AWS Glue Studio ist eine grafische Oberfläche, die das Erstellen, Ausführen und Überwachen von Extraktions-, Transformations- und Ladeaufträgen (ETL) vereinfacht AWS-Kleber. Sie können Datentransformations-Workflows visuell zusammenstellen, indem Sie Knoten verwenden, die verschiedene Datenverarbeitungsschritte darstellen, die später automatisch in auszuführenden Code umgewandelt werden.
AWS Glue Studio vor kurzem veröffentlicht 10 weitere visuelle Transformationen, um fortgeschrittenere Jobs auf visuelle Weise ohne Programmierkenntnisse zu erstellen. In diesem Beitrag diskutieren wir mögliche Anwendungsfälle, die allgemeine ETL-Anforderungen widerspiegeln.
Die neuen Transformationen, die in diesem Beitrag demonstriert werden, sind: Concatenate, Split String, Array To Columns, Add Current Timestamp, Pivot Rows To Columns, Unpivot Columns To Rows, Lookup, Explode Array Or Map Into Columns, Abgeleitete Spalte und Autobalance-Verarbeitung .
Lösungsüberblick
In diesem Anwendungsfall haben wir einige JSON-Dateien mit Aktienoptionsoperationen. Wir möchten vor dem Speichern der Daten einige Transformationen vornehmen, um die Analyse zu erleichtern, und wir möchten auch eine separate Datensatzzusammenfassung erstellen.
In diesem Datensatz repräsentiert jede Zeile einen Handel mit Optionskontrakten. Optionen sind Finanzinstrumente, die das Recht – aber nicht die Verpflichtung – zum Kauf oder Verkauf von Aktien zu einem festgelegten Preis (sog Ausübungspreis) vor einem definierten Ablaufdatum.
Eingabedaten
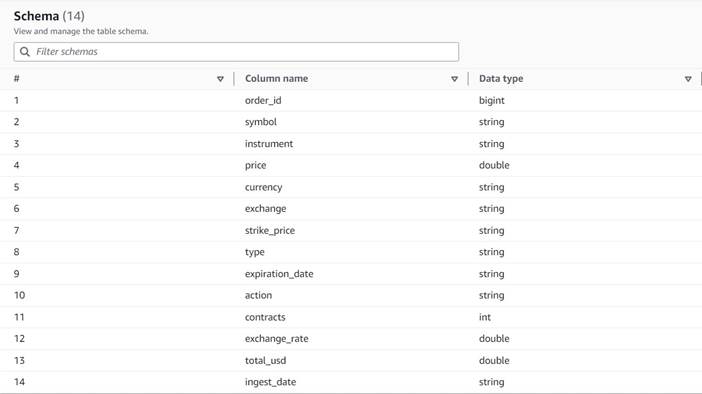
Die Daten folgen dem folgenden Schema:
- Auftragsnummer – Eine eindeutige ID
- Symbol – Ein Code, der im Allgemeinen auf wenigen Buchstaben basiert, um das Unternehmen zu identifizieren, das die zugrunde liegenden Aktien ausgibt
- Instrument – Der Name, der die spezifische Option identifiziert, die gekauft oder verkauft wird
- Währung – Der ISO-Währungscode, in dem der Preis ausgedrückt wird
- Preis – Der Betrag, der für den Kauf jedes Optionskontrakts gezahlt wurde (an den meisten Börsen können Sie mit einem Kontrakt 100 Aktien kaufen oder verkaufen)
- Austausch- – Der Code des Börsenplatzes oder Handelsplatzes, an dem die Option gehandelt wurde
- verkauft – Eine Liste der Anzahl der Kontrakte, die zugewiesen wurden, um den Verkaufsauftrag auszuführen, wenn es sich um einen Verkaufshandel handelt
- gekauft – Eine Liste der Anzahl der Kontrakte, die zugewiesen wurden, um den Kaufauftrag auszuführen, wenn es sich um einen Kaufhandel handelt
Das Folgende ist ein Beispiel der synthetischen Daten, die für diesen Beitrag generiert wurden:
ETL-Anforderungen
Diese Daten weisen eine Reihe einzigartiger Merkmale auf, die häufig auf älteren Systemen zu finden sind und deren Nutzung erschweren.
Im Folgenden sind die ETL-Anforderungen aufgeführt:
- Der Instrumentenname enthält wertvolle Informationen, die für Menschen verständlich sind; Wir möchten es zur einfacheren Analyse in separate Spalten normalisieren.
- Die Attribute
boughtundsoldschließen sich gegenseitig aus; Wir können sie in einer einzigen Spalte mit den Kontraktnummern zusammenfassen und eine weitere Spalte haben, die angibt, ob die Kontrakte in dieser Reihenfolge gekauft oder verkauft wurden. - Wir wollen die Informationen über die einzelnen Vertragszuordnungen erhalten, aber als einzelne Zeilen, anstatt die Benutzer zu zwingen, sich mit einer Reihe von Zahlen auseinanderzusetzen. Wir könnten die Zahlen addieren, aber wir würden Informationen darüber verlieren, wie die Order ausgeführt wurde (was auf die Marktliquidität hinweist). Stattdessen entscheiden wir uns dafür, die Tabelle zu denormalisieren, sodass jede Zeile eine einzelne Anzahl von Kontrakten enthält, wobei Aufträge mit mehreren Nummern in separate Zeilen aufgeteilt werden. In einem komprimierten Spaltenformat ist die zusätzliche Dataset-Größe dieser Wiederholung oft gering, wenn die Komprimierung angewendet wird, sodass es akzeptabel ist, das Dataset einfacher abzufragen.
- Wir möchten eine zusammenfassende Volumentabelle für jeden Optionstyp (Call und Put) für jede Aktie erstellen. Dies liefert einen Hinweis auf die Marktstimmung für jede Aktie und den Markt im Allgemeinen (Gier vs. Angst).
- Um allgemeine Handelszusammenfassungen zu ermöglichen, möchten wir für jede Transaktion die Gesamtsumme angeben und die Währung auf US-Dollar standardisieren, wobei eine ungefähre Umrechnungsreferenz verwendet wird.
- Wir möchten das Datum hinzufügen, an dem diese Transformationen stattfanden. Dies kann beispielsweise nützlich sein, um einen Hinweis darauf zu haben, wann die Währungsumrechnung durchgeführt wurde.
Basierend auf diesen Anforderungen erzeugt der Job zwei Ausgaben:
- Eine CSV-Datei mit einer Zusammenfassung der Anzahl der Kontrakte für jedes Symbol und jeden Typ
- Eine Katalogtabelle, um eine Historie der Bestellung zu führen, nachdem die angegebenen Transformationen durchgeführt wurden
Voraussetzungen:
Sie benötigen Ihren eigenen S3-Bucket, um diesen Anwendungsfall zu verfolgen. Informationen zum Erstellen eines neuen Buckets finden Sie unter Einen Eimer erstellen.
Generieren Sie synthetische Daten
Um diesem Beitrag zu folgen (oder selbst mit dieser Art von Daten zu experimentieren), können Sie diesen Datensatz synthetisch generieren. Das folgende Python-Skript kann in einer Python-Umgebung mit installiertem Boto3 und Zugriff darauf ausgeführt werden Amazon Simple Storage-Service (Amazon S3).
Führen Sie die folgenden Schritte aus, um die Daten zu generieren:
- Erstellen Sie in AWS Glue Studio einen neuen Job mit der Option Python-Shell-Skript-Editor.
- Geben Sie dem Job einen Namen und auf der Jobdetails wählen Sie a passende Rolle und einen Namen für das Python-Skript.
- Im Jobdetails Abschnitt, erweitern Erweiterte Eigenschaften und scrollen Sie nach unten Auftragsparameter.
- Geben Sie einen Parameter namens ein
--bucketund weisen Sie als Wert den Namen des Buckets zu, in dem Sie die Beispieldaten speichern möchten. - Geben Sie das folgende Skript in den AWS Glue-Shell-Editor ein:
- Führen Sie den Job aus und warten Sie, bis er auf der Registerkarte „Ausführungen“ als erfolgreich abgeschlossen angezeigt wird (es sollte nur wenige Sekunden dauern).
Bei jeder Ausführung wird eine JSON-Datei mit 1,000 Zeilen unter dem angegebenen Bucket und Präfix generiert transformsblog/inputdata/. Sie können den Job mehrmals ausführen, wenn Sie mit mehr Eingabedateien testen möchten.
Jede Zeile in den synthetischen Daten ist eine Datenzeile, die ein JSON-Objekt wie das folgende darstellt:
Erstellen Sie den visuellen AWS Glue-Job
Führen Sie die folgenden Schritte aus, um den visuellen AWS Glue-Job zu erstellen:
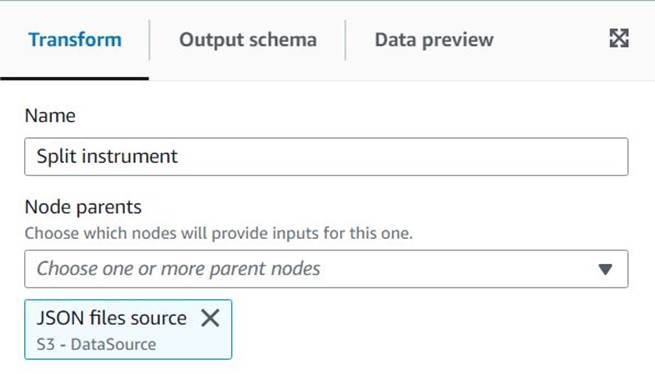
- Gehen Sie zu AWS Glue Studio und erstellen Sie mit der Option einen Job Visuell mit einer leeren Leinwand.
- Bearbeiten
Untitled jobum ihm einen Namen zu geben und zuzuordnen eine für AWS Glue geeignete Rolle auf die Jobdetails Tab. - Fügen Sie eine S3-Datenquelle hinzu (Sie können ihr einen Namen geben
JSON files source) und geben Sie die S3-URL ein, unter der die Dateien gespeichert sind (z. B.s3://<your bucket name>/transformsblog/inputdata/), dann auswählen JSON als Datenformat. - Auswählen Schema ableiten Daher wird das Ausgabeschema basierend auf den Daten festgelegt.
Von diesem Quellknoten aus verketten Sie weiterhin Transformationen. Stellen Sie beim Hinzufügen jeder Transformation sicher, dass der ausgewählte Knoten der letzte hinzugefügte Knoten ist, sodass er als übergeordneter Knoten zugewiesen wird, sofern in den Anweisungen nicht anders angegeben.
Wenn Sie nicht das richtige übergeordnete Element ausgewählt haben, können Sie das übergeordnete Element jederzeit bearbeiten, indem Sie es auswählen und im Konfigurationsbereich ein anderes übergeordnetes Element auswählen.
Für jeden hinzugefügten Knoten geben Sie ihm einen bestimmten Namen (so dass der Zweck des Knotens im Diagramm angezeigt wird) und eine Konfiguration auf der Transformieren Tab.
Jedes Mal, wenn eine Transformation das Schema ändert (z. B. eine neue Spalte hinzufügt), muss das Ausgabeschema aktualisiert werden, damit es für die nachgelagerten Transformationen sichtbar ist. Sie können das Ausgabeschema manuell bearbeiten, aber es ist praktischer und sicherer, dies über die Datenvorschau zu tun.
Außerdem können Sie auf diese Weise überprüfen, ob die Transformation soweit wie erwartet funktioniert. Öffnen Sie dazu die Datenvorschau Registerkarte mit der ausgewählten Transformation und starten Sie eine Vorschausitzung. Nachdem Sie überprüft haben, dass die transformierten Daten wie erwartet aussehen, gehen Sie zu Ausgabeschema Tab und wählen Verwenden Sie das Datenvorschauschema um das Schema automatisch zu aktualisieren.
Wenn Sie neue Arten von Transformationen hinzufügen, zeigt die Vorschau möglicherweise eine Meldung über eine fehlende Abhängigkeit an. Wenn dies geschieht, wählen Sie Sitzung beenden und starten Sie einen neuen, damit die Vorschau die neue Art von Knoten aufnimmt.
Instrumenteninformationen extrahieren
Beginnen wir damit, uns mit den Informationen zum Instrumentennamen zu befassen, um ihn in Spalten zu normalisieren, auf die in der resultierenden Ausgabetabelle leichter zugegriffen werden kann.
- Hinzufügen String teilen Split Knoten und benennen Sie ihn
Split instrument, die die Instrumentenspalte mit einem Whitespace-Regex tokenisiert:s+(Ein einzelnes Leerzeichen würde in diesem Fall ausreichen, aber dieser Weg ist flexibler und visuell klarer). - Wir möchten die ursprünglichen Instrumenteninformationen beibehalten, geben Sie also einen neuen Spaltennamen für das geteilte Array ein:
instrument_arr.
- Fügen Sie ein ein Array zu Spalten Knoten und benennen Sie ihn
Instrument columnsum die gerade erstellte Array-Spalte in neue Felder umzuwandeln, außer fürsymbol, für die wir bereits eine Spalte haben. - Wählen Sie die Spalte aus
instrument_arr, überspringen Sie das erste Token und weisen Sie es an, die Ausgabespalten zu extrahierenmonth, day, year, strike_price, typeVerwendung von Indizes2, 3, 4, 5, 6(Die Leerzeichen nach den Kommas dienen der Lesbarkeit, sie wirken sich nicht auf die Konfiguration aus).
Das extrahierte Jahr wird nur mit zwei Ziffern ausgedrückt; Lassen Sie uns eine Lücke schließen, um anzunehmen, dass es in diesem Jahrhundert ist, wenn sie nur zwei Ziffern verwenden.
- Hinzufügen Abgeleitete Spalte Knoten und benennen Sie ihn
Four digits year. - Enter
yearals abgeleitete Spalte, damit sie diese überschreibt, und geben Sie den folgenden SQL-Ausdruck ein:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Der Einfachheit halber bauen wir eine expiration_date Feld, das ein Benutzer als Referenz für das letzte Datum haben kann, an dem die Option ausgeübt werden kann.
- Hinzufügen Spalten verketten Knoten und benennen Sie ihn
Build expiration date. - Benennen Sie die neue Spalte
expiration_date, wähle die Spalten ausyear,monthundday(in dieser Reihenfolge) und einen Bindestrich als Abstandshalter.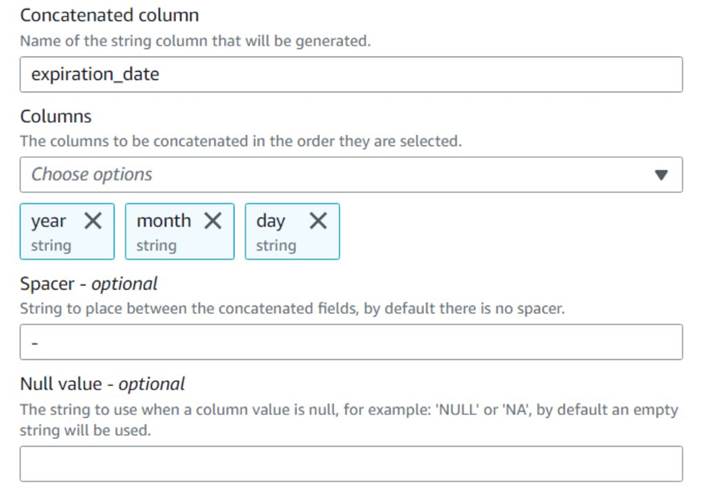
Das bisherige Diagramm sollte wie im folgenden Beispiel aussehen.
![]()
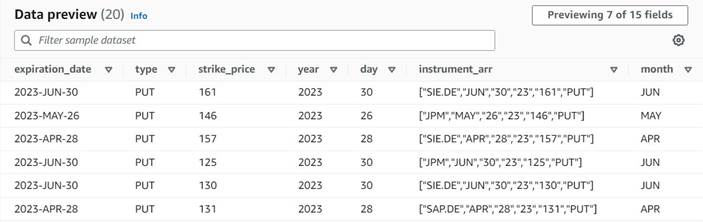
Die Datenvorschau der neuen Spalten sollte bisher wie im folgenden Screenshot aussehen.
Normalisieren Sie die Anzahl der Verträge
Jede der Zeilen in den Daten gibt die Anzahl der Kontrakte jeder Option an, die gekauft oder verkauft wurden, und die Chargen, für die die Aufträge ausgeführt wurden. Ohne die Informationen zu den einzelnen Chargen zu verlieren, möchten wir jeden Betrag in einer einzelnen Zeile mit einem einzelnen Betragswert haben, während der Rest der Informationen in jeder produzierten Zeile repliziert wird.
Lassen Sie uns zunächst die Beträge in einer einzigen Spalte zusammenführen.
- Fügen Sie ein ein Entpivotieren Sie Spalten in Zeilen Knoten und benennen Sie ihn
Unpivot actions. - Wählen Sie die Spalten aus
boughtundsoldum die Namen und Werte in den benannten Spalten zu entpivotieren und zu speichernactionundcontracts, Bzw.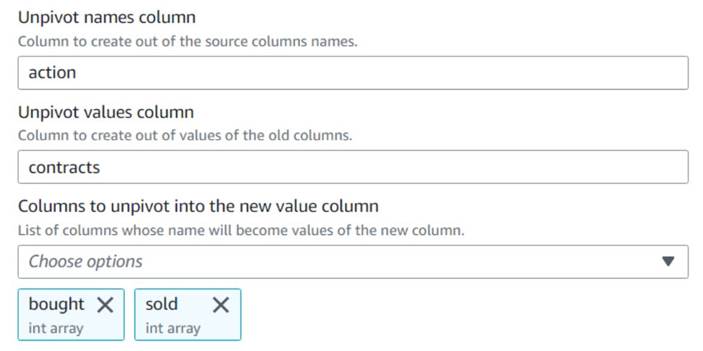
Beachten Sie in der Vorschau, dass die neue Spaltecontractsist nach dieser Transformation immer noch ein Array von Zahlen.
- Fügen Sie ein ein Explodieren Sie Array oder Map in Zeilen Reihe benannt
Explode contracts. - Wähle die
contractsSpalte und geben Sie eincontractsals neue Spalte, um sie zu überschreiben (wir müssen das ursprüngliche Array nicht beibehalten).
Die Vorschau zeigt nun, dass jede Reihe eine Single hat contracts Betrag, und die restlichen Felder sind gleich.
Das bedeutet auch, dass order_id ist kein eindeutiger Schlüssel mehr. Für Ihre eigenen Anwendungsfälle müssen Sie entscheiden, wie Sie Ihre Daten modellieren und ob Sie denormalisieren möchten oder nicht.
Der folgende Screenshot ist ein Beispiel dafür, wie die neuen Spalten nach den bisherigen Transformationen aussehen.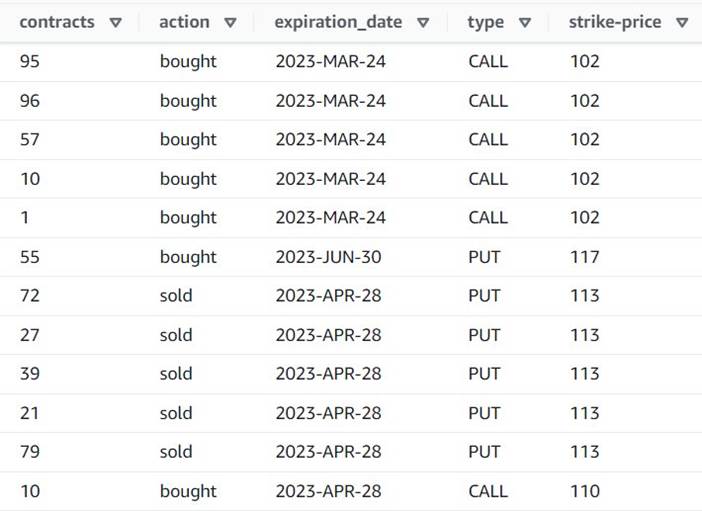
Erstellen Sie eine Übersichtstabelle
Jetzt erstellen Sie eine zusammenfassende Tabelle mit der Anzahl der gehandelten Kontrakte für jeden Typ und jedes Aktiensymbol.
Nehmen wir zur Veranschaulichung an, dass die verarbeiteten Dateien zu einem einzigen Tag gehören, sodass diese Zusammenfassung den Geschäftsanwendern Informationen über das Marktinteresse und die Marktstimmung an diesem Tag gibt.
- Hinzufügen Felder auswählen Knoten und wählen Sie die folgenden Spalten aus, die für die Zusammenfassung beibehalten werden sollen:
symbol,typeundcontracts.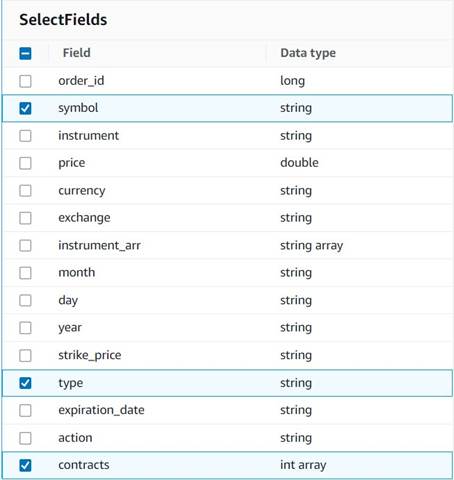
- Hinzufügen Pivot-Zeilen in Spalten Knoten und benennen Sie ihn
Pivot summary. - Aggregat auf der
contractsSpalte mitsumund wählen Sie, um die zu konvertierentypeSpalte.
Normalerweise würden Sie es zu Referenzzwecken in einer externen Datenbank oder Datei speichern; In diesem Beispiel speichern wir es als CSV-Datei auf Amazon S3.
- Fügen Sie ein ein Autobalance-Verarbeitung Knoten und benennen Sie ihn
Single output file. - Obwohl dieser Transformationstyp normalerweise verwendet wird, um die Parallelität zu optimieren, verwenden wir ihn hier, um die Ausgabe auf eine einzelne Datei zu reduzieren. Geben Sie daher ein
1in der Konfiguration der Anzahl der Partitionen.
- Fügen Sie ein S3-Ziel hinzu und benennen Sie es
CSV Contract summary. - Wählen Sie als Datenformat CSV und geben Sie einen S3-Pfad ein, in dem die Job-Rolle Dateien speichern darf.
Der letzte Teil des Jobs sollte nun wie im folgenden Beispiel aussehen.![]()
- Speichern Sie den Job und führen Sie ihn aus. Verwenden Sie die Läuft Registerkarte, um zu überprüfen, ob es erfolgreich abgeschlossen wurde.
Unter diesem Pfad finden Sie eine Datei, die eine CSV-Datei ist, obwohl sie diese Erweiterung nicht hat. Sie müssen die Erweiterung wahrscheinlich nach dem Herunterladen hinzufügen, um sie zu öffnen.
Auf einem Tool, das CSV lesen kann, sollte die Zusammenfassung etwa wie im folgenden Beispiel aussehen.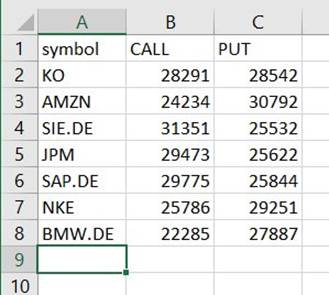
Bereinigen Sie temporäre Spalten
Lassen Sie uns in Vorbereitung auf das Speichern der Bestellungen in einer Verlaufstabelle für zukünftige Analysen einige temporäre Spalten bereinigen, die auf dem Weg erstellt wurden.
- Hinzufügen Drop-Felder Knoten mit dem
Explode contractsKnoten, der als übergeordneter Knoten ausgewählt wurde (wir verzweigen die Datenpipeline, um eine separate Ausgabe zu generieren). - Wählen Sie die zu löschenden Felder aus:
instrument_arr,month,dayundyear.
Den Rest möchten wir behalten, damit er in der historischen Tabelle gespeichert wird, die wir später erstellen werden.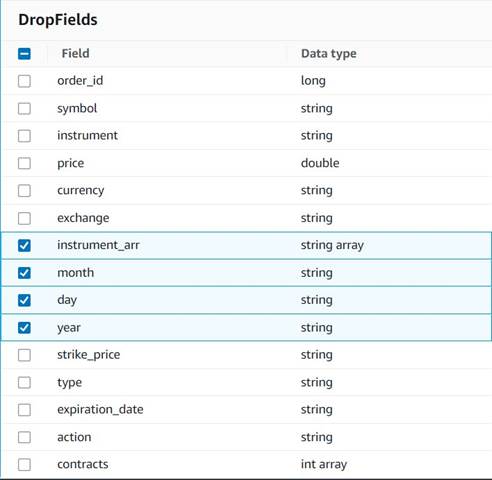
Währungsstandardisierung
Diese synthetischen Daten enthalten fiktive Operationen mit zwei Währungen, aber in einem realen System könnten Sie Währungen von Märkten auf der ganzen Welt erhalten. Es ist nützlich, die gehandhabten Währungen in einer einzigen Referenzwährung zu standardisieren, damit sie für Berichte und Analysen einfach verglichen und aggregiert werden können.
Wir verwenden Amazonas Athena um eine Tabelle mit ungefähren Währungsumrechnungen zu simulieren, die regelmäßig aktualisiert wird (hier gehen wir davon aus, dass wir die Bestellungen so zeitnah bearbeiten, dass die Umrechnung zu Vergleichszwecken angemessen repräsentativ ist).
- Öffnen Sie die Athena-Konsole in derselben Region, in der Sie AWS Glue verwenden.
- Führen Sie die folgende Abfrage aus, um die Tabelle zu erstellen, indem Sie einen S3-Speicherort festlegen, an dem sowohl Ihre Athena- als auch Ihre AWS Glue-Rollen lesen und schreiben können. Außerdem möchten Sie die Tabelle möglicherweise in einer anderen Datenbank als speichern
default(Wenn Sie dies tun, aktualisieren Sie den qualifizierten Namen der Tabelle in den bereitgestellten Beispielen entsprechend). - Geben Sie einige Beispielumrechnungen in die Tabelle ein:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Sie sollten die Tabelle jetzt mit der folgenden Abfrage anzeigen können:
SELECT * FROM default.exchange_rates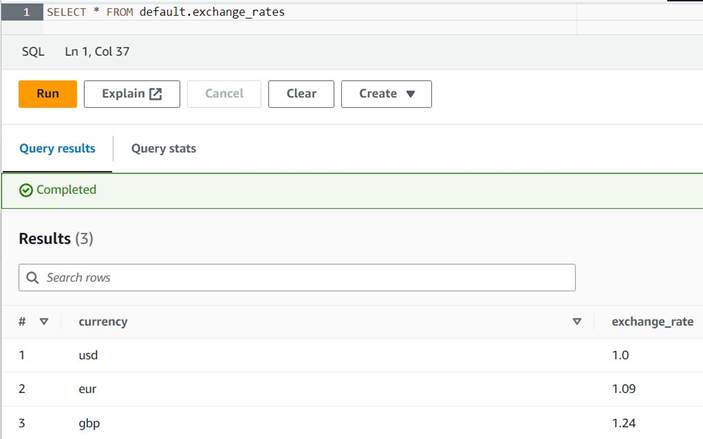
- Zurück zum visuellen AWS Glue-Job, fügen Sie a hinzu Lookup Knoten (als Kind von
Drop Fields) und nennen Sie esExchange rate. - Geben Sie den qualifizierten Namen der gerade erstellten Tabelle mit ein
currencyals Taste und wählen Sie die ausexchange_rateFeld zu verwenden.
Da das Feld sowohl in den Daten als auch in der Nachschlagetabelle gleich benannt ist, können wir einfach den Namen eingebencurrencyund müssen kein Mapping definieren.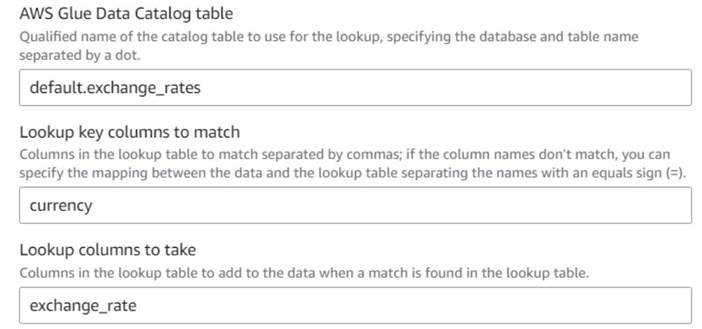
Zum Zeitpunkt der Erstellung dieses Artikels wird die Lookup-Transformation in der Datenvorschau nicht unterstützt und es wird ein Fehler angezeigt, dass die Tabelle nicht vorhanden ist. Dies dient nur der Datenvorschau und verhindert nicht, dass der Job korrekt ausgeführt wird. Die wenigen verbleibenden Schritte des Beitrags erfordern keine Aktualisierung des Schemas. Wenn Sie eine Datenvorschau auf anderen Knoten ausführen müssen, können Sie den Lookup-Knoten vorübergehend entfernen und dann wieder einfügen. - Hinzufügen Abgeleitete Spalte Knoten und benennen Sie ihn
Total in usd. - Benennen Sie die abgeleitete Spalte
total_usdund verwenden Sie den folgenden SQL-Ausdruck:round(contracts * price * exchange_rate, 2)
- Hinzufügen Aktuellen Zeitstempel hinzufügen Knoten und benennen Sie die Spalte
ingest_date. - Verwenden Sie das Format
%Y-%m-%dfür Ihren Zeitstempel (zu Demonstrationszwecken verwenden wir nur das Datum; Sie können es präzisieren, wenn Sie möchten).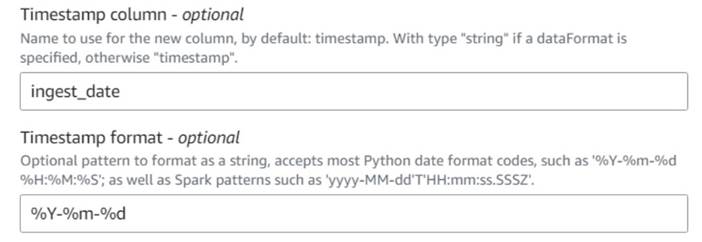
Speichern Sie die historische Auftragstabelle
Führen Sie die folgenden Schritte aus, um die Tabelle mit historischen Bestellungen zu speichern:
- Fügen Sie einen S3-Zielknoten hinzu und benennen Sie ihn
Orders table. - Konfigurieren Sie das Parquet-Format mit bissiger Komprimierung und geben Sie einen S3-Zielpfad an, unter dem die Ergebnisse gespeichert werden (getrennt von der Zusammenfassung).
- Auswählen Erstellen Sie eine Tabelle im Datenkatalog und aktualisieren Sie bei nachfolgenden Ausführungen das Schema und fügen Sie neue Partitionen hinzu.
- Geben Sie eine Zieldatenbank und einen Namen für die neue Tabelle ein, zum Beispiel:
option_orders.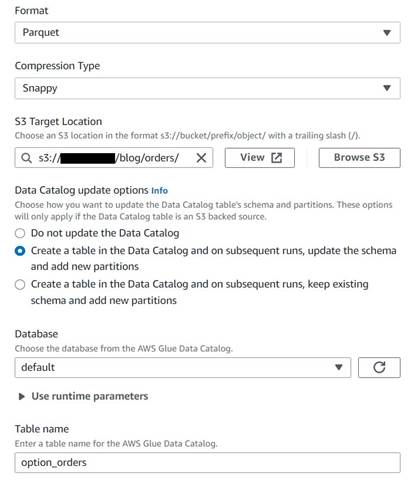
Der letzte Teil des Diagramms sollte nun wie folgt aussehen, mit zwei Zweigen für die zwei getrennten Ausgänge.![]()
Nachdem Sie den Job erfolgreich ausgeführt haben, können Sie ein Tool wie Athena verwenden, um die Daten zu überprüfen, die der Job erzeugt hat, indem Sie die neue Tabelle abfragen. Sie können den Tisch auf der Athena-Liste finden und auswählen Vorschautabelle oder führen Sie einfach eine SELECT-Abfrage aus (aktualisieren Sie den Tabellennamen auf den von Ihnen verwendeten Namen und Katalog):
SELECT * FROM default.option_orders limit 10
Der Inhalt Ihrer Tabelle sollte dem folgenden Screenshot ähneln.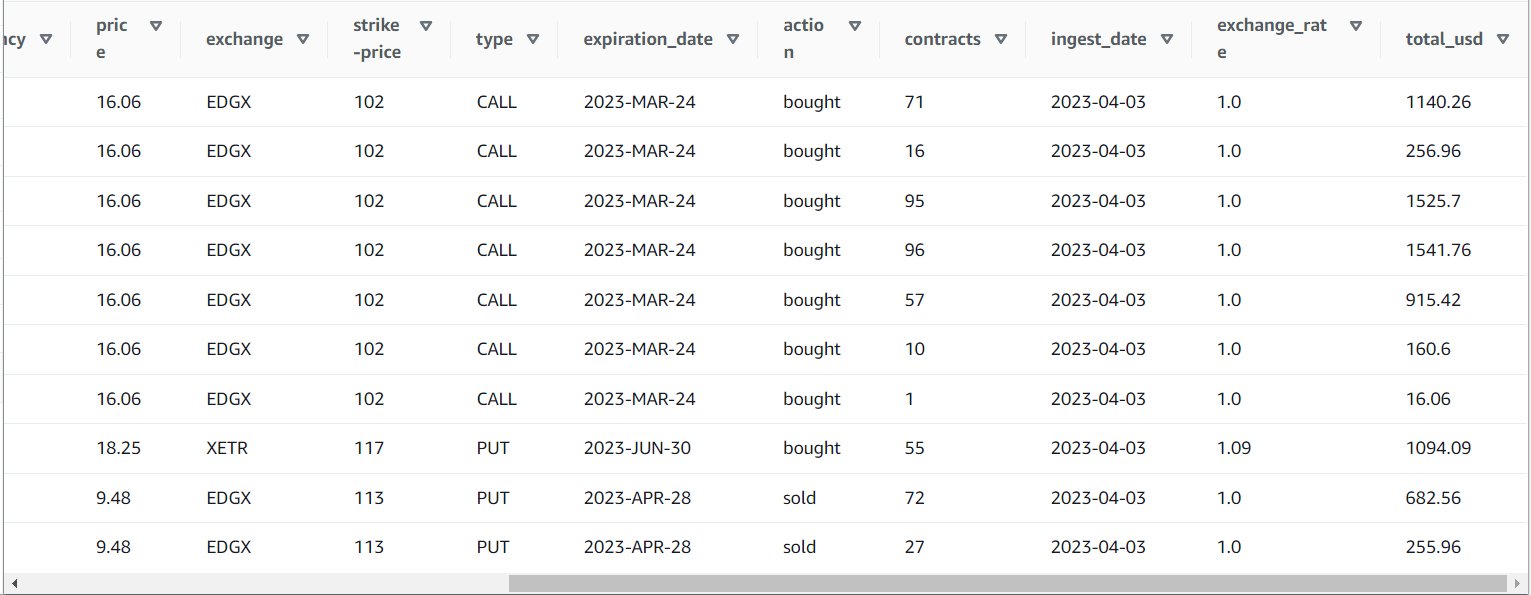
Aufräumen
Wenn Sie dieses Beispiel nicht beibehalten möchten, löschen Sie die beiden von Ihnen erstellten Jobs, die beiden Tabellen in Athena und die S3-Pfade, in denen die Eingabe- und Ausgabedateien gespeichert waren.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie die neuen Transformationen in AWS Glue Studio Ihnen helfen können, fortgeschrittenere Transformationen mit minimaler Konfiguration durchzuführen. Das bedeutet, dass Sie mehr ETL-Anwendungsfälle implementieren können, ohne Code schreiben und pflegen zu müssen. Die neuen Transformationen sind bereits in AWS Glue Studio verfügbar, sodass Sie die neuen Transformationen noch heute in Ihren visuellen Jobs verwenden können.
Über den Autor
![]() Gonzalo herreros ist Senior Big Data Architect im AWS Glue-Team.
Gonzalo herreros ist Senior Big Data Architect im AWS Glue-Team.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Kaufen und verkaufen Sie Anteile an PRE-IPO-Unternehmen mit PREIPO®. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Fähig
- Über uns
- akzeptabel
- Zugang
- entsprechend
- hinzufügen
- hinzugefügt
- Hinzufügen
- advanced
- Nach der
- Alle
- zugeordnet
- Zuweisungen
- erlauben
- erlaubt
- entlang
- bereits
- ebenfalls
- immer
- Amazon
- Betrag
- Beträge
- an
- Analyse
- analysieren
- und
- Ein anderer
- jedem
- angewandt
- ungefähr
- Apr
- SIND
- Argument
- Feld
- AS
- zugewiesen
- At
- Attribute
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- AWS
- AWS-Kleber
- Zurück
- basierend
- BE
- Bevor
- Sein
- Big
- Big Data
- leer
- BMW
- beide
- gekauft
- Geäst
- bauen
- Geschäft
- aber
- Kaufe
- by
- rufen Sie uns an!
- CAN
- Häuser
- Fälle
- Katalog
- Center
- Jahrhundert
- Änderungen
- Charakteristik
- aus der Ferne überprüfen
- der
- Auswählen
- Auswahl
- klarer
- Code
- Programmierung
- Kolonne
- Spalten
- gemeinsam
- verglichen
- Vergleich
- abschließen
- Abgeschlossene Verkäufe
- Konfiguration
- Konsul (Console)
- konsolidieren
- enthält
- Inhalt
- Vertrag
- Verträge
- sehr beliebtes Sprach- und Freizeitprogramm
- Umwandlung (Conversion)
- Konvertierungen
- verkaufen
- umgewandelt
- KONZERN
- könnte
- erstellen
- erstellt
- Erstellen
- Coins
- Währung
- Strom
- TAG
- technische Daten
- Datenbase
- Datum
- Datum
- datetime
- Tag
- Deal
- Behandlung
- entscheidet
- Standard
- definiert
- weisen nach, dass
- Abhängigkeit
- Abgeleitet
- Trotz
- Details
- anders
- Ziffern
- diskutieren
- do
- Tut nicht
- Dabei
- Dollar
- Nicht
- doppelt
- nach unten
- Drop
- fallen gelassen
- jeder
- einfacher
- leicht
- Einfache
- Herausgeber
- ermöglichen
- genug
- Enter
- Arbeitsumfeld
- Fehler
- Äther (ETH)
- EUR
- Beispiel
- Beispiele
- Außer
- Austausch-
- Warenumtausch
- Exclusive
- existieren
- Erweitern Sie die Funktionalität der
- erwartet
- Experiment
- Ablauf
- zum Ausdruck gebracht
- Erweiterung
- extern
- extra
- Extrakt
- weit
- Angst
- wenige
- fiktiv
- Feld
- Felder
- Reichen Sie das
- Mappen
- füllen
- gefüllt
- Revolution
- Finanzinstrumente
- Finden Sie
- Vorname
- fixiert
- flexibel
- folgen
- Folgende
- folgt
- Aussichten für
- Format
- gefunden
- für
- Zukunft
- GBP (Faster Payments Service, Advcash, ZEN)
- Allgemeines
- allgemein
- erzeugen
- erzeugt
- bekommen
- ABSICHT
- gibt
- Go
- Graph
- Gier
- Handling
- das passiert
- Haben
- mit
- Hilfe
- hier
- historisch
- Geschichte
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- Humans
- i
- identifiziert
- identifizieren
- if
- Impact der HXNUMXO Observatorien
- implementieren
- importieren
- in
- Indizes
- angegeben
- zeigt
- Anzeige
- Indikation
- Krankengymnastik
- Information
- Varianten des Eingangssignals:
- Instanz
- beantragen müssen
- Anleitung
- Instrument
- Instrumente
- Interesse
- Schnittstelle
- in
- ISO
- IT
- SEINE
- Job
- Jobs
- jpg
- JSON
- nur
- Behalten
- Wesentliche
- Art
- Nachname
- später
- Gefällt mir
- LIMIT
- Line
- Liquidity
- Liste
- Belastung
- Standorte
- länger
- aussehen
- aussehen wie
- SIEHT AUS
- Nachschlagen
- verlieren
- verlieren
- gemacht
- halten
- um
- MACHT
- manuell
- Karte
- Mapping
- Markt
- Grundstimmung des Marktes
- Märkte
- Kann..
- Mittel
- Merge
- Nachricht
- könnte
- Minimum
- Kommt demnächst...
- Modell
- Überwachen
- mehr
- vor allem warme
- mehrere
- gegenseitig
- Name
- Namens
- Namen
- Need
- Bedürfnisse
- Neu
- nicht
- Knoten
- Fiber Node
- Normalerweise
- jetzt an
- Anzahl
- Zahlen
- Objekt
- of
- vorgenommen,
- on
- EINEM
- einzige
- XNUMXh geöffnet
- Betrieb
- Einkauf & Prozesse
- Optimieren
- Option
- Optionen
- or
- Auftrag
- Bestellungen
- Original
- Andere
- Andernfalls
- Möglichkeiten für das Ausgangssignal:
- übrig
- Gesamt-
- Override
- besitzen
- bezahlt
- Brot
- Parameter
- Teil
- Weg
- Picks
- Pipeline
- Drehpunkt
- Ort
- Plato
- Datenintelligenz von Plato
- PlatoData
- Post
- Potenzial
- Praktisch
- präzise
- verhindern
- Vorspann
- Preis
- wahrscheinlich
- Prozessdefinierung
- Verarbeitung
- produziert
- Produziert
- die
- vorausgesetzt
- bietet
- Kauf
- Zweck
- Zwecke
- setzen
- Python
- qualifiziert
- erhöhen
- zufällig
- Lesen Sie mehr
- echt
- vernünftig
- Veteran
- reflektieren
- Region
- verbleibenden
- entfernen
- repliziert
- Reporting
- vertreten
- Vertreter
- Darstellen
- representiert
- erfordern
- Voraussetzungen:
- erfordert
- beziehungsweise
- REST
- was zu
- Die Ergebnisse
- Überprüfen
- Rollen
- Rollen
- REIHE
- Führen Sie
- Laufen
- Sicherheit
- gleich
- Saft
- Speichern
- Einsparung
- blättern
- Sekunden
- ausgewählt
- Auswahl
- verkaufen
- Senior
- Gefühl
- getrennte
- Sitzung
- Sets
- Einstellung
- Shares
- Schale
- sollte
- erklären
- Konzerte
- ähnlich
- Einfacher
- Single
- Größe
- Fähigkeiten
- klein
- So
- bis jetzt
- verkauft
- einige
- etwas
- Quelle
- Raumfahrt
- Räume
- spezifisch
- angegeben
- gespalten
- Kalkulationstabelle
- SQL
- Anfang
- Shritte
- Immer noch
- -bestands-
- Lagerung
- speichern
- gelagert
- Schnur
- Studio Adressen
- Folge
- Erfolgreich
- geeignet
- ZUSAMMENFASSUNG
- Unterstützte
- Symbol
- synthetisch
- synthetische Daten
- synthetisch
- System
- Systeme und Techniken
- Tabelle
- Nehmen
- Target
- Team
- erzählen
- vorübergehend
- zehn
- Test
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Der Graph
- die Informationen
- die Welt
- Sie
- dann
- deswegen
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- Zeit
- mal
- Zeitstempel
- zu
- heute
- Zeichen
- tokenisieren
- nahm
- Werkzeug
- Gesamt
- Handel
- gehandelt
- Transformieren
- Transformation
- Transformationen
- verwandelt
- XNUMX
- tippe
- für
- zugrunde liegen,
- verstehen
- einzigartiges
- bis
- Aktualisierung
- aktualisiert
- Aktualisierung
- URL
- us
- US-Dollar
- USD
- -
- Anwendungsfall
- benutzt
- Mitglied
- Nutzer
- Verwendung von
- wertvoll
- Wertvolle Information
- Wert
- Werte
- Veranstaltungsort
- verified
- überprüfen
- Anzeigen
- sichtbar
- Volumen
- vs
- warten
- wollen
- wurde
- Weg..
- we
- waren
- Was
- wann
- welche
- während
- werden wir
- mit
- ohne
- Workflows
- arbeiten,
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- würde
- schreiben
- Schreiben
- Jahr
- U
- Ihr
- Zephyrnet











