissenschaftler
- Wissenschaftler
- Umfang
- Die Geheime
- Abschnitt
- Sicherheitdienst
- Auswahl
- Modellreihe
- Dienstleistungen
- kompensieren
- Sets
- mehrere
- Form
- Teilen
- Short
- sollte
- erklären
- Konzerte
- ähnlich
- da
- Single
- Geschicklichkeit
- Fähigkeiten
- kleinere
- schleichen
- So
- Lösung
- Auflösung
- einige
- Jemand,
- anspruchsvoll
- Quelle
- Quellen
- Spark
- Spezialist
- spezialisiert
- spezifisch
- Rede
- Spot
- SQL
- Aufführung
- Stakeholder
- Anfang
- Beginnen Sie
- statistisch
- bleiben
- Kleben
- Immer noch
- Lagerung
- speichern
- gelagert
- Läden
- Storytelling
- mit Stiel
- Strategie
- Struktur
- strukturierte
- Studie
- so
- zusammenfassen
- Super
- Supermacht
- System
- Systeme und Techniken
- Nehmen
- Einnahme
- sprechen
- Aufgabe
- und Aufgaben
- Einführungen
- Techniken
- Technologies
- Technologie
- zehn
- Tensorfluss
- AGB
- Test
- Testen
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Grundlagen
- die Informationen
- ihr
- Sie
- Dort.
- Diese
- nach drei
- Durch
- Zeit
- Zeitfolgen
- zu
- gemeinsam
- morgen
- auch
- Werkzeug
- Top
- verfolgen sind
- trainiert
- Ausbildung
- Transformieren
- Transformieren
- transparent
- Trends
- vertrauenswürdig
- Lernprogramm
- typisch
- verstehen
- Verständnis
- verstanden
- -
- nützliche Informationen
- gewöhnlich
- Bestätigung
- wertvoll
- Werte
- Vielfalt
- verschiedene
- riesig
- Geschwindigkeit
- Video
- Videos
- Assistent
- Seh-
- Visualisierung
- Volumen
- Volumen
- Warehouse
- Lagerung
- Weg..
- Wege
- Wetter
- Netz
- GUT
- Was
- ob
- welche
- während
- WHO
- werden wir
- mit
- ohne
- Arbeiten
- zusammenarbeiten
- arbeiten,
- würde
- Jahr
- Ihr
- Youtube
- Zephyrnet